PLRデータの2次利用に資するデータハブシステムの構築と運用
Building and Operating Data Hub System for Secondary Use of PLR Data
1. はじめに
大阪大学では2018年9月から,文部科学省が実施する「Society 5.0実現化研究拠点支援事業」に採択された「ライフデザイン・イノベーション研究拠点事業」を理化学研究所と日本電気(株)とともに推進している[1].本事業は,一般社会の様々な生活シーンにおける多種多様なデータを活用することに重きをおいている.データを活用し,生活の質(Quality of Life,QoL)の維持・向上を目指した「ライフスタイル」研究,心と体の健康増進を目指した「ウェルネス」研究,楽しみと学びを実現する「エデュテインメント」研究を並行して推進することで,人と日常の健康・生活の関わりから,身体の健康,心の健康,社会的健康(コミュニケーション),環境の健康を基軸にして輝く人生(高いQoL)をデザインし,様々な技術革新と社会経済環境の変革を大学から発信することを目指している.
本事業では図1に概要を示すシステムを構築してきた.ここで収集されるデータが個人情報を内包するデータであることから,主に「個人情報の保護に関する法律」[2]およびGDPR(General Data Protection Regulation)「データポータビリティ権」[3]に定められた個人の同意にもとづいたデータ利用を可能にすべく,個人の意思決定を必要な局面ごとに同意管理できる仕組みを実装したPLR基盤を構築した[4].個人の健康や医療・介護に関するデータであるパーソナルヘルスレコード(PHR)や日常生活で発生する個人データや生活環境データであるパーソナルライフレコード(PLR)を,この仕組みを利用して活用することによって,今まで解決が難しかった個々人によって異なるそれぞれの課題により近く寄り添った対応ができる社会の構築が期待できる.
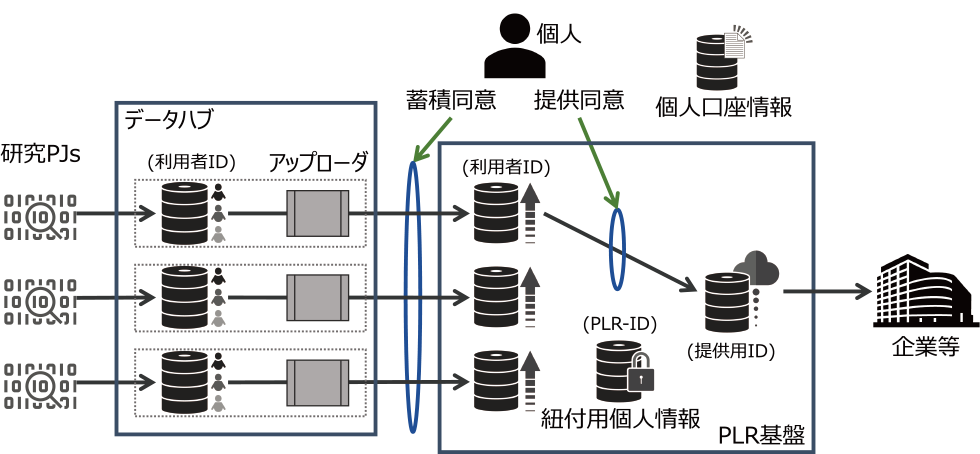
Fig. 1 The decision to store PLR data in the PLR infrastructure is left to the individual, and consent is requested before storing or providing the data. On the other hand, the data hub transfers only the data that the individual agrees to store to the PLR infrastructure after processing to ensure uniform quality.
ここで,個人と研究プロジェクト,PLR基盤との関係を整理する.まず,PLRデータ*1を提供する個人は,PLR基盤に利用者登録する(PLR基盤では口座を開設するという).口座開設にあたっては,個人の本人確認をマイナンバーカードや免許証等の公的書面を用いて行っている.口座開設後に個人は研究プロジェクトに参加することになるが,その際に研究プロジェクトからインフォームドコンセントの一環として説明を受ける.個人はその理解のもとに,PLR基盤のWebインタフェースにて「口座開設時に登録した,本人性確認情報が申請先の組織に提示される」という点と,「あなたのMYPLR口座に,あなたのデータが蓄積される」という点に同意する.ここで同意が得られないPLRデータはPLR基盤には蓄積されない.
また,PLR基盤にはPLRデータを活用するデータ取引事業者のための取引機能が実装されている.PLRデータのデータカタログが事業者に提示され,必要なデータを活用するために必要なデータ量を当該事業者と取引できる.PLR基盤ではPLRデータを構成する各要素に関するメタデータをデータカタログと呼んでいる.PLR基盤からデータが取り出され活用される際にも,事前にその目的を個人に開示し同意を取得している.提供同意とよんでいる.ここでもPLR基盤のWebインタフェースを用いて,提供の必要性や目的が丁寧に説明され*2,個人の意思決定の一環として同意がなされる.PLRデータの提供にあたっては,当該事業に係るコンソーシアム*3を設立し,会員法人に限定した提供を行っている.また,法人が会員になる際にはコンソーシアムが厳正な審査を行っている.提供同意がなされた後に,取引事業者との間で取引が成立した場合には,報奨が個人に返される機能もPLR基盤は実装している.
各研究プロジェクトが収集したPLRデータはマルチモーダルなデータであり,PLR基盤に直接蓄積するには品質に関するリスクが残るとともに,PLRデータの利用者(2次利用者)にも負担をかけることになる.そこで,各研究プロジェクトが収集したPLRデータを一旦集約するデータハブを,SaaS(Software as a Service)として利用するPLR基盤にPLRデータを蓄積する前に配置する図1のアーキテクチャを採用した.データハブの主たる役割は,研究プロジェクトからの多種多様なデータの品質の一様化にある.
以下,本稿ではデータハブのアーキテクチャ策定からその実装,運用を通してのプラクティスを述べる.2章では,PLR基盤に前置されるデータハブに関する課題を議論する.3章では,それらの課題から導き出されたシステムに対する要求およびアーキテクチャ要素を述べるとともに,データハブの実装に関して述べ,本データハブの特徴をまとめる.4章では,関連研究を述べるとともに,本データハブの特徴と対比する.5章で3年間の運用期間中に発生したインシデントを層別化し,対応策のプラクティスに関して議論する.最後に6章で本稿をまとめる.
2. 課題
データハブではPLR基盤に記録されている同意状況に制約された形でPLRデータの取り扱いが必要であるので,データハブの構築にあたっては3省2ガイドライン[5], [6]に規定された内容を考慮する必要がある.本章では,データハブ構築に際しての課題を整理する.
- (1) 蓄積されるPLRデータの品質を一様に保つためのデータ管理方針の一元化
各研究プロジェクトで扱われているPLRデータは,その種類,量,担当者の熟練度,等々プロジェクトごとに異なっている.PLRデータを蓄積する際には,各研究プロジェクトはデータカタログというデータの設計図を作成し,審査を受けなければならない.PLRデータはこのデータカタログのもとに統制されている.これは,管理ポリシーの一元化につながる.それが強制されることで,プロジェクトごとの差異を吸収することができ,プロジェクトアウトプットを一様化できる. - (2) PLRデータの加工処理のための計算資源に対する多様な要求対応
各研究プロジェクトでのデータ解析にはマルチモーダルなPLRデータが利用されている.計算資源に対して高性能を要求するデータもあれば,多くのストレージ資源を要求するデータもある.倫理審査委員会の審査は研究プロジェクトごとであり,これらの資源は研究プロジェクト間での無用なアクセスがないことを保証できなければならない. - (3) 標準に準拠したセキュリティ基準への遵守
3省2ガイドラインには,個人情報を含むデータを適切に扱うために,情報セキュリティマネジメントシステム(ISMS) [7]等の標準規格に準拠したセキュリティ基準を満たすことを要求している.同時に,基準に対する準拠を証明する監査ログを確実に収集し,監査に対する証跡として提供できることを要求している. - (4) サイバー攻撃に対する回復力
経産省のガイドラインでは対象システムのライフサイクルを合意形成から合意の維持までの観点から整理している( [6]図3–4).ここでは,この合意の維持を回復力(resilience)として定義する.サイバー攻撃はインターネットに繋がっている限り避けられないので,その影響を最小にするとともに,当該攻撃に対しても合意を維持するための回復力の実現が重要である.
これらの課題に対して次章でアーキテクチャ設計を行い対応を検討する.
3. 設計と構築
本研究ではマイクロサービスアーキテクチャの採用を基本方針とし,当該アーキテクチャが課題解決に与える影響を議論する.次に,構築に関して議論する.実装はLinux*4上のKubernetes [8]を利用して構築する.実行中のプロセスのルートディレクトリを変更するchroot機能や計算資源に対する名前空間を隔離する機能を利用して実装されているDockerコンテナ(以下単にコンテナ)を基本に実装手段を検討する.表1にマイクロサービスアーキテクチャを実現するシステム要件とその実装案をまとめた.
Table 1 System requirements vs. proposed implementation strategies.

3.1 アーキテクチャ設計
マイクロサービスアーキテクチャとは大規模なソフトウェアシステムを小さなソフトウェア部品(ここではマイクロサービスと呼称)から構成する手法であり,そこには次の3つの基本的特性がある[9].
- (1) 無特権(no privilege)
- (2) メッセージ均一性(uniform communication)
- (3) 合成(composition)
無特権とは構成するマイクロサービスには特権を持つ部品がなく同様に重要であることであり,メッセージ均一性とはマイクロサービス同士は均質な方法で相互作用を行うことであり,合成とは1つのマイクロサービスが複数のマイクロサービスに分割可能なことであり,転じて複数のマイクロサービスを合成して別のマイクロサービスとすることが可能であることである.これらの基本的特性によりマイクロサービスアーキテクチャにより構築されたシステムには次の3つの性質が具備される.
1つ目は,マイクロサービスの独立性である.マイクロサービス間の独立性のみならず,マイクロサービスの実行環境依存を切り離す.これにより用語(terminology)の適用範囲が明確化される.大規模ソフトウェア開発では複数の責任境界が用語の誤用を招き品質に対するリスクを増大させている.この独立性により,課題(1)のデータ管理方針はマイクロサービスに対する方針として一元化できる.また,課題(3)のセキュリティ基準への遵守に際しては,マイクロサービスという一様な責任境界を考慮すれば良い.セキュリティリスクはマイクロサービス内部に閉じ込められ,外部に対しては一様なリスク管理方針を適用できる.
2つ目は,マイクロサービスの加算性である.マイクロサービスは追加しても既存の環境には影響を与えないという特性を有する.もはや本番環境とステージング環境という区別は必要ない.複数のバージョンのマイクロサービスが混在できる.この性質は,課題(2)の要求の多様化に対して有効である.新しい要求に対応したマイクロサービスを追加すれば良い.また,課題(3)に対しても修正や削除に対するセキュリティリスクは考慮しなくて良い.ただし,ISMS対応には注意を要する.ISMSは基本的に引き算が原則であり,この加算性とは相容れない.この加算性がISMS基準で何らセキュリティリスクに影響してないことの保証が必要になる.
そして3つ目が,マイクロサービスの検証可能性である.すなわち開発者の意図どおりにシステムがデプロイされていることをコンピュータが確認できるという特性を有する.開発者の意図はコード化され,IaS(Infrastructure as Code)としてシステムを構成するとともに自動化される.課題(4)に対しては,サイバー攻撃の侵入口はメッセージによるマイクロサービス間の相互作用のみであり,必要な回復力はコードにより実装できる.また,課題(3)に関して,ISMSはリスクは手動操作に内在しているとする立場であり,操作に対する計画と実行履歴の記録を要求している.以上のように,マイクロサービスアーキテクチャをデータハブを実装する際の基本的なアーキテクチャとすることで,前章の課題に対して適切に対応可能である.
3.2 実装概要
構築したデータハブの実装概要を図2に示す.オンプレミスにKubernetesクラスタを配置する.サービスメッシュにIstioを利用し,テナント分離によりマイクロサービス群を配置する.当該クラスタはGitOpsによりクラスタ制御を実行する.後述する回復力を実装するためにパブリッククラウド上にオンプレミスクラスタの複製を配置する.
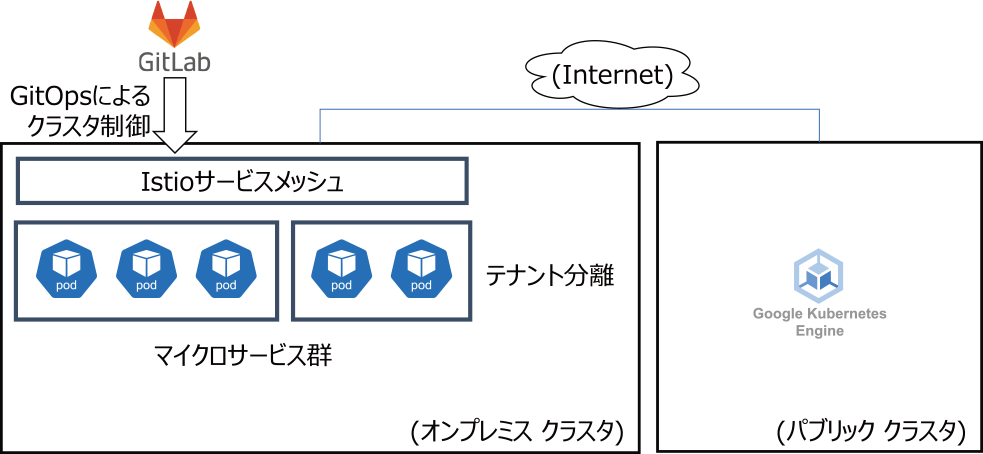
Fig. 2 Kubernetes clusters have been deployed on the on-premise environment as well as the public cloud. Those clusters are managed by GitOps.
本システムでマイクロサービスとして主に動作させたのは,複数の研究プロジェクトからのデータのアップロード要求を受け付け,PLR基盤に格納するアップローダサービスである.その構成は図3のとおりである.研究プロジェクト共通のサービスと研究プロジェクト固有のサービスに分けられる.
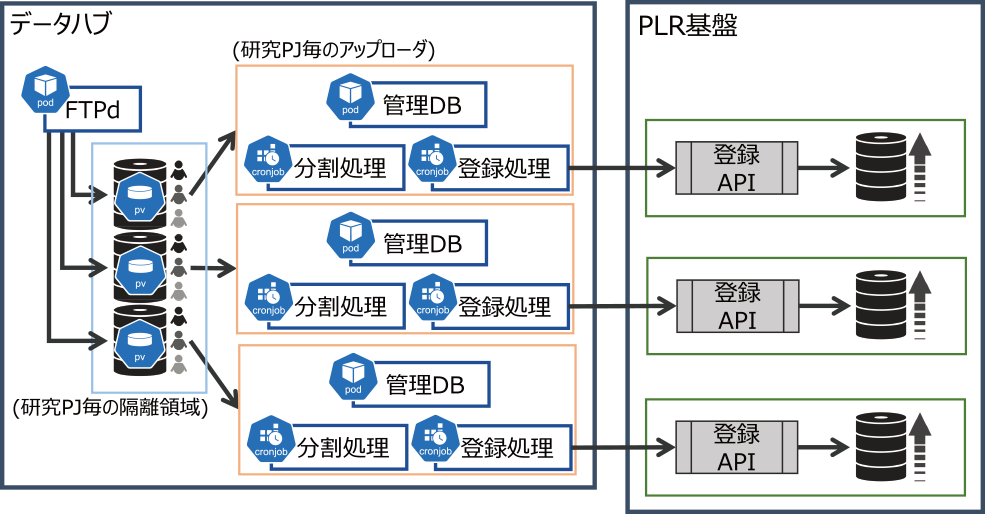
Fig. 3 Research projects transfer data to a pre-assigned unique area using the FTPS protocol. The uploader service for each project consists of three pods, and only data that have been agreed to be stored by individuals are transferred to the PLR infrastructure with a uniform quality process.
- (1) FTP Pod|研究プロジェクト共通にデータアップロードを受け付けるftpサービス
- (2) 研究プロジェクト固有サービス
- (a)Service|管理DB(PostgreSQL)
- (b)CronJob|オブジェクトデータ分割処理(Node.js)
- (c)CronJob|オブジェクトデータ登録処理(Node.js)
FTP Podは,研究プロジェクトごとのストレージ領域へのデータ転送で用いるため,「研究PJごとのアップローダ」の数に関係なく全体で1つのPodの構成にした.プロトコルにはFTPSを利用しているので,SSL証明書の更新作業が発生する.
SSL証明書の有効期限を1年にしたので,更新作業は年に1回発生する.
結果として当該Podの運用には定期作業が発生することになり,運用コスト削減の観点でテナントを分離せずに一元管理することにした.ここでの構成は以下の3点を考慮して運用面・セキュリティ面のリスクは低いと判断した.
- ・当該Podは閉域網にデプロイされていること
- ・各研究プロジェクトからのアクセスに対しても通信経路が保護されていること
- ・研究プロジェクトごとに1つのIDとパスワードを配付し,「研究プロジェクトごとの隔離領域」へアクセスしていること
FTP Podは,システム内外の境界部分に位置しており,その提供している機能や全体ネットワーク構成を考慮し,同一テナントにしたほうが運用コストは下がると考える.トレードオフの関係にある.
各研究プロジェクトからアップロードされたPLRデータは,分割処理と登録処理の2つの処理を経てPLR基盤にアップロードされる.分割処理では,当該PLRデータを読み込み,PLR基盤に登録するための個人データ(オブジェクトデータ)に変換する.具体的には,csv形式ファイルを読み込み,PLR基盤に登録する個人単位データ(オブジェクトファイル(json))に分割する.分割処理に問題が発生した場合には,当該PLRデータすべてに対する処理を破棄する.正常に処理が行われると,登録処理にて当該PLRデータをPLR基盤に転送し登録する.登録処理で問題が発生した場合には,PLR基盤に登録中のものも含めてすべてロールバックされ,当該PLRデータはアップローダ内の「error」フォルダに格納し,エラーが記録される.成功した場合は「完了済」フォルダに格納される.これらはすべてバッチ処理にて行われ,障害時のログメッセージに対するアクションは,管理者向けと利用者向けに標準化された手順書*5に記載された手順で対応できるようにした.
ここでの処理過程では個人データDB,オブジェクトデータDB,ログDBから構成される管理DBに必要な記録を残している.個人データDBには,個人データを一時的に格納するとともに,分割処理により,データファイルの1行ごとに個人データとして登録される.なお,個人データは,オブジェクトデータ分割処理のデータ編集により,個人ID単位の編集処理終了後に削除される.オブジェクトデータDBには,PLR基盤に登録する際のスキーマ定義に修正したデータが格納される.個人ID単位に蓄積が行われ,登録処理終了後にデータが削除される.ログDBには処理の履歴を記録している.
3.3 コンテナ管理
本データハブでは,コンテナ管理にコンテナオーケストレーションを利用することにした.コンテナオーケストレーションとは複数のコンテナのライフサイクル管理を支援するソフトウェアである.代表的な実装には,Kubernetes,Docker Swarm [17],Mesos [18]があるが,データハブでは後述する回復力の実装にパブリッククラウドを利用する関係でKubernetesを採用した.
データハブでは,複数の研究プロジェクトが計算資源を共有することになる.複数利用者がKubernetesを利用するための構成としては,1つのKubernetesクラスタを共有するマルチテナント型と,利用者ごとに複数のKubernetesクラスタを提供するマルチクラスタ型がある[19], [20].データハブでは,マルチテナント型により名前空間に分けて単一のKubernetesクラスタを共用する形をとることにした.主な理由は計算機リソースの利用効率とKubernetesクラスタの管理コストである.
基本的に1つのKubernetesクラスタであるが,パブリッククラウド上は独立したクラスタを構築することにした.インターネットを経由してオンプレミスとパブリッククラウド間で単一のKubernetesクラスタを運用するには,遅延や通信障害時の動作などにリスクを抱えることになるため,独立したクラスタとして実装することを選択した.
3.4 サービスメッシュ
マイクロサービス間の通信制御にサービスメッシュ技術を利用することにした.これにより2章で述べた課題のうち,課題(3)のセキュリティと課題(4)の回復力に対する解決が期待できる.サービスメッシュを実装するオープンソースとして,本データハブでは以下の機能が実装できるIstioを選択した.
- ・トラフィック制御
マイクロサービス間の通信をアプリケーション層で仮想化しサービスの発見,フロー制御,通信キャパシティ制御を実装可能にする. - ・回復性,耐障害性
サーキットブレーカや,タイムアウト処理,再実行などの機能を実装可能にする. - ・セキュリティ
通信の暗号化,IAM制御,およびAAAツールにより,セキュリティポリシーを適切に制御する機能を実装可能にする. - ・可観測性
ポリシーが適切に実施されていることの証跡となるメトリクスを計測でき,マイクロサービスのトラブルシュート,保守,最適化を実装可能にする.
3.5 システム運用監視
データハブの運用では,システム監視が必要な項目を次の4つに絞った.
- (1) ホストレベルでの死活監視,およびリソース利用量などのメトリクス
- (2) Podごとやサービスごと,あるいはサービスメッシュ
- (3) マイクロサービスの状態やログ情報
- (4) クラスタやホストマシンの操作履歴を含む監査ログ
これらの項目に対して,以下の方針で実装を行った.
- ・(1)に関しては,Prometheusによる監視を行い,収集したデータをGrafanaにより可視化する.
- ・(2)に関しては,(1)同様にPrometheusによる監視を行い,Grafanaにより可視化する.サービスごとのネットワーク利用状況に関してはIstioの機能(Kiali)を利用する.
- ・(3)に関しては,FluentdをKubernetesのDeploymentとしてノードごとに動作させ,ノードごとの標準出力を回収しElasticsearchに統合する.より複雑なログを回収したいアプリケーション用に,各アプリケーションにサイドカーとして動作させることも推奨する*6.
- ・(4)に関しては,OSレベルのauditdでの監査ログ取得するとともに,GitOpsでクラスタ操作を記録する.
これらの構成について図4に概略を示す.監査ログについてはKubernetesの構成ノードすべての監査ログをauditdにより収集し,監査ログとして分離格納している.また,Kubernetesの操作ログをkubeapiサーバで取得することができる.現状ではKubernetesのマニフェストをArgoCD経由で操作させることによって,Gitリポジトリの履歴にクラスタ操作ログを残している.
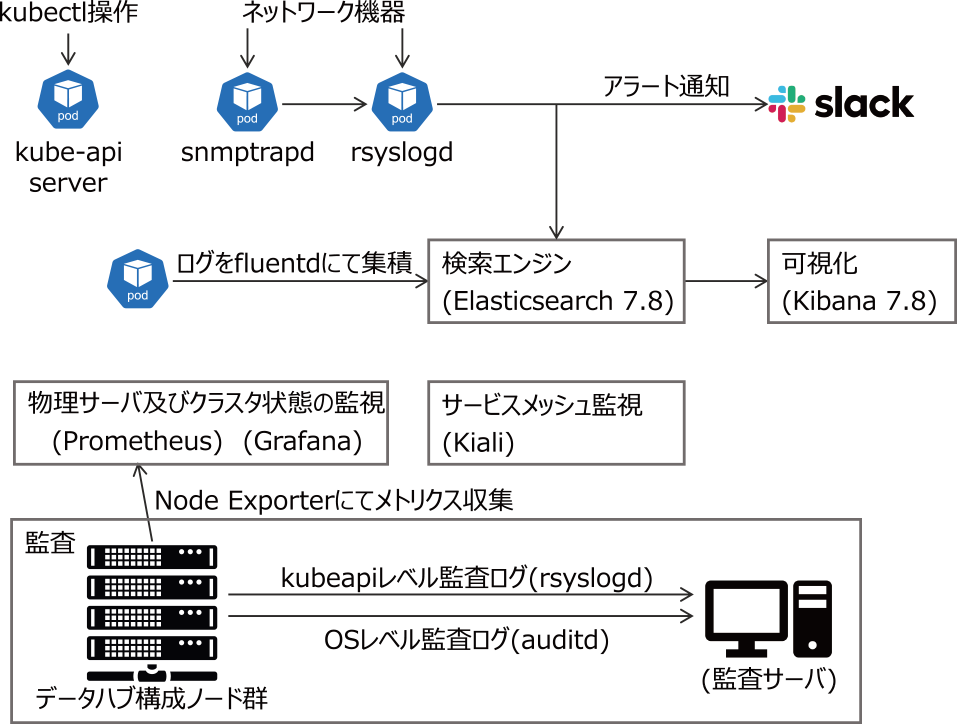
Fig. 4 Pod logs have been aggregated to Elasticsearch by fluentd, and the cluster status and the service mesh status have been aggregated using OSS (Open Source Software) and visualized by Grafana. Separately, audit logs have been aggregated on a separate server in consideration of security risk. The elements in the figure (except Slack) have been deployed in the on-premise environment.
なお,上記の監視系サービスは,オンプレミスの隔離されたテナント内にデプロイした.提案するデータハブはハイブリット構成をとっているので,監視系サービスをパブリッククラウド上のマネージドサービスを利用することもできたが,今回は監査ログに対する責任範囲を外部には広げないという上位要求によりオンプレミス環境にデプロイした.
3.6 回復力の実装
本データハブでは,Gitリポジトリに格納されたKubernetesマニフェストをArgoCDを用いてKubernetesクラスタに同期する形でGitOps運用を行う.マイクロサービス開発者がGitリポジトリにマニフェスト変更をマージリクエストとして発行し,運用管理者がマージリクエストを確認することでクラスタの状態変更操作を承認して,クラスタ状態の修正を行う.このような形態とすることで,クラスタ状態の変更動作はマージリクエストのレビューによってチェックされ,クラスタ操作が基本的にGit更新履歴として保持される.また,操作ミスが発生した際には容易に過去の状態に戻すことが可能である.
このGitOpsの仕組みを用いて,オンプレミスクラスタからパブリッククラスタへの回復力を実現した構成図を図5に示す.オンプレミスクラスタとパブリッククラスタ間でのマニフェストの設定の差は,Kustomize(helmなどのパッケージマネージャでもよい)を用いて設定差を吸収するよう指定しておく.本構築システムでは,オンプレミス環境とパブリッククラウドの差は,nfsサービスのIPアドレスとpathのみである.その差分設定のみのマニフェストを用意し,Kustomizeツールを通すことで差分のみ変更されたマニフェストをパブリッククラウド側のクラスタに適用できる.ArgoCDサービスはあらかじめパブリッククラウドのクラスタでも動作するようにしておき,サイバー攻撃を含む外部要因によるオンプレミスサービスの停止時などサービスを移行する必要がある際に,ArgoCDサービスを立ち上げ,サービス切り替えを行う.インターネット向けサービスを運用している場合には,DNSを更新することでサービスIPアドレスをパブリッククラウド側に切り替えることが可能である.
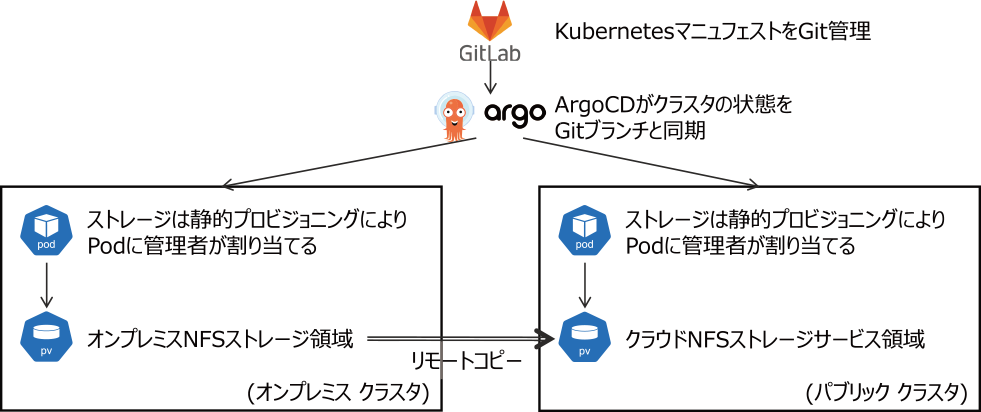
Fig. 5 The implementation of resilience using the GitOps mechanism is achieved by switching Git-managed difference manifests between on-premise and cloud environments.
3.7 セキュリティ実装
本データハブでは,Kubernetesのセキュリティ対策を実装する.CIS(Center for Internet Security)ベンチマーク[21]を実行し,121項目の内,7件のFAILと39件のWARNの内容を検討し,必要な対策をデプロイすることにした.また,セキュリティポリシーの適用をマイクロサービス開発者と運用管理者の2つのロールに分けて設定する.前者にはNameSpaceに対する操作権限のみを与える.後者にはクラスタを構成するホストへのログイン権限を与える.両者に共通のポリシーとして,VPN接続にてデータハブシステムにアクセスする際には,アクセス元IPアドレス制限による保護を追加するとともに,証明書によるKubeletへのアクセス権限を与える.また,より厳しい条件としては,運用途中から次の項目を追加することにした.
- ・一般的なマイクロサービス開発者にはGitへのアクセス権限のみ与える.
- ・運用管理者がレビュー,マージリクエスト承認により必要なマイクロサービスをデプロイする.
3.8 データハブの特徴
ここで,本稿で構築したデータハブの特徴を簡単に3つにまとめると次のようになる.
- ・各研究プロジェクトからのPLRデータの品質はデータカタログにより一様化され,PLR基盤を通して2次利用に供される.
- ・セキュリティ基準に準拠したPLRデータの加工処理に関する証跡が記録されている.
- ・PLRデータのライフサイクルにおける責任境界が個人の意思決定に基づくガバナンス下にある.
4. 関連研究
大阪大学病院では院内データの流通を管理する仕組みを,EHR(Electronic Health Record)の拡張としてPHR(Personal Health Record)を定義し,その1次利用と2次利用の両面に関して試行している[22].ここでは,PHRデータの取り扱いに関しては,個人からの医療情報銀行への信託にもとづき,医療情報銀行に管理責任がある.本稿との関係では,本データハブとPLR基盤を含めた構成と対比され,院内に配置されたゲートウェイサーバが本データハブに対応する.データの2次利用まで考えた場合に1次利用でのデータ品質に対する2次利用での影響をどこまで吸収できるか懸念が残る.たとえば,DMBOK [23]では13章でデータの利用目的に合致した品質保証の重要性を指摘している.一方,本データハブではPLRデータの品質は研究プロジェクトによりデータカタログとして定義され,2次利用に際して利用者に提供される.その際の個人の2次利用に対する意思決定はあくまで本人にある点は同じである.
PHRデータを個人が所有するスマートフォン等のデバイスに記録する分散PDSに関する研究がある[24].ここでは,PHRデータそのものは,個人が保有し,管理する点で,すべての責任が個人に帰属していることを特徴とする.その点で個人情報保護法の改定に対する耐性が最も高い方法でもあると言える.一方でデータ品質に対しては,個人の責任を超えるケースもあり,またフェイクデータの懸念が残る.PHRデータのアクセス可能性を保証するにも何らかの対応を必要とする.さらに,自分のPHRデータが漏洩しないように防御するのも個人の責任である.一方,本データハブではデータはPLR基盤に蓄積され,個人の関心は本人のPLRデータの利用目的に対する同意のみである.
個人情報を内包するPHRデータを蓄積するためには,蓄積に至る過程におけるデータ管理に,規制の改正を含む環境の変化に対する耐性を始め,セキュリティに対する個人起点のガバナンスが必要である.Ohmuraらは,責任境界を超えてデータを集積する仮想データレイクと,データレイク内のデータをサンドボックス内で処理する仕組みを提案している[25].ここでは,仮想データレイクに集積されるのはデータそのものではなく,データへのリンク情報を含むメタデータである点に特徴がある.しかし,責任境界は法人と法人の間の境界であり,個人を起点とするデータガバナンスに懸念が残る.一方,本データハブでは個人がデータガバナンスの起点であるが,個人は利用目的に関しての同意のみに関心をもち,データガバナンスに係る他のことは本データハブ(およびPLR基盤)が責任を負う.Ohmuraらのサンドボックスの仕組みは本データハブとテナント分離と同じ概念である.
Riscoらはオンプレミス環境とクラウド環境を連続体(continuum)として捉えたサーバーレスのFaaS(Functions as a Service)環境を構築し,データサイエンスワークフローを実行する仕組みを提案している[26].個人情報を含むデータの処理は規制遵守のためオンプレミス環境で行い,高度の弾力性を必要とする計算をクラウド環境で行うことができる.PHRデータを対象としたデータガバナンスに関しては,クラウド環境の厳密に管理されたサービスを用いて実装できる.しかし,責任の境界が複雑になるため,説明責任の遂行リスクを高める.一方,本データハブではRiscoらとはパグリッククラウドの位置付けに違いがあるとともに,FaaSより下位に制御層を置いており,より多様な計算資源要求に対応できる(たとえば,AWS LambdaではCPU性能はメモリ量と連動している[27]).
5. 議論
本章では,構築したデータハブの妥当性を次の3つの観点から議論する.
- ・サービス運用,特にデータ蓄積に関するプロセスの観点
- ・情報セキュリティマネジメントシステム(ISMS)認証取得の観点
- ・運用期間中に発生したインシデント対応の観点
図6に本データハブの運用期間のイベントを時系列で並べた.以下,この系列にそってにプラクティスを議論する.

Fig. 6 The events that have occurred since 2020 are arranged chronologically according to the three perspectives of 'data accumulation', 'ISMS certification' and 'incident response'. Data accumulation began in the later of 2021 due to the Corona Disaster.
5.1 データ蓄積
PLR基盤への研究プロジェクトからのデータ蓄積に関する一連のプロセスを支援する目的で図3に示した構成で複数のマイクロサービスを実行した.データをPLR基盤に蓄積するには,研究プロジェクトは適切な事前承認を得る必要がある.その際に,研究プロジェクトはデータカタログを準備する.データカタログは,データ提供者が蓄積同意の際の確認目的で利用されるほか,データ利用者が購入するデータを検討するためにも利用される.データハブ管理者は当該承認を待って,共有ストレージからプロジェクト固有領域を払い出し,データを一時蓄積するために研究プロジェクトに対してアクセスアカウントを発行する.そして,複数のPodから構成され,当該アカウント権限で実行されるアップローダサービスをデプロイする.また,研究プロジェクトでは,研究データを蓄積するにあたって,データをPLR基盤蓄積に適した形式に整形する.実験の参加者の個人名は被験者IDに置き換え,データはCSV形式で記述する.マルチメディアデータや時系列データはCSV形式では扱い難いので,データをハッシュ化し,ハッシュ値をデータとして蓄積する.その際の原データは研究プロジェクトで保管する.
上記にて準備されたデータは,図3記載のFTP Pod経由で研究プロジェクトごとの固有領域にFTPアップロードする.分割機能PodはCronJobとして定期的に起動され,固有領域にあるデータをPLR基盤に蓄積する適切な単位に分割する.別途CronJobとして定期的に起動される登録機能PodがPLR基盤が提供する登録APIを利用してPLR基盤に蓄積する.
3年間の運用期間を通して,4つの研究プロジェクトのアップロード処理を行った.上記3.5節のシステム運用監視によりアップロード処理のログを検証した.システム動作の健全性,およびPLR基盤の蓄積状況とアップロードデータの整合性を確認した.上記プロセスでは,もっぱらデータハブ運用組織の人手に頼っている処理が多かった.理由の1つに,扱うデータが機微なデータであるために,上述するISMS認証取得に十分な証跡を残す必要があったからである.一方で,研究プロジェクト側のデータ整形作業は自動化が可能であったがプログラム開発のリソースが不足しておりシステム化は実現できなかった.
5.2 ISMS認証取得
データハブにて取り扱うデータには個人情報を含むので,適切なデータハンドリングがデータハブ運用組織によりなされていることを第3者機関が認証することで,セキュリティに関しての対外的信頼性を確保することを目的に,ISMS認証を取得することになった.その際にシステムに対する変更要件は発生しなかった.主な理由として,上記3.5節で構築したデータハブシステムを構成する要素技術が既にISMSの求める要求に対応可能な手段を提供済みであったことが挙げられる.上記3.7節でのセキュリティポリシーの設定により,認証にあたって設定した認証スコープに対して適切な証跡を残すことができた.課題としては,証跡の記録を監査にあたって別途準備する必要があった.図7に設置したISMS推進体制を図示する.
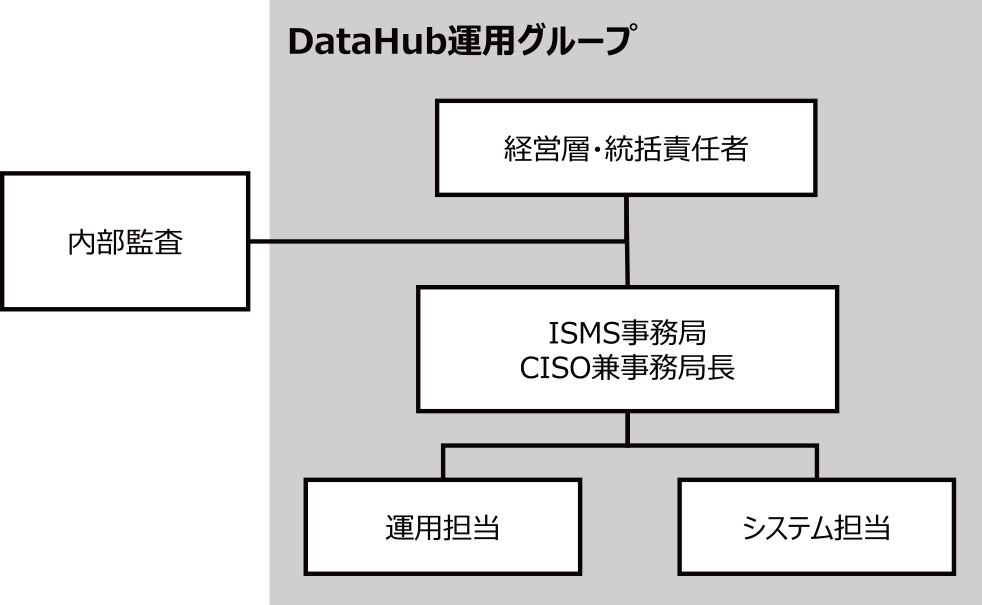
Fig. 7 A management and general manager has been established. The ISMS Secretariat, headed by the Chief Information Security Officer and Secretary General, has been placed under it. Actual responsibility has been placed in charge of general operations and system operations. The internal audit has been placed these outside.
ISMSは責任境界を明確にし,国際規格ISO 31000 [28]に基づいたリスクマネジメントとしてセキュリティ対策を実装するフレームワークと考えることができる.一方で,マイクロサービスアーキテクチャでは明確な責任境界が織物のように絡まっている.APIによるサービス同士の接続という横の糸と,仮想化によるレイヤー間の接続という縦の糸である.ISMSが想定する説明責任の構造と,マイクロサービスアーキテクチャによる説明責任の構造とは,粒度が違い,複雑度も違う.その影響が証跡の記録と監査との関係に具現化し,課題になったと考えられる.
5.3 インシデント対応
2020年4月から2023年3月までの運用期間を通してインシデントは20件あった.大きく次の5つに分類できる.各々に関して代表的なインシデントの内容とその対策,および再発防止策を議論する.
更新 システム要素を更新する際に発生
キャパシティプランニング リソース不足により発生
構成管理 構成情報のエラーにより発生
通信何らかの原因で通信不可の障害発生
セキュリティパッチ 緊急セキュリティ修正更新が必要になった
5.3.1 更新
多くのインシデントは,何らかのシステム構成要素を更新する際に発生した.最も影響の大きかったのはKubernetesの更新時に発生したインシデントであった.この更新は以下の大きな変更を伴っていた.
- ・サポートコンテナランタイムの変更(dockerからcontainerd)
- ・API名称の変更
このような大きな影響を及ぼすアップグレードの場合,原因調査,対策などに数時間程度の時間を必要とすることがあった.バックアップクラスタでの事前検証は行っていたが,オンプレミス環境でのみ発生した現象もあり,ローリングアップグレードなどダウンタイムを引き起こさない方法で行う必要がある*7.
また,各種証明書更新忘れによりkubeapi操作ができなくなった.実際にデプロイなどを行わないと気づかないため,管理者が認識できないことがあった.対策として,年オーダの更新計画を立て,アップグレード時期を年間線表に組み込んだ.
本システムは約3年以上動作し,その際にKubernetesのアップグレードを繰り返しながら運用を行った.Kubernetesの動作に問題は発生しなかったが,Istioは途中で動作しなくなってしまった.その時点でIstioは構築当初と比べ,インストール方法・構成など大きく異なっており,初期構築時のマニフェストを自力で修正して対応することは困難であった.本システムにおいてIstioの必要性は低かったため,その時点でIstio関連サービスを取り除くなどの対処を行った.Kubernetesは頻繁にアップグレードされ,長期にわたりアップグレードを繰り返した場合の検証などが行われているとは考えにくいため,本来は定期的に新規クラスタを構築しなおし,サービスを移植するといった対策が必要なのではないかと考える.
5.3.2 キャパシティプランニング
キャパシティプランニングに関して,特に性能見積もりが十分でなかったことが要因で発生したインシデントがあった.当初はElasticsearchの中長期的な運用を想定しておらず,sharding数など初期設定のまま運用していた.これにより,メモリ利用量の肥大化やElasticsearchコンテナが起動しなくなる,などの問題を引き起こした.システムやインデックス構成を見直し,サービスを再構築して復旧を行った.
5.3.3 構成管理
構成管理に関して,特にPodのマニフェストファイルのエラーにより発生したインシデントは,Kubernetesの更新によりAPI名変更(古い名称での利用が不可)になり,マニフェストの修正が必要になった.
5.3.4 通信
ホストネットワークの一時的障害が発生し,サービス性能が一時的に低下することがあった.コンテナサービスとしては安定的に動作していたため,問題に気づくのが遅れたことがあった.ホストネットワークレベルの監視などを増やす必要がある.
Kubernetes内のCoreDNSの障害が発生し,Kubernetes内でServiceの名前解決ができなくなることがあった.CoreDNSのstatusとしては正常動作している,毎回名前解決ができない訳ではない,など原因が不明であり,NodeLocal DNSCacheを導入することで解決した.
5.3.5 セキュリティパッチ
運用期間中には多くの脆弱性が報告され対策が必要になった.Apache Log4jの脆弱性(CVE-2021-44228)はその代表であり,データハブもその影響を受けた.具体的には,データハブで動作しているPodのシステムソフトウェア調査を行い,脆弱性対応の必要性の有無の確認作業を行った.実際にElasticsearchとKibanaの更新作業を行った.
5.4 内省と後続システムに向けて
5章の議論を通しての内省として次の3点を記す.1つ目は,パブリッククラウド上に構築したバックアップクラスタは,災害対策という観点のほかに,本番サイトでのホストOSやKubernetesの更新を事前検証ができるという利点があった点である.ただ,バックアップクラスタはKubernetesの導入に別のツールを利用*8したことにより,バックアップ側で起きなかった問題が,本番サイトで発生することがあった.このような観点ではできる限り同じ環境を用意することが望ましいと考える.
2つ目は,3年間の運用を通して障害やエラーなどのSlack通知が効果的だった点である.省工数で運用する都合もあり,日々管理ページや管理アプリにアクセスするのは難しく,通知に基づいてログや実際のシステムを確認するという順になりがちであった.実際のオフィスではディスプレイに常時ダッシュボードを表示するなどのアプローチも考えられるが,コロナ禍でリモート勤務が増えると,常に表示し続ける環境を用意することが困難であるため,その点でも通知機構は有用性が高いと考える.
3つ目は,仮想マシンのオーバーヘッドに関するリスクを考慮し,データハブをベアメタルサーバー上に構築したが,Kubernetesの更新に際してのインシデントの際も,仮想マシン上であればダウンタイムを最小にできたと考えられる.
以上の内省にたつと,様々な後続システムが構想される中で,ここでは,次の3点を記す.
- ・個人の意思決定に基づく同意管理は,多様な要求を考慮する必要があるため俊敏性を高める必要があり,データハブの機能とPLR基盤の機能はUX含めた一貫性のあるアーキテクチャのもとに構築する.
- ・ハイブリッド構成はTCOを考慮すると本支援事業の目的には合致した構成ではなかったので,パグリッククラウド上にマネージドサービスとセルフマネージドサービスのバランスのもとに構築する.
- ・データを提供するという視点に欠けていたので,データの2次利用という利用目的の観点からのデータマネジメントを組み込む.
6. まとめ
本稿では「Society 5.0実現化研究拠点支援事業」において構築されたPLR基盤に対して個人情報を含むデータを蓄積するためのデータハブに関して述べた.本データハブは,高品質のデータを2次利用目的で蓄積するために必要な処理を実行する環境であり,マイクロサービスアーキテクチャに基づいて構築した.3年間の運用期間で得られたプラクティスは我々が次のシステムを構築するに際して十分なインサイトを与えてくれた.現在,後続のシステムを構築中であり,そこでのプラクティスが得られ次第,本誌で発表する予定である.
謝辞 原稿を注意深くお読みいただき適切な助言をいただいたことに対して査読者の皆様に感謝します.本研究活動は,文部科学省によるSociety 5.0実現化研究拠点支援事業(グラント番号:JPMXP0518071489)によって行われたものである.
参考文献
- [1] 八木康史:パーソナルデータの安全安心な利活用を目指して:ライフデザイン・イノベーション研究拠点,生産と技術,Vol.73, No.3, pp.72–74 (2021).(オンライン),入手先〈https://cir.nii.ac.jp/crid/1520572360038521728〉
- [2] 日本国国会:個人情報の保護に関する法律(平成十五年法律第五十七号) (2023).
- [3] Falque-Pierrotin, I.: Guidelines on the right to data portability (2017). Adopted on 13 December 2016, As last Revised and adopted on 5 April 2017.
- [4] 八木康史:特願2021–553675:パーソナルデータ流通管理システムおよびその方法.優先権主張日2019/10/31.
- [5] 厚生労働省:医療情報システムの安全管理に関するガイドライン第6.0版 (2023).
- [6] 経済産業省:医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン (2022).
- [7] JIS: JIS Q 27001: 2014(ISO/IEC 27001: 2013):情報技術–セキュリティ技術–情報セキュリティマネジメントシステム–要求事項 (2014).
- [8] Kubernetes Authors: Kubernetes, Cloud Native Computing Foundation (online), available from 〈https://kubernetes.io/〉
- [9] Rodger, R.: The tao of microservices, Simon and Schuster (2017).
- [10] Istio Authors: Istio, Cloud Native Computing Foundation (online), available from 〈https://istio.io/〉
- [11] Fluentd Project: Fluentd, Cloud Native Computing Foundation (online), available from 〈https://www.fluentd.org〉
- [12] Elastic: Elasticsearch, Elasticsearch B.V. (online), available from 〈https://www.elastic.co/elasticsearch〉
- [13] Argo Project Authors: Argo CD, The Linux Foundation (online), available from 〈https://argoproj.github.io/cd/〉
- [14] Prometheus Authors: Prometheus, The Linux Foundation (online), available from 〈https://prometheus.io/〉
- [15] Grafana Labs: Grafana, Grafana Labs (online), available from 〈https://grafana.com/〉
- [16] Kustomize.io: Kubernetes native configuration management, Kustomize.io (online), available from 〈https://kustomize.io/〉
- [17] Docker Inc.: Swarm mode, Docker Inc. (online), available from 〈https://docs.docker.com/engine/swarm/〉
- [18] ASF: Apache Mesos, The Apache Software Foundation (online), available from 〈https://mesos.apache.org/〉
- [19] 坂下幸徳:マルチコンテナオーケストレーションを用いた大規模コンテナ環境の設計と運用,情報処理,Vol.62, No.8, pp.d33–d56 (2021).
- [20] Truyen, E., Van Landuyt, D., Reniers, V., Rafique, A., Lagaisse, B. and Joosen, W.: Towards a container-based architecture for multi-tenant SaaS applications, Proceedings of the 15th International Workshop on Adaptive and Reflective Middleware, ARM 2016, New York, NY, USA, Association for Computing Machinery, (2016). (online), DOI: 10.1145/3008167.3008173
- [21] CIS: The CIS Benchmarks, The Center for Internet Security, Inc. (CIS® (online), available from 〈https://www.cisecurity.org/cis-benchmarks〉
- [22] 松村泰志,武田理宏,真鍋史朗,小西正三,宮内 恒,坂田健太郎,杉下滉紀,東 博暢,五味健太郎,片岡宏輔,高石友博,高木かなえ,山内 玲:医療情報銀行を中心とするPersonal Health Recordのアーキテクチャとその試行,医療情報学,Vol.41, No.1, pp.17–28 (2021).(オンライン),DOI: 10.14948/jami.41.17
- [23] DAMA International:データマネジメント知識体系ガイド第二版,日経BP (2018).
- [24] 橋田浩一:分散PDSによる個人データの自己管理,人工知能,Vol.28, No.6, pp.872–878 (2013).
- [25] Ohmura, K., Zhai, H., Katayama, S., Kawai, S., Kashiwagi, K., Umakoshi, K., Yosuke, Y. and Kimura, T.: Next-generation Data Hub for Secure and Convenient Data Utilization across Organizational Boundaries, NTT Technical Review, Vol.20, No.4 (2022).
- [26] Risco, S., Molt´o, G., Naranjo, D. M. and Blanquer, I.: Serverless workflows for containerised applications in the cloud continuum, Journal of Grid Computing, Vol.19, No.20, pp.1–18 (online), DOI: 10.1007/s10723-021-09570-2 (2021).
- [27] AWS:メモリと計算能力はAWS Lambdaのコストにどのように影響しますか?,Amazon Web Services, Inc.(オンライン),入手先〈https://repost.aws/ja/knowledgecenter/lambda-memory-compute-cost〉(参照2024/06/29). AWS re: Post.
- [28] Technical Committee: ISO/TC 262: ISO 31000: 2018: Risk management ― Guidelines (2018).
脚注
- *1 ここでは,PHRデータやPLRデータをPLRデータに統一して用いている
- *2 たとえば,個人はビデオを用いた説明を閲覧できる
- *3 一般社団法人データビリティコンソーシアムhttps://cds.or.jp/
- *4 Ubuntu18.04LTS.2022年末に20.04に更新した
- *5 「管理者向けアップローダ運用マニュアル」と「利用者向けアップローダ利用マニュアル」
- *6 しかし,運用期間を通してこの方法を採ったアプリケーションはなかった
- *7 本データハブでも作業そのものはローリングアップグレードで行っているが,サービス停止時間を確保して行った
- *8 本番サイトはkubeadm,バックアップクラスタ側はKubesprayを利用した

harumoto@ids.osaka-u.ac.jp
1994年大阪大学大学院基礎工学研究科博士前期課程修了.同年同大学大学院工学研究科情報システム工学専攻助手.1999年同大学大型計算機センター講師,2000年同大学サイバーメディアセンター講師,2004年同大学大学院工学研究科助教授,2007年同准教授.2017年同大学データビリティフロンティア機構教授を経て,2024年より同大学D3センター教授となり,現在に至る.博士(工学).データ利活用プラットフォーム等の研究に従事.電子情報通信学会,日本データベース学会,IEEE(CS)各会員.

kan@lwing.tech
2003年東京工業大学知能システム科学専攻修士課程修了.2003年よりNEC中央研究所にて分散ストレージ,省電力クラウド,リソース分離型コンピュータアーキテクチャの研究開発および事業化活動に従事.2017年~2018年スタートアップ企業で最高技術責任者(CTO)として従事.現在,2017年に創業した合同会社リトルウイング代表社員,2019年に創業した株式会社Diagence代表取締役社長を兼務.情報処理学会2013年度山下記念研究賞受賞,情報処理学会会員.

yasuhiko.yokote@riken.jp
1988年3月慶應義塾大学工学研究科電気工学専攻後期博士課程修了.工学博士.同年4月からソニー・コンピュータサイエンス研究所にて世界初のリフレクション機構を備えたオブジェクト指向OSの研究に従事.1996年4月から当該OSをソニー商品に組み込むべくソニー株式会社に転籍.2004年4月から株式会社ソニー・コンピュータエンタテインメント出向.2008年4月からソニー株式会社CELLアプリケーション開発センター長兼務.2009年3月からJSTディペンダブル組込みOS研究開発センター出向.2010年4月からサイバーアイ・エンタテインメント株式会社CDO.2019年6月から国立研究開発法人理化学研究所にて開放系総合信頼性の研究に従事.ACM,IEEE(Computer Society)会員.

大阪大学基礎工学部大学院後期課程,1986年3月修了.同年同大学・助手.1989年同大型計算機センター・講師.1991年4月同助教授,1998年4月同教授,2000年4月同大学サイバーメディアセンター副センター長,2005年8月 同大阪大学センター長,2007年8月 同副センター長,2008年4月から3年間 情報通信研究機構大手町ネットワーク研究統括センター センター長/上席研究員.2011年4月サイバーメディアセンター教授.2015年より2022年,センター長.2023年3月,退職,同年4月より青森大学ソフトウェア情報学部教授.現在に至る.大阪大学名誉教授.工学博士.電子情報通信学会(H22フェロー),情報処理学会(H22フェロー),IEEE(Computer Society).本会フェロー.

1986年京都大学工学研究科情報工学専攻修士課程修了.2020年総合研究大学院大学(国立情報学研究所)博士課程修了.博士(情報学).1986年より松下電器産業株式会社(現パナソニック)本社研究部門にてシステムソフトウェアの研究開発に従事.1991年~1993年マサチューセッツ工科大学客員研究員.2008年~2012年パナソニック株式会社オートモーティブシステムズ社常務CTO兼海外ビジネスユニット長.2021年より大阪大学ライフデザインイノベーション研究拠点戦略室長・産学共創教授.

1982年電気通信大学通信工学科卒業 同年松下電器産業株式会社(現パナソニック)入社 1983年より化合物(GaAs)系半導体デバイスの研究開発に従事.2019年より大阪大学大阪大学ライフデザインイノベーション研究拠点・特任研究員.

1985年大阪大学大学院基礎工学研究科修士課程了.工学博士.1985年三菱電機(株)応用機器研究所/産業システム研究所研究員.1990年大阪大学助手,同講師,同助教授を経て,2003年大阪大学産業科学研究所教授,2012年 同研究所長,2015年8月から2019年8月まで大阪大学理事・副学長研究,産学共創,図書館担当)を経て,同年8月より産業科学研究所教授,現在,JST創発的研究支援事業およびJST先端国際共同研究推進事業およびJST経済安全保障重要技術育成およびAMED臨床研究等ICT基盤構築・人工知能実装研究事業の各プログラムオフィサー.2018年からは,パーソナルデータの利活用により,身体の健康,心の健康,社会的健康(コミュニケーション),環境の健康を基軸にして輝く人生(高いQOL)をデザインし,様々な技術革新と社会経済環境の変革を大学から発信することを目指す,ライフデザイン・イノベーション研究拠点本部長,データ取引所MYPLRを運用する(一社)データビリティコンソーシアム代表理事.Asian Federation of Computer Vision Societies(Vice President).本会フェロー.

2013年東京都市大学大学院工学研究科博士前期課程修了.同年日本電気株式会社入社.SDN/NFVシステムの研究/SW開発,クラウドへのLift&Shift,IoT・Web/ECシステムの基盤設計・運用保守等を経て,現在,教育研究システムのPJ管理,スマートキャンパス/シティ・Society5.0の推進に従事.電子情報通信学会(IEICE),プロジェクトマネジメント協会(PMI),各会員.

1993年日本電気ソフトウェア株式会社入社後,1997年日本電気株式会社へ移籍.官庁系システム開発/運用保守,OAシステム構築/運用保守等を経て,現在,教育研究システムのPJ管理,Society5.0の推進に従事.
採録日 2024年8月27日