
(邦訳:テキスト圧縮と圧縮文字列マイニング)
| 後藤 啓介 富士通研究所 研究員 |
[背景]情報爆発,非定型データの氾濫
[問題]大規模データに適した利活用方法の開発
[貢献]圧縮データ処理に基づく大規模データの利活用方法の提案
[問題]大規模データに適した利活用方法の開発
[貢献]圧縮データ処理に基づく大規模データの利活用方法の提案
インターネット上を流通するデータ量は指数関数的に増大し,科学技術分野ではセンシング技術等の発達を背景に種々の観測・実験データが巨大化している.また,企業や機関等においては保管が必要な内部文書が増加の一途を辿っている.これらのデータの多くは定まった形式を持たない非定型データ,すなわち,文字列データと捉えることができ,このような大規模文字列データから価値ある知識を抽出し利活用したいという要求が,学界のみならず産業界でも高まっている.
通常,大規模データの処理には膨大な計算資源が必要となるため,計算対象とするデータ量を制限せざるを得ず,データを十分に利活用できないというジレンマに陥りがちである.そこで本研究では,「データ圧縮」を核に据え,大規模文字列データマイニングの高速化と省領域化の両方を同時に達成する手法の開発に取り組んだ.
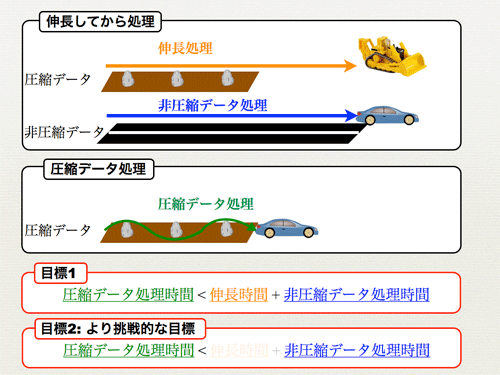
データ圧縮とは,データに含まれる規則性や統計的性質に着目することにより冗長性を除去し,データの表現長を短くする技術である.データ圧縮により記憶容量や通信コストを節約することができるが,その反面,データ利用時には伸張作業が必要となる.だがもし,圧縮データを伸張することなく直接処理できれば,このオーバヘッドは解消される.このような背景の下,「圧縮データ処理」の研究は,1990年代より今日まで世界の各所で行われてきた.この研究の目標は,
[目標1]伸張時間 + 非圧縮データ処理時間 > 圧縮データ処理時間
であり,主にパターン照合問題を対象としさまざまなデータ圧縮形式について目標1が達成されている.一方,より挑戦的な目標として,
[目標2]非圧縮データ処理時間 > 圧縮データ処理時間
があり,いくつかの圧縮形式に関してこの目標が達成できることが示されている.これは,圧縮を高速化のための前処理と捉えるものであり,「圧縮による高速化」という新しい研究潮流に繋がっている.
しかしながら,圧縮データ処理の研究の多くはパターン照合問題やその変種に限られており,文字列データマイニングにかかわる文字列処理については,ほとんど行われていなかった.そこで本研究では,文字列データマイニングに必要な文字列処理としてq-グラム頻度統計問題およびその変種に取り組んだ.ここで,q-グラムとは,文字列に出現する長さqの部分文字列をいい,q-グラム頻度とは,文字列に出現する全q-グラムの頻度を求める問題をいう.q-グラム頻度統計は文字列の特徴を表す重要な指標のひとつであり,機械学習や分類問題などに応用されている.
圧縮による高速化と省領域化を同時に達成することを研究の主眼とし,その結果として以下の2つの研究成果を上げた.また,計算機実験により[目標1]並びに[目標2]を達成し,実用的な優位性があることを確認した.
(A)圧縮データ上で動作する効率的なq-グラム頻度統計アルゴリズムの開発.
(B)圧縮データ処理に適した圧縮データを出力する,高速かつ省領域な圧縮アルゴリズムの開発.
通常,大規模データの処理には膨大な計算資源が必要となるため,計算対象とするデータ量を制限せざるを得ず,データを十分に利活用できないというジレンマに陥りがちである.そこで本研究では,「データ圧縮」を核に据え,大規模文字列データマイニングの高速化と省領域化の両方を同時に達成する手法の開発に取り組んだ.
データ圧縮とは,データに含まれる規則性や統計的性質に着目することにより冗長性を除去し,データの表現長を短くする技術である.データ圧縮により記憶容量や通信コストを節約することができるが,その反面,データ利用時には伸張作業が必要となる.だがもし,圧縮データを伸張することなく直接処理できれば,このオーバヘッドは解消される.このような背景の下,「圧縮データ処理」の研究は,1990年代より今日まで世界の各所で行われてきた.この研究の目標は,
[目標1]伸張時間 + 非圧縮データ処理時間 > 圧縮データ処理時間
であり,主にパターン照合問題を対象としさまざまなデータ圧縮形式について目標1が達成されている.一方,より挑戦的な目標として,
[目標2]非圧縮データ処理時間 > 圧縮データ処理時間
があり,いくつかの圧縮形式に関してこの目標が達成できることが示されている.これは,圧縮を高速化のための前処理と捉えるものであり,「圧縮による高速化」という新しい研究潮流に繋がっている.
しかしながら,圧縮データ処理の研究の多くはパターン照合問題やその変種に限られており,文字列データマイニングにかかわる文字列処理については,ほとんど行われていなかった.そこで本研究では,文字列データマイニングに必要な文字列処理としてq-グラム頻度統計問題およびその変種に取り組んだ.ここで,q-グラムとは,文字列に出現する長さqの部分文字列をいい,q-グラム頻度とは,文字列に出現する全q-グラムの頻度を求める問題をいう.q-グラム頻度統計は文字列の特徴を表す重要な指標のひとつであり,機械学習や分類問題などに応用されている.
圧縮による高速化と省領域化を同時に達成することを研究の主眼とし,その結果として以下の2つの研究成果を上げた.また,計算機実験により[目標1]並びに[目標2]を達成し,実用的な優位性があることを確認した.
(A)圧縮データ上で動作する効率的なq-グラム頻度統計アルゴリズムの開発.
(B)圧縮データ処理に適した圧縮データを出力する,高速かつ省領域な圧縮アルゴリズムの開発.
(2014年5月26日受付)