クエリに対応した事前の要約を伴う大規模言語モデルによる企業事業概要生成
Generating Corporate Business Overviews Using Large Language Models with Query-Responsive Pre-Summaries
1. はじめに
経済および金融の分野において,大量かつ高頻度で生成されるテキストデータの処理は,企業の経営や投資判断における重要な要素である.たとえば,東京証券取引所に上場している企業は,プライム市場,スタンダード市場,グロース市場,TOKYO PRO MARKETを含め,総計3933社(2023年末時点)[1]にのぼり,報道されるニュースや企業から発信される決算情報は非常に大規模となる.これらの情報を迅速に解析し,適切な意思決定を行うためには専門的な知識と多くの時間が必要とされている.それに伴い自動化されたデータ処理のニーズが高まっている.
具体的には,多量のテキストデータから機械的に必要な情報を抽出し,整理・構造化を行うことが求められている.特に,ニュースや経済情報,市場で開示される企業情報から,いち早く情報を分類・抽出[2]-[8]することが必要とされてきた.そのため,様々な自然言語処理(NLP)の基礎タスクが重要視されている.
2018年にGoogleが発表したBERT [9]などの先進的なNLP技術は,このような状況に対応するための有効な手段として登場した.様々な自然言語処理タスクが人間以上の精度で解決されるようになったため,自然言語処理の基礎タスクである情報分類や固有表現抽出などを利用することで情報抽出を行うものや,テキスト間の因果や含意関係を見出すものなどが提案され,情報の構造化に関する研究が進んだ.
最近では,言語データを扱う生成AIモデル[10]-[14]が相次いで発表され,特に2023年にOpenAIからChatGPTが発表されたことによって,企業情報を高速に処理する課題に生成AIモデルを利用することの注目が集まっている.生成AIモデルのなかでも,大量のテキスト情報で学習された大規模言語モデル(LLM)の利用が特に期待されている.
LLMは,公開ウェブデータ等から学習した知識を用いて,生成モデルとして文章を生成することを中心に構成されている点と,大規模構造をもつことでの精度のよい出力を得られる点が,これまでのAIモデルと異なる.そのため,LLMを用いることで情報の構造化にとどまらない,高度な要約文の生成やユーザからのクエリに応じて生成結果を変えるインタラクティブな機能を持たせることが可能とされている.具体的なモデル(一部サービス含む)として,ChatGPT [10],Claude [12],Gemini [11]のようなAPIサービスとして公表されているものや,Meta社のLlamaシリーズ[13], [14]や東京工業大学が開発したSwallow [15]などの公開モデルとして公表されているものなど多様なモデルが知られている.
これらのモデルを利用することで,経済や金融の領域における,ニュースや開示情報などのテキストデータの扱いを大きく転換できると考えられ,企業情報,金融・経済情報への研究開発が熱心になされている.
当該領域におけるLLMも個別に開発されていて,アメリカのブルームバーグ社とジョンズ・ホプキンズ大学がBloombergGPT [16]を発表している.国内では,Stockmark [17]や日経[18]が独自LLMの開発を発表している.
このように金融・経済情報におけるLLMの開発が行われているが,独自のLLMの開発は主に大規模計算機リソースを要する開発プロセスを経ているため,非常にハードルが高い.このプロセスには相当な投資と技術的な専門知識が必要であり,多くの企業にとって障壁となっている.また,運用や改善の過程でも,継続的な学習のリソース確保や投資の課題や生成AIによるハルシネーションなど,多くの企業が技術的挑戦やその実装・運用の難しさに直面している.
企業固有のデータやナレッジを使い,企業が直面する具体的なビジネス課題に対し,生成AIのポテンシャルを最大限に活用することが求められる.独自のLLMを作ることが行われる一方で,検索拡張生成(RAG: Retrieval Augmented Generation)と呼ばれる技術も提案[19]されている.このアプローチでは,生成AIモデルの開発自体を避けることができ,既存のAPIサービスを利用しつつ,企業固有のデータとナレッジを組み込んだ生成結果を得ることができる.
本稿では,大規模言語モデルを利用したRAGによる企業の事業情報の要約を実施する.事業内容の要約においては様々なトピックが必要となり,大規模かつ多様なテキストデータが必要となる.一方で,データ間で必要となる情報の濃淡が異なることなどから,適切なデータの加工や選定が必要となる.
以降の章では,生成AI(本稿ではLLM)の導入や運用に関する課題とその解決にむけて取り組んだ内容を共有する.具体的な要約の生成の取り組みの成果を通して,実務的には,RAGによる要約を作る方法として実施が容易と考えられるため,このアプローチにより,生成AIがもたらす可能性をより多くの企業が活用できるようになることを期待する.
2. 関連研究・事例
本研究では検索拡張生成(RAG:Retrieval-Augmented Generation)と呼ばれる技術を中心に扱う.RAGは2020年にPatrick LewisらによってRetrieval-Augmented Generation for Knowledge-Intensive NLP Tasksとして,提唱された.大規模言語モデル(LLM)と外部情報源の検索技術を組み合わせることで,テキスト生成の精度と関連性を向上させる手法である.具体的には,ユーザからのクエリに基づいて,関連する外部知識から情報を検索し,その情報を入力として与えたうえで,LLMが回答を生成するというプロセスとなっている.
この技術は,特に情報が頻繁に更新される金融や経済の分野において重要な意味を持つ.金融情報サービスは,経済・市場動向や企業情報が日々更新されるため,過去のデータだけでは不十分な場合がでてくる.しかし,LLM自体をデータの更新のタイミングで定期的に再構築することは,非効率かつ実行が困難となる.RAGを活用することで,追加的なデータを学習することなく,最新の市場データやニュース記事から得られる洞察を反映した生成が高速かつ低コストで実現できる.
RAGの定義や分類は,様々に整理されている[20]が,ここでは基本的な方法としては,Lewisらの提唱したRAG-Sequence Modelの表式を使うと,次のように定式化される.\[ \begin{split} & p_{RAG}(y|x) \\ & \quad = \sum_{z \in top_k(p( \cdot |x))} p_\eta (z|x)p_\theta (y|x,z)\\ & \quad = \sum_{z \in top_k(p( \cdot |x))} p_\eta (z|x) \prod_i^N p_\theta (y_i|x,z,y_{i - 1}) \end{split} \](1)
xはクエリ,zは外部情報源となるデータ,yは最終的な生成物(ここでは系列となる)である.このRAGシステムはpηは検索モデルで,クエリに応じたデータzはtop-kで選ばれたデータを使い,pθの生成モデルに与えられて生成する.
具体的なRAGのプロセスは図1および下記の手順のようになる.図は基本的な概念図であり,一般にデータが蓄積されたデータベース(外部情報源)があり,入力されたクエリに応じて検索モデルが適切なデータを選ぶ.そして,その選ばれたデータをもとに当初のクエリに基づき,生成モデルで生成が行われる.
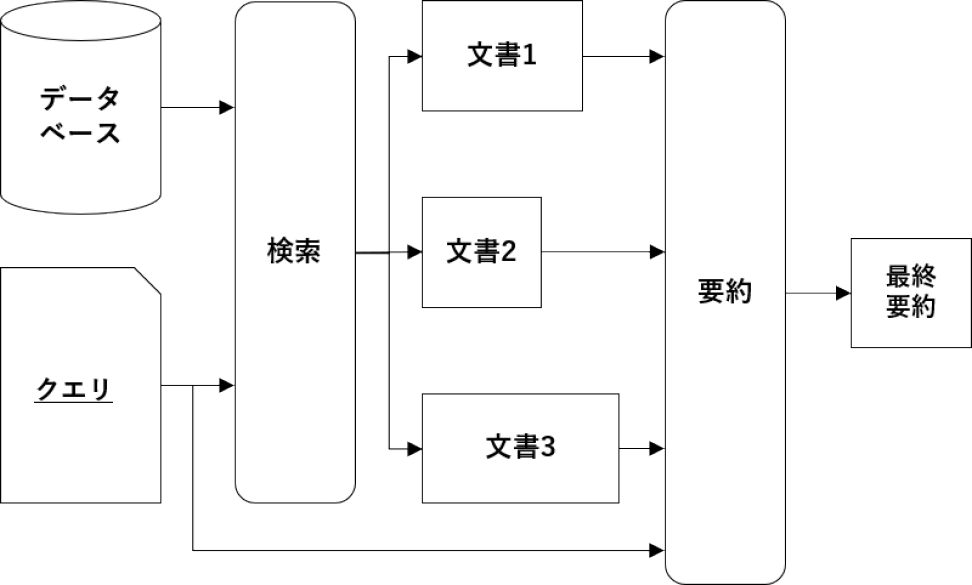
Fig. 1 Schematic view of the RAG process from inputting query to generation.
この一連の流れは,AIが単に学習した情報を再利用するのではなく,与えられた新たな情報をもとに適切な回答を生成することが考慮されている.
RAG技術は,検索と生成の2つの重要な側面がある.特に,最終的な精度を高めるためには,LLMに対するプロンプトエンジニアリングだけでなく従来の検索システムで考えられていたチャンキング[21]-[23],要約[25]やクエリ拡張[26], [27]といった方法で生成物の精度を上げる方法が検討[20]されている.
チャンキングは長いテキストを分割したチャンクと呼ばれる単位で検索を実施し,テキスト全体から回答に必要な個所を抽出することで処理するテキスト量を削減したり,データのノイズを除去することで精度をあげる方法である.長いテキストを適切な長さの文や節単位で処理できるような加工が検討されている[21]-[23].同様に,元データを要約したものを用意し,データ量を削減したり,均一化したうえで検索を実施するSummary Embeddingsもある[25].これは,前述のチャンキングと合わせて,チャンキングした内容を要約する方法もとられる.また,クエリ拡張[26], [27]では,RAGシステムに与えられるクエリを意味的に分解し,複数のクエリまたは別の表現のクエリに変換し,それらに対して検索を実行して,性能を向上をさせることである.
つまり,RAGではデータをどのように選定するかが重要となるため,あらかじめデータに加工を施したり,高度な検索モデルを構築する方式がよく検討される.これらの方式を適用することで,精度が改善することは報告されている[25]-[27]ものの,データやケースに応じて,検討する必要がある.また,この検索結果をどのようにLLMに入力するかというプロンプトエンジニアリングも,システム全体の成功を左右するため,工夫が必要となる.
3. 株式会社ユーザベースでの生成AIの取り組み
本稿の内容に関連して,ユーザベースではRAG技術を使った生成AIの取り組みがある*1.RAG技術を使うことにより,独自のデータを簡易にLLMに扱わせることができ,非エンジニアが自発的に多くのプロトタイプやアイデアを創出している.しかし,実際のところ開発や運用にむけて細部では専門家の知見が個々のケースで必要になることも多いことが課題である.
ユーザベースは,上場企業からスタートアップまで様々な属性をもつ企業の情報を多角的な視点で知ることができる経済情報プラットフォーム「スピーダ」を運営している.経済や金融市場での決算情報だけでなく,ニュースなどの速報性の高いデータも持ち合わせているため,LLMで扱うことになるデータの更新頻度は高い.そのため,生成AIに最新の事実に基づいた回答をさせるために,データの更新頻度に合わせたモデルの構築は非効率と考えている.一方で,多量の企業情報の資料から要点を抽出し,企業概要の把握や営業の効率化のために利用するユーザからのニーズは高い.
これらのニーズへの生成AIの利用として,いくつかの取り組みを行っている.
AI決算サマリー*2
LLMを用いて企業の決算情報を要約し,インサイトを抽出するサービスを提供している.通常は,企業の事業状況の理解・把握には時間がかかり,同時にニュースなどが事業と関連するかを判断することも容易ではない.決算資料や有価証券報告書には,財務数値だけでなく企業の状況,リスクや展望などが定性的に記されている.そのため,企業の置かれる状況や背景をLLMの技術によって整理している.
AI企業課題サジェスト*3
営業先となるターゲット企業が抱える可能性のある課題を特定し,営業プロセスを効率化することを支援している.具体的には,企業情報や自社アナリストが作成した業界レポートなどをもとに,LLMを利用することで,企業の潜在的な課題の内容とその根拠を提案する.現在は,上場企業4000社だけでなく,非上場企業約2万社も対象となっている.
AIセールストーク自動生成*4
営業提案先企業ごとに最適化されたセールストークのスクリプト構築を支援する.提案先企業がもつ事業の課題と,自社プロダクトが与える便益から,最適な営業スクリプトをLLMに生成させることを行っている.
これらのサービスでは,生成AIを利用し,会社が有するデータを生成AIに与えてテキストを生成する方式で解決を図っている.しかしながら,上記の取り組みのなかでは,LLMに多種多様なデータを入力させる点で,主に質と量に由来する課題が抽出された.
具体的な課題として,異なる形式のデータを混在させた入力が挙げられる.たとえば,決算に関する資料,アナリストによるレポート,プロダクト説明文など,異なるソースからのデータを組み合わせて使用する際,各データの文体やフォーマットの違いが,生成結果の精度の低下を招くことである.たとえば,紹介したケースにおいてはレポート系の整った文体と比較し,会話文で構成されるアナリストとの質疑応答のデータや,自社製品のプロダクト説明文として,性能が箇条書きで構成されるようなデータが入力されることになる.結果として,生成結果に直接話法のような形式が混ざったり,意図せず箇条書きの文体で出力されるなど,入力したテキスト形式が影響を与えてしまうことがあった.
2つ目の課題として,テキストデータのサイズに起因して,モデルの制限や精度の低下が挙げられる.大規模言語モデル(LLM)では,入力可能なテキスト長がトークン数によって設定されており,適切なデータが検索によって選ばれたとしても,そのすべてをモデルに入力することができない状況が生じる.この問題は,特に長文のテキストや大量のテキスト情報を要約する必要がある場合に顕著である.さらに,入力データ間でサイズに格差がある場合,これがバイアスを生じさせ,最終的な生成物の精度を低下させる原因となる.そのため,入力データのサイズを均一化することも重要な課題である.
このような異なるデータフォーマット,データサイズの課題を解消するために,入力データをあらかじめ要約し,データの特徴を均一化する技術が有効であると考えられる.実際に,事前に要約を用いる方法[24], [25]があり,異なるソースとなるデータやチャンク化されたデータを統一的な形式と文体に変換し,同程度の質・量データとすることで,出力の品質向上を報告[25]したものもある.さらに,この方法ではデータのノイズ的な情報が削減されるため,LLMのトークン数制限に対する課題も緩和される.期待されることとして,より多くの関連情報をモデルに供給できるようになり,生成されるテキストの情報密度と精度が向上する.
以上のアプローチにより,異なるデータソースからの情報を効果的に統合し,精度の高いテキスト生成を実現する点に課題があることから,本研究ではこの点における解決を目指す方式の提案を行う.
4. 事業概況サマリの生成
前章で紹介した我々の取り組みでは,決算内容や課題の要約といった,要約したい範囲があらかじめ定まったコンテンツ生成を行ってきた.本稿では,決算情報だけでなく複数のデータを利用して,同じデータに対して複数の観点で要約を生成することを取り組む.その題材として,企業の概況を知る要約文の生成を試みる.広範なデータと視点から企業の概要を知ることにユーザからニーズがあり,その観点として「環境」「課題」「展望」「強み」が挙げられ,これらを使い要約を生成する必要がある.本稿で紹介する内容は,研究開発段階において注力した部分的な側面のみをとり挙げていることに注意していただきたい.
4.1 利用データ
事業概況サマリにおける利用データとしては,企業が開示する情報や自社で組成したデータを利用する.詳細の内訳は次のとおりである.データの期間は2023年の1年間のデータである.
有価証券報告書
本稿では,上場企業が決算年度の最終期に開示する有価証券報告書を利用する.有価証券報告書には,貸借対照表,損益計算書,キャッシュフロー計算書などの財務諸量が表形式でまとめられているが,ここでは,第2【事業の状況】で記載される「1.経営方針,経営環境および対処すべき課題等」「3.経営者による財政状態,経営成績およびキャッシュ・フローの状況の分析」の項目の文章を利用する.これらの項目には,決算数値とともに事業の現況や課題や展望がテキストとして記載されているため,表形式の財務情報の読取りを直接行う必要がなく,概況の把握には有用と考えられる.
データはEDINETの提供するXBRLから該当箇所を抽出し,タグ情報を取り除いたものをテキストデータとして保持する.2023年に開示された有価証券報告書を使うため,決算期としては,2022年のことも含んでいる.データの特徴として,テキストの長さが企業ごとに大きく異なり,大手の企業の内容だとLLMへの入力制限を超えるものもあるため,データ量への適切な対処が必要となる.
決算説明会の書き起こしデータ
決算説明会での経営層からのプレゼンテーションの内容やアナリストからの質疑応答などのやりとりが文字起こしされているテキストデータである.上場企業のすべてではないが,投資家向けの情報として公開している企業がある.ここでは,通期の決算説明会の書き起こしデータを取得して利用する.
プレゼンテーション部分は,対応する期の決算説明となるため,有価証券報告書の内容と類似した内容である.一方で,質疑応答部分では,実際にアナリストととのやり取りされた会話がテキストとなっているので,あいさつ,言葉のつまりのほか話者が複雑に入れ替わる場面が存在する.そのため,レポート形式となるテキストとは大きく異なっている.受け答えは基本的に’Question(Q)’→’Answer(A)’のやりとりで構成されるが,場合によってはQ→AA,Q→QAなどもあり,ここでは,QからAを挟んで,次のQまでを1つの質問としてチャンク化したデータの整形を行っている.
4.2 提案手法
事業の概況にかかわる観点では「環境」「課題」「展望」「強み」の4つの観点で要約文を生成する.
本件における課題は,テキストデータは文章量がデータの種類や企業によって様々であり,そのままモデルに投入することでは,テキスト間の文章長に格差があることや複数のテキストを入力すると入力上限に達することで,ケースによって情報の濃淡が異なってきてしまう.そのため,有価証券報告書と決算説明会書き起こしデータを事前に要約し,文章長を短くしたものを,LLMに投入し最終的な要約文を生成する多段階の方法を検討する.
提案するプロセスとして,データの均一化が目的だけでなく,観点の抽出を行う事前の要約を取り入れる.具体的には,クエリに応じた要約と呼び,元データとなるドキュメントの均一化のために,単にLLMによって要約を施すだけではなく,データを与えたときに,同時に与えられる要約の観点である「環境」「課題」「展望」「強み」に関する情報を残す要約を施すことである.これによって,事前の要約で答えてほしい情報が欠落してしまうことを防ぐことが目的である.
提案手法の全体プロセスは図2のとおりである.クエリに回答するために必要な部分を要約することを各データごとに行う.これにより,データ長をそろえるための要約と,その要約によって,クエリに回答するための情報が削除されない処理を行っている.

Fig. 2 Schematic view of the proposed process. The part in the rectangle is the process for pre-summarization.
具体的な提案方式の表式としては,下記のようになる.\[ \begin{split} p_\eta (d|x) & = D_{dx}\\ p_{RAG}(y|x) & = \sum_{d,d'} p_\eta (d|x)p_\theta (d'|x,d)p_\theta (y|x,d') \end{split} \](2)
ここで,xはクエリ,dはクエリに紐づくデータであり,Dはクエリxにデータdが紐づくときに1,そうでないときに0となる行列である.この行列Dは適切なデータを選ぶモデルという点で,原典のモデルの検索pη(d|x)に対応する.一般には,ドキュメントの埋め込み表現をベースにして,データを検索するシステムとすることが多い.本稿では,ある企業Xの要約文に必要なデータは,Xの有価証券報告書とXの決算説明会書き起こしデータと定まるため,データが端的に定まる状況にある.
本稿の検証では,与えられるクエリxは企業Xと観点Tを含むテキストであるが,文章は定型化してあるため,企業名Xと観点Tを実質的には明示的に与えているクエリとなっている.*5
次に,pθ(d′|x, d)によって,データdに対して,クエリに回答するために必要な情報を含んだ形での要約が行われる.最後に,得られた要約データd′をすべて使って,クエリに応えるための回答文(最終的な要約)yを得ることになっている.
具体的なプロセスとしては,次のとおりとなる.
提案手法におけるプロセス
・企業Xと観点Tをさだめる.ここで,Xは企業名,Tは「環境」「課題」「展望」「強み」から選ぶ.
・企業Xに紐づくデータをデータベースから選出する.本件においては,有価証券報告書と決算説明会書き起こしデータである.
・上記データを観点Tに応じた事前要約でデータの均一化を施す.
・事前要約したデータ群を使って,企業Xの観点Tにおける要約文の生成を実施する.
本提案手法における重要な点は,図の破線の四角で囲まれた部分である.クエリに含まれる観点Tに応じた要約によって,最終的な生成物の質を向上させることである.
5. 実験
事業概況の要約文を生成する提案手法を試行する.提案するシステムでは,Azure OpenAI のgpt-4(2024年5月時点)を利用する.2021年9月までのデータで学習されていて,3万2768トークンの利用が可能である.
前述のとおり,有価証券報告書や決算説明会書き起こしデータを利用するが,データの形式がデータ間で異なることや,企業ごとに文章の長さが異なり,入力データが不均一になっていることが課題として挙げられる.そのため,gpt-4を利用して,レポートのような文体と口語が混ざる文体のテキストデータを事前要約することでデータの成形を行う.事前要約によるデータの成形では,表1のようなトークン数となるようにデータを加工する.質疑応答のテキストは先述のとおり,質問から回答までを1つのチャンクとして扱っている.
Table 1 token length of summarized text.

Table 2 Comparison between generated texts.

LLMで扱うテキストサイズが入力制限を超えるものについて,入力制限である3万トークンでデータを分割する方式をとっている.この分割したデータは後述する要約で最終的に1つのデータにまとめられる.
各プロセスにおいて,内部的に構成しているプロンプトは下記のとおりである(図2のクエリ番号に対応).事業概況を生成する観点として,事業の「環境」「課題」「展望」「強み」があり,観点ごとに概況文の生成を行う.
図2におけるクエリ①においては,企業名Xや「環境」「課題」「展望」「強み」の各観点Tをクエリの一部として与えている.
まず,プロセスとして,企業Xと観点Tを定める.これを用い,下記の入力を構成し,システムへのクエリとする.
クエリ①における入力内容
X社に関して,与えた各資料から事業のTの要約を完成させてください.
このクエリ中の企業Xに基づいて,企業Xに紐づく有価証券報告書や決算書き起こしのデータが選ばれる.
次に,企業名Xと観点Tを用いて,クエリ②が生成され,選ばれたデータに対し,抽出したい観点の情報を残して要約を行うように事前要約が行われる.その際に与えられるプロンプトが下記である.
クエリ②における入力内容
以下の内容で,X社の事業のTを要約するために必要な内容を,Lトークン以内の文章に要約してください.(以下,各テキストデータを挿入)
クエリ②での事前要約によって,表1にあるようなデータに成形され,データの均一化と観点が抽出された形での要約が行われる.
クエリ③では,事前要約が行われたテキストを使って,最終的な要約文を作成する.
クエリ③における入力内容
このX社に関する下記の文章を使って,X社の事業のTについての要約を完成させてください.(以下,事前要約された各テキストを連結して挿入)
クエリ②,③におけるテキストが,LLMへの入力制限長をこえてしまった場合は,分割の単位が入力制限以下となるまで,当分割する.分割したテキストごとに要約を実施し,これら文章群を使って,当初のクエリを実施する.
上記,クエリ対応した事前要約の提案手法との比較として,事前要約は行うが「環境」「課題」「展望」「強み」といった観点を指定せずに,与えた文書を表1の長さになるように,資料を単に要約させること(以下,単純要約)を行う.つまり,クエリ②の部分で与えるプロンプトとして,下記のクエリ②'としたものとの比較を行う.そのほかのクエリ①,③は企業X,観点Tを含む同じものを利用する.
クエリ②'における入力内容
以下の内容を,Lトークン以内の文章に要約してください.(以下,各テキストデータを挿入)
実験では,クエリに対応した事前要約と単純要約を実施する.ただし,生成文を数値的に比較することは難しいため,定性的な評価を行う.
6. 結果
提案手法であるクエリ対応する事前要約を行うケースと単純要約を行うケースでの生成文を複数生成した.具体的には,上場企業のうち決算説明会書き起こしデータを公開している30社を選定し,4.1で記述したデータをもとに事業の「環境」「課題」「展望」「強み」の4観点について,生成した.ここでは,日本ハム(2282)における事業の課題についての生成文を提案手法と単純要約の手法の比較として,日本たばこ産業(2914)の事業環境,資生堂(4911)の事業環境を例示した.
日本ハムの例では,単純要約では,財務数値が中心に記述され,課題としては財務数値の改善などを語る内容となっている.しかし,提案手法では,財務的な話題は少なく,事業を取り巻く具体的な課題とその理由を提示できており,より妥当な事業課題のサマリーとして評価されている.
事業課題として生成された結果:単純要約
日本ハムの経営方針は社会貢献を目指し,従業員の幸せと生き甲斐を追求するとともに,高品質の食品を提供することにより,消費者の健康な生活に貢献することを目指しています.その一環として,2023年の中期経営計画では,売上高1兆2,600億円,事業利益380億円などの目標を(中略)加工事業部が若干のマイナスを見込んでいる一方で,食肉,海外,ボールパーク・その他の事業部がプラスを見込んでいると述べています.これらの結果を受けて,企業は今後の事業戦略として,売上高を通期で1兆3,000億円,事業利益を440億円と見込んでいます.
事業課題として生成された結果:提案手法
日本ハムは,社会的な変化や環境課題に対応するために,事業の強化と構造改革,持続可能性の追求,新規事業の育成を進めています.その一方で,原材料やエネルギー価格の高騰,消費者の節約志向による低価格帯へのシフトなどにより,経営環境は厳しさを増しており,(中略)価格高騰や売り場の縮小による在庫管理の問題や,労働コストのうえ昇などが挙げられます.経営課題の解決に向けては,適切な在庫管理やマーケティング戦略,新商品開発,労働力の確保などが重要となります.また,構造改革や事業の再編も視野に入れており,これらの取り組みにより,事業の持続的な成長を目指しています.
日本たばこ産業の例では,提案手法による方法でも事業環境として生成された文には,財務や製品の話が中心となり,事業の環境としては内容がずれている傾向がみられる.これは,有価証券報告書や決算説明会書き起こしでは事業の環境への記述が少なかったことが原因とみられる.
事業環境として生成された結果:提案手法
日本たばこ産業は,「4Sモデル」の追求を通じて企業価値を向上させ,全社利益目標および株主還元の中長期方向性設定を行っています.変化への対応力を高めつつ,大胆かつスピーディーに意識・行動を変革し,各事業の成長戦略を着実に実行することを目指しています.2022年12月期の経営成績は,売上収益が前年度比14.3%増の2兆6,578億円,調整後営業利益が前年度比19.2%増の7,278億円(略)RRP(リスク低減製品)とHTS(加熱式タバコ製品)など,様々なカテゴリーが現在進行中であることを示しています.最後に,企業は,Risk Reduced Products(RRP)の戦略において,Heated Tobacco System(HTS)を優先し,その領域にリソースと取り組みを集中させる方針を堅持していると述べています.
同じく,提案手法による資生堂の事業環境の生成文の例では,事業環境としてのファクターが列挙されているが,その背景や理由などの記述がないものとなっている.
事業環境として生成された結果:提案手法
資生堂の2023年3月24日の有価証券報告書によると,2022年は,中国市場の厳しい状況や新型コロナウイルスの影響緩和や経済活動の正常化が進む一方,中国の断続的なロックダウン,ウクライナ紛争の長期化,資源・エネルギー価格の高騰,ドル高などによる不透明な状況が続いている.(中略)事業のリスクファクターとして大規模なリセッションや地政学的なリスクが挙げられているが,これらは現在の事業計画には考慮されていないとの説明があった.資生堂としては,新型コロナウイルスや地政学的なリスクへの対応,中国市場の厳しい状況への対策を筆頭に,日本市場の成長性回復,持続的な売上成長と収益性の向上,ブランド力強化,投資効率の改善,人財開発の強化等に取り組むことが挙げられている.
30社の4つの観点の生成文の評価には人手による定性的な評価を行っている.評価の観点としては,生成結果の文章の形式や構造の適切性とコンテンツとしての妥当性という点で行っている.
6.1 文章の形式や構造の適切性
文章の形式や構造の適切性では,人手によって,金額の科目,数値,地名や人名などが元データのテキスト中と同一の表現で出現するか,その単語周辺の意味合いと元データが矛盾のない状態にあるかを確認した.全体的に,単純要約では財務数値について言及することが多く,30社のうち4観点とも財務数値を言及しているものは23社あり,財務的な話題に無理やりこじつけた生成結果もうち10件ほどみられた.また,財務が中心であったため,元データに記載された地名や人名などがあまり生成結果に反映されなかった.そのため,適切に参照されていないことがうかがえた.
提案手法や単純要約のどちらでも,言及している単語や表現は与えた入力文章の一部が転載・要約される傾向が非常に高く,誤用などはみられなかった.しかし,提案手法でも生成した120件の文章のうち,企業のセグメント名(事業部名)が改変されてしまうケースや「AIソフトウェア企業である○○」といった修飾表現が意図せずついてしまうケースが6件確認された.部分的な細かな表現でも厳密性はさらなるプロンプトなどでの改善が必要となる.しかし,提案手法においては,財務的な話題へすりかえることなどで記載事実ではない(ハルシネーション)記述が発生したケースは2件と少なかった.
また,単純要約や提案手法ともに会話文調の文章が混ざったり,箇条書きが現れることはなかった.これは,事前の要約において文体が統一されたことによるものが大きく,事前要約をすること自体に生成結果の文調を制御できることが示唆された.また,接続詞が適切に利用されていること,内容が繰り返して記述されることもなく,文章の形式的な点については,生成結果の質として提案手法と単純要約に大きな差はなかった.
6.2 コンテンツとしての妥当性
単純要約では有価証券報告書に記載される財務数値が「環境」「課題」「展望」「強み」に頻繁に参照された.前述のとおり,30社のうち4観点とも財務数値を言及しているものは23社あった.実際に,上に例示した生成結果でも,事業課題や事業環境として財務数値が参照され,事業セグメントごとの売上・利益の増減が頻繁に言及される.一見すると,定量的な表現とともに文章が生成されているように見えるが,適切に文章から抽出できていないことが分かる.
これは,観点Tを定めずに事前要約させたことで,事前要約時点で観点に関する書きわけができていないことから起きる.つまり,有価証券報告書や決算説明会書き起こしデータを事前要約する段階で,事業課題に着眼せずに,与えた文章の事前要約が行われたことで,事業課題の記述に重要な部分が欠落したことによる.特に,単純要約の方法では事前要約時点で財務数値の列挙や理念などを中心に要約されるケースが30社すべてで起き,課題や背景といった観点が事前要約時点で欠落してしまっていることが分かった.
ただし,提案手法でも,財務数値が参照される同様の傾向があり,手法の問題ではなく,データに事業環境などの記載が少なく,抽出が失敗している可能性も考えられる.提案手法でも,うまく生成できたものは事業の課題や環境が定性的な表現として記述されているが,財務だけでなく社会の変化をはじめ,原材料の調達コストや消費者の嗜好など話題が多岐に参照されている.特に,例示した日本ハムの事業課題については列挙するだけでなく,理由が挙げられている点で,求める事業概況のサマリーとなっていると評価した.
6.3 総論としての評価
前述のような細かい点での評価のほかに,文の形式・構造やコンテンツとしての評価を総合して,提案手法と単純要約の生成結果を比較したときに事業概況文としてどちらが妥当かという点で評価を行っている.人手による生成文をチェックした結果として,提案手法が定性的に優位であることがみられた.
有価証券報告書や決算説明会書き起こしデータでは,もともと「課題」「環境」に関する記述は多いため,これらの観点を指定した生成結果は提案手法が優位となった.単純要約が優位となるケースにおいては,提案手法で「課題」や「環境」の列挙ができていても,その企業での主要な「課題」や「環境」を挙げることができなかったケースがほとんどである.そのほか,挙げられていても理由や改善策の記述が乏しく,情報として端的すぎる場合において,「どちらともいえない」と評価されるケースが多かった.
一方で,「展望」「強み」に関する記述は,元データのテキストにおいて企業ごとに記載の量に差があり,記載がほとんどない場合もある.そのため,観点を指定しても,他の観点とうまく書き分けられないケースや元データにも記載のないものに対し,一般論に近い内容を取り上げるケースもみられた.そのため,観点として要約を生成すること自体が難しいものであると考えられるが,それでも一定程度の提案手法の優位性が見て取れた.
最後に,生成結果の評価を行うコストは非常に高く,より効率的な手法の開発が必要となる.具体的には,生成文の評価として,独自表現が重要な情報であるとして固有表現を抽出したり,固有表現間の関係抽出をすることで,人手での確認をより円滑に行う点が期待される.そのため,LLMとは異なるモデルや,これまで行われてきた情報抽出技術を利用した生成文評価の観点を導入することが求められる.
7. まとめ
本研究のまとめとして,Retrieval Augmented Generation(RAG)技術を参考にして企業データの生成を行った際の課題に焦点を当て,形式やサイズが異なる複数のデータソースを用いることによる問題点を明らかにした.それに対して,複数種類の入力データの均一化を図ることと,記述したい観点を整理する事前要約のプロセスを提案した.観点を指定するか否かに関わらず,事前要約自体に生成結果の文体を整える効果があることが示唆された.これは過去研究[24], [25]と整合する.さらに,提案手法として観点を指定して事前要約することで,要約時に重要な情報が欠落してしまうことを防ぎ,最終的な生成結果の質を挙げられることが示唆された.
8. 今後の課題
今後の課題として,事前要約による扱うトークン数の増大への対処,生成結果の自動評価が挙げられる.
まず,事前要約を行うことでテキストを多段的に要約する処理が必要なため,LLMで扱うトークン数が増大することである.これは,APIサービスとして生成AIを利用する際のコスト増加に直結する.改善策として,クエリに応じた適切なテキストデータのチャンク化と,それに基づく部分的な検索の実施が考えられる.このアプローチにより,必要な情報が含まれるチャンクのみを効率的に抽出し,処理コストを削減することが期待される.ほかにも,生成AIモデルとして日本語での性能が良好な大規模言語モデルを自己の環境で利用することでのコストの削減も検討したい.
次に,生成された文の妥当性や品質を機械的に評価することも重要となる.完全な機械的評価と並行して,人手での評価をなくすことは難しく,評価の効率性を高める方式の検討も考えられる.重要単語を固有表現抽出や関係抽出で抜き出すことで,確認する部分をより簡略化したり,どのテキストを参照しているかの透明性を確保するために元データとの類似箇所の判定も運用上必要とされる.自動評価技術の検討に対し,これまで当該分野で行われてきた情報抽出技術が利用されることも考えられるだろう.さらに,生成結果を利用するドメインにおける固有の評価軸もある.たとえば,記述内容の網羅性や深さなどのコンテンツの価値につながる点もあり,ドメインに適用していくうえで専門家と実務家の協同が必要となる.
本研究によって,LLMを利用したデータの統合と高品質な生成にむけた事前要約の知見を示したことで,提案手法がRAGを使った生成の一手法として検討の余地を与えたものである.さらなる改善とその応用の可能性のために,手法の検証を行っていきたい.
参考文献
- [1] 上場会社数・上場株式数(参照値は2023年末),〈https://www.jpx.co.jp/listing/co/index.html〉
- [2] 奥田裕樹,髙橋寛治:ニュース記事からの企業キーワード抽出,言語処理学会第26回年次大会(2020).
- [3] 橋本航,笛木正雄,黒木裕鷹:日本語固有表現抽出におけるBERT-MRCの検討,言語処理学会第28回年次大会(2022).
- [4] 高橋寛治,甫立健悟,奥田裕樹:ニュース記事中の組織名の曖昧性解消,人工知能学会全国大会論文集(2023).
- [5] 田村光太郎,北内啓,高山温:固有表現抽出によるニューステキスト内の企業名抽出,人工知能学会全国大会論文集(2023).
- [6] 田村光太郎:疑似ニュース生成による固有表現抽出タスクのデータ拡張,第19回Webインテリジェンスとインタラクション研究会(2023).
- [7] 田村光太郎:固有表現抽出タスクにおける文章のランダム連結によるデータ拡張,2023-IFAT-153(3)(2023).
- [8] 澤田悠冶,安井雄一郎,大内啓樹,渡辺太郎,石井昌之,石原祥太郎,山田剛,進藤裕之,日経企業IDリンキングのための類似度ベースELシステムの構築と分析,言語処理学会第30回年次大会(2024).
- [9] J. Devlin, M. Chang, K. Lee and K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv: 1810.04805.
- [10] 入手先〈https://chatgpt.com〉
- [11] 入手先〈https://gemini.google.com/〉
- [12] 入手先〈https://claude.ai/〉
- [13] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. LLaMA: Open and Efficient Foundation Language Models. arXiv. /abs/2302.13971 (2023).
- [14] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Scialom, T. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv. /abs/2307.09288, (2023).
- [15] 藤井一喜,中村泰士,Mengsay Loem,飯田大貴,大井聖也,服部翔,平井翔太,水木栄,横田理央,岡崎直観.継続事前学習による日本語に強い大規模言語モデルの構築.言語処理学会第30回年次大会(2024).
- [16] Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., and Mann, G., BloombergGPT: A Large Language Model for Finance. ArXiv. /abs/2303.17564, (2023)
- [17] 入手先〈https://tech.stockmark.co.jp/blog/202310_stockmark_13b/〉
- [18] 入手先〈https://www.nikkei.com/article/DGXZQOUC1941R0Z10C24A4000000/〉
- [19] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. /abs/2005.11401 (2020).
- [20] Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., & Wang, H. Retrieval-Augmented Generation for Large Language Models: A Survey. ArXiv. /abs/2312.10997 (2023).
- [21] R. Teja, Evaluating the ideal chunk size for a rag system using llamaindex. https://www.llamaindex.ai/blog/evaluating-the-ideal-chunk-size-for-a-rag-system-using-llamaindex-6207e5d3fec5, (2023).
- [22] Langchain, Recursively split by character, https://python.langchain.com/docs/modules/data connection/document transformers/recursive text splitter, (2023).
- [23] S. Yang, Advanced rag 01: Small-to big retrieval, https://towardsdatascience.com/advanced-rag-01-small-to-big-retrieval-172181b396d4, (2023).
- [24] Optimizing Retrieval-Augmented Generation with Advanced Chunking Techniques: A Comparative Study, https://antematter.io/blogs/optimizing-rag-advanced-chunking-techniques-study
- [25] Matouš Eibich, Shivay Nagpal, Alexander Fred-Ojala, ARAGOG: Advanced RAG Output Grading, arXiv: 2404.01037
- [26] Mao Y., He P., Liu X., Shen Y., Gao J., Han J., and Chen W. Generation-Augmented Retrieval for Open-Domain Question Answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), (2021)
- [27] Zhuang S. and Zuccon G. Dealing with Typos for BERT-based Passage Retrieval and Ranking, In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2836–2842, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics (2021).
脚注
- *1 筆者の所属組織が発表したものであり,筆者が直接かかわった取り組みではない
- *2 https://jp.ub-speeda.com/news/20231220/
- *3 https://www.forcas.com/news/product-info/ai-suggest/
- *4 https://www.forcas.com/news/product-info/ai-sales-talk-poc/
- *5 実用では,クエリ内の企業名を抽出する固有表現モデルを利用したり,観点を分類するモデルを使うことや,より広範なニュース記事データなどから企業名を抽出することでデータの検索を行っている.

koutarou.tamura@uzabase.com,
k.tamura.phd@gmail.com
1988年生.2016年東京工業大学大学院総合理工学研究科博士課程修了.同年同大学大学院科学技術創成研究院ビッグデータ数理科学研究ユニット特任助教.2018年株式会社野村総合研究所データサイエンティスト・研究員,2023年に株式会社ユーザベース現職.専門は,非線形物理学,複雑ネットワーク科学.金融経済情報に係るデータ分析・自然言語処理の研究開発に従事.
採録日 2024年8月27日