教育デジタルトランスフォーメーション(DX)とデジタルエコシステム:国際技術標準,相互運用性,教育IoT
1.教育デジタルトランスフォーメーション(DX)と教育情報デジタルエコシステム
1.1 時代背景
我が国では2020年に入り顕在化した「コロナ禍」(新型コロナウイルス感染症の世界的流行のもたらした災厄)の中で,オンライン教育の普及,教育の情報化は急速に進展した.小学校・中学校ではコロナ禍以前から構想されていた政府のGIGAスクール構想によって2年あまりの間に1人1台環境が実現された.後年度分を含め1,200万台を超えるインターネット端末を配布し家庭での復習や課外活動でも利用を認めるというこの政策は,後年世界でも類を見ないものとして研究対象となるはずである.高等教育や生涯学習においても,キャンパスでの対面授業が不可能となる中で,通信制課程ばかりでなく通学制課程のほぼすべての機関で学習管理システム(Learning Management System, LMS)やテレビ会議システムを利用したオンライン授業が実施され,その有効性については一定の評価を得た.その一方,我が国の教育情報インフラの弱点も見えた.教育情報システムは担当部署で独立に運用されサイロ化している場合も多く,その場合は人手を介してデータを交換しなくてはならない.システムやアプリケーション単体の性能や利用に遜色がなくても,システム間のデータ連携やクロスプラットフォームでのデータ共有が自動化されていないが故に,デジタル化による省力化の効果が上がらない.ボトルネックが個々のシステム内部にあるのではなくシステム間の連携にあること,そして連携すべきシステムの開発ベンダや運用機関が複数で,自前主義では解決できず,企業間・組織間の意見や利害の調整も必要としているというのが特徴である.2022年秋コロナ禍が一段落し対面授業が復活する中で,オンライン教育のメリットを否定するような揺り戻しがあるとすれば,現在の教育情報システムの課題,ユーザの視点でシステム全体を眺めた場合使い勝手が悪く手間暇がかかるという課題に帰せられる可能性が高い.この弱点は,学生や教師の利用動機を下げ,結果的に新たな教育イノベーション,教育DXの実現を先送りにする.
1.2 教育の情報化の進展:教育DX
教育デジタルトランスフォーメーション(DX)とは,Web3.0技術を用いたインターネット上の分散型システム間で安全安心なデータ連携を図ることで,革新的な(イノベーティブな)学習・教育の内容や方法を実現し,「公正に個別最適化された学び」(文部科学省),「マイクロクレデンシャル」[1],「21世紀型スキル」[2]や「Transformative Competency」[3],「多様性・公正性・包摂性(Diversity,Equity and Inclusion,DEI)」[4],「持続可能な開発目標4(SDG4,すべての人に包摂的かつ公正な質の高い教育を確保し,生涯学習の機会を促進する)」[5],「リスキリング(Re-skilling)」・「アップスキリング(Up-skilling)」など,新たな価値を有する学習・教育目標を創出・実現することである.
1.2.1 教育情報システムの進化
我が国でも,1990年代以降教育の情報化の中で,教育用に特化した情報システムの導入が進められてきた.我が国の場合,初中等教育と高等教育,企業内教育では様相は異なった.大学などの教育機関の多くでは,コロナ禍以前より,教員や学生はコンピュータやモバイル端末を使えることが前提になっていて,組織的な利活用については課題が山積していても,さまざまな情報システムが導入されてきた.一般的な名称では,
- 学習管理システム(LMS)
- テスト作成・管理システム(テストバンク)
- eポートフォリオシステム
- オンライン試験監督システム
- 教務/校務/学務システム
- コンテンツ管理システム/コンテンツリポジトリ
- テレビ会議システム
- 連携認証システム(SSO)
- デジタルクレデンシャル(電子履修証明)システム
- 図書館情報システム
などが挙げられる.学習支援については,LMSを中核に,プラグインで必要な機能を追加するという形式で,これは企業の人材開発を目的にしたLMSでも変わらない.最近では,オンプレミスではなく,クラウド環境で構築することが多く,SaaSとして学習環境を提供するプロバイダーも増えている.
一方,初中等教育では,もともとセキュリティ対策の観点から,校内LANをインターネットと切り離して設計することが多く,また対面指導が基本であったため,校務システムやコンテンツ管理システム(リポジトリ)はあっても,LMSがない時期が続いた.文部科学省の推進する「学習eポータル」は初中等教育向けのクラウドベースのLMSと考えることもできるが,学習履歴データをどこまでだれが管理するのかという議論もあり,「公正に個別最適化された学び」という,学習者中心のデータ駆動型学習を実現するまでに検討すべき課題は多い.
1.2.2 次世代電子学習環境(NGDLE)
LMS中心のシステム設計に大きな転換点をもたらしたのが,2010年代前半,北米の高等教育レベルでのICT利活用を推進するEDUCAUSE[6]と,そこからスピンオフした国際標準化団体,IMS Global Learning Consortium(IMS-GLC,現在の1EdTech Consortium[7])が中心となった共同研究である.次世代のLMSはどうあるべきか研究が進められ,「次世代電子学習環境」(The Next Generation Digital Learning Environment, NGDLE[8],[9],[10])という概念が提案された.NGDLEが持つべき機能として,相互運用性(Interoperability)とシステム統合,パーソナル化(Personalization),分析・助言・学習評価,連携・協働,アクセシビリティとユニバーサルデザイン,の5つが挙げられた.当時北米では,LMSが本格的に使われるようになった一方,その課題も見えてきたところで,「LMSの次」が検討された.5つの特徴は,その後の北米での教育情報システム開発に影響を与え,現在の日本の教育DXにもつながる.
EDUCAUSEは,1,800を超える高等教育機関,400以上の教育ベンダや公的機関が参加する,高等教育におけるICT活用を推進する国際団体である.大学経営層(CIOやCDOなど)やIT関連センター教職員が多数参加することから,ICTを活用したイノベーションや大学改革に関するビジョンや共通指針の策定,その普及も担う.こうした目標を具体化する際に,技術標準が必要になる場合があり,EDUCAUSEでは1995年に教授管理システムに関するプロジェクト(the Instructional Management System project at National Learning Infrastructure Initiative)が立ち上がっている.このプロジェクトは1999年にNPOとして独立し,IMS Global Learning Consortium(2022年5月に1EdTech Consortiumに改称)となる.EDUCAUSEの大学経営層や教職員が策定したビジョンから,必要な技術仕様について産学のステークホルダー間で協議し,その合意をまとめたものをIMS技術標準として公表するという役割分担が行われてきた.
平行して,システム設計やソフトウェア開発の新たな考え方や手法も教育分野の技術標準に取り入れられた.アーキテクチャの分野では,「SOA(Service Oriented Architecture)」,「API (Application Programming Interface)」が提案され,システム連携も,エンタープライズ・アーキテクチャからクラウドに広がり,さらに「もののインターネット(Internet of Things, IoT)」,「Open Architecture」,「ゼロトラストセキュリティ」といった可能性や必要性が生まれてきた.開発方略(手法)では,オブジェクト指向,アジャイル開発,マッシュアップといった考え方も広く行き渡るようになり,技術標準の内容にも影響を及ぼした.
1.2.3 データ連携と相互運用性
NGDLEを技術的に特徴づけるのが,「相互運用性(Interoperability)とシステム統合」である,教育情報システムにはさまざまなものがあるが,従前は,こうしたシステムは,各教育機関の担当部署で個別に導入され,相互に接続されることはなく独立に運用されることが多かった.あるシステムで貴重なデータがログデータとして自動的に蓄積されても,データの形式(データモデル)は標準化されていなかったため別のシステムで利用されることもなく(「サイロ化」),後年機関研究(Institutional Research, IR)や学習解析(Learning Analytics, LA)を進める上でしばしば障害となった.この問題は,北米では2015年以前に認識され,NGDLEの提案につながったことに注意したい.
NGDLEでは,異なるシステムのデータが相互利用できるだけでなく,システム同士が自動的にデータのやりとりを行うことも想定する.ユーザ(教師や学生)個々の情報端末(スマート端末)がインターネットを介して大学のキャンパス外に分散しているというだけでなく,機関内外のデータベースやリポジトリが連携され,既存のアプリケーションやツール,コンテンツ(学習オブジェクト)が共有再利用・流通・マッシュアップされるデジタルエコシステムであることも想定する.NGDLEは,コロナ禍以前に提案されたものであるが,もともと教育分野では学習者端末はインターネット上に分散しているため,そのデジタルエコシステムを支える技術標準は,ゼロトラスト並みのセキュリティが求められた.
システム間で相互運用性を実現するには,データ形式(データモデル)や通信方法(プロトコル)を共有することが必要で,そのためのコミュニティの合意が技術標準(Technical Standards)仕様文書として具体化する.グローバル化の進んだ現代では,それは国際的な技術標準であることがのぞましく,教育分野では1EdTech Consortiumの活動が活発である.
図1は,その後さらに発展したNGDLEの概念図である.まず,LMSは中核ではなく,多くのシステム(1EdTech Consortiumではシステムやアプリケーションも含め「ツール」と総称する)の1つになっている.そして,ツール同士は,LMSを介さなくてもつながっている.さらに,すべてのツールがファイアウォールの内部にあるのではなく,少なくとも一部はインターネットを介して外部につながっているという点にも注意したい.コロナ禍以前からクラウドの利用が増えていたこと,コロナ禍で在宅勤務やオンライン授業が普及し,ファイアウォール外からのアクセスも常態化し,境界防御に加えゼロトラストセキュリティが普及したことも関係する.この時点で,相互運用性は,インターネットを介したデータ連携でも成立する必要があり,国際技術標準により厳しいセキュリティやプライバシー要件が加えられた(例,1EdTech「セキュリティフレームワーク」[12]).
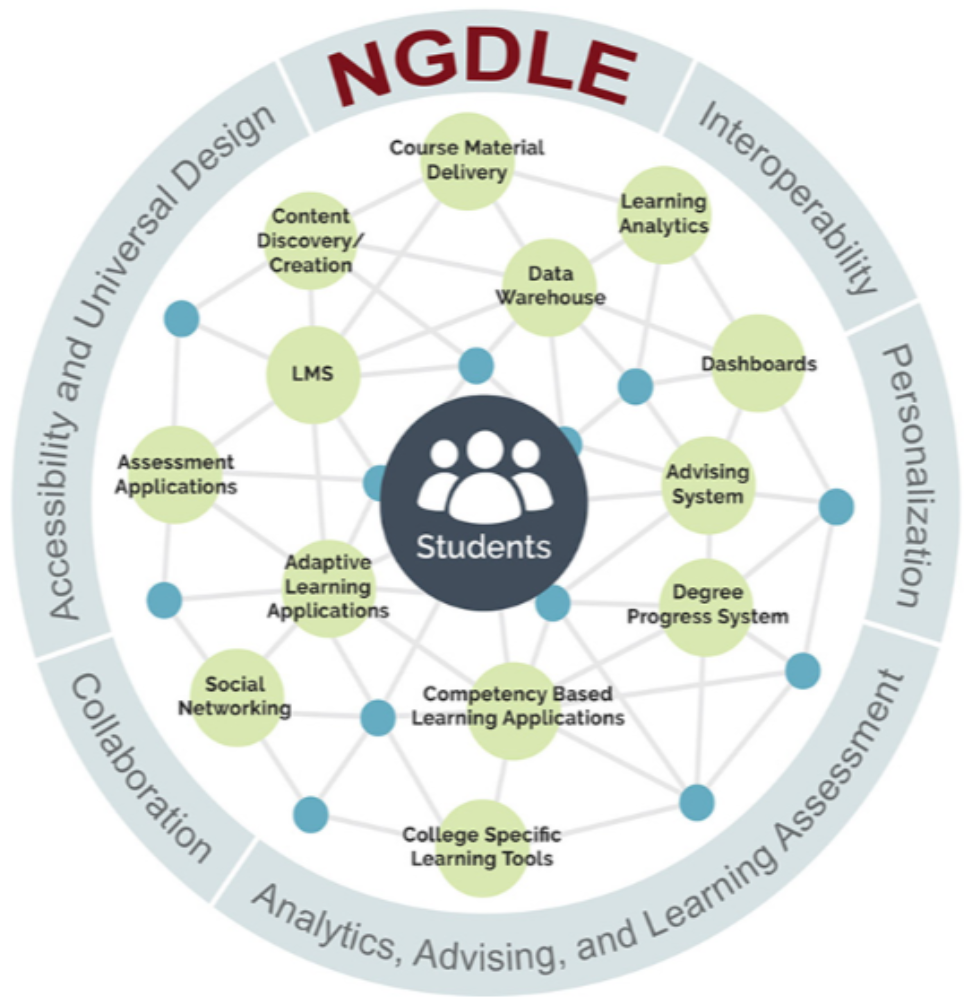
また,NGDLEのシステム連携では,拡張性・カスタマイズ性・再利用性が求められ,「プラグ&プレイ機能」の実現を具体化する.その背景として,学習管理システム(LMS)に求められる機能が,使用される教育機関や科目によって多様化したということがあった.大多数の科目で使用する機能がある一方,科目が限定される機能もある.このため,オプションとして必要な機能だけ追加するプラグイン方式が主流となった.教育機関や部局,科目によって必要なときにプラグインを追加する.こうした場合も基幹プラットフォームであるLMSとプラグインの間で情報のやりとりを標準化できれば,ユーザ,ベンダともに再利用しやすくなるわけである(図2).
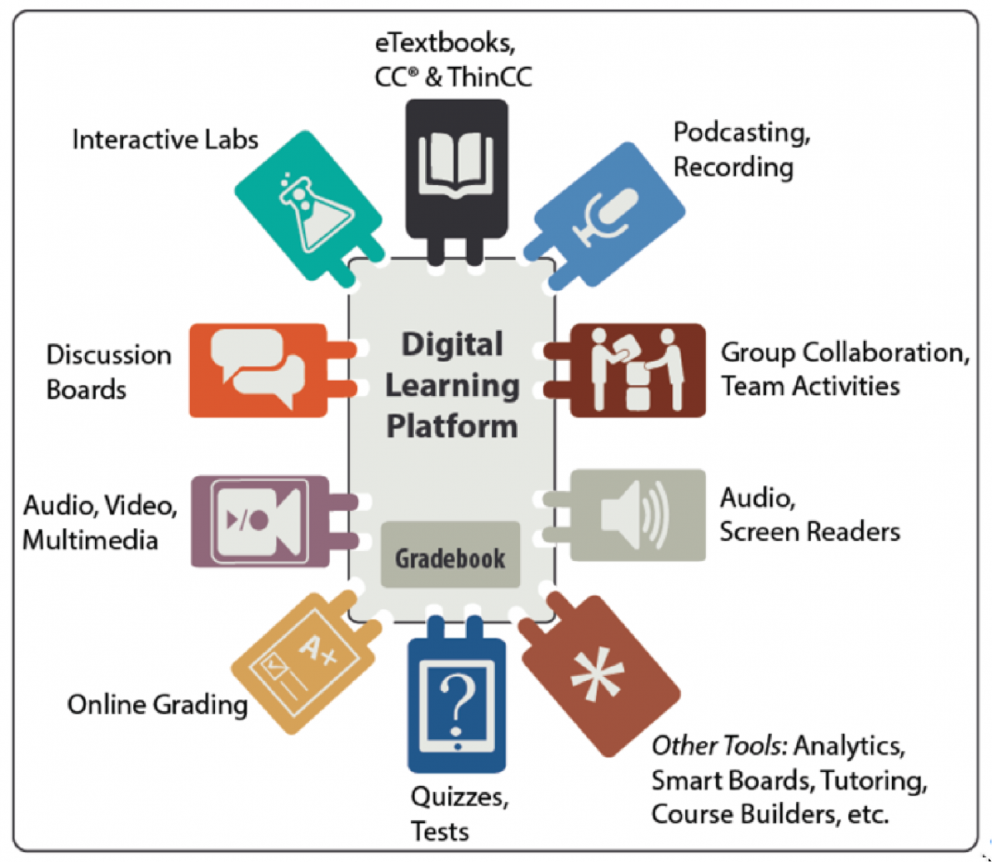
中央のDigital Learning PlatformはLMSのことである.科目によって,電子教科書を使ったり,実験シミュレーションを行ったり,グループ活動を行う.小テスト(クイズ),成績,視聴覚・マルチメディアコンテンツ,掲示板などは,多くの科目(コース)あるいはクラスで共通するが,インタラクティブ実験室,グループ学習機能などは,科目や教員に依存することになる.理系の科目では,バーチャル実験室やシミュレーションが必要であっても,文系の多くの科目では必要でない.
1.3 デジタルエコシステム
エコシステム(ecosystem)とは本来,生物学の用語で,「生態系」の意味であるが,転じて,「ビジネス生態系」という意味が派生した.さまざまな企業やステークホルダーが協調・連携関係,相互依存関係を形成しながら,新しいビジネス分野を成立・発展させていく様態を意味する.デジタルエコシステムでは,さらにデジタル技術(ICT)を活用することで,ビジネスの在り様(顧客のプロセスやバリューチェーン)に本質的な変化(いわゆるデジタル・トランスフォーメーション,DX)を期待する.インターネットの普及とともに,多くのビジネスがフラット化(国境や企業連合を超えた水平分業)・オンライン化し,さまざまなデータ,製品,サービスはオンラインかつピアツーピアでやりとりされる.デジタルエコシステムには,技術的基盤(インフラストラクチャ)の協調・連携も含まれ,さまざまなシステムやデバイスが組織の垣根を超えて簡単にしかし安全にデータをやりとりすることも含む.そのためには,システムやツールの相互運用性(Interoperability)を保証することが必要で,データの構造や通信の方式など関係者で合意の形成された仕様については技術標準として共有される.グローバル化した社会では,それらはオープンな(公開された)国際技術標準であることがのぞましいとされ,WebAPIは有力な解決策の1つである.
こうして,エンタープライズ・アーキテクチャとして発展したものが,クラウドの普及もあって,自然にデジタルエコシステムに移行しつつある,それは教育分野でも,同じトレンドが生じ,教育デジタルエコシステムの出現が予想される.
2.学習履歴データの構造
一人ひとりに最適で快適な学びを,持続可能な方法で実現するには,学習者個々の学習履歴と学習過程のデータを集積し,その分析やレコメンデーションに,機械(AI)の支援が必要となる.ここでは,データ駆動型パーソナル学習やエビデンス駆動型学習指導を実現するために不可欠となる学習履歴データについてまとめる.
2.1 学習とは何か
学習とは,生物学的には「有機体の個体発生における適応」のことを意味し,系統発生における適応である進化(evolution)と対比される用語である.しかし最近では,「機械の学習」のように,生物に限定せずに用いられたり,学校教育における「学習」のように,内容や形式が教育制度との関係において限定された使用法がなされる.
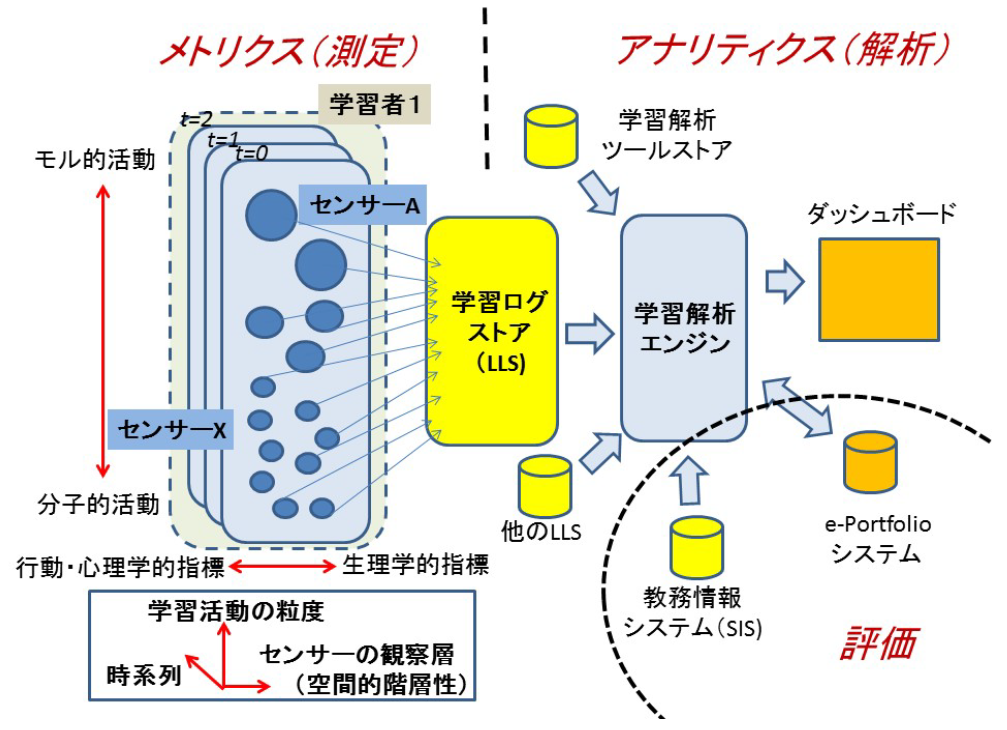
「学習」を記録,測定,評価する場合,ある状況における学習活動をすべて記録することは,実際には困難な課題である.学習活動にあったセンサを用意し,適切な時間で標本化し,しかも空間的・時間的に重層化している活動を分析する必要がある(図3,[14]).
2.2 学習過程と学習評価の記録
学習履歴データは,学習者それぞれの学習活動によって生成されるものであるが,学習活動を反映し学習活動の制御に使用される学習過程に関するデータと,学習目標および学習内容と対応しそこから評価される学修成果に関するデータに大別される.
前者でも測定される行動の粒度ということでは,モル行動(molar behavior)と分子的行動(molecular behavior)という区別もある.「行動を,筋運動や腺分泌などの物理的・生理的過程(分子的行動)として要素的に捉えるのではなく,固有の特性を持った1つの全体的行動」として捉えるとき,それをモル行動という(モーラー行動とも訳す).行動をその要素的過程から構成するのではなく,総体として包括的に理解したものなので巨視的行動ともよばれる[15].ディスプレイに「A」という文字を表示させるというモル行動は,右指でキーを押しても左足指で押しても,ペン入力しても音声認識機能を使っても,つまり,異なる分子的行動で実現できる.解答Aを選択するということでは,分子的行動の差異に機能的な意味はないが,マン・マシン・インタフェースやユニバーサルデザインではむしろ主たる課題である.
2.3 学習活動の階層性
さらに粒度が大きい(大きな粒になる)と,学習目標との関係が生じる.学術的なカリキュラムでは,個々の学習目標を有する学習モジュールの達成度テストに合格する,コースを修了する,学位を取得するといった階層が考えられるほか,学習目標がコンピテンシーモデルで構造化されている場合には,スキル・知識の体系で整理されることになる.こうしたデータは,学習目標にひもづき評価を含む学修成果に関するデータである.通常,人間の学びでいわれる学習活動は,運動学習を除くと,大半がモル行動で,しかもそれ自体の粒度の分散は大きい.トールマンは,モル行動の特性として目的性・認知性を挙げたが,ハルはそれを認めず独自の公準系を作り上げた.
行動には階層性もある,他覚的な指標と自覚的指標では,時間の単位が異なる.キーボードでタイピングをしながら音声で内観報告をする,あるいは同時に脳活動を記録することも可能であるが.記録する行動や反応,それらの関係については,計算機資源の有効利用も考え,絞り込みを行う必要も出てくる.
さらに,学習者の特性や学習の文脈に関する情報もある.出現した時間や場所,社会的な関係(グループ活動などの場合)などが記載される.こうしたものがすべて,学習履歴データを構成する.
2.4 学習の目標と測度
さまざまな生物や機械の,さまざまな学習において,どのような行動や反応を測定すべきかという問題は,100年を超える心理学や動物行動学の研究系譜があり,これまでに存在しなかった新たな学習目標や学習方法を検討する場合には,新たな測定方法とその測度が検討されてきたところである.心理学研究法では,長らく,実験,測定とともに,観察は基本的な方法とされ,自然的観察,実験的観察などさまざまな手法が開発整理されてきた.学習解析(Learning Analytics)は,もともとコンピュータになかば自動的に保存されてきたログデータの有効利用という側面があったため,クリッカブルデータやカメラ・マイクの映像音声データが主流ではある.もとより,クリックする対象の表示コンテンツ(教材やテスト)そのものも進化していることは論を俟たないが,現在の入出力デバイスが完成形という認識は遠く,生体情報や社会的文脈で得られる情報(他者による評価情報など)の収集(いわゆる「センサ」)の開発も急速に進められている.さまざまなセンサの百花繚乱が標準化の制約になっている.
2.5 学習者および学習文脈の記録
学習履歴データを教育指導に用いる場合には,それがどの学習者のものか識別する必要がある.研究目的で匿名化する場合でも,データを観測した日時,科目や単元,教材の位置やテスト問題に関する情報,いわゆる文脈情報を記載しないと,学習解析の分析精度を上げることはできない.これは学習履歴データにも,学習目標や評価基準を記載する必要があるということである.学習目標には地域差,文化差もあることから,Localization(地域対応)を想定したデータモデルが必要となる.
2.6 学習履歴データデジタルエコシステム
こうした学習履歴データはまずデータ主体である学習者のものでありその管理利用はデータ主権により整理される必要がある.学習者本人や教育機関においては,個人情報に紐づけられた状態で学習や教育に用いるというのが第一義的な利用である.そして,生涯学習の観点からは,1つの教育機関で生涯学習が完結することはきわめて稀で,1つの教育機関が持ち得る学習履歴データは断片的なものにならざるを得ない.こうした意味でもデータ主体の責任と権利は増大するのであり,情報銀行のような支援機能も社会基盤として必要となる.研究やビジネスの観点からは,学習履歴データのビッグデータは匿名化し,知的資源としての2次利用が期待される.
学習履歴データの利用や流通を図る場合,社会インフラとしてのエコシステムには,プライバシーを守る仕掛けと制度が必須となる.
3.教育情報システムの国際技術標準
教育情報システムが利用する国際技術標準には,1EdTech Consortiumのものに限らず,ADL,IEEE,W3Cのものがある.しかし,背景とする教育・人材開発分野のコミュニティの規模が圧倒的に大きいこと,対象とする教育情報システムが多岐にわたり,ほぼすべてをカバーすることから,ここではThe1EdTech Consortiumの技術標準を例に説明する.
3.1 1EdTech Consortiumの技術標準
1EdTech Consortiumは米国に登記された非政府組織(NGO)である.北米の大学CIOやITセンタの組織であるEDUCAUSEから1999年にスピンオフしたのが始まりであるが,その後対象は初中等教育から企業内教育に広がり,生涯学習全般に及んでいる.こうした背景から,特定の政府や軍あるいは企業からの独立性を保つために,メンバシップモデル(会員による会費で運営)を採用し,現在29カ国から810を超える法人等が参加している.なお,発足以降,IMS Global Learning Consortiumを称してきたが,2022年5月に1EdTech Consortiumに改称した.我が国の(一社)日本IMS協会[16]は密接な連携関係を有するが,法的には別の法人である.
デジュール標準(de jure standard))が国際標準化機関等,公的機関により定められた標準であるのに対し,フォーラム/コンソーシアム標準(forum/consortium standard)は,業界(関連する企業や機関),関連団体(関係する専門の学会など)が集まり合意に至った標準である.もともと,デファクト標準やフォーラム/コンソーシアム標準であったものが,公的機関により認められ,デジュール標準になる場合がある.1EdTech Consortiumの技術標準はフォーラム/コンソーシアム標準であるが,そのコミュニティには教育ベンダばかりでなく,大学等の教育機関や教育委員会などの公的機関を含み,さまざまなステークホルダーの意見を反映させ,コミュニティの合意を形成する点に特色がある.
3.2 The1EdTech Consortium技術標準の分類
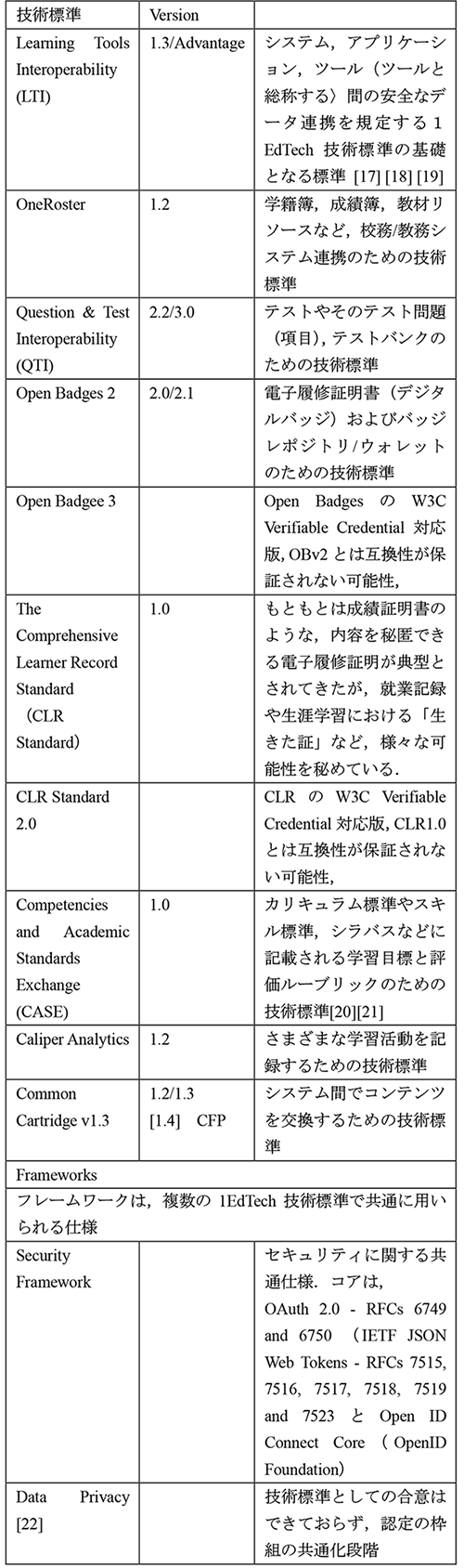
1EdTech Consortiumでは,1999年IMS Global Learning Consortiunとして発足して以来,バージョンの相違を含めると100を超える技術標準を開発してきた.そのうち上位の分類にあたるものを図4に示す.現時点で実際に使用されるものは,さらに絞られて15程度であるが,採用されている製品数で多いのは,LTI,OneRoster,QTIである(Product Directoryにおける認定製品数,2022年11月30日現在).以前のものが言及されるのはまだアフターケアがなされているためで,新しい技術標準がリリースされる際にこうした技術標準との整合性の担保なども含まれる.

2022年11月7日1EdTech Quarterly Meeting “Building the 1EdTech Ecosystem Wonderland”セッションで,チーフアーキテクト(技術標準策定の最高責任者)Colin Smythe 博士により示されたもの.
以前は,データモデルの標準と通信プロトコルの標準という区別もあったが,最近はその両方が含まれるものが多い.代表的な技術標準を表1に示すが,現在使用されている教育情報システムの大方について,1EdTech Consortiumにおいて開発済みで公表されているか,開発中である.
3.3 実装(Implementation)の実際
実際の実装にあたっては,1EdTech Consortiumが公開している文書やWeb教材で仕様を検討した後,開発物に実装する.会員であれば,さまざまなツール等の使用も可能となる.
例をLTI Advantageについて見る.まずWebサイトには,手引(Guide)と仕様書(Specification Documents)が公開されている(表2).
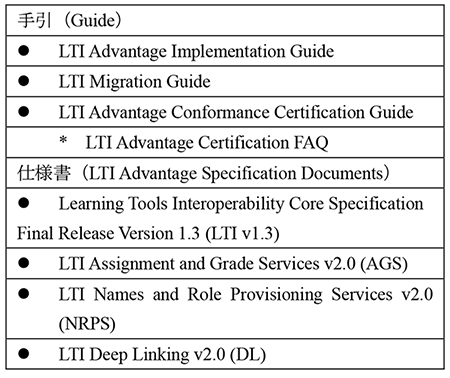
LTI Advantageは,LTI v1.3 (LTI Core と略記されることもある)に,3つのサービス,すなわち課題設定と成績情報の取得で用いるAssignment and Grade Services(AGS),ユーザネームおよび役割を提供する際に用いるNames and Role Provisioning Services(NRPS),教材や試験問題等でDeep Linkingを行うためのDeep Linking(DL)が追加されたものである(2023年1月現在,LTI Advantageのサービスは今後追加される可能性もある).LTI v1.3(コア)は,認証(Authentication)と認可(Authorization)にかかわる部分で,IETF OAuth 2.0 とOpen ID Connect(JWT)を使用するので,そうした知識があったほうがよい.
仕様と実装手順を理解した後,会員であれば,リファレンス実装(Reference Implementation,RI) ,コードライブラリーのサンプルコード,さらに部会のMember Roundtableの記録や,1EdTechスタッフのアドバイスを受けながら実装を進めることになる.1EdTech Consortiumの場合,1からコードを書くことはあまりなく,こうしたリソースを利用しながら開発していくことが多いようであるが,これは1EdTechのほかの技術標準でも共通する作業となる.
さらに,実装製品が技術標準に適合しているかテストするためのツール(適合性試験ツール,Conformance Test Tool)も用意されていて,最終動作確認テストとして,あるいは形成的評価の一環として利用することもできる.これも会員限定となるが,希望すれば,このテスト結果をもって1EdTech Consortiumから当該技術標準の適合製品として認定(Certification)を受けることができ,認定製品はProduct Directory(TrustEd Apps Directory)に掲載され公開される.デジタルエコシステムでは,他社の製品を前提に実装を進めることもあるが,どの製品がどの技術標準に対応しているか事前に確認する際にも有効である.一方,1EdTech ConsortiumのProduct Directoryに掲載されていない製品は,動作確認の基準や根拠が不明確で,信頼性の点で問題がある.特定の製品とのデータ連携を想定した実装では,技術標準の適合性のテストだけでは不十分なことが多い.技術標準の拡張(Extension)項目やパラメータの値などは,別途定め確認することになる.
LTIでは,ツール間のデータ連携を規定しているだけであり,それぞれのツールは互いにブラックボックスでよく,そのペイロードの内容についても関知しない.2つのツールでデータ連携を試み,その動作がうまくいかないとき,適合性試験はデータのやりとり自体に不具合はないことを確認するための仕組みといってよい.LTIで規定される部分が完全であっても,ツール間の動作がうまくできない原因はほかにもある.ペイロード層(コンテンツ層)の標準も,たとえば,科目別のカリキュラム標準や各国の定める学校コードなどの分類体系などが国・地域によって異なる.これらは,1EdTech技術標準ではパラメータの相違と理解され,コンパティビリティチェック(後述)の対象となる.
3.4 今後の進化
1EdTech Consortiumにおいては,技術標準の改善について,さまざまな試みがなされている.
3.4.1 The 1EdTech技術標準間の整合性
1EdTech Consortiumでも,開発時点の設計思想が技術標準間で統一されていない部分もあり,現在,技術標準間でも互換性を高めるべく,用語の統一を含めた抽象化(アブストラクション)が検討されている,フレームワークによる整理もそうした流れの中にある変化である.
3.4.2 ほかの標準化団体の技術標準の関係
Advanced Distributed Learning(ADL)[23]のExperience API(xAPI)[24]とCaliper Analyticsの関係もそうである.現時点で,学習解析はまだ開発途上にあり,ベンダ間で合意できる範囲は多くなくCaliper Analyticsのセンサはまだ少ない.こうした状況では,研究者・開発者の独創性を反映できるxAPIが使いやすい.研究者がその時点で蓄積されたデータを活用しグッド・プラクティスやエビデンスを積み重ね,社会的合意が図られた部分からCaliper Analyticsにも対応させるという方略があり得る.
3.4.3 Localization:国際技術標準と国内・地域技術標準の関係
国際標準化団体において,各国・地域の状況にどう対応するかは個々のケースに応じ解決すべき課題となる.教育は,国・地域の制度や文化を基礎に形成・実施されるものであるため,グローバルあるいはユニバーサルな技術標準として適用可能な仕様とローカルな状況に応じて変更・追加する仕様が出てくる.1EdTech Consortiumは,国際標準化を目指す団体ではあるが,国や地域での技術標準の実装に不可避な要素として,Localizationを尊重する立場に立っている.これは教育の特殊性への配慮やデジタルエコシステムを支えるコミュニティを尊重する姿勢からくるものと考えられる.
各国・地域,あるいは地方・コミュニティにおいて,ローカルな技術標準を,しかるべき組織(国,地方公共団体などのオーソリティー)が定めることはむしろ当然のことといえる.その場合でも,ユニバーサルな標準として定めたほうがよいデータモデルや通信プロトコルは国際標準,ローカルな状況にあわせて機能を限定したりパラメータの値やその範囲を限定する場合は,ローカルな標準を策定し,全体としてその国や地域の技術標準として構成する必要が生ずる.1EdTech Consortiumの場合,技術仕様文書の改訂を必要とするケース(Extension(拡張)ルールで項目を追加する場合や必須項目を任意項目にする場合)はProfileで対応し,単にパラメータの値を定める場合はペイロード側の対応として関与しないなどの可能性が想定される.ただ,こうしたLocalizationへの対応は,1EdTech Consortiumでも始まったばかりで,今後の事例の蓄積が期待される.2023年1月現在,その先駆けとしてOneRoster技術標準においてノルウェーと日本で,QTI技術標準において米国,オランダ,ノルウェーでProfileの提案が進行中である.
4.データ連携の品質保証
教育テクノロジーの国際標準化団体である1EdTech Consortiumに,データ連携の品質保証の例をみる.
異なる業種やベンダの間でのシステム連携を常態として想定する場合,中立性・公益性の高い団体が,データ連携の相互運用性を保証する技術標準を策定し,動作確認テストを実施することがのぞましい.1EdTech Consortiumでは,技術標準の策定プロセス,技術標準実装の支援にその特徴が見られる.
4.1 技術標準の策定プロセス
1EdTech Consortiumにおける技術標準の策定プロセスを図5に示す.
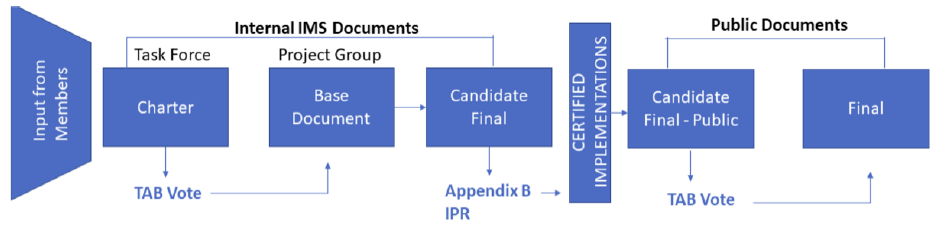
1EdTech Consortiumでは新たな技術標準の策定,および既存の技術標準の改訂の提案は,正会員(Contributing Memberという)の発議により始まる.いくつかの賛同者が集まると,正会員により構成されたTaskforceとしてCharter文書がまとめられ,Technical Advisory Board(TAB,全正会員で構成)で投票が行われる.そこで,承認されると,Project GroupがBase Documentをまとめ,その後1EdTech Consortiumの技術スタッフの支援も得て,Candidate Final文書がまとめられる.この時点で,知的財産に関する文書が添付され,ボランティアメンバにより実装が始まり実証実験が行われ,あわせてGood Practicesが収集される.こうした知見の結果をふまえ,さらにCandidate Final Public文書として修正され公表,さらに広くステークホルダーのレビューを受けた後に,TABでの投票があり,承認されると,Final版として確定する.1EdTech Consortium はオープン・スタンダードを推進する団体であり,最終的にはすべて公開されるが,Candidate Final文書までは非公開で,正会員のみがアクセスできる.これはそれまでの段階では改変がたびたび行われ,そうした事情を理解し利用できることをアクセスの条件とするためである.それぞれのステージで,会員や非会員のステークホルダーの意見を反映させる仕組みが組み込まれている.結果として,日の目を見ない提案があったり,バージョンアップに時間がかかるというデメリットも指摘されるところであるが,本来競争関係にあるベンダ間の意見調整も含まれるため,より多くのステークホルダーが合意に参加できるよう許容されているようである.
4.2 技術標準実装の支援
こうした過程を経て策定された技術標準はステークホルダーの合意事項であるが,その仕様書ができただけでは路半ばである.それが社会で実装されないと意味がない.このような実装支援を行うため,さまざまなリソースや工夫が見られる.
4.2.1 技術標準仕様(規格)の公開
1EdTech Consortiumはオープン・スタンダードを推進し,確定した仕様(Final版)については公開される.実装の手引書の作成に加え,最近の仕様書の改訂では,技術者が読みやすいような構成・内容に工夫もなされている(たとえば,QTI 3.0シリーズの文書[25]).
4.2.2 実装支援のための各種ツール,サービスの提供
実装にあっては,開発支援のための各種ツール,サービスが提供されている.リファレンス実装(Reference Implementation),実装を検証するためのツールやサンプルコードなどを納めたGitHubやCode Library,技術標準に適合しているか最終的な動作確認に用いられる「適合性テスト(Conformance Test)」ツールなどのほか,認定製品の特徴を記述し(Characterization),パラメータなどのチェックも含む製品間の互換性のチェックを行う「互換性チェック(Compatibility Check)[26]」も提供され始めた.
4.2.3 実装製品の認定とその普及
さらに,実装製品の普及を促進するためのサービスとして認定(Certification)制度,認定製品ディレクトリ(Product Directory),学習インパクト賞(Learning Impact Awards)などの提供がある.
会員はConformance Testに合格すると,1EdTech Consortiumから製品の認定を受けることができる.その有効期限は1年間である.そして認定製品ディレクトリ(TrustEd Apps Directory[27])に登録され,第3者がその仕様を確認することができる.
学習インパクト賞(Learning Impact Awards, LIA[28])は,2007年に始まった由緒ある賞で,4ランクで構成される.評価方法や評価基準に変遷はあったが,単に学習インパクトのある製品や実践を顕彰するだけではない.コミュニティにおける関心や潜在的な動向を知る手段ともなる.審査には,専門家グループによる評価だけでなく,会員による投票も考慮されている.
日本IMS協会でも,LIAに範をとり,その地域予選をかねたIMS Japan賞を行っている(2022年度で第7回).日本のベンダは1EdTech Consortiumの部会活動に十分参加しているとはいえないが,応募も増え,さらにLIAを受賞する製品も出てきている.
4.2.4 実装技術者の研修と認定
1EdTech Consortiumでは,主に日本IMS協会からの働きかけを受けて,IMS認定訓練/実装支援管理士(IMS-certified Training and Implementation Manager)制度ができた.すでに日本では10名を超える資格者が出ている.認定にあたっては,1EdTech Consortium チーフアーキテクトColin Smythe博士が自ら講義と実習(3カ月程度にわたり2〜3回)を指導,最終的には各自の行った実装について個別の試問を行うというもので,大変内容の濃いものである.国際技術標準に関するセミナーでありコンテンツは英語であるが,翻訳サービスを利用可能であり,また受講者のミートアップも推奨されるので,技術者の実践的英語学習の機会としても貴重である.日本IMS協会としては,各社での実装や社内研修にあたり,最低限の品質保証を行うためにこの制度を必要とした.資格の有効期間は1年間で,毎年講習会(4回の季節大会で行われる)のほか,日本向けの特別セッションも用意される.
5.デジタルエコシステムのユースケース
デジタルトランスフォーメーション(DX)ではさまざまなプロバイダーの提供するWeb上のリソースを組み合わせ,データ連携によって新たな価値を持ったサービスを創出する.データ連携は,複数のツールの間で,複数の技術標準を用いて実現される.そこでは多様なニーズにあわせて,さまざまなツールやコンテンツの組合せが必要とされることから,多様なサービスを許容できるデジタルエコシステムは有力なソリューションとなる.現在のところ,我が国の教育分野においては,エコシステムとして実運用されている事例がないため,一部ユースケースとして記載する.
5.1 電子履修証明(デジタルクレデンシャル)エコシステム
高等教育・生涯学習の例として,産学連携も視野に入れたデジタル履修証明エコシステムについて述べる.
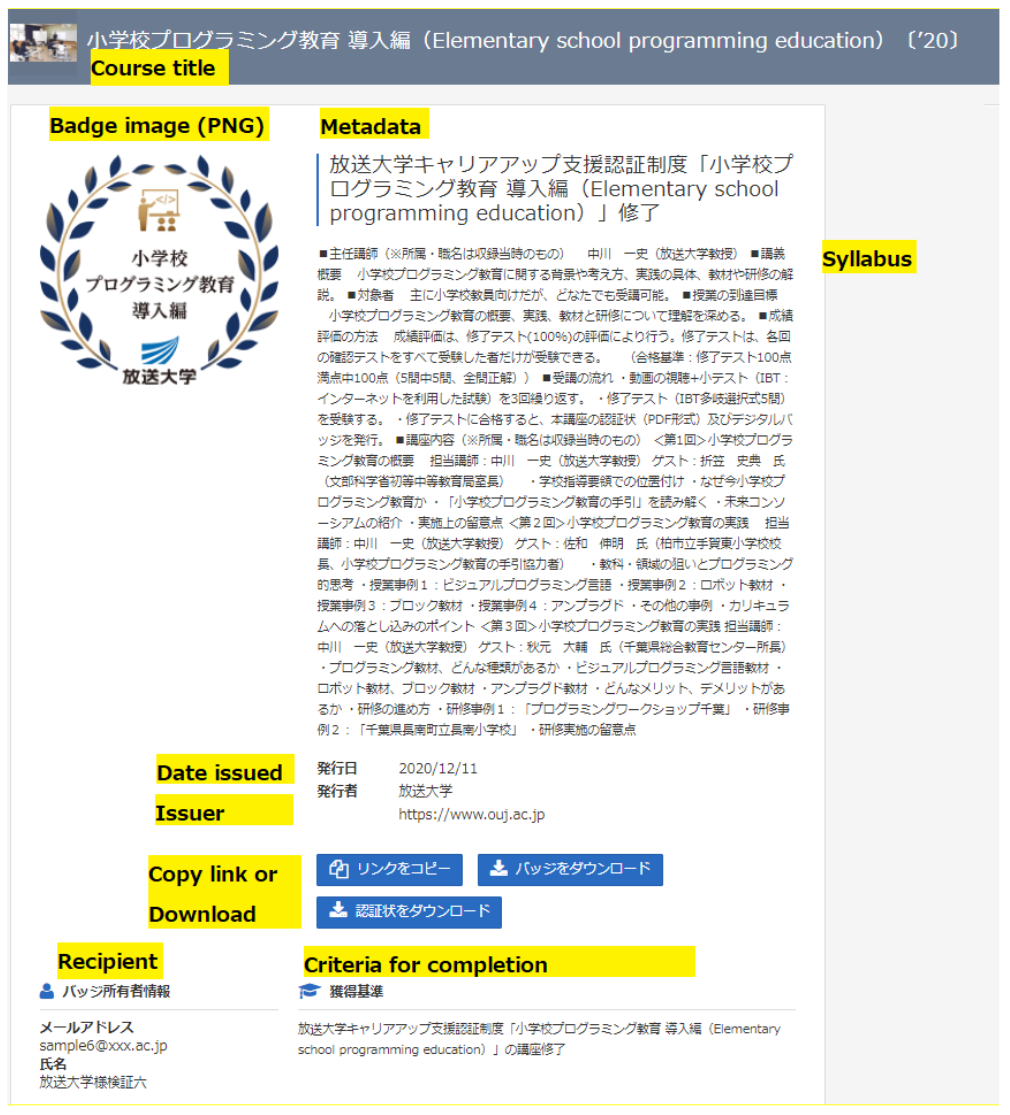
放送大学では,ノンフォーマル教育の一環として,「インターネット配信公開講座」[29]を開講している.修了すると,修了証が印刷可能なPDFとデジタルバッジ(図6,OBv2準拠)で発行される.デジタルバッジには,発行者,修了者の情報(電子メールアドレスを暗号化したもの)を記載できるほか,シラバスの内容も記載できる.修了者がデジタルバッジを実際にどのように活用しているかについては今後の調査を待つ必要があるが,SNSで取得バッジを披露している例は報告されている.放送大学では,AO入試や就職にバッジが使用されたという事例は把握していないが,国内の(財)オープンバッジネットワーク(2019年11月設立)[30]の事例報告や海外のWellspring Initiative(Phase1,2019〜20年;Phase2,2022年〜)[31]などの実証実験,さらにグローバル企業での実用化(IBMでの研修と人的資源管理の連携)など,すでに多くの実践が行われている.
この先は将来の可能性の話となるが,もしその科目(コース)があるカリキュラム標準に準拠して作成されている場合には,修了証バッジに対応関係も記載できることになる.こうしてカリキュラム標準とバッジに記載された学修内容を対応させることで学習パスウェイを表示したり,次の学習目標に応じたコースやコンテンツを推薦したり,異なる発行機関のバッジでもその記載内容をあわせて,単位互換や上位の資格証明を行うこともできる(マイクロクレデンシャルでの利用).
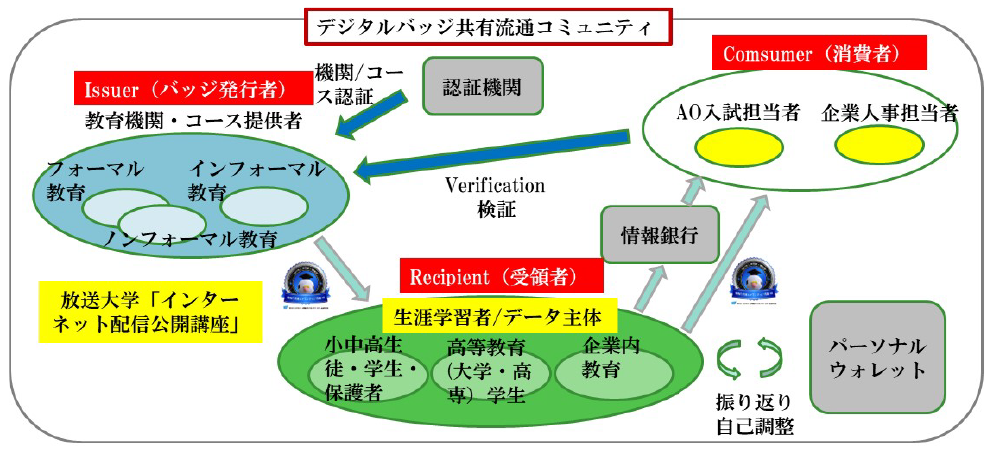
修了者(バッジ受領者)の観点からは,データ主体として,自らの履修証明を自ら管理し自らの判断で利活用することで,第三者(コンシューマという)が利用する路を拓く.さまざまな新たなサービスの可能性が生じ,第三者がバッジ発行機関に情報のフィードバックを行うことで,新たな価値を創出する事業の創出も期待できる(図7).こうした場面では修了証ばかりでなく,内容を秘匿する成績証明書のニーズも高いため,放送大学ではCLR準拠のデジタル証明書や学生用ウォレットの概念実証(PoC)を行った[32].
電子履修証明エコシステムのデータ連携において,システムやツールのデータモデルや通信プロトコルを規定する技術標準と,データの内容(いわゆるペイロード)に関するデータ標準は分けて考えることが重要である.前者はできるだけユニバーサルな標準をめざすべきであるが,後者は使用する文脈によってローカライズする必要があり,開発や検証の方法も異なる.
5.2 学習ePortalとMEXCBT(メクビット)
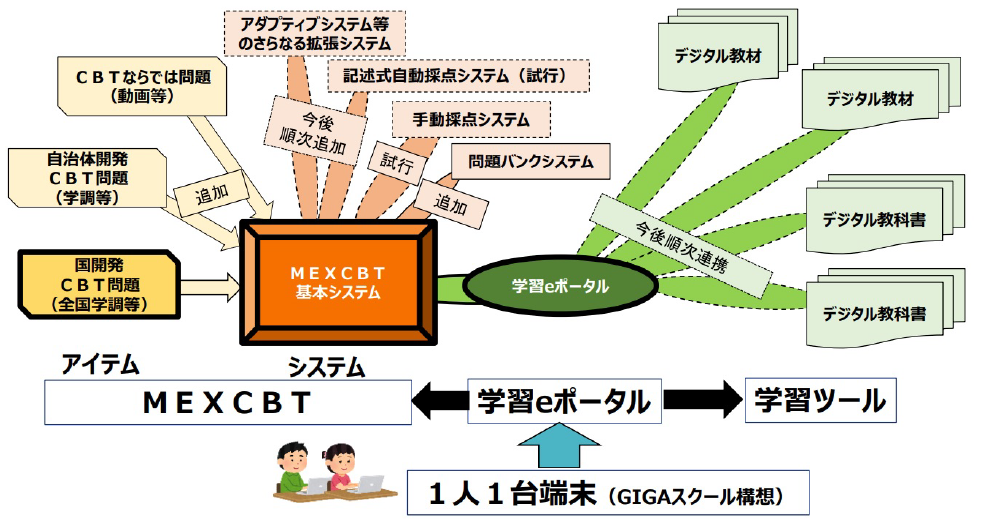
政府の進めるGIGAスクールプロジェクトは,規模および政策目標の革新性で世界でも類例を見ないものである.小中学校生全員(さらに高校でも展開予定)に端末を配布し,1人1台コンピュータ(インターネット)環境を実現したこと自体挑戦的な取り組みであるが,掲げられている目標(たとえば,公正で個別最適化された学び,そしてオンライン授業の併用など)を考えると,コンテンツ・ツール・実践ノウハウなど,さまざまな要素において,生徒・学生など学習者および教師に対する支援を自動化する検討が必要である.
組合せGIGAスクール構想を支えるものとして整備されているのが,「学習eポータル」と「MEXCBT」である(図8)[33].「MEXCBT」とは,文部科学省の英語略称であるMEXT(Ministry of Education, Culture, Sports, Science and Technology)とコンピュータ支援テスト(Computer-Based Testing)の頭文字CBTをあわせた造語である.その基本的な機能は,問題を作成し,蓄積管理し,さらに問題を組合せでテストを実施することである.一方,「学習eポータル」は初等中等教育向けの学習管理システムというべきもので,教育委員会や企業が提供する.2022年12月の時点で,「学習eポータル」事業者として6事業者が明らかになっている.エンドユーザである教師や児童・学生から見ると,まず教育委員会や学校が契約した「学習eポータル」にログインし,ついで外部教育リソースにアクセスすることになる.MEXCBTも有力な接続先の1つであるが,「学習eポータル」事業者としては,エンドユーザのニーズも勘案し,さまざまな出版社やツールベンダにも接続できるようにする.こうしたシステム間の連携には,LTIやOneRosterが使用されるほか,MEXCBTではテストおよびテスト問題のデータモデルにQTIが使われている.こうした相互運用性を高めることで,プロバイダーを超えたコンテンツやテスト問題の取得や将来的には成績情報のフィードバックの自動化も可能となり,「公正に個別最適化された学び」のためのデジタルエコシステムが実現される.
6.展望
メタバースもAIも,データ連携やビッグデータがあって初めて,これまでになかったサービスを実現できる.これは教育や学習の分野でも同じであり,相互運用性はさらに重要な特徴となる.
6.1 健全なデジタルエコシステムを維持するために
デジタルエコシステムは,技術的にはWeb3.0やAIをベースに,ポストコロナ時代の新たな価値観の実現をめざす社会やコミュニティの社会基盤を提供するビジネスモデルと期待される.民主主義の理念の上に,DEI(多様性・公正性・包摂性)などの新たな価値を実現していくことから,規模の大小にかかわらず,それぞれの特色を活かしたプレイヤ,製品・サービスが尊重され,ニッチ(生態学地位)を確保するという形態が期待される.対極には,資金や法的拘束力を背景に,必要な製品・サービスを買収や法的規制により囲い込むという方略があり得るわけであるが,こうしたビジネスモデルのいずれが成功するのかは,歴史的な評価を待つ必要がある.ここでは,こうしたデジタルエコシステムが有効に機能するビジネス規範について,若干考察する.
- 模倣開発と自前主義は,SDGsの観点からも非効率的である
インターネットの世界では,アイディアも含め,その出自を検索できるので,これは当然のこととしてなくなるだろう.プログラマーも同じで,コピペ(コピー&ペースト)ばかりでなく,リバースエンジニアリングを行った場合でもオリジナルに敬意を表し,出自を明記する.一方,権利者としてのプレイヤも,デジタルエコシステムにおいて独占性を行使し不当な利用制限を行わないといった配慮が必要である.
- 共創と競争のルールを明確にする
デジタルエコシステムにおいて,既存の開発物を前提にした開発が日常化すると,開発者間で共有,共同開発する部分(共創分野)と,開発者の独自性を発揮する部分(競争分野)を区別し,参加者の間で合意を図る必要もでてくる.技術標準の開発は前者に位置づけられるものであるが,その主体がだれか(国,標準化団体など)についても,意見の調整が必要になる.また,その運用にあたっては,新たなビジネス規範も必要になる.
- 研究者倫理と国際標準化活動
国際標準化の分野は,コミュニティで合意を図っていく過程であるので,その実現方法に新規性,独自性が発揮されることはあっても,合意そのものに独占的権利を認め囲い込むことはそぐわない.したがって,1EdTech Consortiumを含め国際標準化の過程では,オープン・スタンダードを理念とし,技術標準をまとめる際にも,Localizationの必要性を認めつつも,独自性をもって評価することはしない.こうした作業に従事する研究者は,技術開発にくわえコミュニティ内の調整など多大な労力を求められるが,独創性を求める学術論文として発表できるわけではないので,その評価については別の尺度が必要である.プラクティス論文はこうした分野を救済するものともいえ,大変期待している.
6.2 AIへの対応
教育分野におけるAIの利用については,大きく2つの可能性が期待される.1つは,匿名化されたビッグデータから,新たな知識が発見されること,もう1つは,学習のパーソナル化においてその(半)自動化に貢献することである.前者については,ガートナーのハイプサイクル(高等教育2022)ではすでに普及期にあるAIであるが,さまざまな教育情報データでも一元的に管理できた範囲内でビッグデータの分析が始まっている.学習・教育や人材開発においても,パーソナル化(例,公正に個別最適化された学び)が達成すべき理想として挙げられている以上,後者の利用も今後進むことが予想され,製品としてのAIチュータツールの組み込みなどを想定すると,人工知能(AI)の標準化への対応は不可避と予見される.そこでは,プラットフォーム・アグノスティック(agnostic),データ・アグノスティックといった考え方が主流を占めるのであろう.なお,「アグノスティック(agnostic)であるとは,ソフトウェアやハードウェアが,特定の プロトコル,プログラミング言語,オペレーティング・システムに依存しない,あるいはその仕様の詳細に関知しない設計であることを指す」[34].学習・教育分野における技術標準をボトムアップ的にフォーラム(コンソーシアム)標準として開発してきた1EdTech Consortiumでも,基本的にはデジュール標準が定まれば,それをベースに再構成していくことになる.1EdTech Consortiumは,教育・人材開発分野に特化した30カ国の800を超える産官学のステークホルダーが参加する団体であり,デジュール団体との意見交換もなされている.この点において,会員の意見が反映される1EdTech Consortiumでは至って柔軟であり,OAuth2.0 やOpenID Connectの普及によるLTI 2からLTI 1.3への変更や,W3C Verifiable CredentialをベースにしたOBv3やCLR2.0の開発にその事例を見ることができる.この標準が受け入れられるまでには,ツールの内部を問わない(ブラックボックスとして扱える)LTI 1.3が業界には受け入れられるのではないか.AIの社会実装にともない,既存の技術標準の改訂や新たな技術標準の開発が期待される.
AIチュータツールの開発において,汎用的な部分については,前者の成果が活用されるが,問題は個々のAIツールのチューニングの部分である.一般には,より良質でより大量のデータを与えることによってAIのパーソナル化は高度に(より効率的でより発展的に)実現される.こうした分野でさまざまな格差が生じないよう,ツールばかりでなく学習データのオープン化についても十分配慮がなされる必要がある.
6.3 国家的なデータインフラの整備
機関やベンダを超えたデータ連携をコミュニティや国レベルの情報インフラの課題としてとらえる場合,それに責任を持つ組織と,大局的見地に立ったアーキテクトの存在は不可欠である.幸い,我が国の場合.デジタル庁が省庁横断的にさまざまなステークホルダー間の調整を行う組織として位置づけられ,そうした役割を果たしつつある.
一方,「データ主権(data sovereignty)」という考え方は,EUの「一般データ保護規則(General Data Protection Regulation, GDPR)」や米国のいくつかの州のデータプライバシーに関する法律等に影響を及ぼしている.インターネットはボーダレスな特性を有するため,国家的なデータインフラには,グローバルな観点で,セキュリティ,プライバシー保護を図る必要があり,国際標準化が1つの解決策となる.すでに,ブロックチェーンなど分散型データ流通技術についても,電子履修証明の分野で利用が始まっている.
謝辞
本研究の実施にあたり,科学研究費補助金(課題番号20H0429)を受けた.1EdTech Consortium,Robert Abel博士,Colin Smythe博士からは資料の提供を受けた.記して謝意を表する.
参考文献
- 1)Lantero, L., Finocchietti, C. and Petrucci, E. : Micro-credentials and Bologna Key Commitments : State of Play in the European Higher Education Area, MICROBOL Project, https://microcredentials.eu/wp-content/uploads/sites/20/2021/02/Microbol_State-of-play-of-MCs-in-the-EHEA.pdf (2021) (参照2023-1-15).
- 2)Binkley, M., Erstad, O., Herman, J., Raizen, S., Ripley, M., Miller-Ricci, M. and Rumble, M. : Defining Twenty-First Century Skills. In P. Griffin, B. McGaw & E. Care (Eds), Assessment and Teaching of 21st Century Skills, Springer, pp.17-66 (2011).
- 3)OECD : Transformative Competencies for 2030. https://www.oecd.org/education/2030-project/teaching-and-learning/learning/transformative-competencies/in_brief_Transformative_Competencies.pdf (2019) (参照2022-12-05)
- 4)EDUCAUSE : The EDUCAUSE Guide to Diversity, Equity, and Inclusion, https://www.educause.edu/about/the-educause-guide-to-diversity-equity-and-inclusion (参照2023-1-15)
- 5)国際連合広報センター:2030アジェンダ,https://www.unic.or.jp/activities/economic_social_development/sustainable_development/2030agenda/ (参照2022-12-05)
- 6)EDUCAUSE : https://www.educause.edu/ (参照2022-12-05)
- 7)1EdTech Consortium : https://www.1edtech.org/ (参照2022-12-05)
- 8)山田恒夫,常盤祐司,梶田将司:次世代電子学習環境(NGDLE)に向けた国際標準化の動向,情報処理,Vol.58, No.5, pp.412-415 (2017).
- 9)Abel, R., Brown, M. and Suess, J. : A New Architecture for Learning, Educause Review, Vol.48, No.5, pp.88-102 (2013).
- 10)Brown, M., Dehoney, J. and Millichap, N. : What’s NEXT for the LMS? Educause Review, Vol.50, No.4, pp.40-51 (2015).
- 11)Brown, M. : The NGDLE : We Are the Architects, EDUCAUSE Review, JULY/AUGUST 2017, pp.11-18 (2017).
- 12)1EdTech Security Framework, https://www.imsglobal.org/spec/security/v1p0/ (参照2022-12-05)
- 13)Abel, R. : Presentation at IMS Japan Conference 2017 (2017).
- 14)山田恒夫:MOOCと学習解析,教育革新のための情報基盤に向けて,情報処理学会論文誌「教育とコンピュータ」,Vol.1, No.4, pp.1-11 (2015).
- 15)山田恒夫:モル行動,分子的行動,中島義明,安藤清志,子安増生,坂野雄二,繁枡数男,立花政夫,箱田裕司(編):心理学辞典,有斐閣(1999).
- 16)日本IMS協会:https://www.imsjapan.org/ (参照2022-12-05)
- 17)常盤祐司,山田恒夫:ぺた語義,学習基盤を拡張する国際技術標準IMS LTI 1.3,第1回 LTI 1.3の機能と意義,情報処理,Vol.63, No.6, pp.293-297, http://doi.org/10.20729/00217812 (2022)
- 18)田中頼人:ぺた語義,学習基盤を拡張する国際技術標準 IMS LTI 1.3,第2回 LTI 1.3開発のための資料とサービス,情報処理,Vol.63 No.7, pp.347-350, http://doi.org/10.20729/00218434 (2022)
- 19)藤原茂雄,秦 隆博:ぺた語義,学習基盤を拡張する国際技術標準 IMS LTI 1.3,第3回LTI 1.3 活用事例と適合試験,情報処理,Vol.63, No.9, pp.507-510, http://doi.org/10.20729/00219007 (2022)
- 20)山田恒夫:ぺた語義,学習目標と評価ルーブリックのための技術標準,デジタルエコシステムをトップダウンでイメージする,情報処理,Vol.62, No.10, pp.549, http://id.nii.ac.jp/1001/00212784/ (2021)
- 21)宮崎 誠:ぺた語義,IMS CASEの仕様とその可能性,情報処理,Vol.62, No.10, pp.550-553, http://id.nii.ac.jp/1001/00212785/ (2021)
- 22)1EdTech Data Privacy : https://www.imsglobal.org/spec/privacy/v1p0 (参照2022-12-05)
- 23)Advanced Distributed Learning : https://www.adlnet.gov/ (参照2022-12-05)
- 24)Experience API (xAPI) Standard : https://adlnet.gov/projects/xapi/ (参照2023-1-15)
- 25)1EdTech Question & Test Interoperability (QTI) 3.0 Beginner's Guide : https://www.imsglobal.org/spec/qti/v3p0/guide (参照2022-12-05)
- 26)Compatibility Check : https://www.imsglobal.org/about/compatibility-check (参照2022-12-05)
- 27)TrustEd Apps Directory : https://site.imsglobal.org/certifications (参照2022-12-05)
- 28)Learning Impact Awards : https://www.imsglobal.org/lili/awards.html (参照2022-12-05)
- 29)放送大学インターネット配信公開講座 : https://www.ouj.ac.jp/special/AOBA/ (参照2022-12-05)
- 30)一般財団法人オープンバッジ・ネットワーク : https://www.openbadge.or.jp/ (参照2022-12-05)
- 31)Wellspring Initiative : https://www.imsglobal.org/about/wellspring (参照2022-12-05)
- 32)Yamada, T., Fushimi, K., Terada, S., Fujimoto, Y. and Hata, T. : Implementation of a Digital Credential Ecosystem for Informal Dducation at the Open University of Japan, Presented Paper at AAOU Annual Conference 2022 (2022/11/2-4, Ceju, Korea).
- 33)文部科学省CBTシステム(MEXCBT:メクビット)について:https://www.mext.go.jp/content/20230227-mxt_syoto01_000013393_002.pdf (参照2022-12-05)
- 34)アグノスティック(情報工学):https://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%B0%E3%83%8E%E3%82%B9%E3%83%86%E3%82%A3%E3%83%83%E3%82%AF_(%E6%83%85%E5%A0%B1%E5%B7%A5%E5%AD%A6) (参照2023-1-15)

山田恒夫(正会員)tsyamada@ouj.ac.jp
放送大学教授(情報学),(一社)日本IMS協会理事・運営委員長,(一財)オープンバッジ・ネットワーク理事,(一社)日本オンライン教育産業協会(JOTEA)理事.
採録決定:2023年1月28日
編集担当:宮下健輔(京都女子大学)