機械学習を用いた退学予測に基づくエンロールメントマネジメントシステムの構築
Development of an Enrollment Management System Based on Dropout Prediction Using Machine Learning
1. はじめに
AIの根幹を成す技術として機械学習があるが,その中でも代表的な“教師あり学習”では,ある事象が将来起こる可能性を予測できるなどといった強みを持つ[1], [2].この技術は現在多方面で注目されているが,大学生の在学中の諸活動をデータ化し,それらを分析し評価するIR(Institutional Research)の分野や,個々の学生の入学から卒業までの修学指導を行うエンロールメントマネジメント(Enrollment Management:以下EM)の分野での活用事例はまだ少ない[3], [4].
日々,大学生の修学指導を行っている多くの大学教員,職員は,学生との関係性の中で,「この学生はこのままの状態が続くと退学する」,「現在はこうだが後半立ち直る可能性があるので様子を見よう」など,“経験則”や“独自のカン”で学生を指導している.この“経験則”や“独自のカン”は,時として見誤ることや見当違いの判断を下すことはあるものの,往々にして正解に至る例が多く,これらは長い教師歴,職員歴によって得られる1つの武器とも言えるものである.しかしながら,それらの“経験則”や“独自のカン”を,他の教員や職員へ引き継ぐことは,実は簡単ではない.
一般に,こうした経験やカンと言った暗黙知を形式知へ転換させることは,経営学の分野では一大テーマともなっており[5],大学での学生の修学指導の現場においてもそのまま当てはまる難しい課題である.そこで,暗黙知を形式知に転換する1つの手段として機械学習を用い,それらを誰もが利用できるシステムとして構築し実用化できれば,学生の修学指導の強力なツールとなり得るのではないかと思われる.
2. 本実践研究の背景と目的
白川らが文部科学省の委託を受けて,全国の国公私立四年制大学・短期大学を対象に,2016年に中途退学等の実態を調査した報告によれば,中途退学率は全国平均で2.12%とあり,さらに昼間部私立大学四年制に限っては2.88%と国公立大学(約1.2%)に比べ2倍以上となっている[6].筆者が勤務する大学(私立大学四年制,以下 自大学)においても,退学率は,ここ数年4%前後とさらに高止まりの状態にあり,一向に減少する気配がない[7].
自大学のある学科では1年次終了時点での取得単位数を基準に対象学生を抽出し面談指導を行ったり,また別な学科では,全学生を対象とするなど,退学防止を目的とした面談指導に多くの時間を費やしている.しかしながら,対象者以外でも退学や除籍に至る例が散見され,退学に至る単位数以外の要因を明らかにして早急に対策を行うべき,との要望が多く出されるといった現状にある.このように退学率が高い大学では,中途退学が重要な課題となっており,退学防止を目的とした取り組みが各大学で行われている.
この退学防止の取り組みの一環として,統計的手法で退学要因を導き出したり[8],学力進捗性の予測を行う[9], [10]など,機械学習を用いたアプローチが近年みられるようになった.ほかにも,個別学生ではなく組織全体に対する中退問題を類型化するために機械学習を活用している報告もなされている[11].しかし,学内での具体的な指導を見据え,それに向けた予測モデルの構築や,実用に則したインタフェースの実装等のアプローチを取っている研究はまだみられない.
そこで筆者らは,1年次終了時の修学指導での利用を見据える形で,学生の様々なデータに基づいて退学に至る確率を予測する仕組みを機械学習によって実現し,現場の教職員が利用することができるEMシステムを構築することを本実践研究の目的として定め,アプローチを開始した.
目的の実現のために次の2つのステップを設定する.
- 1) 予測モデルの構築
- 2) EMシステムのプロトタイプの構築
この2つのステップの具体的な内容については,次章以降で述べる.
3. 予測モデルの構築
本章では,学生の退学予測モデルを構築するプロセスについて述べた後,予測モデルの解釈可能性を利用して,学生の退学につながる要因について考察する.以下の流れで行う.
- (1) データの収集
- (2) モデル構築と評価
- (3) モデルを用いた解釈
(1) データの収集
機械学習の適用にあたって,目的変数と説明変数を定義する.学生が退学に至る確率を予測することから,目的変数は,「卒業」と「退学」の二値で表される学生の在籍状況とするのが適切である.退学には自主退学と除籍処分による退学があるが,これらは集約して考える.実際には休学などの在籍状況も存在し,これには学業不振で修学を続けられないなどの理由もあるが,留学などの理由も相当数あるので,今回は除外して考える.
説明変数としては,学生の在籍状況に影響を与えると考えられるもののうち,1年次終了時点で記録され得られるものを選択する.高校時代の専攻分野や学力等が大学での成績,ひいては在籍状態に関係している可能性があることから,高校学科,高校課程,高校評定平均,高校偏差値,入試種別を説明変数として使用する.大学1年次の成績は在籍状況に大きな影響を与えると推察されることから,1年次GPA,1年次単位数に加え,ほとんどの学生が履修している科目である英語,論述作文,コンピュータ基礎の評定も使用する.また,大学での人間関係という観点から,課外活動に関する変数も追加する.それらに,属性情報である性別を加えた計18個を説明変数として用いる(表1).
Table 1 Property of data.
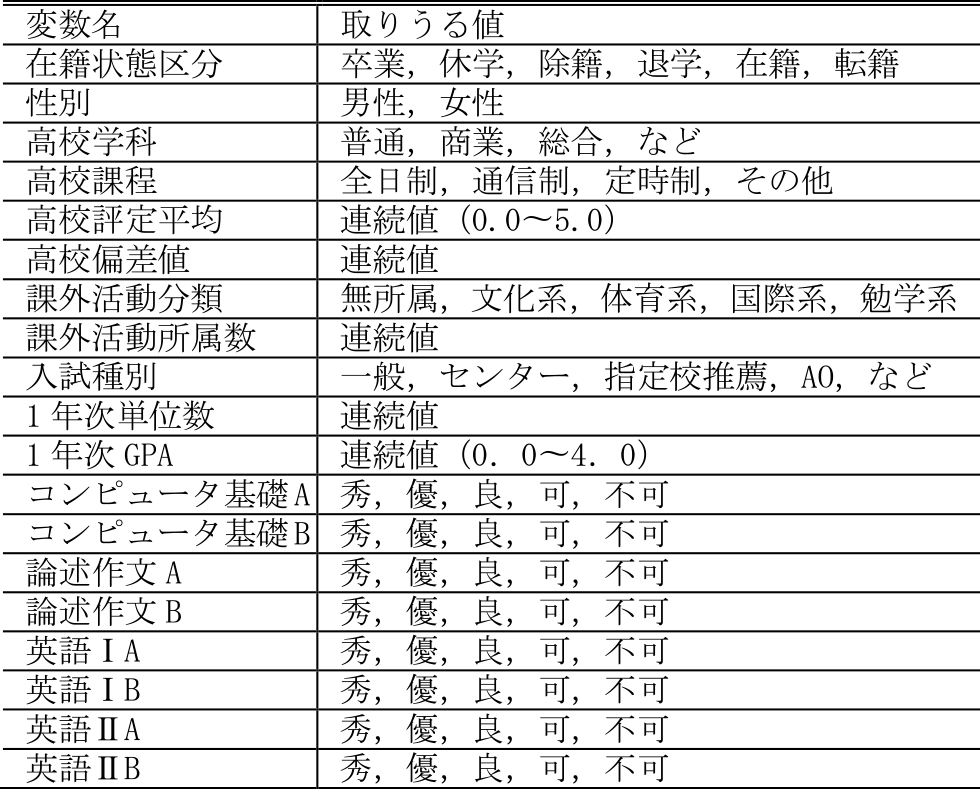
2011年度から2017年度に入学し,1年次終了時点で在籍している学生を対象に,以上に示したデータを収集する.使用したデータはすべてIR活動で取得した既存データであり,個人を特定できないようにハッシュ化された学籍番号で突合されている.
(2) モデル構築と評価
学生の退学確率を高い精度で予測可能な分類モデルを構築する.二値分類のアルゴリズムとして,複数の手法を比較した結果,以下で述べる評価指標に基づいて最も高い予測精度を示したLightGBMを採用する[12].
LightGBMは2016年にMicrosoft社によって開発された手法であり,決定木を基にした予測アルゴリズムである勾配ブースティングの一種である.決定木とは,「GPAが2より大きいか」,「英語の成績が良より上か」など,単純な識別規則を組み合わせてフローチャートのような構造を作り,退学確率などの予測値を算出する手法である.勾配ブースティングでは,この決定木を大量に構築し,前の決定木の結果を次の決定木の構築に反映させるというように,複数の出力を組み合わせることで予測を行う.具体的には,以下の手順で行う.
- 1) 最初の決定木を作成して,予測値を算出する.
- 2) 目的変数と,それまでに作成した決定木による予測値の誤差を最小化するように,新たな決定木を作成する.
- 3) あらかじめ指定した数だけ2)を繰り返す.
- 4) 予測対象のデータがそれぞれの決定木で属する葉のウェイトの和を予測値とする.
勾配ブースティングには,欠損値をそのまま扱うことができる,変数間の交互作用を反映可能,特徴量のスケーリングが必要でない,などの特徴がある.LightGBMでは,大規模なデータセットに対しても高速で学習を行うことができるような工夫が施されている.一般的な勾配ブースティングの手法では,決定木を階層ごとに分岐させるのに対して,LightGBMではジニ不純度(Gini Importance)に基づいて,葉単位で誤差を最小化させるような分岐を行う.また,分岐点をすべて探索するのではなく,ヒストグラムを用いて一定のまとまり単位で分岐させることで,計算量の削減を実現する[13].
次に予測モデルの評価に用いる指標について検討する.予測値と実測値における「正解率」が最も分かりやすい指標であるが,今回のような退学者に比べて卒業者の多い不均衡データの場合,仮にすべての学生を「卒業する」と予測しても正解率は非常に高くなり,評価としては適切ではない.そのため本節では,AUC(Area Under the ROC Curve)を利用する.AUCでは,予測値を正例と判断する閾値を1から0に動かすなかで,偽陽性率(卒業者を誤って退学者と予測する割合)と真陽性率(退学者を正しく退学者と予測する割合)の関係を図示するROC曲線(Receiver Operating Characteristic Curve)(図1参照)における,曲線の下部の面積を用いる.0から1までの値を取り,1に近いほど判別能が高いことを示す.完全にランダムな予測をした場合には,0.5となる.
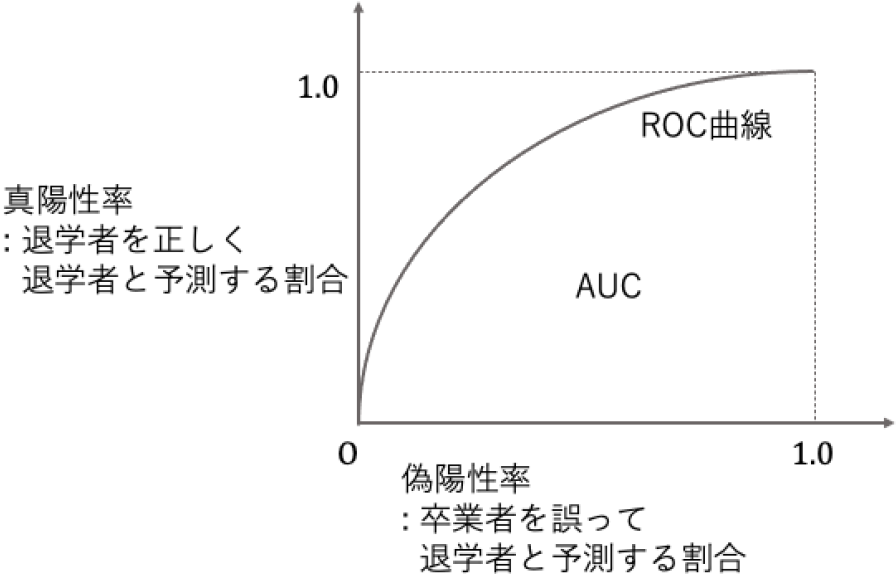
Fig. 1 ROC curve and AUC.
モデルの学習に先立ち,適切な前処理を施す.目的変数の在籍状況に関して,退学と除籍を正例,卒業を負例とした二値変数に変換する.GPAや単位数など,連続値を取る変数はそのままの形式で用いることができるが,性別,高校学科,高校課程,課外活動分類,入試種別といったカテゴリ変数においては,変換をする必要がある.決定木系のモデルで有効とされているLabel Encoding [13]を行い,連続値に変換して用いる.科目ごとの評定は,不可,可,良,優,秀の順に,0~4の連続値に変換する.以上により,モデル構築に使用するデータのサンプルサイズは2,848人,うち正例(退学者)が374人,負例(卒業者)が2,474人,という内訳になった.
続いて,LightGBMによる学習を行い,5-foldの交差検証法によって評価を行う.まず,データのうち,80%を訓練データ,20%をテストデータとし,訓練データを用いて学習を行ったモデルに対して,テストデータにおけるAUCを算出する.さらに,図2に示すような形で訓練データとテストデータの分け方を変更し,同様の方法でAUCを算出する.このようにして得られた5回分の評価指標の平均値をモデルの予測精度とする.
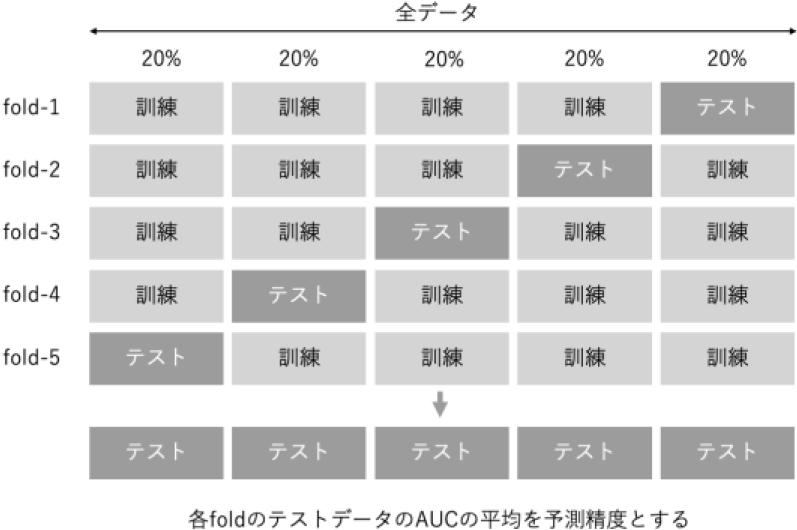
Fig. 2 Image of cross validation.
構築したモデルのAUCは0.870であり,十分な判別能があるといえる.この交差検証では,Apple M1チップ,メモリ16 GBのMacBook Airにて,5分程度の実行時間を要した.実装にあたっては,LightGBMにおける専用のライブラリ[14]を使用している.
(3) モデルを用いた解釈
LightGBMを用いて予測を行った場合,特徴量重要度(Feature Importance)の算出が可能であり,これによって,どのような変数が退学者の予測に寄与しているのか,確認することができる.各変数の値を閾値として決定木の分割を定義した際のジニ不純度の減少度合いによって,重要度を算出している.
得られた特徴量重要度(図3)によると,1年次で取得した単位数,1年次のGPAの順で,予測への寄与度が大きいことが読み取れる.この2つの変数が退学確率に影響することは,“暗黙知”とも一致するほか,卒業者と退学者の評定分布を比較しても明らかである(図4,図5).
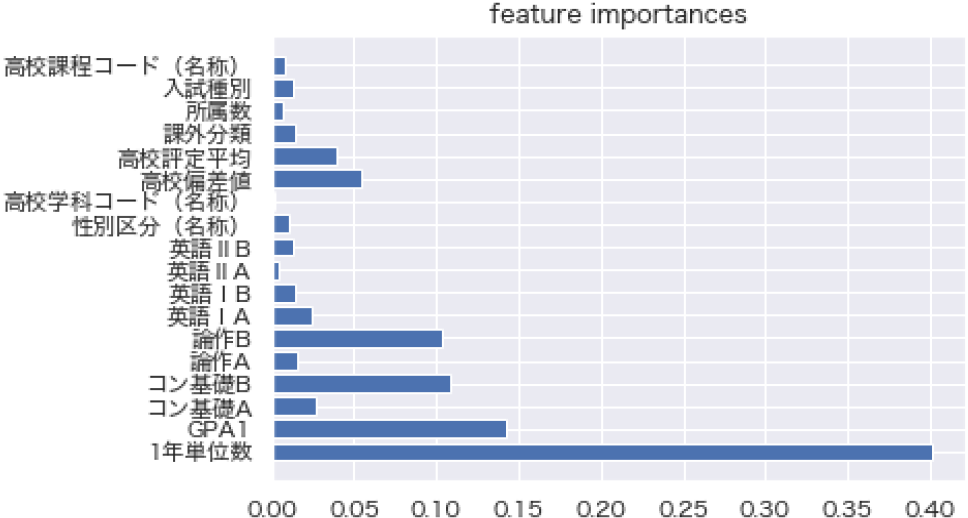
Fig. 3 Feature importances.
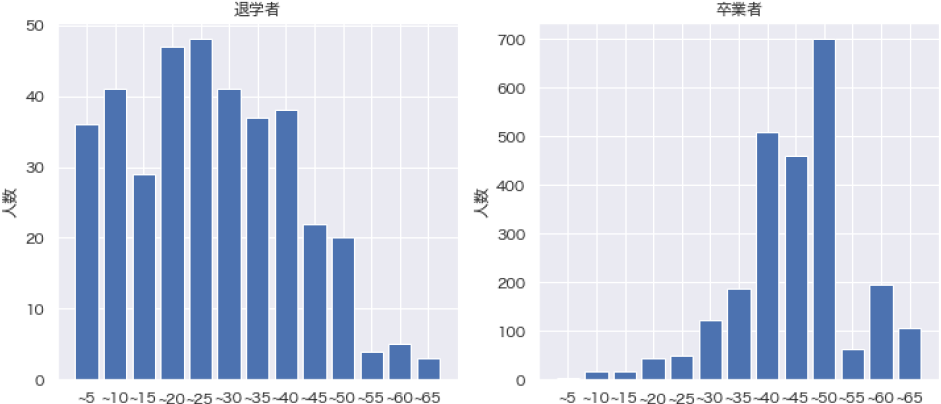
Fig. 4 Credits earned in first year by dropout and graduate.
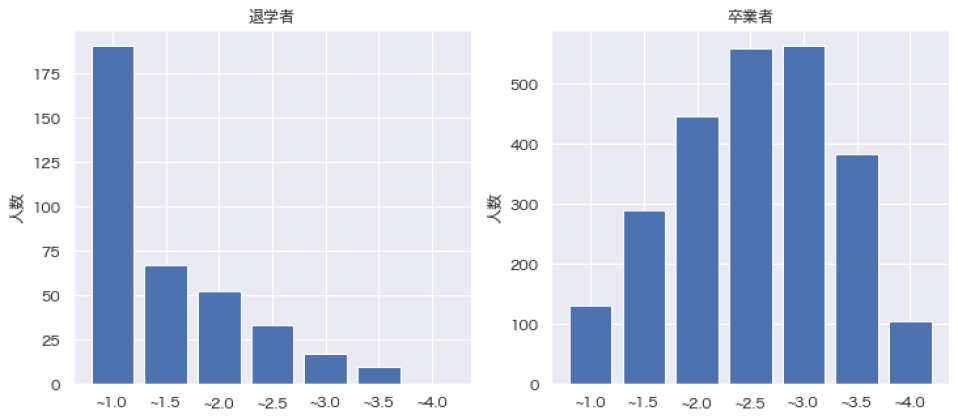
Fig. 5 GPA in first year by dropout and graduate.
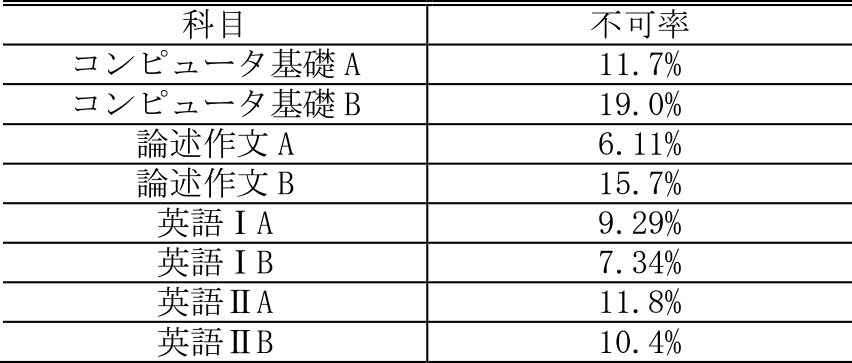
続いて,コンピュータ基礎B,論述作文Bの評定が重要視されている.両者とも1年次後期に開講される講義であり,1年次終了時直近の学生の状態を表していることが,前期に開講されるコンピュータ基礎A,論述作文Aに比べて重要度が高く出ている要因だと考えられる.卒業者と退学者の,これらの科目における評定分布からも,大きな違いが観察される(図6,7).また,他の必修科目と比較しても,この2科目は不可率が高い傾向にあり(表2),これらの単位の取得有無が退学と卒業を決定付ける重要な分かれ道になっている.
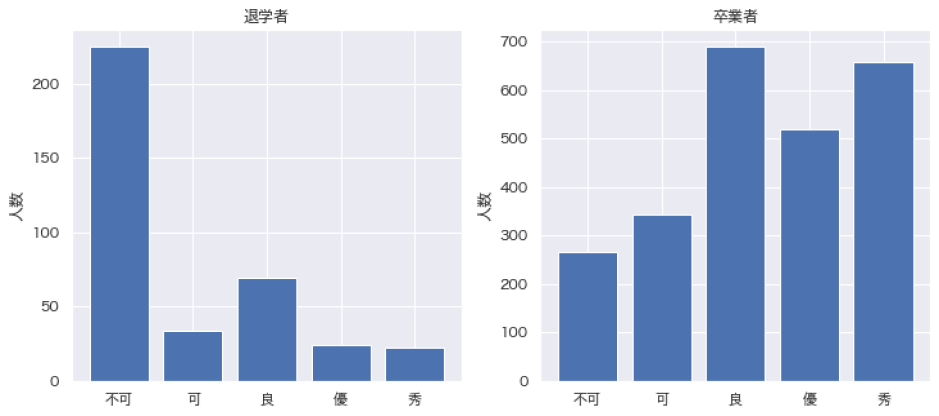
Fig. 6 Grade distribution for computer basics B by dropout and graduate.
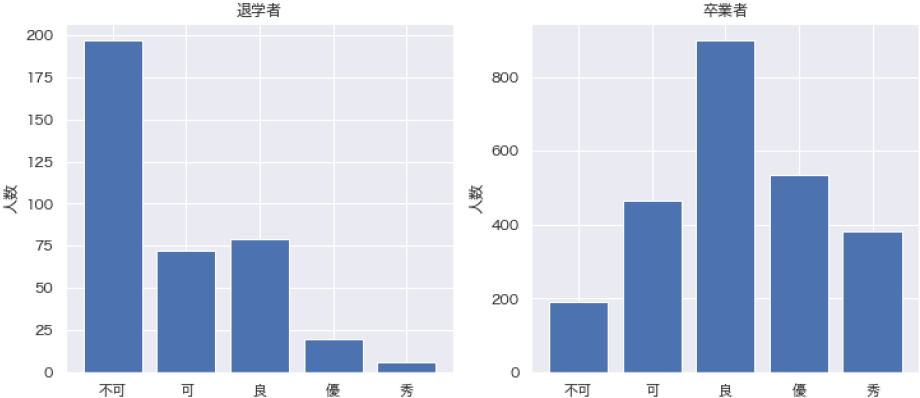
Fig. 7 Grade distribution for thesis statement B by dropout and graduate.
Table 2 Subjects and rate of D grade.
次章で取り上げるプロトタイプシステムの構築を見据え,利用者である教職員の入力負荷を低減させる目的から,予測にあまり影響を与えなかった変数である,高校課程,高校学科,入試種別,課外活動の所属数,課外活動の分類,性別の情報は,以後説明変数から除外する.
4. プロトタイプシステムの構築
構築した予測モデルを,実際の学生のサポートに使用するEMシステムとすべく,退学予測ツールのプロトタイプを実装する.本システムは,Microsoft Excelで作成されたユーザインタフェースに加え,Visual Basic for Applications(VBA)を用いて記述されたソースファイル,Pythonを用いて記述されたソースファイル,およびLightGBMにおける学習済みモデルがpickle形式で格納されたソースファイルから構成される.図8に示した模式図に従い,処理の概要を述べる.
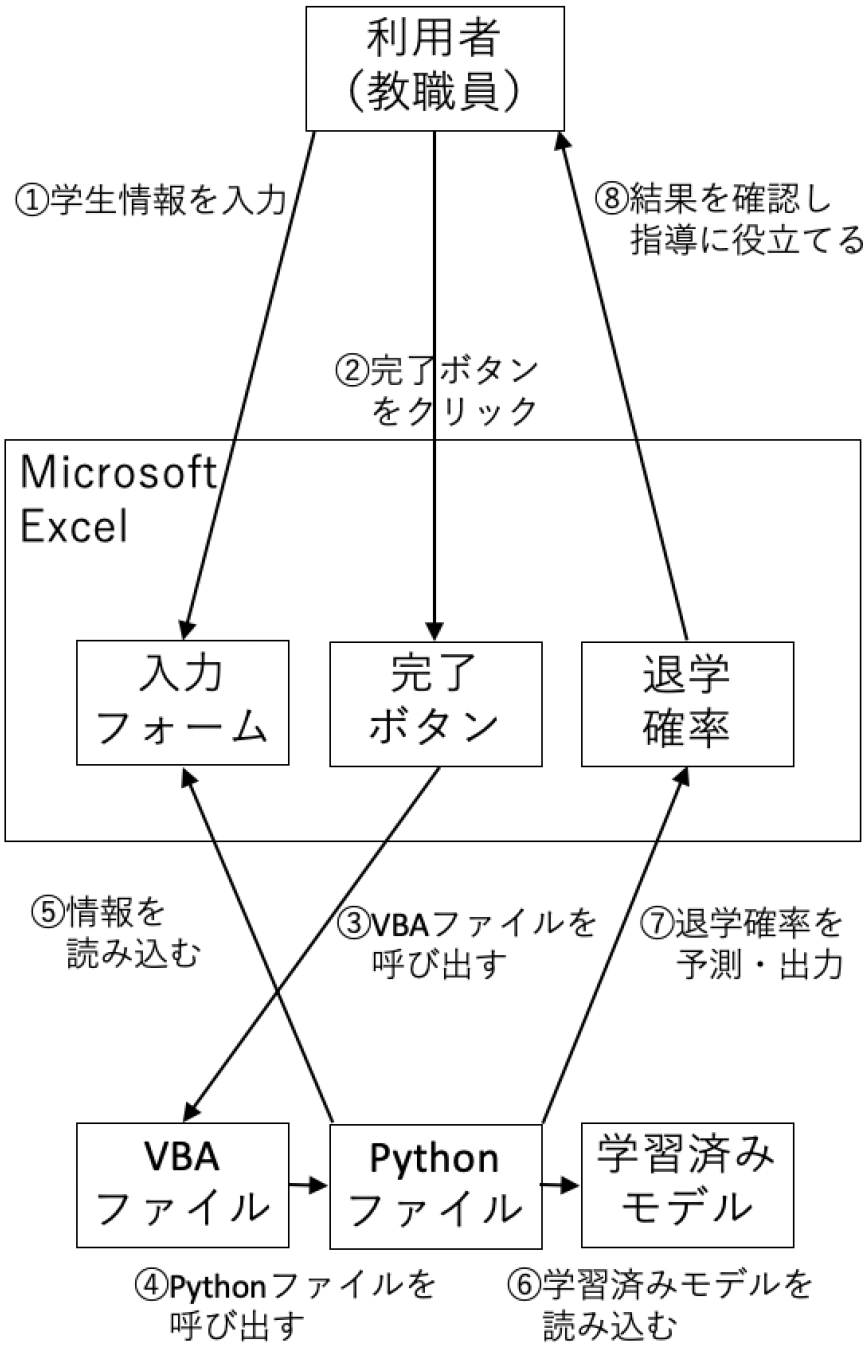
Fig. 8 Flow of prediction tool.
Excel上には,学生の氏名のほかに,説明変数である1年次単位数,1年次GPA,各講義(コンピュータ基礎A,B,論述作文A,B,英語IA,IB,IIA,IIB)の評定,出身高校の偏差値,高校時代の評定平均を入力項目として,入力フォームを用意する.利用者は入力フォームを埋めた後(①),入力完了ボタンをクリックする(②).これは,VBAで記載されたソースファイルと紐づいており(③),VBAファイルではPythonファイルを呼び出す処理が記述されている(④).
Pythonファイルでは,Excel上に入力されている学生情報(⑤),pickle形式で格納された学習済みモデルを読み取り(⑥),退学確率を算出した後,Excelのセル上に結果を出力する(⑦)という一連の処理が記述されている.この結果を基に,教職員の学生指導に役立てることを想定している(⑧).例として,不真面目な学生,真面目な学生をイメージした学生情報を入力し,予測を行った場合の結果を図9に示す.それぞれ退学可能性が71%,11%と出力され,直感にも則した退学確率が表示されているとみられる.
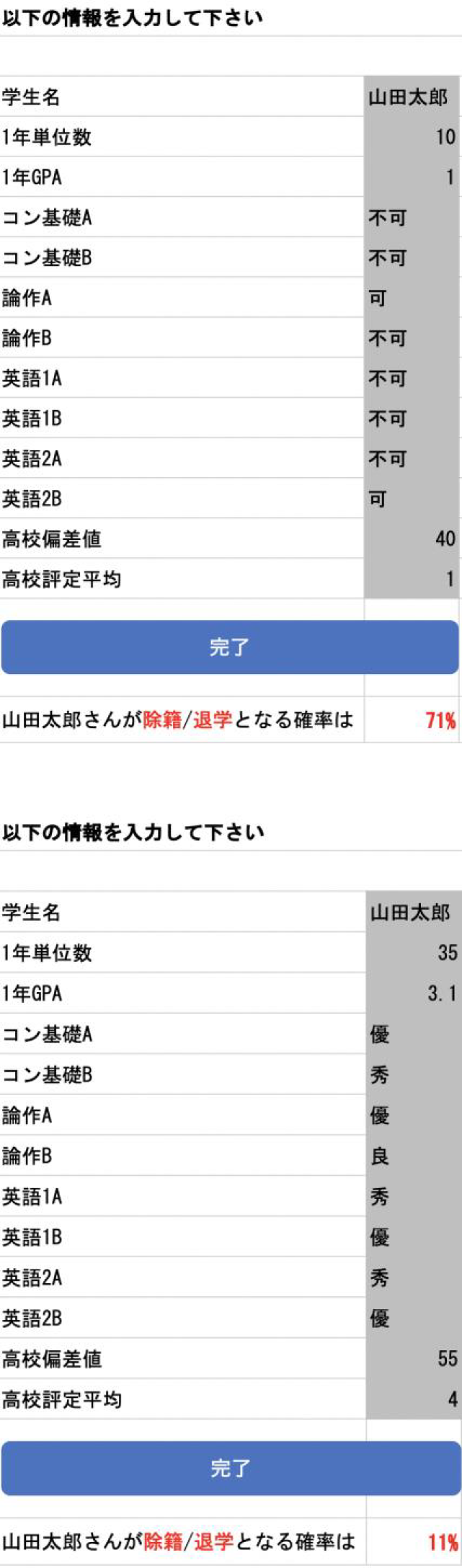
Fig. 9 Examples of prediction tool.
このような仕様を実現することで,利用を想定する教職員においては,裏側で機械学習による処理が行われていることを意識せずとも,必要な情報を入力すれば結果を得ることができる.すなわち,コーディングや機械学習に関する知識や技術が伴わない場合でも,問題なく利用可能ということになる.本実践ではMicrosoft Excelを利用しているが,ブラウザベースのユーザインタフェースにすることも考えられる.いずれのインタフェースを採用したとしても,裏側で行われるのは数100 KB程度のpickleファイルを読み込んで数値を当てはめるだけの処理であるため,大規模な計算資源や特殊なマシンは必要ではない.第3章で示したとおり,モデルのパラメータ学習にはPCによって数分~数十分程度の時間を要するが,パラメータ学習を実施するのは学生情報が更新されるタイミングに合わせて1年に1回程度のものである.本システムの利用においては,通常のノートPCであっても,完了ボタンをクリックしてから結果が出力されるまでの工程は,1秒足らずで完了する.
5. プロトタイプの検証
今回の実践研究では,2011年度から2017年度までのデータを訓練データとテストデータに分割して教師データとして使用していることから,2018年度以降のデータがあれば純粋に本システムの予測の評価が可能となる.
2022年3月に卒業年であった2018年度に入学した学生(前処理後,540人)の退学確率の予測結果を,AUCを用いて評価すると,0.896という精度であった.従来,指導対象の学生を単位数のみの情報から抽出していたことから,1年次単位数のみを特徴量に用いたLightGBMのモデルを構築し,ベースライン(baseline)として,本システム(prediction model)と比較する.ROC曲線は図10のようになり,ベースラインのAUCは0.867と,本システムが勝る結果となった.この結果から,従来の単位数のみを条件に学生を抽出する方法に比べ,機械学習の力を使い,様々な変数を基に学生を抽出する本システムが優位であるといえる.
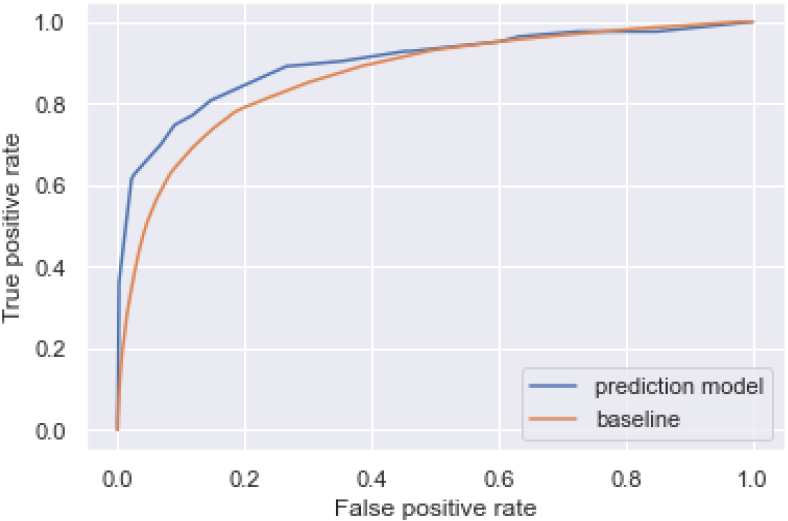
Fig. 10 ROC curve.
さらに,本章では現場での適用を見据えて,より解釈性の高い混同行列を用いた評価,考察も行う.混同行列では,
- ①本システムで退学と予測して実際に退学した学生の数(真陽性,True Positive)
- ②本システムで退学と予測したが実際には退学しなかった学生の数(偽陽性,False Positive)
- ③本システムで卒業と予測したが実際には退学した学生の数(偽陰性,False Negative)
- ④本システムで卒業と予測して実際に卒業した学生の数(真陰性,True Negative)
を2×2のクロス表で提示する.
今回は「退学確率」を最終結果としていることから,何%以上を退学と判断し指導対象にするのか,何%未満を卒業と判断するのか,閾値を変更してシミュレーションを行うことができる.たとえば,退学確率80%を閾値とすると,本当に退学しそうな学生だけを指導することになり,②が小さくなって指導の負荷は下がるが,逆に③が大きくなり見落としが増える.20%を閾値とすると,少しでも退学可能性がある学生には指導をするので,見落としは減る分,指導の負荷が増える,というようなトレードオフが生じる.つまり,ここの判断は,確実性をとるか負担削減をとるかという実践上の観点が大いに絡んでくる.
表3にて,2022年3月に卒業年であった2018年度に入学した学生(前処理後,540人)の退学確率について,閾値を0.1から0.5と変更して得られた混同行列を示す.
Table 3 Threshold and confusion matrices.
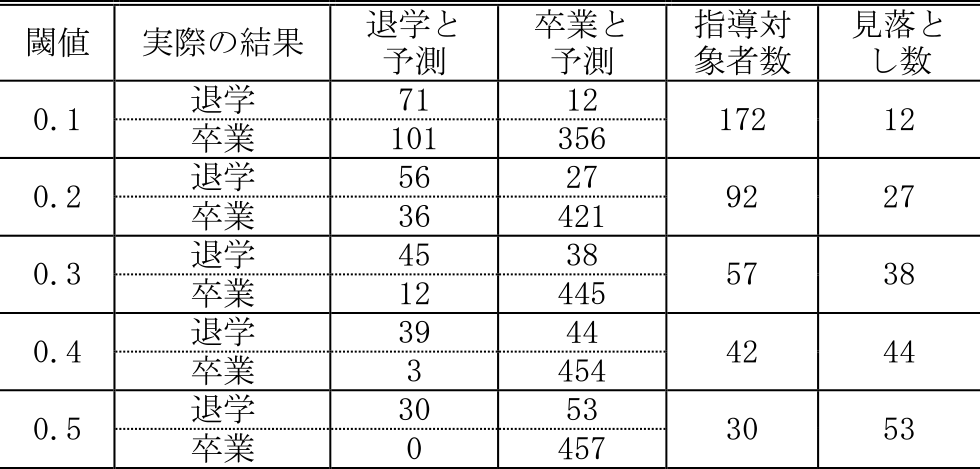
この結果を見ると,閾値0.1に設定した場合,指導対象者数は172名(全体の約32%)と多くはなるが,卒業と予測したのに退学した学生,すなわち見落とし数は12と少なくなった.また,閾値0.5の場合は,指導対象者数30名(全体の5%強)と少なく,退学と予測し実際に退学した学生も30名であるが,逆に見落とし数は53名に達しており,これでは指導の意味がない.現在行われている指導対象者の範囲は学科によっては対象者の5割以上のところもあるので,閾値0.1でも実際の運用は可能と考えられる.さらにいえば,退学可能性20%~50%の学生にはメールを送る,50%~70%の学生には面談を行う,70%以上の学生には保護者にも働きかける,といった閾値をコントロールして段階的な処置を行うといったことも実践上は可能である.
実際の2018年度入学者のデータから,1年次の単位数が30単位以上と比較的多いにもかかわらず退学に至っており,閾値0.2で本システムが退学と予測することに成功した二人の学生の状況を一例として抽出する(表4).
Table 4 Examples of predicted dropouts.
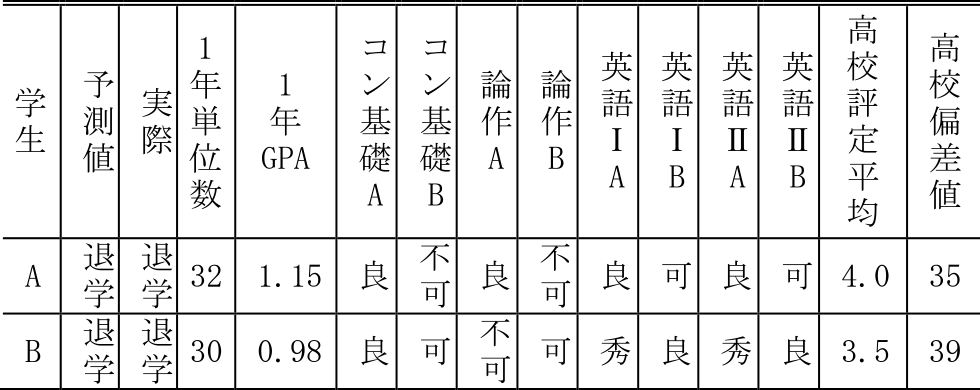
上の段の学生は,コンピュータ基礎B,論述作文B,英語など重要な必修科目の単位を落としている.下の段の学生は,単位自体は取れているが,GPAが非常に低く,ほとんどの科目をギリギリの状態で取得している.指導基準が単位数だけだとすると1年次終了時の修学指導の対象とならない学生であり,単位数だけに留まらない教職員の経験やカンといった暗黙知を,形式知に変換できた例といえる.
6. おわりに
今回は,筆者が勤務する大学のIR活動の中で生じた,退学に至る学生を早期に発見し適切な修学指導に結び付けられないか,という課題を解決するために,IRで得られたデータを機械学習で分析し退学予測を行うエンロールメントマネジメントシステムを開発し,その開発に至る経緯と過程を実践研究事例として報告した.
今後の課題としては,本システムを実際の教職員の修学指導の現場に導入し,本当にこの機械学習による退学予測が現場の感覚,いわゆる教職員の経験やカンに代わるものになり得るのかを検証する必要がある.その際,指導対象の学生が,これら機械学習による予測で抽出された学生であることに対する教職員の不信感(いわゆるAIが何故その予測を導き出したのかの理由が分からない)があるままでは,教職員も効果的な指導ができないと思われる.予測理由の説明が可能なAIとして,2017年に発表されたSHAP(SHapley Additive exPlanations) [15]などが注目されているが,本システムにそのような説明可能なAIを導入することも有効であると考えられる[16].
また,入手可能な学修データの中でほかに本EMシステムの退学予測の精度を高めるデータがないか更なる検証が必要である.候補としては,個々の科目の出席データなどが想定されるが,必ずしも主要科目で出席取得が徹底されていないこともあり,難しい側面もある.また,2020年,21年とかなりの授業科目が新型コロナの影響で,出席そのものが完全にオンライン上の学習履歴に置き換わったこともあり,それらの学習データ取得も簡単ではない[17].しかし,これら出席データは,GPAや退学予測に関わるデータとして重要との指摘もあり[18],今後これらデータの収集を精力的に進めたい.
さらに,これ以外にも学生生活実態調査等の学生アンケートや,奨学金受給状態,各部局が都度行っている様々な調査や学生との面談履歴なども当然ながら退学予測に利用可能と考えられる.しかしながら,アンケートならば調査の目的と利用範囲が事前に学生に通知されたうえで入手されたデータであるという前提が必要となったり,個人情報保護の観点から直ちに入手したデータを分析へと結びつけることは実は簡単なことではない.ただ,これら様々なデータが活用できれば,予測確率は確実に向上することが期待される.また,学生が退学に至る理由をより詳細に分析できることから,指導の選択肢が大幅に拡がることは間違いない.
他方,本実践手法の他大学への適用可能性については,大学ごとに履修システムやカリキュラム,評価システムの違いがあるので,ここでの実践がそのまま適用できるわけではないが,各大学の1年次の必修科目の成績やGPAを中心に,ほかに大学独自に特徴的な説明変数をいくつか用意して,予測モデルの構築を行うことは可能と考えられる.そのうえで,自大学に合わせたEMシステムを構築できるのではなかろうか.
最後に,現在,全国の大学で行われているIRは確かに組織のパフォーマンスを評価するうえで欠かせない取り組みであるが,個々の学生の入学から卒業までをきめ細やかに支援するものとしては考えられていない.一方,実際の修学指導の現場では,学生達に直面する教職員が,学生との日常的なコミュニケーションや,修学状況を見ながらその学生が無事に卒業できるかを真剣に見守っている.結局のところ,学生が4年間滞りなく学生生活を全うし卒業できるのは,学生本人の力と教職員のこれら不断の活動に支えられているが,大学も人手不足や教職員の業務過多に直面している.だからこそ,これからはIT,特にAIがその役割の一端を担っていくのではないかと考える.本稿では,その可能性の一端を極めて限定的な地方私立大学の一事例として紹介できたとしたら幸いである.
謝辞 本稿はJSPS科研費JP19K02868の助成を受けたものです.
参考文献
- [1] 照井伸彦:ビッグデータ統計解析入門,日本評論社 (2018).
- [2] 山口達輝,松田洋之:機械学習&ディープラーニングの仕組みと技術がしっかりわかる教科書,技術評論社 (2019).
- [3] 金 明秀:日本におけるエンロールメント・マネジメントの展開,私学経営,412号,pp.21–29 (2009).
- [4] 大友愛子,岩山 豊,毛利隆夫:学内データの活用~大学におけるIR(Institutional Research)への取組み~,Fujitsu, Vol.65, No.3, pp.41–47 (2014).
- [5] 城川俊一:知の創造プロセスとSECIモデルオープン・イノベーションによる知識創造の視点から,東洋大学経済論集,Vol.33, No.2, pp.27–37 (2008).
- [6] 白川優治,大島真夫,黄 文哲:経済的理由による学生等の中途退学の状況に関する実態把握・分析等および学生等に対する経済的支援の在り方に関する調査研究報告書 平成27年度文部科学省大学改革推進委託事業,東京大学,第4章,pp.175–210 (2016).
- [7] 札幌学院大学教学IR委員会:札幌学院大学IR報告書2020-2021年度版,札幌学院大学 (2021).
- [8] 近藤信彦,松田岳士:教学IRにおける予測モデル活用の枠組み,第6回MJIR予稿集,pp.42–47 (2017).
- [9] 高松邦彦,村上勝彦,伴仲謙欣,野田育宏,光成研一郎,大森雅人,中田康夫:教学IRにおける機械学習の意義と可能性,神戸常盤大学紀要,No.14, pp.22–29 (2021).
- [10] 高松邦彦,村上勝彦,鷹尾和敬,村瀬有紀,深川 大,旭潤一郎,伴仲謙欣,野田育宏,光成研一郎,中村忠司:機械学習を用いた学力進捗予測の可能性,第7回MJIR予稿集,pp.48–53 (2018).
- [11] 白鳥成彦,大石哲也,田尻慎太郎,森 雅生,室田真男:中退確率の遷移を用いた中退学生の類型化,日本教育工学会論文誌,Vol.44, No.1, pp.11–22 (2020).
- [12] Ke, G., Meng, Q., Finely, T., Wang, T., Chen, W., Ma, W., Ye, Q., Liu, T.-Y.: LightGBM: A Highly Efficient Gradient Boosting Decision Tree (2017).
- [13] 門脇大輔,阪田隆司,保坂桂佑,平松雄司:Kaggleで勝つデータ分析の技術,技術評論社 (2019).
- [14] LightGBM: 〈https://lightgbm.readthedocs.io/en/v3.3.2/〉(参照2022-06-15)
- [15] Lundberg, S., Lee, S.-I.: A Unified Approach to Interpreting Model Predictions, Proceedings of the 31st International Conference on Neural Information Processing Systems, pp.4768–4777 (2017).
- [16] 大堀耕太郎:システム科学に基づくAI社会実装へのアプローチ,人工知能,Vol.35, No.4,pp.542–548 (2020).
- [17] 近藤伸彦,畑中利治:教学IRにおけるLMSログデータ活用の試み,教育システム情報学会第42回全国大会予稿集,pp.119–120 (2017).
- [18] 竹橋洋毅,藤田 敦,杉本雅彦,藤本昌樹,近藤俊明:退学者予測におけるGPAと欠席率の貢献度,大学評価とIR,5, pp.28–35 (2016).

石川 千温(正会員)chiharu@sgu.ac.jp
1985年北海道大学応用物理学科卒業.1989年同大学大学院修士課程生体工学専攻修了.2001年室蘭工業大学大学院博士課程生産情報システム専攻修了.博士(工学).1996年札幌学院大学商学部講師.1998年同助教授.2002年同教授.現在,札幌学院大学大学院地域社会マネジメント研究科長.

石本 翔真(非会員)
2021年北海道大学工学部情報エレクトロニクス学科卒業.現在,北海道大学大学院情報科学院修士課程に在学.
採録日 2023年1月19日