問い合わせ履歴の匿名化と利用:プライバシー保護を確保したチャットボット開発
Anonymizing and Utilizing Inquiry Histories: Developing a Privacy-Preserving Chatbot
1. はじめに
近年生成AI技術の発展はめざましく,文章,画像,音楽,動画といった様々なコンテンツを,人間が作ったものに近いレベルで生成することが可能になってきている.
その中でも,LLM(Large language Models)はLlama [1],Claude [2],GPT [3]など国内外の多くの事業者が開発をしており,一般消費者が使えるサービスとして日本語での自然な文章を生成することが可能なモデルが提供され始めている.
文章生成は質問文に対し応答文を生成するチャットボットとして広く使われており,企業のサポートに利用されるケースもみられる.
経済産業省と総務省が取りまとめたAI事業者ガイドライン[4]では,AI事業者は“AI開発者”,“AI提供者”,“AI利用者”の3つに大別される.LLMを使用してチャットボットを提供する事業者はAI提供者にあたる.
AI提供者はプライバシー保護に関して,プライバシー・バイ・デザインの観点から
“AIシステムの実装の過程を通じて,採用する技術の特性に照らし適切に個人情報へのアクセスを管理・制限する仕組みの導入等のプライバシー保護のための対策を講ずる” [5]必要があると記載されている.
生成AIを利用したチャットボットの運営にはプライバシー保護に関して懸念が存在する.既存の問い合わせ事例を元に学習をするとき,既存のLLMに対しトレーニングデータと別に知識ベースを検索し,参照して応答を作成する検索拡張生成(retrieval augmented generation (RAG))[6]を行うときに入力情報に個人情報が含まれてしまい,生成AIが回答文を出力する際に個人情報を出力してしまう可能性がある.チャットボットを公開して顧客が利用する場合は,利用者が自身の個人情報を入力してしまう可能性がある.
機械学習を使用して入出力された情報に個人情報(personally identifiable information(PII))が含まれているかどうかを検出するAWS Comprehendといったサービス[7]も存在するが,Comprehendの個人情報検出は日本語に対応しておらず,ユーザがカスタマイズすることもできない.日本語での個人情報の検出を自動化することは難しいといえる.本稿ではLLMを個人情報検出に使用する実証も目的であったため,Comprehendを使用しなかった.
また,問い合わせチャットボットである場合,提供しているサービスの実態に即した事実に基づいた返答をする必要がある.しかし,生成AIにはハルシネーションを起こすリスクがあり,間違った返答を事実であるかのように返答する.RAGにより,信頼できるドキュメントを提供してより正確な回答を生成する手法が存在する.
2. 目的
株式会社Urbsでは,学会・国際会議を主なターゲットとした決済,参加者管理オンラインサービスPayventを提供している[8].Payventにはイベント主催者,イベント運営代行業者,イベント参加者,決済事業者など多種の立場の人物が関わり,利用方法が立場によって大きく異なる.そのため,問い合わせ者の立場に合わせた返答を提供する必要があり,問い合わせの返答に要するコストが大きい.また,間違った案内をしてしまう懸念も存在する.
株式会社Urbsは少人数の組織であるため,問い合わせへの返答コストを下げるために生成AIを利用した.
顧客への問い合わせに対し適切な回答をするチャットボットを作成することが最終的な目標である.しかし,RAGを使用して返答精度を高められたとしてもハルシネーションを完全に無くすことは不可能であると考えられるため,本稿では前段としてサポートスタッフが問い合わせに返答する際に返答案を生成することで返答にかかる時間コストを減らすことを目的とした.
既存の問い合わせ情報とヘルプとして提供しているドキュメントや利用規約を元に問い合わせに返答するチャットボットを想定し,以下の生成AIを作成した.
・ 既存の問い合わせ情報から個人情報を除去して匿名化する生成AI
・ 問い合わせ返答を評価するための架空の問い合わせをデータセットとして生成する生成AI
・ ヘルプセンターおよび利用規約,プライバシーポリシーをRAGで検索し,返答を生成する生成AI
・ 上記に加え,個人情報を除去した既存の問い合わせをRAGで検索し,返答を生成する生成AI
全体の生成処理の流れを図1に示す.
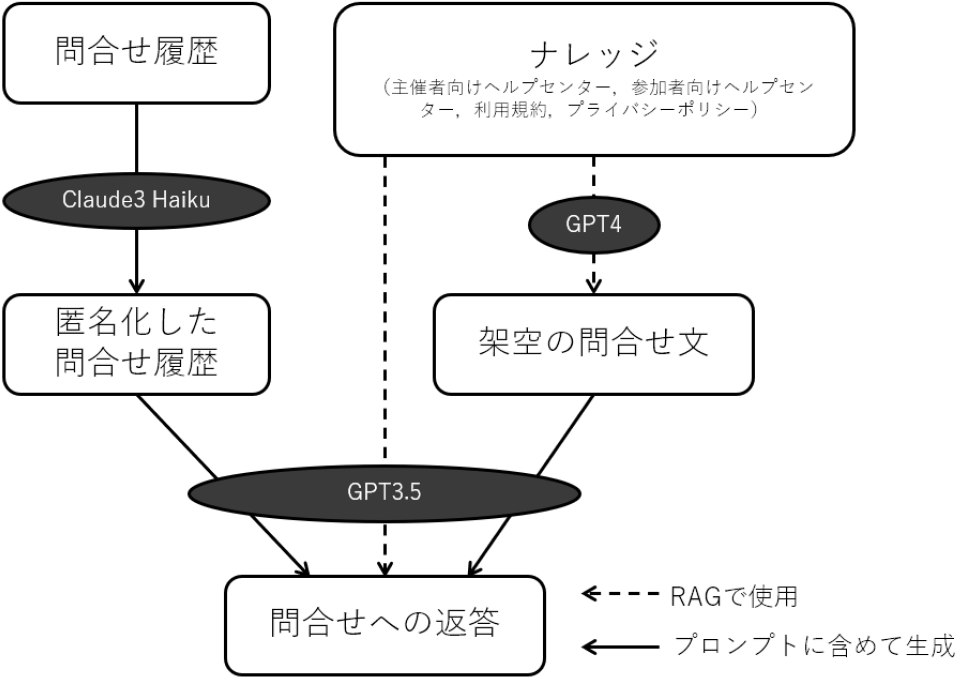
Fig. 1 Overall generation flow.
なお,現段階では社内でのみ使用しており顧客への公開は行っていない.Payventは決済サービスであるため,金銭が絡む問い合わせは誤答による被害が大きいことが予想される.また,返金や不審請求対応など,人の意思決定が必要とされる問い合わせも多く,チャットボットですべての問い合わせに対応することは不可能であると考える.したがって,顧客への公開の際は操作方法や機能,仕様に関する問い合わせのような,返答が一意に定まるものについてはチャットボットが返答し,そうでないものはサポートスタッフにエスカレーションするようにチャットボットに判断させる運用を想定している.
3. 個人情報保護のための匿名化
生成AIを活用するにあたり,既存の問い合わせ情報を利用することを想定した.問い合わせ情報は個別の事例であり,個人名やメールアドレス,電話番号等の個人情報が含まれることから,生成AIチャットボットにそのまま入力してしまうと,チャットボットが回答に個人情報を使ってしまうリスクが存在する.
したがって,問い合わせ情報の履歴から個人情報を除去する試みを行った.なお,個人情報を研究開発に使用することはプライバシーポリシーに記載されている.AWS bedrock [9]を利用してAnthropic Claude3 Haikuを呼び出し,個人情報を削除する試みを行った.
プロンプトは以下のとおりである.発見した個人情報を{項目名}の形に置換させる指示を記述した.temperatureは生成される回答のランダム性の量を指定するパラメーターであり,0.0から1.0の値を取る.文章の創造の際はこの値を上げることになるが,今回は元文章を維持することが求められるため0.0を指定した.System内の{}は入力された問い合わせ文章に置換される.名前の定義はプロンプトに記載していないため,人名の検出はClaude3 Haikuの判断による.

ClaudeではXMLを使用することが推奨されている[10]ため,文章の入力にはXMLを使用し,プロンプト内でXMLタグを参照した.
株式会社Urbsでは問い合わせ情報の管理に株式会社インゲージのRe:lation [11]を使用している.Re:lationが出力したCSVファイルをXMLファイルに変換し,入力に使用した.XMLファイルの形式は以下のとおりである.
<root>
<ticket>
<ticketid>問合せID</ticketid>
<receive>問合せとして受け取った文章</receive>
<send>問合せに返答した文章</send>
</ticket>
</root>
<ticket>は問合せの件数だけ存在し,<ticket>には<receive>タグと<send>タグがそれぞれ0件以上含まれる.チケットの数は150,そのうち返答が含まれたチケットの数は127である.
Pythonを用いたプログラムを作り,<ticket>ごとに上記のプロンプトで個人情報を除去したXMLを生成させた.その後,人間の目視によるチェックで残留する個人情報を確認し除去した.生成AIの出力では,情報の除去精度に加えて元情報からの不必要な改変が含まれる懸念がある.本稿では,問い合わせ1件ごとに個人情報を除去した文章を生成し,都度生成結果に不必要な改変が含まれていないかチェックを行い,文章が改変されていた場合再生成を行った.生成AI出力時点での置換結果と,人間のチェック後の置換結果を以下に示す(図2)(表1).
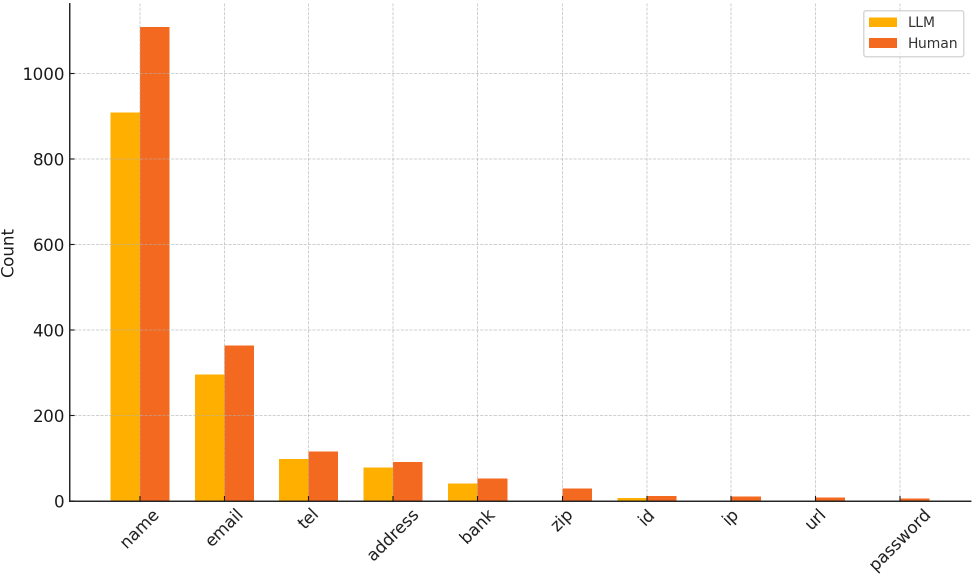
Fig. 2 PII replacements count of generated by LLM and checked by human.
Table 1 PII replacements count of generated by LLM and checked by human.

前述のプロンプトのとおり,指示したものは名前,電話番号,メールアドレス,住所,銀行口座番号であるが,アカウントのIDについては指示に含まれていないにも関わらず置換を行った.人間のチェック後に追加された項目はチェック者の主観による.
名前,メールアドレス,住所,電話番号は具体的な定義をプロンプトで与えたためか精度が比較的高く,80%を超えて生成AIでの除去ができている.銀行口座番号やIDに関しては定義を与えていないにも関わらず60%を超えて除去ができている.
生成AIで置換できず,人間がチェックした際に置換したものを以下に例示する.掲載にあたり一部情報を■に置換した.

林はPayventサポートスタッフの名字である.このような,文字数が少なく一般名詞と同じ名称は固有名であると判断できない場合があり,置換漏れが起こったと考えられる.また,メールアドレスについてはプロンプトの定義と一致するにも関わらず漏れがあった.
置換するようにプロンプトに指示をしたにも関わらず置換できなかったものについては,文単位で判断させるように指示を追加する対応が考えられる.アドレスという単語が文内にあればメールアドレスが近くに存在する可能性が高く,単語が主語である(“が”,“は”が後に続く)場合や挨拶の直後にある場合は固有名である可能性が高いと考えられる.
個人情報の除去前と除去後の比較を以下に例示する.掲載にあたり一部情報を■に置換した.会社名や個人情報は特にメールのフッターに多く含まれている.

個人情報の除去は絶対的に行われなくてはならず,少しでも漏れが発生してしまうことで漏洩リスクが発生するため,いずれの場合でも,人間のチェックは必要となる.
しかし,合計で比較して80%近い個人情報を生成AIで除去することに成功しており,すべてを人間が置換するよりもはるかに人的コストを抑えることができるという知見が得られた.
4. 架空の問い合わせの生成
問い合わせチャットボットを評価するためのデータセットとして,架空の問い合わせを生成する生成AIを作成した.OpenAI APIからgpt-4-turbo-previewを使用した.Payventは前述のとおり様々な立場の人物が利用し,問い合わせ内容も立場によって異なるため,実際の問い合わせに近づけるために,問い合わせ者のペルソナを想定させた.プロンプトは以下を使用した.
このGPTはウェブサービス「Payvent」に来ると思われる問合せ文章を想像してXML形式で出力します.
まず,架空のPayventに対する質問者を想像します.質問者は以下の情報を持ちます.
・法人または個人
・法人の場合,法人名
・質問者名
・業種
・職種
・主催者または参加者
・Payventを既に利用しているか,これから利用しようとしているか
・主催者で既に利用している場合,主催しているイベントの名称
なお,Payventの利用者は学会関係者,国際会議関係者,大学関係者,または学会運営代行会社が多いです.
次に,Payventのwebサイトに掲載している主催者向けヘルプセンター,参加者向けヘルプセンター,利用規約,プライバシーポリシーをそれぞれマークダウン形式のファイルにしてナレッジとしてOpenAI APIのVector Storesにアップロードし,RAG対象とした.以降これらのファイル群およびそれらをRAGのために保存したVectorデータベースをナレッジと呼称する.プロンプトは以下のとおりである.
ナレッジは以下のファイルです.
・プライバシーポリシー.md
・利用規約.md
・主催者向けヘルプセンター.md
・参加者向けヘルプセンター.md
これらはナレッジとして提供されているマークダウン形式のファイルです.
提供されたナレッジの中から日本語のキーワードを1つ任意に選択し,ナレッジからキーワードを検索して,その結果の文章を元にして想定した利用者が問合せすると思われる文章を作ります.
問合せ文章は1つのトピックを含み,3–10個の文の組み合わせから成り,回答するのに充分な情報量を持ちます.
ナレッジの中から日本語のキーワードを選択することで,生成される問い合わせ文が特定のトピックにフォーカスされる.また,ペルソナを先に作成し,問い合わせ者の立場を明確にすることで実際のユースケースに近い文章が生成できた.生成は基本的に生成する件数のみ指定して行ったが,ヘルプセンターの内容を鑑みて不足していると感じたトピックに関しては,キーワードを指定して生成を行った.
生成した架空問い合わせは110件で,具体的な生成例を以下に示す.うち生成結果が英語のものが1件あったため除外した.生成された問い合わせの例を以下に示す.





ペルソナを先に定義させ,ナレッジ内のキーワードを元に架空の問い合わせを生成することで,質問者の立場が明確で,提供サービスに対して適切な質問ができ,実際の問い合わせに近い文章を作成が可能であるという知見が得られた.
5. ナレッジを使用した返答の生成
ナレッジを使用して問い合わせに返答するチャットボットを作成した.OpenAI APIからgpt-3.5-turbo-0125を使用した.利用コストの観点から問い合わせ返答にgpt-4を使用することは困難であった.
プロンプトは以下のとおりである.
あなたは学会向け決済・参加者管理サービスPayventの運営スタッフです.あなたの役割はPayventに来た問い合わせに対して,適切な回答を提示することです.回答は日本語で行ってください.
Payventのドキュメントは”主催者向けヘルプセンター”,”参加者向けヘルプセンター”,”利用規約”,”プライバシーポリシー”にまとめられています.必ず,これらのドキュメントから問い合わせに関連する情報を探し出し,それを元に回答を提示してください.
ドキュメントに記載のない項目や,ドキュメント内に項目を見つけることが出来なかった場合,回答できない旨を示してください.手順や機能を想像しないでください.
回答はサポートスタッフが顧客に向けるような丁寧な文体を心がけてください.
回答の後,ドキュメント内の回答生成のために使用した文章をそのまま引用してください.
プロンプトの後半部はハルシネーションを防ぐためにナレッジに記載されている情報のみを元に回答するよう記述した.ただし,“文章をそのまま引用してください.”と記述したにも関わらずナレッジに記載された文章がそのまま引用されず,文章の元となったファイルへのリンクを示すのみにとどまった.
前項で生成した架空問い合わせ109件に対し回答を生成した.生成された回答例を以下に示す.

6. 生成された返答の評価
前項のチャットボットで生成された返答を人力で定量評価した.評価軸を以下に示す.
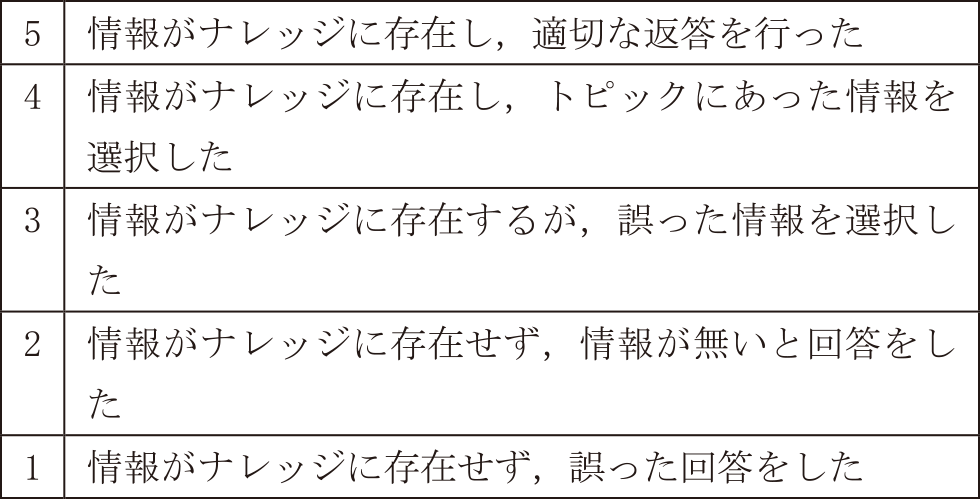
・情報の正確性
正しい情報を見つけ出せるかを5段階で評価した(表2).
Table 2 Evaluating of information accuracy.
ナレッジはすでにPayventのwebサイトで提供している情報であり,追加された機能や問い合わせの多い項目が重点的に記述されている.
・網羅性
問い合わせで質問された内容に的確に答えているかどうかを3段階で評価した(表3).
Table 3 Evaluation of comprehensiveness.

・自然さ
返答文が日本語として自然かどうかを3段階で評価した(表4).文意は問わない.
Table 4 Evaluation of naturalness.
・明確さ
内容の理解のしやすさを示す(表5).専門用語を説明せずに使用した場合,回答に無関係または不要な情報が含まれている場合は質問者を混乱させるため評価を下げた.
Table 5 Evaluation of clarity.

評価は株式会社Urbsに所属する3人で行った.評価結果を表6に示す.
Table 6 Evaluation of answers generated by RAG from Help Center, Terms of Use and Privacy Policy.
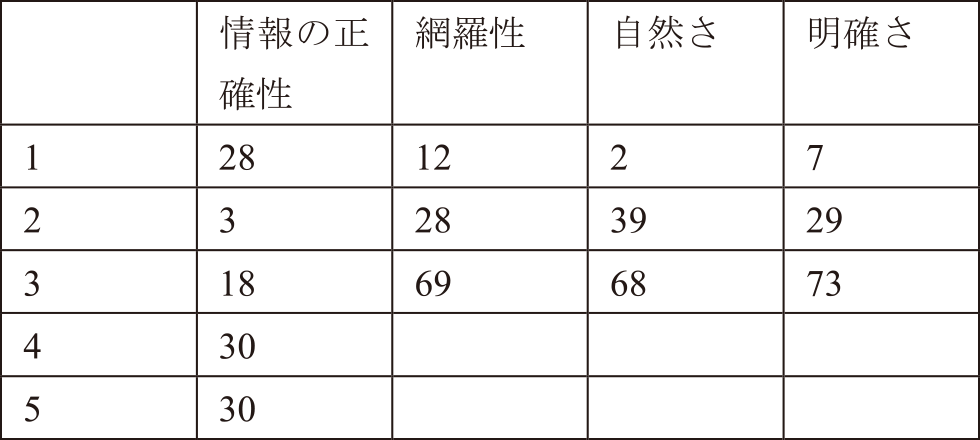
情報の正確性については,ナレッジに記述の無い項目について誤った情報から回答を生成してしまう(評価1)や,記述があるにも関わらず間違った情報から回答を生成してしまう(評価3)ものが目立った.
網羅性については質問文に含まれるすべての質問に回答していないものや,一部の質問の要旨を間違ったものを評価2とした.
自然さについては使用したLLMのモデルに依拠する.プロンプトで生成AIの立場“運営スタッフ”を明確にし,問い合わせの返答文を生成するように指示したにもかかわらず,回答文が第三者からの視点で書かれているものや,文章のつなぎが不自然なものは,評価2とした.
明確さについては概ね良好な結果を示したが,評価を2としたものは余分な情報を記載していることが多かった.特に,銀行振込についての質問の場合に質問に対する返答に加えて返金について答えてしまう傾向がみられた.これは,銀行振込での参加費受付に関して過去に振込先の間違い,振込金額の間違いといったトラブルが多く,ヘルプセンターの銀行振込に関する記述が返金について案内しているものが多いことによる.
以下に内容について評価が低かった回答の例をいくつか抜粋して示す.

この回答は情報の正確性を1とした.記載されている写真の条件は登録時の本人確認書類に関するものであり,“ファイルのアップロード”という状況でのみナレッジを検索しており,誤った回答である.

この回答は情報の正確性を1とした.支払い方法を後から変更することは不可能であり,支払方法の変更についてはナレッジに一切記載はない.

この回答は網羅性を1とした.質問文は参加者の立場であるのに対し回答で主催者の管理画面について記述されている.また,記載の方法は主催者の売り上げを銀行口座に入金する際の方法であり,銀行振込決済とは異なる.
これらの評価から,RAG対象とするドキュメントが充分に網羅されていても情報の偏りにより検索結果に影響を及ぼしてしまう知見が得られた.ナレッジベースをより構造化し,トピックごとの記述量の偏りをなくすことで改善することができると考える.また,プロンプトについては,回答例を提示するFew-Shotプロンプティングが改善案として考えられる.
また,類似した用語が別の文脈で使われている場合に混同してしまう例がみられた.具体的には,イベント主催者が売上を主催者の銀行口座に振り込む“入金”と,イベント参加者が銀行振込決済をする場合に参加費を振込“入金”を混同した.上述の偏りと合わせて,売り上げの入金について質問した場合に混同したうえで参加費の返金についての記述が追加されてしまうといった例があった.
7. 問い合わせ履歴を使用した返答の生成
ナレッジを使用して問い合わせに返答するチャットボットは多くの場合正しい情報を選択し,回答文として自然な日本語で返答を生成することができた.ナレッジに加え,前項で作成した個人情報を除去した問い合わせ履歴をRAG対象にすることで,既存の問い合わせ事案も参考にしてより精度の高い回答を生成させることを目指した.使用モデルは前項と同じくOpenAI APIからgpt-3.5-turbo-0125を使用した.ClaudeはXMLを扱うことに長けていたが,OpenAI APIで利用できるファイル形式にXMLが含まれていなかったため,json形式に変換しinquiries.jsonとしてアップロードした.
問い合わせ履歴も含めた返答の生成は,ナレッジと問い合わせ履歴の情報を分けて検索したうえでソースを元に条件分岐した手順が必要になる.以下の3パターンのプロンプトを用意して生成を試みた.
・ 問い合わせ履歴とナレッジを合わせて検索して回答を生成する
・ 問い合わせ履歴をまず探して見つからなかった場合ナレッジを検索して生成する
・ ナレッジをまず探して見つからなかった場合問い合わせ履歴を検索して生成する
各プロンプト共,役割の指定や文体の指示は前項の“ナレッジを使用した返答生成”と共通であるが,ナレッジおよび問い合わせ履歴を検索する指示が異なる.異なる部分を抜き出して以下に提示する.



回答の生成に利用した質問文は問い合わせ履歴のものと架空問い合わせから以下の条件で選択した.
・ 問い合わせ履歴とナレッジ双方に記述がある質問4件
・ 問い合わせ履歴に記述が存在するがナレッジに記述がない質問5件
・ ナレッジに記述が存在するが問い合わせ履歴に記述がない質問3件
・ 問い合わせ履歴とナレッジどちらにも記述がない質問5件
問い合わせ履歴に記述がある質問は実際に返答を行ったため実際の問い合わせ文を使用し,問い合わせ履歴に記述がない質問は前項で生成した架空の問い合わせ文を使用した.
なお,inquiries.jsonにはRe:lationのファイル出力の制約上回答が全文記録されていないものが存在した.問い合わせ履歴に回答が全文含まれていない質問を行った場合,質問文を見つけることができても回答例が存在しないため,“過去に事例があった”と紹介するような回答を生成することがあった.そのため,返答を生成させる質問は回答が全文記録されているものを選択した.
いずれのプロンプトでも,問い合わせ履歴とナレッジを使用して回答を生成することができ,ナレッジに加え問い合わせ履歴をRAG対象にすることで回答を改善できるという知見が得られた.
問い合わせ履歴に存在するがナレッジに記述がない質問では,問い合わせ履歴から返答事例を見つけて正しい回答を提示し,返答が改善された.
ナレッジに存在するが問い合わせ履歴に記述がない質問では,ナレッジのみで生成したときと同等の回答を提示した.
しかし,問い合わせ履歴とナレッジどちらにも記述がない質問に関しては,いずれのプロンプトでも間違った情報を提示してしまう例がみられた.
問い合わせ履歴,ナレッジ双方に記載のある質問文では,検索する順番の指定に従わない返答がみられた.問い合わせ履歴を先に探すよう指示したプロンプトであっても,双方の文章を引用して回答を生成した.
以上のプラクティスから,RAG対象のドキュメントを網羅的に検索することはできるが,検索する順番の指示は難しいと考えられる.
また,問い合わせ履歴に類似事例を発見できたかどうかにかかわらずナレッジを検索して,両方の情報を使用して回答を生成するようなプロンプトを記述した場合に,“ナレッジの内容を精査せず,問い合わせ履歴のみで回答してしまう”という現象もみられた.
さらに,問い合わせ履歴から生成した回答をA,ナレッジから生成した回答をBとして回答A,回答B両方を記載せよとプロンプトに記述した場合,手順が複雑になりすぎたためか,回答A,回答Bを記載しわけることができなかった.
モデルをgpt-4-turbo-previewに切り替えた場合は回答A,回答Bを記載しわけることはできたが,問い合わせ履歴からの生成とナレッジからの生成を混同してしまい,回答Bに問い合わせ履歴の情報を使用して答えてしまう現象がみられた.
8. 課題と活用
本稿では,個人情報が含まれる問い合わせ履歴とヘルプセンターを活用して適切な返答を生成するチャットボットの開発を試みた.
個人情報の除去の試みでは,プロンプトに記載した個人情報の定義が不十分であった.特に,住所の定義を「”県”や”市”といった文字が含まれる」としたが,“市場”,“県営”といった住所ではない文字列を誤検出する可能性がある.また,“都道府区町村”といった文字が含まれていれば住所である可能性が高いが今回は未対応であった.人名と地名が同一である場合もある.これらを正しく検出するための対策として,プロンプトに前後の文章を考慮するように指示することが考えられる.たとえば,単語の前後の文章から判断して当該の単語が主語である場合人名の可能性が高く,郵便番号や番地といった数字が前後に存在する場合は住所である可能性が高い.文内に“都道府県市区町村”のいずれかの文字が連続して出現する場合住所である可能性が高い.これらの指示で,単語そのものでは個人情報であるかどうかの判断が難しい場合でも検出精度を高められると考えられる.
個人情報保護については,生成AIでは完全な匿名化を保証することはできず,不十分であった際の責任問題もあるため,どれだけ精度を高めたとしても人の手による確認,修正は必須である.また,どこまでの個人情報を保護するべきかの要件は時代に合わせて変化していくため,長期的に継続してプロンプトに記述する個人情報の定義を更新していく必要がある.
本稿の試行では生成AIによって80%近くの個人情報を除去できた.現時点でもすべてを人の手で除去するよりも大きく労力を下げることができている.前述したプロンプトの改善で検出精度を高めることはできると考えるが,生成AIの精度目標は高いほど大きなコストがかかる.本稿の見解では生成AIによる個人情報の除去はあくまで人による除去の補助と考え,生成AIでは電話番号やメールアドレス等の定義が明確なものをより確実に検出できるようにし,個人情報の定義の継続的な更新および,生成AIによる除去後のチェック,漏れの修正は人の手で行っていくのが望ましい.
生成された回答の中には,問い合わせ履歴にもナレッジにも基づかない誤った情報を含むものがあった.記述の無い項目を無いと答えるのは,記述を見つけるよりも難しいと考えられる.回答の網羅性が不足しており,問い合わせのすべての質問に対して回答できていない例が多くみられた.
RAG対象のドキュメントの記述が充分に網羅している項目であっても偏っていると検索結果もそれに伴い偏ってしまう現象がみられた.例として,ヘルプセンターに記載されている銀行振込に関する項目は返金に関する記述がほとんどであり,銀行振込について聞くだけで返金についても追加で答えてしまうことがあった.
また,ヘルプセンターの記述で,違う文脈で同じ文言が使われている場合にRAGが混同してしまう現象がみられた.例として,ヘルプセンターでは“入金”という言葉が売り上げの入金と銀行振込の参加費の入金の2パターンの記述が存在した.同様に,参加者の立場での質問文に対し主催者向けヘルプセンターの記述から回答を生成してしまう現象や,質問文に含まれる単語の記述はあるが異なる内容の項目から回答を生成してしまう現象がみられた.人間のサポートスタッフは文脈から適切な返答が可能だが生成AIが判別することは難しいと考えられる.
これらの課題は,RAGでのドキュメントの検索に原因があると考える.永江らは,章で区切られたドキュメントを検索する際に,単一の章を検索単位とするよりも,近隣の3つの章を検索単位とするほうが回答生成の性能があがったと報告した[12].このようなドキュメントの検索範囲の設定や,ナレッジの偏りをなくし,より構造化するといったドキュメントの前処理段階での改善で生成する回答の質を向上できると考えられる.
質問者の立場によってナレッジ内のヘルプセンターのファイルを分けていたにもかかわらず,プロンプトの指示ではまとめて“ナレッジ”として扱ってしまったことも原因として考えられる.質問者の立場によって検索対象のファイルを指定するように指示することでも回答の質を向上できる可能性がある.さらに,異なる項目で意味の似た単語(銀行振込決済の代金の“入金”と売上の主催者口座への“入金”など)を使用しないようにヘルプセンターの記述を変更することでナレッジの検索結果に異なる項目が混同されることは回避できると考えられる.
今回の試行ではナレッジを使用した生成AIを人間の手で定量評価したが,この方法は問い合わせ数が増えるほどに人的,時間的コストが高くなるため,RAGの評価の自動化が求められる.評価の自動化により,同じ質問に対して複数回回答させた結果を評価して回答の揺れについても評価することが可能であると考える.RAGの評価を自動化する手法としてはRAGAS [13]が存在する.
試行で判明した業務の改善案としては,ヘルプセンターに追記が必要な情報の洗い出しや記述ミスの発見ができたこと,架空の問い合わせを実際のサポートスタッフが答えるトレーニングに使用できることがあげられる.
Payventのヘルプセンター内の項目には,文章での説明が不足しておりスクリーンショットを読み取る必要がある項目があり,画像をRAG対象に含められないことにより当該項目に関する質問では回答の生成に支障をきたした.副次的に,音声でブラウジングしている閲覧者などの画像を読めない環境で問題があることが判明した.
顧客による個人情報の入力リスクや誤回答リスクがあるため,現段階では社内のみの活用にとどまっているが,今後チャットボットを顧客に向けて公開しサポート業務の自動化を目指す.
謝辞 株式会社Urbs関係者ならびにPayventを利用していただいた皆様に,謹んで感謝の意を表する.
参考文献
- [1] Meta: Meta Llama(オンライン)入手先〈https://llama.meta.com/〉(参照2024-05-11).
- [2] ANTHROPIC: Introducing the next generation of Claude(オンライン),入手先〈https://www.anthropic.com/news/claude-3-family〉(参照2024-05-11).
- [3] OpenAI: GPT-4 | OpenAI(オンライン),入手先〈https://openai.com/index/gpt-4/〉(参照2024-05-11).
- [4] 総務省 経済産業省:AI事業者ガイドライン(第1.0版), p.5 (2024).
- [5] 総務省 経済産業省:AI事業者ガイドライン(第1.0版), p.32 (2024).
- [6] Amazon Web Services: RAGとは何ですか?(オンライン),入手先〈https://aws.amazon.com/jp/what-is/retrieval-augmented-generation/〉(参照2024-05-11).
- [7] Amazon Web Services: PIIエンティティの検出(オンライン),入手先〈https://docs.aws.amazon.com/ja_jp/comprehend/latest/dg/how-pii.html〉(参照2024-05-11).
- [8] 株式会社Urbs: Payvent(オンライン),入手先〈https://payvent.net/〉(参照2024-05-11).
- [9] Amazon Web Services: Amazon Bedrock(オンライン),入手先〈https://aws.amazon.com/jp/bedrock/〉(参照2024-05-11).
- [10] ANTHROPIC: XMLタグを使用する(オンライン),入手先〈https://docs.anthropic.com/claude/docs/use-xml-tags〉(参照2024-05-11).
- [11] 株式会社インゲージ:Re: lation(オンライン),入手先〈https://ingage.jp/relation/〉(参照2024-05-11).
- [12] 永江尚義,吉田尚水,小林優佳,久島務嗣,岩田憲治:マニュアルの章構造にロバストなマニュアル検索技術,人工知能学会研究会資料 言語・音声理解と対話処理研究会,人工知能学会,p.190(2023)
- [13] Shahul Es, Jithin James, Luis Espinosa-Anke, Steven Schockaert.: RAGAS: Automated Evaluation of Retrieval Augmented Generation, arXiv: 2309.15217, pp.1–2

dt22a001@oecu.jp
大阪電気通信大学大学院.株式会社Urbs.

大阪電気通信大学総合情報学部.
採録日 2024年8月27日