
(邦訳:言語処理システムのための語彙的情報の教師なし学習)
| グラム・ニュービッグ 奈良先端科学技術大学院大学 助教 |
[背景]音声認識や機械翻訳のような言語処理システム
[問題]言語処理システムにおける処理の基本的な単位である「単語」
[貢献]音声認識と機械翻訳のための語彙を教師なし学習で獲得
音声認識や機械翻訳のような言語処理システムは従来「単語」を処理の基本的な単位とする.しかし,多くの場合,「単語」の定義は自明ではない.例えば,日本語や中国語のような分かち書きされない言語では,どの文字列を単語と見なすかは言語学者にとっても難しい問題であり,人手で決めた単位は必ずしも言語処理システムにとって最適であるとは限らない.音声においても同等であり,明確な単語区切りが存在せず,音声波形を単語に分割するのは容易ではない.
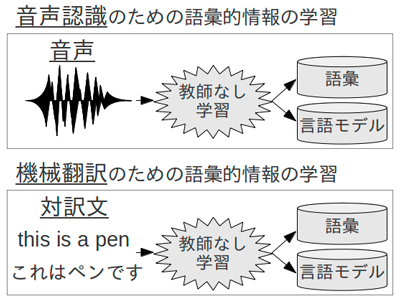
本論文は,図で示すように,音声認識と機械翻訳のための語彙を教師なし学習で獲得することで最適な単語単位を発見する手法を提案する.この手法には主に3つの利点がある.まず,言語処理においては,データが多く頑健な確率推定が可能な場合は長い単語や句単位,データが少なく未知語が頻出する場合は単語より短い単位を利用することは最適であるが,教師なし学習を採用することによって,自動的にデータ量に合わせて単語単位を選択することができる.また,人手を介さずに獲得された単語単位は言語的知見に基づき選択される単位と異なり,その違いの考察を行うことで新たな知見が生まれる.最後に,人手作業を要しないため,言語学者や解析ツールが不足している少数言語でも利用可能である.
音声認識に関する研究では,テキストを用いずに連続音声のみから認識に必要な語彙と言語モデルを学習する方法を提案する.音声から語彙を学習する際,連続した音素列から単語境界を発見する必要があり,音声認識の不確かさにも対処しなければ頑健な学習ができない.単語境界を選択するために,ノンパラメトリックベイズ統計に基づく語彙選択基準を採用する.音声認識の不確かさに対処するために,膨大な認識候補を効率良く格納する音声認識ラティス上で推論を行う手法を提案する.実験的評価で,この手法を用いて自然な連続音声のみから学習されたモデルは音声認識の精度向上に貢献できることを示した.
機械翻訳に関する研究では,単語境界を予め決めずに,翻訳に利用する単語単位を対訳文から学習する手法を提案する.これにより,人名や活用語,日本語と中国語の分かち書きなど,翻訳の様々な語彙処理を統一した枠組みで扱うことが可能となる.語彙の選択基準として,ノンパラメトリックベイズ統計に基づく階層モデルを採用する.また,部分文字列に対してモデル構築を行う際に,学習の効率が重要となるため,新たな探索アルゴリズムと学習法を提案し,学習の効率を大きく向上させる.実験的評価で,この手法は人手で決定された単語単位を用いた翻訳とほぼ同等の精度を実現し,未知語や低頻度語による様々な問題を解決することが分かった.
(2012年7月24日受付)