分散台帳を用いた複数組織による機密情報の共同管理および利活用システムの検討
Study of Joint Management and Utilization System of Sensitive Data by Multiple Organizations Using Distributed Ledger
1. はじめに
1.1 信頼ある自由なデータ流通(DFFT)
信頼ある自由なデータ流通(Data Free Flow with Trust, DFFT)[1]は,2019年1月の世界経済フォーラム年次総会および同年6月のG20大阪サミットにて日本国が提唱した概念である.DFFTは,プライバシーやセキュリティ,知的財産権に関する信頼を確保しながら,ビジネスや社会課題の解決に有益なデータが国境を意識することなく自由に行き来する,国際的に自由なデータ流通の促進を目指している.日本国は,DFFTの実現に向けて2021年9月にデジタル庁を設立し,提唱国として責任を持ち推進していくと宣言している[2].また経済産業省は,DFFTの具体化に向けて「データの越境移転に関する研究会」を立ち上げ,越境データ移転の実態調査や有識者会議を行い,データ流通プラットフォームの構築に関して議論している[3].特に,DFFTの具体的な実現に向けて,データを分散管理することが議論されており,分散台帳技術の活用が見込まれる.分散台帳に一度書き込まれたデータは一般的に消すことが不可能とされており,特に機密情報を取り扱う際にはプライバシーの保護を最優先に考える必要がある.
1.2 分散台帳技術と高信頼実行環境
本研究では,複数組織による機密情報の共同管理および利活用に焦点を当て,許可型分散台帳のHyperledger Fabricと,高信頼実行環境(Trusted Execution Environment, TEE)の一種であるIntel SGXを用いてスマートコントラクトを実行する拡張機能であるFabric Private Chaincode(FPC)を用いたシステムを構築した.本節では,分散台帳技術とTEEに関する基礎概念を示し,許可型分散台帳技術のFabricとFabricのプライバシー保護機能を説明する.
1.2.1 分散台帳技術
ブロックチェーンを筆頭とした分散台帳技術は,破壊的イノベーションとして金融分野や産業分野などへの応用が期待され,注目を集めている.金融分野では,第三者機関を経由して実施されてきた従来の取引手法を,利用者間のピアツーピア(Peer-to-Peer, P2P)通信で直接取引を行う分散台帳技術に代替することで,時間的および金銭的な取引コストが削減できると期待されている.分散台帳技術の特徴に,取引やデータの内容が分散台帳ネットワークに参加しているすべての組織に共有され,各組織が保有する分散台帳に書き込まれる点がある.この特徴により,悪意を持つ攻撃者はデータを改ざんするために各組織が保有する分散台帳すべてを書き換える必要があるため,高い耐改ざん性を有するとされる.一方で,医療データや個人情報などの機密情報は,個人情報保護法やEU一般データ保護規則(GDPR)[4]などの各国が定める法律に基づいて厳重に扱う必要がある.
また,分散台帳におけるネットワークの構成方法は主に2種類に分けられる.1つ目は,暗号資産のように不特定多数の計算機資源が形成する自由参加型分散台帳であり,たとえばBitcoin [5]やEthereum [6]などがある.2つ目は,特定の企業や団体などの組織のみで形成されており,参加にはすでにネットワークに参加している組織の一部もしくはすべての許可が必要となる許可型分散台帳であり,たとえばFabric [7]やQuorum [8],Corda [9]などがある.
本研究にて取り扱う機密情報を扱うようなケースにおいては,許可型分散台帳を使用することで,公開範囲をネットワーク参加者のみに制限することを前提としているが,ネットワークに参加するすべての組織が信頼できるとは保証できないため,機密情報本体を直接分散台帳に書き込むことは避ける必要があるという課題がある.高い耐改ざん性および非中央集権的なシステムの運用を実現する分散台帳技術の利点を活かしつつ,プライバシーは保護したいという需要に応えるために,本稿ではそれらを実現可能とする分散台帳基盤技術であるFabricの利用を検討する.
1.2.2 高信頼実行環境
本研究の提案システムにおいて採用するIntel SGXを具体例としてTEEの概念を説明する.TEEは,コンピュータシステム内で機密データやプログラムを保護するための隔離された実行環境を提供する機能である.この環境では,機密データが他のシステムコンポーネントからアクセスされることを防ぎ,外部からの攻撃に対する耐性を提供する.特にセキュリティが重視される分野で利用されており,金融サービス,医療データの保護,デジタル証明書の管理など,様々な用途において機密性を確保するために使用される.TEEは主にCPUベンダ各社が製造および販売しており,Intel社のSoftware Guard Extensions(SGX)やARM社のTrustZone,AMD社のSecure Encrypted Virtualization(SEV)などが存在する.
提案システムにおいて採用するIntel SGXは,アプリケーションが信頼できないOSやハイパーバイザの下でも機密データを保護できるようにするために設計された.McKeenら[10]は,Intel SGXの設計と実装について詳細に説明しており,SGXがどのようにして隔離された実行環境を提供し,攻撃に対する耐性を強化するかを論じている.SGXは,Enclave Registrationという仕組みにより主記憶装置上に暗号化されたEnclaveと呼ばれる保護領域を生成し,その領域にプログラムやデータを読み込むことによって機密情報を保護しつつプログラムを実行することを可能にする.Remote Attestationという仕組みを用いて,Intel社のサーバと通信することで,セキュアなEnclaveおよびTEE環境が正しく設定され,信頼できる状態であることを第三者に証明するプロセスを有する.
1.3 Hyperleder Fabric
Fabricは許可型分散台帳であり,TEEを使用したスマートコントラクトの実行が可能となる拡張機能を持つ.本節にて,Fabricの基礎概念と,Fabricが持つプライバシー保護機能を説明する.
1.3.1 Fabricの基礎概念
Fabricは,Hyperledger Foundationにより管理されているオープンソースソフトウェア(Open Source Software, OSS)の許可型分散台帳基盤である.
図1は,Fabricを用いて分散台帳ネットワークを立ち上げた際の簡略図である.組織は,分散台帳ネットワーク内の独立したエンティティであり,ネットワークの構成メンバーとして機能する.各組織は,それぞれが独立してメンバーシップサービスプロバイダ(Membership Service Provider, MSP)および認証局(Certificate Authority,CA)を持ち,認証とID管理を担当する.また,各組織が保有するPeerノードはLedger,State DB,およびChaincodeの実行環境を含む.Ledgerはネットワーク全体にわたって取引記録を分散して保持する台帳であり,分散台帳である.State DBはLedgerが管理しているトランザクションを実行した際の結果の最新情報を保存するデータベースである.ChaincodeはPeerにインストールされるFabricにおけるスマートコントラクトであり,複数組織のPeerにインストールされたChaincodeの実行結果が一致することによって信頼性を確保している.Ordererはトランザクションの順番を決定し,Peerにブロックを配布する役割を担うノードである.Clientはユーザが操作するインタフェースであり,ユーザはClientを介してChaincodeに記述された各関数を選択し呼び出しを行う.
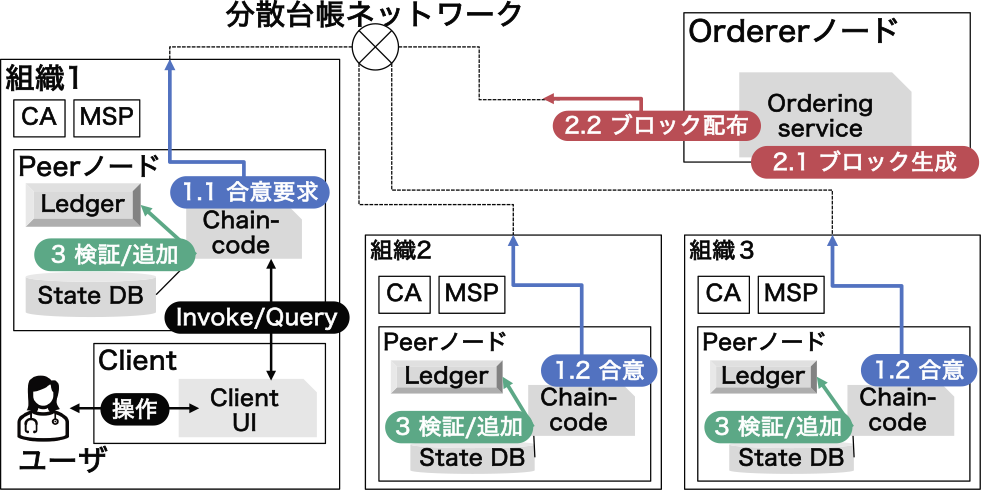
Fig. 1 Basic overview of Fabric: consensus algorithm among participating organizations during transaction issuance in a distributed ledger network using Fabric.
また,FabricではExecute-order-validate構成と呼ばれる3段構成の合意形成アルゴリズムを用いてトランザクション書き込みおよび実行の合意を取得している.図1を用いてFabricにおける合意形成の流れを示す.まず(1)Executeでは,ユーザがClientを介してChaincodeを呼び出しトランザクションの実行を命令すると,分散台帳ネットワークに参加する他の組織に合意を要求し,他の組織のPeerが,Chaincode上でトランザクションの検証および署名を実施することで合意する.次に(2)Orderでは,Ordererは署名を集めたトランザクションを受け取り,トランザクション同士の順序関係を解決して複数のトランザクションを梱包したブロックを生成し,そのブロックを各組織のPeerに配布する.最後に(3)Validateでは,Ordererから渡されたブロックを各Peerが検証し台帳に書き込む.ブロック内に書き込まれたトランザクションを実行し,State DBに結果を書き込む.
1.3.2 Fabricにおけるプライバシー保護技術
Fabricには,データを秘匿しつつ共有するための標準機能やFabricを拡張する形で実装されたOSSが存在する.本節にて3種類のプライバシー保護技術を紹介し,提案システムの構成に使用する技術の選定指針を示す.
1.3.2.1 Channel
Channel機能を用いることで同一の分散台帳ネットワークに参加する特定の組織間でのみ共有される台帳を作成することができる.そのChannelに属していない他の組織からは台帳を見ることができないような仕組みを実現することが可能となる.Fabricの標準的な機能として実装されており,本機能を用いてトランザクションおよびデータの開示先を制限するような機能を持つシステムを簡単に構築することが可能となる.しかし,数多くの組織が参加する分散台帳ネットワークにおいて,2つの組織間のみでのやり取りを秘匿するためには,膨大な数(具体的には,分散台帳ネットワークに参加する組織数がNの場合,N(N−1)個)のChannelを作成する必要があり,参加組織が増加することが前提の運用には向かない課題がある.
1.3.2.2 Private Data Collection
Private Data Collection(PDC)機能は,他の組織に対して秘匿したい機密情報を台帳外の外部記憶装置に保存する機能である.Benhamoudaらの研究[19]にて提案され,Fabricの標準機能としても実装されている.PDC機能を用いて保管されているデータを他の組織に共有する際は分散台帳ネットワークを介さずP2Pの直接通信で送受信を行う.しかし,機密情報をP2P通信で他の組織に送信するため,他の組織に送られたデータがどのように活用されるか,提供者は分からないという課題がある.また,PDC機能は数テラバイトオーダーのデータを取り扱うことは考慮されておらず,1つのファイルが数ギガバイトオーダー以上の大容量のデータを扱うユースケースには適応が非現実的である.
1.3.2.3 Fabric Private Chaincode
Fabricに標準搭載されているChaincodeの実行環境においては,台帳に書き込まれるトランザクションおよびデータは平文の状態で保存されている.Chaincodeを介さずとも分散台帳やState DBにユーザが直接アクセスすることでそれらの内容を確認することが可能となっているため,機密情報を取り扱うユースケースには適していない.Brandenburgerらの研究[20]にて提案されたFabric Private Chaincode(FPC)は,SGXを用いてChaincodeの実行を可能にする技術である.トランザクションおよびデータがEnclave内で暗号化された後に台帳に書き込まれることにより秘匿化を実現している.FPCはFabricの拡張機能として実装され,OSSとして提供されている.
FPCでは各PeerにChaincodeをインストールした後に初期化処理として,そのChaincode専用のEnclaveが作成される.次に,Enclave固有の暗号鍵が生成され各Peerが保有するEnclave Registry Chaincode(ERCC)に登録される.Chaincodeを呼び出し,分散台帳およびState DBに書き込まれるトランザクションおよびデータはERCCに登録された暗号鍵を用いて暗号化される.よって,悪意を持った攻撃者およびユーザさえも,それらに直接アクセスしてもトランザクションおよびデータを取り出すことはできない.
一方で,FPCの本稿執筆時の最新バージョンであるv1.0-RC3では,他のPeerのEnclaveに対する暗号鍵の配布機能は非対応となっており,暗号化を実行したPeer上でのみデータの復号化およびChaincodeの実行が行われ,単一のPeerでのみ合意形成アルゴリズムが実行されるものとなっている本来であれば他のPeerのEnclaveに対して暗号鍵を配布し,すべてのPeerでデータの復号化およびChaincodeが実行でき合意形成ができるような仕組みで動作する必要があることに注意する必要がある.本稿では,近い将来OSSであるFPCが成熟し,暗号鍵の配布機能や複数組織のPeerによる合意形成が実行可能となることを期待し,本技術を選定することとした.
2. 関連研究
分散台帳におけるプライバシー保護を秘密計算技術によって実現する研究および技術が数多く存在する.秘密計算手法は主にゼロ知識証明(ZKP),マルチパーティ計算(MPC),およびTEEに大別される.本節では,表1に関連研究をまとめ,提案システムと比較を行う.はじめに,ZKPおよびMPCによるプライバシー保護に関する研究を紹介し,TEEを用いる場合との比較を示す.次に,TEEによるプライバシー保護に関する研究を示し,本研究の位置づけを示す.
Table 1 Related work on privacy protection in distributed ledgers and the proposed system.

2.1 ZKPおよびMPCによるプライバシー保護
ZKPは,相手に情報の内容を明かすことなく,その情報が正しいことを暗号学的に証明する技術である.文献[11], [12]は,ZKPを用いて情報を暗号化した状態で分散台帳に保存し,プライバシー保護を実現している.一方で,ZKPは計算コストが非常に高く,特に複雑な証明では効率が低下する可能性を有する.
MPCは,複数の参加者が個々のデータを秘密にした状態で共同で計算を行い,その結果を得る技術である.文献[13], [14]は,MPCと分散台帳技術を組み合わせたプライバシー保護を実現している.一方で,ZKP同様計算コストが高く,更に複数の参加者が協力して計算を実行するため通信のコストが高いことから,複雑な計算では効率が低下する可能性を有する.
加えて,ZKPおよびMPCともに実装にはTEEと比較して暗号技術に対する高度な専門知識必要となることが課題となっている.様々なユースケースに対応することが可能な基盤システムにおいて,技術者による実装の容易さは重要な焦点となる.本研究の提案システムはTEEを採用しており,分散台帳に精通している技術者であれば追加で専門的な知識は不要となる点が利点としてあげられる.一方で,TEEを用いる手法にもハードウェア依存により計算機の準備が困難である課題が存在する.本研究ではAzureを用いたパブリッククラウドVMによるSGXハードウェアによる実装手法の提示していることから,その課題を解決している.
2.2 TEEによるプライバシー保護
TEEを用いて分散台帳に書き込まれるデータを秘匿する手法にもいくつか種類がある.LayerX社が開発したAnonify [15]はTEEを用いてオフチェーン領域におけるプログラムを正しく実行できることを保証している.一方で,本研究の提案システムに用いるFPCはオンチェーン領域におけるチェーンコードの実行にTEEを用いている点に違いがある.Chengらの研究[16]では,EthereumとTEEを組み合わせ,プライバシー保護を実現するとともに高速な処理かつ低遅延を実現している.一方で,本研究の提案システムは,医療分野における研究組織から構成されるコンソーシアムによる機密情報の共同管理を推進するために許可型分散台帳Fabricを使用する.
分散台帳とTEEを組み合わせる研究の中でも,提案システムと同様にFabricとFPCを利用する研究も存在する.DesaiらのSECAUCTEE [17]は分散台帳ネットワークを用いて競売を実現する際に使用するスマートコントラクトのセキュリティ上の課題を解決するため,FPCを使用することを提案している.これにより,入札の情報を秘匿し談合などの不正な入札を防止することと,競売の透明性を維持することを両立している.Wuらの研究[18]は,FPCを用いて複数のサイトで収集された臨床試験データを管理,共有,および分析する方法を提示している.また,Amazon Web Service(AWS)クラウドとローカルマシンの2種類の環境を使用した実装を提案しているが,AWSクラウドにはSGXを搭載した環境を作成できないためSGXシミュレーションを使用した実装となっている.
本稿の提案システムは,医療分野における「がんの全ゲノム解析」のユースケース実現に特化したシステム要件を定義し,実装および評価を行っている.また,システムの実運用を見据えたハードウェアの選定を実施し,SGXが利用可能でありパブリッククラウドとして提供されているMicrosoft Azureで作成したVM上にシステムを構築した.比較対象となるすべての分散台帳環境を構築し,条件を正しく揃えた実験を設計し評価を行った.
3. 本研究の貢献
本研究は,分散台帳技術を用いて複数の組織で医療データの1つであるゲノムデータを管理および利活用を目的としている.既報[21]では機密情報を各組織が保有する外部記憶装置に格納し,そのデータのメタデータのみを分散台帳に格納することにより,機密情報の複数組織管理を実現していた.しかし,この管理および利活用基盤では,データの利活用に関係しない組織が解析依頼や結果情報の閲覧が可能となる.ゲノム情報を扱う研究者にとって,研究対象としているゲノムデータに関する情報は秘匿したいという課題がある.
その課題に対して,研究速報として既報[22]にてFPCを用いたトランザクションおよびデータを秘匿しつつデータを複数組織管理および利活用の促進を実現するシステムのプロトタイプ構想が示された.本稿では,既報[22]の内容を拡張し,適応ユースケースの具体化,実運用に向けたシステム要件の定義,および提案システムの実機評価を行った.
本研究の貢献を以下に示す.
- ・全ゲノム解析ユースケースの具体的なシナリオ提示
- ・ユースケース実運用に向けたシステム要件定義
- ・適切なハードウェア・ソフトウェア選定および実装
- ・実機評価による性能フィージビリティ検証
4. ユースケースの前提とシナリオ
本章にて,医療分野における「がんの全ゲノム解析」をユースケースとした分散台帳を用いた複数組織によるがんゲノムデータの共同管理および利活用システムの要件を定義する.はじめに,ユースケースの前提となる全ゲノム解析についての説明と分散台帳を用いた共同管理を実現するための条件を示す.次に,本ユースケースにおけるユーザおよびシステムの動きをシナリオとして説明する.最後に,ユースケース実装の条件を踏まえたシナリオを実現するためのシステム要件をハードウェア構成とソフトウェア構成に分けて説明する.
4.1 ユースケースの前提
医療分野ではがんの研究において,発がん要因等を発見するために全ゲノム解析が行われている[23], [24].全ゲノム解析は,リファレンスとなるゲノムデータとがんを発症した患者から提供されたゲノムデータを用いて,がんによるDNA情報の変異を検出する処理である.がんの全ゲノム解析を進めるにあたり,ワークフローは大きく5つで構成され,(1)患者への説明と同意取得,(2)ゲノム読み取り,(3)全ゲノム解析,(4)解析結果の分析,(5)担当医による患者への薬剤という流れで解析処理が進められる.
4.2 ユースケースシナリオ
本研究は,これまで1つの組織内で閉じた形で管理されていたゲノムデータを分散台帳上で管理し,複数の組織間でのゲノムデータの利活用を促進することを目的としたユースケースの実現を目指す.複数組織での非中央集権的なシステム運用に加えて,改ざん不可能な堅牢なデータの利用証跡を管理することも分散台帳利用のモチベーションとなる.医療関連の組織,たとえば病院や大学,医療研究機関が分散台帳ネットワークに参加し,他の組織が保有するゲノムデータを利活用するための仕組みを実現するシナリオを示す.
まず前提として,ゲノムデータの特性を考慮する.ゲノムデータは,1つのファイルで数百ギガバイトから数テラバイトに及ぶ膨大なデータ量を持ち,また個人情報が含まれた機密性の高いデータである.よって,生のデータを他の組織に直接渡すことはデータ転送にかかる時間の観点やプライバシー保護の観点からも避けるべきである.そこで,ゲノムデータに関するデータのハッシュ値や患者の国籍,性別,年齢,発症したがんの種類といったメタデータを管理する「ゲノムデータカタログ」を分散台帳上で運用する.データを活用したい他の組織のユーザは,データを保有する組織に許諾を得た後に解析処理を依頼し,結果のみを返すような運用を実現する.
本ユースケースの具体的なシナリオを示す.図2に本ユースケースのシナリオを実現する提案システムの概観を示す.本シナリオでは,組織1にデータを利活用したいユーザが所属しており,組織2がそのデータを保有していることとする.まず,組織2に所属するユーザががん患者から同意を得て,ゲノムデータを自組織のストレージに保存する.同時に,このデータに対応するハッシュ値および患者に関するメタデータを,分散台帳上のゲノムデータカタログに記録する.次に,組織1に所属するユーザがこのカタログを照会し,研究を推進するための適切なメタデータ条件を指定してデータの検索をする.必要なデータを発見した組織1のユーザは,組織2が保有するそのゲノムデータの利活用を希望し,分散台帳で管理されるワークフローシステムを通じて利用申請を行う.
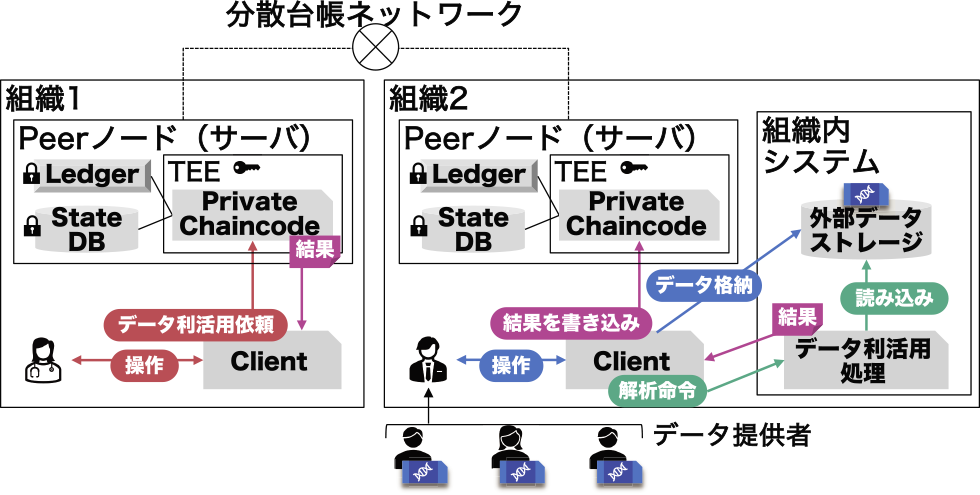
Fig. 2 Overview of the proposed system: joint management and utilization system of sensitive data by multiple organizations using distributed ledger.
次に,組織2のユーザは,組織1からの利用申請を確認し,承認した場合はその旨をワークフローシステムに記録する.組織1のユーザは,自身の申請が承認されたことを確認した後,分散台帳で管理される全ゲノム解析タスク管理システムに,解析条件を含むタスク情報を記録する.組織2の全ゲノム解析管理システムは,組織1から依頼されたタスク情報を取得し,ワークフローシステム上で利用許諾が得られていることを確認した後に解析処理を実行する.最終的に,解析結果は組織1のユーザに提供され,一連のプロセスが完了する.
このように,研究者が分散台帳上のゲノムデータカタログを照会し,必要なデータを効率的に検索し,適切な解析を依頼し,結果のみを受け取るというプロセスを安全かつ確実に実現することを目指す.また,全ゲノム解析は,使用するアルゴリズムや比較対象となるリファレンスゲノムデータなど解析条件を詳細に設定する必要があり,これらの条件設定はがんゲノム研究を推進するうえでの重要な要素となっている.研究者からはこの全ゲノム解析に関する解析情報はなるべく秘匿したいという要望があり,分散台帳上で管理されるメタデータやワークフロー,解析依頼の発行および結果の共有に関する情報は,関係組織以外に閲覧されないような仕組みが必要となる.
5. 提案システム要件
本章にて,ユースケースとシナリオから必要となるシステム要件を定義する.提案システムは主に分散台帳部,各組織がそれぞれ保有するクライアント部,ゲノムデータの保存および全ゲノム解析を実行するデータ保存解析部に分け,それぞれに対する要件を示す.
はじめに,本ユースケースにおいては複数組織が同一権限で参加する非中央集権的運用が可能なシステムが必要とされており,改ざん不可能かつ堅牢なデータ利用証跡管理を目指すことからも,許可型分散台帳の利用を要件とする.また,ゲノムデータを利活用する際の組織間の取引は当事者間のみが閲覧できるようしたいというニーズがあり,プライバシー保護機能を備えた許可型分散台帳基盤を使用する必要がある.2章に述べたとおり,分散台帳におけるプライバシー保護技術として秘密計算技術と組み合わせる手法がいくつか存在するが,容易なChaincode実装方式および今後の拡張性を考慮し,TEEによる手法を要件とした.一方で,TEEによる手法は専用のハードウェアを準備する必要があるという課題を抱えており,なるべく準備コストを書けないようなハードウェア選定を必要としたい.そこで,TEEを利用可能なパブリッククラウドサービス上で提案システムの分散台帳部を構築することを要件とした.
次に,分散台帳およびゲノム解析を命令するためのユーザが操作するクライアント端末が必要となる.ユーザが分散台帳部へのChaincode関数呼び出しを実行するための操作を可能とするユーザインタフェースを含むクライアントソフトウェアの実装を要件とする.
続いて,ゲノムデータは1つのファイルで数百ギガバイトから数テラバイトに及ぶデータサイズであることから,膨大な容量のストレージを必要とする.また,全ゲノム解析を実行するための計算機を必要とする.全ゲノム解析に必要となる一連のソフトウェアを含むものとする.なお,既報[21], [22]において全ゲノム解析に必要となるストレージ,計算機,およびソフトウェアに関する環境は構築済であり,本稿では既存環境を流用することとした.
以下に,提案システムの要件をまとめ列挙する.
- ・分散台帳部
- −許可型分散台帳によるネットワーク構築
- −TEEによるプライバシー保護
- −パブリッククラウドサービス上の構築
- −シナリオ実現のためのChaincode
- ・クライアント部
- −ユーザが操作するクライアント端末
- −UIを含むクライアントソフトウェア
- ・データ保存解析部
- −ゲノムデータ保管のための大容量ストレージ
- −全ゲノム解析のための計算リソース
- −全ゲノム解析を実行する一連の解析ソフトウェア
6. 提案システム実装
本章にて提案システムの要件定義に沿った具体的な実装を示す.
6.1 ハードウェア構成
図3に,提案システムのハードウェア構成を示す.分散台帳部,クライアント部,およびデータ保存解析部に分けそれぞれの実装について示す.
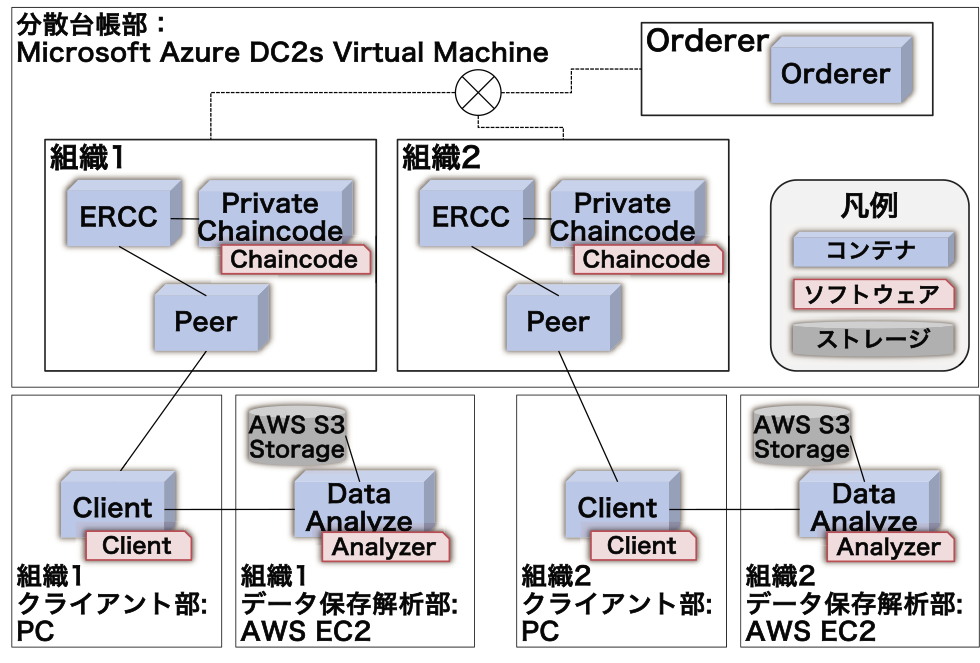
Fig. 3 Proposed system configuration: hardware and software arrangement.
6.1.1 分散台帳部
分散台帳部は許可型分散台帳によるネットワーク構築,TEEによるプライバシー保護,およびパブリッククラウドサービス上の構築を要件としている.Fabricは許可型分散台帳であり,中でもTEEを活用した拡張機能であるFPCを有している.FPCを動作させるにあたり,ハードウェアとしてIntel製のCPUの中でもSGXが搭載されたものを選定する必要がある.さらに,マザーボードがSGX対応しており,さらにBIOSの設定でSGXが実行できるよう設定する必要がある.Intel SGXが搭載されたハードウェアを提供するクラウドサービスは数少なく,Amazon,Google,およびMicrosoftの世界的有力クラウドベンダ3社の中ではMicrosoftのAzureのみで利用可能である.よって,本研究ではAzureを採用し,Azure上でSGXが使用可能となるDCsv2シリーズのVM上でFabricおよびFPCを動作させることとした.
ユースケースの実現にあたり,メタデータを書き込むゲノムデータカタログ機能,他の組織が保有するゲノムデータの利活用申請および承認を実施するワークフロー機能,ゲノムデータ解析依頼の発行および結果の共有機能を持つChaincodeが必要となる.提案システムではそれぞれ機能が独立したChaincodeプログラムを作成し,各組織のPeerにそれぞれインストールすることとした.Fabricは各機能を持つモジュールがdockerを用いたコンテナ化がされており,本システムもdockerを用いたコンテナベースのシステムで動作する.dockerを用いて2組織から構成されるFabricの分散台帳ネットワークを構築した.この分散台帳ネットワークを構成する各組織はPeerコンテナを1つ持つ.各Peerは分散台帳本体とその分散台帳で管理されているトランザクションを実行した結果となる最新のデータを管理するState DBを所有する.また,この分散台帳ネットワークは1つのOrdererを持つ.各組織が保有するPeerはそれぞれEnclave Registry Chaincode(ERCC)コンテナを介してPrivate Chaincodeコンテナに接続される.ERCCは,TEEの外部で実行されるChaincodeであり,Private Chaincodeと関連するTEEのEnclaveに関する情報や公開鍵情報などを管理する.Private Chaincodeコンテナには6.2.1節にて述べるChaincodeがインストールされる.
6.1.2 クライアント部
次に,各組織のユーザが直接操作するクライアント部は,各ユーザが保有するPCを利用することを想定する.Clientソフトウェアが動作するコンテナが配置され,ユーザはこのソフトウェアを使用することでPeerコンテナに対する分散台帳に関する操作およびデータ保存解析部のデータ解析ソフトの操作が可能となる.
6.1.3 データ保存解析部
続いて,各組織が保有するデータ保存解析部は,ゲノムデータを保存しておく膨大な容量のストレージおよび解析処理を実行するための専用の計算機を必要とする.データ保存解析部は,既報[21], [22]にてがんゲノム解析環境がAWS上に構築されている,ストレージにはAWS S3,解析プログラムを配置するVMにはAWS EC2を使用することとした.データ解析を行うAnalyzerソフトウェアを含むData AnalyzeコンテナはClientと接続されユーザからの操作を受け付ける.
6.2 ソフトウェア構成
提案システムにおけるソフトウェアは,ハードウェア構成における分散台帳部にて使用するChaincodeソフトウェア,クライアント部にて使用するClientソフトウェア,およびデータ保存解析部にて使用するAnalyzerプログラムの3つを設計および実装した.本章において,各ソフトウェア事に設計および実装を示す.
6.2.1 Chaincode
提案システムのChaincodeはシナリオ例に沿って実装された.シナリオ例の実現には,(1)データカタログ管理を行う機能,(2)データの権限管理を行う機能,および(3)タスク管理を行う機能が必要となる.それぞれの機能を実現するため各関数の詳細を表2に示す.各関数は台帳への書き込みおよびState DBの更新を伴う関数(Invoke)とState DBの情報を読み出しのみを行う関数(Query)に分けられる.
Table 2 Chaincode functions list.

6.2.2 Client
Clientはユーザが提案システムを操作するために用意されたコマンドラインベースのCUIソフトウェアである.本ソフトウェアは,各組織にそれぞれ独立して配置される.患者から提供されたゲノムデータをストレージに保存する機能や,分散台帳ネットワークのPeerを介してChaincode内の関数を呼び出すための機能,Analyzerに対して解析処理を依頼する機能など,ユーザがシステムに対して操作を必要とする場合はClientを介して実行する.
6.2.3 Analyzer
提案システムのAnalyzerはClientを介して自身が保有するデータに対して利活用依頼が来ているかを定期的に確認し,依頼が来ていた場合そのタスクを実行するためのアプリケーションである.Analyzerに接続されたStorageから解析を依頼されたデータを読み出し,タスクを実行する.本稿では,医療分野におけるゲノムデータの管理および利活用を例にしたシナリオを想定しており,OSSであるBurrows-Wheeler Aligner(BWA) [25], Sumtools [26], IGV.js [27]を使用することで全ゲノム解析に必要となる一連の処理を実行することとした.
6.3 シナリオに沿ったソフトウェア操作
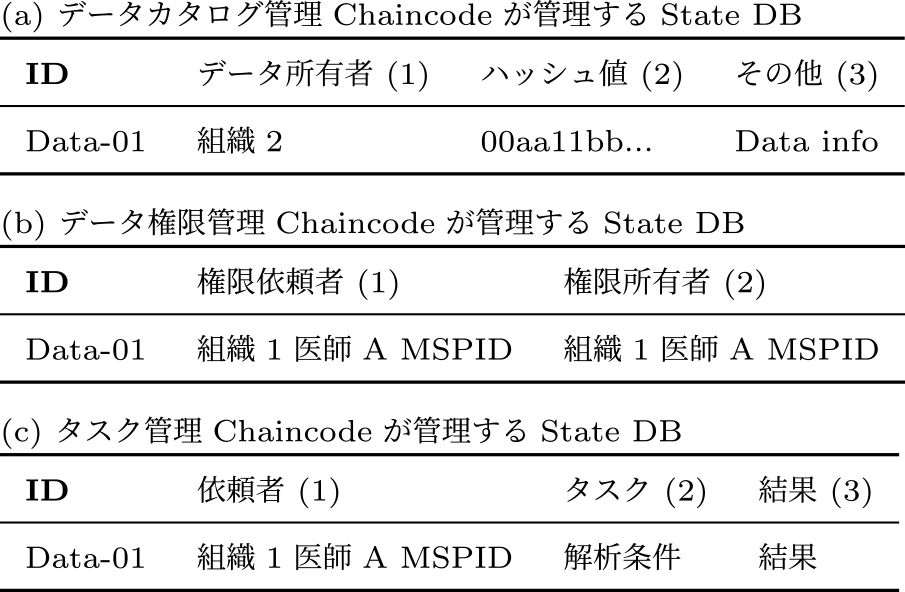
表3にトランザクションの最新データを管理するState DBの内容を示す.
Table 3 State DB Data.
6.3.1 データカタログの操作
はじめに,組織2の医師は患者から提供を受けたゲノムデータを外部記憶装置に格納する.同時に,組織2の医師はClientを操作してChaincodeの(i)SetData関数を呼び出し,ゲノムのメタデータを分散台帳に書き込む(表3(a)).次に,組織1の医師はClientを操作してChaincodeの(ii)GetData関数を呼び出し,ゲノムのメタデータを参照し,活用したいデータを検索する.活用したいデータを見つけた場合,(b)の処理に移る.
6.3.2 データ利活用権限の申請および承認
組織1の医師はClientを操作してChaincodeの(iii)RequestPermission関数を呼び出しデータ所有者である組織2にデータ利用権限を求める申請を書き込む(表3(b)(1)).次に,組織2の医師はClientを操作して,自身が所有するゲノムデータに関する利活用権限の申請を確認する.組織2の医師はClientを操作してChaincodeの(iv)ApprovePermission関数を呼び出して組織1の医師に対して申請を承認することでデータ利活用権限を付与する(表3(b)(2)).組織1の医師はデータ権限の申請が承認されたことを確認し,(c)の処理に移る.
6.3.3 タスクの実行依頼および結果の書き込み
組織1の医師はClientを操作してChaincodeの(v)RequestTask関数を呼び出して組織2にゲノムデータの解析処理を依頼する(表3(c)(2)).次に,組織2のゲノム解析処理装置がClientを操作してChaincodeの(vi)GetTask関数を呼び出して,組織1の医師から依頼された解析処理の内容を読み込む.ゲノム解析処理装置は,指定されたゲノムデータを外部記憶装置から読み込み,解析処理を実行する.最後に,ゲノム解析処理装置はClientを操作してChaincodeの(vii)WriteTaskResult関数を呼び出して,解析処理の結果を分散台帳に書き込む(表3(c)(3)).
7. 評価
7.1 提案システムの要件に対する実装評価
分散台帳部はAzureによるSGXが動作するVM上にFabricネットワークを構築することで,要件を満たした構成を実現した.また,全ゲノム解析ユースケースに必要となるChaincodeも実現した.Chaincodeは全ゲノム解析ユースケースに必要となるゲノムデータカタログ,ワークフロー管理,タスク管理それぞれの機能を要件としており,実装後の実機検証により必要な機能要件を満たしていることを確認した.
クライアント部に関しては,本研究では各ユーザが保有するPCをハードウェア要件とし,Clientソフトウェアをインストールする構成とした.ユーザはCUIを操作しClientソフトウェアによりChaincodeの関数呼び出しを実現した.
データ保存解析部に関しては,既報[21], [22]において全ゲノム解析に必要となるストレージ,計算機,およびソフトウェアに関する環境は構築済であり,本稿では既存環境を流用することとしたため,既に要件を満たしている.本稿にて実装した分散台帳部およびクライアント部とは正しく接続し,一連の全ゲノム解析処理を実行できることを確認した.
7.2 性能フィージビリティ評価
7.2.1 実験設計
本研究では提案システムのシナリオ例の正常系の実行時に要する実行時間を計測し比較を行った.提案システムのシナリオ例の実行時間を計測することにより,本システムの実用性を示すことを目的とする.従来の実装手法の実行時間と比較することによって,提案システムのボトルネック箇所を解析し,提案手法のさらなる改善を目指すことを目的とする.また,本稿のシナリオとして例示しているゲノム解析のユースケースにおいては,ゲノムデータ解析処理に膨大な時間がかかることは自明であるため,評価実験を実施する際は解析処理をスキップし,解析結果はダミーデータを書き込むこととした.
実験には6.1節にて述べたハードウェア構成を使用した.評価実験には表4に示す3つの環境を用意した.(1)と(2)を比較することによって,SGXハードウェアを使用することによる遅延時間を測定する.また,(1)と(3)を比較することによって,SGXのハードウェアおよび暗号化や鍵管理,証明書管理等のSGX全体の処理による遅延時間を測定する.Fabric標準として動作するChaincodeの呼び出しには,Fabric標準として提供されているpeerコマンドを利用し,実行時間の測定を行った.
Table 4 Experimental environment.

評価実験は6.3節にて述べたシナリオ例の正常系を実行した際の実行時間をそれぞれの環境で3回計測する.また,シナリオ例の正常系を進めるにあたり実行される各関数の実行時間も同時に計測した.
7.2.2 結果および考察
表5に実験結果を示す.表5aは,シナリオ例の正常系を実行した際の実行時間をそれぞれの環境で3回計測した結果である.環境(1)では10.649秒,(2)は10.628秒と差はなかった.環境(3)の場合,0.235秒と(1)と比較すると提案システムの実行時間は約45倍かかった.次に,表5bは,各関数をInvokeとQueryに分類し,平均実行時間を求めた結果である.Invokeに関しては,環境(1)の結果は2.111秒,(2)の結果は2.108秒と差はなかった.環境(3)の結果は0.034秒と(1)と比較すると提案システムの実行時間は約62倍かかった.Queryに関しては,環境(1)の結果は0.043秒,(2)の結果は0.043秒,(3)の結果は0.032秒と,(3)が若干高速であったものの大きな差は生じなかった.
Table 5 Experimental results.
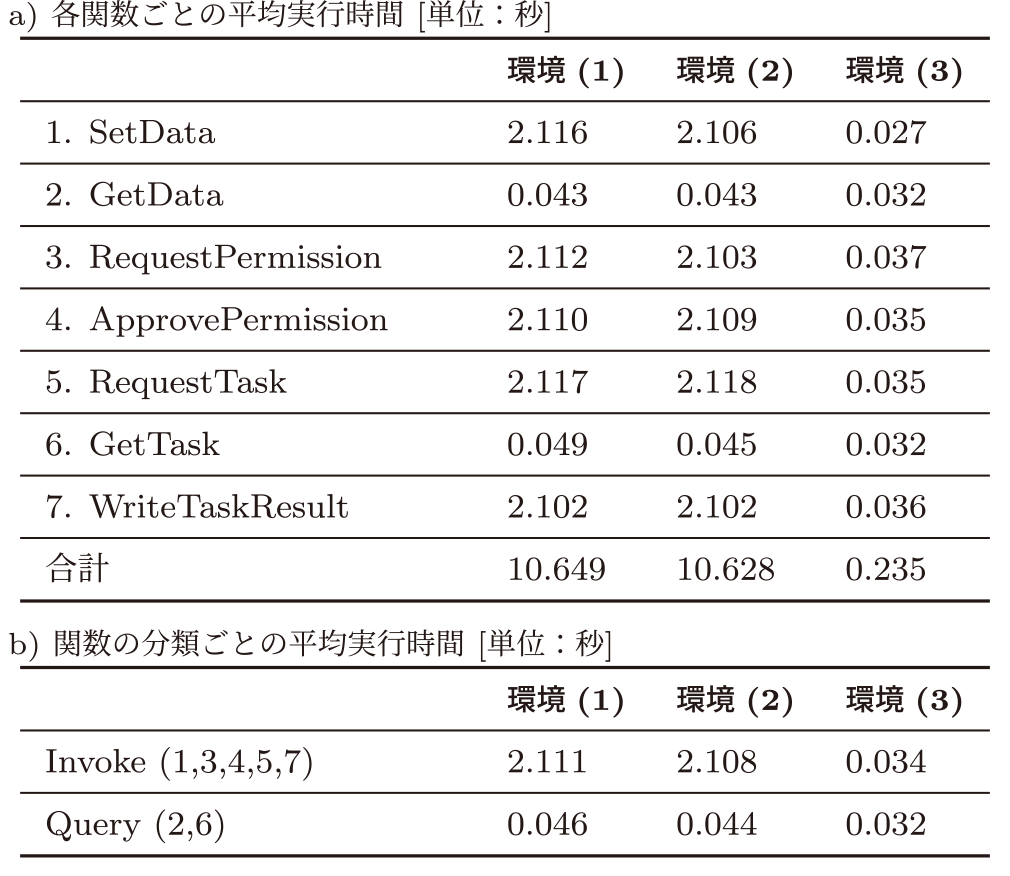
表5aにおける,環境(1)と(2)の測定結果より,SGXハードウェアの使用自体には遅延がないことが示唆された.また,環境(2)と(3)の測定結果より,Enclave RegistrationやRemote AttestationなどSGXを実行する際に必要となる処理に関してシミュレーションであっても処理遅延が発生することが示唆された.特にRemote AttestationはIntel社が所有するサーバと通信を行うことで信頼できる状態であることを第三者に証明する仕組みであるため処理に時間がかかると考察する.また,表5bの結果より,特に動作遅延となっている原因は分散台帳およびState DBの更新を伴うInvokeの関数であることが分かる.Queryの関数に関しては,Enclaveにてデータを復号化するのみの処理であるため,事前にローカル登録された証明書や鍵を用いているため外部のサーバとの通信は不要であることから,大きな遅延が生じないと考察する.
以上より,提案システムにおいては一部の処理で従来システムと比較すると若干の遅延は生じた.一方で,提案システムはゲノムデータを活用した処理であり,解析処理自体に数時間以上の処理時間を要することから,10秒程度の遅延はシステムの運用に影響を与えない.
7.3 機密データの安全性に関する評価
データの利活用を行った組織を組織1,データを所有する組織を組織2,一連の処理とは関係がない組織を組織3とし,機密データの安全性に関する評価を以下に示す.
はじめに,提案システムにおけるLedgerおよびState DBを直接参照するケースを評価する.提案システムにおけるLedgerおよびState DBに書き込まれるデータはTEE上で動作するChaincodeにより暗号化されて保存されている.よって,Chaincodeを介さない直接のLedgerおよびState DBに対するデータアクセスを行ったとしても組織1,2,3すべてのユーザにおいて内容を確認することはできない.このことは,実際に提案システムを実機検証し,一通りユースケースシナリオを実行した後にLedgerおよびState DBに直接参照することで確認できた.
次に,提案システムにおけるLedgerおよびState DBに対してChaincodeを介して参照するケースを評価する.Chaincode関数における(vi)GetTask関数の挙動に焦点を当てて評価をする.GetTask関数は自身が保有するデータIDに対して解析タスクの依頼が行われていた場合,そのタスクを読み出す機能である.よって,自身が保有するデータID,もしくは自身がタスクを依頼したデータID以外を引数に関数を呼び出しを実行した場合はエラーとして処理される.提案システムを実機検証し,組織1が(v)RequestTask関数により組織2が保有するデータに対する解析処理を依頼した.次に,データを所有する組織2がそのデータIDを引数に(vi)GetTask関数を実行したとき,正常処理として正しくデータが渡されることを確認した.また,一連の処理とは関係がない組織3が同様の(vi)GetTask関数を実行した際はエラーとして処理されることを確認した.
一方で,本提案システムおよびユースケースにおいては,組織に属するユーザが操作するクライアントPCのユーザ権限が奪われ,そのユーザになりすましてChaincode関数呼び出しをするようなケースの安全性は確保できない.クライアントソフトウェアにアクセスするパスワードや秘密鍵は,提案システムの保護機能とは別に厳重に管理する必要がある.
8. まとめ
8.1 得られた知見
本研究では,プライバシー保護機能を備えた分散台帳技術であるFabricを用いて,複数組織が参加するネットワークを構築し,機密情報を共同管理および利活用するシステムを検討した.提案システムは,医療分野の機密情報共有および利活用への実用化が期待されており,ゲノムデータを取り扱うユースケースおよびそのシナリオを具体的な事例として示した.
また,ユースケースシナリオの実運用に向けたシステム要件定義を行った.ゲノムデータを取り扱うユースケースにおいて,研究者は研究対象としているゲノムデータに関する情報は秘匿したいというニーズがある.分散台帳に書き込まれるデータを秘匿する手法としてZKPやMPC,TEEなどの秘密計算技術を用いる研究が数多く存在するが,実装時に比較的暗号学分野の専門知識が不要であるTEEを採用することとした.加えて,ハードウェアに依存するため計算機を準備するコストがかかるというTEEの課題に対しても,パブリッククラウドであるAzureを使うことで解決した.そこで,複数のプライバシー保護機能を備えたFabricを使用することとし,その中でもFPCを使用することが適していることを明らかにした.
さらに,提案システムの要件に対する実装評価,提案システムと既存システムの実機評価による性能フィージビリティ検証,機密データの安全性に関する評価を実施した.提案システムは既存システムより処理遅延は存在するものの,想定するヘルスケア分野のユースケースにおいては十分耐えうる性能を持つことを明らかにした.
8.2 今後の課題
今後は,提案システムの実証実験や実運用を進め,社会実装した際の運用した際の課題を発見し解決していく.また,FPCの開発コミュニティにおいては,現在Fabric標準のChaincodeと同様にGo言語で書かれたChaincodeをFPCに使用可能にする開発プロジェクトが進んでいる.Go言語はFabricにおけるChaincode開発のためのプログラミング言語としてデファクトとなっており,Fabric ChaincodeエンジニアはGo言語でコーディングできることを好む傾向にある.今後は,提案システムをGo言語で実装し,追加の評価を行う.
また,SGXはIntel社を信頼することを前提とした設計となっており,非中央集権的なシステム構成および運用を目指す分散台帳の基本的な理念と相反する点が課題としてあげられる.近年ではIntel社だけでなくAMD社やarm社が設計するCPUアーキテクチャも普及しはじめており,各社それぞれ別の手法でTEEを実装している.それらが相互運用可能にすることで,TEEの観点において非中央集権的なシステム構築を可能にすると予想する.今後は,各CPUベンダのTEEを利用可能とするFPC実装をOSSコミュニティに提案し,実装を推進する.
参考文献
- [1] World Economic Forum 2019: Data Free Flow with Trust (DFFT): Paths towards Free and Trusted Data Flows (2020).
- [2] デジタル庁:デジタル社会の実現に向けた重点計画(2022).
- [3] 経済産業省:データの越境移転に関する研究会報告書(2022).
- [4] Voigt, P. and Bussche, A. v. d.: The EU General Data Protection Regulation (GDPR): A Practical Guide, Springer Publishing Company, Incorporated, 1st edition (2017).
- [5] Nakamoto, S.: Bitcoin: A Peer-to-Peer Electronic Cash System (2009).
- [6] Buterin, V.: A Next Generation Smart Contract and Decentralized Application Platform (2013).
- [7] Androulaki, E., Barger, A., Bortnikov, V. et al.: Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains, Proceedings of the Thirteenth EuroSys Conference, EuroSys '18, New York, NY, USA, Association for Computing Machinery, pp.1–15 (online), DOI: 10.1145/3190508.3190538 (2018).
- [8] ConsenSys: Quorum, ConsenSys (online), available from 〈https://github.com/ConsenSys/quorum〉 (accessed 2024–08–27).
- [9] Brown, R., Carlyle, J., Grigg, I. and Hearn, M.: The Corda Platform: An Introduction (2016).
- [10] McKeen, F., Alexandrovich, I., Berenzon, A. and et al.: Innovative instructions and software model for isolated execution, Proceedings of the 2nd International Workshop on Hardware and Architectural Support for Security and Privacy, HASP '13, New York, NY, USA, Association for Computing Machinery, (online), DOI: 10.1145/2487726.2488368 (2013).
- [11] Kosba, A., Miller, A., Shi, E., Wen, Z. and Papamanthou, C.: Hawk: The Blockchain Model of Cryptography and Privacy-Preserving Smart Contracts, 2016 IEEE Symposium on Security and Privacy (SP), pp.839–858 (online), available from 〈https://doi.org/10.1109/SP.2016.55〉(2016).
- [12] Kang, H., Dai, T., Jean-Louis, N., Tao, S. and Gu, X.: FabZK: Supporting Privacy-Preserving, Auditable Smart Contracts in Hyperledger Fabric, 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), pp.543–555 (online), DOI: 10.1109/DSN.2019.00061 (2019).
- [13] Benhamouda, F., Halevi, S. and Halevi, T.: Supporting private data on hyperledger fabric with secure multiparty computation, Vol.63, No.2–3 (online), DOI: 10.1147/JRD.2019.2913621 (2019).
- [14] Zhou, J., Feng, Y., Wang, Z. and Guo, D.: Using Secure Multi-Party Computation to Protect Privacy on a Permissioned Blockchain, Sensors, Vol.21, No.4 (online), DOI: 10.3390/s21041540 (2021).
- [15] LayerX: Anonify, LayerX (online), available from 〈https://www.anonify.layerx.co.jp〉 (accessed 2024–08–27).
- [16] Cheng, R., Zhang, F., Kos, J., He, W., Hynes, N., Johnson, N., Juels, A., Miller, A. and Song, D.: Ekiden: A Platform for Confidentiality-Preserving, Trustworthy, and Performant Smart Contracts, 2019 IEEE European Symposium on Security and Privacy (EuroS&P), pp.185–200 (online), DOI: 10.1109/EuroSP.2019.00023 (2019).
- [17] Desai, H. and Kantarcioglu, M.: SECAUCTEE: Securing Auction Smart Contracts using Trusted Execution Environments, 2021 IEEE International Conference on Blockchain (Blockchain), pp.448–455 (online), available from 〈https://doi.org/10.1109/Blockchain53845.2021.00069〉 (2021).
- [18] Wu, Y., Liu, C., Sebald, L., Nguyen, P. and Yesha, Y.: Apply Trust Computing and Privacy Preserving Smart Contracts to Manage, Share, and Analyze Multi-site Clinical Trial Data, The International Conference on Deep Learning, Big Data and Blockchain (DBB 2022), Cham, Springer International Publishing, pp.3–14 (online), available from 〈https://doi.org/10.1007/978-3-031-16035-6_1〉 (2023).
- [19] Benhamouda, F., Halevi, S. and Halevi, T.: Supporting Private Data on Hyperledger Fabric with Secure Multiparty Computation, 2018 IEEE International Conference on Cloud Engineering (IC2E), pp.357–363 (online), DOI: 10.1109/IC2E.2018.00069 (2018).
- [20] Brandenburger, M., Cachin, C., Kapitza, R. and Sorniotti, A.: Blockchain and Trusted Computing: Problems, Pitfalls, and a Solution for Hyperledger Fabric (2018).
- [21] Koshi, I., Nao, N., Yoji, O. and et al.: Secure and Traceable System for Genomic Data Sharing Using Hyperledger Fabric Blockchain, Informatics In Biology, Medicine and Pharmacology 2020, IIBMP 2020 (2020).
- [22] 池川航史,西島 直:ブロックチェーンを用いた信頼ある機密データの管理および利活用基盤,電子情報通信学会論文誌D, Vol.105, No.11, pp.653–656(オンライン),DOI: 10.14923/transinfj.2021SGL0001(2022).
- [23] Senkin, S., Moody, S., Díaz-Gay, M. et al.: Geographic variation of mutagenic exposures in kidney cancer genomes, Nature, Vol.629, No.8013, pp.910–918 (online), DOI: 10.1038/s41586-024-07368-2 (2024).
- [24] Horie, S., Saito, Y., Kogure, Y., Mizuno, K., Ito, Y., Tabata, M., Kanai, T., Murakami, K., Koya, J. and Kataoka, K.: Pan-Cancer Comparative and Integrative Analyses of Driver Alterations Using Japanese and International Genomic Databases, Cancer Discovery, Vol.14, No.5, pp.786–803 (online), DOI: 10.1158/2159-8290.CD-23-0902 (2024).
- [25] Li, H. and Durbin, R.: Fast and accurate short read alignment with Burrows-Wheeler transform, Bioinformatics, Vol.25, No.14, pp.1754–1760 (2009).
- [26] Danecek, P., Bonfield, J. K., Liddle, J., Marshall, J., Ohan, V., Pollard, M. O., Whitwham, A., Keane, T., McCarthy, S. A., Davies, R. M. and Li, H.: Twelve years of SAMtools and BCFtools, GigaScience, Vol.10, No.2, p.giab008 (online), DOI: 10.1093/gigascience/giab008 (2021).
- [27] Robinson, J. T., Thorvaldsdottir, H., Turner, D. and Mesirov, J. P.: igv.js: an embeddable JavaScript implementation of the Integrative Genomics Viewer (IGV), Bioinformatics, Vol.39, No.1, pp.1–2 (online), DOI: 10.1093/bioinformatics/btac830 (2022).

koshi.ikegawa.mf@hitachi.com
2019年筑波大学大学院システム情報工学研究科博士前期課程修了.同年株式会社日立製作所入社.Web3/ブロックチェーンに関する研究開発に従事.
採録日 2024年10月9日