Structuring the Japanese Course of Study with CASE: Development and Evaluation of a System for Visualizing Learning Progressions
1. Introduction
1.1 Background: The Rise of Microcredentials
Microcredentials, which electronically certify specific learning outcomes, have garnered significant international attention. This trend has prompted national-level initiatives for their adoption and standardization. For instance, the European Union (EU) has adopted the “Council Recommendation on a European approach to micro-credentials” [1], while the governments of Australia and Malaysia have published guidelines to assure their quality [2], [3]. The primary technology for implementing these microcredentials is the digital badge, exemplified by the Open Badges international technical standard from the 1EdTech consortium [4]. In Japan, the environment for their widespread adoption is also maturing, with the publication of official usage guidelines [5].
However, the intrinsic value of microcredentials extends beyond the issuance of individual badges. As Yamada [6] points out, their true potential is unlocked through the creation of a “digital ecosystem” that integrates these badges with diverse learning and career-related systems. For this ecosystem to provide advanced functions—not only to certify a learner's history of what has been learned but also to personalize learning pathways by identifying what challenges remain and what should be learned next—a machine-readable, standardized framework of evaluation criteria is essential.
1.2 Challenges in Educational Assessment in Japan
In Japan, criterion-referenced assessment, based on the national Course of Study, was introduced following a 2001 notification from the Ministry of Education, Culture, Sports, Science and Technology (MEXT) [7]. Prior to this, a report by the Central Council for Education [8] advocated for the “Integration of Instruction and Assessment.” This principle frames assessment not merely as a measurement of learning outcomes (assessment of learning), but as a continuous cycle where the results of assessment are used to improve subsequent instruction, which is then, in turn, assessed.
However, structural challenges have hindered the realization of this principle. NISHIZUKA [9], after analyzing 71 domestic educational practices and theoretical studies, found that many teachers conflate Assessment for Learning with evaluation for grading purposes, concluding that the “learning process has been overused for final grades.” This finding aligns with a 2025 report from a MEXT curriculum committee, which noted that data from Assessment for Learning still tends to be used as material for final evaluations rather than for instructional improvement [10].
This issue is notattributable to the qualifications of individual teachers but rather to a combination of constraints. These include: (1) technical constraints, as paper-based records make it difficult to accumulate and reference detailed learning histories; (2) time constraints, which prevent teachers from closely monitoring the progress of each student; and (3) institutional constraints, where assessments are compartmentalized by semester, impeding support for continuous growth. These factors collectively complicate the practical implementation of the “Integration of Instruction and Assessment.”
As an approach to these challenges, this study draws upon the theoretical framework of Assessment for Learning (AfL). AfL is a concept that further develops the principles of formative assessment, whose effectiveness was demonstrated in research by Black and William [11], [12], among others [13]. The Assessment Reform Group (ARG) defines AfL as “the process of seeking and interpreting evidence for use by learners and their teachers to decide where the learners are in their learning, where they need to go and how best to get there” [14]. As this definition indicates, AfL is a continuous process centered on three core questions:
- 1.Where are the learners in their learning?
- 2.Where do they need to go?
- 3.How can they best get there?
This framework provides a concrete model for the “Integration of Instruction and Assessment” and aligns with the microcredential digital ecosystem described in the previous section and the objectives of this research as described in Section 1.4. Based on the AfL definition, this study aims to visualize learning progressions using the goals and content specified in the Japanese Course of Study.
1.3 Opportunities from the GIGA School Program and a Remaining Barrier
The advancement of Japan's GIGA School Program [15], through the widespread adoption of one-to-one devices and digital educational materials, has created an environment for the continuous accumulation of study logs from learning activities. By analyzing this data chronologically, it becomes possible to objectively capture growth processes—such as mastering a topic that was previously unachieved—and to identify the root causes of a student's current difficulties. Consequently, the technical foundation required to resolve the aforementioned challenges in assessment is now being established.
However, a critical barrier emerges when attempting to leverage these study logs to build a digital ecosystem for microcredentials: a profound disconnect between the machine-readable data (the study logs) and the standard (the Course of Study) that serves as its reference point. The current Course of Study [16] is primarily available in print or PDF format, which severely limits its machine-readability. Furthermore, the existing Course of Study Code (CSCODE) [17] only provides unique identifiers and fails to represent semantic relationships between items, such as prerequisite knowledge. This disconnect between data and standards is the primary bottleneck in utilizing study logs, and it represents a fundamental challenge to building a quality-assured ecosystem.
1.4 Purpose of the Study and Research Questions
This study aims to resolve the disconnect between data and standards, enabling a data-driven visualization of a learner's learning progression—a process that has been historically difficult to capture continuously. In this paper, a learning progression is defined as a multifaceted trajectory of learning that encompasses two aspects:
- 1.Temporal changes in achievement: The progression over time as a learner masters content that was previously unachieved.
- 2.Systematic connections in learning content: The relationships that show how a learner's current difficulties may stem from insufficient mastery of prerequisite items.
To achieve this purpose, this study focuses on the international technical standard Competencies and Academic Standards Exchange (CASE) [18] and adopts a two-pronged approach. First, as illustrated in Figure 1, we establish a method for structuring the Japanese Course of Study into the CASE format (hereafter, CSCASE). Second, we develop a prototype system (hereafter, the system) that integrates CSCASE with study logs to support the visualization of learning maps and the issuance of microcredentials. This work aims to support teachers in assessing students based on their learning progressions, thereby contributing to the realization of the “Integration of Instruction and Assessment.”
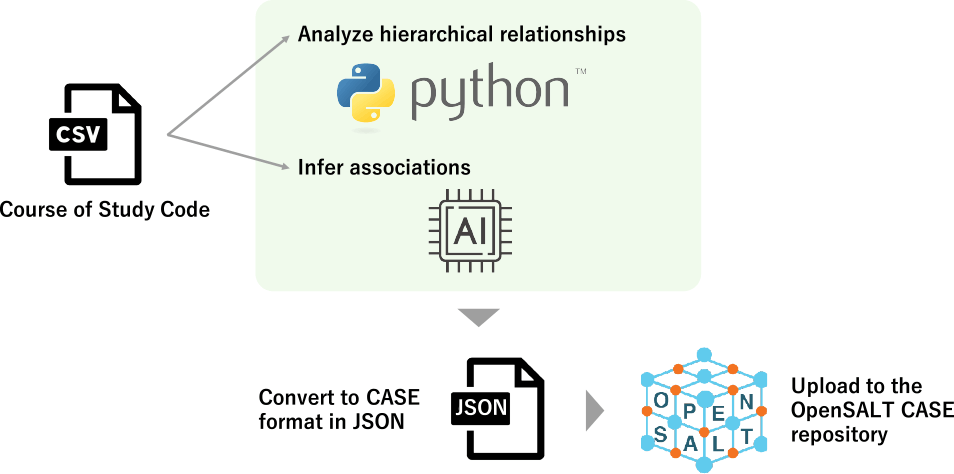
To validate the proposed approach and its effectiveness, we establish the following research questions (RQs):
- ・RQ1: To what extent can the complex structure of the Japanese Course of Study be accurately represented by the international CASE format? Furthermore, how valid are the relationships between items (i.e., systematic connections and relatedness) when automatically estimated using Large Language Models (LLMs)?
- ・RQ2: To what extent are learning maps and microcredentials based on CSCASE effective in visualizing aspects of a learner's progression—specifically, temporal changes in achievement and the systematic connections between knowledge and skills—that were previously difficult to capture?
Finally, the key terms used in this paper are defined as follows. CSCASE refers to the data of the Japanese Course of Study structured into the international CASE format using the methodology of this research. The framework refers to the overall approach proposed in this study, as illustrated in Figure 2. It is a comprehensive model that includes the construction of CSCASE, the design of the system that leverages it, and the strategy for achieving the “Integration of Instruction and Assessment.” The system refers to the prototype web application developed in this study, which utilizes CSCASE and includes features for visualizing learning maps and issuing Open Badges.
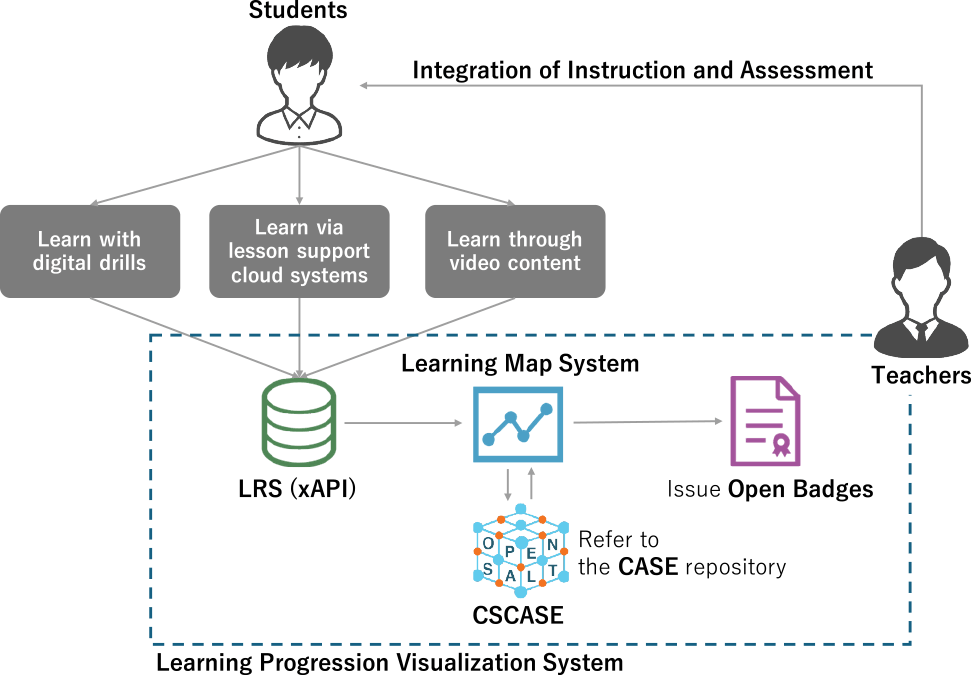
2. Related Work
2.1 Features of Competency and Academic Standards Exchange (CASE)
CASE is an international technical standard designed to represent learning objectives and academic standards in a machine-readable format, ensuring interoperability between different systems [18]. This specification, also developed by the 1EdTech consortium like Open Badges, provides the technical foundation for the advanced utilization of educational data, such as study log analysis and microcredentials.
Written in JSON-LD, it is highly compatible with web technologies and comprises components such as the overall standards document (CFDocument), individual items (CFItem), relationships between items (CFAssociation), and rubrics (CFRubrics). Since the current Japanese Course of Study lacks explicit rubrics, CFRubrics are not addressed in this research.
CASE is particularly noteworthy for two reasons. First, its CFAssociation component can express relationships that CSCODE cannot, such as systematic connections (e.g., precedes) and relatedness (e.g., isRelatedTo) between learning items (CFItems). Second, CASE can integrate with other technical standards, such as the Experience API (xAPI) [19] and Open Badges [4]. Integrating xAPI with CASE enables learning experiences—such as “[Student A] [correctly answered] [a problem] on[solving quadratic equations]”—to be recorded and correlated with specific items in the Japanese Course of Study. Similarly, Open Badges v3.0 can reference a CFItem in their alignment field, allowing a digital badge to serve as a verifiable assertion that a learner has met the criteria for a specific item in the Japanese Course of study [20], [21].
2.2 Initiatives for Academic Standards in the United States
In the United States, several states have established the CASE Network, publishing their academic standards for core subjects in the CASE format to ensure interoperability among learning tools from distinct vendors [22]. Furthermore, Google for Education has announced plans to integrate with the CASE Network, introducing a feature that allows teachers to link relevant academic standards to assignments in Google Classroom [23]. This integration will support the collection and visualization of data on each learner's attainment of standards, thereby facilitating instructional improvement based on objective insights.
2.3 Initiatives for the Course of Study in Japan
In Japan, no previous studies have demonstrated the concrete effectiveness of structuring the national Course of Study with CASE or integrating it with xAPI and Open Badges. While initiatives such as the development of CSCODE and the release of the Course of Study LOD (Linked Open Data) [24] represent important steps toward the digital utilization of the Course of Study. Nonetheless, CSCODE mainly offers unique identifiers for reference and does not inherently support the detailed hierarchical structures and or complex relationships between items (e.g., systematic connections and relatedness) that CASE enables. Although the Course of Study LOD offers more advanced structuring, its objectives and specifications differ in part from those of CASE, an international standard designed to promote interoperability across educational systems. These differences present challenges for collaboration within the global educational ecosystem.
2.4 Estimating Prerequisite Relationships with Large Language Models
Previous studies, both in Japan and internationally, have explored the use of Large Language Models (LLMs) to estimate the prerequisite relationships that determine the learning sequence of educational content.
Le et al. [25] investigated the extent to which 13 different LLMs could accurately predict prerequisite relationships between skills in a zero-shot setting, using data from the European skills/competences framework (ESCO). Their results showed that models such as LLaMA4-Maverick and Claude 3.7 Sonnet achieved accuracy close to that of human expert judgment, suggesting that LLMs are effective for the automated construction and recommendation of skill maps.
Yang et al. [26] used three models from OpenAI to identify prerequisite relationships based on contextual information from online courses, such as descriptions and subtitles. Their findings indicated that GPT-4o was the most accurate. They also noted that cases where the LLM erred were often those where human experts also disagreed, highlighting the necessity of expert review and correction. This work underscored that performance is highly dependent on prompt design.
Focusing on the Japanese Course of Study for junior high school mathematics, Kim et al. [27] compared the prerequisite relationships between units as identified by humans versus a Large Vision Language Model (LVLM). They reported that the LVLM could only extract a sparser set of relationships than humans, concluding that human intervention remains necessary for estimating learning sequences.
These studies indicate that the accuracy of LLMs depends on model performance and prompt design. While they cannot fully replace human expertise, LLMs can automate parts of the manual process of classifying and organizing large volumes of documents, thereby reducing time and effort.
2.5 Significance of Utilizing Large Language Models in This Research
This research utilizes LLMs for the following three reasons.
First is the challenge of scalability. The Japanese Course of Study is vast, encompassing dozens of subjects across elementary, junior high, and high schools; elementary school mathematics alone contains 217 items. For human experts to comprehensively extract and structure the relationships between all these items is prohibitively time-consuming and costly. Furthermore, the Course of Study is revised approximately every ten years. Following each revision, there is a short period for dissemination and transition before full implementation, during which the vast network of item relationships must be redefined and reflected in new digital materials and curricula. Addressing such large-scale, periodic updates comprehensively and rapidly through manual labor alone is practically infeasible. LLMs can perform this large-scale data processing at high speed, ensuring the scalability required to keep pace with these revision cycles.
Second is to ensure consistency. When multiple experts are involved in determining item relationships, variations in their individual interpretations and criteria can lead to inconsistencies (inter-annotator disagreement) in the final structured data. This can destabilize the quality of the data. In contrast, an LLM performs reasoning based on a pre-designed prompt and consistent internal criteria, thereby eliminating the subjectivity inherent in human judgment. This allows for stable relationship estimation aligned with defined standards, which can significantly improve the overall consistency and reliability of the constructed knowledge base.
Third is to maximize the efficiency of experts. This study does not aim for full automation. Rather, it positions LLMs as powerful support tools within a Human-in-the-Loop framework. The role of the LLM is not to replace the expert, but to efficiently generate a high-accuracy initial structure (a baseline) that serves as a foundation for validation and refinement. Instead of building the structure from scratch, experts can review this LLM-generated baseline, making corrections and additions from an educational perspective. This approach can substantially reduce their workload.
2.6 Originality and Contribution of This Research
The originality of this research lies in applying CASE to the Japanese Course of Study and utilizing LLMs to estimate relationships between its items. A key feature of this study is its specific approach: it first identifies hierarchical relationships using the 16-digit Course of Study Code and then attempts to estimate relationships within and between these hierarchies. This estimation focuses particularly on the systematic connections of prerequisite knowledge and the relatedness between learning items for “Knowledge and Skills” and those for “Thinking, Judgment, and Expression.” This approach offers two key advantages. First, unlike an exhaustive search, it constrains the search space to a pre-structured hierarchy, reducing the likelihood of incorporating irrelevant information into the reasoning process and thereby improving accuracy. Second, this constrained search space significantly reduces inference time compared to an exhaustive search, leading to faster processing.
Furthermore, this work extends beyond mere structural mapping by implementing and proposing a model that seamlessly connects the macro-level academic standards of the Course of Study with micro-level individual learning achievements. This is accomplished by linking CSCASE with the award criteria for Open Badges. This approach seeks to transform the Japanese Course of Study from a static “reference document” into a dynamic “academic standards model,” offering a novel perspective on collaborative research between educational technology and microcredentials.
3. Methodology
This section outlines the methodology employed to construct CSCASE and develop the Growth Progression Visualization System in response to the research questions.
3.1 Design and Construction of CSCASE
3.1.1 Scope and Data Structure Design
The scope for the construction of CSCASE in this study was limited to the “Japanese Course of Study for Elementary School Mathematics (Notified in 2017)” [16]. The data was sourced from the corresponding CSCODE, which contains the text of the Course of Study and the 16-digit codes. Mathematics was chosen as a model case because its content exhibits a clear hierarchical structure, making it well-suited for data structure design (see Figure 3).
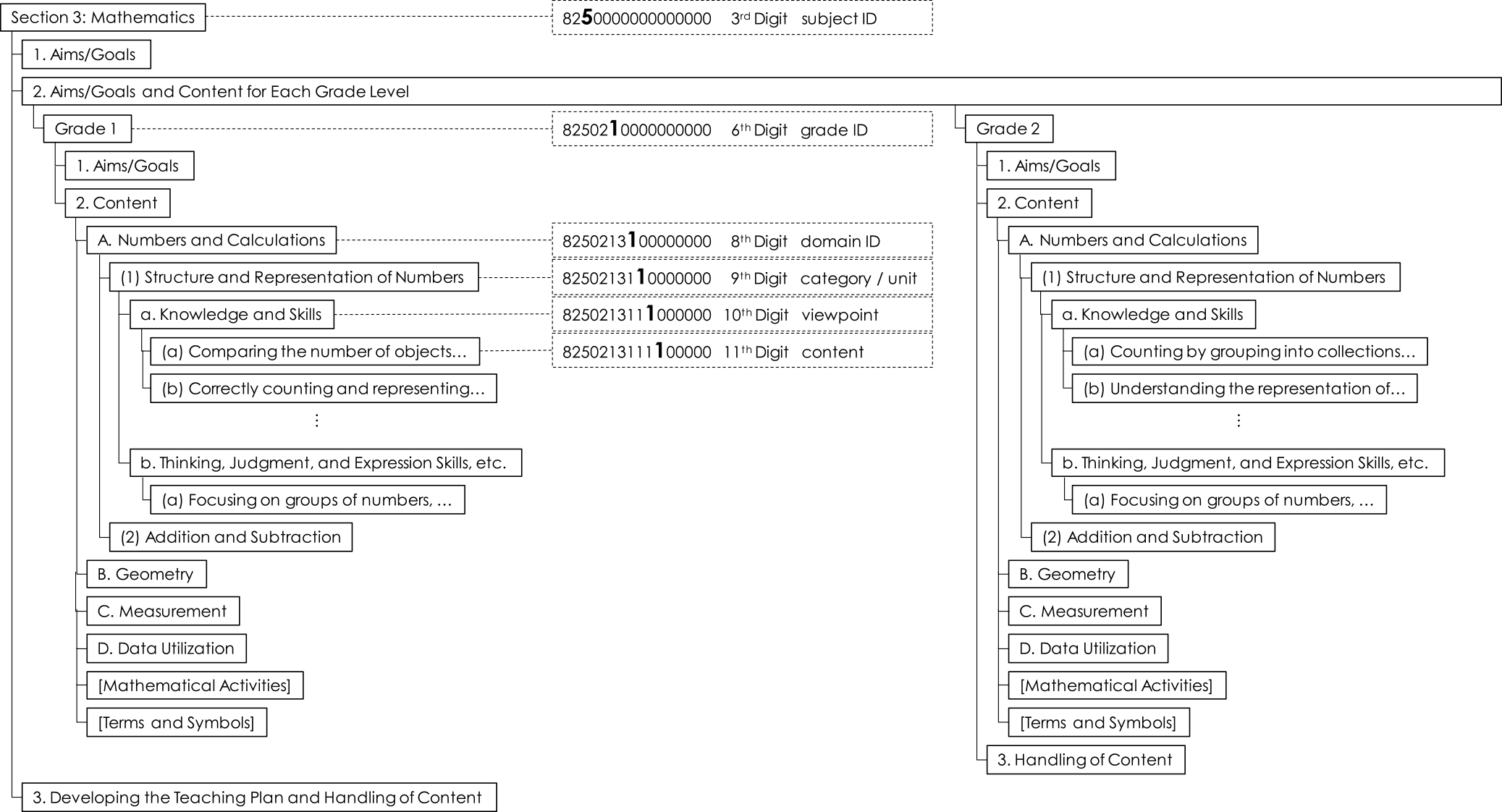
First, the “Course of Study for Elementary School Mathematics” was defined as the CFDocument, and grades, domains, categories, and content were mapped to individual items (CFItems). Categories such as “Goals” and “Content” were represented using the itemType field. The data format adheres to CASE v1.0 (published July 2017) [28], which is compatible with the OpenSALT data management platform [29] used in this work.
3.1.2 Methodology for Estimating Item Relationships (Hierarchy, Systematic Connections, and Relatedness)
To define the relationships between the learning content items (CFItems), which are located at the 11th digit of the CSCODE, we first developed a program to automatically generate hierarchical relationships. This program parses the 16-digit CSCODE to identify parent-child relationships (e.g., Subject–Grade–Domain–Category–Viewpoint) and encodes them as isChildOf relationships within CFAssociation. Specifically, parent-child relationships were determined according to the numbering rules within the 3rd digit (subject ID), 6th digit (grade ID), and 8th digit (domain ID) (see Figure 3).
Subsequently, to estimate the systematic connections (precedes) and relatedness (isRelatedTo) between the hierarchically structured CFItems, we employed seven distinct LLMs available as of July 10, 2025, from OpenAI [30], Google [31], and Anthropic [32]. The instructions for the LLMs were provided using a prompt written in Japanese (an English translation is shown in Figure 4). This prompt presented the structure of the Course of Study and the definitions of the relationships, requesting the LLMs to estimate connections between items both within and across grade levels.


3.1.3 Construction of the Ground Truth Dataset
To objectively evaluate the estimation accuracy of the LLMs, a benchmark ground truth dataset was constructed. The construction procedure was as follows:
Selection of Source Materials: The source materials were the “curriculum sequence charts” published online by TOKYO SHOSEKI CO., LTD. [33] and SHINKOSHUPPANSHA KEIRINKAN CO., LTD. [34], two textbook publishers that together account for over 30% of the adoption rate for elementary school mathematics textbooks in Japan [35]. These charts visually represent the systematic connections between textbook units (corresponding to the 9th digit of CSCODE) both within and across grade levels.
Item Mapping: As the CFItems defined in this study correspond to the 11th digit of CSCODE, the source curriculum sequence charts, which are based on the 9th-digit unit level, could not be used directly. Therefore, we obtained the publishers' editorial guides and annual teaching plan materials from their respective websites. From the detailed descriptions of the units in these documents, we extracted the 10th and 11th-digit level content and compiled them into comprehensive lists.
Extraction and Definition of Relationships: From each list, all relationships between items were extracted and classified into two types: systematic connections (precedes) and relatedness (isRelatedTo). This task was performed by the first author, who has experience as an elementary school teacher and is proficient in the overall structure of the Course of Study and the mathematics curriculum.
Adoption of the Common Set: Finally, a set of relationship pairs was created from each publisher's list. Only the relationship pairs that were common to both sets were adopted as the ground truth. This approach was taken to eliminate bias arising from a single publisher's interpretation and to construct a more objective dataset.
3.1.4 Methodology for Evaluating Estimation Accuracy
The validity of the LLM-generated relationships was evaluated by comparing them against the ground truth dataset constructed in the previous section. The evaluation metrics used were Precision, Recall, and the F-measure, which is the harmonic mean of the two.
In this study, the F-measure was adopted as the final evaluation metric to provide a comprehensive assessment of LLM accuracy. The F-measure offers a balanced evaluation of the trade-off between precision (the accuracy of the results) and recall (the comprehensiveness of the results). A high F-measure indicates that a model generates few incorrect relationships while also missing few correct ones. Therefore, it was determined to be the most appropriate metric for simultaneously evaluating the accuracy and comprehensiveness of the generated relationship pairs.
3.2 Design and Development of the Growth Progression Visualization System
We designed and developed a prototype web application to visualize and evaluate a learner's growth progression based on CSCASE. This system is composed of two main components: a learning map feature integrated with study logs (xAPI) and a microcredential issuance feature using Open Badges.
As this research is currently in the technical validation phase, we created a prototype version of CSCASE and used dummy data from a digital drill as the associated learning content for verification. For future real-world implementation, it is desirable that either an official version by MEXT or a version officially recognized by MEXT of CSCASE be implemented, with actual learning content, such as digital drills, linked to its unique identifiers (CFItem UUIDs).
3.2.1 System Architecture and Data Flow
The learning map feature of the system is realized through the following data flow, from the learner's activity to the final visualization:
Linking Learning Activities to CSCASE and Recording with xAPI: When a learner answers a question in external learning content like a digital drill, the activity (e.g., “Student A correctly answered Question 5”) is recorded. The problem sets within the learning content must be pre-assigned a unique CSCASE identifier (a CFItem UUID). When the learner engages with a problem, the learning content generates an xAPI statement containing information such as “actor”: “Student A”, “verb”: “answered”, “object”: “Question 5”, “result”: “correct”. Crucially, the corresponding CFItem UUID is stored in the result.extensions field, and the entire statement is sent to a Learning Record Store (LRS). It should be noted that most existing learning content does not currently support the generation of xAPI statements linked to CFItem UUIDs. Therefore, to simulate the output from a digital drill for this study, we created dummy xAPI data with assigned CFItem UUIDs and imported it into the LRS.
Data Extraction from LRS and Proficiency Judgment: When a teacher or learner requests the learning map, the system queries the LRS for the learning history of a specific student. It analyzes the retrieved xAPI statements, aggregating the number of correct/incorrect answers and timestamps for each CFItem UUID. Based on this aggregated data, the system internally determines the proficiency level for each learning item (e.g., “Not Started, ” “In Progress,” “Mastered”).
Dynamic Visualization of the Learning Map: Using the proficiency data, the system dynamically renders the learning map using the D3.js JavaScript library. This map is a network graph where nodes (circles) represent Course of Study items and edges (lines) represent the relationships between them. Each node is color-coded according to its proficiency level, and teacher-defined proficiency labels (A, B, C) allow for an at-a-glance understanding of the student's status.
View Switching Functionality: We implemented a feature that allows users to switch the map's display system based on their analytical goals. One option is the “Curriculum View,” which follows the structure of the Course of Study. The other is the “Unit View,” which is based on textbook units and shows the prerequisite relationships between them. This enables a user, for example, to identify a student's struggle in a particular unit and then trace back through the data to check their proficiency in the prerequisite units.
3.2.2 Architecture for Digital Badge Issuance
We designed an integration feature to issue digital badges compliant with the Open Badges as microcredentials certifying learning achievement. This feature creates highly reliable digital credentials by leveraging CSCASE as the certification criteria for learning outcomes. The issuance process is as follows:
Monitoring Achievement and Notifying the Teacher: The system analyzes the xAPI statements in the LRS to determine if a learner has met a predefined criterion (e.g., achieving over 90% accuracy on a set of problems related to a specific CFItem). When a learner meets the criteria, they are presented as a “badge candidate” on the teacher's dashboard or the learning map.
Teacher Approval and Issuance: The teacher reviews the presented candidate and can approve the badge issuance with a single button click. Incorporating this final step of teacher approval ensures the validity of the assessment by combining the system's automated judgment with the teacher's professional expertise.
Digital Badge Generation and Awarding: Upon teacher approval, the system generates and awards the digital badge to the learner. To guarantee the badge's reliability, it uses the alignment field to structurally link the certified achievement to a Course of Study item (CFItem). Specifically, the CFItem's name is stored in targetName, its UUID in targetCode, and CSCASE is listed as the targetFramework. This design makes the issued badge a highly reliable and objective credential, as it is machine-verifiable which specific item in the Course of Study the competency is based on.
4. Results
4.1 Results of CSCASE Construction
The estimation of relationships (systematic connections and relatedness) between learning items using LLMs revealed significant differences in accuracy among the seven models tested. Table 1 shows the evaluation results by subject domain, and Table 2 shows the results for “systematic connections” (precedes) and “relatedness” (isRelatedTo) as estimated by each LLM.

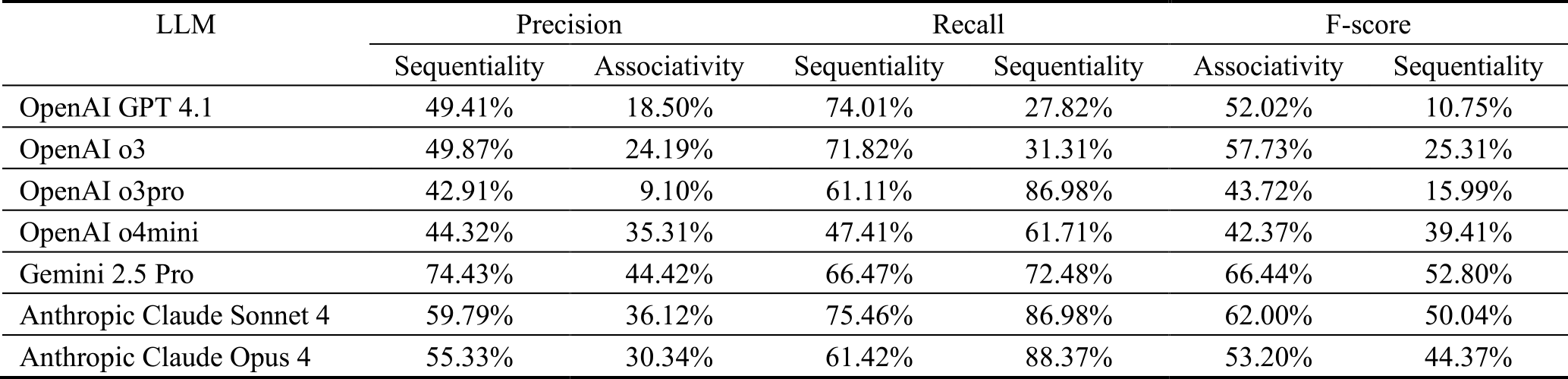
As a general trend, the F-measure for estimating systematic connections was higher than for relatedness across most models. Notably, GPT 4.1 achieved the highest F-measure (0.877) for systematic connections in Domain C but failed entirely to extract any relatedness connections in the same domain (F-measure of 0). Gemini 2.5 Pro demonstrated balanced performance in Domain B, showing high F-measures for both systematic connections (precedes: 0.764) and relatedness (isRelatedTo: 0.737).
Many models, particularly Claude Opus 4, Sonnet 4, and OpenAI o3pro, recorded high recall (Recall > 0.8) across multiple domains but tended to have low precision. This suggests a model characteristic that tolerates a high number of false positives to reduce false negatives.
Viewed by domain, Domain A exhibited lower F-measures overall compared to other domains, with many models showing remarkably low precision for estimating relatedness. This may indicate that the learning items in Domain A contain more complex or ambiguous relationships.
Due to the limited accuracy of the LLM estimations, we adopted a Human-in-the-Loop approach, using the LLM output as a preliminary draft. This draft was then manually corrected, supplemented, and revised by the first author, who has experience as an elementary school teacher, based on the ground truth data. This process produced the final CSCASE data, which defines the hierarchy, systematic connections, and relatedness for all 217 learning items in elementary school mathematics (an English translation is shown in Figure 5). Upon importing this dataset into the OpenSALT data management platform, we confirmed that basic functions—such as keyword searches and relationship visualizations—operated as intended (Figure 6).

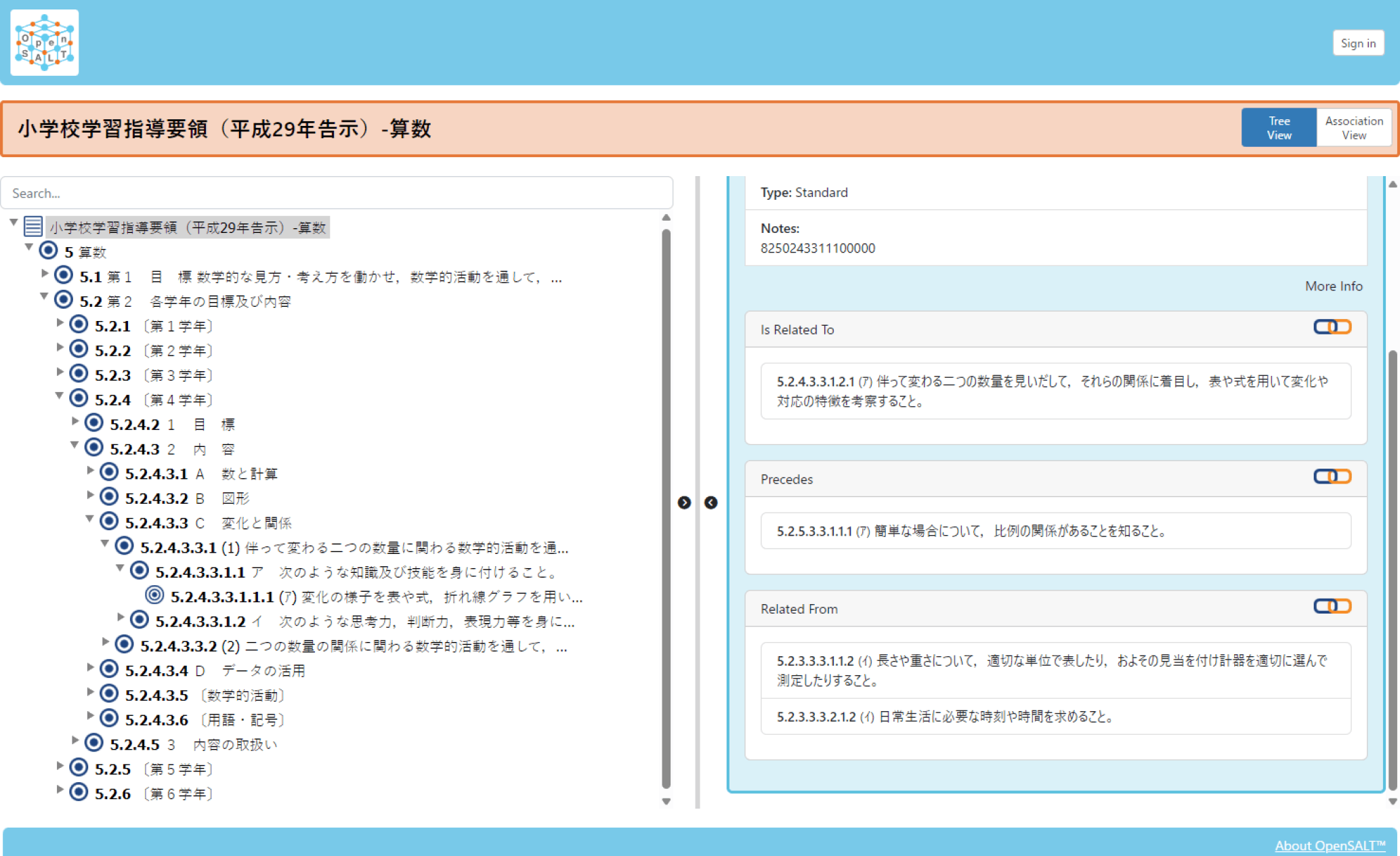
4.2 Implementation Results of the Growth Progression Visualization System
4.2.1 Visualization of Learning Progressions via the Learning Map
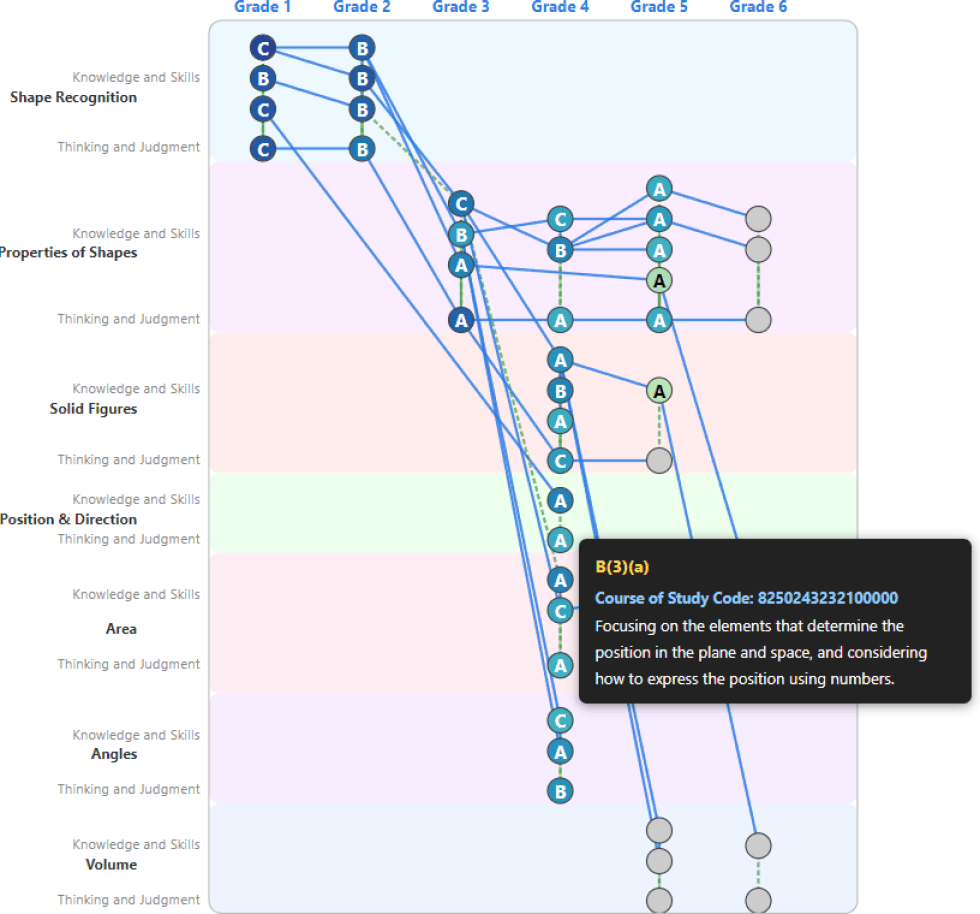
Based on the design in Section 3.2, we implemented a prototype web application to visualize a learner's growth progression (Figure 7). Using D3.js, we implemented a feature that determines the proficiency level of each learning item from xAPI data stored in an LRS and dynamically visualizes it as the color of a node on a network graph. We also implemented a “view switching feature” that allows the display to toggle between the Course of Study structure and the textbook unit structure, making it possible to trace back and check the proficiency of prerequisite items that may be causing a student's difficulties.
4.2.2 Verification of Learning Achievement via Digital Badge Integration
We implemented a process compliant with Open Badges that presents learners who meet achievement criteria (based on LRS learning records) to the teacher as “issuance candidates” and issues badges upon teacher approval. To ensure reliability, the CSCASE item's UUID is stored as the targetCode in the badge's alignment field, making it machine-verifiable which specific Course of Study item the badge certifies.
5. Discussion
5.1 Discussion on RQ1: Validity of Structuring the Course of Study and Estimating Relationships
RQ1 asked to what extent the complex structure of the Japanese Course of Study could be accurately represented by the international CASE format and with what degree of validity the relationships between learning items could be estimated using LLMs.
Regarding the first point, our implementation verified that the hierarchical structure of the Course of Study (Subject–Grade–Domain–Category–Viewpoint) can be comprehensively represented by the CASE data structure. However, concerning the latter point—the estimation of relationships by LLMs—our comparative validation against expert-created ground truth data indicated that even with various LLMs, it is difficult to fully automate the estimation of “systematic connections” (precedes) and “relatedness” (isRelatedTo) with an accuracy comparable to that of human experts.
Notably, most LLMs performed better at estimating “systematic connections,” which indicate prerequisite relationships, than “relatedness,” which covers a broader range of connections. A likely factor is that precedes relationships are based on a clear criterion (a time series), making them easier for LLMs to infer. In contrast, isRelatedTo is more context-dependent. For instance, estimating isRelatedTo can include identifying connections between different categories of learning content, such as between “Knowledge and Skills” and “Thinking, Judgment, and Expression,” which is presumably more challenging.
The trend of “high recall and low precision” observed for isRelatedTo estimation across many LLMs may reflect this difficulty. That is, LLMs extract a wide range of potential candidates that could be related, but this set contains a large number of incorrect items. This result suggests that while LLMs can identify relationships based on word co-occurrence and general context, they have not yet reached the point of understanding and structuring the specialized pedagogical connections within the curriculum, such as those tied to student developmental stages or subject-specific expertise.
Thus, the fact that LLM accuracy was limited—a finding also supported by previous research—confirms that full automation is not yet feasible. The optimal use of LLMs at present is not to replace experts but to support their process of defining and verifying relationships through a Human-in-the-Loop approach.
5.2 Discussion on RQ2: Effectiveness in Supporting the “Integration of Instruction and Assessment”
RQ2 asked to what extent learning maps and microcredentials based on CSCASE are effective in visualizing a learner's growth progression. The implementation results presented in Section 4.2 demonstrate clear effectiveness in addressing this question. The learning map records and visualizes the mastery of each learning item over time. This makes it possible to capture temporal growth—such as mastering a topic in the second semester that remained unachieved in the first—as objective data. Furthermore, by leveraging the systematic connections defined in CSCASE, the system can identify the prerequisite items causing a student's current difficulties and illuminate pathways to future learning. This represents a paradigm shift in assessment, moving from static “point-in-time” evaluations by teachers to dynamic “line” evaluations that map a learner's entire progression.
In this way, the system acts as a compass for teachers, allowing them to augment their professional experience and intuition with data-driven insights to provide personalized instruction for each student. Assessment is no longer a task for grading but is transformed into a “dialogue” tool that visualizes growth and supports the learner's next steps. Ultimately, the entire framework proposed in this research contributes fundamentally to the realization of the “Integration of Instruction and Assessment” by enabling Assessment for Learning and Assessment of Learning to operate integrally on a common data foundation.
5.3 Broader Potential of This Framework in Education DX
This framework holds the potential to contribute to solving other educational hurdles in Japan beyond its primary objective.
First, it can contribute to the substantive guarantee of Equality of Educational Opportunity, independent of the learning environment. Open Badges based on the “common scale” of CSCASE can serve as a “learning passport,” verifiably certifying the diverse learning accomplished by students who may be absent from school for long periods due to illness or other circumstances. This provides a technical foundation to ensure that their efforts and accomplishments are fairly evaluated and seamlessly integrated into their next stage of learning, regardless of their circumstances.
Second, the system promotes learner-centric education and fosters self-efficacy. CSCASE breaks down the broad goals of the Japanese Course of Study into manageable, incremental steps. The accumulation of these “small wins,” visualized as Open Badges, can offer learners with a tangible sense of self-efficacy. Furthermore, by making the connections between items visible, learners can comprehend their current position and see a clear path for future learning, allowing them to take ownership of their educational journey. For other practitioners aiming to leverage this framework, we offer a key insight: the initial effort to structure the curriculum standard, while substantial, is a critical investment. We recommend a collaborative approach involving subject matter experts, teachers, and engineers to ensure the resulting structure is both pedagogically sound and technically robust. This foundational work is what enables the subsequent development of meaningful visualizations and reliable micro-credentials.
5.4 Limitations and Future Work
There are three key challenges that necessitate further consideration for the real-world implementation of this framework.
The first consideration is the qualitative improvement of assessment to guarantee the reliability of issued Open Badges. The current Japanese Course of Study does not specify detailed rubrics, leaving the judgment of mastery to the discretion of each school. This could potentially cause variations in the value of issued badges. To objectively ensure badge reliability, it is essential to establish standardized award criteria, potentially by incorporating multi-level evaluation measures (rubrics) into the Japanese Course of Study and defining them as CFRubrics within the CASE framework.
The second consideration is the validation of this framework's applicability to subjects other than mathematics. Careful evaluation is necessary to assess its effectiveness in subjects with non-linear learning progressions, such as Japanese language and social studies, to enhance its versatility.
The third consideration involves establishing ethical standards and data governance for learner data. Given the sensitive nature of learning histories, it is critical to develop clear guidelines on privacy protection, data ownership, and scope of use. Addressing these ethical hurdles and building a transparent data management system are prerequisites for the social acceptance of this framework.
6. Conclusion
In this study, we proposed and implemented a framework for structuring Japan's national Course of Study utilizing the international CASE standard and for estimating the relationships between its items with LLMs. Our findings indicate that while the complex structure of the Japanese Course of Study can be accurately represented in the CASE format, expert knowledge remains crucial, as the fully automated relationship estimation by LLMs is not yet feasible (RQ1).
Furthermore, through the development of a prototype, we demonstrated that this system—built on the structured Course of Study (CSCASE)—can effectively visualize learners' “learning progressions,” including temporal changes in achievement and systematic connections between knowledge and skills, through a learning map and micro-credentials (RQ2).
By visualizing learning progressions through data, this framework addresses the structural challenge of achieving the “Integration of Instruction and Assessment” in education. It redefines the teacher's role from evaluator to supportive partner and empowers learners to develop autonomy and recognize their own growth. Broader applications are also envisioned, such as advancing “equality of educational opportunity” and “fostering self-efficacy.”
Nonetheless, this research has limitations. Its scope was confined to elementary school mathematics, and challenges remain regarding LLM estimation accuracy, assessment quality, and ethical considerations, as discussed in Section 5.4. Despite these limitations, the proposed approach to “structuring national standards” offers valuable insights for advancing micro-credential utilization and Education DX in Japan. The central practice highlighted in this paper is the methodical structuring of national curriculum standards as a foundational data layer. Our experience demonstrates that this structured approach, combining automated processing with expert validation, is not merely a technical exercise but a crucial step in building a trustworthy ecosystem for data-informed education. We believe this model provides a viable pathway for other institutions seeking to bridge the gap between curriculum, instruction, and assessment. We hope this study will serve as a catalyst for further dialogue and contribute to shaping the future of education.
Acknowledgments This work was supported by the 2025 grant from the Foundation for the Promotion of the Open University of Japan.
Reference
- [1] European Commission: A European approach to micro-credentials (online), available from 〈https://education.ec.europa.eu/education-levels/higher-education/micro-credentials〉 (accessed 2025-10-04).
- [2] Australian Government Department of Education: National Microcredentials Framework (online), available from 〈https://www.education.gov.au/higher-education-publications/resources/national-microcredentials-framework〉 (accessed 2025-10-04).
- [3] Malaysian Qualifications Agency: Guidelines to Good Practices: Micro-credentials (online), available from 〈https://www2.mqa.gov.my/qad/v2/garispanduan/2020/GGP%20Micro-credentials%20July%202020.pdf〉 (accessed 2025-10-04).
- [4] 1EdTech Consortium Inc.: Open Badges (online), available from 〈https://openbadges.org/about〉 (accessed 2025-07-10).
- [5] Preparatory Committee for the Establishment of Japan Micro-credential Organization, General Incorporated Association: Guidelines for Issuing Digital Certificates of Micro-credentials as Digital Badges ver.3.0 (online), available from 〈https://micro-credential-jwg.org/document/〉 (accessed 2025-07-10).
- [6] Yamada, T.: The Role of Information on Learning Objectives and Evaluation in the Educational Digital Ecosystem, Journal of JSEE, Vol.71, No.4, pp.4_25-4_30 (2023).
- [7] Ministry of Education, Culture, Sports, Science and Technology (MEXT), Elementary and Secondary Education Bureau: Notification on the Improvement of Student Guidance Records for Elementary Schools, Junior High Schools, High Schools, Secondary Education Schools, and the Elementary, Junior High, and High School Departments of Schools for the Blind, Deaf, and Other Special Needs (2001).
- [8] Curriculum Council: On the Evaluation of Student Learning and the Implementation of the Curriculum (Report of the Curriculum Council, December 4, 2000 (Excerpt)) (online), available from 〈https://www.nier.go.jp/kaihatsu/houkoku/tousin.pdf〉 (accessed 2025-10-04).
- [9] Nishizuka, K.: A Critical Review of Formative Assessment Research and Practice in Japan, International Journal of Curriculum Development and Practice, Vol.22, No.1, pp.15–47 (2020).
- [10] MEXT, Elementary and Secondary Education Bureau, Curriculum Division, Curriculum Subcommittee: Status of Deliberations at the Special Subcommittee for Curriculum Planning (online), available from 〈https://www.mext.go.jp/content/20250709-mext_kyoiku01-000043656_01.pdf〉 (accessed 2025-07-10).
- [11] Black, P. and Wiliam, D.: Assessment and Classroom Learning, Assessment in Education: Principles, Policy & Practice, Vol.5, No.1, pp.7–74 (1998).
- [12] Black, P. and Wiliam, D.: Inside the Black Box: Raising Standards through Classroom Assessment, Phi Delta Kappan, Vol.80, No 2, pp 139–148 (1998).
- [13] Black, P., Harrison, C., Lee, C., Marshall, B., and Wiliam, D.: Assessment for Learning: Putting it into Practice, Open University Press (2003).
- [14] Broadfoot, P., Daugherty, R., Gardner, J., Harlen, W., James, M., and Stobart, G.: Assessment for Learning: 10 Principles, Assessment Reform Group (2002).
- [15] MEXT: About the GIGA School Program (online), available from 〈https://www.mext.go.jp/a_menu/other/index_0001111.htm〉 (accessed 2025-07-10).
- [16] MEXT: 2017-2019 Revised Courses of Study (online), available from 〈https://www.mext.go.jp/a_menu/shotou/new-cs/1384661.htm〉 (accessed 2025-07-10).
- [17] MEXT: About the Code Table of the Course of Study Code (online), available from 〈https://www.mext.go.jp/a_menu/other/data_00002. htm〉 (accessed 2025-07-10).
- [18] 1EdTech Consortium Inc.: Competencies and Academic Standards Exchange (CASE) (online), available from 〈https://www.1edtech.org/standards/case〉 (accessed 2025-05-30).
- [19] ADL Initiative: xAPI Profiles (online), available from〈https://profiles.adlnet.gov/〉 (accessed 2025-05-30).
- [20] 1EdTech Consortium Inc.: CASE with Open Badges 3.0 (OB 3.0) and Comprehensive Learner Record 2.0 (CLR 2.0) (online), available from 〈https://www.imsglobal.org/spec/CASE/v1p1/impl〉 (accessed 2025-07-10).
- [21] 1EdTech Consortium Inc.: Open Badges (online), available from 〈https://www.1edtech.org/standards/open-badges〉 (accessed 2025-07-10).
- [22] 1EdTech Consortium Inc.: CASE Network 2 (online), available from 〈https://www.1edtech.org/program/casenetwork2〉 (accessed 2025-05-30).
- [23] 1EdTech Consortium Inc.: Unlocking the Power of Open Standards: Expanding Utility of Learning Frameworks with CASE and CASE Network 2 (online), available from 〈https://www.1edtech.org/blog/ unlocking-the-power-of-open-standards-expanding-utility-of-learning-frameworks-with-caser-and〉 (accessed 2025-07-10).
- [24] Education Data Plus Research Group: Course of Study LOD Project (online), available from 〈https://jp-cos.github.io/〉 (accessed 2025-05-30).
- [25] Le, A. T., Wagner, P., Le, N., and Ulges, A.: Zero-shot prerequisite skill identification from course syllabi using LLMs, arXiv preprint arXiv: 2507.18479 (2025).
- [26] Yang, T., Ren, B., Gu, C., He, T., Ma, B., and Konomi, S.: Leveraging LLMs for Automated Extraction and Structuring of Educational Concepts and Relationships, Machine Learning and Knowledge Extraction, Vol.7, No.3, p.103 (2025).
- [27] Kim, Y., Kojima, T., Iwasawa, Y., and Matsuo, Y.: Differences in Annotation Tendencies between Humans and LVLMs for Directed Graphs of Learning Order: A Case Study on the Junior High School Mathematics Course of Study, Proceedings of the Annual Conference of the Japanese Society for Artificial Intelligence, Vol.JSAI2025, No.3Win5–11, p.3Win511 (2025).
- [28] 1EdTech Consortium Inc.: IMS Competencies and Academic Standards Exchange (CASE) Service Version 1.0 (online), available from 〈https://www.imsglobal.org/sites/default/files/CASE/casev1p0/ information_model/caseservicev1p0_infomodelv1p0.html〉 (accessed 2025-07-10).
- [29] OpenSALT Community: OpenSALT GitHub Repository (online), available from 〈https://github.com/opensalt〉 (accessed 2025-05-30).
- [30] OpenAI: OpenAI Model (online), available from 〈https:// platform.openai.com/docs/models〉 (accessed 2025-07-10).
- [31] Google: Gemini models (online), available from 〈https://ai. google.dev/gemini-api/docs/models〉 (accessed 2025-07-10).
- [32] Anthropic: Claude models (online), available from 〈https://docs. anthropic.com/ja/docs/about-claude/models/overview〉 (accessed 2025-07-10).
- [33] TOKYO SHOSEKI CO., LTD.: Mathematics Content Progression Chart (online), available from 〈https://ten.tokyo-shoseki.co.jp/text/hs/sugaku/data/sugaku_16661_dm08.pdf〉 (accessed 2025-07-10).
- [34] SHINKOSHUPPANSHA KEIRINKAN Co,ltd.: Elementary School Arithmetic and Junior High School Mathematics Content Progression Chart (online), available from 〈https://www.shinko-keirin.co.jp/keirinkan/chu/math/support/data/content_line.pdf〉 (accessed 2025-07-10).
- [35] Jiji Press: 2024 Elementary School Textbook Adoption Status, Naigai Kyoiku, No.7135 (2024).

m238105s@st.u-gakugei.ac.jp
Mitsushiro Ezoe received his B.A. in Letters from Soka University in 2012. After working as an elementary school teacher at public and private schools, he joined codeTakt, Inc. in 2021, where he currently works. He received his master's degree in education from the Graduate School of Education at Tokyo Gakugei University in 2025 and is currently a Ph.D. student in the Graduate School of Information and Systems Engineering at the University of Electro-Communications. His research is focused on self-regulated learning, teacher feedback, and learning analytics. His awards include the Student Encouragement Award at the IPSJ Symposium on Information and Systems in Education (SSS2025). He is a member of the Japan Society for Educational Technology (JSET), the Information Processing Society of Japan (IPSJ), the Japanese Society for Information and Systems in Education (JSiSE), and Japanese Society of Learning Analytics (JASLA).

Masanori Takagi received his B.Eng. in 2003 and his Ph.D. in Engineering in 2007, both from Soka University. He began his academic career as an Assistant Professor at Soka University's Faculty of Engineering in 2007. In 2010, he became a Lecturer at the Faculty of Software and Information Science, Iwate Prefectural University, where he was promoted to Associate Professor in 2013. Since 2022, he has been an Associate Professor at The University of Electro-Communications. His research is focused on the development of item-generation learning support systems and e-testing. His awards encompass the Student Encouragement Award at the 65th National Convention of the IPSJ, the Encouragement Award at the IPSJ Symposium on Information and Systems in Education (SSS2003), and the Best Paper Award at SSS2019. He is a member of the Information Processing Society of Japan (IPSJ), the Institute of Electronics, Information and Communication Engineers, the Japanese Society for Information and Systems in Education (JSiSE), the Japan Society for Educational Technology (JSET), and the Japan Association for Educational Measurement.
採録日 2026年1月13日