
(邦訳:深層ニューラルネットワーク向け高効率HWアクセラレータに関する研究)
| 植吉 晃大 ルーヴェンカトリック大学 博士研究員 |
キーワード
| 計算効率化 | 機械学習 | コンピュータアーキテクチャ |
[背景]低電力環境下における機械学習を用いた計算需要の向上
[問題]ニューラルネットワークの計算規模拡大に伴う電力制限
[貢献]アルゴリズムとアーキテクチャの協調設計による最適化
本研究は,深層ニューラルネットワーク(DNN: Deep Neural Network)の推論処理における,高効率なハードウェア実装技術に関するものである.DNNは,人間の脳神経(ニューロン)を模した数理モデルで,近年の人工知能技術の発展の礎となっている.特に,画像認識,音声認識,自然言語処理の分野で高い性能を達成している今日の人工知能技術の発展は,集積回路技術の進化とともに,大量のデータを現実時間内で処理可能となったことに起因する.これらの処理を電力制約の厳しい,実世界のデバイス上で実現させるためには,HW単体技術だけでは難しく,アルゴリズムやアーキテクチャ側の見直しが非常に重要な役目を担う.これらを統合的に考慮して,1つのシステムを実現させる本研究は,高度な知能情報処理のプラットフォームを拡張し,新規応用先を創出する重要な役割を果たすと考えられる.
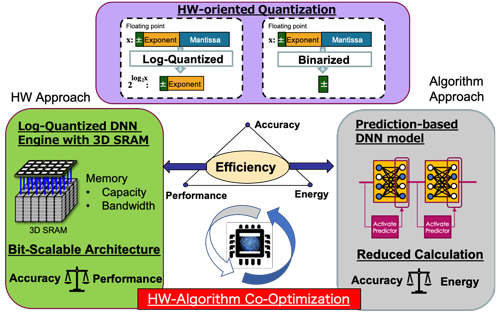
本研究では,高い電力効率でDNNをハードウェア実装するために,アルゴリズムとアーキテクチャの双方から最適な方法を探索する.ここでは,(1)量子化技術,(2)アーキテクチャ探索,(3)モデルの効率化の3点を評価し,新たな手法を提案した.
(1)DNN計算は,多くを積和演算が占めており,その計算コストを軽量化させる必要がある.ここでは,値を低ビット精度で表現する,量子化を用いて,精度を落とさずに,いかに低電力化を行えるかを評価した.そこで,2を底とする対数量子化を用いると,2進数での計算が基本となるディジタル回路上で高効率な計算を行うことができるため,この計算を効率的に行える回路アーキテクチャを評価した.そして,ビット精度を可変にすることができる,ビットシリアル機構と組み合わせ,ビット精度に柔軟な機構を提案した.これにより,ビット幅を可変にすることで精度と電力効率・速度のトレードオフを制御することが可能となった.
(2)応用技術の性能向上に伴って,DNNの規模や複雑さが増大している.そのため,オンチップのメモリ上にDNNを構築するパラメータがすべて格納することは難しい.多くのHWアクセラレータは外部メモリにDRAMを利用しているが,実際は電力の大半をこの外部メモリアクセスが占めることが知られている.そこで,三次元積層技術に着目し,代表的な実用メモリである,SRAMとDRAMの評価した.その結果,DNN推論計算に許容される程度の容量であれば,SRAMを積層させることで,高い電力効率を実現できることを示した.さらに,これらを用いたDNN推論計算を行うHWアクセラレータを提案し,実チップ上に実装・評価を行った.
(3)近年,多くのDNNは,ニューロンがゼロを出力する,スパースな演算となっている.本研究では,このゼロを出力するニューロン(無効ニューロン)を予測することで,計算量を削減する手法を提案した.これにより,DNNモデル自体の計算量とメモリアクセスを削減することが可能となる.この予測機構は,二値化されたNNで構成されるため, 小さなオーバーヘッドで予測を可能とする.この NN を実装・評価し,元のネットワークの不必要な計算を,入力に 応じて動的に予測し,計算量を削減できることを示した.
[貢献]アルゴリズムとアーキテクチャの協調設計による最適化
本研究は,深層ニューラルネットワーク(DNN: Deep Neural Network)の推論処理における,高効率なハードウェア実装技術に関するものである.DNNは,人間の脳神経(ニューロン)を模した数理モデルで,近年の人工知能技術の発展の礎となっている.特に,画像認識,音声認識,自然言語処理の分野で高い性能を達成している今日の人工知能技術の発展は,集積回路技術の進化とともに,大量のデータを現実時間内で処理可能となったことに起因する.これらの処理を電力制約の厳しい,実世界のデバイス上で実現させるためには,HW単体技術だけでは難しく,アルゴリズムやアーキテクチャ側の見直しが非常に重要な役目を担う.これらを統合的に考慮して,1つのシステムを実現させる本研究は,高度な知能情報処理のプラットフォームを拡張し,新規応用先を創出する重要な役割を果たすと考えられる.
本研究では,高い電力効率でDNNをハードウェア実装するために,アルゴリズムとアーキテクチャの双方から最適な方法を探索する.ここでは,(1)量子化技術,(2)アーキテクチャ探索,(3)モデルの効率化の3点を評価し,新たな手法を提案した.
(1)DNN計算は,多くを積和演算が占めており,その計算コストを軽量化させる必要がある.ここでは,値を低ビット精度で表現する,量子化を用いて,精度を落とさずに,いかに低電力化を行えるかを評価した.そこで,2を底とする対数量子化を用いると,2進数での計算が基本となるディジタル回路上で高効率な計算を行うことができるため,この計算を効率的に行える回路アーキテクチャを評価した.そして,ビット精度を可変にすることができる,ビットシリアル機構と組み合わせ,ビット精度に柔軟な機構を提案した.これにより,ビット幅を可変にすることで精度と電力効率・速度のトレードオフを制御することが可能となった.
(2)応用技術の性能向上に伴って,DNNの規模や複雑さが増大している.そのため,オンチップのメモリ上にDNNを構築するパラメータがすべて格納することは難しい.多くのHWアクセラレータは外部メモリにDRAMを利用しているが,実際は電力の大半をこの外部メモリアクセスが占めることが知られている.そこで,三次元積層技術に着目し,代表的な実用メモリである,SRAMとDRAMの評価した.その結果,DNN推論計算に許容される程度の容量であれば,SRAMを積層させることで,高い電力効率を実現できることを示した.さらに,これらを用いたDNN推論計算を行うHWアクセラレータを提案し,実チップ上に実装・評価を行った.
(3)近年,多くのDNNは,ニューロンがゼロを出力する,スパースな演算となっている.本研究では,このゼロを出力するニューロン(無効ニューロン)を予測することで,計算量を削減する手法を提案した.これにより,DNNモデル自体の計算量とメモリアクセスを削減することが可能となる.この予測機構は,二値化されたNNで構成されるため, 小さなオーバーヘッドで予測を可能とする.この NN を実装・評価し,元のネットワークの不必要な計算を,入力に 応じて動的に予測し,計算量を削減できることを示した.
(2020年5月29日受付)