
(邦訳:機械読解における自然言語理解の評価)
| 菅原 朔 国立情報学研究所 助教 |
キーワード
| 自然言語処理 | 言語理解 | 文章読解 |
[背景]言葉を理解しているかどうか文章題で評価
[問題]ちゃんと分かっているかどうかを知るのは難しい
[貢献]質問の品質を検証・分析するための方法を提案
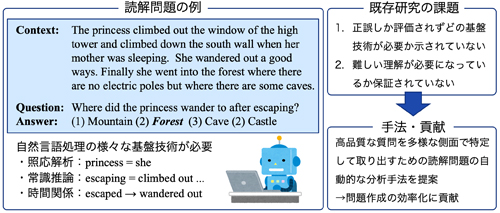
背景:自然言語処理分野では,人間のように文章を理解するシステムを作ることがひとつの大きな目標です.研究を進めるためにはシステムの言語理解の良さを評価するためのタスクが必要であり,そのひとつとして国語の文章題のような形式の質問が課される機械読解タスクがあります.近年は機械学習技術の進展にともなって数万単位の問題数を備えたデータセットが(主に英語で)多く提案され,より高性能なシステムを作るために世界中の大学やIT企業の研究者が研究を進めています.中には人間と同程度の性能が出せるシステムも登場しています.
課題:しかし,限られたデータセットの上で高性能なシステムを開発できたとしても大きく2つの課題が残っています.1つは,現状ほとんどの場合システムの性能を「データセット中でどれくらいの割合の質問が解けたか」という観点でしか評価していないことです.そのような評価のみだと,文章理解に含まれるような仕組み,たとえば指示表現が何を指すか当てることや,否定文・条件文が論理的に理解できることなど多様な側面の理解について詳細に知ることができません.もう1つは,現状の読解問題では本当に高度な読解が必要とされていないかもしれないことです.たとえば課題文の末尾に「質問文によく似た紛らわしい文 (ただし本来の正答は変わらない)」を人手で作成して追加すると,既存のシステムの性能が大きく低下することが分かっています.ちゃんと文章を読んでいるというよりも,質問文に出てくる単語を課題文から探してそれが近くにある答えを選んでいる可能性があるということです(近年の機械学習モデルは特にそういうことが得意です).以上のような課題があると,見かけ上は高性能なシステムであっても実際にできることは限られ,社会で応用するときに大きな問題になってしまうかもしれません.
手法と貢献:まず上記の2つの課題について解決策を提案しました.1つ目の課題については,読解で登場すると考えられる能力を10ほど定義して,それぞれが問題を解くのに必要になるかどうか人手で分析できるようにしました.2つ目の課題については,「ちゃんと文章を読まなくても質問文との単語の一致を見るだけで簡単に解けてしまう質問」を特定する方法を考案し,なるべく難しい質問を見つけられるようにしました.最後に両者をまとめる形で,複雑な推論・能力が必要とされると思われる質問を特定するための自動的な手法を提案しました.たとえば「課題文のそれぞれの文の語順をランダムに並べ替えても質問が解けてしまうかどうか」を確認します.もしシステムが解けるならば,文章の主語・述語などが正確に分からなくても解ける,つまりその質問は文の構造について正確な理解を要求していないかもしれないことが分かります.このような手法をいくつか考案して既存のデータセットに適用することで,すでにシステムが解けている多くの質問では推論・文法の観点から高度な言語理解が要求されているわけではなさそうである,という観察を得ました.今後より良いデータセットを開発する際に本研究が提案する手法を使うことで,特定の能力を必要とされないものを取り除きながら質問を集められるようになり,円滑な言語理解システムの評価・発展に寄与すると考えられます.
[貢献]質問の品質を検証・分析するための方法を提案
背景:自然言語処理分野では,人間のように文章を理解するシステムを作ることがひとつの大きな目標です.研究を進めるためにはシステムの言語理解の良さを評価するためのタスクが必要であり,そのひとつとして国語の文章題のような形式の質問が課される機械読解タスクがあります.近年は機械学習技術の進展にともなって数万単位の問題数を備えたデータセットが(主に英語で)多く提案され,より高性能なシステムを作るために世界中の大学やIT企業の研究者が研究を進めています.中には人間と同程度の性能が出せるシステムも登場しています.
課題:しかし,限られたデータセットの上で高性能なシステムを開発できたとしても大きく2つの課題が残っています.1つは,現状ほとんどの場合システムの性能を「データセット中でどれくらいの割合の質問が解けたか」という観点でしか評価していないことです.そのような評価のみだと,文章理解に含まれるような仕組み,たとえば指示表現が何を指すか当てることや,否定文・条件文が論理的に理解できることなど多様な側面の理解について詳細に知ることができません.もう1つは,現状の読解問題では本当に高度な読解が必要とされていないかもしれないことです.たとえば課題文の末尾に「質問文によく似た紛らわしい文 (ただし本来の正答は変わらない)」を人手で作成して追加すると,既存のシステムの性能が大きく低下することが分かっています.ちゃんと文章を読んでいるというよりも,質問文に出てくる単語を課題文から探してそれが近くにある答えを選んでいる可能性があるということです(近年の機械学習モデルは特にそういうことが得意です).以上のような課題があると,見かけ上は高性能なシステムであっても実際にできることは限られ,社会で応用するときに大きな問題になってしまうかもしれません.
手法と貢献:まず上記の2つの課題について解決策を提案しました.1つ目の課題については,読解で登場すると考えられる能力を10ほど定義して,それぞれが問題を解くのに必要になるかどうか人手で分析できるようにしました.2つ目の課題については,「ちゃんと文章を読まなくても質問文との単語の一致を見るだけで簡単に解けてしまう質問」を特定する方法を考案し,なるべく難しい質問を見つけられるようにしました.最後に両者をまとめる形で,複雑な推論・能力が必要とされると思われる質問を特定するための自動的な手法を提案しました.たとえば「課題文のそれぞれの文の語順をランダムに並べ替えても質問が解けてしまうかどうか」を確認します.もしシステムが解けるならば,文章の主語・述語などが正確に分からなくても解ける,つまりその質問は文の構造について正確な理解を要求していないかもしれないことが分かります.このような手法をいくつか考案して既存のデータセットに適用することで,すでにシステムが解けている多くの質問では推論・文法の観点から高度な言語理解が要求されているわけではなさそうである,という観察を得ました.今後より良いデータセットを開発する際に本研究が提案する手法を使うことで,特定の能力を必要とされないものを取り除きながら質問を集められるようになり,円滑な言語理解システムの評価・発展に寄与すると考えられます.
(2020年5月21日受付)