東北大学における生成AIの実践的活用
Practical Application of Generative AI at Tohoku University
1. はじめに
東北大学では,2021年3月にAIチャットボットを導入して以降,大学業務の効率化および高度化を実現するために,AIの実装を積極的に推進してきた.2022年3月にAI契約審査プラットフォームである「リーガルフォース」[1]を導入し,契約事務における各種書類のリーガルチェック業務の高度化と効率化を同時に実現している.同年8月にはAIを活用してオンライン会議の会話や動画の音声をリアルタイムに文字データに変換・翻訳する「オンヤク」[2]を導入し,議事録作成や翻訳に活用するのみならず,多国語で行われる学内の各種会議や,講演における同時通訳にも活用している.2023年3月にはAI音声合成技術を搭載し手軽に読み上げさせることが可能な入力文字読み上げソフトである「ボイスピーク」[3]を導入し,広報動画や,学内で行われる会議資料動画のナレーションに活用している.
このように,業務へのAI実装を進めるなかで大きな転機となったのが,2022年11月30日のChatGPT公開である.チャット形式の画面上からのあらゆる問いかけに対して的確な返答をする精度の高さから,米国のみならず世界中で話題になり,同時にいくつかの懸念も指摘されることとなった.そのため本学では,2023年3月31日に「教育における生成AIに関する注意喚起」を発出している(図1).
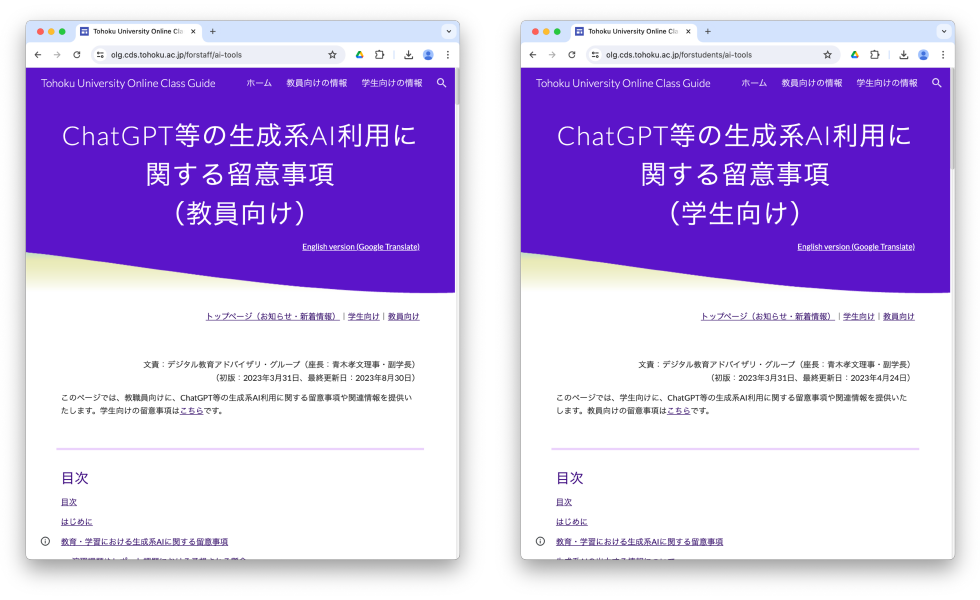
Fig. 1 Points to note for using generative AI in education and research at Tohoku University.
これは,教員向けと学生向けにそれぞれ発出され,教員向けのページでは,演習課題やレポート課題を課した場合に予想される懸念事項を示すとともに,その対応方法を記載している.また,教育上懸念される事項に加えて機密情報の漏洩の危険性についても触れるとともに,他大学の対応や注意喚起などのリンクもあわせて紹介している.学生向けのページでは,やみくもな生成AIの利用は自身の学習にならないことや,場合によっては剽窃とみなされる可能性があること,情報漏洩の危険性があることなどに触れるとともに,生成AIの出力が正しいとは限らないことを紹介している.
インターネットを利用するうえでGoogle検索が不可欠になったように,ChatGPTなどの生成AIもいずれ生活に不可欠なものとして入り込んでくることが見込まれ,それによって様々な場面で教育や学習を効率化し,生産性を向上させる可能性もあるので,この留意事項を参考にしつつ活用していこうという機運が本学において高まるなか,2023年5月18日,全国の大学に先駆けてChatGPTを導入した.2020年7月の「コネクテッドユニバーシティ戦略」にある,教育,研究,社会との共創,さらには業務全般のデジタル化のさらなる発展に向けChatGPTを導入し,これまで推進してきたAIの実装による大学業務の効率化および高度化の実績を踏まえて,生成AIという新たな技術をまずは大学の業務に実装することで積極的に利活用し,そこで得た知見を教育,研究,社会との共創に応用し,発展させることを狙いとしている.
本稿では,大学における諸活動をさらに高度化する目的で導入された生成AIの実装について報告する.また,この過程において得られた知見と,今後の展望についても詳述する.
2. 東北大学のDXの取り組み
東北大学は1907(明治40)年に日本で3番目の帝国大学として創立され,建学以来の伝統である「研究第一」と「門戸開放」の理念を掲げ,世界最高水準の研究・教育を創造し,研究の成果を社会が直面する諸問題の解決に役立て,指導的人材を育成することによって,平和で公正な人類社会の実現に貢献することを使命としている.
2020年の新型コロナウイルス感染症という世界規模の危機に際しては,この危機を克服し,新常態のもとでの社会変革を先導することを責務と考え,教育,研究,産学共創,社会連携,経営等,あらゆる活動のさらなる発展を期して,同年6月1日に「オンライン事務化」を宣言し,デジタル活用により「あたりまえ」とされていた窓口サービスや各種手続などの従来の業務プロセスを徹底的に見直すこととした.同年7月には,「最先端の創造,大変革への挑戦」を掲げた「東北大学ビジョン2030」をアップデートし,大学の変革を加速する「コネクテッドユニバーシティ戦略」を策定した.この戦略は,教育,研究,社会との共創など,大学の諸活動のDX(Digital Transformation)を強力に進めるとともに,サイバー空間とリアル空間の融合的活用を通して,ボーダレスで多様性に富み,真にインクルーシブな大学を創り上げるためのものである.
これらを実現するため,国立大学法人で初めて,CDO(Chief Digital Officer:最高デジタル責任者)を創設した.大学DXを強力に推進するCDOの下,ニューノーマル時代に相ふさわしい教育・研究環境の実現と構成員にとって魅力ある職場環境を創生することを目的とし,DXによる先導的な業務改革を短期的スパンで集中的かつ戦略的に実行する「業務のDX推進プロジェクト・チーム」を結成した.このチームのメンバは公募で集められた.本プロジェクト・チームにおいては,「オンライン事務化」宣言に掲げた「窓口フリー」「印鑑フリー」「働き場フリー」の3つのWGを立ち上げ,オンライン窓口業務の実現(「窓口フリー」),電子決裁の導入(「印鑑フリー」),在宅勤務の制度化(「働き場フリー」)などに取り組んだ.
「窓口フリー」では,大学の窓口業務323件を洗い出し,これまで対面や電話等で行ってきた定型的な質問への対応をオンラインで可能とした.対面が望ましい各種相談窓口については,Google meet等のオンラインミーティングプラットフォームを活用し,”顔が見える”オンライン窓口を実現した.2021年3月には,全国の国立大学法人に先駆けてきめ細やかな対応を必要とする場合にその連絡先を案内するオンラインコンシェルジュの役割を果たす日本語・英語・中国語の3ヶ国語に対応したAIチャットボットを導入した.AIチャットボットの導入を契機に,AIを活用した業務の効率化を本チームが主となって推進し,前章で述べた各種AIサービスの導入を行ってきた.生成AIの業務活用検討についても,これまでの実績から本チームが中心となり検討を行った.
これまで本学で導入したAIサービスは,契約書レビューや音声合成など,特定の用途が定められていた.これに対し,生成AIは利用者の指示に基づいて生成を行うため,利用者が用途を明確化して設定する必要がある.しかしながら,生成AIは新規の技術であるため,組織における業務活用用途はトライアルアンドエラーの状態であり,大学組織においても,活用モデルはまだ確立されていない.
そこで本学では,生成AIサービスを部署や用途を限定せずに配布し,実業務において実践を行いながら活用可能性を検証することにした.また,実践のみならず研修も行うことにより,「実践」と「理論」の双方向のアプローチから生成AIの業務活用を推進した.次章では本学における生成AI活用推進の「実践」および「理論」について紹介する.
3. 東北大学における生成AI実践活用事例
3.1 利用者アンケート
3.1.1 利用者アンケートの実施
生成AIサービスの導入に際し,まず利用希望者に広くアカウントを配布して業務で活用してもらい,どのような業務に活用したかをアンケート形式で調査した.その結果を表1に示す(表中は順不同).
Table 1 Survey results: Potential applications of generative AI at Tohoku University.

表1より,文章校正や文章作成補助,要約など,あらゆる部署に共通する業務の効率化に活用される一方で,コーディング・コードレビューや作業手順調査など,主に技術系職員による専門的な業務へも活用可能であることが分かる.また,英訳補助や専門用語理解の補助など,専門用語辞書として生成AIが活用可能であることも確認された.
また,同アンケートにて生成AIを業務活用するために必要となる機能を同アンケートにて併せて調査した.その結果を表2に示す(表中は順不同).表2より,ファイル・データのアップロード機能,すなわちマルチモーダルへの対応が多いことが分かる.また,主に技術系職員より,チャットによる利用のみではなくアプリケーションに組み込むためのAPIの提供も挙げられた.
Table 2 Survey results: Required features for expanding generative AI use at Tohoku University.

本アンケートの結果より,部署を限定せずにアカウントを配布することで,業務や部署に依らない共通的な活用方法のみならず,特定の職種に特化した活用方法も確認された.また,さらなる生成AI業務活用のために必要な機能についても,様々な部署・職種から多様な要望があることが確認された.
3.1.2 利用者アンケートの考察
表1に示したアンケート結果は,プロンプトに含まれる生成AIへの指示と入力の元となるデータの形式によって類型化することが可能である.
たとえば文章校正は,元データとなるテキスト形式のデータに対して作成・加工する旨の指示を記載し生成を行う一方で,会議事録作成などは,元データは音声ファイルや動画ファイル形式であり,それを何らかの方法によってテキスト形式に変換したのちに,作成・加工指示と併せて生成AIへ入力することによって実現される.また,専門用語理解の補助などは,プロンプトに知りたい語句をテキスト形式で入力するとともに,教示する旨の指示も併せて記載することによって,LLM内部の知識を引き出すものである.英会話学習についても同様に,LLMが有する知識を引き出すものであるが,会話データは音声ファイルや動画ファイルであるため,データ形式は非テキストとなる.生成AIへの指示とデータ形式に基づき,生成AIの活用様態を類型すると表3のとおりとなる.
Table 3 Classification of generative AI usage based on prompts and input data types.

表3において,元データ形式がテキスト形式である類型1および3については,本学が導入したText to Textの生成AIサービスにより直接的に業務効率化が実現可能である.一方で,非テキスト形式である類型2および4には,テキストデータに変換するため,生成AIの入力前段にテキスト形式に変換する機能を追加することによって,更なる業務の効率化が可能であると強く推察される.そこで,部署や役職を問わない共通業務であり,業務効率化の効果が高いと推察される会議事録要約作成業務に着目し,会議の動画・音声ファイルを直接入力して要約を作成するシステムを構築した.これにより議事録要約業務の効率化が実現できた.この要約システムについて3.2節で紹介する.
また,同表の類型3および4のように,生成AIが有する知識を教示する活用様態においては,LLMの学習データセットに含まれる知識に限り回答が可能であるため,英会話や特定の専門用語は教示可能である一方,基盤モデルのみで事前学習のデータセットに含まれないデータの教示を行うことは困難である.そこで,3.3節では,Retrieval-Augmented Generation(RAG)を活用し,基盤モデルの学習データセットに含まれないデータに基づいた教示を可能とする生成AIシステムを導入することで,生成AIの知識を拡張し,更なる業務の効率化を実現した方法について述べる.
3.2 要約作成アプリの内製
3.2.1 要約生成アプリのシステム環境
前節のアンケート結果に基づき,更なる生成AIの活用に向けて,非テキストデータを対象とした生成AI活用による業務効率化について検討を行った.具体的には,動画・音声ファイルを入力として,文字起こしによるテキスト化およびそれを活用した生成AIによる要約作成システムを行うWebアプリケーションを内製した.
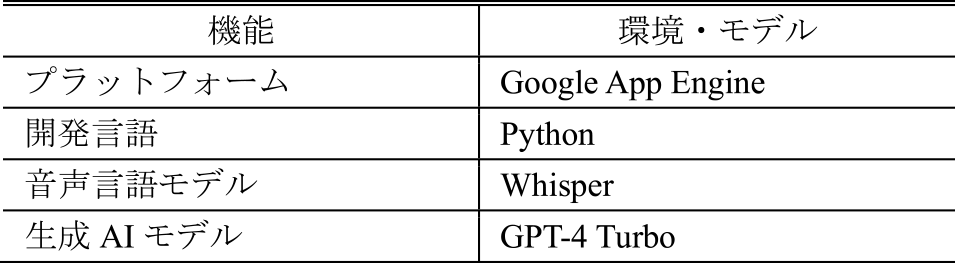
本システムの開発環境および利用したモデルを表4に示す.本システムでは,動画ファイル形式であるmp4と音声ファイル形式であるmp3のいずれかの形式のファイルを入力データとしてアップロードし,Googleドキュメントにテキストデータとして出力するものである.本学は全学でGoogle Workspaceを利用しているため,親和性の高さからGoogle Cloud Platformを活用し,Python言語でWebアプリケーション形式にて構築した.音声言語モデルは,OpenAI社のWhisperを,生成AIモデルは,OpenAI社のGPT-4 Turboを用いた.
Table 4 Development environment for the transcription and summarization system.
利用フローを図2に示す.利用者はシステムにアクセスし,認証および本システムへの各種権限許諾を行った後に,要約を行う動画・音声ファイルを選択する.なお,生成AIに対するプロンプトは,事前に作成したシステムプロンプトとしてあらかじめ設定されている.ファイルのアップロードが正常に完了すると,文字起こしおよび要約作成が非同期で開始され,完了後に利用者へメールで文字起こしされたデータと要約データが記載されたGoogleドキュメントへのリンクが送付される.なお,会議データなどの機密性が高いデータを扱うことを想定し,文字起こしされたデータと要約データは,Googleドライブの個人領域であるマイドライブに格納することで,意図しない共有等による情報漏洩等を回避している.
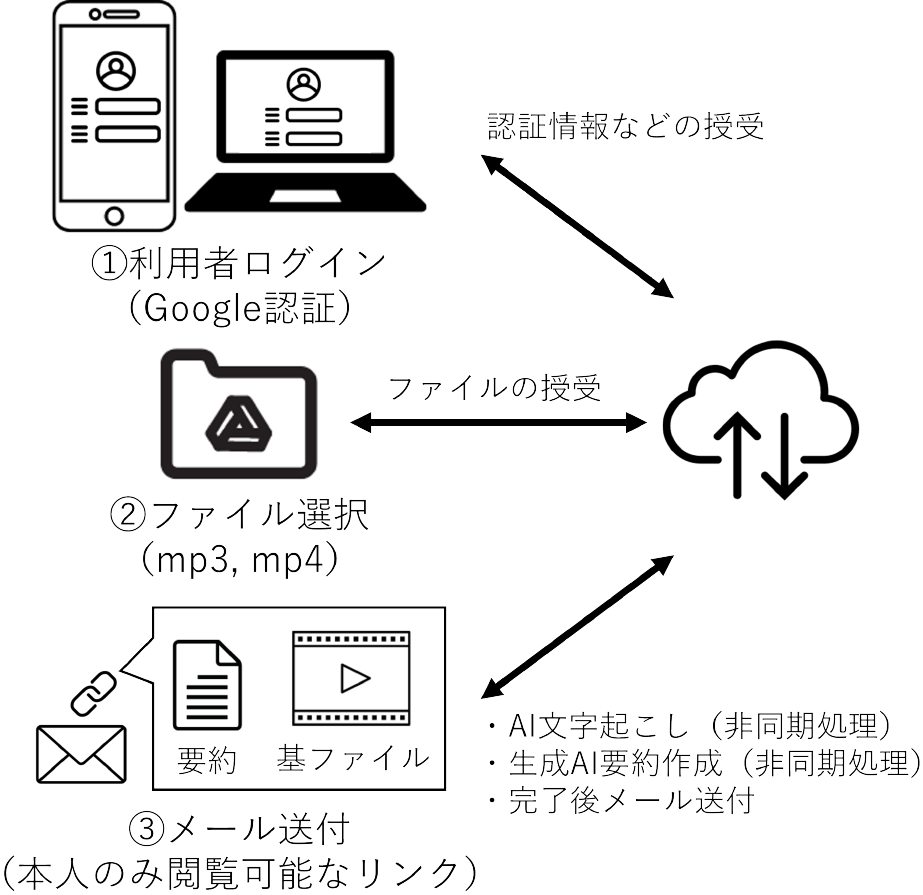
Fig. 2 Workflow of the transcription and summarization system.
3.2.2 要約作成アプリの実証実験と考察
本システムに動画および音声ファイルを入力し,動作検証を行った.3時間の動画ファイル(mp4形式)および1時間の音声ファイル(mp3形式)各1件を本システムに入力したところ,いずれも文字起こしデータと要約データが記載されたGoogleドキュメントへのリンクがメールにて送付された.また,送付されたGoogleドキュメントは,ファイルストレージの個人領域に格納されており,送付された当人のみがアクセス可能な設定となっていることも確認された.文字起こしおよび要約データについても,同音異義語の誤認識は数件あるものの,発言された内容が漏れなく文字データとして記載されており,会議議事録の初稿として実業務において活用可能な精度であることが確認された.
本アプリケーションの効果を定量的に測定するために,アプリ開発者を除く本プロジェクト・チームのメンバー11名を対象に実証実験を行った.具体的には,本アプリを1カ月使用し,利用頻度や業務削減効果に関するアンケート調査を行った.その結果を表5に示す.同表のとおり,1人あたりの月間平均利用回数は3.63回であった.また,本アプリを活用せずに,1時間のオンライン会議の要約作成を行うのに要する時間は1人あたり平均で1.98時間であったのに対し,本アプリを活用することにより0.51時間と約1/4に短縮された.上記より,本アプリによる要約作成業務の効率化が大きいことが示された.
Table 5 Survey results: Evaluation of the transcription and summarization system.

また,当初活用を想定していたオンライン会議の要約(議事録)作成以外にも本システムが応用可能であることが実証実験の過程で分かった.本プロジェクト・チームでは,アウトリーチ活動を行うプロモーションチームが組織されており,インタビューや対談から記事を作成する機会も多い.このインタビュー動画や音声データから記事を作成する補助ツールとしても本システムが活用可能であることが明らかとなった.そこで,本システムを改修し,会議議事録作成用とインタビュー要約作成用の用途別のプロンプトを作成し,それらを利用者画面上で選択することで,用途に応じた適切な様式にて要約を作成可能とした.
生成AIは様々な業務へ活用が可能であるがゆえに,大学組織のように多岐にわたる業務が存在する大規模組織の場合,今回のように,システムに軽微な改修を加えることで他の業務に応用可能な場合がある.また,生成AIは技術の進歩が早く,最新の技術を取り入れるためには頻繁にシステムを更新する必要がある一方で,システム改修を頻繁に行うことは,金銭的および調達手続きに要する時間的コストの面において非効率である.業務への応用可能性が高く,また技術動向が激しい生成AIにおいて,内製開発は合理的であると考えられる.
本アプリにより,非テキストデータである動画・音声ファイルをテキストデータに変換する前処理を行い,生成AIを活用して要約を作成することで,大幅な効率化が期待できる業務が多いことが確認できた.
なお,要約作成における生成AIのプロンプトとしてChain of Thoughts [4]を用いたが,要約作成においてはChain of Density [5]などの手法も提案されており,最適なプロンプトの検証については今後の課題である.また,本実証実験で得られた結果に基づき,今後は本アプリの利用拡大を行い,更なる業務効率化を実現する予定である.
3.3 生成AIチャットボットの導入
3.3.1 Fine-tuningとRAG
3.2節までのプロンプトに入力された元データに基づき,作成や加工を行う活用方法のみならず,生成AIが保持する知識からの教示という活用方法も3.1節のアンケートにて確認された.しかしながら,生成AIのモデルは,広範なデータに基づいて訓練されたAIモデルであり,これにより多様なタスクに適用できる汎用性が得られる一方,学習データセットの範囲内の情報のみに基づいて回答を生成するため,新しい情報や学習に含まれない独自のデータに基づいて回答を行うことは困難である.この問題を解決するための手法として「Fine-tuning」と「Retrieval-Augmented Generation(RAG)」が広く活用されている.
Fine-tuningは,特定のタスクやデータセットに合わせて事前学習済みのモデルの重みを調整する手法であり,タスク固有のニーズに深く対応することが可能である一方,学習に時間を要するなどの課題がある.
一方,RAGは外部の知識データベースを活用し,利用者からの質問に関連した情報を検索・取得してプロンプトに含める技術である.学習を行わないため,Fine-tuningと比較して高速な応答が可能である.
これらの手法は,それぞれ異なる利点を持ち,用途に応じて選択されるべきであるが[6],本学のように大学事務業務での活用の場合,データは比較的高い頻度で更新されるため,学習を経ずに高速にデータ読み込みが可能なRAGを活用し,問題を解決するほうが良い.そこで生成AIを本学のホームページなどで運用する14のチャットボットに実装し,ホームページや各種資料を読み込ませることで,本学に固有の問い合わせ対応に活用した.
3.3.2 生成AIチャットボットの導入
本学は,2021年3月に国立大学法人で初めて全学を対象に多言語対応チャットボットを導入し,2024年4月に,生成AIを同チャットボットに実装した.
従来のチャットボットは,利用者からの質問に,あらかじめ想定された回答を提示する方式であり,想定外の質問があると適切な返答が困難な場合が存在した.また,日々更新される膨大な学内のデータから想定される質問を網羅的に列挙し,一対の質問と回答群からなる構造化されたデータを生成する必要があり,運用コストの増大が課題であった.
生成AIは高い言語理解能力を有しており,それをチャットボットに活用することで,多様な言語表現も的確に理解し,従来のチャットボットよりもさらに人間らしい対話応対が可能である.また回答は,RAGを活用することで,事前に登録されたデータから回答に必要な情報を生成AIが検索し,回答を生成するため,質問と回答からなる構造化されたデータを作成する必要がなく,運用コストの大幅な低減が期待できる.
3.3.3 生成AIチャットボットの構築
3.3.3.1. 生成AIチャットボットの構成
生成AIチャットボットは会話型AI構築プラットフォームである「miibo」[7]を用いて構築した.本生成AIチャットボットの主要な構成要素を表6に示す.ベクトルデータベースおよび埋め込みモデルについては,メーカ非公表となっている.検索クエリ生成用モデルは,メーカによりあらかじめ固定値として設定されており,構築当初はGPT-3.5 Turboが設定されていたが,現在はGPT-4oが設定されている.回答生成モデルは本学側で設定可能であり,OpenAI社のGPT [8]やGoogle社のGemini [9],Anthropic社のClaude [10]などが
Table 6 Components of the generative AI chatbot of Tohoku University.
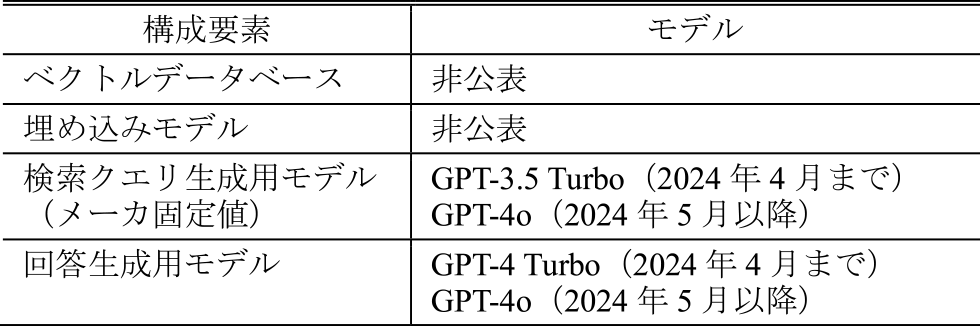
選択的に利用可能である.構築当初はトークン数が少なく,回答精度が高く,回答速度が高速なGPT-4 Turboを用いていたが,トークン数が少なく,また精度や回答速度も向上した後継モデルGPT-4oが2024年5月より利用可能となったため,現在はGPT-4oを用いている.
3.3.3.2. 生成AIチャットボットの動作
生成AIチャットボットのRAGワークフローを図3に示す.モデルを使用して独自データを検索(retrieval)する工程では,入力された利用者の会話と検索クエリ生成プロンプトから,検索クエリ生成用モデルにて検索クエリを生成する.生成された検索クエリでベクトルデータベースの検索を行い,会話に必要な情報を取得する.モデルを使用して会話を生成(generation)する工程では,ベースプロンプト,会話履歴(利用者の直前の発話を含む),ベクトルデータベースより取得した情報を基に利用者への回答を生成し,返答する.
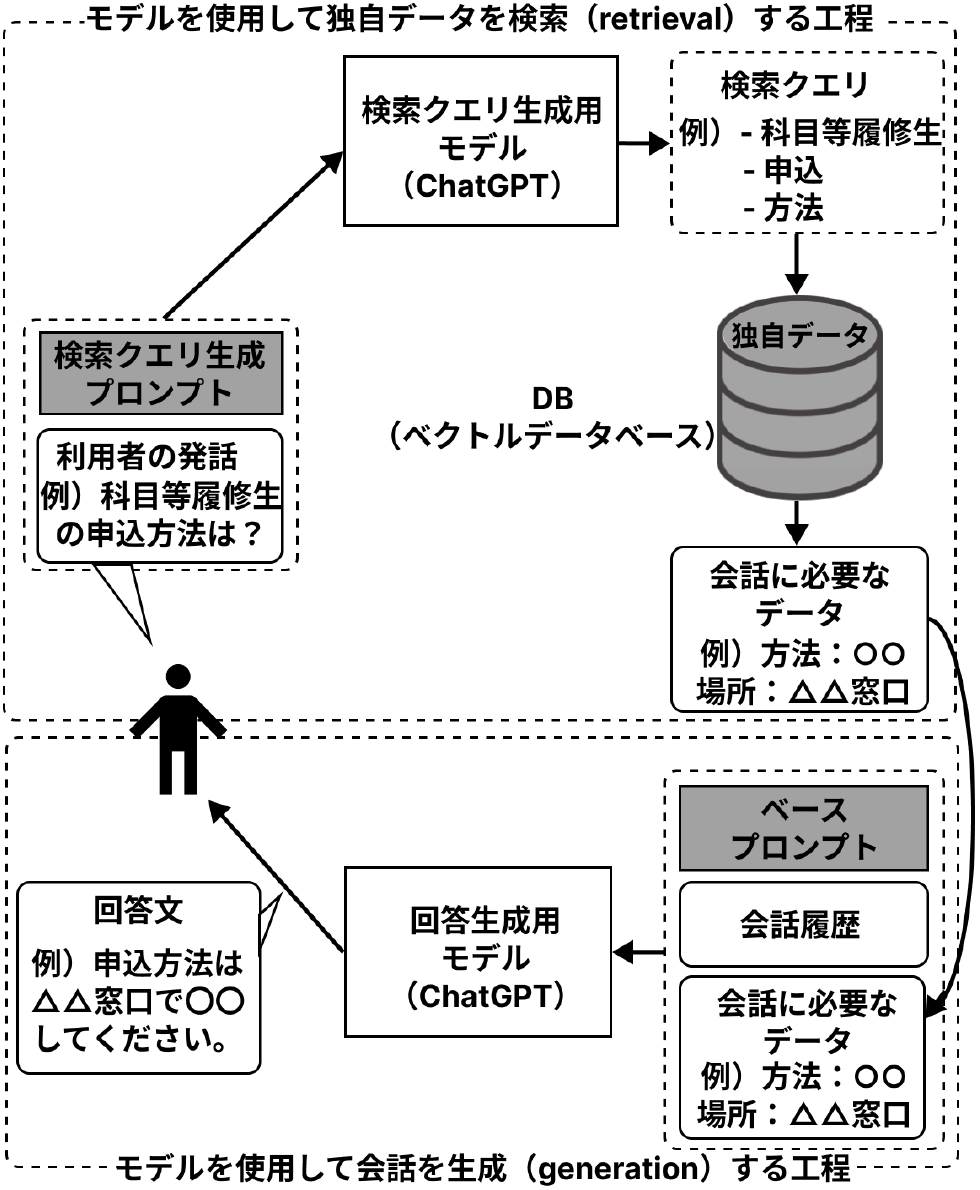
Fig. 3 Overview of RAG in the generative AI chatbot of Tohoku University.
3.3.3.3. 生成AIチャットボットの設定
今回導入した生成AIチャットボットのRAGに関する主な設定項目は,以下の1)~3)の3つである.また,RAGに関する設定以外にも重要な設定として,会話開始時の発話の設定(利用の同意)について,以下4)に述べる.
1) ベースプロンプトの設定
生成AIチャットボットの応答を制御する基盤となるプロンプトである.チャットボットへの指示文を記述し,質問に対する回答の方針や制限事項,口調なども含めて設定する.さらに,ハルシネーションを防ぐために,登録されていない独自データ(ベクトルデータベースに登録されていないデータ)を基にした回答を行わないようにするなどの禁止事項も設定している.また,多言語に対応するために,利用者の言語に合わせて回答するように設定している.たとえば,「最寄駅」という漢字の単語のみが入力された場合,初期の設定では中国語で返答してしまうことがあったが,簡体字または繁体字が含まれていれば中国語と判断し,そうでなければ日本語と判断する手順を追加し,この問題を解決した.
2) 検索クエリ生成プロンプトの設定
生成AIチャットボットのデフォルトプロンプトである.会話履歴と直近の会話を重視して検索クエリを生成する設定を基に作成されている.多言語対応を行うために,プロンプトへの工夫が必要であった.多言語対応と検索の精度向上を両立させるために,検索クエリは日本語で生成するようにし,日本語での生成が困難である場合のみ,英語で検索クエリを生成するように設定している.すなわち,日本語,英語以外での検索クエリを生成しないようにしている.これは,日本語による検索クエリを作成すると検索精度は良好であり,英語で検索クエリを生成した場合は日本語で生成した場合と比べ検索精度が劣るが,実用に耐えうるものである一方で,日本語,英語以外の言語で検索クエリが生成された場合,検索精度が悪化するためである.ベクトルデータベースは,言語間の境界を越えて検索が可能であり,このような設定は不要かと思われたが,格納したデータが日本語である場合には,検索プロンプトにこのような設定が必要であることが分かった.実際に本生成AIチャットボットにて設定したプロンプトを以下に示す.なお,以下のプロンプト中の@{history}は本生成AIチャットボット独自の記法であり,過去の会話履歴を参照するよう設定されている.
The following is a conversation between user and AI.
@{history}
Please create a search query to find the information that the above user wants.
Please make sure to create the search query in Japanese. If translation into Japanese is not available, please create the search query in English.
Please use Japanese Kanji characters in your search query, not simplified or traditional Chinese characters.
Please output only search queries (up to 5 words) and do not use double quotes or other symbols. Include the last user's question in the query as much as possible, giving priority to the content of the last user's question.
3) 独自データのベクトルデータベースへの格納
生成AIチャットボットでは,ベクトルデータベースへのデータ登録方法が複数用意されている.手入力による登録,PDFファイルアップロードによる登録,WebページのURL指定による登録,CSVファイルアップロードによる登録,API経由でデータを登録する方法などがある.昨年度まで使用されていた従来のチャットボットのFAQデータをGoogleスプレッドシートに格納し,Google Apps Scriptを用いてAPI経由でベクトルデータベースに格納した.更に,URL指定による本学Webページを読み込ませてベクトルデータベースに登録した.従来のルールベースのチャットボットで使用していたFAQデータは,単調なQuestionとAnswerの蓄積であり,それらをベクトルデータベースに格納しただけでは,限られた回答しかできない.生成AIを使用したチャットボットの場合,利用者がチャットボットに期待する回答のバリエーション,クオリティともに高くなるため,ベクトルデータベースに様々な本学に関する独自データを格納することが必要であった.本学Webサイトには,すでに多くの信頼できるデータが存在するため,それらをベクトルデータベースに登録することで,短時間で多くの独自データを格納することができた.
4) 会話開始時の発話の設定(利用の同意)
生成AIチャットボットは,適切に設定することによりハルシネーションを抑えることができるが完全になくすことができるとは言い切れない.そのため,図4のように,チャット画面が開かれた直後に,「本チャットボットは生成AIを活用して回答を行います.生成AIでの回答は一部誤りを含む場合がございます.ご了承いただける場合は「同意する」をクリックし,ご利用ください.」と発話させ,了承いただける場合にだけ「同意する」ボタンを押してから会話ができるようにしている.このように,サービスが生成AIを利用していること,回答に誤りを含む可能性があること,そしてそれらを理解・同意したうえでサービスを利用するよう求めている.
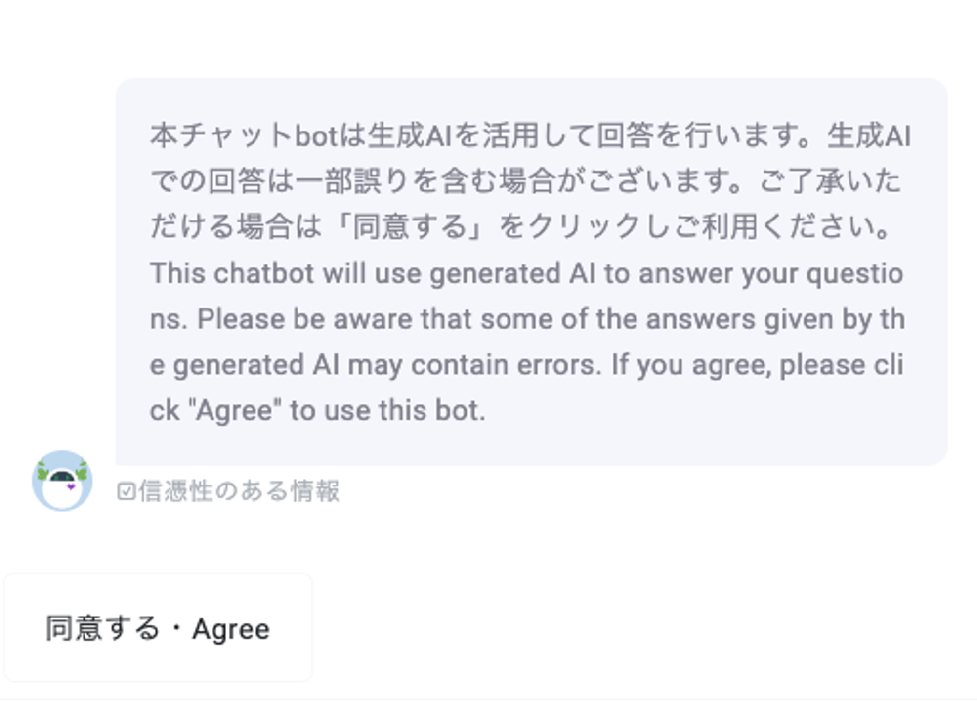
Fig. 4 User consent screen in the generative AI chatbot of Tohoku University.
3.3.3.4. 生成AIチャットボット導入・運用の評価
従来のチャットボットは構造化されたFAQデータを参照する形式であったため,ホームページとは別にFAQデータ作成を行う必要があり,情報の二重管理が生じていた.
生成AIチャットボットはRAGによってURLを読み込むことでホームページに基づく回答が可能であるため,情報管理が一元化による管理性が可能である.本学では,従来約1000件のFAQデータを保持していたが,生成AIチャットボットにより約350のURLに情報が削減され,管理対象が削減された.
また,生成AIを活用することで,管理性の向上のみならず利用者の利便性の向上も実現された.本学には様々な国の外国人留学生や研究者が在籍しており,多言語での応対が求められる.システムに多言語対応機能を実装する場合,言語ごとに翻訳機能を実装する必要があるため,言語数に応じた実装コストかかる.そのため,英語などの主要言語に限定することが多いと推察される.しかしながら,生成AIチャットボットはプロンプトに数行文言を追加するのみで新規言語の追加が対応可能であり,本学では30カ国語に対応している.従来のチャットボットは3カ国語対応であったため,生成AIチャットボットによって,より広範な利用者の利便性向上に寄与できたものと推察される.
また,一問一答のチャットボットは1往復の対話が基本であり,チャットボットが提示した回答についてさらに発展的な質問を行うことはできなかったが,生成AIチャットボットではマルチターン型のシステムの特性が利用されており,平均で2.7往復の対話ができていることが分かった.
生成AIチャットボットの導入により,管理工数の低減や利用者利便性の向上などが実現された一方で,生成AIが潜在するハルシネーションやプロンプトインジェクションなどのリスクについては,今後さらに検証を行う必要がある.各種リスクに対してはプロンプトにおいて対策を行っており,現時点において,利用者から不利益があったという報告はないが,上記の生成AIの利便性を最大限活用するためにも,これらの各種リスク低減については引き続き検討を行う予定である.
3.4 生成AI活用研修
前節までは,生成AIシステムを活用した業務効率化の実践について紹介をしたが,新規技術である生成AIを正しく理解し,業務応用展開するためには研修による知識習得も必要不可欠である.そこで,2023年12月6日,本学は生成AIの実用性と潜在能力を全学的に理解し,具体的な活用方法を共有するため,株式会社MAKOTO Primeの協力のもと,生成AIの基本的な機能から業務適用までの幅広いテーマを理解することを目的としたオンライン研修セミナーを実施した.本研修は当初,業務効率化に主眼を置き,本学の事務職員を対象としていた.しかしながら,生成AIは業務効率化のみならず教育・研究にも活用可能な汎用性が高い技術であり,これらを共有することは大学全体のメリットとなりうるとの考えから,学生や教員そして本プロジェクトにて組んでいるアライアンス参画機関からの参加も承諾し,1,000名以上が参加する大規模な研修となった.
研修は,まず,AI技術が社会や産業に与える影響についての基礎知識から始まった.続いて,実際の業務プロセスに生成AIをどのように組み込むかの具体的な方法が提示された.たとえば,大学業務でもみられるような,イベントの企画,案内文作成,タスク表作成,台本作成など,一連の業務への生成AIの適用,そしてその際に気を付けるべきプロンプトのコツなどが解説された.さらに,部署ごとの活用シナリオを解説し,参加者に自身の業務において生成AIをどのように活用できるかの見通しを立てやすくした.これらの事例を通じて生成AIの実際の応用を学び,それによって業務の効率化や問題解決がどう改善されるかの理解を深めた.
研修では,生成AIの利用における倫理的考慮やセキュリティの重要性についても強調され,生成AIを安全かつ効果的に使用するためのガイドラインを紹介した.これにより,参加者はAI技術を適切に理解し,誤った情報に惑わされることなく,正しい知識を身につけることができた.
また,本研修後の受講者アンケートの結果,60.6%が「生成AIの使用経験なし」と回答したのに対し,81.2%が「生成系AIの活用イメージを具体化できた」と回答し,また,89.5%が「生成系AIの基礎知識・技術・使用時の注意点の理解度」が向上したと回答した.本アンケートにより,多くの受講者が生成AIの業務活用を行うための活用法や懸念点などの知識を習得できたものと推察される.今後,この研修の内容を生かして,より多くの業務やプロジェクトに生成AIを組み込み,その成果を大学運営に反映させていく計画である.
4. 生成AIの実践的活用を支える組織的側面
3章で述べた生成AIの活用に向けた挑戦は,失敗することをできるだけ回避したい大学組織の取り組みにとしては稀有な例である.組織的側面から,これを可能にしている要因は,以下のように整理できる.
- (1) 新規取り組みの是非の判断基準の明確化・定着化
建学以来の伝統である「研究第一」の実現には,十分な研究時間の確保が不可欠である.事務系職員は,研究時間を十分確保するために研究者が行わなければならない研究以外の作業時間の効率化・短縮化に優先的に取り組む意識が醸成されている.さらに作業時間の効率化・短縮化は,研究者のみならず事務系職員にも魅力ある職場環境を実現する重要な取り組みであることが理解されている.その結果,組織の構成員全員が,作業時間の効率化や短縮化につながる取り組みを進める組織風土ができている. - (2) 意欲ある多彩なメンバからなるプロジェクト・チームによる取り組み
(1)で述べた判断基準の明確化に加え,生成AIといった新しい技術を業務に適用するときはプロジェクト・チームとして取り組んでいる.プロジェクト・チームのメンバは,公募で集められるため,新しい技術に挑戦する意欲が高いメンバが集まっている.さらに,メンバには,事務系職員だけでなく情報システム開発経験のある技術系職員も含まれていることに加え,適用する技術に詳しい外部組織からの参画もある.このような意識が高く業務と技術を良く知っている多様なメンバからなるチームで取り組むため,取り組み始めてから結果を出すまでの時間を短縮でき,成功する確率も高くできる. - (3) スモールスタートによる立ち上げ
最初は限られた部署や人,業務を対象に取り組み(スモールスタート),取り組んだ結果を広報し,取り組みに参加したいと考える人を少しずつ拡大する形をとっている.全学への展開は,すべての構成員が取り組みを強制されるのではなく,全学で参加したいと考える人は誰でも取り組めることを意味する.すなわち,全学への展開であっても100%を目指すのではなく80%や90%を目指すことになる.これにより,全員参加を強いられることによる抵抗や要求水準の高騰を回避している.さらに参加したいと考える人が取り組む際には,先行して取り組んでいた人が支援することで取り組みの成果を得やすくし,参加したいと考える人を増やすスピードを上げている.近くに新しい取り組みで成果を得ている人がいれば自分も取り組もうと考えることが多く,自分で取り組もうという意識を持つことで成果を得るだけでなく得るまでのスピードを上げることにつながるし,80%や90%を目指すことで費用対効果を考慮した取り組みを実現している.
5. 今後の展望
本学は,研究第一主義を掲げる総合大学であり,日々多くの研究データや論文が創出されるとともに,附属図書館や資料館などに,多くの歴史的資料を保管しており,学術的な資産を数多く保有している.国立大学法人として,これらの研究成果や歴史的資料のオープンアクセスを促進し,社会に広く開放する使命を担っている.
研究成果や各種資料を公開するためには,各データの表題や特性を示すメタデータを付与し,誰もがアクセスしやすい形態にて公開することが求められる.しかしながら,各種データは膨大な数があり,すべて手作業でメタデータの付与を行うのは非常に困難である.本学では生成AIを活用して,メタデータを半自動的に付与するシステムを構築する予定である.
予備実験として,画像入力対応生成AIモデルに図5の画像データを入力し,メタデータの作成を試みた.明らかに「東北大学法学部」と記載されている画像データを「秋田大学法学部」と誤認する結果となった.また,他の文字が記載されている画像データを用いて同様に検証を行った結果,実際に記載されている文字とは異なる文字に誤認することが散見された.本予備実験より,画像入力対応生成AIモデルのみを用いてメタデータを付与する方式は,画像・文字認識精度の観点から困難である可能性が高いと判断した.

Fig. 5 Example of text misrecognition using multimodal generative AI.
そこで今後は,生成AIを活用した別のアプローチについて検証を行う予定である.具体的には,入力データに応じて画像認識技術やOCR技術などの従来からある各種の技術を選択的に活用して認識を行い,それらの認識結果をもとにオーケストレーションとして機能する生成AIがメタデータの付与するものである.すなわち,自然言語理解や自然言語生成を得意とする生成AIが人間と各種認識モデルとの仲介役となることで精度向上を目指すものである.これにより,半自動的に高精度のメタデータを作成する予定である.
6. まとめ
本稿では,新型コロナウイルス感染症という世界的な危機をきっかけに,東北大学が推進したDXの取り組みと,生成AIの活用事例について述べた.本プロジェクトの一環として,AIチャットボットの導入や,AIを活用した契約審査や広報活動など,様々な分野でAIを実装する中で,その成果を上げた.
そして,2023年に全国の大学に先駆けて,生成AIを業務へ導入し,様々な業務へ活用した.さらに,要約作成システムの開発や,独自データを活用したRAGによるチャットボットなど,多くの実践例が生まれ,大学運営業務の効率化が推進された.また,学内外の教職員・学生等を対象とした生成AI活用研修を開催し,生成AI活用促進にも取り組んだ.
生成AIは汎用性が非常に高くあらゆる業務効率化で有用である一方,明確な用途が定義されている個別の分野においては,精度向上が困難な場合がある.すべてを生成AIのみに依存するのではなく,その特性を理解したうえで活用範囲を明確に定義し,適材適所に活用することで真に生成AIの活用が最大化されると考える.
本学では,今後も生成AIを最大限に活用し,社会の発展に貢献していく所存である.
謝辞 本稿の執筆にあたり,東北大学土井美和子データ戦略・社会共創理事および東北大学未踏スケールデータアナリティクスセンター樋地正浩特任教授から数々の貴重なご助言を賜りました.深く感謝申し上げます.
参考文献
- [1] 株式会社LegalOn Technologies:株式会社LegalOn Technologiesの製品,サービス(オンライン),入手先〈https://www.legalon-cloud.com/legalforce〉(参照2024-05-07).
- [2] 株式会社ロゼッタ:株式会社ロゼッタの製品,サービス(オンライン),入手先〈https://www.rozetta.jp/onyaku/〉(参照2024-05-07).
- [3] 株式会社AHS:株式会社AHS,サービス,入手先〈https://www.ah-soft.com/voice/6nare/index.html〉(参照2024-05-07).
- [4] Wei, J. et al.: Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv: 2201.11903 (2022).
- [5] Griffin A. et al.: From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting. arXiv preprint arXiv: 2309.04269 (2023).
- [6] Oded O., Menachem B., Moshik M., and Oren E.: Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs. arXiv preprint arXiv: 2312.05934 (2024).
- [7] 株式会社miibo:株式会社miiboの製品,サービス(オンライン),入手先〈https://miibo.jp/〉(参照2024-07-10).
- [8] OpenAI, Inc.: GPT,OpenAIの製品(オンライン),入手先〈https://openai.com〉(参照2024-07-10).
- [9] Alphabet Inc.: Gemini,Googleの製品(オンライン),入手先〈https://deepmind.google/gemini〉(参照2024-07-10).
- [10] Anthropic, PBC: Claude,Anthropicの製品(オンライン),入手先〈https://claude.ai〉(参照2024-07-10).

shota.suzuki.e8@tohoku.ac.jp
東北大学情報部デジタル変革推進課デジタルイノベーションユニット専門職員.2013年東北大学大学院工学研究科電気・通信工学専攻修士課程修了.同年キヤノン株式会社入社.2017年東北大学入職.東北大学におけるデジタル変革の推進に従事.

takei@makotoprime.com
株式会社MAKOTO Prime 代表取締役.東北大学生命科学研究科博士課程修了.東北大学特任准教授(客員).東日本大震災を経験したことをキッカケに「地域からチャレンジャーが産まれて育つ仕組み作り」を目指し,2011年7月にMAKOTOを設立.MAKOTOグループ7社の体制を作る.ベンチャーキャピタルとして20億円弱のファンド組成.10年以上スタートアップ投資・支援に従事.現在は生成AIにコミットし,多数の組織にて生成AIの業務活用支援を推進.

t.neba@makotoprime.com
2002年大阪大学医学部保健学科看護学専攻.学士(看護学).2019年専門学校HAL名古屋情報処理学科.専門士(情報処理).2023年より株式会社MAKOTO Primeにて会話型AIチャットボット構築を担当.

kazuyuki.fujimoto.a7@tohoku.ac.jp
東北大学情報部デジタル変革推進課長.2004年秋田大学教育文化学部卒業.2009年東北大学入職.東北大学におけるデジタル変革の推進に従事.
採録日 2024年9月17日