Watsonの文章解析を用いた保全指示表作成システム
※本稿の著作権は,日本アイ・ビー・エム(株)に帰属します.
1.はじめに
IT技術の進化に伴い,近年デジタルトランスフォーメーション推進(DX推進)の取り組みが活発に行われている.経済産業省では,「デジタルトランスフォーメーションを推進するためのガイドライン」[1]が2018年に発行されており,DX推進の指針やポイントがまとめられている.
DX推進により,AI(人工知能)は企業活動のさまざまな場面で活用されるようになった.中でも,AIによる自然言語処理が注目されている.調査会社Market Research Futureが2023年8月に発表したレポートによると,世界の自然言語処理ビジネス市場は2022年の650億ドルから2030年には約3,577億ドル規模になると予想されている[2].自然言語処理とは,人間が日常的に使っている自然言語をコンピューターに処理させる技術である.自然言語処理はさまざまな分野に応用ができるため,市場規模が拡大している.自然言語処理を活用することで人間が行っていた業務を委任できるようになり,業務効率化や人件費削減等の効果が得られるためである.
本稿では,Watsonの文章解析機能を使い,保全業務における保全指示表作成システムの開発事例を報告する.
2.背景
2.1 化学業界の動向
化学産業は経済や雇用を語る上でも欠くことはできない産業といわれている[3]が,海外からの安価な汎用品の大量流入により,汎用品から高機能製品の生産へと転換している.化学産業でのAI活用というとマテリアルズ・インフォマティクスなどが取り上げられることが多いが,今回は高機能製品の生産を下支えするプラントの保全でのAI活用について言及する.
経済産業省では「スーパー認定事業者制度」が運用されている.「スーパー認定事業者制度」とは,多様化する災害,プラントの高経年化,熟練従業員の減少等に対応するため,IoT,ビッグデータの活用,高度なリスクアセスメント,第三者による保安力の評価の活用等の高度な保安の取り組みを行っている事業者を認定し,連続運転期間や検査方法などについてインセンティブが与えられる制度である.このような取り組みからも,保全の重要性や他の製造業と同様な人材不足が課題となっていることが伺える.
プラントの保全には,実施メンバーの経験やスキルが大きく影響する.石油精製プラントの高圧ガス事故をトレンドとして,ミドル層の不足が課題として顕在化した時期と重なっており[4],プラント保全を実施するメンバーのスキル・経験不足が原因と考えられている.しかし,スキル・経験はすぐに身につけることができないという課題が存在する.
2.2 プロジェクトの背景
本稿で事例として取り上げるお客様では,毎年設備起因のトラブルにより数十億円という損害が出ており,対応が急務とされている.設備起因のトラブルには,「保全計画の不備」「変更管理の不備」「工事品質の不具合」が考えられる.「変更管理の不具合」「工事品質の不具合」についてはすでに対応システムが導入され改善が行われている.しかし「保全計画の不備」についてはまだ対応が進んでいないという状況があった.
「保全計画の不備」とは具体的に,点検の時期の見誤り,優先点検個所の見誤り,潜在故障の見過ごし,懸案不具合の放置などがある.これらを防ぐためには,検査結果を正しく理解し,適切な保全指示ができるベテランの知識が必要となる.一方で,ベテランの退職による知識伝承,人材不足による業務範囲・業務量増加,情報リソースの分散化による見落としなどが顕在化している.
3.保全計画とは
3.1 保全計画の重要性
設備を安全かつ効果的に機能させるために保全計画は重要である.保全計画を策定するメリットとして以下があげられる.
- (1)事故発生の可能性を低減
適切な保全計画を策定し実施することにより,先手を打ちトラブルを予防することができる. - (2)ダウンタイムの回避
適切な保全が実施できず大きな障害が発生すると,対象設備を利用した業務を停止せざるを得なくなり,かつ修理などの対応が必要になるため,時間とお金を浪費することにつながる. - (3)作業者の負担軽減
予期しない故障やトラブル対応によるスケジュールの乱れや時間外労働が減少する.
3.2 保全計画作成プロセス
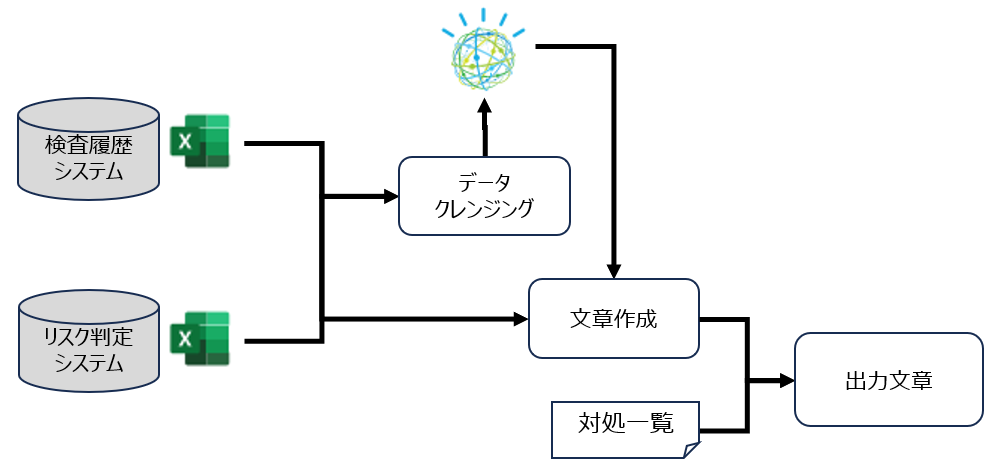
本稿で事例として取り上げるお客様での現状の保全計画作成プロセスについて説明する.まず,保全実施者がプラントの検査を行い,検査の履歴を複数のシステムに登録する.各システムの詳細については次の節で説明する.検査結果が登録された2つのシステムの情報をもとに保全指示表作成者が保全指示表を作成する.各システムからExcelファイルを出力し,記述内容を確認しながらどの部分に注意をして次回保全を実施する必要があるかを指示表として整理する.最後に保全計画策定者が,保全指示表をもとに保全計画を策定していくという流れとなる(図1).
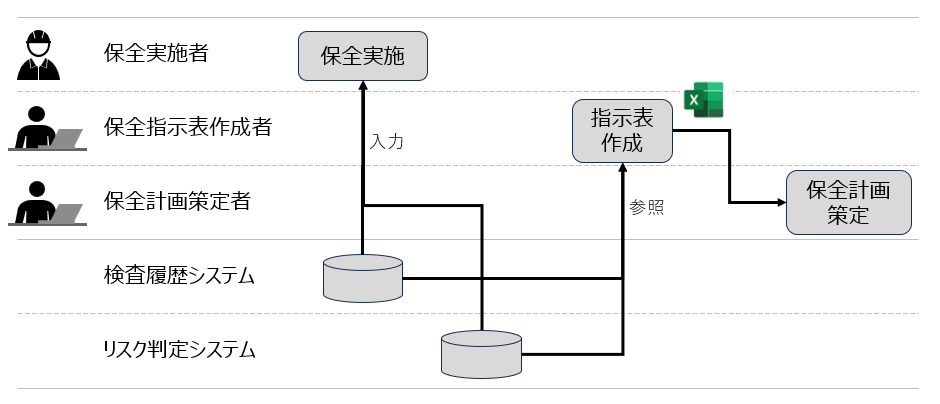
保全指示表はすべてのプラント・設備が対象となっているわけではなく,高負荷な設備などリスクが高い設備が対象となっている.本事例でのお客様では,保全指示表作成のプラントが100程度あり,1つのプラントの中で対象となる設備が20~50程度ある.この設備ごとに,保全計画策定プロセスに基づいて保全指示表を作成していくことになるが,このプロセスでの課題が2点ある.
- 保全に精通したベテラン人員の不足
知見を持った人が少なくなることで,保全指示表に適切な指示を記載することができなくなるため,属人化の解消と,保全指示表の品質担保が必要. - 保全指示表作成のための工数がかかる
設備の単位だと1,000を超える保全指示表の作成が必要となるため,効率性が求められる.
3.3 検査履歴システム
保全実施者が検査・対応した内容は検査履歴システムに自然文として記録される.年度ごとに,点検結果と処置という項目がある(図2).プラントが稼働し始めてからの情報が含まれているため,30年分以上の記録が残されている設備も存在する.

各設備の部位や劣化の種類(減肉or割れ)ごとにその内容に適した検査が実施され,必要に応じて処置が行われる.そのため,1つの設備でも検査すべき複数の部位があり,それぞれに劣化の可能性がある場合には,検査履歴システムに複数行の点検結果・処置の情報として記録されている.
図2のように,点検結果には,点検を実施した日,どの個所に対してどのような検査を実施したのかが記載されている.処置には,対応を実施した日,対応した内容と結果が記載されている.
3.4 リスク判定システム
リスク判定システムはプロセスの情報やプラントの設計・運転情報をもとにリスクを判定するシステムである.業務的な観点でのロジックが含まれたシステムであり,お客様が構築し長年運用されている.
保全実施者が点検の内容や点検した範囲を選択することで,該当の設備が今後何年後にリスクになるのかが出力される.そのリスクがある設備に対しては確実に対応が求められるため,抜け漏れなく保全を実施するため保全指示表を作成している.
4.Watsonサービス
IBM Watsonは,ビジネスでの活用に特化したAIサービスの製品群である[5].主に言語のやりとりが大量に発生する業務で活用されている.保全指示表作成システムを開発するにあたり,知識探索に用いられるWatson Knowledge StudioとWatson Natural Language Understandingを使用した.
4.1 Watson Knowledge Studioの概要
Watson Knowledge Studio(WKS)は,カスタム機械学習モデルを作成してトレーニングすることにより,Watsonに専門用語などドメインの言語を学習させる機能である[6].コーディングなしに業界知識から生成した機械学習モデルで,非構造テキストデータから洞察を得ることができる.「ヒューマン・アノテーション」と呼ばれる用語学習を行い,ユーザー固有の用語や言い回しを自動認識する機械学習モデルを構築する.Watson Natural Language Understandingとあわせて利用することにより,より精度の高いエンリッチを実現することが可能となる.
4.2 Watson Natural Language Understandingの概要
Watson Natural Language Understanding(NLU)とは,自然言語理解を使用してテキストを分析し,概念,エンティティー,キーワード,区分,評判,感情,関係,意味役割などのメタデータをコンテンツから抽出する機能である[7].本システムではWKSで業界知識を学習させたモデルを使い,文章構造把握のためにエンティティー,リレーションの抽出機能を用いた.
4.3 Watson Knowledge Studioへの設定と学習
本節では,WKSへの具体的な設定・学習内容を述べる.保全実施者が記載した文章の意味を正しく把握することができるようにWKSの学習方法で工夫を加えた.
4.3.1 エンティティー
エンティティーとは人,組織,場所など特定の性質をもった単語,ないしは複数単語の連なりを意味する.ユーザー固有の言葉をWKSの辞書や機械学習を用いて学習させることで,検査履歴内に書かれた重要な単語を識別することができる.NLUのモデルでは一般的な単語はデフォルトでエンティティーに登録されており,自動でアノテーションすることができる.しかし,業務特有の言葉の入った文章を理解するためには,WKSで新しく定義を行い,モデルを構築する必要がある.
本システムでは点検や処置の内容を把握できるように,単語をグループ分けし,「部位」,「範囲」,「劣化状態」,「結果」,「補修内容」,「測定項目」,「測定値」の7つのエンティティーを設定し,識別できるようにした.各エンティティーは図3のように,WKSにインプットした検査履歴の文章に対し単語ごとにアノテーションをして学習させた.

業務の単語が含まれた複数の文章に対して,どの単語がどのエンティティーなのかを学習させることで,文章に対して適切なエンティティーを自動でアノテーションできるようになった.
4.3.2 サブタイプ
エンティティーにはサブタイプとよばれる属性を設定することができる.サブタイプは同じエンティティーグループの中で単語を区別するために活用される.
本システムでは,「部位」「範囲」「劣化状態」「補修内容」「測定項目」「結果」に対しサブタイプを設定した.たとえば,検査履歴には “検出した”や“検出せず”という言葉が含まれる.エンティティーの分類では「結果」として判定されるが,その単語が点検した結果,合格なのか不合格なのかがエンティティーだけでは判別できない.そこで,サブタイプに「OK」「NG」など属性を割り当てることで,検査履歴の意味が分かるようになる.エンティティーとサブタイプはそれぞれ表1のように設定をした.
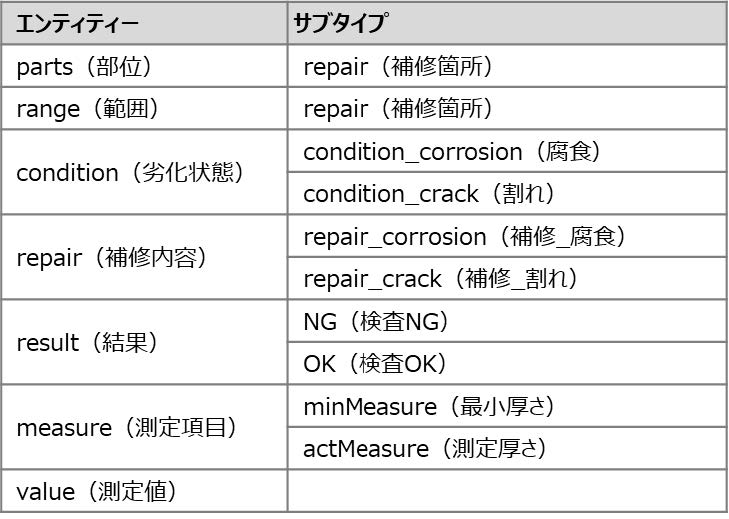
エンティティーとサブタイプの組合せを工夫することで,検査履歴に記載された文章から必要な情報を抽出することができるようになった.
4.3.3 リレーション
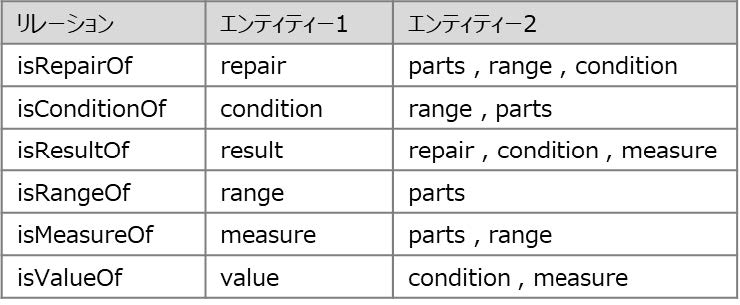
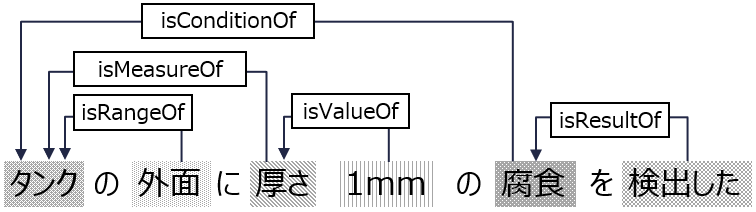
リレーションは,同じ文章中にある2つの異なるエンティティーの関係タイプを識別する.リレーションを設定することにより,取得した各エンティティー間の意味が分かるようになる.これにより,「結果」のエンティティーから「劣化状態」,「劣化状態」から「部位」のように,各エンティティーを辿って情報を参照している.たとえば,エンティティーの「結果」と「劣化状態」に対し「isResultOf」というリレーションを設定した場合,“劣化状態の結果は~”という意味合いの関係性が分かる.設定したリレーションは表2に示す.リレーションは図4のように,エンティティー間でアノテーションをして学習させた.
5.保全指示表作成システムの機能
保全指示表作成システムは,過去の点検・検査状況をもとに対応方法や注意点を記載した資料を自動で出力するためのシステムである.
WKSで過去の検査履歴を学習済みのモデルを使用し,新たな検査履歴に対してNLUで必要な情報を抽出する.
保全指示表作成システムは「検査履歴システム」と「リスク判定システム」から出力したExcelデータをアップロード,画面上よりバッチを実行することで文章を自動生成し,出力することができる.読み込まれたデータに対してNLUを実行し学習済みモデルでエンティティーやリレーションの情報を取得する.NLUは実行数が費用に効いてくるので,費用削減と実行時間削減のため事前にデータクレンジングを行い,文章作成に必要な履歴のみをNLUで実行する工夫を入れている.
また,お客様の知見として「部位」や「劣化状態」によって推奨される検査・処置する方法が整理されている.その内容は保全指示表に表示するべき内容であったため,「部位」や「劣化状態」の組合せごとに対処一覧として文章を事前に定義し,自動で作成する文章と連結させることで最終的な文章を出力させることとした(図5).
画面はシステムへのログインやユーザー権限の管理,ファイル出力など基本的な機能があるが以下では,主な機能であるバッチ実行,文章確認・変更機能について説明する.
5.1 バッチ実行機能
バッチは「検査履歴システム」と「リスク判定システム」で出力したExcelデータをインプットとして出力文章を作成する機能である.
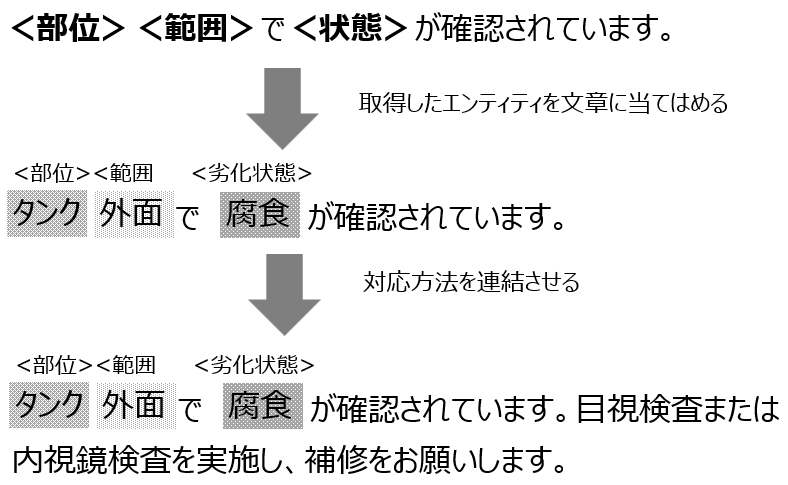
Excelの情報に加えてNLUで出力された情報を用いてPythonで組んだロジックによって文章を作成する.ロジックは,業務観点から文章のテンプレートを作成し,取得したエンティティー,リレーションをもとに分類されるような“分類フロー”を定義した.文章のテンプレートは想定される「劣化状態」を元に数十種類定義した.リスク判定システムとエンティティーの情報から分類フローによって,適用させるテンプレートが定まる.判別後,図6のように定義文章に取得したエンティティーを当てはめ文章を作成する.最後に該当する「部位」や「劣化状態」を元に対処一覧から,対応内容を連結させ,文章を完成させる.バッチは1プラントあたり数分で実行が完了する.
5.2 文章確認・変更機能
文章確認機能は,バッチ実行後に自動生成された文章を人の目で確認できる機能である.学習モデルから想定と異なる文章が生成されていないかを確認することができる.出力文章の精度は取得したエンティティー,リレーションのスコアをもとにA,B,Cで評価できるようにした.これにより,精度の低いものから生成文章を確認することができるため,効率よく確認作業をすることができる.また,文章確認画面では,生成された文章に関連する検査履歴システムとリスク判定システムの情報が参照できるようになっている.従来は各システムから検査履歴を手作業で探す必要があったがシステム側で表示されることによって確認が容易になった.
確認した文章に不備がある場合には,ユーザーが文章を変更できる.上記の参照機能と合わせて同じシステム上で確認・変更ができるようになった.さらに,システムで出力した文章とユーザーが変更した文章を比較した履歴も参照できるようになっており,どのユーザーがどのように文章を変更したのかも分かるようになっている.
6.導入効果
本事例において,当初お客様は複数のシステムを参照しながら,手作業で保全指示表を作成していた.
本事例で開発した保全指示表作成システムは1プラントあたり数分で文章が自動作成される.1プラントの中には保全指示を記載すべき設備が20~50程度ある.さらに,中身の確認や一部修正する個所は全体の1割程度に抑えられており,残りの9割はシステムで出力されたものをそのまま活用できるような精度で出力がされている.本システムによって,ベテラン担当者と同等の精度で保全指示表を作成できるようになり,保全指示表の品質担保ができるようになった.
また,現在保全指示表作成システムの対象プラントは100程度あるため,精度の高い文書を作成するだけでなく,保全指示表を作成するための工数を大きく削減することが可能となった.
7.おわりに
本稿では,化学業界のプラント保全におけるWatsonの文章解析を活用した保全指示表システムの事例を紹介した.NLUに対し業界固有の言葉を学習させたWKSモデルを連携させることで,検査履歴のような独特の言い回しを持つ文章に対しても精度の高い文章解析が可能となった.これにより,膨大な検査履歴情報をシステムによって一括解析し,網羅的に履歴をチェックすることで誰でも適切な保全指示表の作成ができるようになった.作成には1プラントあたり数分で実行ができるため,システム化によってお客様が抱える「保全計画の不備」の課題に対応ができるだけでなく,保全指示表作成に際する工数の大幅な削減が可能となった.
現状,システムでは修正した文章をモデルに反映する仕組みがないため,手動で間違ったアノテーションのモデル更新をする必要がある点が課題となっている.システムから修正した文章をWKSへ自動学習できるよう対応できれば,システムの利便性はさらに向上すると考える.
今後はWKSモデルの自動更新による精度向上,各種保全システムとの連携によるさらなる効率化や,いまだ保全指示表を作成していない工場へシステム導入し,保全計画の不備による設備起因トラブルを削減していく予定である.
本稿の執筆にあたり,数多くのご助言をいただいた日本アイ・ビー・エム・デジタルサービス(株)デジタル事業部の吉原泰弘さんに深く感謝いたします.
参考文献
- 1)経済産業省:デジタルトランスフォーメーションを推進するためのガイドライン(DX推進ガイドライン),https://warp.da.ndl.go.jp/info:ndljp/pid/12109574/www.meti.go.jp/press/2018/12/20181212004/20181212004-1.pdf,2018年12月,(2023.8.31アクセス)
- 2)Natural Language Processing (NLP) Market Overview:https://www.marketresearchfuture.com/reports/natural-language-processing-market-1288(2023.8.31アクセス)
- 3)経済産業省:化学産業の現状と課題,https://www.meti.go.jp/shingikai/sankoshin/seizo_sangyo/pdf/010_04_00.pdf,2021年12月,(2023.8.31アクセス)
- 4)経済産業省:保安力の維持・向上を目的とする基礎調査,https://www.meti.go.jp/meti_lib/report/H30FY/000284.pdf,2019年3月,(2023.8.31アクセス)
- 5)日本IBM:IBM Watson,https://www.ibm.com/jp-ja/watson(2023.9.4アクセス)
- 6)日本IBM:IBM Watson Knowledge Studio,https://www.ibm.com/jp-ja/cloud/watson-knowledge-studio/details(2023.9.4アクセス)
- 7)日本IBM:IBM Watson Natural Language Understanding,https://www.ibm.com/jp-ja/cloud/watson-natural-language-understanding(2023.9.4アクセス)

伊集院絵里香
ERIJU@jp.ibm.com
2017年東京学芸大学教育学部情報教育課程修了,同年,現日本アイ・ビー・エムデジタルサービス(株)入社,製造業におけるWatsonやSPSSを活用したソリューション開発業務に従事.

丹正淳文
BI912056@jp.ibm.com
2011年岡山大学大学院環境学研究科博士前期課程修了,同年,現日本アイ・ビー・エムデジタルサービス(株)入社,半導体製造実行システム(IBM SiView Standard)開発を経て,製造業における分析技術検証やWatsonやSPSSを活用したソリューション開発業務に従事.
採録決定:2024年6月25日
編集担当:斎藤彰宏(日本アイ・ビー・エム(株))