
(邦訳:階層的な見出しブロック構造の分析に基づくWeb検索)
| 真鍋 知博 ヤフー(株) |
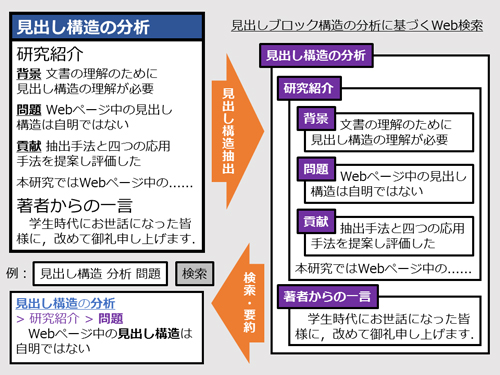
[背景]文書の理解のために見出し構造の理解が必要
[問題]Webページ中の見出し構造は自明ではない
[貢献]抽出手法と4つの応用手法を提案し評価した
[問題]Webページ中の見出し構造は自明ではない
[貢献]抽出手法と4つの応用手法を提案し評価した
本研究ではWebページ中の見出し構造の抽出と応用について論じる.ここで見出しとはページ中のある一部分の非常に簡潔な要約であり,そのような見出しを持つ部分をブロックと呼ぶ.ブロックは他のブロックを包含することがあり,あるページ中の見出しとブロックは階層的な見出し構造を成す.見出し構造は,ページの構成要素であるメニューや本文をより細かく構造化し,同時に,複数の文をまとめてより粗く構造化する.
本研究で収集したデータによれば,8割ものWebページが少なくとも一対の見出しとブロックを含む.つまりほとんどのページについて,その内容の包括的な理解のためには見出し構造の理解が必要である.しかし,Webページ中の見出し構造の自動抽出や利用は十分に研究されてはいない.これは,Webページ中のレイアウト構造の抽出や本文抽出,文構造の自然言語処理が広く研究されているのとは対照的である.
このような状況を打開するため,本研究ではまず,Webページ中の見出し構造を自動抽出する手法を提案した.HTMLには見出しを表すタグがあるが,前述のデータによれば,見出しタグで記述されるのは真の見出しの1/3程度であり,またそれらの1/3程度は真の見出しではない.真の見出しのみをすべて抽出するため,本研究では,ページ中に同じ見た目の真の見出しが複数存在する場合が多いこと,真の見出しは人間にとって目立つことに注目した.提案手法はページ中の要素を見た目により分別し,最も目立つ要素の集合から順に見出しの集合であるかを識別する.提案手法はタグ名に基づく抽出と同等の精度で,2倍の再現率を達成した.
本研究では続いて,抽出された見出し構造のWeb検索への応用手法を提案した.提案手法はWebページをその中で最高スコアのブロックのみに基づきランキングし,ブロックのスコアリングには祖先ブロックの見出しをメタデータとして考慮する.パラメータ最適化の結果は,祖先ブロックの見出しこそが,ページタイトルなど既知のメタデータやブロックの内容よりも重要であることを示した.これは既存研究にはない成果である.
抽出された見出し構造のさらなる応用として,本研究では,検索結果スニペット生成手法も提案した.提案手法は文をスコアリングし抽出することにより要約を行うが,その際文を階層的に含むブロックの見出しをスコアリングのために考慮し,またそれら見出しをも抽出する.ユーザ実験の結果は,検索意図の明確なクエリおよび多くのキーワードから成るクエリに対して,提案手法が有効であることを示した.
博士論文本文においては,その他2つの応用についても論じた.1つはクエリに対してその意図を特化・明確化するクエリのランキングを返すサブトピックランキングへの応用.もう1つはWebページ中のキーワードの出現間の論理的関係の強さを測りページのスコアリングのために考慮する近接検索への応用である.
本研究で収集したデータによれば,8割ものWebページが少なくとも一対の見出しとブロックを含む.つまりほとんどのページについて,その内容の包括的な理解のためには見出し構造の理解が必要である.しかし,Webページ中の見出し構造の自動抽出や利用は十分に研究されてはいない.これは,Webページ中のレイアウト構造の抽出や本文抽出,文構造の自然言語処理が広く研究されているのとは対照的である.
このような状況を打開するため,本研究ではまず,Webページ中の見出し構造を自動抽出する手法を提案した.HTMLには見出しを表すタグがあるが,前述のデータによれば,見出しタグで記述されるのは真の見出しの1/3程度であり,またそれらの1/3程度は真の見出しではない.真の見出しのみをすべて抽出するため,本研究では,ページ中に同じ見た目の真の見出しが複数存在する場合が多いこと,真の見出しは人間にとって目立つことに注目した.提案手法はページ中の要素を見た目により分別し,最も目立つ要素の集合から順に見出しの集合であるかを識別する.提案手法はタグ名に基づく抽出と同等の精度で,2倍の再現率を達成した.
本研究では続いて,抽出された見出し構造のWeb検索への応用手法を提案した.提案手法はWebページをその中で最高スコアのブロックのみに基づきランキングし,ブロックのスコアリングには祖先ブロックの見出しをメタデータとして考慮する.パラメータ最適化の結果は,祖先ブロックの見出しこそが,ページタイトルなど既知のメタデータやブロックの内容よりも重要であることを示した.これは既存研究にはない成果である.
抽出された見出し構造のさらなる応用として,本研究では,検索結果スニペット生成手法も提案した.提案手法は文をスコアリングし抽出することにより要約を行うが,その際文を階層的に含むブロックの見出しをスコアリングのために考慮し,またそれら見出しをも抽出する.ユーザ実験の結果は,検索意図の明確なクエリおよび多くのキーワードから成るクエリに対して,提案手法が有効であることを示した.
博士論文本文においては,その他2つの応用についても論じた.1つはクエリに対してその意図を特化・明確化するクエリのランキングを返すサブトピックランキングへの応用.もう1つはWebページ中のキーワードの出現間の論理的関係の強さを測りページのスコアリングのために考慮する近接検索への応用である.
(2016年6月9日受付)