
(邦訳:自然言語の分散表現へのエンコードに関する研究)
| 高瀬 翔 NTTコミュニケーション科学基礎研究所 |
[背景]単語の分散表現構築手法の発展
[問題]句や文の分散表現をどのように計算するか
[貢献]単語の分散表現合成手法の提案と応用タスクでの評価
自然言語で書かれた文書の意味をモデル化することは,自然言語処理における主要な課題の一つであり,関係抽出,含意関係認識,言い換え抽出など,多くの応用タスクを解くために,なくてはならない技術である.文書の意味を計算するためには,文書を構成する単語や句の意味を計算できる必要がある.たとえば「タバコは肺癌を引き起こす」という文と「喫煙は癌の危険性を高める」という文について,主語である「タバコ」と「喫煙」,述語である「引き起こす」と「危険性を高める」,目的語である「肺癌」と「癌」がそれぞれ似た意味であることが分かれば,この2つの文がほとんど同じ意味であることが分かる.本研究の目的は,文書の意味を理解するために,上記のような,単語や句の意味を計算可能なモデルを構築することである.
単語の意味については,自然言語処理では伝統的に,似たような文脈で出現する単語は似た意味を持つという,分布仮説にもとづき,意味を表すベクトルを構築してきた.これに加えて,近年では,各単語の意味を表すベクトルとして,分散表現という,低次元で密な実数値のベクトルをコーパスから学習する手法が提案されているなど,盛んに研究されている.しかしながら,複数単語からなる句の意味をどのように計算するかについては,ほとんど研究が進んでいないのが現状である.
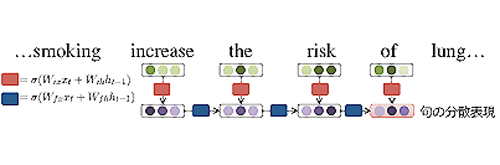
そこで本研究では,句の意味表現(分散表現)を構成単語から計算することに取り組み,単語の分散表現を合成するモデルを2つ提案した.1つ目は,「危険性が減る」という句については「危険性」というネガティブな極性が「減る」で打ち消されている,ということを計算する,ポジティブ/ネガティブなど意味の極性変化を扱ったモデルである.このモデルの実験結果は,意味の極性変化を扱うためには,分散表現の各次元への重みが重要であると示唆している.また,句の意味計算においては,前置詞や冠詞より内容語の方が重要であろうという直観がある.これらを考慮し,単語の意味的重要性を扱えるモデルを提案した.これは,図に示したように,句を構成する単語を順に読み込んで計算していくモデルであり(図ではincrease the risk ofという句の分散表現を計算している),各単語の意味的重要性(正確には,各単語の分散表現の各次元への重み)をその単語の分散表現と,すでに読み込んだ単語列の分散表現から計算する.言い換えれば,単語の意味と,すでに読んだ単語列の意味から,その単語の重要性を計算するモデルである.
また,単語の分散表現の性能を評価するデータセットは数多くあるが,句の意味計算の性能を評価するためのデータセットはきわめて少ない.そこで,本研究では,句と句の間に意味的類似度を付与したデータセットを構築し,句の意味計算性能の比較を可能とした.実験を通して,提案手法が句の分散表現を精度良く合成できていることを示した.さらに,提案手法によって合成した分散表現を用いることで,関係分類の性能が向上することを示し,精度良く句の分散表現の計算を行うことにより,応用タスクの性能も向上することを明らかにした.
単語の意味については,自然言語処理では伝統的に,似たような文脈で出現する単語は似た意味を持つという,分布仮説にもとづき,意味を表すベクトルを構築してきた.これに加えて,近年では,各単語の意味を表すベクトルとして,分散表現という,低次元で密な実数値のベクトルをコーパスから学習する手法が提案されているなど,盛んに研究されている.しかしながら,複数単語からなる句の意味をどのように計算するかについては,ほとんど研究が進んでいないのが現状である.
そこで本研究では,句の意味表現(分散表現)を構成単語から計算することに取り組み,単語の分散表現を合成するモデルを2つ提案した.1つ目は,「危険性が減る」という句については「危険性」というネガティブな極性が「減る」で打ち消されている,ということを計算する,ポジティブ/ネガティブなど意味の極性変化を扱ったモデルである.このモデルの実験結果は,意味の極性変化を扱うためには,分散表現の各次元への重みが重要であると示唆している.また,句の意味計算においては,前置詞や冠詞より内容語の方が重要であろうという直観がある.これらを考慮し,単語の意味的重要性を扱えるモデルを提案した.これは,図に示したように,句を構成する単語を順に読み込んで計算していくモデルであり(図ではincrease the risk ofという句の分散表現を計算している),各単語の意味的重要性(正確には,各単語の分散表現の各次元への重み)をその単語の分散表現と,すでに読み込んだ単語列の分散表現から計算する.言い換えれば,単語の意味と,すでに読んだ単語列の意味から,その単語の重要性を計算するモデルである.
また,単語の分散表現の性能を評価するデータセットは数多くあるが,句の意味計算の性能を評価するためのデータセットはきわめて少ない.そこで,本研究では,句と句の間に意味的類似度を付与したデータセットを構築し,句の意味計算性能の比較を可能とした.実験を通して,提案手法が句の分散表現を精度良く合成できていることを示した.さらに,提案手法によって合成した分散表現を用いることで,関係分類の性能が向上することを示し,精度良く句の分散表現の計算を行うことにより,応用タスクの性能も向上することを明らかにした.
(2017年5月31日受付)