
(邦訳:音声認識のための潜在語言語モデルに関する研究)
| 増村 亮 日本電信電話(株) NTTメディアインテリジェンス研究所 研究員 |
[背景]音声認識システムの適用領域の拡大
[問題]学習タスクと実タスクのミスマッチによる音声認識の性能劣化
[貢献]タスクミスマッチに頑健な音声認識用言語モデリングの確立
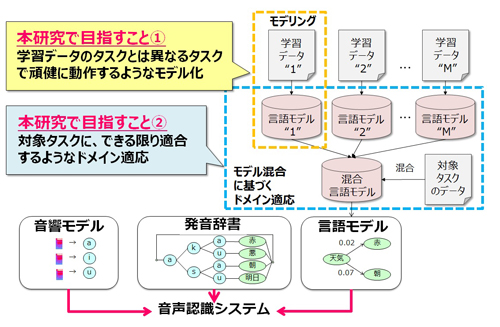
本研究では,話し言葉などの実用的な音声認識タスクの性能向上を目指して,統計的言語モデリング技術の高度化を目指す.言語モデルは,音声認識における言語的制約を担うモデルであり,話題やスタイルなどに関して,対象の音声認識タスクと適合した学習データを大量に得ることができれば,性能の高いモデル化が可能である.しかしながら,話し言葉等の実用的なタスクでは,対象の音声認識タスクに適合した学習データを十分に得ることは非現実的である.そこで本研究では,対象タスクとは異なるタスクの学習データを有効活用することが可能な言語モデリング技術の確立に取り組んだ.
本研究では近年機械学習の分野で提案された潜在語言語モデルの音声認識タスクでの利用に着眼する.潜在語言語モデルの特徴は,潜在語と呼ばれる潜在変数を有する点であり,潜在語は語彙空間上の具体的な単語として表される.潜在語言語モデルに着眼した理由は次の2点である.まず1点目は,潜在語空間に基づき単語間の意味的関係性を柔軟に捉えることで,学習データのタスクと異なるタスクでも頑健に動作する言語モデリングが期待できるからである.さらに2点目は,潜在語が具体的な単語として表されるという特徴を活かすことで,それぞれ異なる学習データから構築した複数の言語モデルを潜在語空間上で統合できるからである.つまり,異なるタスクの学習データを柔軟に活かしたドメイン適応技術の確立が期待できる.
本研究の具体的な貢献は,次の4点である.1点目の貢献は,潜在語言語モデルを実用的な音声認識で利用するために,近似手法を確立した点である.潜在語言語モデルは,膨大な潜在変数を持つため,単語生成確率の算出を実用的な計算量で行うことは困難である.そこで本研究では,1パスの音声認識デコーダで直接利用することが可能なN-gram近似と,音声認識仮説のリスコアリング時に利用可能なViterbi近似という2つの近似手法を提案した.両者の提案手法により,従来のモデル化方法と比較して,学習データのタスクと異なるタスクでも頑健に動作する音声認識を実現できることを示した.2点目の貢献は,潜在語言語モデルのモデル構造の高度化のために,潜在語間の長距離の関係を捉えることが可能な潜在語リカレントニューラルネットワーク言語モデル,および,潜在語空間の階層的な意味構造を捉えることが可能な階層潜在語言語モデルの2つの新たな言語モデルを確立した点である.これらの手法により,学習データとは異なるタスクにおいて,通常の潜在語言語モデルよりもさらに高い性能の音声認識を実現した.3点目の貢献は,潜在語空間上でのモデル混合に基づくドメイン適応手法を確立した点である.提案手法により,タスクが異なる学習データや,部分的にタスクが適合した学習データを有効活用して,対象の音声認識タスク用の言語モデルを構築できることを示した.4点目の貢献は,潜在語言語モデルを,その他の主要な言語モデル技術と併用した場合に,どのような関係があるのかを明らかにした点である.これにより,教師なし適応や外部言語資源の利用,識別的言語モデルなどとの併用が有効であることを示した.
本研究では近年機械学習の分野で提案された潜在語言語モデルの音声認識タスクでの利用に着眼する.潜在語言語モデルの特徴は,潜在語と呼ばれる潜在変数を有する点であり,潜在語は語彙空間上の具体的な単語として表される.潜在語言語モデルに着眼した理由は次の2点である.まず1点目は,潜在語空間に基づき単語間の意味的関係性を柔軟に捉えることで,学習データのタスクと異なるタスクでも頑健に動作する言語モデリングが期待できるからである.さらに2点目は,潜在語が具体的な単語として表されるという特徴を活かすことで,それぞれ異なる学習データから構築した複数の言語モデルを潜在語空間上で統合できるからである.つまり,異なるタスクの学習データを柔軟に活かしたドメイン適応技術の確立が期待できる.
本研究の具体的な貢献は,次の4点である.1点目の貢献は,潜在語言語モデルを実用的な音声認識で利用するために,近似手法を確立した点である.潜在語言語モデルは,膨大な潜在変数を持つため,単語生成確率の算出を実用的な計算量で行うことは困難である.そこで本研究では,1パスの音声認識デコーダで直接利用することが可能なN-gram近似と,音声認識仮説のリスコアリング時に利用可能なViterbi近似という2つの近似手法を提案した.両者の提案手法により,従来のモデル化方法と比較して,学習データのタスクと異なるタスクでも頑健に動作する音声認識を実現できることを示した.2点目の貢献は,潜在語言語モデルのモデル構造の高度化のために,潜在語間の長距離の関係を捉えることが可能な潜在語リカレントニューラルネットワーク言語モデル,および,潜在語空間の階層的な意味構造を捉えることが可能な階層潜在語言語モデルの2つの新たな言語モデルを確立した点である.これらの手法により,学習データとは異なるタスクにおいて,通常の潜在語言語モデルよりもさらに高い性能の音声認識を実現した.3点目の貢献は,潜在語空間上でのモデル混合に基づくドメイン適応手法を確立した点である.提案手法により,タスクが異なる学習データや,部分的にタスクが適合した学習データを有効活用して,対象の音声認識タスク用の言語モデルを構築できることを示した.4点目の貢献は,潜在語言語モデルを,その他の主要な言語モデル技術と併用した場合に,どのような関係があるのかを明らかにした点である.これにより,教師なし適応や外部言語資源の利用,識別的言語モデルなどとの併用が有効であることを示した.
(2017年5月25日受付)