動物園のゾウを対象にした単一監視カメラ映像によるトラッキング手法の検討と実践
Consideration and Practice on Tracking Methods for Zoo Elephants Using Single Surveillance Camera Footage
1. はじめに
動物園における飼育動物の行動観察は,動物の健康管理と飼育環境の改善のために欠かせない.飼育員は日頃から飼育動物を観察し,食事量は適切か,他の個体と喧嘩しないかなどをチェックしている.また,直接観察するだけでなく,飼育場の監視カメラ映像を見て,異常行動や繁殖行動の有無,発育状態,睡眠時間などを記録している.監視カメラは複数台設置されており,24時間稼働している.その映像を飼育員が早送り再生し,目視で確認しながら行動の記録をおこなっている.仕事内容が幅広く人員が限られる動物園にとって,これは大きな負担となっている.
そこで筆者らは,札幌市円山動物園(以下,円山動物園)の協力のもと,動物園飼育場の監視カメラ映像からの動物の行動記録(エソグラム)の自動化をめざしている.本稿では,行動記録の自動化のベースとなる個体識別を伴ったトラッキング手法について提案する(図1).実環境での運用に耐えうる手法を構築することを目的とし,特に,環境の変化やカメラから姿が確認しづらい状況などといった実運用で起こりうる状況に対する頑健性をもつ手法を提案する.特に,アジアゾウ(以下,単にゾウ)を対象にして各動物個体の位置を長時間にわたり追跡する手法について述べる.

Fig. 1 Overview of our proposed method.
本稿では,「物体検出」「個体識別」「トラッキング」の3つのタスクの既存手法を組み合わせたモデルを構築する.それぞれのタスクをDetection,Identification,Trackingと表記する.以下に手法の概要について説明する.
まず,深層学習における物体検出モデルによって動画フレームごとに対象動物の位置を推定する(図1 Detection).飼育場ではエサ箱や遊具の定期的な変更や床砂がたびたびゾウによって掘り返されるが,深層学習を用いることでこのような背景の流動性にも対応することができる.次に,推定された位置で画像を切り抜き,別の深層学習モデルによって各個体の判別をおこなう(図1 Identification).ここでは各個体の識別IDを予測する分類モデルを用いる.また,実験では物体検出と個体識別を分けた手法のほうが精度が高いことを示した.最後に最小費用流を用いたトラッキング手法によって各個体の軌跡(各フレームでゾウの位置を特定し,時系列データとしたもの)を求める(図1 Tracking).
実験では円山動物園のゾウ舎における2頭のゾウを対象に手法の有効性を示す.筆者らは円山動物園の監視カメラから映像を取得し,ゾウの位置と個体のアノテーションをおこないデータセットを作成した.また,提案手法は24時間分のカメラ映像で評価している.
本稿の構成を述べる.2章で本研究に用いるデータセットについて述べ,3章では関連研究について説明する.4章では本手法についての詳細を述べ,5章では実施した実験手法と結果について報告する.6章に実践から得られた知見について述べたあと,7章にまとめを述べる.
2. データセット
本章では,本研究で用いる動画データセットの概要と特性を説明する.
2.1 監視カメラ映像
本研究で扱う動画データは,円山動物園のゾウの監視カメラ映像である.映像は園内の屋内飼育場で録画されており,手動でのカメラ操作時を除き24時間連続で録画されている.録画データは1時間ごとに5 FPS(frame-per-second)の動画ファイルとして取得できるが,通常,ゾウの飼育エリアごとに1台の監視カメラが設置されており,複数のカメラによって獣舎全体をカバーしている.そのため,施設の制約上,ゾウの観察には単一の監視カメラ映像のみしか用いることができない.また,昼間(およそ午前5時から午後6時)はカラー映像として記録されるが,夜間(およそ午後6時から午前5時)は自動で暗視モードに切り替わり,グレースケールの映像として記録される.また,カメラ位置と撮影角度は常に固定であり,本研究で用いる映像は屋内飼育場を上から見下ろす形で撮影されたものである(図2).

Fig. 2 Surveillance camera images.
2.2 対象物
円山動物園には5体のゾウ(メス4頭,オス1頭)が飼育されている.それぞれのゾウは諸般の事情から同一の飼育場で飼育するか,別々の飼育場で分けて飼育されるかが決められている.本稿では,特定のメスとオスが1頭ずつ映る動画を対象にする.これは,ゾウの繁殖にかかわる行動分析の飼育員からのニーズが強いためである.
オスには牙があるがメスには牙がないため,牙の有無を確認することでオス・メスの判別が可能である.本研究に用いる監視カメラ映像からでも牙は確認できる.しかし,ゾウの正面がカメラと反対側に向いてしまうと牙の位置が映像から確認できなくなり,1フレーム単位ではオス・メスの判別は難しくなる.また,ゾウがプールに潜る,飼育場の仕切りに隠れるといった場合にも同様の理由でオス・メスの判別は難しい.本提案手法では,トラッキングによって複数フレームから軌跡を判別するため,1フレーム単位では判別が難しい状況下でも正しい推定は可能である.
3. 関連研究
関連研究としては,物体検出,個体識別,トラッキングがあげられる.本章では,この3つのタスクに関連する研究を述べる.
3.1 Detection
近年,深層学習を用いた高精度な物体検出モデルが非常に多く提案されている.この物体検出によってトラッキングをおこなうことは,「tracking by detection」とも呼ばれる.深層学習による物体検出モデルの性能が,深層学習を用いないモデルよりも高いため現在の主流となっている[1], [2].本提案手法も,このtracking by detectionにもとづいている.
本節では実験に用いたモデルを数点挙げる.TanらはEfficientNet [3]をベースにしたモデルであるEfficientDetを提案し,入力解像度,ネットワークの深さ,ネットワークの幅をスケールする方法について考案,検証している[4].このスケーリング手法により,同様の構造をもつモデルを速度・精度のトレードオフを考慮して使用することができる.これをさらに推し進め,精度を高めたものにYOLOv5 [5]がある.
また,動物に特化したモデルとしては,MegaDetector [6]がある.これは主に自動撮影カメラ(カメラトラップ)映像から野生動物を検出するモデルとして作成されている.MegaDetectorは複数のバージョンがあるが,2023年9月時点の最新モデルであるv5はYOLOv5がベースとなっている.
3.2 Identification
個体識別をおこなう場合,個体の識別IDを判定するCNNモデルを用いることが考えられる.CNNは,VGGのほかに,ResNet [7],MobileNetV2 [8],EfficientNet [3]等現在まで数多くのモデルが提案されている.ResNetは,スキップ接続と呼ばれる手法を導入することで,VGGと比較して非常に深いネットワークの学習を可能としており,結果として高い性能を達成できる.ResNetは2016年の登場以来,様々なタスクで広く利用されている.一方で,計算量やメモリ消費量が多く,画像の解像度や求める精度によっては多大な計算リソースを必要とする.EfficientNetは,3.1節で述べたように,モデルのスケーリングによって効率的に処理することが可能である.一方で,ResNetと比較するとEfficientNetの適用例は少ない.MobileNetは,Depthwise Separable Convolutionと呼ばれる畳み込み演算の手法を導入し,計算効率を向上させている.エッジデバイスなどの計算リソースが制約された環境でも動作ができる一方で,ResNetやEfficientNetよりも精度面で劣る.
次に,動物を対象とした個体識別の研究例を挙げる.Schofieldらは,23体のチンパンジーの顔識別のためにVGG [9]を用いており,92.5%の正答率を達成したと述べている[10].また,Pangらは動画を入力とした羊の顔識別に取り組んでおり,これにはMobileNetV2をベースにしたモデルを用いている[11].また,Moskvyakらは,目,耳,尾などのキーポイントを入力に加えることにより,個体識別の精度が大幅に向上したと報告しており,水中で撮影されたマンタ(大型のエイ)の画像に対して実験をおこない,手法の有効性を示した[12].しかし,顔やキーポイントを利用する場合は,物体検出用のデータセットとは別に,顔またはキーポイントをアノテーションしたデータセットを用意し,学習モデルを作成する必要がある.本研究では,学習データセットを作成する労力が高いことから,これらの手法は取らなかった.
3.3 Tracking
トラッキングは教師ありの手法と教師なしの手法がある[1].教師ありの場合は精度がよい傾向にある半面,教師データとして,連続したフレームに対する個体ごとの矩形位置情報が必要であり,そのアノテーション作業には多大な労力を必要とする.たとえば,本稿で扱う5 FPSの動画には,24時間分であっても432,000(=5×24×3600)フレームに対してオス・メスの矩形位置を示す必要がある.本稿では,データセットとして5カ月間の動画を用いており,すべてのフレームに対してアノテーションを用意するのは現実的ではない.また,ゾウの成長や飼育環境の変化に応じてアノテーションをやりおなす必要があることを考慮し,今回は労力のかからない教師データを用いない方法を採用することとした.
また,トラッキングはオンライン(またはリアルタイム)とオフライン(またはバッチ処理)の手法に分かれる.オフライン手法の場合には,オンライン手法と異なり,過去フレームだけでなく未来のフレームも使えるという利点がある.そのため,精度はオフライン手法のほうがオンライン手法よりもよい傾向にある.オフライン手法では,ネットワークフローとして定式化をおこない,最小費用流問題を解くことによって各トラッキングの軌跡を求めることが多い[2].行動記録の作成にリアルタイム性は必須ではないため,本稿ではネットワークフローを用いたオフライン手法を用いることにした.手法には主にJiangら,およびZhangらによる定式化をベースとしている[13], [14].
次に,動物を対象にしたトラッキングの研究例を述べる.Schofieldらは,23体のチンパンジーの個体識別のために,フレームごとの顔検出に続いてKanade-Lucas-Tomasi(KLT)trackerによる顔のトラッキングをおこなっている[9].ただし,Schofieldらの手法はチンパンジーの顔がカメラから確認できる状況に限定されている.idTrackerは,実験動物の行動分析を目的としたトラッキング手法であり,ゼブラフィッシュ,ショウジョウバエ,クロナガアリおよびハツカネズミを対象に手法の有効性が示されている[15].idTrackerは,それぞれのフレームから二値化に基づく個体の領域抽出をおこなった後,他個体とオーバーラップしていない個体に対して軌跡を求める.次に,各軌跡上の個体の画像と,事前に収集した各個体画像(参照画像)の特徴量と比較し,軌跡単位で識別IDを割り当てている.筆者らの提案手法と同様に,idTrackerも個体識別を伴ったトラッキング手法である.ただし,idTrackerの適用範囲は,背景が一様で変化が少ない環境に限られており,カメラの角度も対象を真上から撮影し,対象の画像上のサイズがあまり変化しない状況が想定されている.また,オクルージョンは対象物同士の重なりに限り対策が取られており,何かの陰に隠れるという状況は考えられていない.本提案手法は,深層学習とネットワークフローを用いることで,複雑な背景や斜め上方向からのカメラ映像でもトラッキングを可能としており,画像上でのゾウのサイズが大きく変わる,施設の陰にゾウの姿が隠れる,といった状況にも適用できる.
なお,異なる方向から撮影した映像が利用可能な場合,より正確にトラッキングできると考えられる[16].ただし,前述したように,本研究では施設の制約から単一カメラの映像のみを用いる.
4. 提案手法
前章にまとめたように,物体検知単独では正確なトラッキング結果を出力するのは難しいため,物体検知,個体識別,トラッキングを組み合わせることにより最終的な精度を高めることを目的とする.本手法は以下の順に処理を進める.
- 1. Detection(物体検出)
CNN物体検出モデルによりゾウの矩形位置を推定する - 2. Identification(個体識別)
フレーム画像を矩形位置で切り抜き,CNN個体識別モデルに入力して各個体の識別IDを推定する - 3. Tracking(トラッキング)
DetectionとIdentificationの結果から各ゾウの軌跡を求める
本章では,1,2,3の各処理内容を詳述する.
4.1 Detection
監視カメラ映像に対して,1フレームずつゾウの位置を検出する.モデルはCNNをベースにした物体検出モデルを採用する.
モデルはゾウの位置を矩形で示したアノテーション付き画像データセットで学習する.検出時には,まず,モデルが信頼度スコアが閾値以上である矩形位置を出力する.次に,出力した矩形位置を用いて検出対象をフレームから切り抜き,切り抜いた画像をIdentificationモデルに渡す.
4.2 Identification
モデルはCNNを用いた画像分類モデルを採用する.本データセットの場合,牙の有無によってオス・メスの判別ができるため,画像上で外見を考慮した判別ができるCNNは有効だと考えられる.ただし,監視カメラ映像ではゾウの牙の位置が確認できない状況がたびたび発生する.たとえば,ゾウの正面がカメラと反対側に向いてしまうと,もはや牙の位置が確認できない.ほかに,ゾウがプールに潜る,飼育場の仕切りに隠れるといった場合もある.このような画像に対してはトラッキングの精度が低下することが予想された.そこで,牙の見えない画像を明示的に区別するため,牙の見えない画像を1クラスにまとめ,「不明瞭」としてクラスを分けた.すなわち,モデルはMale(オス),Female(メス),Unclear(不明瞭)の3種類の判別をおこなう(図3).ここで「Unclear」は,ゾウがカメラ映像から牙の有無が確認できない場合につけるラベルとするが,ゾウが2頭映っていて,どちらも牙が確認できないときは,どちらもUnclearとしている.Unclearは,Trackingにおけるネットワークの構成と軌跡に対する識別IDの割り当てに用いる.

Fig. 3 Dataset of identification.
4.3 Tracking
ここではDetectionとIdentificationの結果から,トラッキングをおこなう方法について述べる.基本的な流れは以下のとおりである.まず,検出位置およびIdentificationの判別スコアからネットワークを構成する.このネットワーク上のフローはゾウの軌跡に対応する.次に,ネットワークから最小費用流を求め,それを各ゾウの軌跡とする.次に,互いのゾウが近接する場合,軌跡を分割する.最後に,軌跡ごとに識別IDを割り当てる.以下にそれぞれについて詳述する.
4.3.1 ネットワークの構成
検出された物体と誤検出を含めたすべての組み合わせを表すネットワークを構成する.Nを総フレーム数,n(1≤n≤N)をフレーム番号,M(n)をnフレーム目の検出個体数(すなわち,Detectionが出力する矩形の個数),K(≥2)を検出対象動物の最大個体数とする.各フレームのDetectionとIdentificationの推定結果をもつ検出ノード$\boldsymbol{d}_i^n$(1≦i≦M(n))を導入する.ここで,$\boldsymbol{d}_i^n$はDetection出力の予測位置$\boldsymbol{r}_i = (r_i^{\rm{top}},\ r_i^{\rm{left}},\ r_i^{\rm{bottom}},\ r_i^{\rm{right}})$,および,Identificationの出力判別スコア${p_i} \in {\mathbb{R}^{K + 1}}$(個体ごとの推定値K次元,および,不明瞭ラベルに対する推定値1次元)で構成されているとする.また,いずれかの個体が検出漏れしていることを表すK−1個のオクルージョンノードonを各フレームに導入する.ただし,検出ノードが存在しないフレーム(すなわち,対象物が検出されていないフレーム)は除いておく.よって,各フレームにはM(n)個の検出ノードとK−1個のオクルージョンノードがある.なお,本稿で扱うデータはK=2の場合にあたるため,各フレーム対して1個のオクルージョンノードが存在する.
次に,各ノードは時間的に最も近い前後のフレームのすべてのノードとエッジで接続される.また,$\boldsymbol{d}_i^n$,$\boldsymbol{d}_j^m$を検出ノードとしたとき,エッジ$\boldsymbol{d}_i^n$・$\boldsymbol{d}_j^m$に対するコスト関数$c_{\boldsymbol{d}_i^n \cdot \boldsymbol{d}_j^m} = \mathrm{cost}(\boldsymbol{d}_i^n, \ \boldsymbol{d}_j^m)$を以下のように定義する.\[{\rm{cost}}(\boldsymbol{d}_i^n,\boldsymbol{d}_j^m) = \lambda {c_{\rm{IoU}}}(\boldsymbol{r}_i,\boldsymbol{r}_j) + (1 - \lambda )c_{\rm{class}}(\boldsymbol{p}_i,\boldsymbol{p}_j),\](1)
\[c_{\rm{IoU}}(\boldsymbol{r}_i,\boldsymbol{r}_j) = 1 - {\rm{IoU}}(\boldsymbol{r}_i,\ \boldsymbol{r}_j),\](2)
\[c_{\rm{class}}(\boldsymbol{p}_i,\boldsymbol{p}_j) = 1 - \exp ( - \mu \cdot KL),\](3)
\[KL(\boldsymbol{p}_i,\boldsymbol{p}_j) = {\sum\limits_{k = 0}^K} {p_i^k} \log \frac{{p_i^k}}{{p_j^k}},\](4)
ここで,cIoUは物体の位置の差に対する費用であり,$\mathrm{IoU}(\boldsymbol{r}_i, \boldsymbol{r}_j)$は$\boldsymbol{r}_i$,$\boldsymbol{r}_j$が表す矩形領域のIoU(Intersection Over Union)値である.ここでIoUとは,2矩形の共通部分の面積を和集合の面積で割った値のことである.また,$c_{\mathrm{class}}(\boldsymbol{p}_i, \boldsymbol{p}_j)$はクラススコアの差に対する費用であり,同じ軌跡の中でクラスが変わることに対してペナルティを与える.μはクラス数に応じて設定し,0≤cclass≤1となるようにする.式(1)のλは,cIoUとcclassの重要度を表すパラメータであり,実験によって決定する.オクルージョンノードに接続する場合は一定値のコストc0を与える.
4.3.2 最小費用流問題の求解
Vを始点s,終点t,検出ノードおよびオクルージョンノードからなる集合,vw(v, w∈V)をエッジ,xvwをフローとする.ネットワーク上のフローxvwは0または1の値をとる.ここで,xvw=0はv, wが異なる識別IDであること,また,xvw=1はv, wが同じ識別IDであることを意味するものとする.フローxvwは複数の実行可能解が取りうるが,その中で総コストが最小となる最小費用流を求める.すなわち,以下の目的関数Jが最小となるフローxvwを求める.\[J = \sum_{v,w} c_{vw} x_{vw}, \quad v, \ w \in V,\](5)
ただし,容量条件,流量保存条件,非重複条件を満たす必要がある.非重複条件はトラッキングの定式化に必要であり,各ノードの始点および終点となるエッジはそれぞれ多くとも1本のみであることを表す[13].式から分かるように,フローは線形計画問題としても求めることが可能である.実際には,フローxvwが0または1であるから,0–1整数計画問題となるが,変数の数が少ないため短時間で解くことが可能である.
例を図4に示した.この例では,3フレームにおいて生成されるネットワークとそのフローを示す.丸型のノードが検出ノード,四角型のノードがオクルージョンを表すノードである.図では,パス$s \cdot d_1^1 \cdot d_1^2 \cdot d_1^3 \cdot t$,および,パス$s \cdot o^1 \cdot d_2^2 \cdot d_2^3 \cdot t$がxvw=1となり,それ以外がxvw=0となる.
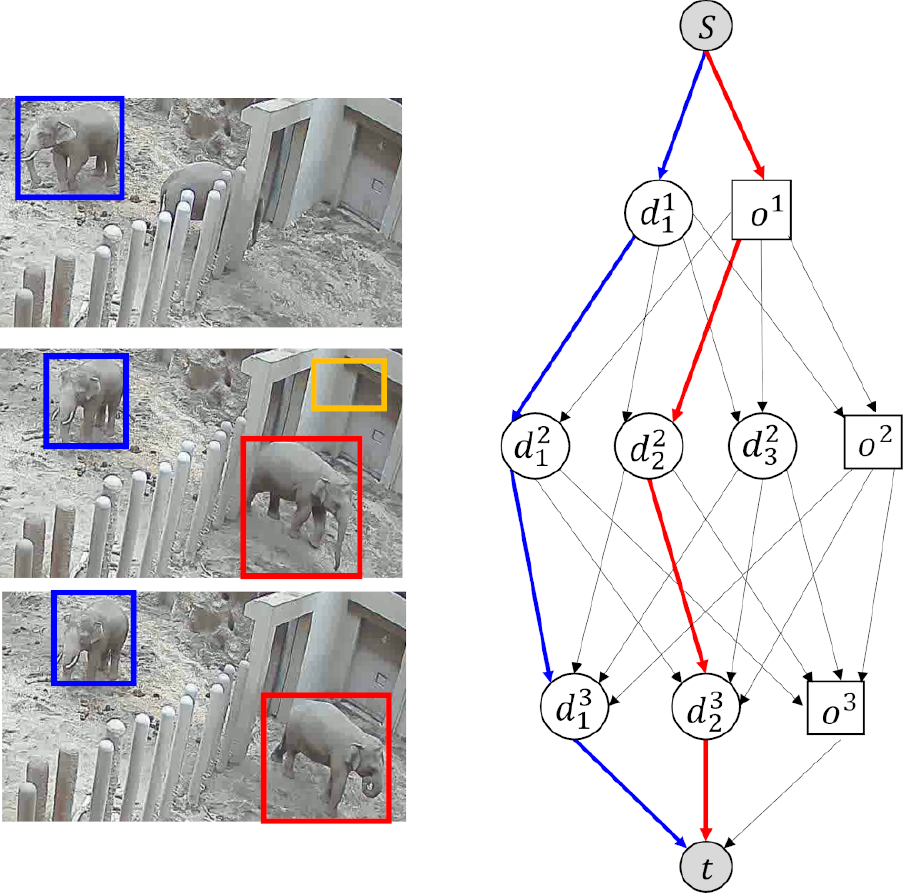
Fig. 4 Network flow.
4.3.3 軌跡の分割
IDスイッチ(複数の個体の軌跡に割り当てたIDの入れ替わり)はゾウのすれ違い時に発生しやすく,IDスイッチの発生後はそれ以降誤った識別子と対応することになる.そのため,2頭それぞれに対し検出された矩形のIoUがあらかじめ定めた閾値τdiv以上となる区間の前後で軌跡を分割する.
4.3.4 識別IDの割り当て
ここでは,分割された各軌跡に識別IDを割り当てる.まず,各軌跡に対してIdentificationモデルの出力スコアの平均値を求める.だだし,平均値はUnclearと判定されたインスタンスを含めずに計算する.次に,その値がUnclearラベル以外で最も高い識別IDを割り当てる.ただし,同一時刻における軌跡は同じクラスが2つ以上にならないように識別IDを割り当てる.加えて,検出矩形のIoUがτdiv以上となる区間の各インスタンスに,Identificationモデルの出力スコアが高いクラスから順に識別IDを割り当てる.
5. 実験
本章では,4章で述べた手法の有効性を示す実験について述べる.なお本実験では,学習データとして,対象物の矩形位置のアノテーションと識別対象物の画像および個体識別不能な画像(「不明瞭」画像)が必要である.
5.1 Detection
5.1.1 データセット
実験で用いたカメラ映像は2章で述べたとおりであるが,ここでは学習と評価に用いるデータセットについて述べる.表1にデータセットの内訳を示す.学習データは2022年1月1日から2022年5月31日の監視カメラ映像を用いており,1月1日から3月31日を訓練データ,4月1日から4月30日をバリデーションデータ,5月1日から5月31日をテストデータの区間としている.データセットは上記期間の動画から一部のフレームを画像として取り出したものを使用する.アノテーションとして,各ゾウの位置を矩形(4点)で指定する.外見のバリエーションが増えるように,動画からフレームを取り出す間隔を1分以上あけた.また,睡眠時などのほとんど動きがない場合,その動作の始めのフレームのみをアノテーションし,それ以降は使用しなかった.昼間の画像(カラー画像)は70.1%,夜間の画像(グレースケール画像)は29.1%であった.
Table 1 Detection dataset.

5.1.2 学習モデルとパラメータ
学習モデルはCNNベースの物体検出モデルを用いて,ファインチューニングをおこなう.検出対象ラベルは「elephant」とし,1クラスのみを検出するモデルを作成する.モデルはEfficientDet,YOLOv5,MegaDetector(v5.0)を用いて精度を比較する.EfficientDetおよびYOLOv5に関しては,COCO [17]で事前学習済みのモデルを用いて,ファインチューニングをおこなう.また,MegaDetectorは野生動物を主なターゲットとした物体検出器だが,多様な背景や学習データに含まれない動物の種にも対応できるように訓練されている.モデルはカメラトラップ映像を含めたデータセットで事前学習されており,実験ではこの事前学習済みのモデルを用いてファインチューニングをおこなう.また,画像拡張処理として,左右反転,ランダムクロップ,拡大縮小をランダムに適用した.YOLOv5-x6,MegaDetectorはバッチサイズ2,それ以外のバッチサイズは4とした.
5.1.3 評価方法
モデルの精度比較にはテストデータに対するAP(@IoU=0.50:0.95)を用いる.これは,COCOの評価指標値であり,IoU閾値0.5から0.95まで0.05刻みで変えたときの平均AP(average precision)である.
5.1.4 結果
結果を表2に示す.最も良いモデルは,YOLOv5-l6となり,AP(@IoU=0.50:0.95)が0.810となった.Detectionの結果はTrackingの精度に直結するため,より精度が良いほうが好ましいが,動物の飼育環境によっては学習が不要となる可能性もある.
Table 2 Detection result.

5.2 Identification
5.2.1 実験方法と結果
クラスはMale(オス),Female(メス),Unclear(不明瞭)とし,Detectionにおいて用いたデータセットの画像から,アノテーションの矩形位置を切り抜いて作成した.内訳は表3のとおりである.オス,メスの判別は牙の有無で判断し,牙の位置が見えない画像にはUnclearラベルを付けた.ただし,ゾウが牙の位置が見える位置にいたとしても,ゾウの画像上のサイズが小さく,オス・メスの判別に迷う画像は取り除いた.加えて,データセット全体において昼間の画像(カラー画像)は66.8%,夜間の画像(グレースケール画像)は33.2%であった.学習モデルとしてはMobileNetV2 [8],ResNet50 [7],EfficientNetを用いて比較した.EfficientNetに限り入力サイズの異なるモデル(B0-B5)を比較した.すべてのモデルはImageNetで事前学習されているため,最終層のノード数を3に変更して全層ファインチューニングをおこなった.最も良いモデルはEfficientNet-B2となり,正答率は0.869となった.
Table 3 Identification dataset.
5.3 Tracking
本節では,5.1,5.2節で学習したモデルを適用した結果を用いてTrackingを行う.また,DetectionモデルとしてYOLOv5-l6,IdentificationモデルとしてEfficientNet-B2を用いた.軌跡分割時の閾値τdivは,本文で言及しない場合τdiv=0.2と設定した.また,20フレーム内で1頭もゾウが検出されていない場合は,その時点でネットワークを分け別々に解析をおこなう.
5.3.1 データセット
テストデータとして2022年5月1日のカメラ映像を用いた.6秒おきにゾウの矩形位置および識別ID(メス・オス)のアノテーションをおこない,結果として,データセットは表4のようになった.データセットを作成する際は,元動画からゾウが映っていない時間,30分以上の睡眠時間,肉眼で判別しづらい時間を除いた.結果として,作成した動画はそれぞれ1分間から48分間の分割されたものとなった.また,データセットは特定の時間帯に偏らないように作成しており,データセット全体において昼間のフレーム(カラー)は55.5%,夜間のフレーム(グレースケール)は44.5%であった.
Table 4 Tracking dataset.

本データセットでは,多人数トラッキングのコンペティションであるMOTChallenge [18]と比べると2点の違いがある.まず,MOTChallengeには個体を識別するIDが存在せず,トラッキング対象の照合をおこなう必要はないという点である.一方,本データセットではトラッキングと同時に事前に定められた識別ID(オス・メス)との照合をおこなう必要がある.次は,本データセットは長時間のデータセットとなっている点である.ここでは「長時間」を実時間(実際の動画撮影時間)の意味で用いている.本稿で扱うような識別IDも同時に推定する場合,推定区間内の初期にIDスイッチが生じると,それ以降の識別IDがすべて入れ替わるということが起りうる.また,推定区間でゾウの総移動量が大きくなるため,IDスイッチが起こるようなゾウの重なりも増える傾向にある.長時間のデータを用いることで,そのような識別IDの入れ替わりも評価することができる.MOTChallengeには複数のデータセットがあるが,たとえば,MOT17のテストデータの実時間は15秒から85秒であり,合計20本の動画(合計動画時間744秒,17,757フレーム,オブジェクト数564,228)で構成されている.本データセットは,MOTに比べてオブジェクト数とフレーム数は少ないが,合計動画時間が9.2時間となっており長時間のデータであることが特徴である.そのため,本データセットは実際のアプリケーションで想定される状況に近く,研究段階から実用化に移る際の指標となる.
5.3.2 評価方法
評価値はオス・メスごとのAP(@IoU=0.50:0.95)の平均値(以下,mAPと略記)と,HOTA [19],MOTA,IDF1の値を記録した.HOTA,MOTA,IDF1は,多人数トラッキングのコンペティションであるMOT Challenge [18]の評価値として採用されている.軌跡が途中で入れ替わるIDスイッチが評価値に反映される.ただし,HOTA,MOTA,IDF1は途中でIDスイッチが起きたときは評価値が低下するが,推論区間の最初から最後までオス・メスが互いに入れ替わっていても評価値は低下しない.行動記録では個体の区別が必須であるため,モデルの良さの指標としては個体の識別性能を表すmAPを最も優先する.
5.3.3 コスト関数
4.3.1項のコスト関数の,λ=1, 0.5, 0の場合を比較する.すなわち,以下の3種類のコスト関数を比較する.
- 1. (IoU)cost(v, w)=cIoU,
- 2. (Class Score)cost(v, w)=cclass,
- 3. (IoU + Class Score)cost(v, w)=(cIoU+cclass)/2,
ここで,クラススコアの違いに対する費用cclass(式(3))のパラメータμを,0≤cclass≤1となるようにμ=1.3358と定めた.また,オクルージョンノードに接続するコストはc0=0.9とした.
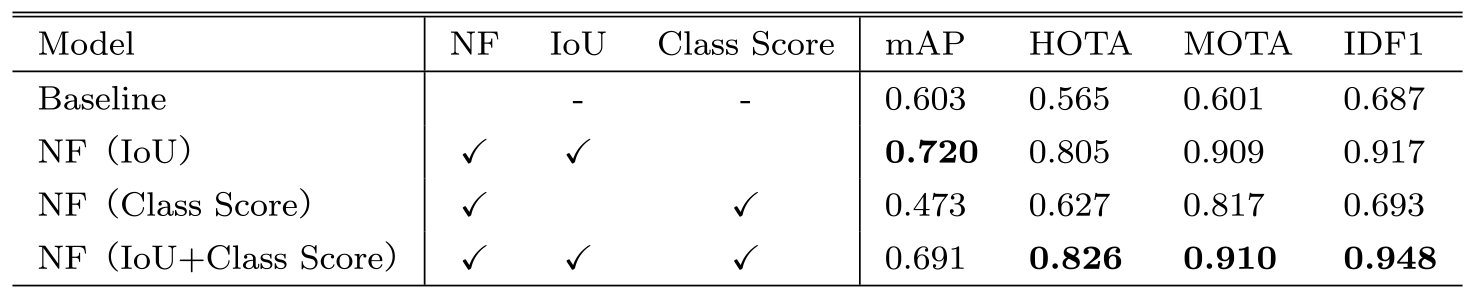
5.3.4 結果
結果を表5に示す.比較のため,DetectionとIdentificationの結果のみを用いて評価をおこなった値(Baseline)も示した.また,「NF」はネットワークフローによるトラッキングを表し,括弧内はコスト関数の種類を表す.まずmAPに着目すると,NF(IoU)はBaselineよりも大幅に精度が高くなり,mAPは0.603から0.720に向上した.一方で,NF(Class Score)はBaselineより,mAPは0.603から0.473に大きく減少した.また,NF(IoU+Class Score)はNF(IoU)よりもmAPは低く0.691に留まっている.これから,精度向上には,隣接フレーム間の位置の差が外見の差よりも重要であることが分かった.HOTA,MOTA,IDF1に着目すると,ネットワークフローを用いたモデルはBeseLineよりも総じて評価値が向上している.これからIDスイッチの抑制にはIoUとClass Scoreのコスト関数のどちらも効果があり,両コスト関数を合わせるとさらに効果的であることが分かる.
Table 5 Tracking result.
5.4 DetectionとIdentificationの統合と分離
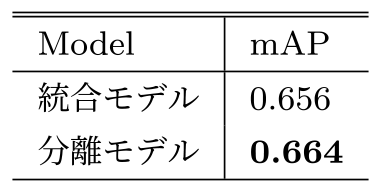
DetectionとIdentificationの統合するモデル(以下,統合モデル)と分離するモデル(以下,分離モデル)の比較をおこなった.ここで統合モデルとは.Detectionモデルが,単にelephantを検出するのではなく,Female,Male,Unclearの3種を直接別々に検出することを指す.分離モデルはDetectionとIdentificationを分けたモデルのことを指す.データセットは1章のDetectionデータセットの一部を利用して作成したが,統合モデルにおけるデータセットには,各オブジェクトに対して矩形位置と識別IDが付加されている.結果として,training 1135枚,validation 461枚,test 324枚となった.
結果を表6に示す.DetectionとIdentificationを分離した場合(分離モデル)は,DetectionとIdentificationを統合した場合(統合モデル)と比較して,わずかながら精度は向上した.
Table 6 Integration and separation model comparison.
5.5 不明瞭ラベルの効果
不明瞭ラベルの効果を確認するため,不明瞭ラベルを用いないIdentificationモデルによるトラッキングをおこなった.Identificationモデル(EfficinetNetB2)を学習する際は,表3のデータセットからUnclearラベルを除いて学習・評価をおこなった.Identificationモデルのtestデータに対する精度は94.2%となった.
結果を図5,図6に示す.不明瞭ラベルの有無によってIdentificationのスコアが大きく変わるため,最適なパラメータが異なる可能性がある.よって,不明瞭ラベルの精度比較に加え,複数のパラメータ値で精度を比較している.
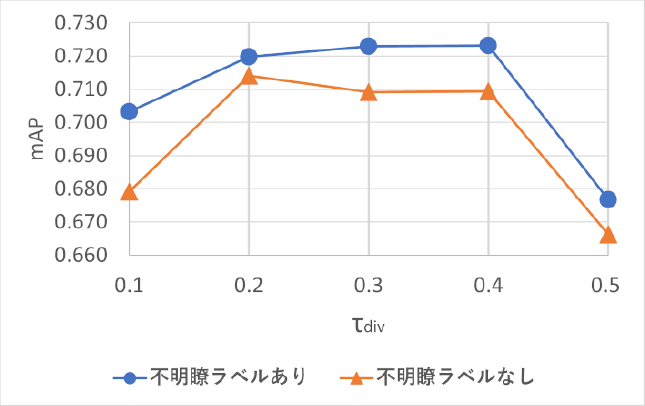
Fig. 5 Effects of unclear labels with trajectories division criteria.
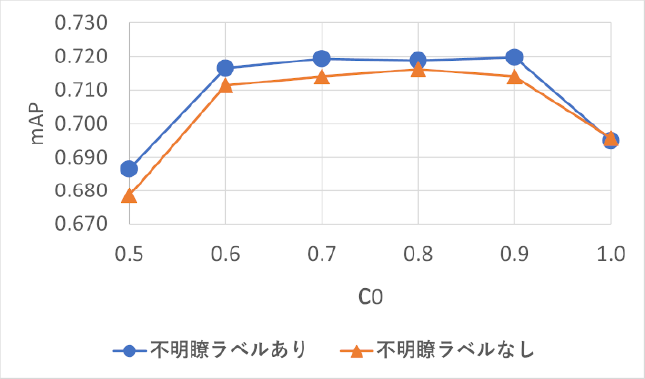
Fig. 6 Effects of unclear labels with occulusion cost.
図5は,軌跡分割時に基準とするIoU値τdivを0.1から0.5まで0.1刻みで増加させたときのmAPを表す.図6は,オクルージョンノードに接続するコストc0を0.5から1.0まで0.1刻みで増加させたときのmAPを表す.「不明瞭ラベルあり」は「不明瞭ラベルなし」と比較すると,小幅ながらc0=1.0を除くほぼすべての閾値で上回った.
5.5.1 精度が低下するケース
本項では,精度が低下するケースを3点述べる.まず,各軌跡上にメス・オス判定に有効な画像が少ない場合である.「ゾウが見切れて映る」「カメラと逆方向に向いている」「カメラから遠い位置にいる」等の場合はメス・オス判別に有効な牙が見えづらく,個体判別率が落ちる.次に,Detectionが誤検出する場合である.ゾウでない物体(背景の足場や給餌器など)が検出されてしまうと,当然全体の精度に影響する.最後に,映像にゾウが1頭しか映らない場合である.本手法では,同一時刻における複数の軌跡には重複しない識別IDをそれぞれの軌跡に割り当てる.それゆえ,ゾウが2頭の場合,一方が判別に難しい外見をしていても,もう一方が容易に判別できれば,正しい識別IDを割り当てることは可能である.しかし,1頭しか映っていない場合は,そのような戦略がとれないため比較的精度が悪くなる.
6. 実践から得られた知見
動物のトラッキングの特性の1つとして,各個体の外見が非常に近いことが挙げられる.この場合,単独のフレーム画像から個体の判別ができないことも多い.これは,表5において,「Baseline」の結果が他のモデルよりも著しく精度が低かったことからも分かる.そのため,トラッキングの軌跡を求めるには,各個体のフレーム間の相対的な変化(たとえば,位置や外見の差)を考慮することが重要になる.本稿の実験により,特に位置情報が重要であると分かった.これは,表5のNF(IoU)がNF(Class Score)と比べて精度が高かったことから分かる.また,外見を学習モデルに組み込む工夫として「不明瞭」ラベルを付加的に用いたが,それによって各軌跡の判別を実現できることを示した.
7. まとめ
筆者らは複数の手法を組み合わせ,ゾウを長時間にわたり安定してトラッキングできる手法を提案した.これには,深層学習ベースの物体検出モデル(YOLOv5)と分類モデル(EfficientNet),また,ネットワークフローを用いている.監視カメラ映像からDetection,Identification,Tracking用のデータセットを作成して学習と評価をおこなった.結果,トラッキング精度はHOTA 0.820と十分な精度が得られたうえ,個体の識別精度はmAP 0.720となり,行動記録のベースとなりうる精度を得ることができた.
謝辞 本研究はJSPS科研費22H03637の助成を受けたものです.また,本研究遂行にあたっては,札幌市円山動物園の協力をいただきました.この場を借りて感謝申し上げます.
参考文献
- [1] Ciaparrone, G., Sánchez, F. L., Tabik, S., Troiano, L., Tagliaferri, R. and Herrera, F.: Deep learning in video multi-object tracking: A survey, Neurocomputing, Vol.381, pp.61–88 (2020).
- [2] Luo, W., Xing, J., Milan, A., Zhang, X., Liu, W. and Kim, T.-K.: Multiple object tracking: A literature review, Artificial intelligence, Vol.293, p.103448 (2021).
- [3] Tan, M. and Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks, International conference on machine learning, PMLR, pp.6105–6114 (2019).
- [4] Tan, M., Pang, R. and Le, Q. V.: Efficientdet: Scalable and efficient object detection, Proc. of the IEEE/CVF conference on computer vision and pattern recognition, pp.10781–10790 (2020).
- [5] Glenn., J.: YOLOv5, (online), available from 〈https://ultralytics.com/yolov5〉.
- [6] Beery, S., Morris, D. and Yang, S.: Efficient Pipeline for Camera Trap Image Review, arXiv preprint arXiv: 1907.06772 (2019).
- [7] He, K., Zhang, X., Ren, S. and Sun, J.: Deep residual learning for image recognition, Proc. of the IEEE conference on computer vision and pattern recognition, pp.770–778 (2016).
- [8] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. and Chen, L.-C.: Mobilenetv2: Inverted residuals and linear bottlenecks, Proc. of the IEEE conference on computer vision and pattern recognition, pp.4510–4520 (2018).
- [9] Simonyan, K. and Zisserman, A.: Very Deep Convolutional Networks for Large-Scale Image Recognition, International Conference on Learning Representations (2015).
- [10] Schofield, D., Nagrani, A., Zisserman, A., Hayashi, M., Matsuzawa, T., Biro, D. and Carvalho, S.: Chimpanzee face recognition from videos in the wild using deep learning, Science Advances, Vol.5, No.9, pp.1–9 (online), DOI: 10.1126/sciadv.aaw0736 (2019).
- [11] Pang, Y., Yu, W., Zhang, Y., Xuan, C. and Wu, P.: Sheep face recognition and classification based on an improved MobilenetV2 neural network, International Journal of Advanced Robotic Systems, Vol.20, No.1 (online), DOI: 10.1177/17298806231152969 (2023).
- [12] Moskvyak, O., Maire, F., Dayoub, F. and Baktashmotlagh, M.: Learning landmark guided embeddings for animal re-identification, Proc. of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, pp.12–19 (2020).
- [13] Jiang, H., Fels, S. and Little, J. J.: A linear programming approach for multiple object tracking, 2007 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, pp.1–8 (2007).
- [14] Zhang, L., Li, Y. and Nevatia, R.: Global data association for multi-object tracking using network flows, 2008 IEEE conference on computer vision and pattern recognition, IEEE, pp.1–8 (2008).
- [15] P´erez-Escudero, A., Vicente-Page, J., Hinz, R. C., Arganda, S. and De Polavieja, G. G.: IdTracker: Tracking individuals in a group by automatic identification of unmarked animals, Nature Methods, Vol.11, No.7, pp.743–748 (online), DOI: 10.1038/nmeth.2994 (2014).
- [16] He, Y., Wei, X., Hong, X., Shi, W. and Gong, Y.: Multi-Target Multi-Camera Tracking by Tracklet-to-Target Assignment, IEEE Transactions on Image Processing, Vol.29, pp.5191–5205 (online), DOI: 10.1109/TIP.2020.2980070 (2020).
- [17] Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P. and Zitnick, C. L.: Microsoft coco: Common objects in context, Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13, Springer, pp.740–755 (2014).
- [18] Dendorfer, P., Osep, A., Milan, A., Schindler, K., Cremers, D., Reid, I., Roth, S. and Leal-Taixé, L.: MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking, International Journal of Computer Vision, pp.1–37 (2020).
- [19] Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixé, L. and Leibe, B.: HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking, International Journal of Computer Vision, pp.1–31 (2020).

nishioka@ist.hokudai.ac.jp
2017年北海道大学理学院数学専攻修士課程修了.同年,株式会社システム計画研究所入社,現職.2020年北海道大学情報科学院情報科学専攻博士課程入学,同大学在学中.

w.noguchi@mdsc.hokudai.ac.jp
2019年北海道大学大学院情報科学研究科博士後期課程修了.同年同大学人間知・脳・AI研究教育センター博士研究員.2021年同大学大学院情報科学研究院博士研究員.2023年同大学数理・データサイエンス教育研究センター特任助教となり現在に至る.博士(情報科学).深層学習を用いた認知モデルの研究に従事.

iizuka@chain.hokudai.ac.jp
2004年,東京大学総合文化研究科博士課程修了.2005年,日本学術振興会特別研究員(PD,はこだて未来大学),イギリスサセックス大学客員研究員.2008年,大阪大学大学院情報科学研究科助教.2013年,北海道大学大学院情報科学研究科准教授.2024年より,同大学人間知・脳・AI研究教育センター准教授.専門は人工生命,複雑系科学,認知科学.博士(学術).

masahito@ist.hokudai.ac.jp
1996年北海道大学大学院工学研究科システム情報工学専攻博士後期課程修了.同年日本学術振興会特別研究員(PD).1997年北海道大学大学院工学研究科助手.2000年同大学院工学研究科助教授.同大学院情報科学研究科助教授を経て,2007年北海道大学大学院情報科学研究科准教授.この間,科学技術振興機構さきがけ研究員,デューク大学客員研究員.博士(工学).現在は,人工知能技術の実社会応用,ゲーム情報学,スポーツ情報学等の研究に従事.NPO法人観光情報学会副会長.,人工知能学会,計測自動制御学会,精密工学会等,各会員.
採録日 2024年3月15日