テキストマイニングを活用した用途探索手法
※本稿の著作権は,日本アイ・ビー・エム(株)に帰属します.
1.はじめに
企業が成長を遂げるためには,研究開発部門において保有する技術や製造する素材の新たな応用を探索し,継続的に新製品を創出することが不可欠である.経済産業省による企業アンケート調査[1]によれば,7割以上の企業が研究開発への投資目的として「新製品・サービスの提供」を挙げており,これが最も多い回答である.一方で,約半数のCTO(最高技術責任者)が研究開発における課題として「経営戦略・事業戦略との整合性を保った研究開発テーマの設定」および「研究開発の成果を製品化・事業化する比率の向上」を挙げているとの調査結果[2]もある.これらの結果は多くの企業が技術や素材の用途探索において課題を抱えていることを示唆している.
本課題に対して,アイデアの発想に基づく用途探索手法[3][4]が提案されてきたが,これらの手法は得られる成果が作業者の発想スキルに大きく依存する問題があった.また,特許システム上でキーワードを掛け合わせて特許を絞り込み,用途を探索する手法も知られているが,現実的な時間内で探索できる特許の範囲に限界があり,幅広い領域を対象に用途を探索することは困難である.
この問題に対して,AIの自然言語処理の技術を活用したアプローチ[5]が提案されている.この手法は大量の特許を対象に特許明細書の【発明の効果】の項目から課題と効果の因果関係を示す記述を抽出し,自社技術が解決する課題および類似課題と因果関係を持つ効果に関する記述を見つける手法である.この手法は作業者のスキルへの依存が少なく,かつ探索範囲の限界という問題を解決している.しかし,特許中の分析対象項目として【発明の効果】を利用するため,明細が項目別に記載されていないものが過半である海外特許の分析が難しいという問題がある.また,専用システムを開発することが前提であり,一般の企業が容易に着手できないという問題もある.
近年,自然言語処理の技術を容易に活用できるテキストマイニングツールが各社から製品化され,またオープンソースも存在する.テキストマイニングツールは特にアンケート等の短文の分析に多く活用されてきたが,その性能は年々向上し,誰もが大量の特許等の長文テキストを分析できる環境が整いつつある.
本稿ではこのテキストマイニングツールを活用した用途探索手法を提案する.なお,本稿において説明に使用した分析例はIBMのテキストマイニングツールであるIBM Watson Discoveryを利用している.
2.特許のテキストマイニング
2.1 特許を対象に用途を探索する理由
特許の記載内容は国際的な統一様式が定められており,「発明が解決しようとする課題」,「課題を解決する手段」,「産業上の利用可能性」が記載されている.つまり,各種技術・素材の具体的な用途が,必要とされる機能特性とともに記載されている.特許は国内では年間約30万件,世界では年間約800万件が申請されており,この膨大な数の特許から,技術・素材,用途,機能特性をその共起関係とともに抽出すれば,自社の技術・素材がどのような用途に利用されているのか,あるいは自社の技術・素材が提供する価値(機能特性)は誰(出願人)がどのような用途で求めているのかを網羅的に把握可能となる.
同様に技術・素材の用途および機能特性が記載されているデータソースとして論文と技術情報誌がある.双方ともに有償のものが多く,多量の文書を分析対象にするとその購入コストが膨大になるという問題がある.さらに論文と技術情報誌はテキストマイニングで分析する際,著作者に承諾を得なければならない場合もあり,容易に分析作業を開始できない.特許は低コストで大量の文書を入手できる利点があり,さらに特許には著作権が認められていないことから分析にあたり著作者の承諾が不要で,容易に大量のデータを揃えることが可能であり,用途探索の対象データに最も適している.
2.2 テキストマイニング概要
テキストマイニングはAIの主要技術領域である自然言語処理のテクノロジーを活用したツールで,大量のテキストから単語を抽出し,単語間の共起関係を可視化する機能を有する.よってテキストマイニングツールは特許に記載のある技術・素材,用途,機能特性に関する単語をその共起関係とともに抽出し,分析を可能とする.
テキストマイニングの機能をより詳細に説明する.図1にIBM Watson Discoveryを例にテキストマイニングの主要機能を示す.最初にファセットと呼ばれる分析の軸となる単語群または文字のパターン(正規表現)を登録する.ファセットは用途,機能特性等,分析の軸別に作成する必要がある.

テキストマイニングツールは形態素解析(自然文中から単語を抽出する),アノテーション(形態素解析が抽出した単語と,定義したファセットに合致する単語を特定する)等の技術を利用して,大量のテキストから構造化データを作成する.構造化データは,どの文書にどのファセットのどの単語が含まれているのかをインデックスにしたものである.さらに,テキストマイニングツールは構造化データを可視化する分析機能を有しており,単語間の共起関係や時系列推移をグラフで示すことができる.分析者はこの可視化機能を活用して,ターゲットとする技術・素材と共起する用途や技術・素材が提供する価値(機能特性)を必要としている(共起する)用途を探索する.
2.3 IBM Watson Discoveryの特徴
IBM Watson Discoveryは特許を分析する上で,大量のテキスト(特許)を分析でき,さらに単語間の共起関係を“相関”を利用して表現できるという利点を有する.以下にそれぞれの利点について解説する.
2.3.1 大量文書の分析
テキストマイニングツールには現実的に分析可能なテキスト量に制約があり,公開されているテキストマイニングの分析事例は数万件の文書を対象としている場合が多い.
用途探索は広範囲の特許を分析対象としたほうがより多様な用途の候補を得られる.国内出願よりも世界各国の出願特許を対象としたほうがより多くの用途の候補を得られる.自社の技術・素材が持つ機能特性を必要としている用途を探索する際には,できるだけ多くの機能特性語が出現する特許を分析したほうが,得られる用途が増える.筆者らがこれまでに参加した用途探索プロジェクトにおいても分析対象としたいキーワードを含む特許数は50万件を超える場合が多く,数百万件が対象となることも珍しくない.
IBM Watson Discoveryは超並列処理技術を活用した大量テキストの処理が可能で,最大で約1,000万件の特許を分析した事例もあり,大量の特許の分析に適したツールである.
2.3.2 相関分析
テキストマイニングは通常,単語間の共起関係を文書数で表現する.ターゲットとする技術・素材と数多く共起する用途はよく知られた用途が上位を占め,その中から分析者にとっての新たな用途を探索するのに時間を要するという課題がある.
IBM Watson Discoveryは単語間の共起関係を文書数に加えて“相関”の概念で分析する機能を有する.“相関”は分析対象の全特許に対する各用途語の出現確率を母数とし,技術・素材と共起する出現確率を分子として計算した値である.確率統計用語の“相関”とは異なる定義であることに留意いただきたい.この“相関”を利用することで,大量の文書の中から,共起数が多くなくともターゲット技術・素材に特徴的な用途を抽出でき,探索作業を効率化できる.
3.分析方法
筆者らが提案するテキストマイニングを活用した用途探索は,ターゲット技術・素材と特許の書誌情報であるIPC(国際特許分類コード)やテーマコード等の特許分類コードとの相関で領域を俯瞰し,調査する領域を特定した後に,特許の全文(要約,請求項,詳細な説明)を対象に技術・素材と用途,機能特性間の相関から用途を探索する手法である.全文を対象とするため,特許の国・地域による記載項目の差異を考慮する必要がなく,容易に分析範囲を海外特許に拡大できる.
また,大量の特許を分析できるためさまざまな領域における用途を探索できるとともに,市販製品やオープンソースのテキストマイニングツールを利用可能なため,容易に着手できるという利点もある.
分析の軸となる特許分類コード,用途,機能特性の各ファセットはあらかじめ作成してテキストマイニングツールに登録する必要がある.用途と機能特性ファセットの語彙数が増えるほど分析精度が向上するため,できるだけ多数の単語を登録する.たとえば今回の分析例では,用途ファセットは総務省が各種統計の基準として設定している日本商品標準分類(約37,000項目)[6]をベースに,注力する用途分野の単語はJST科学技術用語(約34万語)[7]等で補うとともに,その表記揺れ語を追加したものを利用した.さらに詳細な分析が必要な場合は,文中に出現する“〇〇装置”や“〇〇機器”といったパターンを持つ単語を正規表現で本文中から抽出したものをファセットに追加する.
機能特性ファセットはJST科学技術用語の「性質カテゴリ」に属する単語約2,900語をベースに,ターゲット技術・素材と共起する〇〇性,〇〇度等の性質,物性値,性能値を意味する文字パターンの単語を抽出して追加した.
領域の俯瞰に用いるIPCは複数の粒度での分析を可能とするため,その階層構造を活用してサブクラス(651語)とメイングループ(7,597語)をファセット化している.
分析は既知の用途,置き換え用途,機能追加による用途の順に探索作業を実施し,最後に見つけた用途の技術動向を分析する.各探索作業は最初に広く全体を俯瞰して未調査の領域があるか否かを確認した後,未調査領域や戦略領域に絞り込み用途を探索する.それぞれの分析内容を具体的な分析例とともに解説する.分析例は「チタン化合物の用途探索」をテーマとし,約6万件の日本語特許を対象としている.
3.1 既知の用途探索
既知の用途探索は他社がすでに特許に記載している用途の中から,自社が気づいていないものを見つける方法であり,従来の調査範囲から漏れていた領域や用途を検知できる.最初に関連特許全体を俯瞰して過去の調査範囲から漏れていた領域の有無を確認し,次に漏れていた領域や事業・研究開発戦略にて重視している領域に絞り込んで認識していなかった用途を探索する.以下にその詳細を解説する.
3.1.1 既知の用途俯瞰
既知の用途の俯瞰にはターゲット技術・素材と共起するIPCやテーマコードとの相関値を利用する.
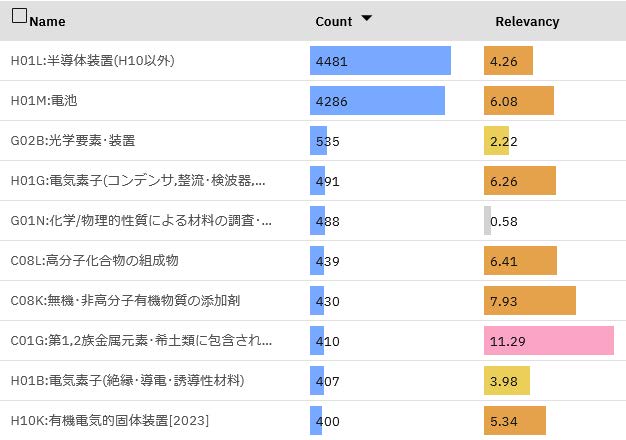
図2は酸化チタン(TiO2)と共起するIPC(サブクラス)の文書数(Count)と相関値(Relevancy)を文書数順に上位10件を示した例である.従来はこの図にあるように文書数が上位の領域に注目して用途を探索する手法が主流であった.図3は同じ内容を相関値順で上位10件を示した例である.文書数は少ないが酸化チタンの出願確率が高い領域が存在することを示している.これらの領域は従来の用途探索手法では調査範囲外となっていた場合が多く,この領域を探索することでこれまで気づけなかった用途を検知できる.

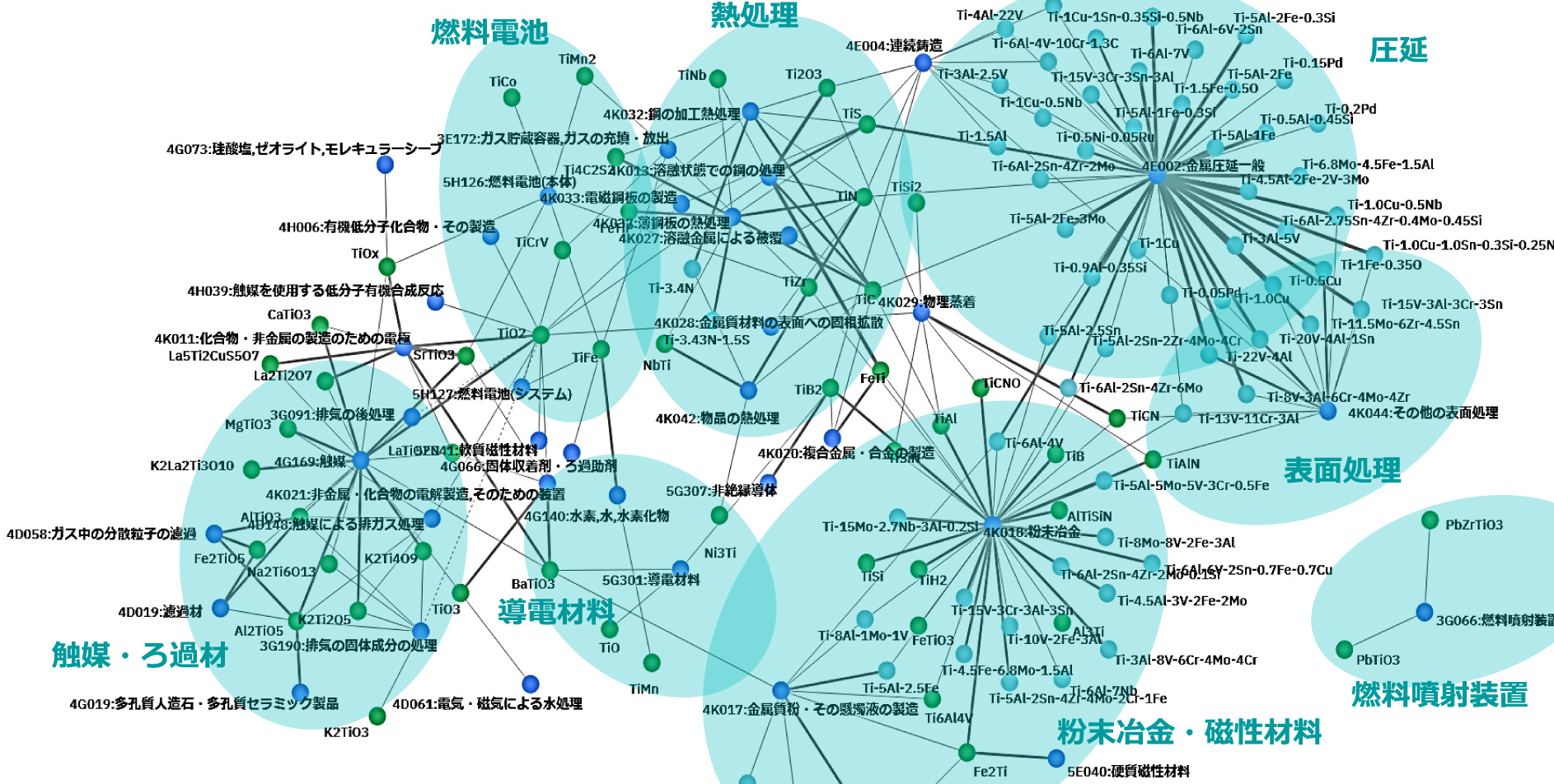
ターゲット技術・素材が複数存在する場合は,各素材・用途と特許分類コードの相関をネットワーク図で確認する.図4は特許中に出現しているチタンを含む化学式を文字パターンで抽出し,テーマコードとの相関をネットワーク図で示した例である.点が単語を意味し,点と点を結ぶ線が単語間に高い相関があることを示している.各チタン化合物がどのような領域で利用されているのかを俯瞰できる.
3.1.2 未調査・戦略領域の深堀
次に過去の調査で漏れていた領域や戦略上重要視している領域に絞り込んでターゲット技術・素材と用途との相関を確認する.なお,絞り込んだ特許数が多い場合は再度IPCとの相関で俯瞰し,注目する領域に絞り込んだ上で用途との相関を確認する.
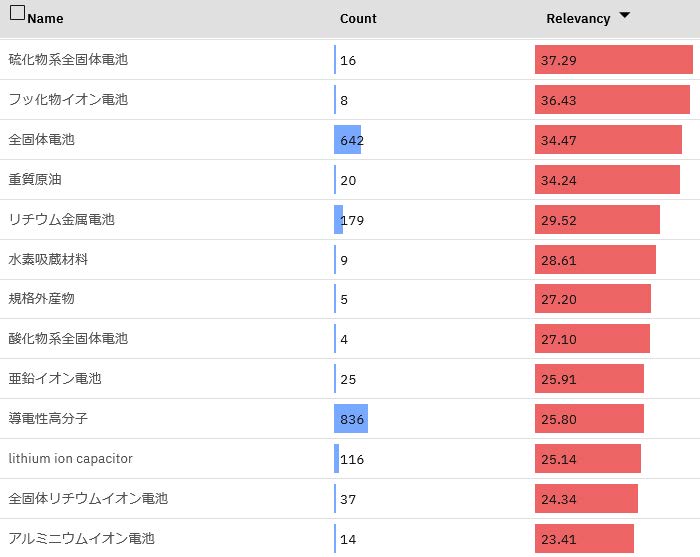
図5は二次電池領域に絞り込んだ上でチタンと用途の相関値を示した例である.チタンと共起する二次電池の具体的な種類が示されており,チタンがどのような種類の電池にて利用されているのかが把握できる.それぞれの特許の内容を確認して各電池における具体的な用途を確認する.
3.2 置き換え用途探索
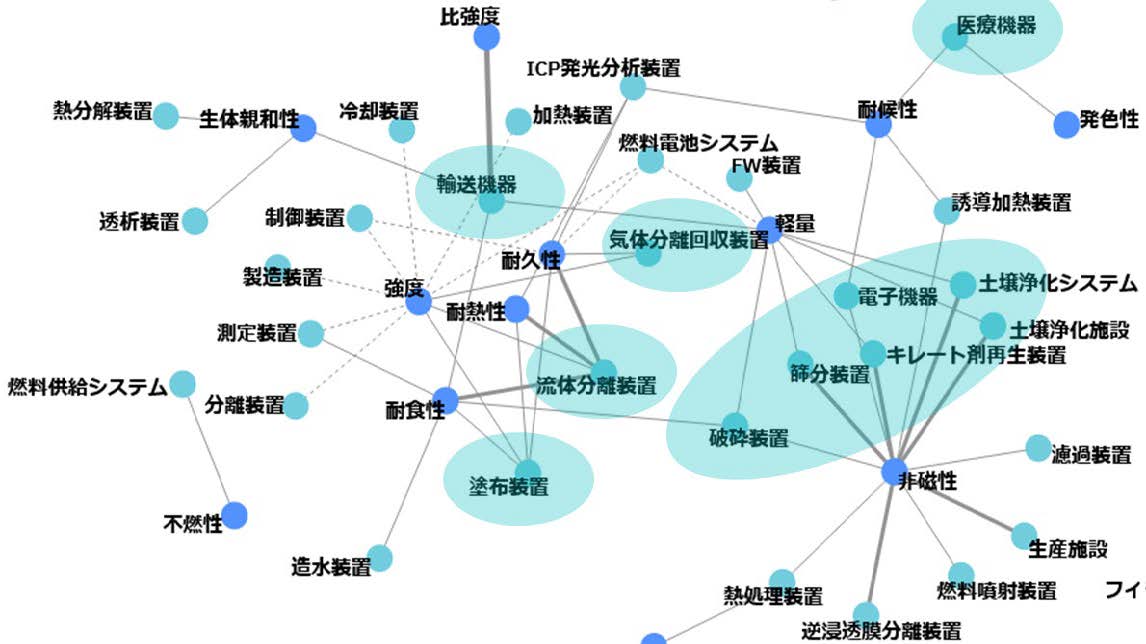
ターゲット技術・素材が出現しない特許を対象に,当該技術・素材が持つ機能特性と共起する用途を探索する.つまり,ターゲット技術・素材が提供する価値(機能特性)を,別の方法で実現している用途を特定し,自社の技術・素材に置き換えることで,より高い付加価値を実現できる用途を探索する.図6は,チタンが出現しない特許を対象に,チタンの代表的な機能特性語と,文中に登場する「〇〇装置」のパターンを持つ用途語の相関をネットワーク図に示したものである.ここで,チタンが持つ複数の機能特性語と相関を持つ用途,つまりチタンが提供する複数の機能特性を必要としている用途に注目し,その特許の内容を確認して用途を探索する.
この分析は製品視点での機能特性語を追加することで,より多くの候補を得られる.たとえば,“吸振性”を持つ素材は,製品に“静粛性”や“消音性”といった機能特性をもたらす.このような製品視点の機能特性語は“吸振性”と相関が高い機能特性語を探索することで容易に見つけだすことができる.
置き換え用途探索では,自社技術・素材が実現できる性能にそぐわない用途が多数出現し,探索効率が悪化する場合がある.たとえば“耐熱性”に注目して,200℃の耐熱性能を持つ樹脂が代替できる用途を探索する際,900度の耐熱性能を持つ合金の特許はノイズとなる.この場合,文字パターンを利用して本文中から温度表記を抽出し,自社技術・素材が対応できる温度が出現する特許に絞り込んで分析する.あるいは対応可能な耐熱性試験の規格名で特許を絞り込んで分析する等の工夫で効率を向上できる.
3.3 機能追加による用途探索
自社の技術・素材に他の技術や添加剤を組み合わせ,新たな機能特性を追加することで,参入可能となる用途を探索する.
具体的には自社の技術・素材が持つ機能特性と相関の高い機能特性,つまり自社技術・素材の機能とあわせて必要とされている機能を探索し,その中から技術的に追加可能と思われる機能を選択する.既存の機能特性と追加機能特性との双方に相関を示す領域と用途を探索する.
3.4 市場の情報収集
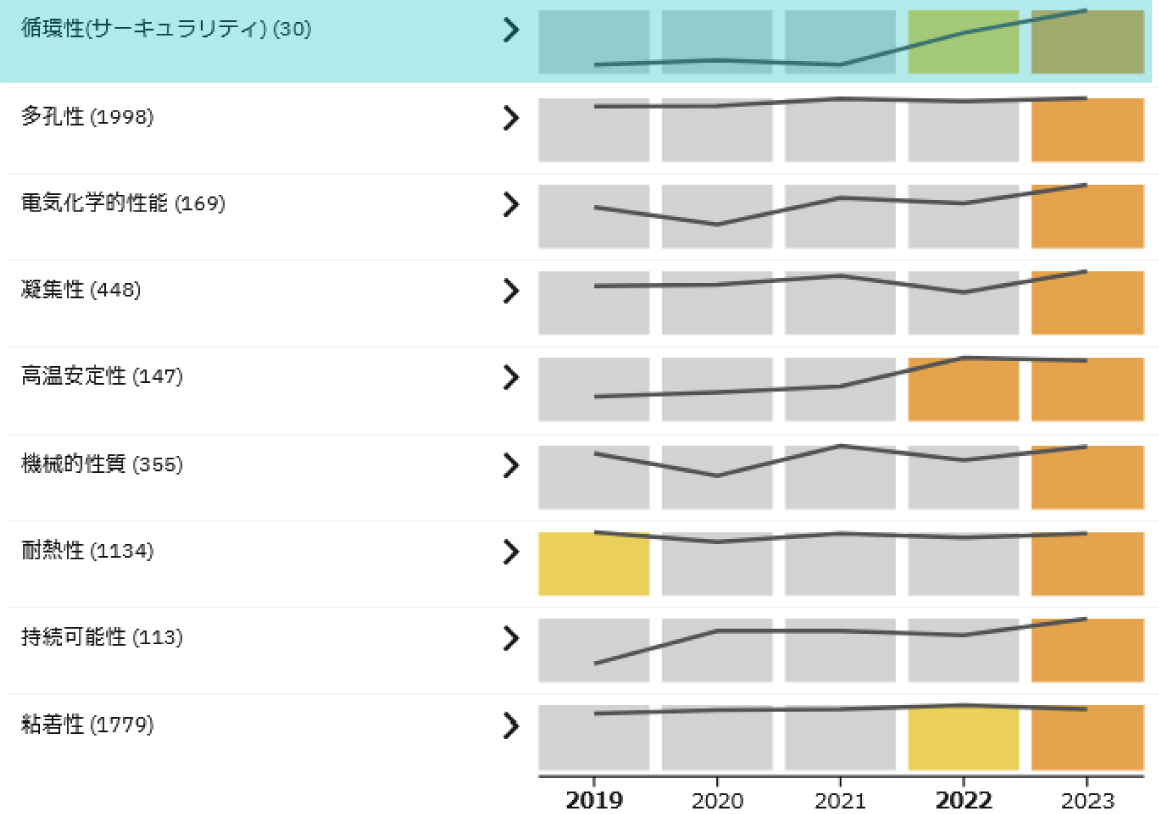
最後に,新たに得られた用途候補について,技術動向をテキストマイニングで分析する.具体的には,技術・素材,用途候補,用途候補に関係する機能特性および出願人等の共起を時系列で確認する.図7は,チタンと共起する機能特性語の時系列推移を示す.折れ線グラフは各単語が出現する特許数の推移を示し,各年の背景に表示されたヒートマップは,ほかの単語と比較して当該年における増加指標が高いことを示している.“循環性”に関連する出願数は少数ではあるが,2022年以降に急増しており,チタンのリサイクル技術への関心が高まっていることを示唆している.この結果,チタンのリサイクル性の向上に貢献するものであれば,技術的需要が増加する可能性があることが分かる.このような時系列推移の分析結果は,新用途候補をスクリーニングする際の有用な情報となる.
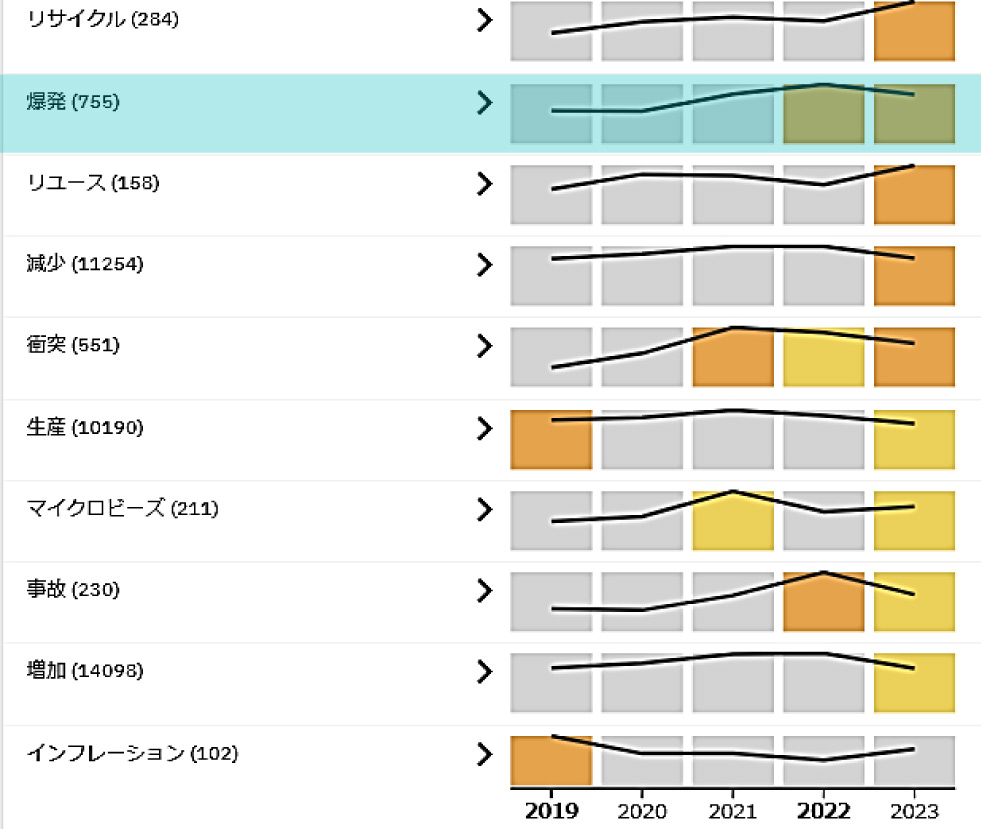
また,特許には発明の有用性が社会的背景に基づいて説明されることが多い.社会的背景に関するファセットを活用すれば,新用途候補に関する社会的ニーズを把握することも可能で,スクリーニングの有用な情報となる.この例を図8に示す.この図は社会的背景を分析するためにPESTELファセット(政治,経済,社会文化,環境,法律等に関する単語群)を準備し,チタンと共起する結果を時系列推移で示したものである.近年「爆発」が増加傾向にあり,この特許を確認するとチタンを利用してリチウムイオン電池の「爆発」を防止する特許である.これより,リチウムイオン電池の安全上のニーズのもとに,チタンが注目されていることが把握できる.
4.おわりに
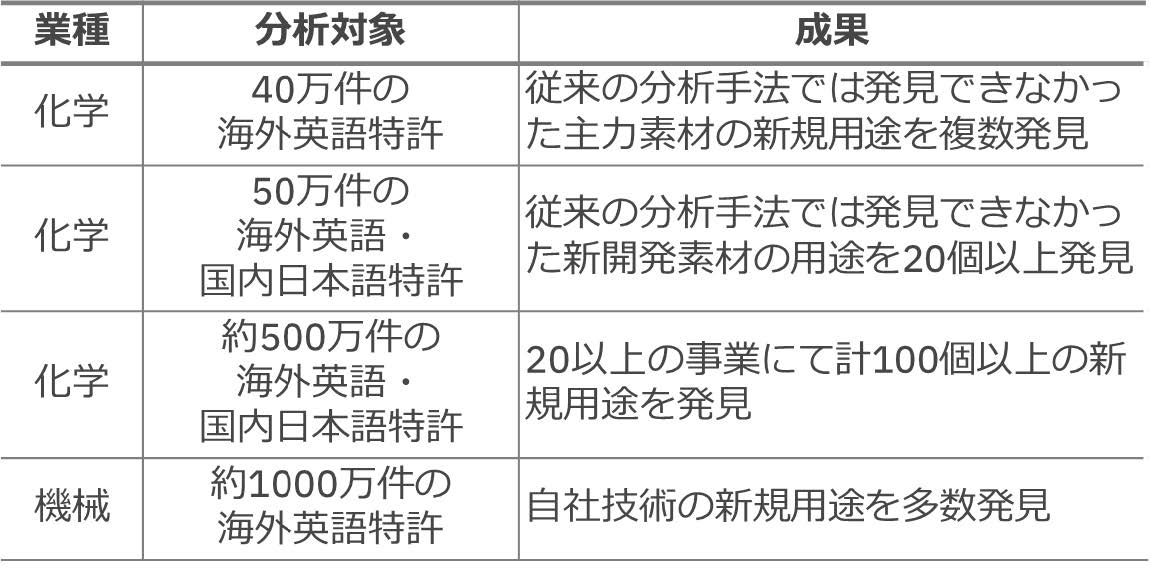
本稿が提案するテキストマイニングツールを活用した特許からの用途探索手法は複数の企業にて,ターゲット素材・技術の有識者が検証し,その有効性を確認している.表1にその成果の例を示す.なお,一部の成果はプレスリリースされている[8].いずれの企業も,従来の発想法や特許検索手法で見つけることができなかった新規用途を国内と海外の特許から発見し,顧客への新提案や自社の次期開発テーマに採用するなど,実務において高い効果を発揮している.特に,異業種での用途が多く確認され,たとえば,食品包材素材が電子部品用に,建築材料が衛生用品に転用可能であることを発見している.このことは,本手法が幅広い分野にわたる用途探索において有効であり,かつ日本と海外の両方の特許から用途探索が可能であることを実証している.
また表1に示す事例はいずれもIBM Cloud上のサービスであるIBM Watson Discoveryを利用し,プロジェクト開始から2~3週間で用途探索作業を開始し,早い場合はプロジェクト開始1カ月程度で成果を享受している.専用システムを構築する必要がないことから,誰もが容易に用途探索を開始できることも実証している.
参考文献
- 1)経済産業省:令和4年度製造基盤技術実態等調査 我が国ものづくり産業の課題と対応の方向性に関する調査(2023).
- 2)日本能率協会:CTO Survey 2020「日本企業の研究・開発の取り組みに関する調査」報告書(2020).
- 3)高橋昭公,渡邉 晃:新規用途開発に有用なアイデア発想支援プロセスの検討,第10回情報プロフェッショナルシンポジウム予稿集B23,pp.99-104(2013).
- 4)高石静代, 他:段階的発想法による用途探索,情報の科学と技術,68(4),pp.180-185(2018).
- 5)太田貴久, 他:特許文書を対象とした因果関係抽出に基づく発明の新規用途探索,人工知能学会全国大会論文集,2L1-03(2018).
- 6)総務省:日本標準商品分類 Retrieved Sep. 16, 2024, from https://www.soumu.go.jp/toukei_toukatsu/index/seido/syouhin/2index.htm
- 7)國岡崇生, 他:JSTシソーラスmap,情報管理,Vol.55, No.9 (2012).
- 8)三井化学:プレスリリース 三井化学,IBM Watsonによる新規用途探索の全社実用をスタート ビッグデータとAIの活用で営業DXを推進(2022).

菊池秋郎
akikuchi@jp.ibm.com
1992年名古屋大学大学院工学研究科修了.2001年日本アイ・ビー・エム(株)入社.現職はコンサルティング事業本部 AI Technologyに在籍.

桐ヶ谷昇
KIRIGAYA@jp.ibm.com
2004年アメリカ州立ネブラスカ大学大学院 情報科学技術学部修了.2011年世界最大規模のコングロマリット企業を経て,日本アイ・ビー・エム(株)入社.現職は,コンサルティング事業本部 AI Technologyに在籍し,Lead/シニア・マネージング・コンサルタントに従事.

大和健太
E36637@jp.ibm.com
2016年早稲田大学政治経済学部卒業.同年日本アイ・ビー・エム(株)入社.現職はコンサルティング事業本部 Manufacturing AI Labをリード.

程智勇
cgzyg@cn.ibm.com
2003年大連交通大学卒業.2016年IBM Dalian Global Delivery Company Limited入社.現職はConsultiong事業部に在籍しAI関連のシステム開発に従事.

鷲澤俊之
TWASHI@jp.ibm.com
2001年慶應義塾大学総合政策学部総合政策学科卒業.同年日本アイ・ビー・エム(株)入社.現職はコンサルティング事業本部 製造・流通統括サービス事業部 アソシエイトパートナー.
採録決定:2025年5月8日
編集担当:斎藤彰宏(日本アイ・ビー・エム(株))