研究業績情報を用いた大学教員の階層的分類
Hierarchical Clustering of University Faculty Based on Professional Accomplishments
1. はじめに
1.1 研究背景
現在,日本は少子高齢化・人口減少社会への転換という大きな環境変化を迎えている.18歳人口の急激な現象により,定員割れの私立大学が増加していることもあり,これまで若者の学位取得に主眼を置いてきた大学は,経営方針の見直しを迫られることとなった.一方,若い世代では自己を重視し,転職等によるキャリアアップを積極的に行う人口が増加してきた.このような生涯にわたる自らの能力の向上を行うために,赤倉[1]は,大学が社会人の再教育機関となることの重要性を言及している.つまり大学は,これまでのような18歳だけではなく,社会人や企業に幅広く自らの価値を提示し,関わりを強化していくことが求められると言える.
大学の提供する価値もしくはサービスとは研究と教育になり,社会が大学を評価するうえでもこの2点が重視される.ただし,教育は教員によって成され,教員は研究者としての専門分野に基づいてカリキュラムやプログラムを提供することとなるため,研究と教育を行う教員群が大学の所有する最もコアな資産となる.そのため,地域や産業の要求に即した教育や研究を提供する場合,大学経営者・社会の双方が,大学に所属する教員およびその教員が持つ知的資産を容易に把握できる必要があると考えられる.
ただし,大学情報の分析・可視化は教育的な観点から論じられることが多い.たとえば関谷・松田・山口[2]は,シラバスを用いたカリキュラム改善支援システムを開発した.中村・赤倉[3]も同じく,シラバスを用いた授業改善支援システムを開発している.筆者もこれらの研究の一環で,教員の教授行動や教科書知識の階層化を行い,教育改善に関する知見獲得を試みてきた[4], [5].これらの研究では,教員の話術や動作や教科書が注目されている.しかし,教授行動[6]はあえて教員の専門性に依存しない形式で定義されており,授業内容を表すシラバスや教科書についても,低学年が受講する科目においては教員の特性に依存しないものが多い.そのため,授業サービスのみを用いた分析では,研究面での大学特性が把握しづらいという課題がある.
ここで,教員の論文をはじめとする研究成果に着目する.研究成果は社会に公開されるが,その教員の所属する大学に紐づいて公開されることは,よほど際立った成果でない限り行われない.たとえばある大学の研究を問うた際に,巨大な研究成果や著名な教員が挙げられることはあれど,その大学に存在する研究の全体的な傾向や特色を述べられることはない.この理由として,大学に紐づいて業績情報が登録されることが少なかったことが挙げられる.大学教員は離転職が多いことから業績はホームページで公開される傾向があることに加え,大学ごとに教員業績管理システムの仕様が異なり業績登録の手間が大きかった点が問題としてあった.しかし,最近では国家主導で開発された業績管理システムが多くの大学で利用されている.そのため,これらの技術を用いることで,大学の所有する研究知識を概観するシステムの開発が可能となった.
そこで本研究では,大学教員の研究情報を可視化・検索するための方法論について検討を行う.本稿では,Webスクレイピングによって研究業績のタイトル情報を取得した後,深層学習技術によって表題から言語特徴を抽出し,階層的クラスタリングと木構造を用いた曖昧検索を行うことによって,可視化された研究情報を示し,考察を行う.1.2節では,本研究と関連する研究について述べ,本研究の位置付けを示す.2章では主に,分析方法と,実験において収集するデータについて述べる.3章では,実験の結果について考察を行い,有効性を評価する.
1.2 関連研究
塩野ら[7]は,業務の効率化や意思決定を支援するために,ファジィ検索および可視化の方法論を示している.特に,蓄積された業務データと,業務を担当する組織の構成員の関係をファジィ関係で定義しており,本研究における研究業績と教員の概念に類似している.また,ここではレベルという概念が定義されており,レベルを適切に設定することで複数の観点が混在するカテゴリを細分化することが可能となる.組織の活動を俯瞰し現状を把握するという目的は本研究と同一であるが,可視化は二次元の格子に設置したノードと,関係性を示すエッジに基づいて描画されることから,データ数が多いとエッジが交差し,可視性が損なわれるという課題が挙げられている.そこで本研究では,可視性を考慮した分析手法について検討する.
データ可視化の代表的な方法としてクラスタリングが挙げられる.山本ら[9]は,情報系センターに対する利用者の問い合わせ業務を効率化するために,文書モデルであるSCDV [17]と分割型非階層的クラスタリングを用いて分類を行うことで,問い合わせを自動的にカテゴライズする方法を示した.しかし,複数の観点が混在する解釈困難なクラスタが存在することが確認されていることから,設定したクラスタの数に依存しない,もしくは解釈が容易な形式での可視化を行う必要がある.別の研究として,松田ら[8]は,計算機科学のカリキュラム標準と教師有りLDAを用いてシラバスを18の知識体系上にマッピングし,凝集型階層的クラスタリングなどを用いてカリキュラムの分析を行った.階層的クラスタリングは,分割の閾値を下げることにより,複数の観点が混在するカテゴリを細分化することが可能である.また,各データに対する抽象ノードを媒介して木構造を構築するため,ノード間を直接連結する方法[7]でのエッジ交差は発生しない.このことから,木構造であればある程度の規模の可視化にも耐えうると考えられる.しかし,一般的な階層的クラスタリングはファジィ検索[7]に類する機能を持たないため,検索の方法論を検討する必要がある.
階層的クラスタリングを検索に応用した研究として,岩山ら[10]は,文書連想検索のための階層ベイズクラスタリング(HBC)を提案している.この研究では,単純な網羅検索では比較対象の大きさNに対して計算量が${O}(N)$となることに対し,二分木を用いたトップダウン検索によって${O}({\log _2}N)$まで抑えることを目的としている.その際に,既存の構造構築の課題に言及し,データ検索に最適化された新たなクラスタリング手法を提案している.ただしHBCは実装例が少なく,システムを開発する際に支障がある.一方で河村と斉藤[11]は,クラスタリング手法として有名なWard法を用いて性質の近いユーザを集約し,ユーザの検索機能を実装している.Ward法は実装も容易であり,その性質も広く考察されているため,検索のためのモジュールとして扱いやすい.そのため,本研究でもWard法を用いたクラスタ検索機能を実装するが,本研究は言語情報を用いてユーザをクラスタリングするため,行動予測を目的として訪問状況のような特性データを用いる当該研究とは異なる.
本研究では教員の特性データとして,業績タイトルの言語情報から何らかの特徴量を抽出し,クラスタリングおよび検索・可視化を行う.言語情報の特徴抽出手法としてはTF-IDF [12]やLDA [13],word2vec(w2v) [14],BERT [15]などが挙げられる.TF-IDFは単語の重要度に基く分散表現を求める手法である.一方で,LDAは単語ではなく文書の背景に潜む潜在的な話題を確率分布の形式で抽出することができる.w2vはTF-IDFと同様に単語の分散表現を獲得することが可能であり,文書の特徴抽出を目指したdoc2vec [16]や,w2vを用いた文書特徴抽出手法であるSCDV [17]も提案されている.BERTは単語や文書の分散表現を得ることが可能であり,高い言語処理能力を有することが知られている.また,文書の分散表現を獲得することに特化したSentenceBERT(SBERT)も開発されている[18].これらの手法は,分析対象となるコーパスを学習することによって言語モデルを構築するのが一般的である[2], [3], [8], [9].これによりモデルをドメインに特化させ精度を向上することが可能となるが,コーパスの品質や規模によっては十分な表現能力が獲得できない場合があり,またデータに依存することから手法の再現性が落ちるという問題がある.Wikipediaなどの公開コーパスを用いてモデルを構築することも可能であるが[5],大規模なコーパスでの訓練は時間がかかる.一方,w2vとBERTは日本語を対象とした学習済みモデルが公開されているため,前述の課題は問題とならない.その中でもBERTは高い言語処理能力を有し,文書特徴を抽出できるSBERTについても学習済みモデルが公開されている.そのため,本稿では業績タイトルからSBERTを用いて特徴を抽出するものとする.
本研究は研究業績のタイトルから自然言語処理技術を用いて特徴を抽出し,それらを教員個々にクラスタリングすることで研究者情報の可視化と特徴抽出を行う.さらに,教員の特徴を再度クラスタリングすることで,大学教員の関係性の可視化およびクラスタ検索を行う.塩野ら[7]の行う構成員のファジィなクラスタリングと検索を,岩山ら[10]や河村ら[11]の二分木で置き換えたのが本研究で検討する方法論であるが,研究者検索にこれらの方法を適用した研究は,筆者の知る限り存在しない.
2. 方法論
分析に用いる手法の概要やアルゴリズムは2.1節で述べる.手法の具体的なパラメータやモジュール,分析に用いるデータの詳細などは2.2節で述べる.
2.1 分析の手順
本研究で行う分析の概要を図1に示す.ここでは大学を木に見立て,教員を葉として扱っている.分析の手順としては,まず教員の業績をクラスタリングすることによって教員の特徴を抽出し,次は教員をクラスタリングすることで大学教員の関係性を分析する.最後に,その構造を用いて教員の検索を行うことを目標とする.次節からは,文書からの言語特徴の抽出と,クラスタリングのアルゴリズムについて詳細を述べる.
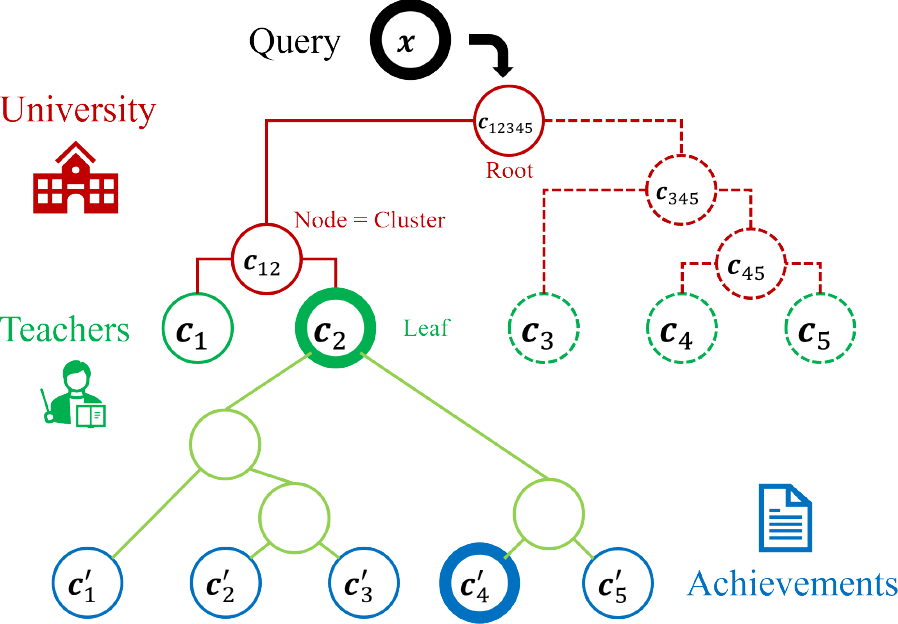
Fig. 1 Clustering of university faculty using achievement titles.
2.1.1 業績タイトルからの文書特徴抽出
後述するクラスタリングの性質により,本研究における特徴抽出手法は,文字列を固定次元の実数空間に写像できることが必要であり,意味が類似した文字列同士が近くに写像される手法であれば十分である.そこで本稿では文書特徴の抽出手法として,文書から特徴量を抽出する手法として比較的新しく,研究が盛んで公開モデルが存在するSentence BERT(SBERT) [18]を用いる.
SBERTは深層距離学習を用いて文書埋め込みを最適化したモデルであり,マスク言語モデルと次文予測を用いて単語の文脈理解を行ったBERTに対し,SBERTはさらにSiamese Networkを用いることで文書間の意味的な類似性を認識できるように最適化される.そのため,クラスタリングにおいて妥当な特徴抽出手法であると言える.
2.1.2 教員のクラスタリング
本研究では教員のクラスタリングとクラスタ検索を行うために,凝集型階層的クラスタリングの結果を二分木の形式で保存する方法を検討する.図1に示すとおり,葉はデータを表し,部分木の根(葉以外の接点)はクラスタを表す.
階層的クラスタリングを二分木の形式で構成する手順について述べる.まず,クラスタcは二分木における節点であるが,二分木とは異なり,この節点は分類対象とするデータの集合として扱われる.クラスタは子cL, cRと子クラスタに属する全データの平均f,および要素数nを持つ.\[c=(c_{\rm L}, \ c_{\rm R}, \ f, \ n)\](1)
cの各項の計算方法について述べる.まず,クラスタの要素数nと平均fは次式のように,子の要素数nL, nRと平均fL, fRを用いて再帰的に計算することができる.\[n=n_{\rm L} + n_{\rm R}\](2)
\[f = \frac{n_{\rm L}f_{\rm L} + n_{\rm R}f_{\rm R}}{n_{\rm L} + n_{\rm R}}\](3)
次に,cL, cRは,クラスタ集合において距離が最も小さいクラスタの二項関係として求める.\[(c_{\rm L}, \ c_{\rm R}) = {\rm arg}\min _{c_i, \ c_j}{\rm D}(c_i, \ c_j)\](4)
ci, cjは各クラスタを木とした場合の根を意味する.クラスタの併合にはWard法を用いる.2つのクラスタci, cj間の距離は以下のように計算することができる.\[{\rm D}(c_i, \ c_j) = \sqrt {2 \frac{n_in_j}{n_i + n_j}(f_i - f_j)^2} \](5)
本研究において教員を表す葉(データ)は,次式のように表現される.\[c = (\emptyset , \ \emptyset , \ f, \ 1)\](6)
ここでの特徴fは,その教員が持つ業績のタイトルから抽出した特徴量を平均したベクトルとする.本稿では教員情報の可視化を容易にするために,図1の下部に示すとおり,業績をクラスタリングしたうえで教員の特徴量を求める.ただし,教員特徴のサイズを業績数に設定した場合,式(5)より業績数の大きい教員が他の教員と接続しづらくなり,クラスタリングの解釈が困難になることが予想される.そのため,教員クラスタに該当する葉のサイズは業績数とはせず,式(6)に準じ単一のデータとして扱うこととする.この業績クラスタによる教員表現は,次項で述べる検索法を実験にて評価する際に利用する.
2.1.3 教員クラスタの検索
研究情報の検索について述べる.ここで本研究は,経営者や社会人が大学の研究情報を把握することを支援するのが目的となる.逆に言えば,検索者は大学の具体的な研究については未知である.そのため検索クエリは,具体的な教員個人の研究ではなく,一般化された研究が対象である可能性が高い.図1で言えば,クエリxの主なターゲットは教員(葉)ではなく,そのうえの抽象的な研究(クラスタノード)であると推測できる.一方,検索方法の手順には,クラスタ木の葉を網羅探索するボトムアップ検索と,クラスタ木を二分探索するトップダウン検索が存在する[10].網羅探索は検索精度において二分探索よりも有効であるが,今回のようにノードがメインターゲットとなる場合,探索後にノードの親を辿って上位のクラスタノードを探索することになるため,効率が悪い.一方,トップダウン検索はターゲットノードを発見した場合に二分探索が終了するため,ボトムアップ検索よりも効率がよい.加えて,トップダウン検索はデータを一般化したクラスタを扱うため,データを直接扱う網羅探索よりもノイズの影響を受けづらいという利点がある[10].これらの利点により,本研究ではトップダウン検索を採用した.
具体的には,アルゴリズム1によって,あるデータの特徴xと類似するサイズNのクラスタを再帰的に探索する.

Nは検索の曖昧さを表し,塩野ら[7]の挙げるクラスタリングレベルと同様の概念と解釈できる.たとえば,図1においてx=c2かつN=2としたとき,検索結果はc12,つまり$ \{ c_1, c_2 \} $となる.4行目に現れる比較演算子<: $ (c, x) \to \{ 0, 1 \} $は二分探索における探索パスを決定する基準であるが,クラスタcの持つ特徴fは多次元ベクトルであることから,クラスタが持つ左右の子の持つ特徴ベクトルに対して順序を定義する必要がある.そこで,ロジスティック回帰を用いて探索パスを決定する.クラスタcに属するデータが左右のどちらに属するかを識別するシグモイド関数φ: $(c, x) \to (0, 1)$を定義する.\[[x < c] \ \equiv [ {\rm P}(x, \ c) < 0.5 ]\](7)
\[{\rm P}(c_{\rm d} \in c_{\rm L}|x, \ c) = \frac{1}{1 + {\rm exp}(w^{\rm T}x + b)}\](8)
式(10)のw, bは,次式で最適化された重みを意味する.\[w, \ b = {\rm arg} \ \min _{w,b} \sum \limits_{c_d} {\rm BCE} ({\rm P}(c_{\rm d}, \ x), \ [c_{\rm d} \in c_{\rm L}])\](9)
ただし,$c_{\rm d} \in c_{\rm L} \cup c_{\rm R}$,BCEは交差情報量である.例として,図1のc12345は$\{ c_1, c_2 \} $と$\{ c_3, c_4, c_5 \} $を識別するwとbを持つ.そのため,二分探索を行う場合,クラスタは以下のように定義される.\[c = (c_{\rm L}, \ c_{\rm R}, \ f, \ n, \ w, \ b)\](10)
2.2 実験概要
教員情報の収集方法と,収集および前節の方法論に関する実装方法について述べる.また,実験分析における有効性評価の観点を示す.
2.2.1 業績情報の収集
業績管理システムとしては各大学の導入したシステムやGoogle Scholarなどが存在するが,利用や論文登録の有無がユーザに委ねられるため,欠損データが多くなることが予想される.一方,researchmap [19]は国立研究開発法人科学技術振興機構が開発した日本の研究者総覧データベースである[20].一部の大学では教員総覧システムとしてresearchmapが用いられており,科学研究費助成に関する審査では審査委員が業績情報の確認のためresearchmapを参照する.そのため,国内の研究者がresearchmapへ業績を登録する動機は十分に存在する.以上の理由により,研究業績はresearchmapから取得する.
researchmapの仕様により,研究者は業績のタイトルと出版年度を入力することが求められ,それ以外の情報の入力は任意となる.加えて,研究は最新のものであることが望ましいと考えられる.以上を踏まえ,分析データはresearchmapから過去5年以内の間に公表された業績のタイトルとする.ここで,業績タイトルが英語で記述されている場合は日本語に翻訳する.また,researchmapでは大学に所属していない教員が専任として登録されている場合がある.この研究者を除くために,各大学の教員総覧から専任教員の名前を取得し,教員総覧に含まれる研究者をその大学の教員として扱う.また,researchmapと教員総覧のデータを取得する際には,教員の名前について外字変換を適用する.注意点として,専任教員以外で総覧に含まれる教員と,実験においてミドルネームの有無等により名寄せに失敗した教員,researchmapに過去5年分の業績を掲載していない教員は分析の対象としない.
対象とする教員は,11月時点で所属が確認されている茨城大学の教員とした.実験の都合上,本稿では教員の名前は表示せず,所属や,業績タイトルにおける重要単語のみを可視化する.
2.2.2 実装
researchmapと各大学の教員総覧のデータの収集にはPythonライブラリのrequestsとBeautifulSoup4を用いた.名前の外字変換にはja-cvu-normalizer 0.2.7 [22]を,英文タイトルの和訳にはgoogletrans 0.9.0 [23]を用いた.googletransはWeb APIであり,入力されたテキストの言語を自動的に判別する機能も持つ.ここで,言語判別機能を用いるためにはAPIにリクエストする必要があるが,すべての業績タイトルをリクエストすると処理時間が膨大になる.そのため,本実験ではローカル環境で言語が日本語か否かを判定し,英語と判定されたもののみをリクエストする方式を取る.researchmapでの取得対象となる業績は,2018年から2023年までの間に公表された論文・MISC・発表・書籍に限定した.リクエストは1秒間隔で実行し,googletransと外字変換の適用はリクエスト間で行った.業績タイトルは,以下の関数E: $title \to [0, 1]$が0.1未満であれば英語と判定した.\[{\rm E}(t) = \frac{|{\rm R}(“[{\rm a - zA - Z - }] +", “", {\rm L}(t))|}{|t|}\](11)
関数Rは英文字と空白を空文字に置換する関数,Lは小文字変換の関数を意味する.なお,英語以外の言語,たとえばフランス語などは前述の手順では正常に翻訳されないが,件数は少ないことが予想されるため,実験では翻訳せずに扱った.この場合,クラスタリングの対象にノイズが混在することになるが,教員の特徴量は研究業績特徴の平均として扱っており,ノイズにある程度の耐性がある.また,トップダウン検索はノイズに頑健な性質を持つと言われている[10].そのため,仮説どおりノイズの数が少なければ,クラスタリングおよび検索に大きな影響はないと考えた.
SentenceBERTの実装には日本語用Sentence-BERTモデル[24]を,単語分割はBERTの日本語用tokenizerを用いた.特徴ベクトルの次元は768となる.クラスタリングはscipy 1.10.1のlinkageを用いた.ロジスティック回帰は機械学習ライブラリのscikit-learn 1.3.0を用いた.文書情報の可視化にはTF-IDFとWordCloudを用いた.TF-IDFにおける文章は,ここでは教員の持つ業績タイトルを連結した文字列と定義した.IDFは大学に所属する全教員の文書を用いて,TFは可視化対象となるクラスタに属する教員の文書を用いて算出した.
2.2.3 評価方法
前節で述べた方法論を,定量的・定性的な観点から評価する.ここでは,研究業績のタイトルから研究者をクラスタリング可能か,およびクラスタリング結果を活用して研究者を検索できるか,の二点を評価する.ただし,今回は大学管理者が組織内教員の研究情報を外観するという目的より,クラスタリング可能性については大学管理者が教員に付与した教員所属情報を用いるが,検索に関しては訓練データのみを分析することで評価を行う.
業績のタイトルを用いたクラスタリングはあくまでSBERTで抽出した言語特徴による分類であり,これらの特徴量が研究の本質を表す保証はないことから,クラスタリング結果が本来の研究の分類とは異なる可能性がある.そのため,定量的な観点から評価を行い,評価結果に基づいて分析インタフェースを作成し,考察を行う.ここで,大学管理者が教員に付与した教員所属情報が研究情報を加味したものであれば,所属とクラスタリング結果は一致すると考えられる.教育学部やセンターについては所属研究者の分野が混在していることも考えられるが,その他の一般的な学部についてはある程度同一の研究分野を持つ研究者が所属している可能性が高い.このことから,大学の定義した所属情報Kを正解ラベルと定義してクラスタリング結果を評価する.ある閾値において得られるクラスタ集合Cについて,その要素cの内で,所属kがどの程度の割合で存在するかをp(k, c)とする.まず,クラスタに含まれる教員の所属リストTを以下のように定義する.\[c = (c_{\rm L}, \ c_{\rm R}, \ f, \ n, \ T)\](12)
\[T = T_{\rm L} \cup T_{\rm R}\](13)
このとき,クラスタ集合の平均ジニ不純度を用いて,各クラスタにどの程度の割合で異なる所属を持つ教員が含まれるのかを定量的に評価する.\[\bar G = \frac{\sum_{c \in C} {\rm G} (c)}{|C|}\](14)
\[{\rm G}(c) = \sum \limits_{k \in K} {\rm p}(k, \ c)(1 - {\rm p}(k, \ c))\](15)
\[{\rm p}(k, \ c) = \frac{\sum_{t \in T} [k = t] }{|T|}\](16)
不純度$\bar G$は,1のときはクラスタ内における所属の混在率が高く,0のときはクラスタ内に存在する教員の所属が単一であることを示す.この不純度を階層的クラスタリングの閾値を変化させながら求め,各クラスタ数におけるクラスタリング精度を求める.なお,クラスタ数が教員数と一致した場合,クラスタ内の教員は1名であるために不純度は0となるが,クラスタリングの結果としては意味をなさない.この事実より,クラスタ数が増加するほどクラスタ内の教員数が減少するため不純度は減少するが,解釈の都合でクラスタ数は少ないほうが望ましいものとする.
次に,検索について述べる.2.1節で述べた方法論は岩山ら[10]の分析手順とは大きく異なるため,有効性を新たに評価する必要があると考えた.そこで,2.1.3項で述べたトップダウン検索を,再現率・適合率を用いて次の2つの観点から評価を行う.まず,クラスタ内に存在する任意の教員の特徴量を入力した場合に,その教員が正しく発見できるかを評価する.これはSBERTとWardクラスタリングの二分探索が妥当であるかを問うベースラインテストであり,たとえば図1におけるxをc2とした際に教員c2を検索できるかどうかを検証する.次に,教員の業績特徴を入力した場合に,その業績を持つ教員を発見できるかを評価する.この評価は研究文書を検索クエリとした際に文書と類似する教員を検索できるかを問う実践的な評価であり,図1におけるxを${c'_4}$とした際に,教員c2を検索できるかどうかを検証する.そのために,ある教員を含むすべての二分木から,その教員の特徴$\overline c $もしくは業績の特徴fを入力したとき,検索結果に教員クラスタcが含まれているか否かを基に,混同行列の各要素を求める.ただし,Rは二分木の根,$S = {\rm SEARCH}({\rm R}, c, n)$とする.\[TP = \sum \limits_{c \in {\rm R}} [c \in S] \](17)
\[FN = \sum \limits_{c \in {\rm R}} [c \notin S] \](18)
これらの値を,検索対象とするクラスタSのサイズnを変化させたうえで求め,再現率を計算する.\[Recall = \frac{TP}{TP + FN}\](19)
なお,nが大きければ再現率は増加するが,検索対象外となるデータの数も増加するため,適合率が減少するのは自明である.ただし,今回はクラスタ検索という観点から適合率は重要ではなく,再現率が100%となるかどうかが重要となる.そのため,本稿では再現率のみを示す.
2.2.4 分析方法
大学に所属する大学教員は100名を超えることから,全体の構造をデンドログラムで可視化するには適さない.そこで,Microsoft Power BI(PBI)を用いて分析インタフェースを作成する.PBIは対話型のデータ視覚化ソフトウェアであり,ノーコードのWebフレームワークとみなすこともできる.本稿では分割ツリービジュアルを用いてクラスタの階層構造を可視化する.
図2にデータのテーブルとリレーションシップを示す.教員テーブルには,階層的クラスタリングの各閾値において教員が所属するクラスタのIDが保持されている.Levelは閾値と同義であるが,Levelについては結果にて具体例を示す.クラスターテーブルは各クラスタのIDと,WordCloudのbase64形式画像を持つ.なお,理想的には単一のクラスターテーブルが教員テーブルの各Levelにおいてリレーションシップを持つことになるが,PBIの仕様と作成時間の削減のために,今回はクラスターテーブルをLevelのサイズ分だけ複製し,それぞれを教員テーブルと関連付けた.このモデルの下で,分割ツリーの分析対象を教員数に,分割対象にLevelやName,Affiliationを設定し,各クラスタの持つ情報を可視化する.
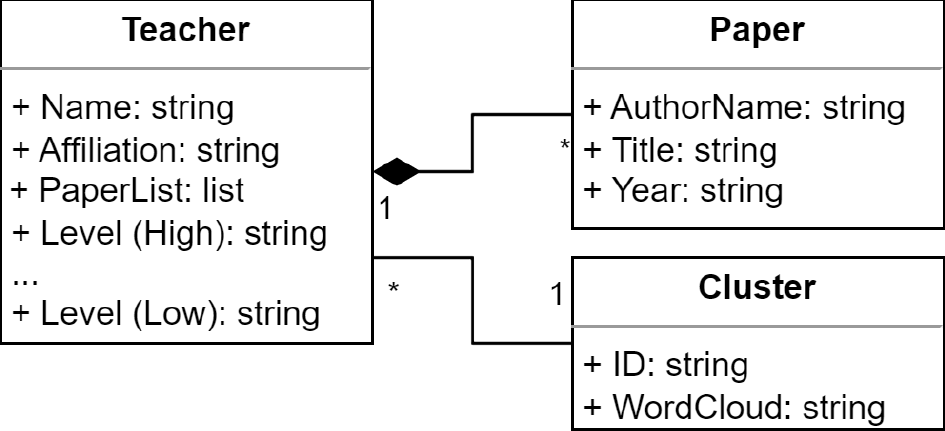
Fig. 2 Class diagram representing relationships for Power BI.
作成した分析インタフェースを図3に示す.図上部の分解ツリーがクラスタ結果であり,左端のノードが根となる.ツリー上部のLevelは分析者によって自由に設定できるが,今回は前章で述べた不純度の傾向によって設定する.ノードを選択するとPBIの機能で図下部の表も更新され,クラスタに属する教員が左下の表に,クラスタ内教員の業績タイトルが下中央に,各クラスタのWordCloudが右下に表示される.

Fig. 3 Example of analysis interface using Power BI's decomposition tree.
3. 結果
教員総覧から得られた教員数は名誉教授を含む635名,researchmapから得られた教員数は600名であった.ここから教員総覧を基にすることでresearchmapの所属誤登録者を除き,総覧に存在する称号欄を用いて名誉教授を除外し,さらに過去5年分の業績未登録者と名寄せに失敗した教員39名を除外したところ,466名の教員から業績クラスタが得られることとなった.
教員総覧の情報より,所属情報Kの要素として,農・教育・人文社会科学部,教育学研究科・理工学研究科(工学野)・理工学研究科(理学野),カーボンリサイクルエネルギー研究・社会連携・保健管理・研究設備共用・フロンティア応用原子科学研究センター,全学教育・地球–地域環境共創・情報戦略・研究・産学官連携機構,遺伝子実験施設,そして学長・副学長が所属する茨城大学の,計17件が得られた.
取得した業績タイトルの数は18,797件であった.また,式(11)が0.1未満でありgoogletransの翻訳対象となった業績は5,324件で,これに関する教員は417名であった.このうち,翻訳前と翻訳後が完全に一致した,つまり翻訳がされなかった業績タイトルの件数は2件であり,両方ともに1名の教員の業績であった.
教員をクラスタリングした結果,二分木のノードは葉を含め891件が得られた.この計測において得られた番号は,各クラスタのIDとして用いる.また,閾値を変化させてクラスタ数が変化する点を計測したところ,37点が得られた.この点は以降でLevelと呼称し,このLevelは抽象度を表すものとする.たとえばLevelが1のときは466件のクラスタ,つまり各教員にあたる葉ノードが得られる,一方で37とした場合,得られるクラスタは1件であり,このクラスタにはすべての教員が含まれる.
3.1 トップダウン検索
教員検索・論文検索の再現率を示し,業績クラスタを可視化して検索の結果を考察する
3.1.1 再現率
トップダウン検索について,ベースラインテストの$1 \le n$における再現率は100%となった.次に,論文タイトルから教員を検索した際の精度を図4に示す.単一データを検索する場合,つまりn=1を与えた場合の再現率は40%であった.nの増加により再現率は上昇するものの,90%に到達するのはnが300の場合であり,n<466の条件で100%となることはなかった.
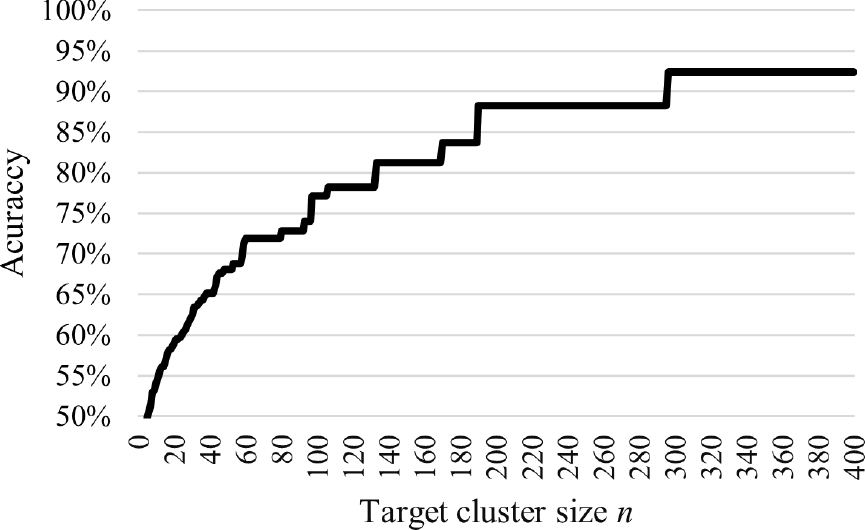
Fig. 4 Relationship between target cluster size and recall.
3.1.2 検索結果の考察
クラスタサイズを増加させても検索ができなかった教員の成果を概観した結果,学内で行われた共同研究の業績よりも筆頭で行った研究の業績が少ない場合,検索クラスタの数によらず発見できないことが明らかになった.このことから,業績における筆頭著者の検索は可能であるが,第2著者以降の教員の業績クラスタからその業績を発見することは困難である.以降で,教員の行う研究内容のばらつきと,共同研究者について考察を行う.
まずは,研究内容のばらつきについて述べる.今回は教員の特徴としてタイトル特徴の平均値を用いたが,分散は考慮していない.そのため,研究内容のばらつきが大きい教員については,外れ値にあたる研究の内容で当該教員を検索することができないと考えられる.このようなパターンは,共同研究者が複数存在する教員にみられる.たとえば,図5の教員業績は大きく3つのクラスタに分類できるが,この教員の特徴は業績数が最も多い第3クラスタに偏ると考えられる.ここで,これらの業績の筆者順を確認すると,1番上のクラスタで当該教員が筆頭著者のものは10件中1件のみで,その他はすべて第2著者であった.2番目のクラスタについても,筆頭著者となっていた業績は7件中1件のみであった.また,これら2つの業績クラスタの筆者には,それぞれ研究を主導していると思われる研究者が含まれていた.一方,3番目のクラスタは第2著者の業績が24件中3件で,それ以外はすべて筆頭著者であった.このことから,この教員が主となる業績は図の下部にある3番目のクラスタに存在し,上部の2クラスタは他大学の教員との共同研究によるものと推測できる.このように,教員の主研究以外の研究については,特に分野が大きく異なる場合,根付近での分岐の時点で探索に失敗している可能性が大きい.今回はresearchmapに共著者を登録していない教員もみられたため共著者の情報は分析から除外したが,実用においては共同研究者の情報を考慮する必要がある.

Fig. 5 Examples of faculty achievement clusters.
続いて,共同研究者が同一クラスタに存在した場合の影響について考察する.今回の方法論は,ある教員を検索する場合において,その教員と類似する研究を行う別の教員が同じクラスタ内に存在する場合,別の教員を検索結果として出力することがある.この状況はたとえば,図1において教員c2と教員c1が類似した研究を行っている,もしくは共同研究者である場合に発生する.この場合,式(5)によって計算されるc1とc2の間の距離が小さくなる.そこで,各教員について,その教員と最も類似するクラスタとの距離を算出し,再現率との関係を図6に可視化したところ,回帰直線の決定係数は0.3程度と,弱い相関関係がみられた.そのため,クラスタ内に存在する共同研究者群が精度低下の原因である可能性がある.
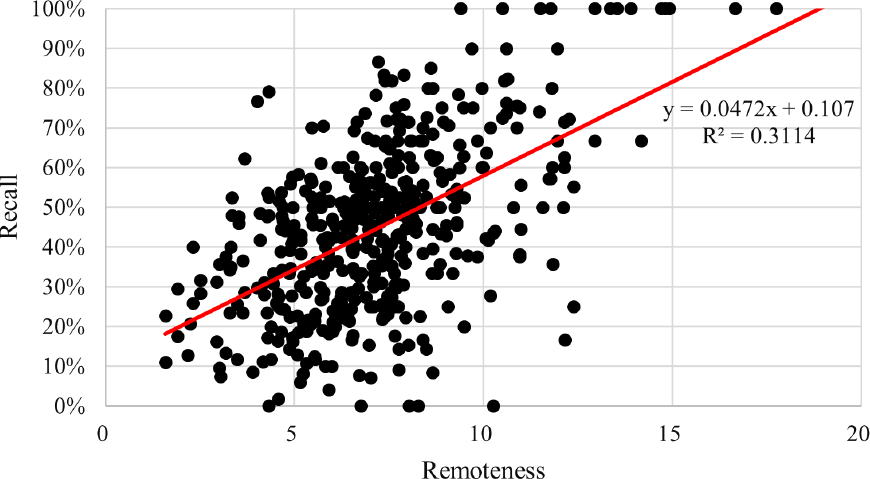
Fig. 6 Relationship between recall and minimum similarity among faculty members.
これらの結果から,共同研究者の把握が重要になることが分かった.筆頭著者の検索には成功する傾向がみられることから,タイトルの言語情報とは異なる観点から検索できる技術を構築し,それを本システムと組み合わせることで精度が向上する可能性がある.論文タイトルは唯一であることから,同一のタイトルを登録している研究者は共同研究者である可能性が高い.そのため,タイトルから共同研究者のネットワークを構築し,それに基づいて研究者を検索することにより,検索精度の向上が期待できる.
3.2 教員のクラスタリング
クラスタリング結果を示し,ジニ不純度を用いた定量的評価と,階層構造の可視化による定性的な考察について述べる.
3.2.1 クラスタ内の所属不純度
クラスタリングの精度として,クラスタ数とジニ不純度の関係を図7に示す.横軸の上段は閾値に応じたクラスタの数,下段はLevelを表す.黒の実線は各クラスタで求めた不純度の平均,エラーバーは不純度の標準偏差を表す.また,赤の点線は不純度曲線を微分した値である.閾値の減少に伴い,クラスタ数が増加すると分散は増加し,各クラスタのサイズは小さくなるため平均値は低下する.
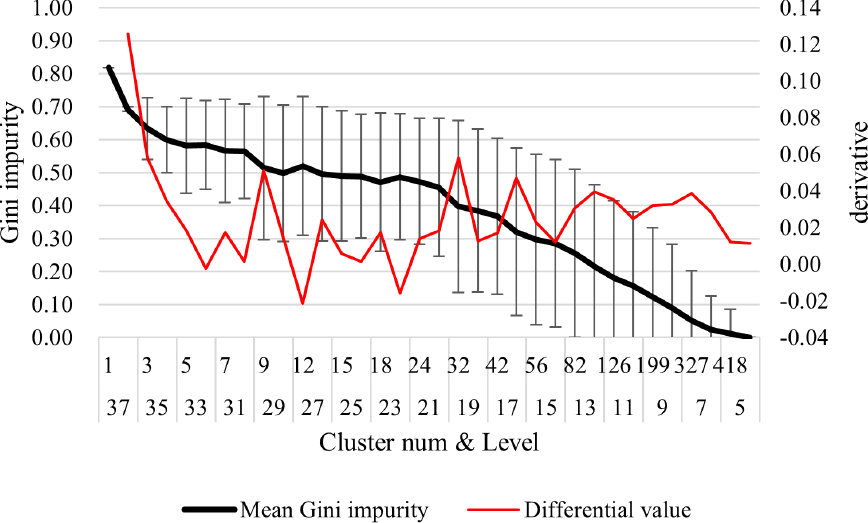
Fig. 7 Relationship among threshold, number of clusters, and Gini impurity.
3.2.2 クラスタリング結果の考察
クラスタリングの有効性について考察する.全体的に見ると,不純度は低いとは言えず,所属に基づいたクラスタリングとはなっていないことが推察される.以降では,その原因について定性的な評価を行う.
図7より,不純度はクラスタ数が9を超えた辺りで0.5まで低下し,24を超えると再度低下する傾向がみられる.茨城大学の定めた所属情報のサイズが17であることを踏まえると,その周辺のクラスタ数で不純度が安定すると考えられる.たとえば,クラスタ数12は図7の微分値よりジニ不純度の減少率が最も大きく,このときのLevelは27が対応する.このLevelでのクラスタのWordCloudは図8のとおりとなる.

Fig. 8 Twelve clusters and WordCloud.
クラスタの一部は人文社会科学や教育学に関する研究者のクラスタであり,もう一部は大まかに理工学分野に関する教員のクラスタであると解釈できる.人文社会科学・教育学のクラスタを図9に示す.ここで示す分解ツリーのLevel 36は,上のノードが理工学分野のクラスタであり,この図では下のノードにあたる人文社会科学・教育学のクラスタの詳細が表示されている.また,閾値を下げてLevel 27に設定すると,理工学分野はさらに生物学クラスタと理工学クラスタに分けることができる.これらを図11と図10に示す.本節では説明の都合上,これらのクラスタを文系・生物系・理工学系と名付け,それぞれ考察を行う.
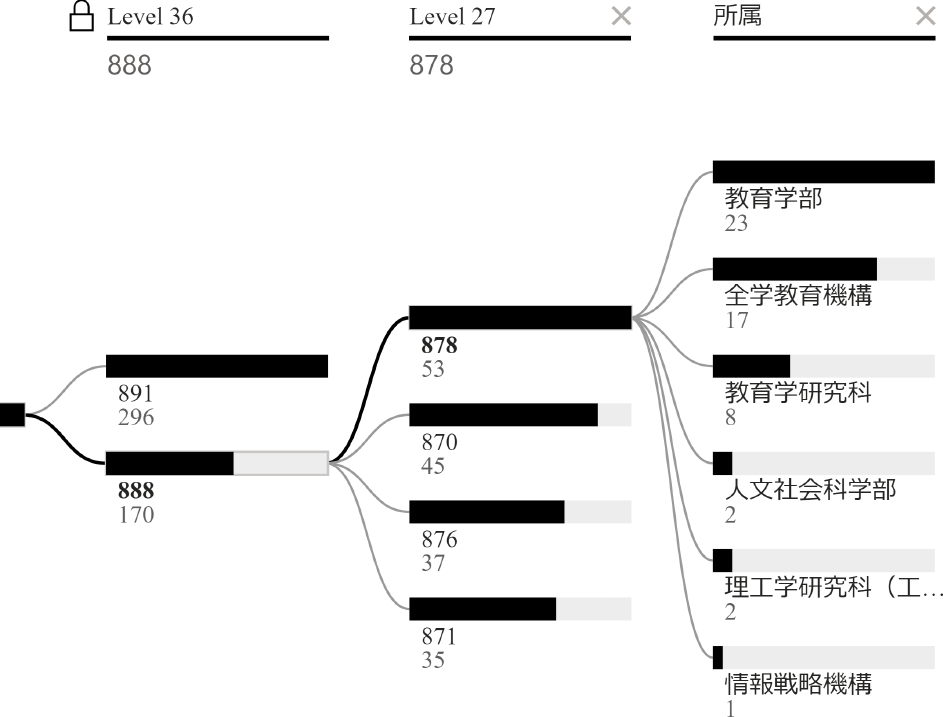
Fig. 9 Overview of impure cluster 878 under humanities cluster 888.
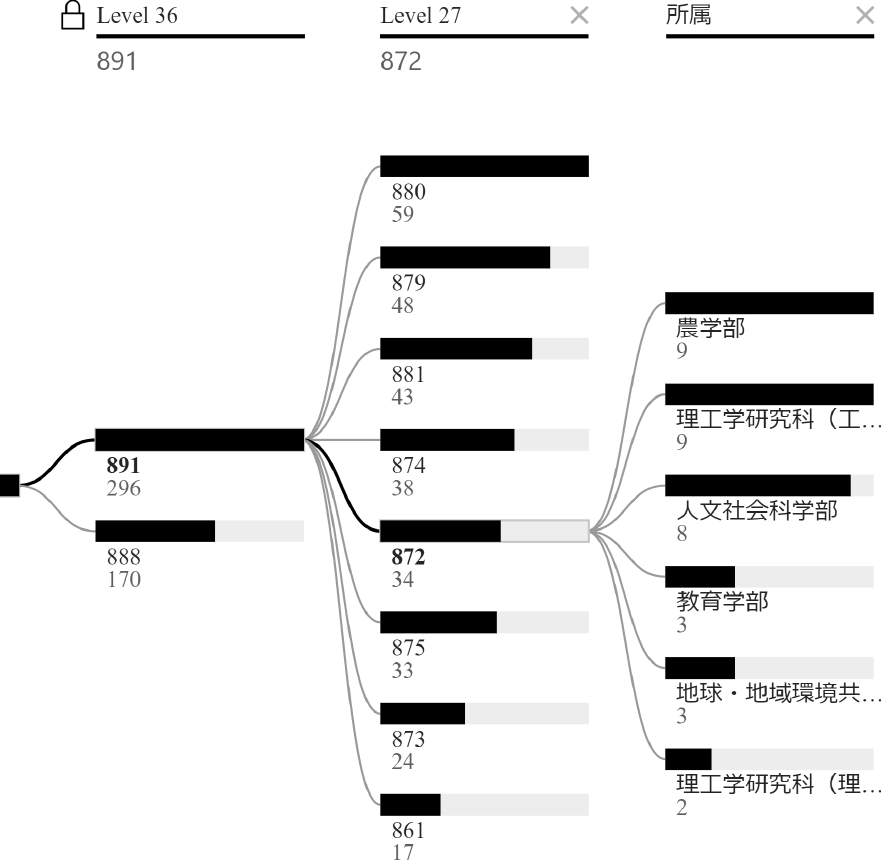
Fig. 10 Overview of impure cluster 872 under biology cluster 889.
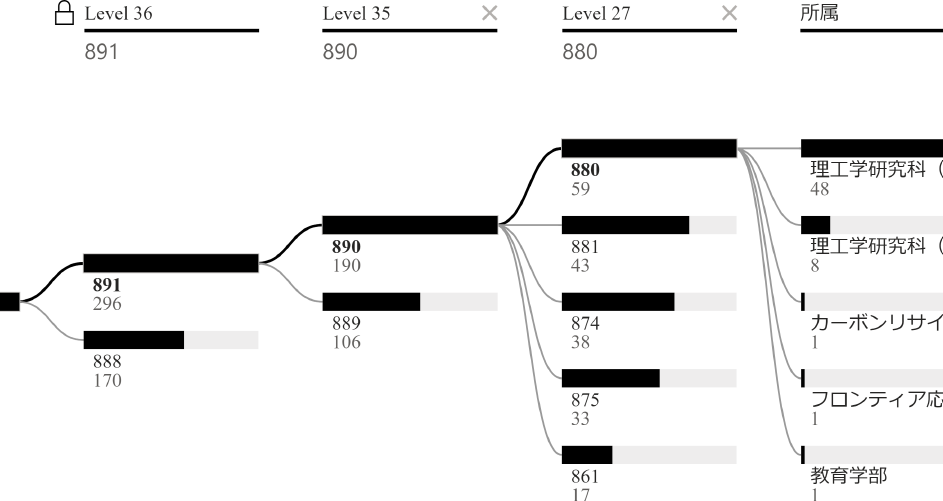
Fig. 11 Overview of impure cluster 880 under engineering cluster 890.
図9に示す文系クラスタについて述べる.876は言語学や音楽・史学に関する研究者が属していた.ただし,工学分野の言語処理研究者2名もこのクラスタに属していた.これは,SBERTが研究の本質ではなく業績のタイトルから特徴を抽出しているため,研究の根幹となる工学技術をとらえられなかったことが原因として挙げられる.870は政治経済学者が多く所属するクラスタであり,人文社会学部が7割,教育学部が2割を占める,教育学部教員の専門は食生活学や家政・福祉であり,これらに関するタイトルが政治経済と関連付いたと考えられる.878は文系クラスタでは最も不純度が高く,教育学部と全学教育機構の教員が主であった.クラスタに含まれる教員所属の件数は図9右の学科名の下に示してある.多くの教員が教育方法や教育技術に関する研究を行っていることから,本クラスタは教育工学に関するものと思われる.871も教育に関するクラスタであるが,こちらは878とは趣が異なり,心理学・用語教育と障碍・スポーツ科学の研究が多く含まれていた.教育方法ではなく教育の対象とその社会的環境に重きが置かれていたためか,教育工学クラスタ878よりも政治経済クラスタ870に近いクラスタとして扱われた.
図10に示す生物学クラスタについて述べる.クラスタ879は農学部の食生命科学に属する教員が多くを占めており,その他も多くが農学部であった.クラスタ872は図10に示すとおり様々な教員が含まれ,ジニ不純度が高い値を示した.ただし,人文科学者は考古学,教育学者は理科・地学教育,工学者は土木・都市・環境,農学は経済農業・地域研究など,地域に関するものであることが分かった.このように,研究の方法論は異なるものの,研究の目的が同一であるような研究は同一のクラスタに集約されやすく,このようなクラスタは分野横断型の教育において有益な知見を得られる可能性がある.クラスタ873も872に近いが,こちらは地球–地域環境共創機構の教員が多いという特徴がみられた.こちらは人文系心理・身体クラスタ871と同様に,研究対象が873よりも具体的であるという印象を受けた.
図11に示す理工学クラスタについて述べる.クラスタ874はほぼ理工学部教員で構成されており,化学や物質に関する教員が属する.このクラスタはさらに材料・生物・化学に分類できる.クラスタ880は機械システム・電気電子工学と物質科学工学者であった.一部他領域の教員が含まれていたが,本クラスタに含まれていた理学者の専門は多くが物生であり,機械工学者も応用化学が主であった.クラスタ875に属する研究者は所属は理学・工学・教育学など幅広く,これがジニ不純度を低下させる原因と考えられる.ただし,内容は代数学・解析学の基礎・応用に関する研究者であった.逆に,クラスタ861はほぼ機械システム工学領域に属する教員で構成されていた.クラスタ881は情報工学に関するクラスタであり,理工学研究科と情報戦略機構で構成されるが,一部人文社会科学者も存在した.
以上の結果から,本稿で検討した分析手順では,研究の対象を加味したクラスタリングが行われると考えられる.ここで示した手法により研究目的に基づいてクラスタリングすることで,分野横断研究や学科再編に関する知見が得られることが期待できる.ただし可視化に関しては,デンドログラムは教員数が増加すると視認性が低下するが,今回用いた分解ツリーなどは局所的かつトップダウンな探索しか行えないため,特定の教員や研究内容を探索するには不向きであることが分かった.そのため,探索を自動化するための検索技術の高精度化が必要である.
4. むすび
大学の所有する研究情報を可視化するために,教員の研究業績に付与されたタイトルから抽出した言語特徴に階層的クラスタリングを適用し,得られた構造を二分探索することによる教員のクラスタ検索機能を実装した.今後の課題として,他大学との比較やシラバスとの関連性の分析を行い,大学の独自性を視覚化可能なシステムを開発していく.
謝辞 本研究はJSPS科研費JP22K13761の助成を受けた.
参考文献
- [1] 赤倉貴子,川又泰介:ラーニング/eテスティングにおける顔画像を利用した個人認証,画像ラボ,Vol.27, No.10, pp.7–14(2016).
- [2] 関谷貴之,松田源立,山口和紀:LDAとIsomapを用いた計算機科学関連カリキュラムの分析,情報処理学会論文誌,Vol.54, No.1, pp.423–434(2013).
- [3] Nakamura, S. and Akakura, T.: Topic Analysis of Syllabus for Faculty of Engineering in the Japanese National University, Proc. IEEE International Conference on Teaching, Assessment, and Learning for Engineering, pp.325–328, DOI: 10.1109/TALE.2018.8615330 (2018).
- [4] 米谷雄介,東本崇仁,赤倉貴子:抽象性の高い教授スキルを具体的教授行動とするプロセス,2014年電子情報通信学会総合大会講演論文集(情報システム1),p.144(2014).
- [5] Kawamata, T., Matsuda, Y., Sekiya T. and Yamaguchi, K.: Analysis of Computer Science Textbooks by Topic Modeling and Dynamic Time Warping, Proc. IEEE International Conference on Teaching, Assessment, and Learning for Engineering, pp.865–870, DOI: 10.1109/TALE52509.2021.9678834 (2021).
- [6] 米谷雄介,東本崇仁,殿村貴司,古田壮宏,赤倉貴子:受講者による逐次評価と総括評価を教員の講義改善支援に利用する講義映像フィードバックシステム,日本教育工学会論文誌,Vol.37, No.4, p.479–490, DOI: 10.15077/jjet.KJ00009296331 (2014).
- [7] 塩野康徳,志村俊也:RoBERTaを用いた組織運用分析のためのファジィグラフによる関係性の可視化と比較,学術情報処理研究,Vol.27, No.1, pp.119–126, DOI: 10.24669/jacn.27.1_119 (2023).
- [8] Matsuda, Y., Sekiya, T. and Yamaguchi, K.: Curriculum analysis of computer science departments by simplified, supervised LDA, Journal of Information Processing, Vol.26, pp.497–508, DOI: 10.2197/ipsjjip.26.497(2018).
- [9] 山本一幸,大瀧保広,佐藤伸也,嶌田敏行,野口宏,羽渕裕真,外岡秀行:問合せデータの分散表現を用いた分類,学術情報処理研究,Vol.24, No.1, pp.68–77, DOI: 10.1109/FIE56618.2022.9962619(2020).
- [10] 岩山真,徳永健伸:確率的クラスタリングを用いた文書連想検索,自然言語処理,Vol.5, No.1, pp.101–117, DOI: 10.5715/jnlp.5.101(1998).
- [11] 河村光則,斉藤裕樹:行動要因情報源検索に基づく情報基盤Hierarchical cluster-based Pub/Subシステム,情報処理学会論文誌,Vol.60, No.8, pp.1370–1378(2019).
- [12] Salton, G., Wong, A. and Yang, C. S.: A Vector Space Model for Automatic Indexing, Communications of the ACM, Vol.18, No.11, pp.613–-620, (1975).
- [13] Blei, D. M., Ngand, A. Y. and Jordan, M. I.: Latent Dirichlet Allocation, Journal of Machine Learning Research, Vol.3, pp.993–1022, DOI: 10.1162/jmlr.2003.3.4-5.993 (2003).
- [14] Mikolov T., Chen K., Corrado G. and Dean J.: Efficient Estimation of Word Representations in Vector Space, Proc. International Conference on Learning Representations (ICLR), DOI: 10.48550/arXiv.1301.3781 (2013).
- [15] Devlin, J.Chang, M. Lee, K. and Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Proc. NAACL-HLT, pp.4171–4186 (2019).
- [16] Quoc, L. and Mikolov, T.: Distributed representations of sentences and documents, International conference on machine learning, pp.1188–1196 (2014).
- [17] Mekala, D., Gupta, V., Paranjape, B. and Karnick, H.: SCDV: Sparse Composite Document Vectors using soft clustering over distributional representations, Proc. the 2017 Conference on Empirical Methods in Natural Language Processing, pp.659–669, DOI: 10.18653/v1/D17-1069 (2017).
- [18] Reimers, N. and Gurevych, I.: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Proc. the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pp.3982–3992 (2019).
- [19] researchmap, 〈https://researchmap.jp/〉,科学技術振興機構(参照2024-01-10)
- [20] 粕谷 直:研究者総覧データベースresearchmapのこれまでとこれから,情報の科学と技術,Vol.71, No.5, pp.214–219(2021).
- [21] G. N. Lance and W. T. Williams: A general theory of classificatory sorting strategies, The Computer Journal, Vol.9, pp.373–380 (1967).
- [22] ekurerice:異体字正規化モジュール,〈https://pypi.org/project/ja-cvu-normalizer/〉(参照2024-01-10)
- [23] SuHun, H.: googletrans, 〈https://pypi.org/project/googletrans/〉(参照2024-01-10)
- [24] Sonobe, I.: sentence-bert-base-ja-mean-tokens-v2, hugging face, 〈https://huggingface.co/sonoisa/sentence-bert-base-ja-mean-tokens-v2〉(参照2024-01-10)

taisuke.kawamata.cw47@vc.ibaraki.ac.jp
1990年生.2015年東京理科大工学部二部経営工学科卒業.2017年同大学大学院修士課程修了.2020年同大学大学院博士後期課程修了.博士(工学).2020年成蹊大学助教.2023年茨城大学助教.オンライン学習の研究に従事.
採録日 2024年6月17日