
(邦訳:メニーコア型大規模並列計算機向けの高性能メッセージパッシング型通信技術)
| 思 敏 アルゴンヌ国立研究所/Enrico Fermi ポスドクフェロー |
[背景]メニーコア型並列計算機上で通信問題の重要性
[問題]伝統的な通信手法がメニーコアに適せず性能低下
[貢献]メニーコア向けの高性能通信手法の提案
[問題]伝統的な通信手法がメニーコアに適せず性能低下
[貢献]メニーコア向けの高性能通信手法の提案
近年,消費電力と発熱問題などの理由で従来通りの動作周波数向上によるプロセッサ処理性能向上は困難になったため,コア数およびSIMD命令の並列化により性能を向上するメニーコアアーキテクチャが登場した.しかし,従来のプログラミングモデルはこの並列環境で高い性能を示さない.まず,メニーコアチップは従来のCPUと違って,高い電力あたりの性能を大量な低動作周波数のプロセッサコアにより実現しているため,アプリケーション全体を大規模並列しないと逆に性能が悪化することもある.また,コア数の増加に比べてメモリ容量などのシステム資源があまり増加せず,コアごとの資源が少なくなりスケーラビリティ阻害の要因となる.
一方,ハードウェアの進化とともに,ソフトウェアのほうも複雑なハイブリッドおよび非規則計算・通信モデルになる傾向がある.たとえば,従来のアプリケーション(たとえば,高速フーリエ変換)では,メモリなどの資源に比べて大量のコアが提供される理由から,プロセスとスレッドを混在させるハイブリッドMPI+OpenMPモデルに移行している例がある.また,MPI片方向通信は,通信の相手の状態に無関係に他のプロセスのデータにアクセスできる通信モデルであり,非規則計算・通信モデルを主流にする化学・生物情報系科学計算によく使われる.
ハードウェア構造の変化とソフトウェアモデルの多様化に伴い,それぞれのモデルにおいて通信が原因となって全体性能を阻害する場合が認められる.本研究は,科学計算に広く用いられるMPI通信モデルを対象としてメニーコアの特徴を活用し,それらのモデルの既存課題を解決して通信性能を最大限に発揮した.
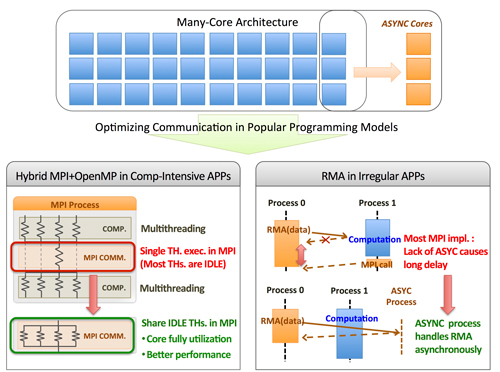
まず,ハイブリッドMPI+OpenMP型アプリケーションでは,複数のOpenMPスレッドが計算を並列化してその中の1つが MPI通信を行うという実行モデルが主流である.浮動小数点計算を大規模並列化することで計算部分の性能を向上したが,通信部分ではほとんどのスレッドがアイドルになり,計算資源が無駄になる.また,1つのコアだけが通信処理を担当することで通信性能の劣化原因ともなる.本研究では,アイドル状態になったスレッドを再利用し,MPI内部通信処理を並列化する手法で通信性能および資源利用率を大幅に向上することを示した(図の左下部分).
また,片方向通信モデルに関しては,MPIが非同期処理されないという課題について取り組んだ.ほとんどのMPI実装では,MPI片方向通信を完了するためにリモート側プロセスがMPI関数を呼び出さないと処理が進まない.本研究は,大量の計算コアからMPI非同期通信に専用するコアを一部割り当て,片方向通信に効率的な非同期処理を提供する非同期通信処理ライブラリを提案した(図の右下部分).この非同期手法で,汎用量子化学計算パッケージNWChemの性能を30%ほど向上することを示した.
一方,ハードウェアの進化とともに,ソフトウェアのほうも複雑なハイブリッドおよび非規則計算・通信モデルになる傾向がある.たとえば,従来のアプリケーション(たとえば,高速フーリエ変換)では,メモリなどの資源に比べて大量のコアが提供される理由から,プロセスとスレッドを混在させるハイブリッドMPI+OpenMPモデルに移行している例がある.また,MPI片方向通信は,通信の相手の状態に無関係に他のプロセスのデータにアクセスできる通信モデルであり,非規則計算・通信モデルを主流にする化学・生物情報系科学計算によく使われる.
ハードウェア構造の変化とソフトウェアモデルの多様化に伴い,それぞれのモデルにおいて通信が原因となって全体性能を阻害する場合が認められる.本研究は,科学計算に広く用いられるMPI通信モデルを対象としてメニーコアの特徴を活用し,それらのモデルの既存課題を解決して通信性能を最大限に発揮した.
まず,ハイブリッドMPI+OpenMP型アプリケーションでは,複数のOpenMPスレッドが計算を並列化してその中の1つが MPI通信を行うという実行モデルが主流である.浮動小数点計算を大規模並列化することで計算部分の性能を向上したが,通信部分ではほとんどのスレッドがアイドルになり,計算資源が無駄になる.また,1つのコアだけが通信処理を担当することで通信性能の劣化原因ともなる.本研究では,アイドル状態になったスレッドを再利用し,MPI内部通信処理を並列化する手法で通信性能および資源利用率を大幅に向上することを示した(図の左下部分).
また,片方向通信モデルに関しては,MPIが非同期処理されないという課題について取り組んだ.ほとんどのMPI実装では,MPI片方向通信を完了するためにリモート側プロセスがMPI関数を呼び出さないと処理が進まない.本研究は,大量の計算コアからMPI非同期通信に専用するコアを一部割り当て,片方向通信に効率的な非同期処理を提供する非同期通信処理ライブラリを提案した(図の右下部分).この非同期手法で,汎用量子化学計算パッケージNWChemの性能を30%ほど向上することを示した.
(2016年6月7日受付)