
| 万代 悠作 トヨタ・リサーチ・インスティテュート・アドバンスト・デベロップメント Engineer |
キーワード
| ゲームAI | 木探索 | 深層学習 |
[背景]ゲームをプレイする人工知能は近年飛躍的に性能向上
[問題]意思決定時の木探索においてゲームの知識を有効活用
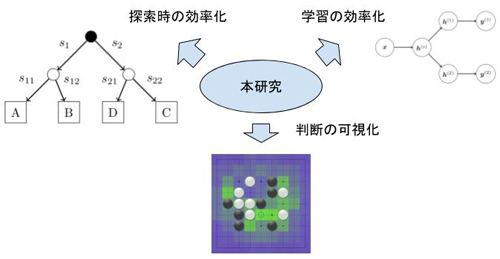
[貢献]探索前・探索中に有効にゲームの知識を獲得する手法を提案
[貢献]探索前・探索中に有効にゲームの知識を獲得する手法を提案
本研究ではゲームを題材に,対象となるゲームの知識をゲーム木探索に利用するためにどのように効率よく獲得すればよいか,また獲得した知識をどのように評価するかについての研究を行った.
ゲーム木探索とは与えられたゲームの利得を明らかにするために行われる探索手法であり,ゲームをうまくプレイするためには木探索によって先読みをする必要がある.ゲーム木探索に関してはこれまでにいくつもの先行研究が存在し,優れた手法によっていくつかのゲームでは人間のトッププレイヤーよりも強いコンピュータプレイヤーを作成することに成功している.一般的に広く遊ばれているようなゲームでは現実的な時間ですべての展開を探索することは不可能であるため,評価関数と呼ばれるゲームの局面の良さを測る関数を用いてヒューリスティックに探索を行う.評価関数とは対象となるゲームの知識を関数の形で表現したものであり,評価関数が正確なほどそのゲームをうまくプレイできる.コンピュータプレイヤーの強さは,実行されるコンピュータの性能と探索アルゴリズムの巧拙,そして評価関数の正確性によって決定される.評価関数は人間が関数の形を設計し,機械学習によって関数のパラメータの重みを調整するという手法が主流である.
しかし棋譜が存在しないゲームにおいて評価関数を学習する際には上記のような教師あり学習を行うことが不可能であるし,棋譜が存在するが数が少ないようなゲームでは少ない棋譜を用いて効率的に学習をする必要がある.また別の状況として,事前に学習ができないようなゲームも考え得る.たとえばGeneral Game Playingに代表される,初見のゲームをうまくプレイするようなコンピュータプレイヤーを作成することを目的とした環境では強化学習,教師あり学習ともに行うことができないため,うまくゲームをプレイするためには探索と同時にそのゲームの知識をなんらかの方法で学習することが重要である.
本研究ではそのような問題を念頭に,ゲーム木探索とともに利用する知識の獲得をいかに効率的に獲得できるかという点について研究を行った.具体的には対象とするゲームに関して事前に強いプレイヤーの棋譜が存在する場合と,事前に学習を行えない場合の2つの場合について研究を行った.
また得られた知識を検証するという目的で,上記2つそれぞれに対応する手法を検証した.最初の事前知識が得られず,探索アルゴリズムによって知識を逐次得ていくようなアルゴリズムの評価を行えるようなテストベッドを考案し,そのいくつかの性質について議論した.提案したテストベッドは局面の特徴を用いない既存の標準的なテストベッドを自然な形で拡張することにより,既存のテストベッドの良い性質を保ったまま利用できるものである.2つ目の,ゲームに関する事前知識が得られ効率的に学習が行えた場合においては,得られた知識の妥当性を人間が検証できるような方法について議論を行った.
ゲーム木探索とは与えられたゲームの利得を明らかにするために行われる探索手法であり,ゲームをうまくプレイするためには木探索によって先読みをする必要がある.ゲーム木探索に関してはこれまでにいくつもの先行研究が存在し,優れた手法によっていくつかのゲームでは人間のトッププレイヤーよりも強いコンピュータプレイヤーを作成することに成功している.一般的に広く遊ばれているようなゲームでは現実的な時間ですべての展開を探索することは不可能であるため,評価関数と呼ばれるゲームの局面の良さを測る関数を用いてヒューリスティックに探索を行う.評価関数とは対象となるゲームの知識を関数の形で表現したものであり,評価関数が正確なほどそのゲームをうまくプレイできる.コンピュータプレイヤーの強さは,実行されるコンピュータの性能と探索アルゴリズムの巧拙,そして評価関数の正確性によって決定される.評価関数は人間が関数の形を設計し,機械学習によって関数のパラメータの重みを調整するという手法が主流である.
しかし棋譜が存在しないゲームにおいて評価関数を学習する際には上記のような教師あり学習を行うことが不可能であるし,棋譜が存在するが数が少ないようなゲームでは少ない棋譜を用いて効率的に学習をする必要がある.また別の状況として,事前に学習ができないようなゲームも考え得る.たとえばGeneral Game Playingに代表される,初見のゲームをうまくプレイするようなコンピュータプレイヤーを作成することを目的とした環境では強化学習,教師あり学習ともに行うことができないため,うまくゲームをプレイするためには探索と同時にそのゲームの知識をなんらかの方法で学習することが重要である.
本研究ではそのような問題を念頭に,ゲーム木探索とともに利用する知識の獲得をいかに効率的に獲得できるかという点について研究を行った.具体的には対象とするゲームに関して事前に強いプレイヤーの棋譜が存在する場合と,事前に学習を行えない場合の2つの場合について研究を行った.
また得られた知識を検証するという目的で,上記2つそれぞれに対応する手法を検証した.最初の事前知識が得られず,探索アルゴリズムによって知識を逐次得ていくようなアルゴリズムの評価を行えるようなテストベッドを考案し,そのいくつかの性質について議論した.提案したテストベッドは局面の特徴を用いない既存の標準的なテストベッドを自然な形で拡張することにより,既存のテストベッドの良い性質を保ったまま利用できるものである.2つ目の,ゲームに関する事前知識が得られ効率的に学習が行えた場合においては,得られた知識の妥当性を人間が検証できるような方法について議論を行った.
(2019年6月11日受付)