
(邦訳:インターネット上でのネットワークスループットの予測可能性に関する研究)
| Chunghan Lee(チュンハン・イ) (株)富士通研究所 研究員 |
[背景]インターネットの発展とともにデータの量が爆発的に増加
[問題]データ転送の効率化のためのネットワークスループットの予測精度の向上
[貢献]ノンパラメトリック統計手法と機械学習を適用したスループット予測手法の提案
[問題]データ転送の効率化のためのネットワークスループットの予測精度の向上
[貢献]ノンパラメトリック統計手法と機械学習を適用したスループット予測手法の提案
インターネット上で取り扱われるデータの量は,コンピュータ技術の発展とインターネットアプリケーションの利用者の増加に応じて爆発的に増加しつつある.このような膨大なデータ量に対して,新たなシステムの提案とインターネットの再設計は有効な手法であるが,直ちに実用化することは容易ではない.一方,ネットワークスループットの予測は現在のインターネットを有効に活用する手法の1つである.たとえば,高精度のスループットの予測手法があるならば,データインテンシブなグリッド・コンピューティングにおいて,複数の拠点の中から有効な拠点を選択したり,データ転送時間を減らすことによって全体の処理時間をより短くすることが可能である.しかし,これまでに多くのスループットの予測手法が提案されたが,以下の問題点により予測精度を高めることは容易ではない.まず,トラフィックの変動の分布が明確ではないため,数学的にモデル化することが困難である.また,ネットワークの帯域幅とスケールの急速な増加によるデータの変動が大きいことが問題である.最後に,ネットワーク状態の突然な変動によるノイズの存在が挙げられる.
本研究では,既存の予測手法より高い予測精度を持つスループットの予測手法の提案とインターネット上での応用に焦点を当てる.本研究の最大の特徴は予測精度を向上するために機械学習分野の手法を応用していることである.
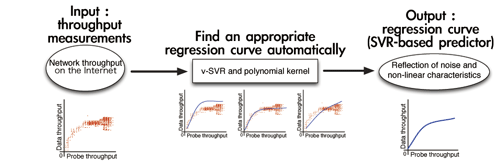
初めに,インターネット上で仮想化技術が使用された際の,インターネットトラフィックの特徴に関する研究争点について議論した.本研究では,スループットを観測するため,先行研究で提案された手法をベースにして学習データの収集を行う.その手法とは,予測のために使う小規模なProbe transferとスループットの観測のためのData transferをペアとして構成し,それらを同時に観測するという手法である.本研究では予測モデルを構成する前に,観測結果をノンパラメトリック統計手法で評価を行い適切な予測パラメーターを決定した.一方,観測結果の中ではネットワーク状態が安定したにもかかわらず,仮想化の影響により本来と異なる異常結果となることが存在することを明らかにした.また,従来の予測パラメーターが高い予測精度を持つモデルを構成するためには不適切であることと,観測結果においてノイズと非線形の特徴が存在することを明確にした.
次に,本研究ではスループットの予測問題を回帰曲線決定問題に帰着させた.モデル化を行う際に,ノイズと非線形の特徴を考慮するために機会学習分野で幅広く使われる多項式カーネルとν-Support Vector Regression(SVR)を使用し,適切な回帰曲線を保持することが可能になった.さらに,従来の予測手法と同じ条件で優劣を論じた結果,従来の手法より高い予測精度が得られることを確認した.
最後に,インターネット上でのグリッドシミュレーションを通じてスループットの予測結果がスケジューラにどのような影響を与えるのかを明らかにした.本研究で提案した手法と従来の予測手法をグリッドのスケジューラに適用し,スループットの予測を使わないスケジューラと定量的な評価を実施した.シミュレーション評価結果,予測結果が与えられたタスクに対して処理時間を減らす保証が必ずしもできるわけでないことと,本研究で提案した予測手法を使う際に多くの結果で全体の処理時間を減らすことが可能であることを示した.
本研究では,既存の予測手法より高い予測精度を持つスループットの予測手法の提案とインターネット上での応用に焦点を当てる.本研究の最大の特徴は予測精度を向上するために機械学習分野の手法を応用していることである.
初めに,インターネット上で仮想化技術が使用された際の,インターネットトラフィックの特徴に関する研究争点について議論した.本研究では,スループットを観測するため,先行研究で提案された手法をベースにして学習データの収集を行う.その手法とは,予測のために使う小規模なProbe transferとスループットの観測のためのData transferをペアとして構成し,それらを同時に観測するという手法である.本研究では予測モデルを構成する前に,観測結果をノンパラメトリック統計手法で評価を行い適切な予測パラメーターを決定した.一方,観測結果の中ではネットワーク状態が安定したにもかかわらず,仮想化の影響により本来と異なる異常結果となることが存在することを明らかにした.また,従来の予測パラメーターが高い予測精度を持つモデルを構成するためには不適切であることと,観測結果においてノイズと非線形の特徴が存在することを明確にした.
次に,本研究ではスループットの予測問題を回帰曲線決定問題に帰着させた.モデル化を行う際に,ノイズと非線形の特徴を考慮するために機会学習分野で幅広く使われる多項式カーネルとν-Support Vector Regression(SVR)を使用し,適切な回帰曲線を保持することが可能になった.さらに,従来の予測手法と同じ条件で優劣を論じた結果,従来の手法より高い予測精度が得られることを確認した.
最後に,インターネット上でのグリッドシミュレーションを通じてスループットの予測結果がスケジューラにどのような影響を与えるのかを明らかにした.本研究で提案した手法と従来の予測手法をグリッドのスケジューラに適用し,スループットの予測を使わないスケジューラと定量的な評価を実施した.シミュレーション評価結果,予測結果が与えられたタスクに対して処理時間を減らす保証が必ずしもできるわけでないことと,本研究で提案した予測手法を使う際に多くの結果で全体の処理時間を減らすことが可能であることを示した.
(2013年6月10日受付)