部門をまたがったトレーサビリティを実現するデータ管理システムの導入から運用におけるプラクティス
Practices for the Implementation and Operation of a Data Management System that Achieves Cross-departmental Traceability
1. はじめに
1.1 背景
近年,気候変動や自然災害,新型コロナウイルス感染症などによるサプライチェーンの分断や経済活動の停滞などを背景として,このような不確実性の高まる時代において製造業が取り組むべき重要な観点として,レジリエンス,グリーン,デジタルがあげられている[1], [2].
製造業に代表されるような,複数の業務から構成される業務プロセスで作業が実施される現場においては,デジタルデータの収集や自動化といったシステム化が取り入れられている.ここで,業務や業務プロセスについて,現場ごとに区別する単位は異なり得る.本稿では,業務とはたとえば部品の入荷検査や組付け作業などを指し,業務プロセスとはたとえば部品の受取りから組付け,検査までの,業務の一連の流れのことを指す.各業務のデジタル資産化とそれに基づく詳細なビジネス分析が可能となることで,製造現場での不具合原因の迅速な追跡や製品のリードタイム改善など,具体的なメリットが示されている[3].このような生産システムを含む,多数のセンサーから収集される膨大なデータを処理・分析するようなIoTソフトウェアの市場規模は,2032年には6700億米ドル超に拡大すると見込まれており,年平均成長率(CAGR)は24.5%程度におよぶとされている[4].
製造業は,複数の業務プロセスから構成されるため,各業務間のつながりを踏まえたシームレスなデジタル化が求められている.しかし,多くの企業では,DX活動は部分最適な改善に留まっており,現場全体の業務プロセス最適化やトレーサビリティの確保に課題が残っている[5].DX推進に対する課題としては,DXノウハウの不足や,セキュリティ対策や運用を行うスキル・人員の不足,といった点が挙げられる.事業活動の効率化のためには,事業を構成する多様な業務のつながりを意識し,バリューチェーン全体の業務プロセスを最適化することが重要であるが,現状では,部門横断的なデジタル化の推進は不十分であり,データについても業務ごとの改善に活用されるに留まる場合が多い.業務プロセス全体を最適化するには,各業務システムから発生する膨大かつ体系の異なるデータを,業務のつながりに基づいて集約し,統合的に管理できる仕組みが必要となる.
1.2 データトレーサビリティを効率化する4Mデータ管理システム
日立では,経済産業省より受託した「平成28年度IoT推進のための社会システム推進事業(スマート工場実証事業)」におけるデータプロファイルの設計コンセプトに基づいて,業務プロセスにおけるデータトレーサビリティを効率化するためのデータモデルの検討を行い,このデータモデルの考えを適用した「4Mデータ管理システム」を開発した[6], [7].ここで,製造業の経営資源を4Mで整理するアプローチについては,先行研究で紹介されている[8].4Mデータ管理システムの特徴は以下の2点である.なお,本システムの詳細については,3章にて述べる.
- ・業務プロセスにつき,関わるモノや情報を単位として,業務データの入出力や処理を実現
- ・モノや情報は,製造業の経営資源となる4要素(4M)で分類・管理:huMan(作業者),Machine(機械,設備),Material(材料),Method(手順)
ここで,4Mデータ管理システムのようなシステムを顧客に提案し,顧客のデータ利活用の効率化を継続的に実現するには,システムの導入提案から運用までを一貫してサポートすることが重要である.
1.3 本稿での報告
本稿では,前述の4Mデータ管理システムについて,実際の顧客現場で導入提案から運用する際に挙がった要件と,それに対応するために検討した機能およびシステムアーキテクチャについて論ずる.
本稿の構成は次のとおりである.2章で本稿での報告の前提とする4Mデータ管理システムの説明を行い,3章で関連研究について触れる.そして,4章にてシステムアーキテクチャの検討および機能開発の内容について述べ,最後にこれらを5章にまとめる.
2. 4Mデータ管理システム
本稿での報告の前提とする4Mデータ管理システムについて,本章で詳述する.4Mデータ管理システムの概念図を図1に示す.4Mデータ管理システムでは,現場のデータを業務と4Mのデータによって構造化する.業務の入力として部品や材料であるMaterialが入力され,業務を実施した結果として完成品であるMaterialが出力される.そして,業務を実施するための資源となるその他4M情報が業務に関連付けられている.これらの業務と4Mの要素に対し,現場で発生する様々なデータを関連付ける.業務に入力されるMaterialは,前段の業務の出力であり,業務の出力であるMaterialは,後段の業務の入力となるため,このような業務と4Mデータからなるデータモデル(以後,プロセスモデルと呼ぶ)を連結することで,一連の業務プロセスとそれに関連するデータを表現できる.ここで,1章で述べたように業務および業務プロセスを区別する単位は,現場ごとに異なり得る.4Mデータ管理システムにおいては,データ管理者の意図を反映して,適切に業務や業務プロセスを定義することが肝要である.
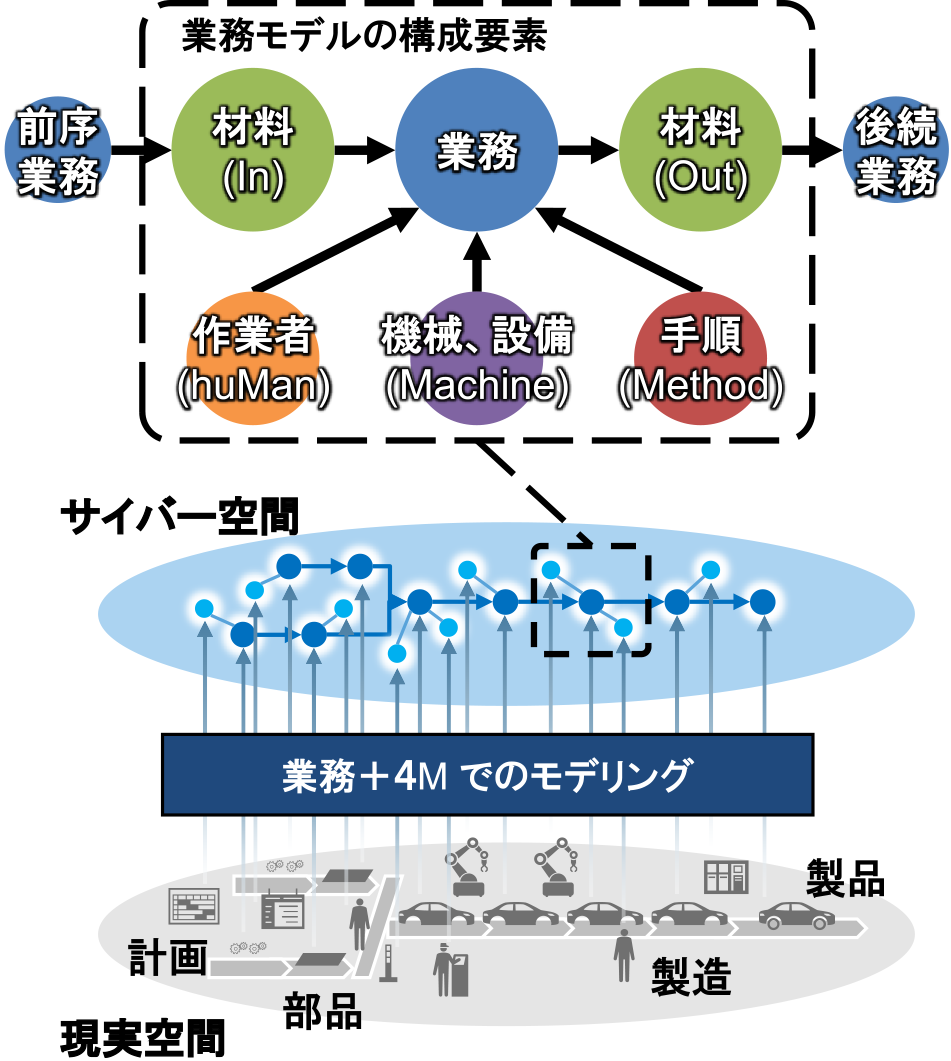
Fig. 1 Conceptual diagram of the data management system.
2.1 トレーサビリティの実現
4Mデータ管理システムでは,一連のプロセスに関連するデータを,データ間のつながりを記録するグラフ構造を持つデータベース(DB)であるグラフDBによって記録する.データ管理システムのDBの構造は,大きくモデルDB,グラフDBおよびデータレイクから構成される.このうち,モデルDBとグラフDBが4Mデータ管理システムのシステム内のDBである.データレイクは業務プロセスに関わるデータが格納される,4Mデータ管理システムでの管理対象とするDBである.
トレーサビリティを事例にしたシステム動作概要を図2を用いて説明する.ここで,プロセスフローについて,溶接・塗装・組立・検査の順で業務が連なることを想定する.たとえば,検査業務において検査に違反した製品(製品X)が発生した場合,検査違反の要因分析のため,当該製品の製造に使用された部品(部品1)について,部品1に対して行われた業務のデータをトレースバックしたい場合がある.このとき,従来のトレースバックにおいては,製品Xに用いられた部品1を特定するためのETL処理(データの抽出・加工・ロード処理)や,部品1に対して使用された設備機器を特定するためのETL処理や,当該設備機器の部品1に対する稼働履歴を抽出するためのETL処理など,複数のETL処理を組み合わせる必要がある.ETL処理の作成においては,どの現場実績データがどこのDBに格納されているか等を把握するためのOT知識と,所望のデータを抽出するETL処理を作成するためのIT知識と,の双方が求められ,実装に工数が多くかかる場合がある.

Fig. 2 Example of data traceability.
4Mデータ管理システムでは,このようなデータ抽出に係る工数の削減に向けて,個別のETL処理を作成することなく,データトレースを可能としている.4Mデータ管理システムでは,グラフDBにあらかじめグラフ構造のデータとして製品IDと,製品に使用された部品の部品IDと,部品に使用された設備機器の機器IDとを保持し,また,検査データや設備機器の稼働履歴データが格納されているデータレイクの参照先をモデルDBに保持する.これにより,検査違反が発生した製品に対して,製品に使用された部品に対する設備機器の稼働履歴を,グラフデータで示されるつながりに基づいてたどることができ,個別のETL処理を作成することなく抽出することが可能となる.これにより,検査違反の要因分析の効率化が期待される.
2.2 4Mデータ管理システムを構成するDBおよびプロセスモデル
モデルDBは,業務と4Mのプロセスモデルを管理する.具体的には,業務プロセス全体において,どのような業務や4Mがあるか,および,Materialを介した業務の前後関係や,業務と4Mの関係,業務や4Mと後述するデータレイクとの関係(テーブルやカラム,データを抽出するためのキーがどのカラムであるか)などを管理する.
グラフDBでは,データはノードと,ノード間のつながりを示す接続線による有向グラフとして表現される.図2に示した業務や4Mは,グラフDBにおいて,ノードとして記録され,業務と4Mとの関係はノード間を接続線でつなぐことによって記録される.このようなデータ間の関係性を記録するグラフDBを用いて,ある業務や4Mのノードを起点として,ノード間のつながりをたどることで,複数の工程にまたがるデータの抽出が容易となる.
グラフDBには,モデルDBに蓄積されたモデル情報に従い,各業務の実績データを登録する.この際,グラフDBにすべての実績データを登録するわけではなく,データ間の関係性に関するデータのみを登録する.具体的には,製品等の業務対象の識別情報や,ある製品に対して業務が実施された時刻情報などの業務の進捗情報を登録し,実際の業務実績データについては,データレイクからデータを抽出するためのキー情報のみを登録する.
このように,モデルDBおよびグラフDBにて,データレイクに格納されたデータの関係性を定義することで,データレイクから必要なデータを紐づけて抽出し,AI分析や可視化,シミュレーション等に活用するためのデータマートとして出力することができる.
3. 関連研究
1章で述べたように,製造業の経営資源を4Mで整理するアプローチについては,Claudioらが報告をしている[8].従来の多くのDfA(Design for Assembly)手法が,主に製品設計(Material)の最適化に重点を置いていたのに対して,手順(Method),設備(Machine),作業者(Man)という,組立作業に関わる他の3要素を明示的に分析対象とし,これらを統合的に扱うフレームワークを提唱している.これにより,製品設計の変更だけでなく,作業プロセスの見直し,設備改善,作業者トレーニングといった多角的な改善策を,体系的に検討し同時並行で実施することを可能としている.
また,製造業における業務プロセス横断的なデータトレーサビリティの向上のため,様々な手法やシステムが提案されている.
Borjaらは,中小規模の製造業者に向けたSmall Start可能な,RFIDやReaderを取り付けたグローブを活用したトレーサビリティ管理フレームワークとしてTF4SM(Traceability Framework for Small Manufacturers)を提案している[9].これにより,コストの高い従来のトレーサビリティシステムを導入するのが難しい場面であっても,トレーサビリティ管理システムの安価な導入が可能となる.
また,Fátimaらは,製薬製造プロセスにおける製品のトレーサビリティとデータの整合性を確保するためのフレームワークとしてSPuMoNI(Smart Pharmaceutical Manufacturing)を提案している[10].SPuMoNIは,ブロックチェーン技術,データ品質保証,インテリジェントエージェントを統合し,製造プロセスの透明性と信頼性を向上させることを目的としており,このアプローチにより,製薬業界の規制遵守とリスク評価が強化され,患者の安全性の向上が期待される.
Nishikawaらは,製造業における生産ラインの各工程のトレーサビリティの要求が,単なる工程管理に留まらず,ミクロレベルでの再帰的な追跡分析への展開が必要であることを論じ,それに向けたデータベース設計の指針を述べている[3].このミクロレベルのトレーサビリティは,製造イベントの祖先や子孫の完全な追跡を可能とし,徹底的な生産検査や欠陥状態の局所的な影響調査,個別のリードタイム分析など,製造現場での幅広い実用例が期待されている.
また,筆者らは,2章で説明したモデルDBで管理するプロセスモデルについて,データドリブンで構築する方法について報告してきた[11]-[13].MES(Manufacturing Execution System)などで収集される現場実績データを入力とした場合のプロセスモデル構築手法について,図3に示す.製品に固有の識別子や,業務が行われたタイミングの情報をもとに,各製品のフローを推定し,また製品―部品関係を考慮することで,複数工程からなるプロセスフロー全体を推定している.ここで,製造業においては,プロセスに係る現場データや設計データの取得元としては,MESのほかにもERP(Enterprise Resource Planning),PLM(Product Lifecycle Management)といった様々な業務システムが考えられる.筆者らは,各業務システムが持つデータにいて,アダプタを介して共通的なプロセス定義データ構造(共通BOP(Bill of Process))に変換し,共通BOPデータを入力としてプロセスモデルの生成を行うことを提案した[13].共通BOPについて,ERPやPLM等の業務システムとして一般に知られているパッケージが持つBOP相当の情報を比較調査した結果に基づき,図4のように定義した.比較調査からは,工程以下の階層や,工程における入出力品目の定義の作法が,パッケージごとに特色があることが分かった.業務プロセスの構成については,製造現場の改修や設計変更に伴って変更されるものである.データ管理の精緻化のためには,その都度モデルの変更が必要となるが前述の先行報告のように,現場実績データや設計データからデータドリブンでプロセスモデルの生成を行い,モデル構築を容易化することで,データ利活用が促進されるものと考える.

Fig. 3 Example procedure for creating a process model.

Fig. 4 Common BOP data structure.
また,日立では,業務実績データを格納するグラフDBにおけるトレーサビリティについて,日立の商用DBであるHADB(Hitachi Advanced Data Binder)の適用を検討している[14].製造業に特有のトレーサビリティを重視したクエリを含むDBのベンチマークである4mbenchを用いて,トレーサビリティを実現するために好適なDB設計について実験的に評価を行っている[3], [15], [16].
このように,製造現場で発生するデータの管理についての先行研究があるが,一方で,このようなデータ管理システムを実際の現場で導入あるいは運用する際の要件や解決方法について論じた文献は少ない.本稿では,これら先行知見を踏まえ,このようなデータ管理システムを実際の現場で導入あるいは運用する際のプラクティスについて報告する.
4. 4Mデータ管理システムの活用に向けたプラクティス
4.1 4Mデータ管理システムの導入から運用までの要件
4Mデータ管理システムを導入提案から運用するまでの各フェーズにおいて,プロセスモデル構築のために行われる作業について,表1のように整理した.4Mデータ管理システムを用いたデータ利活用を行うにあたっては,フェーズごとに異なる顧客要件およびシステムを構築・運用するSI担当者側の要件が,実際の案件を進めるうえで挙げられた.
Table 1 Tasks for constructing the process model.

提案のフェーズにおいては,顧客ニーズに合わせたデモ環境を活用したいというSI担当者の要望がある.現場プロセスにおけるデータ管理に対しての,顧客が抱える課題を把握し,その解決策としての本システムの有効性を示すためには,個別のデモ環境を柔軟にかつ迅速に用意できることが望ましい.
構築のフェーズにおいては,顧客現場プロセスの実態を把握するためのヒアリングや認識合わせといった作業や,実際にプロセスモデルを構築するためのSI作業が必要となる.顧客現場プロセスの把握のためのヒアリングは,PPTやExcel等を用いたドキュメントベースで行われる場合が多く,持ち帰ったヒアリング結果をもとに設計したプロセスモデルについて確認する作業を繰り返すことで,最終的なプロセスモデルの構築を行っている.構築フェーズの迅速化に向けては,顧客とのディスカッションの場にて,柔軟にモデル構築・変更を可能とすることが期待される.
運用のフェーズでは,製品の設計変更や製造設備の変更,生産性改善等に伴う工程変更などの理由に伴いプロセスモデルの更新が必要となる場合があり,その都度モデルを作り替えるSI作業が必要となる.したがって,運用フェーズの迅速化のためには,顧客の意思や現場実態を踏まえたプロセスモデルの更新を容易化することが期待される.
以上をまとめると,4Mデータ管理システムに対しては,SI作業者や顧客からモデルを確認可能なインタフェースを備え,デモ用のスモールスタートなモデルから実際の現場のモデルまで,柔軟かつ迅速にモデル構築が可能であり,データ利活用が開始できることが求められている.
3章で述べたように,筆者らはこれまで,データドリブンでのプロセスモデル構築方法について報告してきており,これにより,構築・運用フェーズにおけるモデル構築・変更工数の削減を見込んでいる.一方で,提案のフェーズにあっては,顧客データを受領できない,あるいは存在しない場合が多く,データドリブンでのプロセスモデル構築はできない.提案フェーズでは,どのようにデータ管理が実現されるのかについて,顧客と意識合わせをしながら,顧客の意図に沿ったプロセスモデルの構築を容易化する機能が求められる.
4.2 機能開発およびシステムアーキテクチャ
上記の提案から運用までの各フェーズにおける要件への対応として開発する各機能の役割の概念図を図5に示す.本稿では,次の4つの観点での機能開発により,4Mデータ管理システムの活用の効率化を狙う.
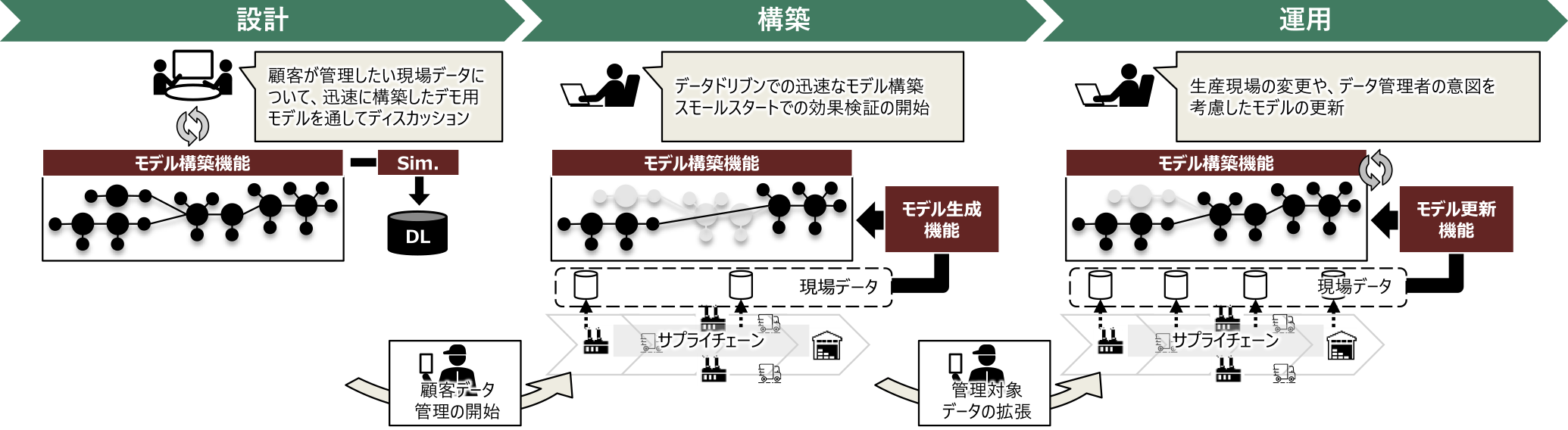
Fig. 5 Overview of the roles of development functions in each phase.
- ・プロセスモデル構築用GUI機能(モデル構築機能)
- ・プロセスモデルと連携した生産シミュレータ(シミュレータ(Sim.))
- ・データドリブンでのプロセスモデル構築機能(モデル生成機能)
- ・データドリブンでのプロセスモデル更新機能(モデル更新機能)
提案フェーズでは,プロセスモデル構築用GUI機能により,顧客とディスカッションしながら迅速にデモ環境を構築し,生産シミュレータと連携することで,4Mデータ管理システムの効果実証を具体化されることが期待される.構築フェーズでは,実際の顧客データをもとにデータドリブンで推定したプロセスモデルを前提としてモデル構築を行うことで,システム導入の迅速化が期待される.運用フェーズでは,管理対象とする顧客データの変更を踏まえて,プロセスモデルの変更をレコメンドすることで,データ利活用の効率化が期待され,また,データ管理のあるべき姿の検討や,プロセス設計の見直しにつながる気づきを得られることも期待できる.
これら4つの機能観点を踏まえたシステムアーキテクチャについて,図6に概念図を示す.これまでに報告した,データドリブンでのモデル構築・更新機能や,共通BOPによる入力データ形式の一元化に加えて,プロセスモデル構築用GUIを介したモデル編集機能を取り込むことで,提案から運用までの各フェーズでの要件への対応を行っている.なお,4つの機能のうち,プロセスモデル構築機能および更新機能の詳細について,これまでの報告を参照されたい[11]-[13].

Fig. 6 System architecture.
プロセスモデル構築用GUIでは,ユーザ操作によってプロセスモデルを編集するための機能を提供する.プロセスモデル構築作業について,従来では,ドキュメントベースで行われていた打合せが,その場での柔軟なモデル構築・変更を可能とすることで,ヒアリングの効率化および迅速化が期待される.
GUIでは,プロセスモデルについて,業務の追加・削除・集約や,業務間のパスの追加・削除,4Mノードの紐づけ設定の編集を可能とする.4Mノードの紐づけ設定の編集においては,業務に紐づく4Mの種類や,当該4Mデータが参照するデータレイクのテーブル,あるいは検索キー等の検索情報を設定できる.プロセスモデルや4Mデータ管理システムでの管理対象とするデータレイクの情報を生産シミュレータと連携することで,提案フェーズにあっては,顧客の意図に即した製造プロセスのデータ収集・可視化が可能となる.
また,適切なプロセスモデルの構築のためには,現場実態に加えて,各業務システムでのプロセス定義や,モデル設計者の意思を加味してモデリングを行うことが必要であり,構築フェーズあるいは運用フェーズでは,データから推定されるプロセスモデルをベースとして,ユーザの意思の元で適切な姿へと編集することが想定される.ユーザによる編集作業の容易化のため,GUIでは下記の補助機能を持つ.
- ・差分検知・レコメンド機能:現在運用中のプロセスモデルが存在する場合,そのプロセスモデルと編集中のモデルの差分を検知し,編集中モデルに追加すべき業務やフローをレコメンドする.
- ・編集履歴反映機能:プロセスモデル編集履歴を保持しておくことで,過去編集内容を一括で再反映する.
- ・プロセスモデルの保存・読込機能:作成したプロセスモデルをファイル出力し,また作成済みのモデルファイルをベースとしてモデル編集を開始する.この機能を用いてプロセスモデルをライブラリ化する.
これらの補助機能により,データドリブンで生成されたプロセスモデルをベースとして,ユーザ編集作業を行う際の作業工数の削減が期待され,構築フェーズ・運用フェーズにおけるプロセスモデル構築・運用の迅速化が期待される.
4.3 評価
4.2節で述べたシステムアーキテクチャおよび開発項目に則り開発したプロトタイプについて,実業務における改善効果を評価した.開発したプロトおよび4Mデータ管理システムの画面例を図7に示す.
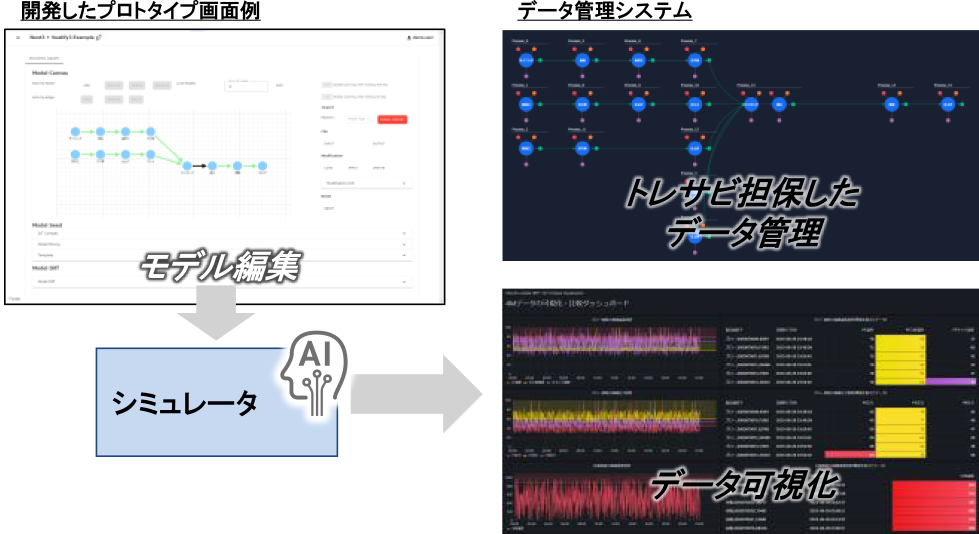
Fig. 7 Example screens of the model editing function and data management system.
提案フェーズにおいては,ある製造プロセスのモデルを作成する事例において,従来ではドキュメントベースでの顧客ヒアリング結果に基づくプロセスモデル構築に係る工数を含めて,4Mデータ管理システムの構築に10人日程度のSI工数が見積もられていたが,プロトの活用により半日での実施が可能となった.また,構築・運用フェーズにおいては,50個近くの工程業務で構成されたある製造プロセスのモデルを作成する事例において,被験者の実作業工数をもとにプロト活用による効果を試算した.当該規模のプロセスモデル構築作業には従来1人月程度の工数が見積もられていたが,データドリブンでのプロセスモデル生成およびGUIベースでのモデル編集により,1週間程度への作業時間の短縮が可能となった.これより,SI作業の工数比で30%程度までの削減効果が見込まれた.
5. おわりに
デジタルデータを活用したDX活動において,部門・工程をまたがった業務プロセス全体の最適化を検討するためには,サイロに管理されたデータを統合的に管理・分析することが重要である.データを統合的に管理するシステムを顧客に導入提案し,データ利活用の効率化を継続的に支援するためには,システムの導入から運用までを一貫してサポートすることが重要である.
本稿では,生産システム内のサプライチェーンを業務+4Mのデータモデルで再現し,データ管理を行う4Mデータ管理システムについて,データモデルの導入・構築・運用に向けたプラクティスについて述べた.各フェーズにおける要件を鑑みて検討したシステムアーキテクチャおよび機能に基づき開発したプロトタイプでの評価を通じて,導入から構築までに従来ではかかっていたSI工数の削減効果が見込まれた.なお,厳密な定量的評価や,工数削減要因の詳細な分析は今後の重要な課題である.
今後,本システムの検討を通じて得られたプラクティスを通して,全体最適視点での継続的な生産性改善に貢献していく.
謝辞 本研究および本稿の執筆にあたり,多くの方にご指導ご協力をいただきました.心より感謝申し上げます.
参考文献
- [1] 経済産業省,厚生労働省,文部科学省:2021年度版ものづくり白書(2021).
- [2] 経済産業省:DXレポート2(中間とりまとめ)(2020).
- [3] Nishikawa, N. et al.: Physical Database Design for Manufacturing Business Analytics, 2023 IEEE International Conference on Big Data (BigData), pp.1793–1802, DOI: 10.1109/BigData59044.2023.10386475.
- [4] Fortune Business Insight: IoT in Manufacturing: Global Market Analysis, Insights and Forecast, pp.2019-2032 (2024).
- [5] 情報処理推進機構:デジタル時代のスキル変革に対する調査(2022年度)(2023).
- [6] 日立製作所,ニュースリリース,入手先 〈https://www.hitachi.co.jp/New/cnews/month/2018/10/1017.pdf〉(参照2024-11-08).
- [7] 日立製作所,入手先 〈https://www.hitachi.co.jp/products/it/IoTM2M/list/iotcompas/index.html〉(参照2024-11-08).
- [8] Favi, C. et al.: A 4M approach for a comprehensive analysis and improvement of manual assembly lines, Procedia Manufacturin, Vol.11, pp.1510–1518 (2017).
- [9] Bordel Sánchez, B. et al.: TF4SM: A Framework for Developing Traceability Solutions in Small Manufacturing Companies, Sensors, Vol.15, pp.29478–29510 (2015).
- [10] Leal, F. et al.: Smart Pharmaceutical Manufacturing: Ensuring End-to-End Traceability and Data Integrity in Medicine Production, Big Data Research, Vol.24 (2021).
- [11] 萩原岳大,石田仁志,川村陸,宮本啓生:製造業におけるデータ管理のためのデータモデリングシステムの検討,情報科学技術フォーラム講演論文集(FIT), Vol.21, No.2, pp.195–196 (2022).
- [12] 萩原岳大,石田仁志,川村陸,宮本啓生:製造業におけるデータ管理のためのデータモデリングシステムの検討,情報科学技術フォーラム講演論文集(FIT), Vol.22, No.2, pp.251–252 (2023).
- [13] 萩原岳大,石田仁志:製造業におけるデータ管理のためのデータモデリングシステムアーキテクチャの提案,情報科学技術フォーラム講演論文集(FIT), Vol.23, No.2, pp.299–300 (2024).
- [14] 日立製作所,入手先 〈https://www.hitachi.co.jp/Prod/comp/soft1/data-binder/index.html〉(参照2024-03-14).
- [15] Goda, K. et al.: 4mbench: Performance Benchmark of Manufacturing Business Database, Lecture Notes in Computer Science, vol. 13860, (2023).
- [16] 西川記史,藤原真二,早水悠登,合田和生:データに基づく品質管理を実現するためのデータベース物理設計の評価,DEIM Forum 2023, 2a-3-5, (2023).

takehiro.hagiwara.wn@hitachi.com
2019年東京大学大学院情報理工学系研究科修士課程修了.同年株式会社日立製作所入社.現在,金融業界向けの生成AIを活用したサービス開発に従事.情報処理学会会員.

hitoshi.ishida.yg@hitachi.com
2009年東北大学大学院工学研究科電気通信工学専攻修士課程修了.同年株式会社日立製作所入社.現在,製造業,社会インフラ等における知識抽出向けデータモデリング技術の研究開発に従事.電子情報通信学会会員.

riku.kawamura.ep@hitachi.com
2021年東京工業大学(現:東京科学大学)大学院情報通信系情報通信コース修士課程修了.同年株式会社日立製作所入社.現在,AIエージェントを活用した鉄道保守向けプラットフォーム技術の研究開発に従事.

hiroki.miyamoto.zu@hitachi.com
2000年東北大学大学院情報科学研究科情報科学専攻修士課程修了.同年株式会社日立製作所入社.現在,生成AIを活用した事業開発と,製造業を中心とした産業分野におけるDXを推進.
採録日 2025年7月8日