
| 木村 輔 (正会員) 大阪大学産業科学研究所産業科学AIセンター 特任助教 |
キーワード
| 自然言語処理 | 自動要約生成 | 深層学習 |
[背景]非構造化データであるテキストデータの爆発的な増加
[問題]多様な観点からなる長文を対象とした要約手法の不足
[貢献]長文テキストを入力とするクエリ指向要約手法の改善
■日常となったビッグデータ時代
現在,私たちの身の回りは,さまざまな方法で収集されたデータで溢れています.このような巨大なデータ群(ビッグデータ)から,Google検索やYahoo!検索に代表される検索エンジン,また,TwitterやFacebookといったソーシャルネットワーキングサービス(SNS)等を通して,自分にとって興味のある情報のみを取得することは当たり前になりました.
■非構造化データに眠る情報
テキストや動画,センサログ等の構造化されていないデータ(非構造化データ)は,ビッグデータ中の80%を占めると報告されています.非構造化データは,コンピュータによる分析が困難である一方,ビッグデータ中の最も大きなウェイトを占めるため,情報の宝庫といえるでしょう.とりわけテキストデータは,企業のすべてのデータの75%以上に及ぶといわれています.
たとえば,無数に存在するWebサイトから,知りたい情報が記載されたサイトのみを効率良く取得したいとします.一番簡単な方法は,検索エンジンを利用することです.知りたい情報のキーワード(クエリ)を入力すると,そのクエリに関連する検索結果が表示されます.このとき,Webサイトのタイトルだけでなく,Webサイトの本文を元に,クエリに関する短いテキスト(スニペット)が生成され,タイトルと合わせて表示されます.ユーザはスニペットを読むことで,知りたい情報を含む可能性が高いWebサイトのみを,短時間のうちに無駄なく選択できます.
このように,膨大な量の非構造化データを対象に,コンピュータによって効率良く情報を分析,取得するための手法が日々研究されています.では,どのようにして,Webサイトの本文から,クエリに関連する要約を生成できるのでしょうか?
■自然言語処理とは?
単純に考えれば,コンピュータにWebサイトを読んでもらい,クエリに関連する個所を特定させ,かつ,その範囲のテキストを短くなるように書き直してもらえばよいでしょう.このような,人間が自然に扱っている言語(自然言語)を,コンピュータに処理させる技術を自然言語処理といいます.基礎技術としては,テキストを,意味を持つ最小単位(形態素)に分割する形態素解析や,テキスト中の語句間の関連(係り受け)等を明確にする構文解析などが研究されています.また,それら基礎技術の上に成り立つ応用技術として,Google翻訳をはじめとする機械翻訳,そして,本研究で扱った自動要約があります.
■クエリ指向要約とその問題点
自動要約では,たとえば,新聞の1つの記事を元に,「記事の内容を明確に表現するタイトル」や「概略をまとめた導入文(リード文)」の出力を目指します.これにより,ユーザはタイトルやリード文(要約)を読むだけで,新聞のすべての記事(膨大な量の本文)を読まずとも,短時間の内にユーザが真に知りたい内容(情報要求)を含む本文のみを見つけることができます.
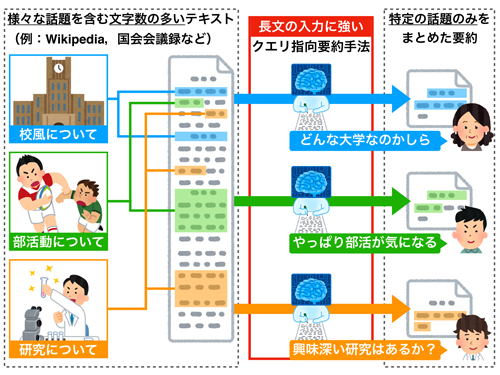
本研究では,自動要約のうち,クエリ指向要約生成に取り組みました.この要約手法は,さまざまな観点(トピック)が含まれた文字数の多いテキストを入力した場合に,ユーザの情報要求(クエリ)に沿った内容を含む要約の生成を目指しています.このクエリ指向の要約は,まさしく検索エンジンのスニペットと同じもので,皆さんの身近にある技術といえます.一方で,現在,主流となっている深層学習による手法は,その構造の性質から,文字数の多い入力をうまく扱えない問題が指摘されています.
■文字数の多いテキストに強い提案手法
従来手法が要約元となるテキストを1単語ずつ入力するのに対して,本研究では,単語単位の処理に加えて,文単位の処理を組み合わせることで,文字数の多いテキストを入力された場合でも,生成される要約の品質の低下を抑える手法を提案しました.また,本研究課題により適した,さまざまなトピックを含み,かつ,文字数の多い新規データセットを構築しました.これにより,クエリ指向要約手法の研究分野の発展の一助になることが期待されます.
[貢献]長文テキストを入力とするクエリ指向要約手法の改善
■日常となったビッグデータ時代
現在,私たちの身の回りは,さまざまな方法で収集されたデータで溢れています.このような巨大なデータ群(ビッグデータ)から,Google検索やYahoo!検索に代表される検索エンジン,また,TwitterやFacebookといったソーシャルネットワーキングサービス(SNS)等を通して,自分にとって興味のある情報のみを取得することは当たり前になりました.
■非構造化データに眠る情報
テキストや動画,センサログ等の構造化されていないデータ(非構造化データ)は,ビッグデータ中の80%を占めると報告されています.非構造化データは,コンピュータによる分析が困難である一方,ビッグデータ中の最も大きなウェイトを占めるため,情報の宝庫といえるでしょう.とりわけテキストデータは,企業のすべてのデータの75%以上に及ぶといわれています.
たとえば,無数に存在するWebサイトから,知りたい情報が記載されたサイトのみを効率良く取得したいとします.一番簡単な方法は,検索エンジンを利用することです.知りたい情報のキーワード(クエリ)を入力すると,そのクエリに関連する検索結果が表示されます.このとき,Webサイトのタイトルだけでなく,Webサイトの本文を元に,クエリに関する短いテキスト(スニペット)が生成され,タイトルと合わせて表示されます.ユーザはスニペットを読むことで,知りたい情報を含む可能性が高いWebサイトのみを,短時間のうちに無駄なく選択できます.
このように,膨大な量の非構造化データを対象に,コンピュータによって効率良く情報を分析,取得するための手法が日々研究されています.では,どのようにして,Webサイトの本文から,クエリに関連する要約を生成できるのでしょうか?
■自然言語処理とは?
単純に考えれば,コンピュータにWebサイトを読んでもらい,クエリに関連する個所を特定させ,かつ,その範囲のテキストを短くなるように書き直してもらえばよいでしょう.このような,人間が自然に扱っている言語(自然言語)を,コンピュータに処理させる技術を自然言語処理といいます.基礎技術としては,テキストを,意味を持つ最小単位(形態素)に分割する形態素解析や,テキスト中の語句間の関連(係り受け)等を明確にする構文解析などが研究されています.また,それら基礎技術の上に成り立つ応用技術として,Google翻訳をはじめとする機械翻訳,そして,本研究で扱った自動要約があります.
■クエリ指向要約とその問題点
自動要約では,たとえば,新聞の1つの記事を元に,「記事の内容を明確に表現するタイトル」や「概略をまとめた導入文(リード文)」の出力を目指します.これにより,ユーザはタイトルやリード文(要約)を読むだけで,新聞のすべての記事(膨大な量の本文)を読まずとも,短時間の内にユーザが真に知りたい内容(情報要求)を含む本文のみを見つけることができます.
本研究では,自動要約のうち,クエリ指向要約生成に取り組みました.この要約手法は,さまざまな観点(トピック)が含まれた文字数の多いテキストを入力した場合に,ユーザの情報要求(クエリ)に沿った内容を含む要約の生成を目指しています.このクエリ指向の要約は,まさしく検索エンジンのスニペットと同じもので,皆さんの身近にある技術といえます.一方で,現在,主流となっている深層学習による手法は,その構造の性質から,文字数の多い入力をうまく扱えない問題が指摘されています.
■文字数の多いテキストに強い提案手法
従来手法が要約元となるテキストを1単語ずつ入力するのに対して,本研究では,単語単位の処理に加えて,文単位の処理を組み合わせることで,文字数の多いテキストを入力された場合でも,生成される要約の品質の低下を抑える手法を提案しました.また,本研究課題により適した,さまざまなトピックを含み,かつ,文字数の多い新規データセットを構築しました.これにより,クエリ指向要約手法の研究分野の発展の一助になることが期待されます.
(2020年6月5日受付)