行政DXに適した検索拡張生成システムの開発と実証実験による検証
Development of RAG System for Digital Transformation of Local Government and Its Verification with Demonstrative Experiment
1. はじめに
本研究は,AichiXTechという愛知県と企業等の連携による事業の一環として実施されており,県庁内の各所属が抱える行政課題に対し,ICTを活用して解決することを目指す[1].現代の行政業務は複雑かつ迅速な意思決定を要求される場であり,情報アクセスの効率化は不可欠である.愛知県庁都市交通局航空空港課では,管理・運営に関わる業務やルールは法規・規程等の文書集として2TB以上のデータ量で蓄積されている.幹部職員に提出する資料作成や,民間事業者等からの問い合わせへ回答作成などにおいては,過去の実例などを参照する必要がある.
その際に,現状ではOSのキーワード検索機能や,フォルダ名やファイル名からあたりをつけてファイルを1つずつ閲覧していくなどの手段を使っている.こういった既存の情報検索手法では蓄積された文書から適切な情報を見つけ出すのに多大な時間と労力が必要である.特に文書ファイルの保存形態が統一されていない現状では,職員個人の経験や知識に依存した非効率な作業となりがちである.そこで,本研究では過去の行政資料に効率的にアクセスでき,その内容を把握できるシステムを目指す.そのためには,検索した文書の内容をそのまま出力するシステムよりも,LLMを用いて説明や要約を生成する検索拡張生成(RAG; Retrieval-Augmented Generation)システムのほうが適している.
検索拡張生成AIでは,事前に外部情報となるテキストを分割することが必要となる.これはプロンプトに入れられる文字数に制限があることと,埋め込みベクトルを生成するテキストにも文字数に制限があるからである.そして,その際の適切な分割文字数は未だに確立されていない.本研究では,異なる分割文字数による検索精度と回答精度への影響を分析する.
2. 関連研究
RAG(Retrieval-Augmened Generation)[2]は,外部情報を検索することで,LLMに独自の文書を参照した回答を生成させることができる.一般的なRAGの手法は,入力クエリの埋め込みベクトルと類似度の高い外部情報を抽出し,それをLLMに与えるプロンプトに追加するものである.ゼロショットで外部の情報にアクセスできる優位性から,法学[3],農学[4],数学[5]や物理学[6]など,多様な分野での応用が期待されている.本研究では,地方行政におけるRAGの有効性を検証する.
Multi-Meta-RAG [7]は,LLMを用いてメタデータを抽出することでRAGの精度向上させている.本研究では時系列メタデータに特に着目した.これにより,時系列情報が重要な行政業務におけるRAGの精度向上を目指した.
RAGの性能の評価方法に関する議論も行われおり,RAGAS [8]やARES [9]などの自動評価フレームワークが発表されている.本研究では,被験者に問題を解いてもらうことで,実際の行政業務に似た状況での評価を行った.
3. 課題と提案手法
行政文書を対象としたRAGを開発するうえで解決すべき課題と提案手法について述べる.
3.1 時系列情報
課題:更新され続ける行政の法規・規程の中では,同一テーマに関連する文書群に対して時間的に前後する情報が別文書に混在している.そのため,1つの問いに対する答えが複数の文書に分散して記述されているケースが頻繁にあり,それらを総合的・横断的に参照する必要がある.よって,時系列情報の整理と把握は,行政文書を扱うRAGシステムにおいて重要な要素であると考えた.また,RAGシステムにおいては文書全体を一括で検索するのではなく,文書を分割したテキストセグメントごとに検索する.この際,検索されたテキストセグメントに含まれていない時系列情報が,同一文書内の検索されなかったテキストセグメントに含まれている場合がある.
提案手法:文書全体から時系列に関する日付情報等をLLMで事前に抽出する.その際のプロンプトを図1に示す.その日付情報をLLMに与えるプロンプトに追記することで,未検索のテキストセグメントに記述された時系列情報を考慮することができると考えた.文書には通常,作成年月日がメタデータとして付与されているが,それはあくまで作成日時を示すものであり,文書内の具体的な日付情報(法改定の施行日や,イベントの実施日程など)を示すものではない.本文中に重要な時系列情報が記されていることが多く,作成年月日のメタデータだけでは,物事の時系列全体を捉えることは難しい.

Fig. 1 Prompt for acquiring temporal information.
具体例:説明のために架空の行政文書を図3に示す.また,簡単のために段落をひとつのセグメントとし,左側にセグメント番号を丸囲み数字で①から⑤と記した.そして「XX県立中央図書館移転基本計画の概要を教えて下さい」というユーザクエリに対してセグメント①,④,⑤がRAGシステムに参照されることを想定する.この場合,セグメント②,③に含まれる重要な時系列情報が欠落する.また,セグメント③が参照されないことで,セグメント④の「翌年」という表現が何年を指すのか不明確になる.
図3の文書に対して図1のプロンプトを用いて時系列情報を抽出すると図2のような結果になることが想定される.②,③に記述されている時系列情報を太文字で示す.これにより,RAGシステムが参照しないセグメントの時系列情報を加味することが可能になる.

Fig. 2 Example of temporal information extraction from a synthetic document.

Fig. 3 Sample image of a synthetic administrative document.
3.2 テキスト分割
課題:RAGでは外部情報をプロンプトに加えるために,事前に外部情報となる文書から埋め込みベクトルを生成して,そのベクトルに基づいて関連する文書を検索する.しかし,特に行政文書などの長いテキストの文書の情報を1つのベクトルで捉えきることは難しい.一般的な解決策は長いテキストを一定の基準で分割することであるが,その際の適切な分割文字数は未だに確立されていない.
提案手法:本研究では,固定文字長によるチャンキングを行う.分割文字数は100文字,500文字,1000文字,2000文字,4000文字とし検索精度を比較することで最適な分割文字数を検証する.これは使用するtext-embedding-ada-002のトークン数上限が8192トークンであるためである.また,分割する際に文脈を維持するために分割文字数の20%のオーバーラップを設ける.固定長分割を採用した理由は,行政文書のように形式が様々であっても,一貫した方法でテキストを分割することができるからである.章,節,段落などの区切りを利用してテキストを分割する手法も存在する.しかし,このような文構造に基づいた分割では形式が様々な行政文書において,各セグメントの分割文字数に大きな差異が生じる可能性がある.Levyら[10]やPawarら[11]により,各セグメントの分割文字数が大きく異なるとき,RAGの精度が下がることが示されている.
4. 実装
RAGはまず,入力されたクエリに基づいて,関連性の高い文書をデータベースから検索する.この検索は,埋め込みベクトルのコサイン類似度によって行われ,最も類似度の高い文書を特定する.検索された文書に基づくプロンプトを使用して,LLMがクエリに対する回答を生成する.システム構成図を図4に示す.テキストの埋め込みベクトルモデルにはOpenAIのtext-embedding-ada-002を用い,LLMにはOpenAIのgpt-4-1106-previewを使用した.
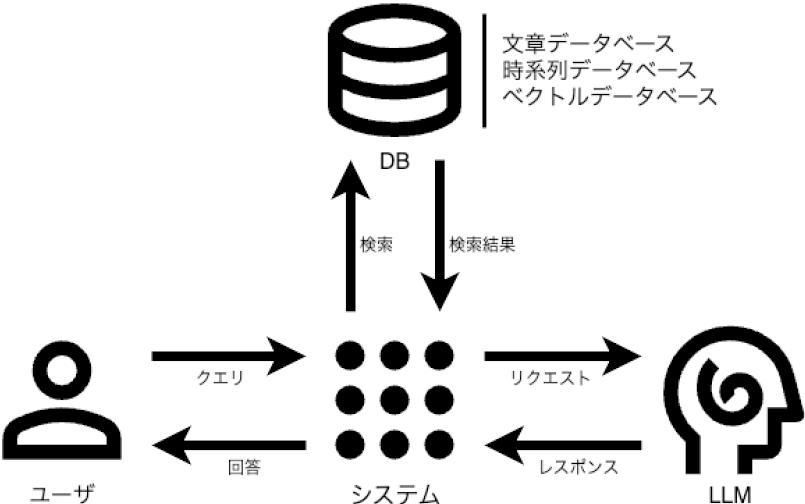
Fig. 4 System architecture diagram.
4.1 情報検索:Retrieval
ユーザのクエリから生成された埋め込みベクトルを用いて,ベクトルデータベース内でコサイン類似度に基づく類似ベクトルを検索する.ベクトルデータベースにはPineconeを用い,近似最近傍探索(Approximate Nearest Neighbor Search; ANN)によるコサイン類似度に基づく検索を行う.検索上位のものからリストに追加される.
4.2 回答生成:Generation
プロンプトの生成プロセスを示す.情報検索によって検索された参考文書と時系列情報を統合して,プロンプトを動的に生成する.初めに,クエリに類似するテキストセグメントをコサイン類似度に基づいて検索する.検索結果が上位のテキストセグメントからプロンプトに組み込む.同一文書内の連続するテキストセグメントは重複するオーバーラップ部分をまとめて追加する.同一文書内の連続しないテキストセグメント間には(・・・中略・・・)を挿入する.そして,設定した制限文字数に達するまでこのプロセスを繰り返す.このようなプロセスにより生成されたプロンプトの例を,図5に示す.

Fig. 5 Prompt for response generation.
4.3 ユーザインタフェース
ユーザインタフェース(図6)ではユーザは,クエリと状況(任意)を入力する.ユーザのクエリでは,具体的に質問したり命令を出したりする.ユーザの状況には,クエリの背景や経緯を入力する.状況の入力は任意であり,システムはクエリのみ入力でも動作する.しかし,ユーザの状況を入力することで,検索の精度が向上し,ユーザの認知負荷の低減に繋がると考えた.
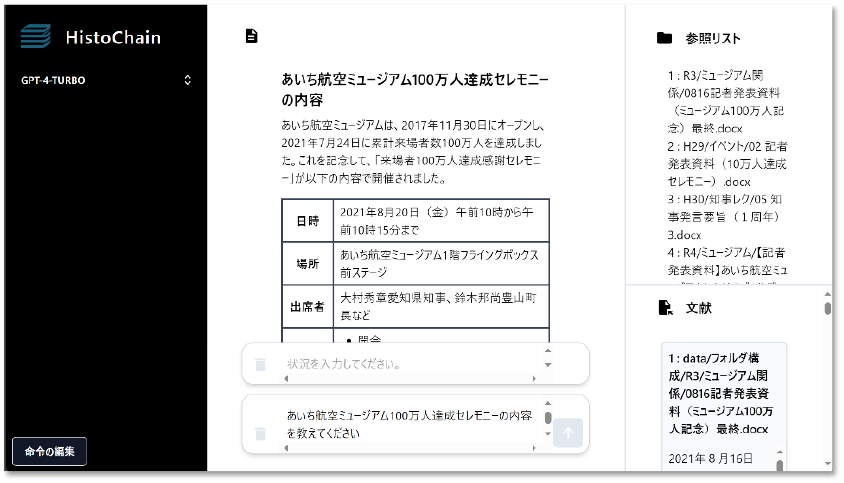
Fig. 6 User inteaface.
5. 回答精度
5.1 実験方法
一問一答形式を用いて,正答率,作業時間および回答への信頼度を調べる.被験者に行政に関する問題を与え,正解が記述されたファイルを探し,回答するという実験を行った.また,本実験は愛知県庁都市交通局航空空港課にて実施した(図9).実験で使用したファイルは実際の行政業務で作成されたものであり,ファイル数は164である.
担当課の行政職員(事前知識あり・行政経験あり)と他課の行政職員(事前知識なし・行政経験あり)と学生(事前知識なし・行政経験なし)の各カテゴリから3人ずつ,合計9人を被験者とし,3つのグループに分ける.各グループは異なるカテゴリの一人ずつから構成される.全9人という人数は統計的に充分とは言えないが,本実証実験事業に関与する部署の人数的制約のため,これ以上被験者を増やすことは不可能であった.問題セットは短答式問題5問,記述問題3問で構成され,これを3セット用意する.各グループは手作業,100文字分割によるRAGシステム,4000文字分割によるRAGシステムの3つの異なる手法で問題セットに取り組む.グループと問題セットを振り分け,問題の難易度によるバイアスを考慮に入れる.問題セットは事前に被験者以外の担当課の行政職員が作成し,すべての問題は必ずいずれかのファイルに解答が記述してある.
短答式問題は数値や名称など明確な答えがある問題であり,正解か不正解かで評価する.記述問題は背景や経緯,理由などを含めて問う問題であり,以下4つの項目に基づき,担当課の行政職員が7段階評価を行う.
- (1) 回答の正確性:被験者の回答がどれだけ正確であるかを評価する.正確性は事実,データ,論理的根拠が正しいかどうかに基づく.
- (2) 回答の完全性:問題に対しどれだけ完全な回答であるかを評価する.完全な回答とは,問題のすべての側面に対処し必要な情報を含んでいることを意味する.
- (3) 背景,経緯,理由の正確性:被験者が問題の経緯や背景,理由をどれだけ正確に説明しているかを評価する.
- (4) 背景,経緯,理由の完全性:被験者が問題の経緯や背景,理由をどれだけ完全に説明しているかを評価する.
作業時間は問題を開始してから回答を終了するまでの時間で,問題ごとに計測する.手作業では,OSのキーワード検索機能や,フォルダ構成などに基づき,実際にファイルを開いて問題に取り組む.システム使用時は,システムの精度を測定するために,被験者にはシステムの出力結果をそのまま信頼して回答してもらう.すなわち,ファイルを開いてシステムの解答の正当性を確認することはしない.また,作業後に自分の回答が信頼できるかどうかを7段階で評価してもらう.「全く信頼できない」が0であり,「非常に信頼できる」が6となっている.
以下に,図3を題材にした架空の短答式問題例と記述問題例を示す.実事例ではなく架空の例にしているのは,本実証実験を実施する条件でもあった秘密保持のためである.
短答式問題例:
問題: XX県立中央図書館移転基本計画により決定した移転先はどこですか?
回答: YY市ZZ駅前WW街区
記述問題例:
問題: XX県立中央図書館の移転計画について,2012年の検討開始から2015年の基本計画策定までの主な経緯はどのようなものですか?
理想の回答: 2012年に既存施設の老朽化問題が顕在化し,移転検討開始.2013年4月就任の新知事が「文化施設の充実」を公約に掲げ,具体的検討進行.同年6月「図書館機能検討プロジェクトチーム」設置,9月に県民アンケート実施.2014年,有識者会議が中間報告で駅前移転を提言.その後パブリックコメント実施し,2015年3月「XX県立中央図書館移転基本計画」策定・公表.
5.2 実験結果
5.2.1 短答式問題の正答率:
表1に短答式問題の正答率を示す.担当課職員と他課行政職員において,手作業,100文字分割システム,4000文字分割システムを用いた正答率に大きな差はみられなかった.学生において,手作業時の正答率53.3%と比較して,システム使用時に正答率が33.3から40.0ポイント増加し,4000文字分割にて93.3%の正答率となった.
Table 1 Correct answer rate of short-answer questions.
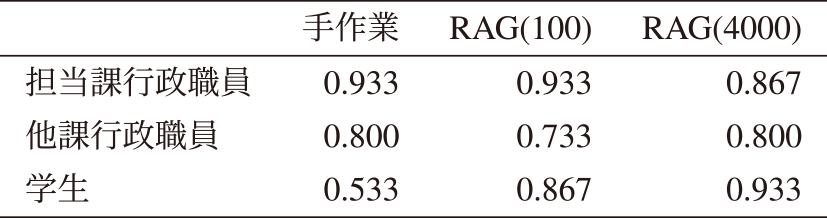
また,手作業時の担当課行政職員の正答率93.3%と学生の正答率53.3%には40.0ポイントの差があった.しかし,システム使用時はその差は−6.7から+6.7ポイントの範囲となり,正答率の差が縮小した.4000文字分割システムを使用時には学生の正答率が最も高くなった.
5.2.2 短答式問題の作業時間:
表2に短答式問題の作業時間を示す.担当課行政職員は23.6%から25.1%,他課行政職員は75.9%から77.6%,学生は77.4%から79.8%の作業時間削減を達成した.
Table 2 Working time of short-answer questions.

図7に正解時,図8に不正解時の作業時間を示す.担当課行政職員と学生においては,手作業では正解時よりも不正解時において作業時間が長くなり,システム使用時では不正解時において作業時間が短くなる傾向がみられた.
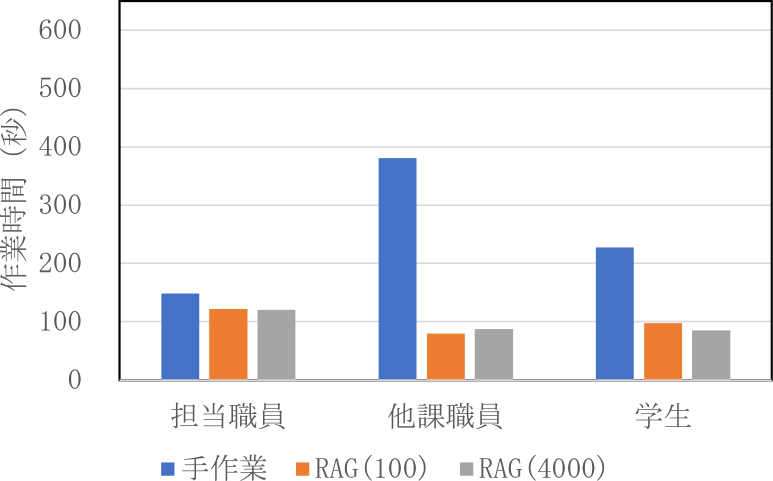
Fig. 7 Working time of short-answer questions when answers were correct.
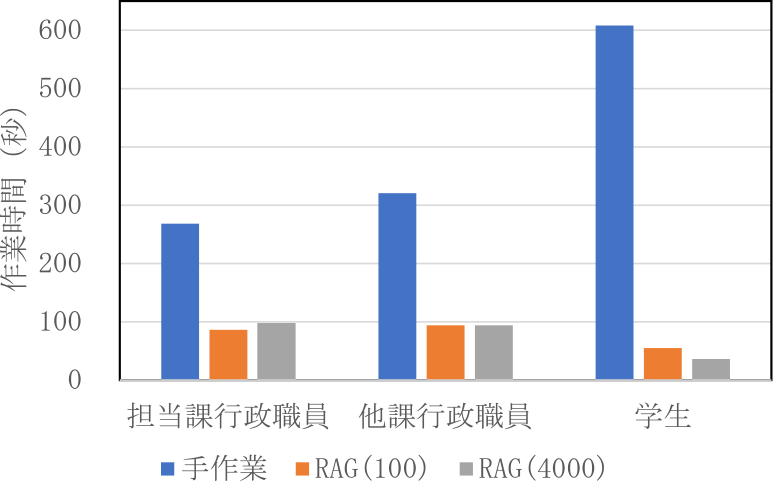
Fig. 8 Working time of short-answer questions when answers were incorrect.

Fig. 9 Overview of the demonstration experiment.
5.2.3 短答式問題の信頼度:
図10と図11に短答式問題の信頼度の結果を示す.担当課行政職員は,手作業時において正解時の信頼度平均4.93から不正解時の信頼度平均2.00となっており,著しく低下した.学生も同様に手作業時において,正解時の信頼度平均5.63から不正解時の信頼度平均3.29となっており,著しく低下した.しかし,担当課行政職員も学生も,システム使用時は正解時と不正解時の信頼度に大きな差はみられなかった.他課行政職員は手作業,システム使用時ともに不正解時の信頼度が著しく低下した.
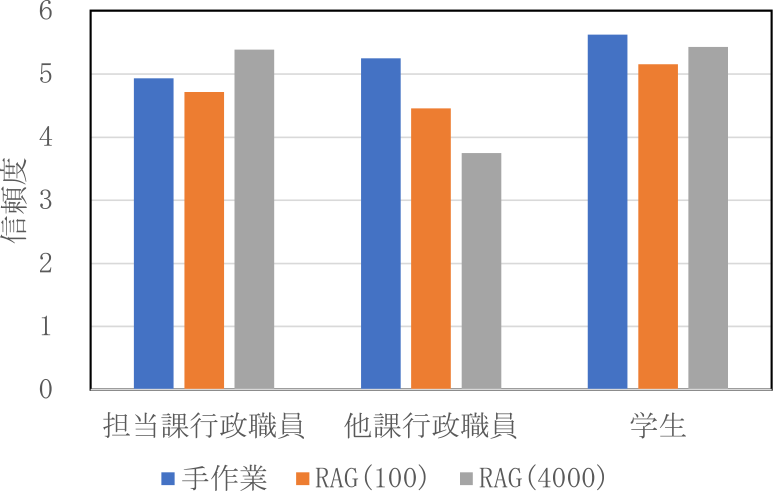
Fig. 10 Confidence of short-answer questions when answers were correct.
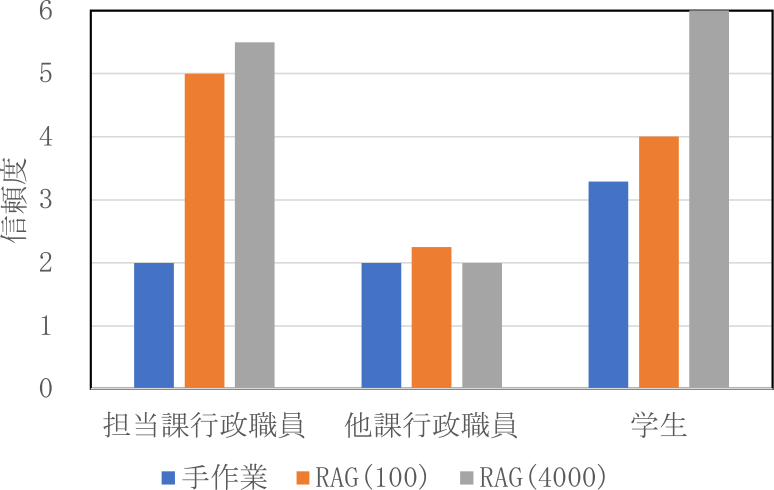
Fig. 11 Confidence of short-answer questions when answers were incorrect.
5.2.4 記述問題の評価:
回答の正確性を表3,回答の完全性を表4,背景,経緯,理由の正確性を表5,背景,経緯,理由の完全性を表6に示す.担当課行政職員,他課行政職員,学生がすべての評価項目において手作業時が最も高くなった.
Table 3 Accuracy of responses.

Table 4 Completeness of responses.

Table 5 Accuracy of background, context and reasons.

Table 6 Completeness of background, context and reasons.

5.2.5 記述問題の信頼度:
図12と図13に被験者が見積もった記述問題の信頼度の結果を示す.行政職員は高評価時に信頼度を高く,低評価時に信頼度を低く見積もる一方,学生は高評価時も低評価時も信頼度を同程度に高く見積もった.これは学生が自身の回答の信頼度を正しく見積もることができていないことを示す.また,行政職員の見積もる信頼度はシステム使用時のほうが高くなった.
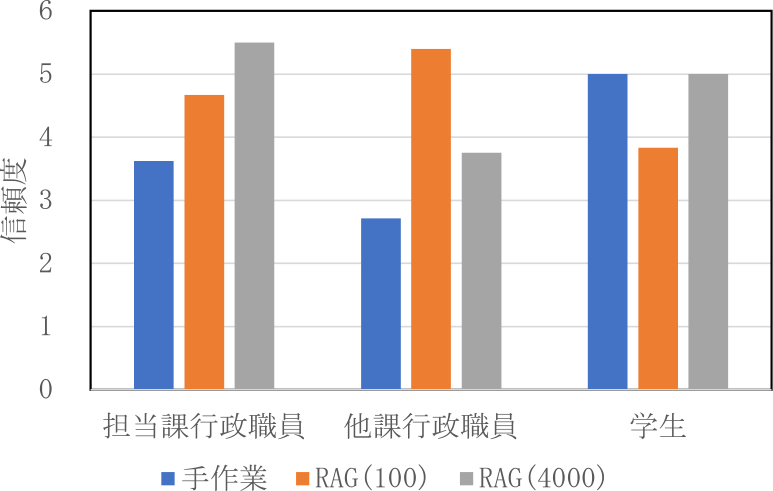
Fig. 12 Confidence of descriptive questions when answers' average evaluation was 4.0 or above.
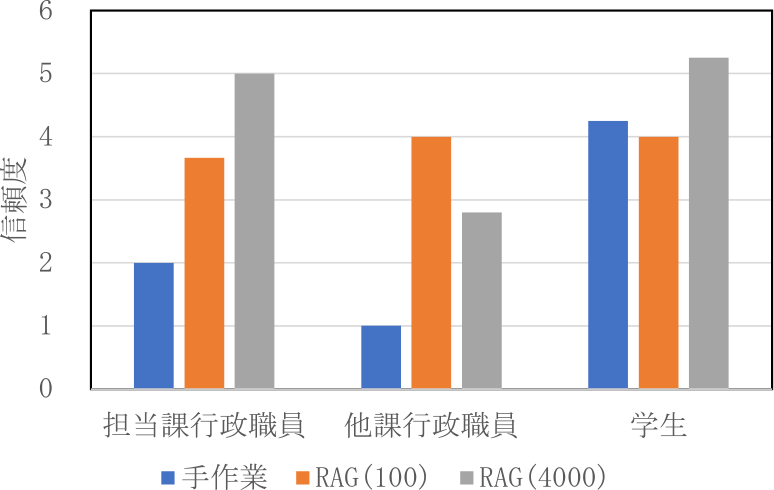
Fig. 13 Confidence of descriptive questions when answers' average evaluation was below rating 4.0.
5.2.6 平均作業時間と平均システム使用回数の比較:
図14と図15に平均作業時間と平均システム使用回数に関する結果を示す.
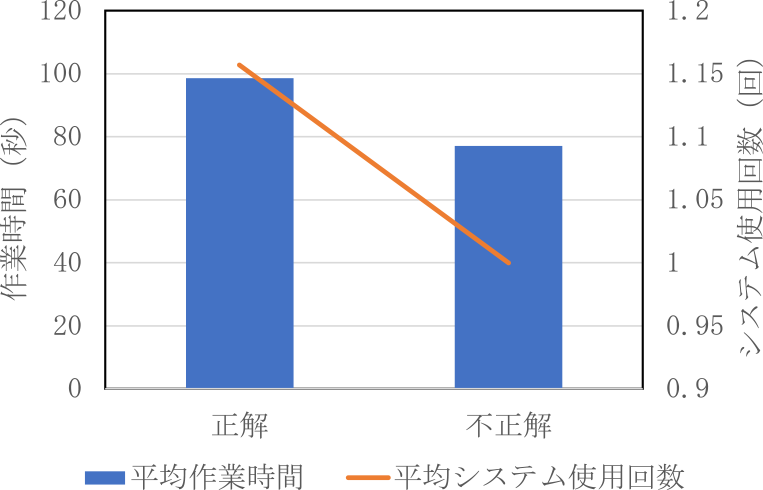
Fig. 14 Working time of short-answer time and system uses.
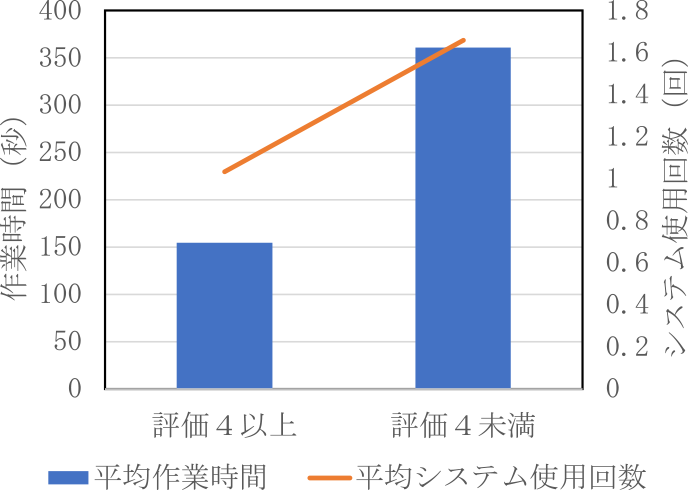
Fig. 15 Working time of descriptive questions and system uses.
5.3 考察
5.3.1 短答式問題の正答率
学生のみがシステムの使用により正答率を大幅に向上させたことが分かった.学生は行政に関する専門知識がほぼないため,システムを利用して必要な情報を得ることで回答できたと考えられる.一方で行政職員は事前知識や行政経験があるため,手作業でも高い正答率を達成し,システムの使用による正答率の向上はみられなかった.また,学生と行政職員の正答率を比較したときに,手作業では行政職員の正答率のほう優れているが,システム使用時には正答率に大きな差がみられなかった.システムが,専門知識や行政経験の差を補い,効率的な問題解決を支援したためだと考えられる.作業時間を保持・削減したうえで,回答精度を維持・向上させたことは,働き方改革に繋がる可能性を示した.
5.3.2 短答式問題の正解・不正解時の作業時間と信頼度の比較
担当課行政職員は不正解の際に手作業で作業時間が長くなり,システム使用時は作業時間が短縮された.また,手作業時には正解時よりも不正解時の信頼度が大きく低下したが,システム使用時には正解時と不正解時の信頼度にほぼ差がなかった.これは,手作業ではファイルを調べる過程で自分の回答が信頼できるかどうかを見積もることができるからだと考える.一方で,システム使用時には回答がすぐに出力されるためその回答の信頼度を測ることが難しいと考える.また,担当課行政職員は事前知識を持っているため,システムがもっともらしい内容を出力すると,たとえ根拠のない情報であっても信じやすいと推察される.また,システムの回答が担当課行政職員の先入観や期待と合致するとき,批判的な分析が欠ける可能性がある.
他課行政職員については,作業時間に差はほとんどなかった.しかし,正解時よりも不正解時の信頼度が著しく低下していた.これは,自分の回答の信頼度を正しく見積もることができていることを示している.事前知識がないが行政経験があるため,不確実な情報に対して懐疑的であり,システムの回答を慎重に扱う傾向があると考えられる.また,システムの回答が根拠を示している場合に限り,その信頼度を高く見積もる傾向がある.根拠を含む回答は正答率も高くなる傾向があると推察される.一方,ソースが明記されていない回答のときは,LLMが回答に必要な情報を十分に得られておらず,回答が不十分な可能性がある.
学生は,手作業で不正解の際に作業時間が長くなり,システム使用時は作業時間が短縮された.これは,システムの回答を疑うための事前知識や行政経験がないため,システムの出力を容易に信じる傾向によるものと考えられる.また,手作業で不正解時に作業時間が長いのは,問題に対するクリティカルな記述を含むファイルを探すのに時間をかけたためであり,最終的にそのファイルを見つけられなかったときに信頼度が低くなると推察する.
5.3.3 記述問題の評価
すべての評価項目において,手作業時の評価が,システム使用時の評価を上回った.これには2つの原因が考えられる.1つは,問題解決に必要な情報をLLMに提供できていなかったこと.すなわち正解について記述されたファイルを検索することができず,LLMに与えるプロンプトにその文書が入っていないということである.もう1つはシステムで使用したLLMモデルのgpt-4-1106-previewの推論能力では解けない問題であったということである.
5.3.4 記述問題の信頼度
行政職員が高評価時に信頼度を高く低評価時に信頼度を低く見積もることができていたのは,行政職員が自分の知識とシステムの提供する情報を比較し,適切に信頼度を判断できたからだと考えられる.また,システム使用時に信頼度が高まったのは,システムが提供する情報が彼らの知識と一致していたからと推察される,学生が高評価時も低評価時も信頼度を同程度に高く見積もったのは,行政業務に関する知識の欠如が原因で,自分の回答の品質を正確に評価できなかったからだと考えられる.学生はシステムの提供する情報を十分に理解し評価することができなかったと推察される.
5.3.5 短答式問題と記述問題における作業時間と正答率の関係についての比較
短文問題では不正解時に作業時間が短くシステム使用回数も少なかったのに対し,記述問題では評価が低いときほど作業時間もシステム使用回数も多くなった.短答式問題においては,システムの出力を十分に検討せずに回答すると作業時間が短くなり,その結果正答率が下がると考えられる.これは被験者がシステムの出力に信頼を置き,そのまま回答として採用することが多かったためだと推察する.システムを使用した際の短答式問題の正答率が高いことから,多くの問題に対してシステムが適切な回答を生成できていることを示す.システムが適切な回答を生成することが多いため,被験者はシステムを過信していたのではないか.さらに被験者は問題の内容が複雑であるほど,システムの出力に頼って,十分な検討をしないという傾向があると考えられる.これにより作業時間が短いときに正答率が下がった可能性もある.一方,記述問題においては,システムを使用しても作業時間の短縮がみられなかった.これは,システムの出力が被験者の期待に沿わないことが多かったことを示唆する.システムの回答に被験者が違和感を覚えると,その回答を採用せずに再度システムを使用する必要が生じる.その結果,システムの使用回数が増加し,作業時間の短縮効果が得られなかったと考える.
5.3.6 分割文字数による比較
100文字分割が短答式問題に,4000文字分割が記述問題に適していると予測していた.100文字分割ではより特定情報にフォーカスした検索が可能で,4000文字分割では文脈を維持しつつ,より情報を包括的な検索が可能であると考えていたからである.しかし,実験結果では短答式問題においては4000文字分割の正答率のほうが高く,記述問題では100文字分割の評価のほうが高かった.これには以下の理由が考えられる.
- (1) 記述問題では,問いに対する答えとなる記述箇所がファイル内の複数箇所または複数ファイルに散在する.そのため多様な情報へのアクセスしやすい100文字分割のほうが有利であった.
- (2) 短答式問題では,ファイル内の一箇所に答えが記述されているため,F値の高い4000文字分割のほうが,正答率が高くなった.
6. 検索精度
本実験の目的は,本システムの検索精度を評価することである.本システムではシステムの回答だけでなく,ファイルを検索するためにも用いられることを想定しているからである.またRAGシステムは外部情報から必要な情報を参照し,必要な情報を取得して回答を生成する.そのため検索精度は重要であると考える.
6.1 実験方法
本実験では検索された上位N件をN-Best解とし,それらに対する適合率,再現率およびF値を算出する.さらに,異なる分割文字数における結果を比較する.
また,入力文はユーザ質問とユーザ状況の2種類ある.ユーザ質問はシステムに回答を求める質問や命令を行う.ユーザ状況はユーザが置かれている状況を入力することができる.質問と状況の両方を入力したときと,質問のみを入力したときの検索精度を比較する.
使用するファイルは回答精度の実験と同じ164ファイルである.正解ファイルは被験者ではない航空空港課の職員が設定する.検証する問題数は7問であり,各問の正解ファイルは1から6個である.
6.2 実験結果
分割文字数を大きくすることで検索の適合率(図16(a)),再現率(図16(b)),F値(図16(c))が向上した.100文字分割においてはユーザクエリのみを入力したときに検索精度が高くなり,4000文字分割においてはユーザクエリとユーザの状況の両方を入力したときに検索精度が高くなった.

Fig. 16 Retrieval accuracy (a):Precision (b):Recall (c):F-Measure.
6.3 考察
分割文字数が大きくなると検索精度が向上した.これは以下の理由が考えられる:
- ・情報の豊富さ:分割文字数が大きいほどチャンクに含まれる情報量が多くなり,各指標において値が向上したと考えられる.
- ・コンテキストの維持:分割文字数が大きいほど,より大きい部分がまとめて埋め込みベクトルになるため,文脈が維持される.これによって関連性の高い情報が抽出されやすくなり,各指標の値が向上したと考える.
- ・ノイズの低減:分割文字数が小さくなるとノイズ(無関係な情報)の割合が増え,その影響が大きくなる可能性がある.一方分割文字数を大きくすることでノイズの割合が減り,その影響が小さくなる可能性がある.
6.4 検索精度と回答精度の比較
検索のF値(図16(c))と,RAGシステム使用による回答精度(表1)に大きな乖離がみられる.これらの結果の乖離を調べるためにさらなる比較を行った.
RAGはプロンプトとして与えられた情報に基づいて回答を生成する.その過程で与えられた情報から回答生成に必要な情報を取捨選択していると考えた.つまり,LLMに与えられたプロンプトの情報内容と,実際に回答生成のためにLLMに参照された情報内容との間の差異に着目した.
本RAGシステムの回答には,参照したファイルが(*1)や(*2)のようにファイル番号で表示される.これらを「RAGシステムが参照したファイル」とする.そして本実験において,RAGシステムが平均で3.97ファイルを参照することが明らかになった.そこで4-Best解とRAGシステムが参照したファイルの適合率,再現率,F値を比較した.
表7には4-Best,表8にはRAGシステムが参照したファイルにおける適合率,再現率,F値を示す.全ての分割文字数において,RAGが参照したファイルにおける測定値が4-Bestにおけるものを上回った.
Table 7 Precision, recall, and F-Measure of 4-Best results.
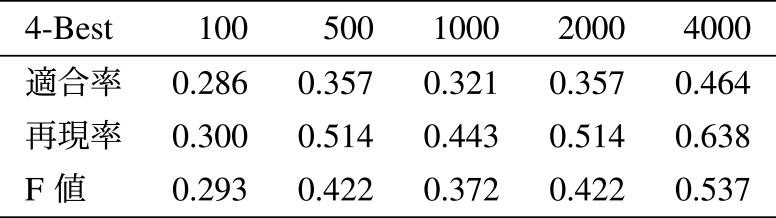
Table 8 Precision, recall, and F-Measure of files referenced by RAG.
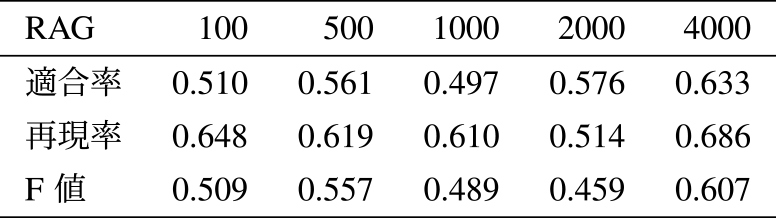
表7と表8の結果から以下のことが考えられる.
適合率:RAGシステムにおける適合率が4-Bestの適合率より高いことは,RAGシステムが情報を取捨選択して,回答生成に必要な情報を参照していることを示唆する.
再現率:RAGシステムにおける再現率が4-Bestの再現率より高いことは,RAGシステムが必要な情報を見逃さずに捉える能力があることを示唆する.
F値:すべての分割文字数においてRAGシステムのF値が4-BestのF値を上回ったことから,コサイン類似度による情報の選択よりもLLMによる情報の選択のほうが,精度が高いと考えられる.これは,LLMが与えられたコンテキスト全体を総合的に理解し,より関連性の高い情報を選択できる能力を持つからだと考える.検索精度で触れている検索の上位セグメントがRAGが実際に使用するセグメントと必ずしも一致しないのは,コサイン類似度による検索上位のスコアに大きな差が開かず,小さな違いがランクに大きな影響を与えるからだと考えられる.
このことから,プロンプトに与える段階で情報を絞りすぎるのではなく,プロンプトのコンテキスト制限まで情報を入れるほうがLLMの解答精度が向上する可能性がある.コサイン類似度に基づくとノイズと見なされる情報も,LLMにとっては重要な情報となり得るからである.
また,RAGシステムでは与えられる情報のF値よりも再現率の重視が必要がであると考えられる.それは,LLMが与えられたプロンプトから必要な情報を選択する能力があると考えられるためである.これによって与えられる情報の再現率が高いとき,RAGシステムは必要な情報を不足なく参照することができる.LLMは不必要な情報を無視して回答を生成するため,適合率が低いことが与える悪影響は小さいと考える.
さらに,検索精度を検証した実験において,正解ファイルは事前に設定した.直接的な言及がないため不正解とされたファイルの中にも,間接的に解答に関連する内容を含むファイルが存在する可能性もある.たとえば,正解ファイルの言及した内容の根拠となるファイルが不正解とされていることなどが考えられる.これによって検索のF値が低く出た可能性も考えられる.
一方で,多くのセグメントをプロンプトにいれることで,実行速度の低下やコストの増加を引き起こす可能性がある.リアルタイム性が求められるアプリケーションなどでは実行速度とのバランスを考える必要がある.また,リランキングシステムを導入するアプローチも有効である.コサイン類似度によってセグメントを一定まで絞り,その中からLLMを用いてより関連度の高いセグメントを選択するといったアプローチである.
7. まとめ
本研究では行政DXのためのRetrieval Augment Generation(RAG)を開発し,その効果を確認した.行政職員は同程度の正答率で作業時間を短縮し,事前知識のない学生は作業時間を短縮して正答率を向上させた.この結果は本RAGシステムが行政職員の業務を効率化させ,働き方改革に繋がる可能性を示した.また,行政に向けたRAGシステムにおけるテキストの分割文字数についても調査し,分割文字数が多いほど検索精度が向上することを確認した.
この研究では,164ファイルのデータセットを使用して実証実験を行ったが,実業務における膨大なデータ量においては,情報検索は作業負担がさらに増加すると予想される.今後は,さらに多くのファイルに対してもRAGシステムを効率的に使用できるかを調査する.
また,確実性が求められる行政業務において,生成AIのハルシネーションや不正確な回答生成の可能性は重要な課題となる.今後は,人間による確認プロセスの統合や,RAGシステムの推論過程の可視化など,精度と信頼性を向上させる方策を検討する必要がある.
謝辞 本研究は,愛知県の実証実験事業AichiXTech,NEDO(JPNP20006),およびJST CREST(JPMJCR20D1)の支援を受けた.特に,実証実験にご協力いただいた愛知県都市交通局航空空港課と総務局情報政策課DX推進室の皆様に深謝します.
参考文献
- [1] AichixTech: Building an In-House System for Easily Discovering Accumulated Administrative Information, 〈https://aichixtech.pref.aichi.jp/2023/projects/project10.html〉(2023).
- [2] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., tau Yih, W., Rocktäschel, T., Riedel, S. and Kiela, D.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2021).
- [3] Ryu, C., Lee, S., Pang, S., Choi, C., Choi, H., Min, M. and Sohn, J.-Y.: Retrieval-based Evaluation for LLMs: A Case Study in Korean Legal QA, Proceedings of the Natural Legal Language Processing Workshop 2023 (Preot,iuc-Pietro, D., Goanta, C., Chalkidis, I., Barrett, L., Spanakis, G. J. and Aletras, N., eds.), Singapore, Association for Computational Linguistics, pp.132–137 (online), DOI: 10.18653/v1/2023.nllp-1.13 (2023).
- [4] Silva, B., Nunes, L., Estevão, R., Aski, V. and Chandra, R.: GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models (2023).
- [5] Levonian, Z., Li, C., Zhu, W., Gade, A., Henkel, O., Postle, M.-E. and Xing, W.: Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference (2023).
- [6] Anand, A., Goel, A., Hira, M., Buldeo, S., Kumar, J., Verma, A., Gupta, R. and Shah, R. R.: SciPhyRAG - Retrieval Augmentation to Improve LLMs on Physics Q &A, Big Data and Artificial Intelligence (Goyal, V., Kumar, N., Bhowmick, S. S., Goyal, P., Goyal, N. and Kumar, D., eds.), Cham, Springer Nature Switzerland, pp.50–63 (2023).
- [7] Poliakov, M. and Shvai, N.: Multi-Meta-RAG: Improving RAG for Multi-Hop Queries using Database Filtering with LLM-Extracted Metadata (2024).
- [8] Es, S., James, J., Espinosa-Anke, L. and Schockaert, S.: RAGAS: Automated Evaluation of Retrieval Augmented Generation (2023).
- [9] Saad-Falcon, J., Khattab, O., Potts, C. and Zaharia, M.: ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems (2023).
- [10] Levy, M., Jacoby, A. and Goldberg, Y.: Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models (2024).
- [11] Pawar, S., Tonmoy, S. M. T. I., Zaman, S. M. M., Jain, V., Chadha, A. and Das, A.: The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey (2024).

kawashima@srmtlab.org
2024年名古屋工業大学工学部情報工学科卒業.2024年同大学大学院修士課程進学.

2003年東京理科大学大学院理工学研究科情報科学専攻修士課程修了.2008年京都大学大学院情報学研究科にて博士(情報学)を取得.2009年から名古屋工業大学大学院工学研究科 助教.2015年から同大学 准教授,2021年から同大学 情報工学類 教授,現在に至る.他に,2014年からCode for Nagoya名誉代表,2019年から人工知能学会 市民共創知研究会 主査.2021年から名工大コミュニティ創成教育研究センター長,2024年から株式会社ソシアノッター代表取締役,2024年から東京大学シビックテック・デザイン学創成寄付研究部門 特任教授を兼任.情報処理学会,人工知能学会,電子情報通信学会,言語処理学会 各会員.

2001年大阪府立高専卒業.2006年京都大学工学部情報学科卒業.2013年同大学大学院情報学研究科博士後期課程修了.博士(情報学)2016年ハイラブル株式会社を創業し代表取締役に就任.音環境分析技術による学校や企業の会話分析やコミュニケーション空間分析の研究に従事.2020年異能vation「破壊的な挑戦部門」採択.情報処理学会,人工知能学会,日本教育工学会,IEEE各会員.
採録日 2024年8月27日