
| 白川 真澄 大阪大学大学院情報科学研究科 特任助教 |
[背景]コンピュータが自然文の意味を把握するために必要な知識
[問題]知識の体系化における知識の種類の不足
[貢献]既存の知識体系との連携が可能な新たな知識の獲得
[問題]知識の体系化における知識の種類の不足
[貢献]既存の知識体系との連携が可能な新たな知識の獲得
人が自然言語で記述されたテキストの意味を理解しようとするとき,「知識」と「知恵」の協調作業が行われる.知識とはこの世界のあらゆる概念や実体(エンティティ),語句に関して知っていることであり,知恵とは論理的に判断し処理する能力である.ある分野についての知識がなければその分野のテキストを理解することは困難であり,知識があっても知恵がなければテキストから正しい理解を導き出すことは難しい.
コンピュータにとっても,自然文の意味を理解するためには知識と知恵の両方が必要となる.そのため,知識体系を手動あるいは自動で構築する研究や,知恵を擬似的に表現するためのアルゴリズムに関する研究が数多く行われてきた.本研究が対象としている知識体系の自動構築に関する既存研究としては,Wikipediaを利用したものが挙げられる.
Wikipediaは,Wikiを利用した協調Web百科事典であり,世界中の誰でもWebブラウザを通じてリアルタイムに記事内容を変更できる.そのため,幅広い分野について,一般的なエンティティから新しいエンティティに至るまで記事が網羅されている(記事数400万以上).精度の面においても,専門家によって作成されたブリタニカ百科事典(記事数7万以下)と同等であると報告されている.
代表的な既存研究であるDBpediaでは,Wikipediaの情報を構造化することにより,エンティティの属性情報やエンティティ間の関係,エンティティの上位概念(上位下位関係)などの基本的な知識を体系化してきた.一方で,基本的な知識以外はあまり体系化されていないため,DBpediaだけでは知識としては不十分であることが多い.
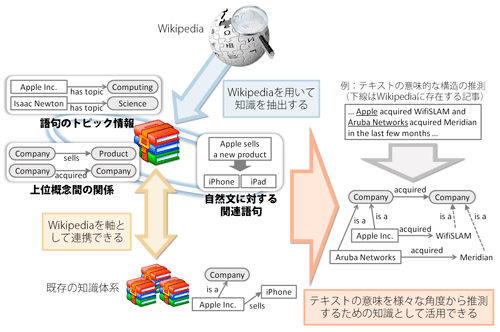
本研究では,これまで体系化されてこなかった知識を,Wikipediaを用いて抽出し,既存の知識体系と連携可能な形で体系化することを目的とする.具体的には図のように,語句のトピック情報,自然文に対する関連語句,上位概念間の関係をそれぞれ対象とし,Wikipediaをベースとした知識の抽出を行った.また,抽出した知識を整理し,Webで公開している(http://sigwp.org/).
語句のトピック情報は,テキストがどのようなトピックに属するかを推測するための知識として利用できる.Wikipediaのカテゴリ構造を利用し,グラフ解析により語句のトピック情報を抽出する手法を提案している.
自然文に対する関連語句は,テキストの内容を表現するための拡張された意味情報として,テキスト中の曖昧性のある語の意味推定やテキストクラスタリングなどに利用可能な知識である.Wikipediaから抽出可能なさまざまな情報を確率として定義し,ベイズ理論に基づく関連語句推測手法を提案している.
上位概念間の関係は,未知の語句に対する推測を,概念を介して行うための知識である.大規模なテキストデータから語句間の関係を抽出した後,Wikipediaの情報を用いて語句を上位概念に置き換えることで,上位概念間の関係を取得している.
コンピュータにとっても,自然文の意味を理解するためには知識と知恵の両方が必要となる.そのため,知識体系を手動あるいは自動で構築する研究や,知恵を擬似的に表現するためのアルゴリズムに関する研究が数多く行われてきた.本研究が対象としている知識体系の自動構築に関する既存研究としては,Wikipediaを利用したものが挙げられる.
Wikipediaは,Wikiを利用した協調Web百科事典であり,世界中の誰でもWebブラウザを通じてリアルタイムに記事内容を変更できる.そのため,幅広い分野について,一般的なエンティティから新しいエンティティに至るまで記事が網羅されている(記事数400万以上).精度の面においても,専門家によって作成されたブリタニカ百科事典(記事数7万以下)と同等であると報告されている.
代表的な既存研究であるDBpediaでは,Wikipediaの情報を構造化することにより,エンティティの属性情報やエンティティ間の関係,エンティティの上位概念(上位下位関係)などの基本的な知識を体系化してきた.一方で,基本的な知識以外はあまり体系化されていないため,DBpediaだけでは知識としては不十分であることが多い.
本研究では,これまで体系化されてこなかった知識を,Wikipediaを用いて抽出し,既存の知識体系と連携可能な形で体系化することを目的とする.具体的には図のように,語句のトピック情報,自然文に対する関連語句,上位概念間の関係をそれぞれ対象とし,Wikipediaをベースとした知識の抽出を行った.また,抽出した知識を整理し,Webで公開している(http://sigwp.org/).
語句のトピック情報は,テキストがどのようなトピックに属するかを推測するための知識として利用できる.Wikipediaのカテゴリ構造を利用し,グラフ解析により語句のトピック情報を抽出する手法を提案している.
自然文に対する関連語句は,テキストの内容を表現するための拡張された意味情報として,テキスト中の曖昧性のある語の意味推定やテキストクラスタリングなどに利用可能な知識である.Wikipediaから抽出可能なさまざまな情報を確率として定義し,ベイズ理論に基づく関連語句推測手法を提案している.
上位概念間の関係は,未知の語句に対する推測を,概念を介して行うための知識である.大規模なテキストデータから語句間の関係を抽出した後,Wikipediaの情報を用いて語句を上位概念に置き換えることで,上位概念間の関係を取得している.
(2013年6月7日受付)