
(邦訳:メニーコアプラットフォームのための効率的かつスケーラブルなDBMSに関する研究)
| 西 方 ファーウェイ R&Dセンター |
[背景]プロセッサチップ中のコア数の増加が著しい
[問題]コア数の著しく増加にDBMSの性能が十分に向上しない
[貢献]メニーコアのための効率的かつスケーラブルなDBMS
[問題]コア数の著しく増加にDBMSの性能が十分に向上しない
[貢献]メニーコアのための効率的かつスケーラブルなDBMS
本研究では,プロセッサチップ中のコア数が著しく増加している近年のメニーコア化の動向において,コア数の増加に比してデータベース処理性能が十分に向上しないスケーラビリティ阻害の問題を対象として,その要因を明らかにし,効果的な対応方法を提案するとともに,実際に複数のマルチコアを用いてその効果を確認しました.
これまでデータベース管理システム(DBMS)をマルチコア上で実行する場合,各クエリをコアに適宜割り振り実行させていました.それらクエリは,ハードウェア・レベルとソフトウェア・レベルのリソースを共有しますが,同時実行クエリ数が増加すると,それらのリソース共有が処理のボトルネックとなります.本研究では,リソース共有の中でもキャッシュとバッファプールに着目しました.
従来のDBMSのリソース共有に関する研究では,DBMSやOSの内部に手を入れるものがほとんどでした.しかし,DBMSやOSは複雑で規模の大きなソフトウェアで,内部を修正することは非常にコストがかかる上,汎用性がなくなります.本研究では,DBMSとOSに手を加えずに効率的なリソース共有を行うために,ミドルウェアを用いるアプローチを取りました.
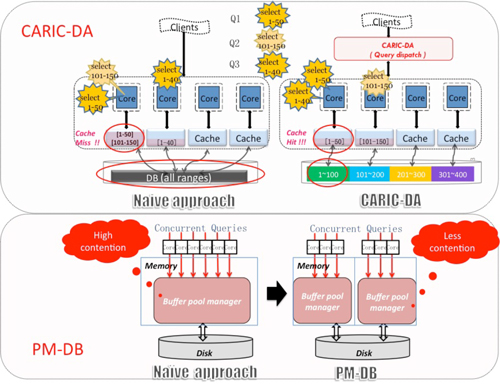
CARIC-DAと名付けたミドルウェアでは,各コアにDBMSプロセスを割り付け,そのプロセスで扱うデータの値の範囲(値域)を設定しておき,ミドルウェアでクエリを解析し,扱うデータの値域に従って対応するプロセスを決め,そこにクエリを投げます.同じ値域のクエリが同一コアで実行されることで,コアのプライベートキァッシュのヒット率が向上します.このアプローチは特にオンライントランザクション処理(OLTP)処理に効果的です.実際に,IntelとAMDの最新のメニーコア環境でOLTPのベンチマークであるTPC-CとPostgreSQLを用いて,CARIC-DAの評価を行い,キャッシュヒット率と実行性能の向上の効果を示しました.
また,OLTPだけでなく異なるワークロードが混在する場合のメニーコア環境の性能を解析し,単一インスタンスのDBMSでのメインメモリ上のバッファプールにおけるリソース共有がボトルネックとなることを明らかにしました.インスタンスを複数にすることで,バッファプールのリソース競合を減らすことができますが,インスタンス間の一貫性制御が必要になります.マルチコア環境では,2相コミットの通信コストが低いことから,マルチコアにDBMSの複数インスタンスを置き,CARIC-DAと同様にミドルウェアで,クエリの内容に従って,それらのインスタンスにクエリを投げ,2相コミットを行うPM-DBと名付けたミドルウェアを提案しました.実際にマルチコア上にPostgreSQLの複数インスタンスを配置し,異なるワークロードが混在するベンチマークであるTPC-Wを用いて,PM-DBの評価を行いその効果を示しました.
今後ますますメニーコア化が進み,複数コアが共有するメインメモリやキャッシュといったリソースの効率的利用がさらに重要になると予想します.既存ソフトやOSに手を加えずリソースを有効利用する本研究のアプローチが他にも適用できるのではないかと思っています.
これまでデータベース管理システム(DBMS)をマルチコア上で実行する場合,各クエリをコアに適宜割り振り実行させていました.それらクエリは,ハードウェア・レベルとソフトウェア・レベルのリソースを共有しますが,同時実行クエリ数が増加すると,それらのリソース共有が処理のボトルネックとなります.本研究では,リソース共有の中でもキャッシュとバッファプールに着目しました.
従来のDBMSのリソース共有に関する研究では,DBMSやOSの内部に手を入れるものがほとんどでした.しかし,DBMSやOSは複雑で規模の大きなソフトウェアで,内部を修正することは非常にコストがかかる上,汎用性がなくなります.本研究では,DBMSとOSに手を加えずに効率的なリソース共有を行うために,ミドルウェアを用いるアプローチを取りました.
CARIC-DAと名付けたミドルウェアでは,各コアにDBMSプロセスを割り付け,そのプロセスで扱うデータの値の範囲(値域)を設定しておき,ミドルウェアでクエリを解析し,扱うデータの値域に従って対応するプロセスを決め,そこにクエリを投げます.同じ値域のクエリが同一コアで実行されることで,コアのプライベートキァッシュのヒット率が向上します.このアプローチは特にオンライントランザクション処理(OLTP)処理に効果的です.実際に,IntelとAMDの最新のメニーコア環境でOLTPのベンチマークであるTPC-CとPostgreSQLを用いて,CARIC-DAの評価を行い,キャッシュヒット率と実行性能の向上の効果を示しました.
また,OLTPだけでなく異なるワークロードが混在する場合のメニーコア環境の性能を解析し,単一インスタンスのDBMSでのメインメモリ上のバッファプールにおけるリソース共有がボトルネックとなることを明らかにしました.インスタンスを複数にすることで,バッファプールのリソース競合を減らすことができますが,インスタンス間の一貫性制御が必要になります.マルチコア環境では,2相コミットの通信コストが低いことから,マルチコアにDBMSの複数インスタンスを置き,CARIC-DAと同様にミドルウェアで,クエリの内容に従って,それらのインスタンスにクエリを投げ,2相コミットを行うPM-DBと名付けたミドルウェアを提案しました.実際にマルチコア上にPostgreSQLの複数インスタンスを配置し,異なるワークロードが混在するベンチマークであるTPC-Wを用いて,PM-DBの評価を行いその効果を示しました.
今後ますますメニーコア化が進み,複数コアが共有するメインメモリやキャッシュといったリソースの効率的利用がさらに重要になると予想します.既存ソフトやOSに手を加えずリソースを有効利用する本研究のアプローチが他にも適用できるのではないかと思っています.
(2015年6月9日受付)