ドローンを活⽤した馬鈴薯の塊茎重予測
1.馬鈴薯の収量予測
馬鈴薯(Solanum tuberosum L.)はナス科に属し,原産地は南米アンデス地域である.現在では世界100カ国以上で栽培されており,最も広く生産されている野菜の1つである.2021年の世界全体の馬鈴薯年間生産量は約3億8千万トンに達しており,中国,インド,ウクライナ,ロシア,アメリカ合衆国の主要5カ国で世界生産量の約55%を占めている[1].また,馬鈴薯は栽培が容易で保存性が高く,炭水化物の供給源として重要である.さらに,健康面や栄養価での利点,生育期間が短いといった特徴を持ち,国連食糧農業機関では,馬鈴薯を「世界の食料安全保障で他の穀物を代替する最も有望な作物の1つ」と位置づけている[2].
日本国内において,農業就業者人口の減少や新規参入者不足問題が深刻化している.農作業の省力化を進めるため,近年,作物の形質(草丈・草高,葉形態,分光反射特性など)を広域で計測する手段として,ドローンの活用が注目されている.ドローンは操作が比較的容易で持ち運びができ,飛行経路や速度を自動制御できるほか,特定の高度・時刻において効率的に高解像度画像を取得できる.これにより,圃場レベルで作物の生育状況を継続的に把握することが可能となっている[3,4].特にRGBカメラやマルチスペクトルカメラを搭載したドローンは,作物の生育状況を新たな視点で捉える有効な手段として,農業情報技術の発展に寄与している.
馬鈴薯の地上部や地下部の重量予測に関して,草丈・草高や植生指数のデータを機械学習モデルと組み合わせる研究が広く行われてきている.既往研究[5,6,7]では,ドローンを用いたRGBやマルチ/ハイパースペクトル画像が,地上部全重や塊茎重の精度良い予測に有効であることが示されている.Luoら[8]はマルチスペクトル画像からスペクトル・テクスチャ・幾何情報の特徴を抽出し,複数の特徴選択法により地上部全重の予測精度向上を報告した.Liら[9]はドローン空撮画像と品種データを組み合わせることで収量の予測精度が大幅に改善されることを示し,Maら[10]はマルチスペクトル画像および地上部の空間構造特徴活用し,馬鈴薯のカリウム含有量の精度向上を実現した.また,Yangら[11]は葉の形態検出による地上部全重の予測法を提案し,Peiら[12]は成長ステージに応じてPLS回帰や重回帰を適用した収量予測モデルを構築した.Gómezら[13]は,Sentinel-2衛星画像とランダムフォレストを組み合わせることで,収穫1〜2カ月前の収量予測に成功した事例を報告した.Sunら[5]は生育ステージごとの空撮画像を用いた収量予測性能を比較し,塊茎形成期や栄養成長期の画像が高い収量予測に有効であることを明らかにした.初期の生育段階,すなわち塊茎形成期[9],栄養成長期[14],塊茎肥大量産期[7]に撮影された画像は,生育後期に撮影された画像を用いるよりも優れた予測性能を示した.以上,従来研究は主に圃場単位や地域単位での地上部・地下部の重量予測に焦点を当ててきたが,株単位での収量予測に踏み込んだ事例はほとんどない.
機械学習を用いた収量予測は近年急速に進展しており,ドローン空撮画像から得られる形質情報を用いた試みも増加している[15,16].しかし,多時期のフェノタイプデータを収集する作業は膨大な人的・物的労力を要する.生育期間中のある特定の限られた時期に,塊茎重や収量予測に直結する重要な形質を効率的に抽出できれば,データ収集や前処理の負担を大幅に軽減することができる.これまでドローンによる空撮画像と機械学習を用いて塊茎重・収量予測のための重要変数を抽出する研究はいくつかあるものの,1株あたりの新鮮塊茎重(以下,塊茎重),塊茎数,塊茎1個あたりの新鮮塊茎重(以下,平均塊茎重)といった地下部の収量構成要素を株単位で予測する研究は少ない.本研究の目的は,ドローン空撮画像から得られる草高および複数の植生指数を用いて,馬鈴薯の塊茎重,塊茎数,平均塊茎重を株レベルで予測することである.本稿では,特徴選択手法により重要な変数を抽出し,複数の機械学習アルゴリズムに適用することで,高精度の馬鈴薯の地下部塊茎重の予測を試みた結果を報告する.
2.圃場での栽培と空撮
2.1 実験圃場
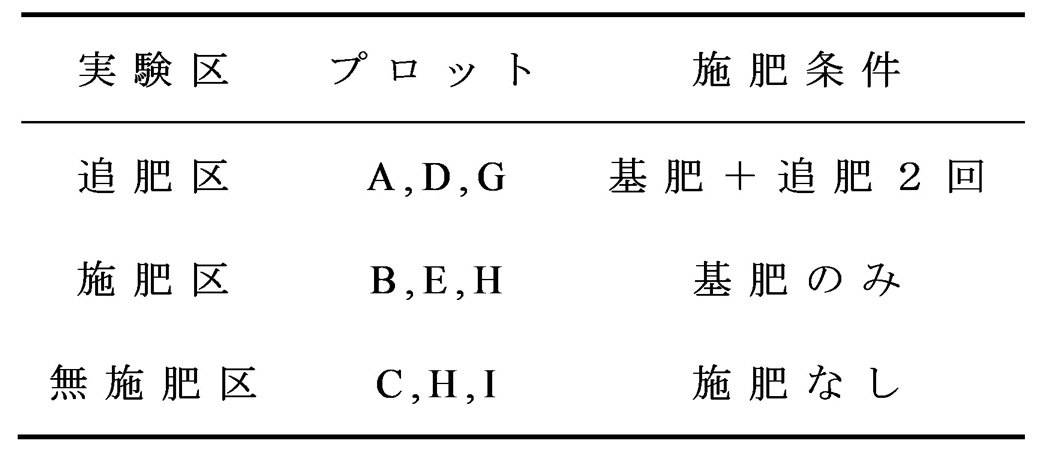
東京農工大学農学部FMセンター府中の実験圃場で栽培試験を行った(図1).植え付けた馬鈴薯の品種は「ニシユタカ」であり,高収量性,二期作適性,早生性,および栽培容易性で知られている.栽培は2022年のDOY(Day of Year)258に植え付け,DOY 355に収穫した.基肥は複合燐加安42号を窒素,リン酸,カリがそれぞれ10kg/10aになるよう施用した.施肥処理区の施肥条件として,基肥に加え,2回の追肥施用を行った追肥区,基肥のみの施用を行った処理区を施肥区とした(表1).また,対照区として,施肥なしの無施肥区を設けた.実験区において,各プロットサイズを8m×3mとし,追肥区A,施肥区B,無施肥区Cが圃場西側から,ABCの順になるよう設定した.D,E,F,G,H,Iについても同様に実験区を設定し,各実験区3プロットずつとなる全9プロットの実験を行い,3反復とした(図2).各試験区は面積240m²(30m×8m),5畝から構成され,1区あたり270株の馬鈴薯を均等に植え付けた.雑草が画像解析に影響を与えるのを防ぐため,生育期間中には手作業で定期的に除草を行った.また,灌水は実施せず,自然降雨のみで栽培を実施した.

2.2 ドローンによる圃場空撮
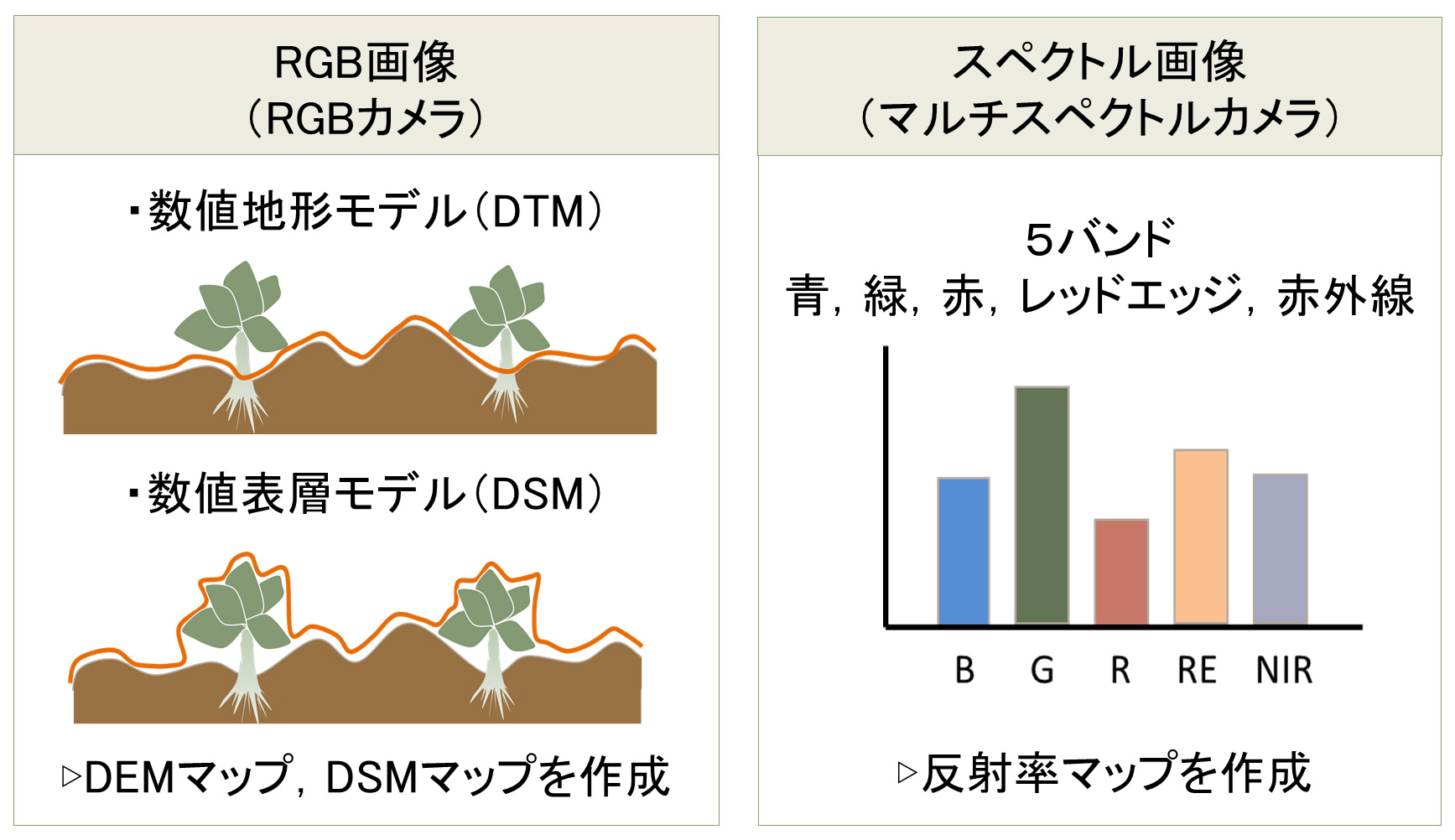
本研究では,ジンバル搭載カメラZenmuse X5S(DJI CO., Ltd., 中国)およびマルチスペクトルカメラAltum(MicaSense社,米国)をドローン(DJI Matrice 210 V2,DJI社)に搭載し,空撮を実施した(図3).飛行高度は地上高12mとし,RGB画像は解像度2.6mm/pixelで撮影した.また,マルチスペクトル画像は6バンド(475nm(青),560nm(緑),668nm(赤),717nm(レッドエッジ),842nm(近赤外),8–14µm(熱赤外))で取得した.センサーの解像度は,RGB画像で5280×3956ピクセル,マルチスペクトル画像(熱赤外を除く)で2064×1554ピクセルである.撮影は快晴日の午前9時〜10時30分の間に行い,DOY 271,278,285,292,299,306,313,320,328,334,341の計11回実施した.なお,撮影のラップ率は前方90%,側方70%に設定した.また,圃場の四隅と中央に黒黄十字型の200mm×200mmのグランドコントロールポイント(GCP)を配置した.

空撮した画像の前処理にはPix4Dmapper(Pix4D社,スイス)を用い,GCPを利用した幾何補正付きオルソモザイク画像を作成した.さらに,RGB画像から裸地面のみを表現したデジタル地形モデル(DTM)および地形標高と地上部草高を加えたデジタル表層モデル(DSM)を生成し,草高の算出に用いた(図4).各飛行では,校正パネルを用いた補正を実施した.具体的には,飛行前にキャリブレーションパネルを上方から撮影し,これに加えてダウンウェリング光センサーおよび太陽高度情報を組み合わせることで,環境光変動に起因する誤差を最小化した.これらの処理により,5バンドの幾何補正・放射補正済み反射率マップを生成した(図4).
2.3 データ取得
各試験区において,約1週間おきに各プロット3株の草高を計測した(DOY 278,285,292,299,306,313,320,326,334,341,348).DOY 292に塊茎形成の開始を確認した後,各区からランダムに3株(計9区×33株=27株)を2週間間隔でサンプリングし(DOY 292,306,320,334,348),収穫まで継続した.葉,茎,塊茎に分解した後,電子上皿天秤(GX6100,アズワン)で塊茎の新鮮重,塊茎数を測定した.なお,栽培試験終了日には,抜き取り調査を実施しなかった残りの各プロット12株ずつ(全9プロットで108株)の収穫を行い,抜き取り調査と同様に塊茎重,塊茎数を測定した.その際,形成された塊茎の個数も調査した.なお,これらの調査は原則としてドローン撮影日の午前中に実施した.
2.4 草高および植生指数の算出
DSMからDTMを差し引くことで草高マップを作成した(図4).さらに,放射補正を施したオルソモザイク画像から,緑正規化差植生指数(GNDVI),正規化差植生指数(NDVI),および正規化色素クロロフィル指数(NPCI)の3つの植生指数を算出した.これらの指数を採用した理由は,多数の植生指数を同時に用いると多重共線性の影響が強く効率的でないこと,NDVIおよびGNDVIが葉のクロロフィル含有量と高い相関を持ち収量予測に広く用いられていること[17],さらにNPCIがクロロフィルの呼吸特性を反映し,作物の生理状態や生産性を把握する上で有効であること[18,19]による.各植生指数の計算式は以下のとおりである.
- GNDVI=(NIR−Green)/(NIR+Green)
- NDVI=(NIR−Red)/(NIR+Red)
- NPCI=(NIR−Blue)/(NIR+Blue)
ここで,NIR,Green,Red,Blueはそれぞれ近赤外,緑,赤,青バンドの反射率をそれぞれ表す.
2.5 植物高および植生指数からの特徴量抽出
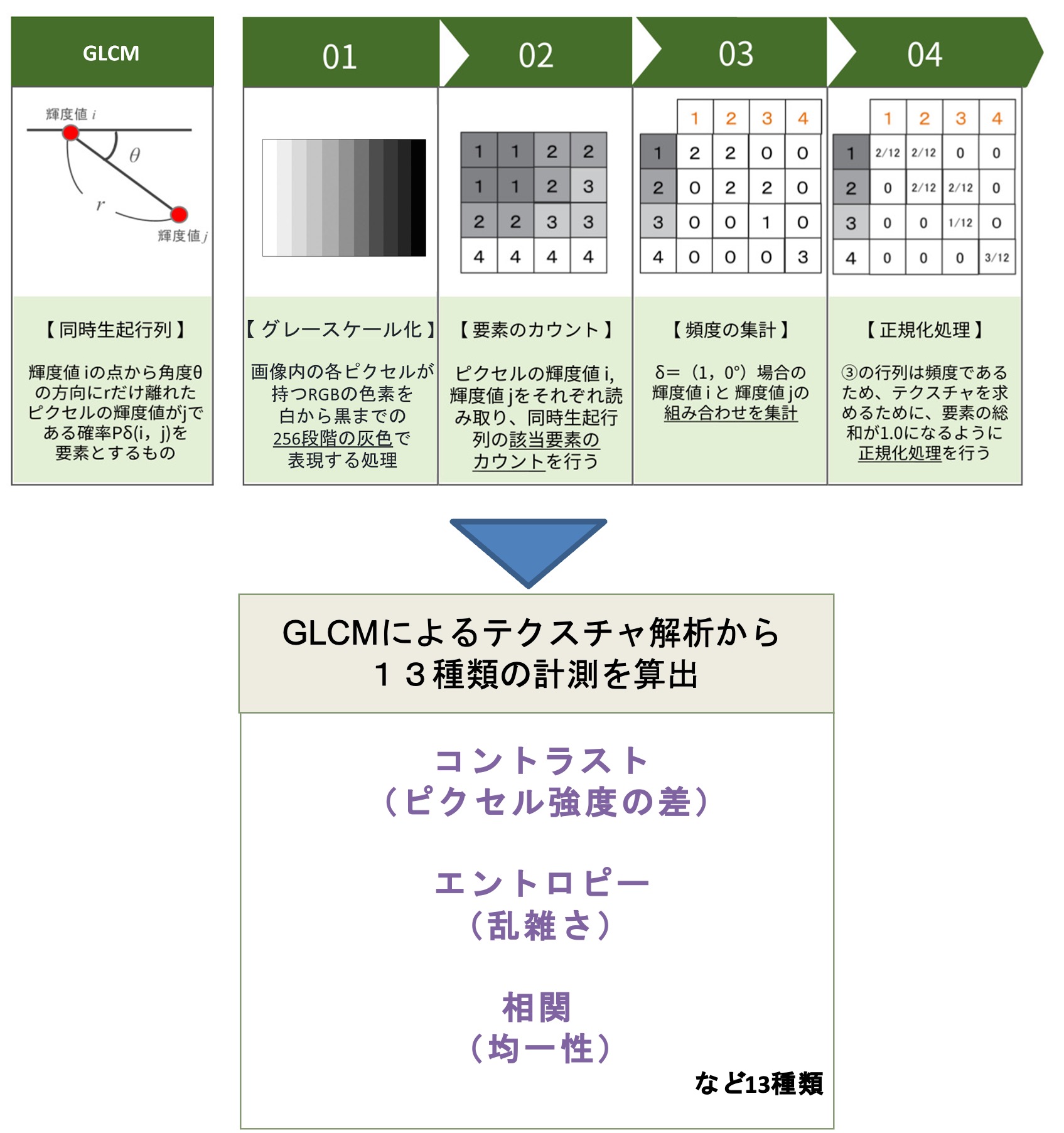
馬鈴薯の地下部塊茎重を予測するため,最初に地上部植被部分を株レベルで抽出した.その際,草高および3つの植生指数マップから各個体を識別する前処理を行った.隣り合う株の葉が非接触の場合には,NDVIが0.3を超える画素を植物体と判断し,雑草として誤判別された画素は手作業で除去した.一方,複数の葉が接触している場合には,まずDOY278に取得した画像から各株の重心を算出し,その重心を中心とした半径20cmの円内でNDVIが0.3を超える画素を抽出することで,それぞれの個体を分離した.以上により,各個体の植被領域を抽出した.この処理により得られた各株の草高および植生指数から統計的特徴量を算出した.まず,平均値,最大値,標準偏差,歪度,レンジの5つの一次統計量を個体ごとに導出した.さらに,グレーレベル共起行列(GLCM)に基づく二次統計量として,総平均,エントロピー,差分エントロピー,和のエントロピー,分散,差分分散,和の分散,角二乗モーメント,逆差分モーメント,コントラスト,相関,および相関情報量(MOC1,MOC2)の計13種類を算出した[20,21](図5).最終的に,草高および植生指数から得られる18種類の特徴量を,9時期(DOY 285,292,299,306,313,320,328,334,342)のデータに基づいて株ごとに抽出した.草高から得た特徴量は162変数,植生指数から得た特徴量は486変数となり,合計648変数が分析に用いられた.
2.6 特徴量の選択
機械学習モデルにおいて,説明変数の寄与度には差があり,不要な変数が多いと予測精度を低下させる要因となる.また,計算コストの増大にもつながるため,効率的な解析を行うためには,馬鈴薯の塊茎重に与える影響の大きいと考えられる特徴量を選択し,予測への影響が相対的に小さい変数を削減することが重要である.本研究では,前節で抽出した648変数を候補とし,次の5つの特徴量選択手法を適用した:Boruta,DALEX,遺伝的アルゴリズム(GA),Least Absolute Shrinkage and Selection Operator(LASSO),および再帰的特徴削除(RFE)[22–27].Borutaはランダムフォレスト(RF)を基盤とし,実際の特徴量とそのシャドー特徴量(ランダムに複製した特徴量)を比較することで有効な変数を選択する.DALEXは複雑な機械学習モデルの予測を解釈可能にするフレームワークであり,変数の影響度を可視化することで特徴選択を補助する役割を果たす.GAは進化的最適化手法に基づき,特徴集合を世代ごとに進化させ,最適もしくは準最適な特徴集合を探索する手法である.LASSOは回帰係数にペナルティを課すことで,寄与度の低い変数をゼロに近づけ,重要な変数を残す手法である.RFEはモデルを繰り返し学習させながら寄与度の低い特徴を逐次削除し,最終的に重要度の高い変数をランキングする手法である.
上記の各手法により,塊茎重,塊茎数,および塊茎平均重の予測に有効な特徴量を抽出した.選択された主要な変数群は,RF[28],リッジ回帰(RI)[29],サポートベクターマシン(SVM)[30]の各機械学習モデルの入力に用い,塊茎重,塊茎数,平均塊茎重の予測性能評価に用いた.なお,全実測データの80%をモデルの学習用として使用し,残りの20%をモデルの検証・評価に用いた.各モデルによる予測性能評価には,決定係数(R2)と相対二乗平均平方根誤差(rRMSE)指標をそれぞれ用いた.
3.馬鈴薯の塊茎重予測結果
3.1 草高と植生指数の時系列マップ
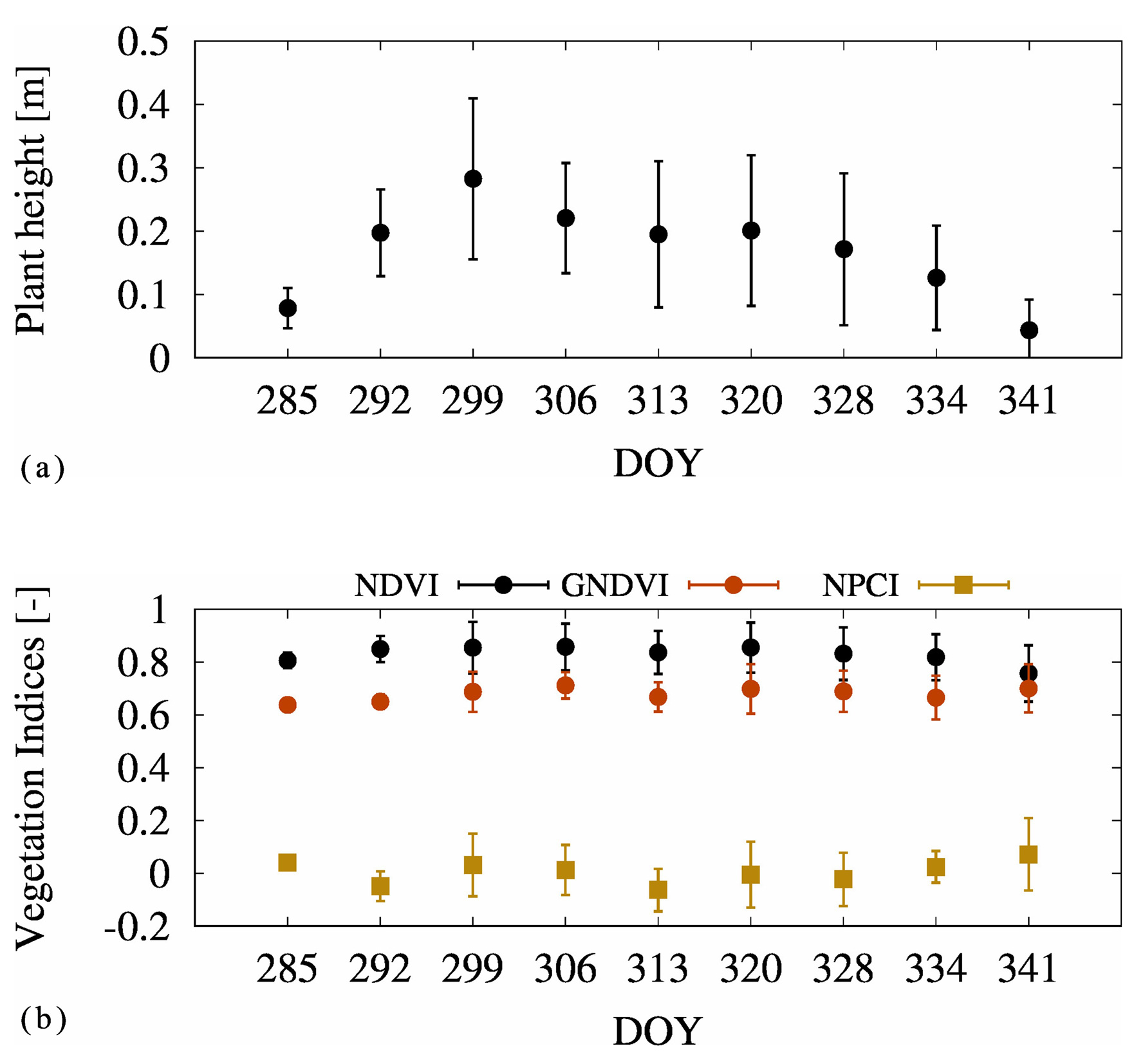
RGB画像から生成したDSMとDEMの差分により得られた草高,ならびに放射補正済みオルソ画像から算出したGNDVI,NDVI,NPCIについて,生育期間を通じた空間分布を作成した(図6〜図9).GNDVIおよびNDVIの値が大きく広範囲に分布するほど,植物体の生育が旺盛で健全であることを示している.草高は定植から塊茎形成期にかけて直線的に増加し,その後は葉が水平方向に展開することで緩やかに減少した.この成長パターンは,植物成長におけるシグモイド曲線に類似している(図10(a)).一方,植生指数の値は生育初期から成熟期(12月初旬)にかけてほとんど変化しなかった.特に,GNDVIはおおむね0.8〜0.9の高い値を安定的に維持し,NDVIは0.6〜0.7,NPCIは±0.1の範囲で推移した(図10(b)).これらの結果は,対象となった馬鈴薯が十分な栄養吸収と高い光合成活性を維持していたことを示している.




3.2 特徴量選択の結果
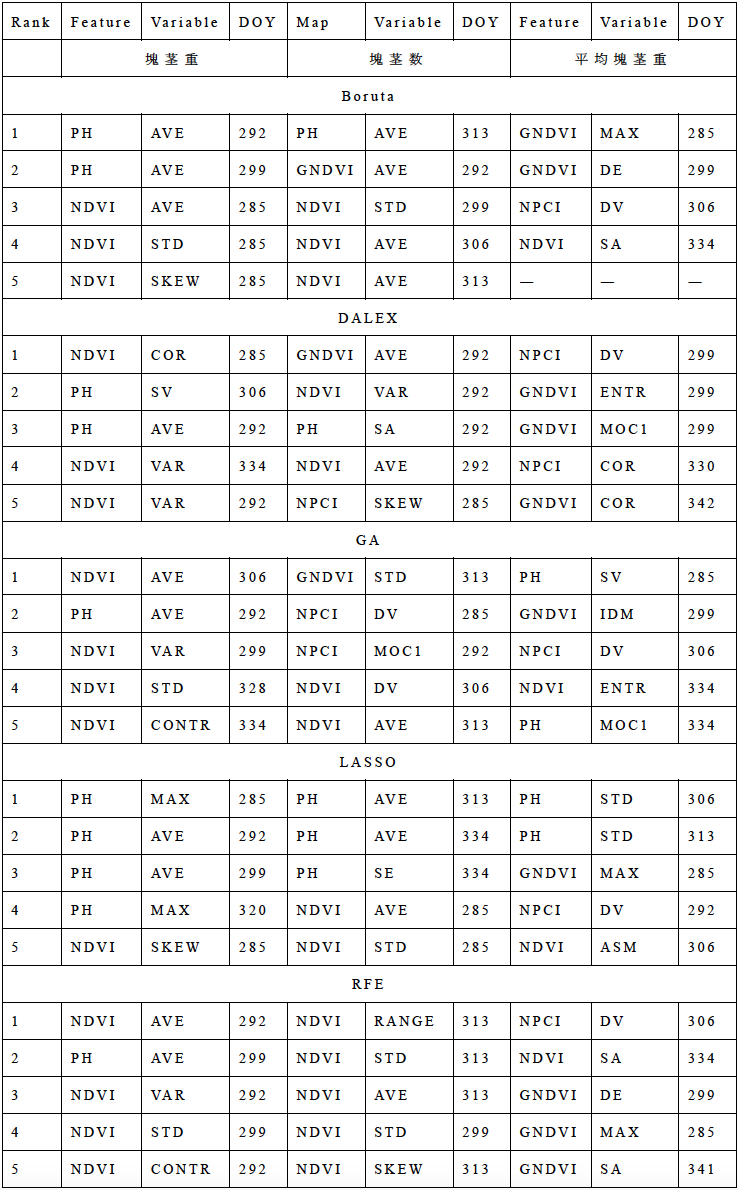
表2に,Boruta,DALEX,GA,LASSO,RFEにより算出された重要度スコアに基づき,塊茎量,塊茎数,および平均塊茎重の予測に有効と認められた上位5変数をそれぞれ示す.塊茎量に関しては,すべての特徴量抽出手法において草高(PH)の一次統計量,および生育期中盤から塊茎形成期にかけて得られたNDVIの一次・二次統計量が選択された.Borutaは草高およびNDVIの一次統計量をより重視し,LASSOは主としてPHの一次統計量を選択する傾向を示した.一方,DALEX,GA,RFEはPHおよびNDVIの一次・二次統計量を組み合わせて抽出した.これらの結果は,草高や植生指数の一次統計量に加え,GLCMに基づくテクスチャ解析による二次統計量が,塊茎重予測において有効であることを示唆している.特に,葉の光合成と塊茎肥大の関係を考えると,草高の一次統計量が強く寄与していた点は注目に値する.塊茎数に関しては,BorutaとLASSOはいずれも草高の平均値を最も重要な変数と位置づけていることが分かる.その一方で,LASSO以外の多くの手法は植生指数に関連する変数を上位に抽出した.また,すべての特徴量選択法でNDVIの平均値が上位にランクインしており,収穫約1.5〜2カ月前の生育状態が最終的な塊茎数決定において重要であることが裏付けられた.これは塊茎形成期における植生指数測定の重要性を示すものであり,植付けや栽培管理において有効な指標となる可能性が高い.平均塊茎重の予測では,栄養生長期から塊茎肥大期にかけて得られる植生指数関連の指標が重要な変数として選択されている.塊茎重および塊茎数の場合と異なり,二次統計量の寄与が大きく,特にBoruta,LASSO,RFEのいずれもDOY285におけるGNDVIの最大値を上位に選択していることが分かる.さらに,NPCIの二次統計量はすべての特徴量選択法で重要変数とされ,塊茎形成期における植物の光合成特性や代謝状態を反映した指標であることが分かった.すなわち,平均塊茎重予測には一次統計量だけでなく,GLCMによる二次統計量の活用が不可欠であることが明らかとなった.
3.3 機械学習モデルによる予測性能結果
選択された上位5つの変数群を用いて,ランダムフォレスト(RF),リッジ回帰(RI),サポートベクターマシン(SVM)の3種類の回帰モデルを構築した.データの80%(n=109)を学習用,残り20%を検証用として分割し,10分割交差検証を行った.図11に,実測値と予測値の関係を示し,表3には変数選択により選択された変数群を用いたモデルごとの実測値と予測値間の決定係数(R2)および相対二乗平均平方根誤差(rRMSE)をそれぞれ示す.
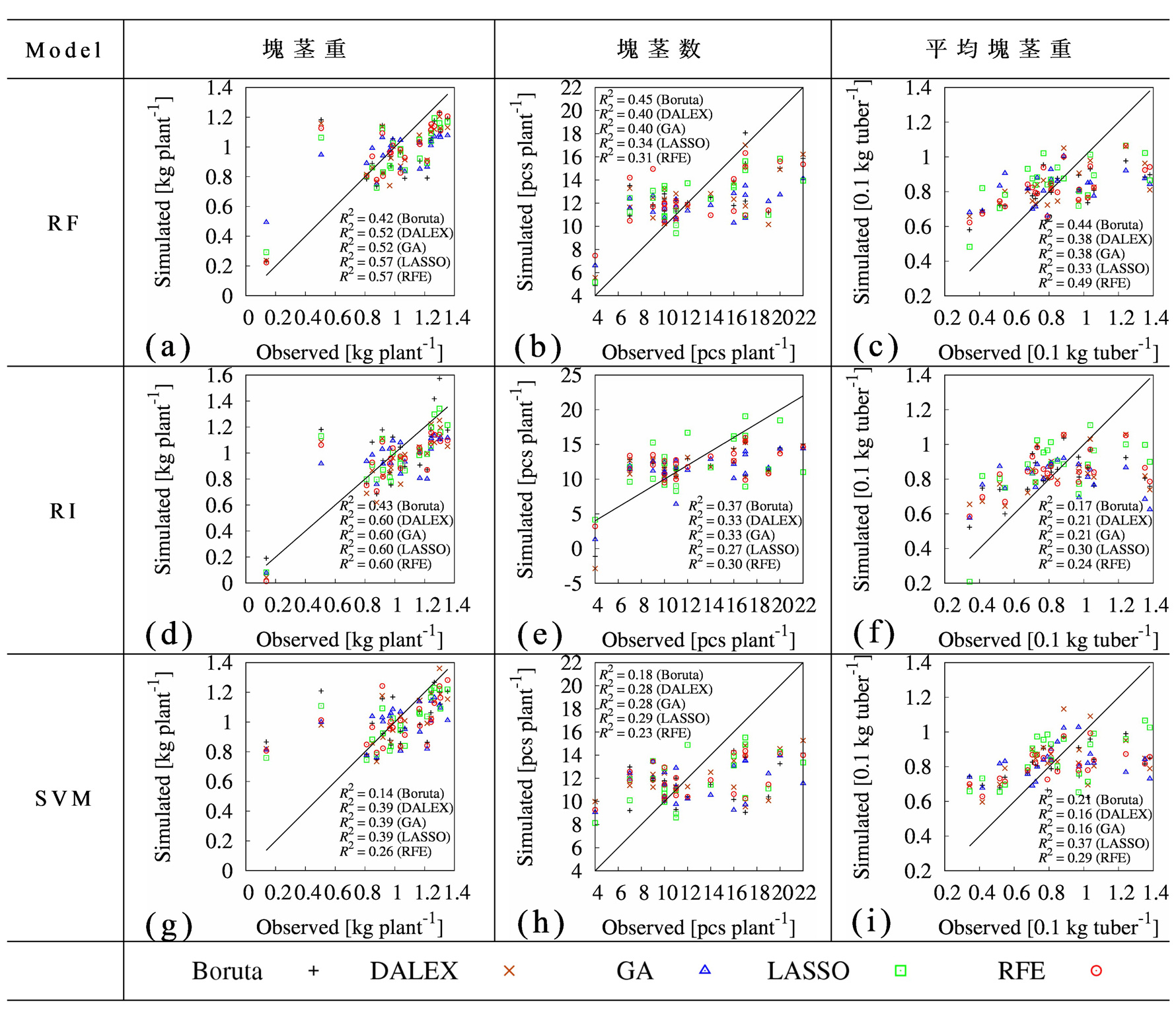
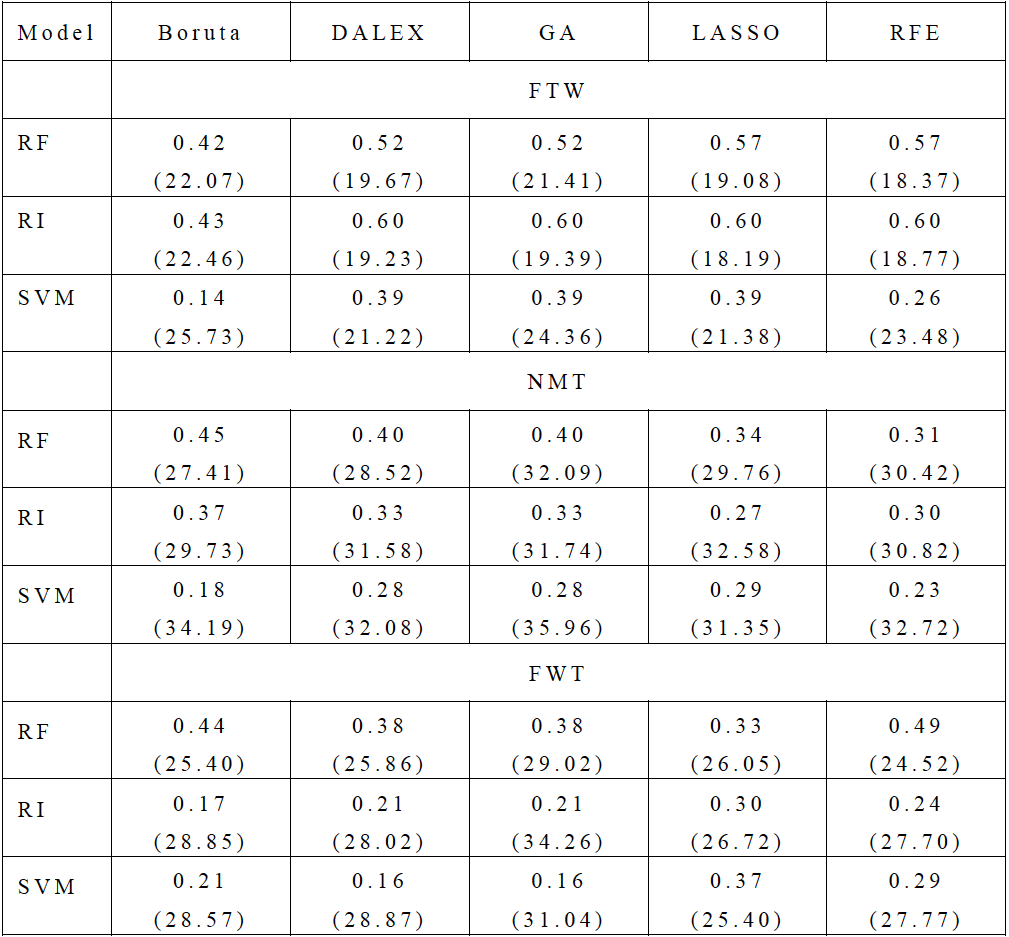
塊茎重の予測に関し,RFおよびRIのいずれの手法も高い精度を示した.特にRIは,DALEX,GA,LASSO,RFEで選択された変数群を用いた場合にR2=0.60の高い一致度を示し,LASSOとの組合せでは最小の誤差(rRMSE=18.19%)を示した.これらの結果は,草高の一次統計量とNDVIの一次・二次統計量が塊茎重予測において不可欠であることを裏付けている.塊茎数の予測では,Borutaにより抽出された変数を組み込んだRFモデルが最も高い性能(R2=0.45,rRMSE=27.41%)を示した.一方,二次統計量の寄与は小さく,主に草高,GNDVI,NDVIの一次統計量が有効であった.これは,地上からは直接観測が難しい塊茎数の予測に,生育中期の植生指数が強く関連することを示している.平均塊茎重に関しては,BorutaおよびRFEで選択された変数を用いたRFモデルが高い予測精度が得られる結果となった(それぞれR2=0.44,0.49;rRMSE=25.40%,24.52%).特に,植生指数から得られる二次統計量を多く含むモデルで予測精度が高く,平均塊茎重の予測にはテクスチャ情報を反映した特徴量が重要であることが明らかとなった.
全体として,塊茎重,塊茎数,平均塊茎重のいずれにおいてもRFは一貫して安定した予測性能を示し,特に異なる特徴量選択法との組合せに柔軟に対応できる結果となった.一方,RIは線形的な関係に強みを持ち,塊茎重の予測精度において高い適合性を示したが,塊茎数および平均塊茎重ではRFと比較して低い予測精度となった.SVMは非線形性の取り扱いに長けるものの,本研究においては相対的に予測性能が低くなった.これらの結果から,株単位の馬鈴薯の塊茎重予測においては,RFモデルが最も実用的であると考えられる.特に,草高や植生指数の一次統計量に加えて,二次統計量を組み込むことで,塊茎重や平均塊茎重の予測精度が向上した.
従来の空撮画像に基づく収量予測は,地域や圃場単位のスケールで行われることが多く,大規模な営農管理には有用である一方,圃場内の生育状況のばらつきを十分に捉えることはできなかった.本研究では,こうした課題を克服するために,株単位に着目した地下部塊茎重の予測を試みた.その結果,株単位での解析は,不均質な圃場環境における生育状況をより詳細に把握できるだけでなく,育種や精密管理の現場で実際に活用可能な情報を提供できる可能性のあることが明らかになった.従来の区画単位では空間的なばらつきが平均化されてしまうのに対し,株単位の予測では,特異な成長パターンや施肥応答を示す株を特定でき,それに基づいた栽培管理が可能となる.これまでの研究[7,9,13,31,32,33]は,地域や圃場単位での収量予測において高い信頼性を示してきたが,圃場内の不均一性という重要な要素を十分に考慮していなかった.既往研究との比較は,評価手法,対象年次,作物種,地域,調査時期,空間スケールといった条件の違いから容易ではないものの,本研究での株単位での塊茎重予測は,計算負荷やデータ取得の複雑性を伴いつつも,既往研究と同等あるいはそれに近い予測精度を示し,得られる知見の有用性も高いことが明らかになった.また,本研究の成果は,形態情報の収集において二次的な特徴量や特定の成長段階に注目することの重要性も示している.今後は,より多様な環境や複数の生育シーズンを対象とする大規模データセットを用いて,提案した特徴量選択手法の汎用性と頑健性を検証することを目指す.これにより,高収量系統を効率的に同定できる育種プロセスの合理化が期待され,農業生産性向上に資する選抜方法の最適化にもつながると考えられる.
4.結論と今後の展望
本研究では,ドローンに搭載したカメラから取得したRGB画像およびマルチスペクトル画像を用いて,馬鈴薯の株ごとの塊茎重,塊茎数,および平均塊茎重の予測を試みた.ドローン空撮画像から得られた草高および植生指数(GNDVI,NDVI,NPCI)の一次・二次統計量を解析した結果,収穫前1.5〜2カ月前の草高および植生指数の統計量が塊茎重および平均塊茎重の予測に重要であることが明らかとなった.一方,GLCMを用いた特徴量は塊茎数予測への寄与が小さいことが分かった.各機械学習モデルの中でRFは総じて高い精度を示し,その有用性が明らかになった.これらの結果から,重要度の低い形質や生育段階のデータを明らかにすることで,収量予測に必要な表現型データの効率的な収集が可能になると考えられる.さらに,ハイパースペクトル画像を用いた統計的特徴量の抽出は育種選抜の高度化に有効であり,今後の農業生産性向上に資する可能性がある.これらの知見は,従来の圃場平均に基づく収量予測が抱える限界を補うものであり,精密農業の高度化や,育種における高収量系統の効率的な選抜に直接的な貢献を果たす可能性がある.
今後の課題として,より多様な品種,圃場条件,生育シーズンにまたがる大規模データセットを活用し,提案手法の一般化と頑健性を検証することが挙げられる.これにより,研究成果を営農現場で実装していくことが可能になるであろう.
参考文献
- 1)FAO : FAOSTAT, http://www.fao.org/faostat/en/#home(2025年8月6日現在).
- 2)Hussain, T. : Potatoes: Ensuring Food for the Future, Adv. Plants Agric. Res., 3, 178–182 (2016).
- 3)Shi, Y., Thomasson, J. A., Murray, S. C., Pugh, N. A., Rooney, W. L., Shafian, S., Rajan, N., Rouze, G., Morgan, C. L. S., Neely, H. L., Rana, A., Bagavathiannan, M. V., Henrickson, J., Bowden, E., Valasek, J., Olsenholler, J., Bishop, M. P., Sheridan, R., Putman, E. B., Popescu, S., Burks, T., Cope, D., Ibrahim, A., McCutchen, B. F., Baltensperger, D. D., Avant, R. V., Vidrine, M. and Yang, C. : Unmanned Aerial Vehicles for High-Throughput Phenotyping and Agronomic Research, PLoS ONE, 11(7), e0159781 (2016).
- 4)Barbedo, J. G. A. : A Review on the Use of Unmanned Aerial Vehicles and Imaging Sensors for Monitoring and Assessing Plant Stresses, Drones, 3, 40 (2019).
- 5)Sun, C., Feng, L., Zhang, Z., Ma, Y., Crosby, T., Naber, M. and Wang, Y. : Prediction of End-of-Season Tuber Yield and Tuber Set in Potatoes Using In-Season UAV-Based Hyperspectral Imagery and Machine Learning, Sensors, 20(18), 5293 (2020).
- 6)Sun, C., Zhou, J., Ma, Y., Xu, Y., Pan, B. and Zhang, Z. : A Review of Remote Sensing for Potato Traits Characterization in Precision Agriculture, Front. Plant Sci., 13, 871859 (2022).
- 7)Li, B., Xu, X., Zhang, L., Han, J., Bian, C., Li, G., Liu, J. and Jin, L. : Above-Ground Biomass Estimation and Yield Prediction in Potato by Using UAV-Based RGB and Hyperspectral Imaging, ISPRS J. Photogram. Rem. Sens., 162, 161–172 (2020).
- 8)Luo, S., Jiang, X., He, Y., Li, J., Jiao, W., Zhang, S., Xu, F., Han, Z., Sun, J., Yang, J., Wang, X., Ma, X. and Lin, Z. : Multi-Dimensional Variables and Feature Parameter Selection for Aboveground Biomass Estimation of Potato Based on UAV Multispectral Imagery, Front. Plant Sci., 13, 948249 (2022).
- 9)Li, D., Miao, Y., Gupta, S. K., Rosen, C. J., Yuan, F., Wang, C., Wang, L. and Huang, Y. : Improving Potato Yield Prediction by Combining Cultivar Information and UAV Remote Sensing Data Using Machine Learning, Rem. Sens., 13, 3322 (2021).
- 10)Ma, Y., Chen, Z., Fan, Y., Bian, M., Yang, G., Chen, R. and Feng, H. : Estimating Potassium in Potato Plants Based on Multispectral Images Acquired From Unmanned Aerial Vehicles, Front. Plant Sci., 14, 1265132 (2023).
- 11)Yang, S., Feng, Q., Yang, W. and Gao, X. : Simple, Low-Cost Estimation of Potato Above-Ground Biomass Using Improved Canopy Leaf Detection Method, Am. J. Potato Res., 100, 143–162 (2023).
- 12)Pei, H., Feng, H., Li, C., Yang, G., Wu, Z. and Liu, M. : Estimation of Aboveground Biomass of Potato Based on Ground Hyperspectral, Proc. 8th Int. Conf. Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, IEEE, 1–4 (2019).
- 13)Gómez, D., Salvador, P., Sanz, J. and Casanova, J. L. : Potato Yield Prediction Using Machine Learning Techniques and Sentinel-2 Data, Rem. Sens., 11, 1745 (2019).
- 14)Tanabe, D., Ichiura, S., Nakatsubo, A., Kobayashi, T. and Katahira, M. : Yield Prediction of Potato by Unmanned Aerial Vehicle, Proc. 7th Int. Conf. Trends Agric. Eng., Prague, Czech Republic, TAE, 540–546 (2019).
- 15)Liakos, K. G., Busato, P., Moshou, D., Pearson, S. and Bochtis, D. : Machine Learning in Agriculture: A Review, Sensors, 18, 2674 (2018).
- 16)Yang, Q., Shi, L., Han, J., Zha, Y. and Zhu, P. : Deep Convolutional Neural Networks for Rice Grain Yield Estimation at the Ripening Stage Using UAV-Based Remotely Sensed Images, Field Crops Res., 235, 142–153 (2019).
- 17)Morier, T., Cambouris, A. N. and Chokmani, K. : In-Season Nitrogen Status Assessment and Yield Estimation Using Hyperspectral Vegetation Indices in a Potato Crop, Agron. J., 107, 1295–1309 (2015).
- 18)Clark, M. L., Roberts, D. A., Ewel, J. J. and Clark, D. B. : Estimation of Tropical Rain Forest Aboveground Biomass With Small-Footprint Lidar and Hyperspectral Sensors, Rem. Sens. Environ., 115, 2931–2942 (2011).
- 19)Yue, J., Yang, G., Li, C., Li, Z., Wang, Y., Feng, H. and Xu, B. : Estimation of Winter Wheat Above-Ground Biomass Using Unmanned Aerial Vehicle-Based Snapshot Hyperspectral Sensor and Crop Height Improved Models, Rem. Sens., 9, 708 (2017).
- 20)Haralick, R. M., Shanmugam, K. and Dinstein, I. : Textural Features for Image Classification, IEEE Trans. Syst. Man Cybern., SMC-3, 610–621 (1973).
- 21)Tatsumi, K., Igarashi, N. and Mengxue, X. : Prediction of Plant-Level Tomato Biomass and Yield Using Machine Learning With Unmanned Aerial Vehicle Imagery, Plant Methods, 17, 77 (2021).
- 22)Son, H., Kim, C., Kim, C. and Kang, Y. : Prediction of Government-Owned Building Energy Consumption Based on a RReliefF and Support Vector Machine Model, J. Civ. Eng. Manag., 21, 748–760 (2015).
- 23)Kursa, M. B. and Rudnicki, W. R. : Feature Selection With the Boruta Package, J. Stat. Softw., 36, 1–13 (2010).
- 24)Biecek, P. : DALEX: Explainers for Complex Predictive Models in R, J. Mach. Learn., 19, 1–5 (2018).
- 25)Scrucca, L. : GA: A Package for Genetic Algorithms in R, J. Stat. Softw., 53, 1–37 (2013).
- 26)Tibshirani, R. : Regression Shrinkage and Selection via the Lasso, J. R. Stat. Soc. Ser. B: Stat. Methodol., 58, 267–288 (1996).
- 27)Guyon, I., Weston, J., Barnhill, S. and Vapnik, V. : Gene Selection for Cancer Classification Using Support Vector Machines, Mach. Learn., 46, 389–422 (2002).
- 28)Breiman, L. : Random Forests, Mach. Learn., 45, 5–32 (2001).
- 29)Hoerl, A. E. and Kennard, R. W. : Ridge Regression: Applications to Nonorthogonal Problems, Technometrics, 12, 69–82 (1970).
- 30)Cortes, C. and Vapnik, V. : Support-Vector Networks, Mach. Learn., 20, 273–297 (1995).
- 31)Al-Gaadi, K. A., Hassaballa, A. A., Tola, E., Kayad, A. G., Madugundu, R., Alblewi, B. and Assiri, F. : Prediction of Potato Crop Yield Using Precision Agriculture Techniques, PLoS ONE, 11, e0162219 (2016).
- 32)Bala, S. K. and Islam, A. S. : Correlation Between Potato Yield and MODIS-Derived Vegetation Indices, Int. J. Remote Sens., 30, 2491–2507 (2009).
- 33)Salvador, P., Gómez, D., Sanz, J. and Casanova, J. L. : Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach, ISPRS Int. J. Geo-Inf., 9, 343 (2020).

辰己賢一
tatsumi@ds.nagoya-cu.ac.jp
2012年東京農工大学農学研究院助教,2016年同大准教授.2016年から2020年さきがけ研究者(兼務),2023年名古屋市立大学データサイエンス学部教授,2025年同データサイエンス研究科教授.米国農業工学会,日本農業気象学会,農業情報学会,農業食料工学会,環境情報科学センター各会員.専門は農業情報気象学,データサイエンス.
採録決定:2025年10月14日
編集担当:藤原真二((株)日立製作所)