
(邦訳:圧縮とマルチキャストを用いた低遅延オンチップネットワーク)
| 和 遠 東京大学情報理工学系研究科 特任研究員 |
[背景]マルチコアプロセッサの規模拡張に伴ってオンチップネットワークの普及と大規模化
[問題]オンチップネットワークの大規模化によりプロセッサ内のコア間の通信遅延が増大
[貢献]低遅延オンチップネットワークの提案と実現
[問題]オンチップネットワークの大規模化によりプロセッサ内のコア間の通信遅延が増大
[貢献]低遅延オンチップネットワークの提案と実現
近年,半導体プロセスの微細化とプロセッサの電力制限によりチップ内に複数のプロセッサコアを搭載する.この現状においてチップ上のデータ転送がより厳しい性能に直面しているので,オンチップネットワーク(NoC)の登場と普及が出てきた.マルチコアプロセッサにおけるコア数の増大はNoCの規模を拡大させたので,遅延が非常に重要な問題になる.NoCはメモリ階層の一部分となるので,その遅延はプロセッサコアの間の転送時間を決定すると同時にコンピュータシステムの全体的な性能も決定する.したがって本研究の目的はNoCの通信遅延を低減することである.
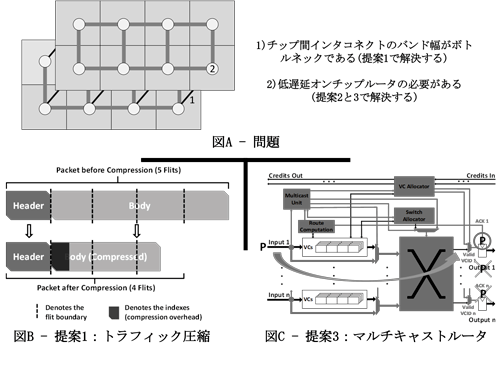
具体的には本研究では3つの提案をし,この3つの提案で2つの面からこの問題(図A)を解決する.まず,第一の提案はNoCのバンド幅の改善である.近年最も流行しているNoCはメッシュトポロジである.実験により,メッシュトポロジのバンド幅が多くのワークロードには余裕があるが,チップを積み重ねるとき(3D IC),状況が変化する.面積などの制約によって,チップ間インタコネクトのバンド幅がボトルネックである.そうなると通信遅延が大幅に増加する.この問題に関して本研究の解決案はNoC上でトラフィック圧縮(図B)を行い,もし成功すればパケットのサイズが小さくなり,チップ間バンド幅が小さいことによる通信遅延を低減できる.実験の結果から,この提案が不規則なバンド幅のNoC,たとえば3D ICのような通信遅延を改善する効果がわかった.
次に,他の2つの提案はNoCの通信遅延を直接に改善する.NoCの中において,パケットの経路はルータとリンクからなる.長い経路のパケットが多くのルータを経由する必要がある.したがってオンチップルータの遅延を低減することが非常に重要である.そのために,本論文の第二の提案では低遅延オンチップルータを,既存の予測ルータに基づいて提案した.予測ルータの原理は予測によるパケットを1サイクルで転送することである.しかし,ルータ内でマルチキャストが許される場合において,同時に複数の予測アルゴリズムを使用することで予測のヒット率を向上でき,したがって1サイクルで転送されるパケットの割合が大きくなる.この提案を通してヒット率を平均に15%向上でき,既存の予測ルータに対して提案予測ルータ(図略)がシステムの性能を平均に3.5%向上する.さらに,多くのワークロードに対し,メッシュトポロジのバンド幅に余裕があるために,多くの時間内においてルータ内に同時に1つのパケットしか存在していないことを観測した.この現象から2つの意味がわかる.①1つのパケットがルータの全部の出力上にマルチキャストされると,必ずある1つの出力が正解である.つまり,ルーティングが必ず成功する.②マルチキャストの採用により,もはや予測は必要がないので,ルータの構造が簡単になる.したがって,本論文の第三の提案がマルチキャストルータ(図C)である.マルチキャストルータの原理はルータのバンド幅に余裕がある場合,マルチキャストによりパケットを1サイクルで転送する.予測ルータに対し,この提案を通してシステムの性能を平均に5%向上できると同時に消費される電力が少なくなる.
具体的には本研究では3つの提案をし,この3つの提案で2つの面からこの問題(図A)を解決する.まず,第一の提案はNoCのバンド幅の改善である.近年最も流行しているNoCはメッシュトポロジである.実験により,メッシュトポロジのバンド幅が多くのワークロードには余裕があるが,チップを積み重ねるとき(3D IC),状況が変化する.面積などの制約によって,チップ間インタコネクトのバンド幅がボトルネックである.そうなると通信遅延が大幅に増加する.この問題に関して本研究の解決案はNoC上でトラフィック圧縮(図B)を行い,もし成功すればパケットのサイズが小さくなり,チップ間バンド幅が小さいことによる通信遅延を低減できる.実験の結果から,この提案が不規則なバンド幅のNoC,たとえば3D ICのような通信遅延を改善する効果がわかった.
次に,他の2つの提案はNoCの通信遅延を直接に改善する.NoCの中において,パケットの経路はルータとリンクからなる.長い経路のパケットが多くのルータを経由する必要がある.したがってオンチップルータの遅延を低減することが非常に重要である.そのために,本論文の第二の提案では低遅延オンチップルータを,既存の予測ルータに基づいて提案した.予測ルータの原理は予測によるパケットを1サイクルで転送することである.しかし,ルータ内でマルチキャストが許される場合において,同時に複数の予測アルゴリズムを使用することで予測のヒット率を向上でき,したがって1サイクルで転送されるパケットの割合が大きくなる.この提案を通してヒット率を平均に15%向上でき,既存の予測ルータに対して提案予測ルータ(図略)がシステムの性能を平均に3.5%向上する.さらに,多くのワークロードに対し,メッシュトポロジのバンド幅に余裕があるために,多くの時間内においてルータ内に同時に1つのパケットしか存在していないことを観測した.この現象から2つの意味がわかる.①1つのパケットがルータの全部の出力上にマルチキャストされると,必ずある1つの出力が正解である.つまり,ルーティングが必ず成功する.②マルチキャストの採用により,もはや予測は必要がないので,ルータの構造が簡単になる.したがって,本論文の第三の提案がマルチキャストルータ(図C)である.マルチキャストルータの原理はルータのバンド幅に余裕がある場合,マルチキャストによりパケットを1サイクルで転送する.予測ルータに対し,この提案を通してシステムの性能を平均に5%向上できると同時に消費される電力が少なくなる.
(2014年5月31日受付)