
(邦訳:カーネル法に基づく共起の計算)
| 横井 祥 東北大学大学院情報科学研究科 助教 |
キーワード
| 自然言語処理 | 共起 | 類似 | カーネル法 |
[背景]ふたつの文の「相性のよさ」を計算したい
[問題]既存の計算法には多くのデメリットがある(計算時間,データ量,解釈性)
[貢献]文の間の「似ている度合い」の情報をうまく活用するとすべての問題が解決
われわれ人間が日常的に使っている「言葉」をコンピュータに理解させ,さらにはコンピュータ自身が自在に言語を運用できるようになるには一体どのような仕組みを作れば良いでしょう.自然言語処理と呼ばれる分野では日々この難題に取り組んでいます.最近では大規模なテキストデータ(SNSの投稿,新聞記事,などなど)が手に入るようになり,またデータの統計的な傾向をコンピュータ自身に学ばせる機械学習と呼ばれる技術が大きく発展したことで,自然言語処理は飛躍的な進歩を遂げました.Google翻訳をはじめとした機械翻訳システムの出力は非常に流暢になりましたし,iPhoneのSiriやGoogle Home,あるいは「人工知能」が扮する企業の窓口担当者やキャラクターに(日本語を使って!)問い合わせることもかなり自由にできるようになりました.
機械翻訳システムや対話システムの実現に際して問題になるのが,ふたつの文の共起(きょうき)の強さ,つまりふたつの文の相性の良さの測りかたです.たとえば対話システムが「財布落とした……」と話しかけられとき,「それはつらい……」「どのブランドが好きですか?」「わからないです」のうちどれを返せば良いかという問題はまさにこの共起の問題です.人間であれば,「財布落とした → つらいね」という文の組み合わせが「財布落とした → どのブランドが好き」よりも圧倒的によく共起する(人間同士のコミュニケーションとして自然であり文同士の相性がよい)ことを知っていいます.しかし計算機にとって共起の推定は難題です.よく利用されるのは情報理論に基づいた尺度なのですが,これはデータが大きいと計算時間がかかり,データが小さいとうまく動かず,また「なぜ」共起が強い(弱い)と推定されたかその理由が示されずシステムの改善が困難です.
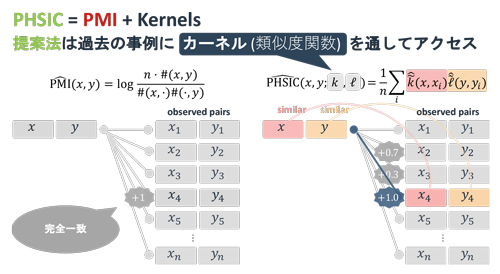
この研究では,情報理論で書かれた尺度をカーネル法の言葉に置き換えることによってこれらの問題を一気に解決します.肝は,文のペアが与えられたときその間の共起の強さを直接計算「しない」ことです.その代わり,左も似ていて右も似ているデータを過去に見たことがあれば共起する,と考えます.つまり「昨日財布なくした → うわ,厳しいね」というデータを見たことがあれば「財布落とした → つらいね」という初見の組合せも共起しやすいだろうと推察するのです.この単純な考え方を使うと,推定は高速になり,少量のデータでもうまく動き,しかも計算の理由がわかる尺度が生まれます.作った尺度を実際の機械翻訳システムや対話システムに導入するとシステムの品質が向上しました.さらに計算機に常識を獲得させるという人工知能の黎明期からの問題にも役に立つことを示しました.
[貢献]文の間の「似ている度合い」の情報をうまく活用するとすべての問題が解決
われわれ人間が日常的に使っている「言葉」をコンピュータに理解させ,さらにはコンピュータ自身が自在に言語を運用できるようになるには一体どのような仕組みを作れば良いでしょう.自然言語処理と呼ばれる分野では日々この難題に取り組んでいます.最近では大規模なテキストデータ(SNSの投稿,新聞記事,などなど)が手に入るようになり,またデータの統計的な傾向をコンピュータ自身に学ばせる機械学習と呼ばれる技術が大きく発展したことで,自然言語処理は飛躍的な進歩を遂げました.Google翻訳をはじめとした機械翻訳システムの出力は非常に流暢になりましたし,iPhoneのSiriやGoogle Home,あるいは「人工知能」が扮する企業の窓口担当者やキャラクターに(日本語を使って!)問い合わせることもかなり自由にできるようになりました.
機械翻訳システムや対話システムの実現に際して問題になるのが,ふたつの文の共起(きょうき)の強さ,つまりふたつの文の相性の良さの測りかたです.たとえば対話システムが「財布落とした……」と話しかけられとき,「それはつらい……」「どのブランドが好きですか?」「わからないです」のうちどれを返せば良いかという問題はまさにこの共起の問題です.人間であれば,「財布落とした → つらいね」という文の組み合わせが「財布落とした → どのブランドが好き」よりも圧倒的によく共起する(人間同士のコミュニケーションとして自然であり文同士の相性がよい)ことを知っていいます.しかし計算機にとって共起の推定は難題です.よく利用されるのは情報理論に基づいた尺度なのですが,これはデータが大きいと計算時間がかかり,データが小さいとうまく動かず,また「なぜ」共起が強い(弱い)と推定されたかその理由が示されずシステムの改善が困難です.
この研究では,情報理論で書かれた尺度をカーネル法の言葉に置き換えることによってこれらの問題を一気に解決します.肝は,文のペアが与えられたときその間の共起の強さを直接計算「しない」ことです.その代わり,左も似ていて右も似ているデータを過去に見たことがあれば共起する,と考えます.つまり「昨日財布なくした → うわ,厳しいね」というデータを見たことがあれば「財布落とした → つらいね」という初見の組合せも共起しやすいだろうと推察するのです.この単純な考え方を使うと,推定は高速になり,少量のデータでもうまく動き,しかも計算の理由がわかる尺度が生まれます.作った尺度を実際の機械翻訳システムや対話システムに導入するとシステムの品質が向上しました.さらに計算機に常識を獲得させるという人工知能の黎明期からの問題にも役に立つことを示しました.
(2020年6月15日受付)