
(邦訳:グラフや超グラフに含まれる非巡回部分構造の列挙に関する研究)
| 和佐 州洋 国立情報学研究所 特任研究員 |
[背景]非巡回なデータ構造からの知識発見
[問題]非巡回な部分構造列挙の理論的限界
[貢献]新しいアルゴリズムの構築,および,理論的な解析
[問題]非巡回な部分構造列挙の理論的限界
[貢献]新しいアルゴリズムの構築,および,理論的な解析
近年,計算機の性能向上やネットワーク環境の発展に伴い,グラフやその一般化である超グラフで定義された情報を容易に,かつ大量に得られるようになった. しかし,その情報すべてを,自らの目で確かめるのは困難である. さらに,その中から,隠れた規則性といった有用な知識を発見するのは,人力では到底不可能な状況である. そこで,私たちは,蓄積されたグラフや超グラフに対して,データマイニングや機械学習を用いることで,先に述べた困難な状況を克服しようとしている. しかし,これらの技術を用いる際は,入力データに含まれる,指数的な数の部分構造を取り扱わなければいけない. 本研究では,この膨大な数の部分構造を効率良く列挙するアルゴリズムの開発,および,列挙アルゴリズムの理論的な解析を行う.本研究で扱う列挙アルゴリズムとは,次のように定義される列挙問題を解くためのアルゴリズムである:グラフ,または超グラフで定義される入力データと制約条件が与えられたときに,入力データに含まれ,かつ条件を満たすすべての部分構造を漏れなく重複なく求めよ.
列挙問題の研究は,筆者の知るかぎり,1950年代から連綿と続いており,現在でも新たなアルゴリズムや新しい理論が発表されている.列挙アルゴリズムの効率の良さは,他のアルゴリズムとすこし異なる点で評価される.列挙問題における解の個数は,一般に,入力サイズに対して指数オーダである.しかし,実際の解の数は,そのオーダよりも小さく,単に入力サイズのみで評価してしまうと,過大に見積ることになる.そこで列挙アルゴリズムは,入力サイズに加え,出力サイズにも着目し,解1つを出力するのにどのくらいの時間(遅延)が必要かによって性能が評価される.1996年にAvisとFukudaが示した逆探索法は,短い遅延を達成する列挙アルゴリズムを構築するための重要な技法の1つとして挙げられる.逆探索法の登場により,それまで個別に考えられてきた列挙アルゴリズムの構築をある程度統一的に扱うことができるようになった.しかし,この技法を用いたとしても,最適なアルゴリズムが知られているのはごく一部の部分グラフに対する列挙問題である.さらに,グラフクラスによっては,入力サイズと出力サイズの多項式時間で列挙できるか分かっていない問題も多数存在するのが現状である.
このような状況のもと,本博士論文では,生命科学や,データベース,自然言語処理といった分野で広く扱われている非巡回な構造に着目し,これらを列挙する問題を考察し,いくつかの最適な列挙アルゴリズム,および,初めての多項式遅延の列挙アルゴリズムを提案した.本論文の具体的な貢献は以下のとおりである:
列挙問題の研究は,筆者の知るかぎり,1950年代から連綿と続いており,現在でも新たなアルゴリズムや新しい理論が発表されている.列挙アルゴリズムの効率の良さは,他のアルゴリズムとすこし異なる点で評価される.列挙問題における解の個数は,一般に,入力サイズに対して指数オーダである.しかし,実際の解の数は,そのオーダよりも小さく,単に入力サイズのみで評価してしまうと,過大に見積ることになる.そこで列挙アルゴリズムは,入力サイズに加え,出力サイズにも着目し,解1つを出力するのにどのくらいの時間(遅延)が必要かによって性能が評価される.1996年にAvisとFukudaが示した逆探索法は,短い遅延を達成する列挙アルゴリズムを構築するための重要な技法の1つとして挙げられる.逆探索法の登場により,それまで個別に考えられてきた列挙アルゴリズムの構築をある程度統一的に扱うことができるようになった.しかし,この技法を用いたとしても,最適なアルゴリズムが知られているのはごく一部の部分グラフに対する列挙問題である.さらに,グラフクラスによっては,入力サイズと出力サイズの多項式時間で列挙できるか分かっていない問題も多数存在するのが現状である.
このような状況のもと,本博士論文では,生命科学や,データベース,自然言語処理といった分野で広く扱われている非巡回な構造に着目し,これらを列挙する問題を考察し,いくつかの最適な列挙アルゴリズム,および,初めての多項式遅延の列挙アルゴリズムを提案した.本論文の具体的な貢献は以下のとおりである:
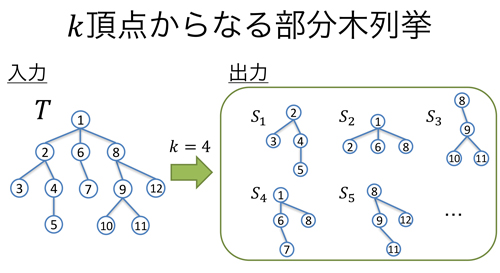
- 木に含まれる頂点数κの部分木を,解1つあたり最悪時定数時間で出力するアルゴリズムを提案.
- 平面グラフのような定数縮退数のグラフに含まれるすべての誘導木を,解1つあたり平均定数時間で出力するアルゴリズムを提案.
- 超グラフに含まれるBerge非巡回な部分超グラフを,解1つあたり入力サイズの最悪時多項式時間で列挙する初めてのアルゴリズムを提案.
これらの具体的な定義等に関しては,博士論文を参照されたい.
(2016年6月7日受付)