
| 倉田 成己 (株)日立製作所 研究開発グループ |
[背景]高性能プロセッサの面積効率・エネルギー効率が重要に
[問題]ロード・ストア・ユニット(LSU)の回路面積・消費エネルギーが増大
[貢献]性能を落とすことなくLSUのコストを大幅に削減
[問題]ロード・ストア・ユニット(LSU)の回路面積・消費エネルギーが増大
[貢献]性能を落とすことなくLSUのコストを大幅に削減
近年の高性能プロセッサは,プログラムの依存関係を解析し,命令の順序を入れ替えて並列実行可能なout-of-orderスーパスカラ・プロ セッサ(OoO SSP)が主流となっている.OoO SSPは,スーパーコンピュータはもちろん,スマートフォンなどのモバイル機器にも搭載されるまでに至っている.一方で,OoO SSPは命令の順序を入れ替えて実行するための制御部が回路面積・消費エネルギーの多くを占めている.
マルチコア・プロセッサが広く普及している昨今においては,このOoO SSPの制御部の面積効率・エネルギー効率がより重要なものになっている.シングル・コアの時代においては,面積効率・エネルギー効率の向上がチップ・コストの削減や省電力化に繋がっていた.一方マルチコア・プロセッサでは,チップ上に搭載するコアの数を増やすことが可能となり,同一面積・消費エネルギーでチップの最大性能を高めることができるのである.
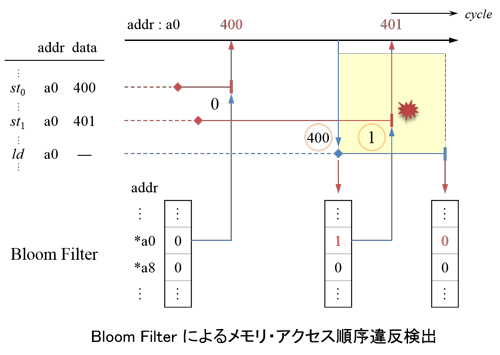
OoO SSPの制御部の中では,ロード・ストア・ユニット(LSU)が最も高コストなものの1つとなっている.LSUは,ロード/ストア命令の依存関係による先行制約を守りつつ,それらを投機的に実行する役割を果たす.ロード/ストア命令の投機実行においては,依存元のストア命令の発見,あるいは,メモリ・アクセス順序違反の検出など,動的なターゲット・アドレスの比較が必須である.この比較は,従来,CAMを用いたロード・ストア・キュー(LSQ)を構成することによって行われてきた.しかしCAMは,その構造上,回路面積と消費エネルギーが非常に大きい.
一方で,メモリの下位階層との速度差を埋めるため,in-flightなロード/ストア命令の数を増加させることはきわめて重要であり,LSQのエントリ数は増加の一途をたどっている.また,同時実行可能なロード/ストア命令の数を増やすことは,LSQを構成するCAMのポート数の増加につながる.CAMの面積は,ポート数の2乗に比例して増加するため,プロセッサの規模の拡大に伴ってLSQの面積は加速度的に増大している.
本研究では,CAMを用いず,Bloom Filter(BF)と,RAMで構成されたLSQを用いてターゲット・アドレスの比較を行う手法を提案した.フィルタは,ターゲット・アドレスのハッシュをキーとするテーブルであり,ハッシュ値の衝突による偽陽性を不可避的に伴う.BFは,複数のハッシュ関数を用いることによってきわめて低い偽陽性率を達成しており,このわずかな偽陽性を許容することによって,CAMを排除することが可能となった.
上記の提案について,シミュレーションによるIPC(クロックサイクルあたりの実行命令数)の計測と,ツールによる回路面積および消費エネルギーの評価を行った.その結果,従来のCAMを用いた手法と比較して,IPCをほとんど落とすことなく,回路面積と消費エネルギーを大幅に削減できることが示された.
マルチコア・プロセッサが広く普及している昨今においては,このOoO SSPの制御部の面積効率・エネルギー効率がより重要なものになっている.シングル・コアの時代においては,面積効率・エネルギー効率の向上がチップ・コストの削減や省電力化に繋がっていた.一方マルチコア・プロセッサでは,チップ上に搭載するコアの数を増やすことが可能となり,同一面積・消費エネルギーでチップの最大性能を高めることができるのである.
OoO SSPの制御部の中では,ロード・ストア・ユニット(LSU)が最も高コストなものの1つとなっている.LSUは,ロード/ストア命令の依存関係による先行制約を守りつつ,それらを投機的に実行する役割を果たす.ロード/ストア命令の投機実行においては,依存元のストア命令の発見,あるいは,メモリ・アクセス順序違反の検出など,動的なターゲット・アドレスの比較が必須である.この比較は,従来,CAMを用いたロード・ストア・キュー(LSQ)を構成することによって行われてきた.しかしCAMは,その構造上,回路面積と消費エネルギーが非常に大きい.
一方で,メモリの下位階層との速度差を埋めるため,in-flightなロード/ストア命令の数を増加させることはきわめて重要であり,LSQのエントリ数は増加の一途をたどっている.また,同時実行可能なロード/ストア命令の数を増やすことは,LSQを構成するCAMのポート数の増加につながる.CAMの面積は,ポート数の2乗に比例して増加するため,プロセッサの規模の拡大に伴ってLSQの面積は加速度的に増大している.
本研究では,CAMを用いず,Bloom Filter(BF)と,RAMで構成されたLSQを用いてターゲット・アドレスの比較を行う手法を提案した.フィルタは,ターゲット・アドレスのハッシュをキーとするテーブルであり,ハッシュ値の衝突による偽陽性を不可避的に伴う.BFは,複数のハッシュ関数を用いることによってきわめて低い偽陽性率を達成しており,このわずかな偽陽性を許容することによって,CAMを排除することが可能となった.
上記の提案について,シミュレーションによるIPC(クロックサイクルあたりの実行命令数)の計測と,ツールによる回路面積および消費エネルギーの評価を行った.その結果,従来のCAMを用いた手法と比較して,IPCをほとんど落とすことなく,回路面積と消費エネルギーを大幅に削減できることが示された.
(2015年6月10日受付)