
(邦訳:時系列テキストコレクションからの歴史関連知識の抽出)
| Duan Yijun 産業技術総合研究所 人工知能研究センター Specially Appointed Researcher |
キーワード
| Computational History (計算史) |
Archive Mining (アーカイブマイニング) |
Knowledge Extraction (知識抽出) |
[背景]ディジタル化された過去の文書が大量に蓄積され,大規模な分析による歴史的知識の掘り起こしが可能になった
[問題]歴史関連資料の増加によって,情報過多となり,過去の情報の理解が難しくなった
[貢献]大規模テキストコレクションから歴史関連の知識を自動的に抽出するデータマイニング技術を提案
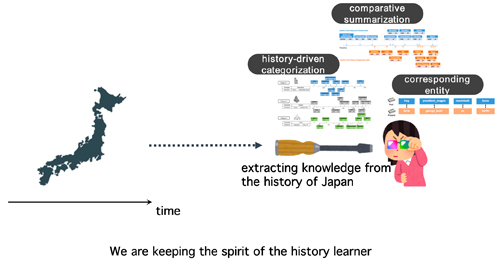
歴史は,私たちの過去に起こったことを記録したものです.歴史から学べることは,驚くほど多く,多様な教訓があります.たとえば,現代人は過去を高度な技術と結びつけることはほとんどありませんが,過去の技術を見ることで,現代の技術が古代世界とどのように結びつき,どのようにして生まれてきたのかを知ることができます.過去のディジタル化された大量の文書が蓄積されてきたことで,大規模な分析によって歴史の知識を掘り起こすことが可能になってきました.
しかし,一般ユーザが歴史を学ぶ際には,以下のような根本的な課題があると考えています.たとえば,Webの急速な発展に伴い,歴史関連の文書がどんどん増え,情報過多になっていること.第二に,過去の情報を理解することは,特に若い世代にとっては困難な場合があること.第三に,歴史文書の中には,通常,その背景にあるパターンが存在していること.たとえば,日本の歴史の中の潜在的な時代.このような高度で有益な情報を手作業で把握するには,膨大な認知的努力が必要となります.
このような課題を克服するために,本論文ではいくつかの研究課題を提案しています.第一に,複数のエンティティの歴史の要約を生成することからなる新しいタイプの要約タスクを紹介します.第二に,カテゴリの特徴付けと理解のため,エンティティを歴史ベースのカテゴリに分類するという新しい研究課題を紹介します.たとえば、博多や長崎のように、過去に日本の国際交流を高める上で重要な役割を果たした都市で構成されるカテゴリ.第三に,比較年表の要約というタスクを紹介し,それを解決するための効果的なアプローチを提案します.第四に,長期ニュースアーカイブに保存されている過去のニュース記事を,ユーザが発行したクエリに基づいて要約する問題にアプローチします.我々が提案した要約の比較特性は,時間的に離れた2つの期間における重要な比較的側面を発見することを可能にします.このような新しいタイプの歴史文書アーカイブへのアクセスは,傾向分析,歴史的類推の決定,教育・娯楽目的などのニーズに応えることができます.
[貢献]大規模テキストコレクションから歴史関連の知識を自動的に抽出するデータマイニング技術を提案
歴史は,私たちの過去に起こったことを記録したものです.歴史から学べることは,驚くほど多く,多様な教訓があります.たとえば,現代人は過去を高度な技術と結びつけることはほとんどありませんが,過去の技術を見ることで,現代の技術が古代世界とどのように結びつき,どのようにして生まれてきたのかを知ることができます.過去のディジタル化された大量の文書が蓄積されてきたことで,大規模な分析によって歴史の知識を掘り起こすことが可能になってきました.
しかし,一般ユーザが歴史を学ぶ際には,以下のような根本的な課題があると考えています.たとえば,Webの急速な発展に伴い,歴史関連の文書がどんどん増え,情報過多になっていること.第二に,過去の情報を理解することは,特に若い世代にとっては困難な場合があること.第三に,歴史文書の中には,通常,その背景にあるパターンが存在していること.たとえば,日本の歴史の中の潜在的な時代.このような高度で有益な情報を手作業で把握するには,膨大な認知的努力が必要となります.
このような課題を克服するために,本論文ではいくつかの研究課題を提案しています.第一に,複数のエンティティの歴史の要約を生成することからなる新しいタイプの要約タスクを紹介します.第二に,カテゴリの特徴付けと理解のため,エンティティを歴史ベースのカテゴリに分類するという新しい研究課題を紹介します.たとえば、博多や長崎のように、過去に日本の国際交流を高める上で重要な役割を果たした都市で構成されるカテゴリ.第三に,比較年表の要約というタスクを紹介し,それを解決するための効果的なアプローチを提案します.第四に,長期ニュースアーカイブに保存されている過去のニュース記事を,ユーザが発行したクエリに基づいて要約する問題にアプローチします.我々が提案した要約の比較特性は,時間的に離れた2つの期間における重要な比較的側面を発見することを可能にします.このような新しいタイプの歴史文書アーカイブへのアクセスは,傾向分析,歴史的類推の決定,教育・娯楽目的などのニーズに応えることができます.
(2020年5月29日受付)