
(邦訳:木生成文法モデルの統計的学習による構文解析)
| 進藤 裕之 奈良先端科学技術大学院大学情報科学研究科 助教 |
[背景]言語の意味理解のために重要な構文解析の高精度化
[問題]構文木を構成する文法規則の統計的自動獲得
[貢献]文脈を広く捉えた文法規則の自動獲得による構文解析の高精度化
英語や日本語など,人が日常的に用いる言葉の意味を計算機で扱う自然言語処理技術は,機械翻訳や自動要約など多くの応用が期待されている分野である.現在,機械翻訳や自動文章校正などのさまざまな自然言語処理アプリケーションが実現されているが,精度が十分であるとはいえず,人間と同様の意味理解レベルに到達するためには,計算機で文の意味を正確に理解する技術を確立する必要がある.
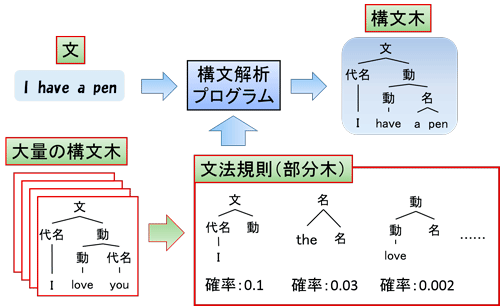
計算機によって文の意味を理解するための重要なステップとして,構文解析がある.自然言語処理分野における構文解析とは,文を構成する単語や句の文法的関係を明らかにすることである.たとえば,英語の文:“I have a dream.”では,“I”は代名詞,“have”は動詞,“a dream”は名詞句であり,“I”と“a dream”はそれぞれ,“have”の主語と目的語となって文全体を構成している.このような文法情報は構文木と呼ばれる木構造で表現することができるため,構文解析は,文を入力とし,構文木を出力する問題として定式化される.
構文解析の難しさは,言語のもつ曖昧性に起因する.たとえば,“bank”という単語は“銀行”と“土手”という2つの意味を持つ.また,“美しい高原の少女”という句は,高原が美しい可能性もあれば,少女が美しい場合もある.これらの曖昧性を解消するために,従来の構文解析研究は,あらかじめ大量の構文木から文法規則(部分木)を統計的に獲得し,それらを対象文の解析に適用して,複数の解析結果の可能性が生じた場合には確率の高い解析結果を選択するという手法を発展させてきた.
構文解析の観点からは,少ない種類の部分木の組合せによって全体の構文木を表現できるならば,それらの部分木は汎用性が高く,言語の特性を反映した適切な文法規則であるといえる.たとえば,英語の他動詞“have”の場合,後ろに目的語として名詞句が来る場合が多いので,「“have:動詞”」単独で計算機に記憶しておくよりも,「“have:動詞”+名詞句」という文法規則として記憶するほうが良い.一方,形容詞や副詞のように文法的に必須ではない要素は,他の文法パターンと組み合わせずに,単独で記憶しておくほうが良い場合が多い.このように,構文木をどのように分割して適切な文法規則を獲得するのか,ということが本研究で対象とする問題である.
本研究は,これまでの構文解析をさらに高精度化させることを目的とし,大量の構文木から文法規則を自動的に獲得するいくつかの手法を提案している.従来の文脈自由文法や木置換文法と呼ばれる文法理論に基づく構文解析では,連続する部分木を組み合わせて全体の構文木を生成する方法であったが,本研究では,部分木の挿入操作を導入することにより,非連続な部分木を文法規則として獲得することが可能となった.また,文脈の情報を広く捉えるために,シンボル細分化木置換文法と呼ばれる確率モデルを新たに考案し,複雑な文法規則を自動的に獲得することが可能となった.本研究で自動的に獲得した文法規則を用いて構文解析を行ったところ,従来よりも高精度に,かつ少ない文法規則で構文解析を行うことが可能となった.,
計算機によって文の意味を理解するための重要なステップとして,構文解析がある.自然言語処理分野における構文解析とは,文を構成する単語や句の文法的関係を明らかにすることである.たとえば,英語の文:“I have a dream.”では,“I”は代名詞,“have”は動詞,“a dream”は名詞句であり,“I”と“a dream”はそれぞれ,“have”の主語と目的語となって文全体を構成している.このような文法情報は構文木と呼ばれる木構造で表現することができるため,構文解析は,文を入力とし,構文木を出力する問題として定式化される.
構文解析の難しさは,言語のもつ曖昧性に起因する.たとえば,“bank”という単語は“銀行”と“土手”という2つの意味を持つ.また,“美しい高原の少女”という句は,高原が美しい可能性もあれば,少女が美しい場合もある.これらの曖昧性を解消するために,従来の構文解析研究は,あらかじめ大量の構文木から文法規則(部分木)を統計的に獲得し,それらを対象文の解析に適用して,複数の解析結果の可能性が生じた場合には確率の高い解析結果を選択するという手法を発展させてきた.
構文解析の観点からは,少ない種類の部分木の組合せによって全体の構文木を表現できるならば,それらの部分木は汎用性が高く,言語の特性を反映した適切な文法規則であるといえる.たとえば,英語の他動詞“have”の場合,後ろに目的語として名詞句が来る場合が多いので,「“have:動詞”」単独で計算機に記憶しておくよりも,「“have:動詞”+名詞句」という文法規則として記憶するほうが良い.一方,形容詞や副詞のように文法的に必須ではない要素は,他の文法パターンと組み合わせずに,単独で記憶しておくほうが良い場合が多い.このように,構文木をどのように分割して適切な文法規則を獲得するのか,ということが本研究で対象とする問題である.
本研究は,これまでの構文解析をさらに高精度化させることを目的とし,大量の構文木から文法規則を自動的に獲得するいくつかの手法を提案している.従来の文脈自由文法や木置換文法と呼ばれる文法理論に基づく構文解析では,連続する部分木を組み合わせて全体の構文木を生成する方法であったが,本研究では,部分木の挿入操作を導入することにより,非連続な部分木を文法規則として獲得することが可能となった.また,文脈の情報を広く捉えるために,シンボル細分化木置換文法と呼ばれる確率モデルを新たに考案し,複雑な文法規則を自動的に獲得することが可能となった.本研究で自動的に獲得した文法規則を用いて構文解析を行ったところ,従来よりも高精度に,かつ少ない文法規則で構文解析を行うことが可能となった.,
(2014年5月31日受付)