
(邦訳:ネットワーク上の移動オブジェクトに対する索引,検索および圧縮: 文字列アルゴリズムによるアプローチ)
| 小出 智士 (株)豊田中央研究所 研究員 |
キーワード
| 空間データベース | データ圧縮 | 文字列アルゴリズム |
[背景] GPS等から得られる移動履歴情報(軌跡データ)の大規模化
[問題]大規模軌跡データに対する効率的な索引・検索・圧縮の実現
[貢献]文字列アルゴリズムの適用による効率的な手法群の提案
自動車やスマホなどの「移動オブジェクト」から収集される軌跡データ(位置情報の時系列)は,データ駆動型のアプリケーション,たとえば自動運転開発,高度な車載ナビゲーションシステム,交通行動分析などにとって重要なものであり,生活の利便性の向上や社会的な課題の解決つながることが期待されるものである.
一方で収集される軌跡データは大規模化している.少し古いデータになるが,米国で2011年に生成されたGPSデータは53テラバイトにものぼる,という試算がある.通常,我々が扱うデータはそれよりも小さいが,それでも軌跡データをテキストファイルとしてそのまま保管しても利用価値が低いことは想像できるだろう.そのため,本研究では大規模な軌跡データを効率良く扱うためのデータ格納や検索アルゴリズムなどの基盤的な操作に関する研究を行った.
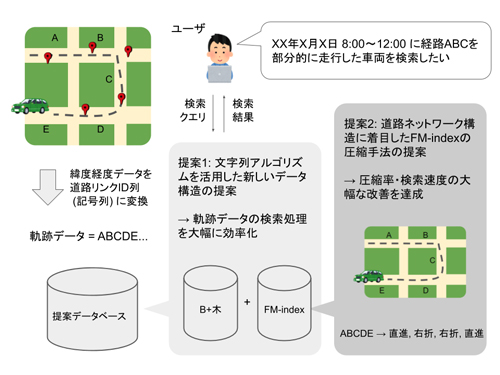
本研究は,通常は緯度経度の列として表現される軌跡データを道路リンクIDの列として表現する,という点が特徴である.この表現を用いることは,(1)ユーザの利便性(2)アルゴリズムの設計,の2つの観点において利点がある.
【1. ユーザの利便性】 道路リンクは渋滞情報などにおいても基本的な情報処理の単位であり,緯度経度情報よりも都合がよいことが多い.また,道路リンクID列表現を用いると,「ある経路を走行した軌跡を検索する」などの,「走行経路」を単位とした実用的かつ高度な問合せも可能になる.
【2. アルゴリズムの設計】 軌跡データを道路リンクID列,すなわち記号列として扱うことで「文字列アルゴリズム」の利用が可能になる.これらは従来,情報検索分野やゲノム情報処理の分野で研究されてきたものである.本研究ではFM-indexと呼ばれる,文字列索引を空間データベース分野の手法に整合的に統合できることを見出した.これにより,上述した「走行経路」を単位とする種々の問合せの効率な処理が可能になった.
上述した方法論の提案に加えて,さらに本研究では軌跡データを格納するFM-index自体の改良も行った.FM-indexはインメモリ索引であるため,大規模データを扱うためにはデータ圧縮を行うことがある.本研究では以下で述べるような「軌跡データの特徴」を積極的に活かすことで,高性能化を実現した.
たとえば約100万(≒2の20乗)種類の道路リンクを持つ道路ネットワークを考える.このとき,記号あたりに必要なビット数はlog2(2の20乗)=20ビットである.一方,道路ネットワークは十字路などの構造的特徴を持ち,これによって軌跡データを「直進,直進,右折,左折...」のような記号列に変換することができる.この表現では記号あたり2ビット以下で表現でき,大幅なデータの圧縮が可能になる.このアイディアをもとに新しい圧縮・検索アルゴリズムを提案し,従来の圧縮手法よりも大幅に高い圧縮率・高速な検索処理を実現した.
[貢献]文字列アルゴリズムの適用による効率的な手法群の提案
自動車やスマホなどの「移動オブジェクト」から収集される軌跡データ(位置情報の時系列)は,データ駆動型のアプリケーション,たとえば自動運転開発,高度な車載ナビゲーションシステム,交通行動分析などにとって重要なものであり,生活の利便性の向上や社会的な課題の解決つながることが期待されるものである.
一方で収集される軌跡データは大規模化している.少し古いデータになるが,米国で2011年に生成されたGPSデータは53テラバイトにものぼる,という試算がある.通常,我々が扱うデータはそれよりも小さいが,それでも軌跡データをテキストファイルとしてそのまま保管しても利用価値が低いことは想像できるだろう.そのため,本研究では大規模な軌跡データを効率良く扱うためのデータ格納や検索アルゴリズムなどの基盤的な操作に関する研究を行った.
本研究は,通常は緯度経度の列として表現される軌跡データを道路リンクIDの列として表現する,という点が特徴である.この表現を用いることは,(1)ユーザの利便性(2)アルゴリズムの設計,の2つの観点において利点がある.
【1. ユーザの利便性】 道路リンクは渋滞情報などにおいても基本的な情報処理の単位であり,緯度経度情報よりも都合がよいことが多い.また,道路リンクID列表現を用いると,「ある経路を走行した軌跡を検索する」などの,「走行経路」を単位とした実用的かつ高度な問合せも可能になる.
【2. アルゴリズムの設計】 軌跡データを道路リンクID列,すなわち記号列として扱うことで「文字列アルゴリズム」の利用が可能になる.これらは従来,情報検索分野やゲノム情報処理の分野で研究されてきたものである.本研究ではFM-indexと呼ばれる,文字列索引を空間データベース分野の手法に整合的に統合できることを見出した.これにより,上述した「走行経路」を単位とする種々の問合せの効率な処理が可能になった.
上述した方法論の提案に加えて,さらに本研究では軌跡データを格納するFM-index自体の改良も行った.FM-indexはインメモリ索引であるため,大規模データを扱うためにはデータ圧縮を行うことがある.本研究では以下で述べるような「軌跡データの特徴」を積極的に活かすことで,高性能化を実現した.
たとえば約100万(≒2の20乗)種類の道路リンクを持つ道路ネットワークを考える.このとき,記号あたりに必要なビット数はlog2(2の20乗)=20ビットである.一方,道路ネットワークは十字路などの構造的特徴を持ち,これによって軌跡データを「直進,直進,右折,左折...」のような記号列に変換することができる.この表現では記号あたり2ビット以下で表現でき,大幅なデータの圧縮が可能になる.このアイディアをもとに新しい圧縮・検索アルゴリズムを提案し,従来の圧縮手法よりも大幅に高い圧縮率・高速な検索処理を実現した.
(2020年5月21日受付)