
(邦訳:発話内・発話間構造を考慮した話者クラスタリング手法の研究)
| 俵 直弘 早稲田大学情報通信学科 助教 |
[背景]マルチメディアデータの利用促進のためのクラスタリング法の重要性
[問題]マルチメディアデータに特有の階層構造を考慮した枠組みが必要
[貢献]雑音等に起因するセグメント内変動に頑健なクラスタリングを実現
近年のデータアーカイビング技術や計算機資源の急速な発展により,超大量のデータに簡単にアクセスができるようになった.日々蓄積されるこれらデータを有効に利用するためには,データの分類・整理を効率的に実現する技術が不可欠であり,そのための基礎技術であるクラスタリング手法の高精度化が求められている.しかし,動画像や音声のようなマルチメディアデータについては,アーカイブの利用に関する要求が急速に高まっているにもかかわらず,データ構造の特殊性により既存のクラスタリング技術の適用は困難で技術は未成熟なままであった.
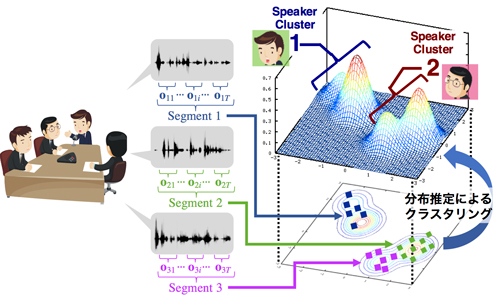
本研究で取り扱うマルチメディアデータに共通する特徴として,個々のデータは複数の観測値の集合として与えられるという点がある.たとえば動画像や音声では,ビデオクリップや発話といった個々のデータは,各時刻の画像や短時間スペクトルなどデータの列として与えられる. ここで発話など上位のデータをセグメントデータ,短時間スペクトルなど上位データを構成する下位データをフレームデータと呼ぶことにすると,上位のセグメントデータを適切にクラスタリングするためには,各データを構成する下位のフレームデータ集合の構造を適切に考慮した枠組みが必要となる.
音声を対象とした話者クラスタリングを例とすると,各発話セグメントを構成する音響特徴量は発話内容や発話スタイルの違い,背景雑音等の影響により同一話者の発話であっても大きく変化する.そのためこれら変動に対し頑健なクラスタリングを実現するためには発話の変動を十分に表現できる枠組みが不可欠となる.しかし,従来のクラスタリング技術は,おおむね個々のデータをベクトル表現したときのベクトルそのものの特徴をもとにクラスタリングする仕組みであって,データを構成する下位データの構造を扱う仕組みではなく,セグメントデータのクラスタリングは不得手であった.
そこで,本研究ではフレームデータの変動により生じる変動構造をセグメント内構造と呼び,この構造を確率分布でモデル化することで,セグメント内変動に対し頑健なクラスタリング法の実現を試みた.このとき分布の推定法としてベイズアプローチに基づく枠組みで定式化することで,セグメント内の構造を考慮したクラスタリングが可能となることを示した.特にマルコフ連鎖モンテカルロ(Markov chain Monte Carlo; MCMC)法に基づく最適化アルゴリズムを導入することで,発話長や発話数が少ない場合においても頑健に分布を推定できる枠組みを提案した.
提案した枠組みを,音声セグメントを対象とした話者クラスタリング問題に適用することで,従来は適用が困難だった雑音や録音環境が未知の条件下においても頑健なクラスタリングが行えることを示した.本研究では適用先を音声クラスタリングに限定したが,本手法は音声以外のセグメントデータにも適用可能であり,広くマルチメディアデータ解析への応用が期待される.
本研究で取り扱うマルチメディアデータに共通する特徴として,個々のデータは複数の観測値の集合として与えられるという点がある.たとえば動画像や音声では,ビデオクリップや発話といった個々のデータは,各時刻の画像や短時間スペクトルなどデータの列として与えられる. ここで発話など上位のデータをセグメントデータ,短時間スペクトルなど上位データを構成する下位データをフレームデータと呼ぶことにすると,上位のセグメントデータを適切にクラスタリングするためには,各データを構成する下位のフレームデータ集合の構造を適切に考慮した枠組みが必要となる.
音声を対象とした話者クラスタリングを例とすると,各発話セグメントを構成する音響特徴量は発話内容や発話スタイルの違い,背景雑音等の影響により同一話者の発話であっても大きく変化する.そのためこれら変動に対し頑健なクラスタリングを実現するためには発話の変動を十分に表現できる枠組みが不可欠となる.しかし,従来のクラスタリング技術は,おおむね個々のデータをベクトル表現したときのベクトルそのものの特徴をもとにクラスタリングする仕組みであって,データを構成する下位データの構造を扱う仕組みではなく,セグメントデータのクラスタリングは不得手であった.
そこで,本研究ではフレームデータの変動により生じる変動構造をセグメント内構造と呼び,この構造を確率分布でモデル化することで,セグメント内変動に対し頑健なクラスタリング法の実現を試みた.このとき分布の推定法としてベイズアプローチに基づく枠組みで定式化することで,セグメント内の構造を考慮したクラスタリングが可能となることを示した.特にマルコフ連鎖モンテカルロ(Markov chain Monte Carlo; MCMC)法に基づく最適化アルゴリズムを導入することで,発話長や発話数が少ない場合においても頑健に分布を推定できる枠組みを提案した.
提案した枠組みを,音声セグメントを対象とした話者クラスタリング問題に適用することで,従来は適用が困難だった雑音や録音環境が未知の条件下においても頑健なクラスタリングが行えることを示した.本研究では適用先を音声クラスタリングに限定したが,本手法は音声以外のセグメントデータにも適用可能であり,広くマルチメディアデータ解析への応用が期待される.
(2017年6月1日受付)