
| 中川 岳 (株)富士通研究所 研究員 |
[背景]メモリシステムの複雑化,システム形態の変化
[問題]効率的なメモリ割り当て,異常なメモリ消費の早期検出
[貢献]メモリ資源の管理指標に関する新たな議論の提起
[問題]効率的なメモリ割り当て,異常なメモリ消費の早期検出
[貢献]メモリ資源の管理指標に関する新たな議論の提起
この研究は計算機システムにおけるリソース管理に関する研究です.中でも特にメモリ管理に焦点を当てています.メモリリソース管理というと「メモリをどれだけ消費したか?」に着目した管理手法が主流です.この従来のメモリ管理に「どのように消費したか?」という情報(メモリ消費に関する経過情報)を加えることで,より高度な管理ができるのではないか? そのアイディアを検証するために実際の問題に適用してみた,というのがこの研究の趣旨です.
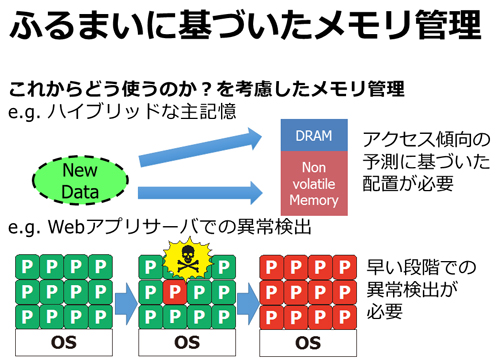
具体的には2つの問題に取り組みました.1つは,不揮発性メモリとDRAMによって構成されるハイブリッドメモリアーキテクチャにおけるデータ配置です.これまでの計算機システムでは,主記憶を構成するメモリ素子は主にDRAMでした.次世代不揮発性メモリ(NVM)の研究開発の進展に伴い,NVMで主記憶空間を構成することが検討されています.NVMを主記憶空間に取り入れることで,DRAMが持つ問題を解決したり,不揮発性を活用した新たな機能を提供できます.しかしながら,現状のNVMの中には,DRAMと比較して書き込みアクセスに短所を持つものがあり,それを克服する手段として,既存のDRAMによる主記憶とNVMによる主記憶を組み合わせることが行われてきました.書き込みの多いデータはDRAMに,書き込みの少ないデータはNVMに配置することで,主記憶にNVMを使用する際の問題を解決することができます.
このハイブリッドメモリにおいては,2つのメモリ素子の間で,データの書き込みアクセスの傾向に基づいて,配置を決定する必要があります.この方法としては,いずれかの領域に配置してみて,実際の書き込みアクセスの挙動に基づいてデータを移動する,という方法が主に検討されていました.しかしながら,この方法には,データが生成された時点で,適切なデータ配置を決定できない,という問題があります.理想的には,データが生成された時点で,データに対する書き込みアクセスの傾向を見積もり,その予想に基づいてデータ配置を決定することが望ましいです.しかしながら,そのような手法は確立されていませんでした.
この問題に対して,この研究では,データの意味(セマンティクス)によって異なる書き込みアクセスのふるまいを利用することを試みました.プログラムが操作するデータは,それぞれのセマンティクスを持っています.また,そのセマンティクスには,それぞれの書き込みアクセスの傾向があります.そのセマンティクスごとの書き込みアクセスの傾向を利用すれば,データが生成された段階で書き込みアクセスの傾向を予測することができます.このアイディアを検証するために,プログラミング言語処理系をベースに,セマンティクスごとの書き込みアクセスのふるまいに基づいたデータ配置手法を設計し,効果をシミュレーションしました.
取り組んだ2つ目の問題は,サーバ環境における,メモリ消費のふるまいを利用した異常なメモリ消費の検出です.詳しく語りたいところですが,紙幅が尽きてしまいましたので,この問題に関しては,ぜひ博論本文をご覧ください.
具体的には2つの問題に取り組みました.1つは,不揮発性メモリとDRAMによって構成されるハイブリッドメモリアーキテクチャにおけるデータ配置です.これまでの計算機システムでは,主記憶を構成するメモリ素子は主にDRAMでした.次世代不揮発性メモリ(NVM)の研究開発の進展に伴い,NVMで主記憶空間を構成することが検討されています.NVMを主記憶空間に取り入れることで,DRAMが持つ問題を解決したり,不揮発性を活用した新たな機能を提供できます.しかしながら,現状のNVMの中には,DRAMと比較して書き込みアクセスに短所を持つものがあり,それを克服する手段として,既存のDRAMによる主記憶とNVMによる主記憶を組み合わせることが行われてきました.書き込みの多いデータはDRAMに,書き込みの少ないデータはNVMに配置することで,主記憶にNVMを使用する際の問題を解決することができます.
このハイブリッドメモリにおいては,2つのメモリ素子の間で,データの書き込みアクセスの傾向に基づいて,配置を決定する必要があります.この方法としては,いずれかの領域に配置してみて,実際の書き込みアクセスの挙動に基づいてデータを移動する,という方法が主に検討されていました.しかしながら,この方法には,データが生成された時点で,適切なデータ配置を決定できない,という問題があります.理想的には,データが生成された時点で,データに対する書き込みアクセスの傾向を見積もり,その予想に基づいてデータ配置を決定することが望ましいです.しかしながら,そのような手法は確立されていませんでした.
この問題に対して,この研究では,データの意味(セマンティクス)によって異なる書き込みアクセスのふるまいを利用することを試みました.プログラムが操作するデータは,それぞれのセマンティクスを持っています.また,そのセマンティクスには,それぞれの書き込みアクセスの傾向があります.そのセマンティクスごとの書き込みアクセスの傾向を利用すれば,データが生成された段階で書き込みアクセスの傾向を予測することができます.このアイディアを検証するために,プログラミング言語処理系をベースに,セマンティクスごとの書き込みアクセスのふるまいに基づいたデータ配置手法を設計し,効果をシミュレーションしました.
取り組んだ2つ目の問題は,サーバ環境における,メモリ消費のふるまいを利用した異常なメモリ消費の検出です.詳しく語りたいところですが,紙幅が尽きてしまいましたので,この問題に関しては,ぜひ博論本文をご覧ください.
(2017年6月2日受付)