Eメールセキュリティサービスをすり抜ける不審メールの傾向と対策の検討
※本稿の著作権は,日本アイ・ビー・エム(株)に帰属します.
1.本取り組みの概要
近年,Eメールを悪用したセキュリティリスクが大きな問題となっている.Eメールを悪用する脅威を防ぐには,悪性なメール(不審メール)が受信者まで届かないよう,メールの配送経路上で内容を検査し遮断を行う「Eメールセキュリティサービス」の導入が有効な対策となる.
Eメールセキュリティサービスを運用する上で問題となるのが,不審メールを通過させてしまう「すり抜け」と,正規の業務メールを誤って遮断してしまう「過検知」である.「すり抜け」の防止と「過検知」の防止はトレードオフの関係にあり,不審メールの判定条件を厳しくすると過検知が増加し,緩めるとすり抜けが増加してしまう.セキュリティ対策においては,マルウェア感染のきっかけとなる不審メールのすり抜け防止が特に重要だが,業務に支障をきたす過検知の影響も考慮する必要があり,どうしても一定数不審メールのすり抜けが発生してしまう.そのため,Eメールセキュリティサービスの運用においては,すり抜けた不審メール(すり抜けメール)を発見し,遮断するブラックリスト設定をいかに早く投入できるかが重要となる.
今回,すり抜けメールの早期発見を目的とし,機械学習と自然言語処理を用いて,メールの件名からすり抜けメールを特定するシステムの構築を行った.機械学習は近年,あらゆる分野で利活用が進んでおり,書籍やライブラリが多数公開されている.本稿では,オープンソースの機械学習エンジン「scikit-learn☆1」[1]と,日本語の形態素解析エンジン「MeCab☆2」[2]を用いた,すり抜けメールの分類に関する取り組みについて述べる.
2.すり抜けメールの傾向と対策の問題
本章では,すり抜けメールの傾向と対策の問題,システム化の検討について述べる.
2.1 すり抜けメールの傾向
現在,(株)エネルギア・コミュニケーションズ(以下,当社)には日々大量の不審メールが送りつけられており,Eメールセキュリティサービスによって,毎月約2万通以上の不審メールを遮断している.
当社が運用するEメールセキュリティサービスをすり抜ける不審メールの多くは,クレジットカード会員サイトや通販サイトのアカウント情報を窃取することを目的とした,フィッシングメールである.フィッシングメールは,メール本文や添付ファイルに記載されたURLリンクから,正規サイトを模した偽サイトに誘導し,騙された被害者が,偽サイト上で入力するIDとパスワードを盗む攻撃である.
フィッシングメールによって誘導される偽サイトは悪意を持って作られているが,ログインの仕組み自体は正規のサイトと同じであり,コンテンツを検査しただけでは検知することが難しい.そのため,フィッシングメール対策においては,過去に発見されたフィッシングメールの情報を基に,送信元メールサーバや,偽サイトのURLを既知の脅威情報リストと照合する「レピュテーション(評価)機能」が用いられる.しかし,この方法では新しく作られたメールサーバや URLには対応できず,一定期間不審メールのすり抜けが発生してしまうという問題がある.
2.2 すり抜けメール対策の問題
現在当社では,すり抜けメールに気づいた受信者自身からの通報と,外部の専門機関から提供される情報に基づいて,すり抜けメールの特定を行っている.しかし,受信者からの情報提供は不審メールに気づけるかどうかにかかっており,確実に発見できる保証はない.また,外部の専門機関から提供される情報は,発見されてから時間が経っているものが多く,情報の鮮度に問題があった.すり抜けメールを迅速に発見し遮断するためには,情報提供を待つという受動的な対応ではなく,より能動的に不審メールを発見する仕組みが必要となっていたため,今回Eメールセキュリティサービスのログから不審メールを特定する,分類システムの検討を行うこととした.
2.3 システム化の検討
システム化の検討にあたっては,以下の条件を満たす必要があると考えた.
- (1)Eメールセキュリティサービスをすり抜けた未知の不審メールを発見可能なこと.
- (2)業務情報を含むメール情報を外部に漏洩しないこと.
本システムは,Eメールセキュリティサービスが検知できなかった未知の不審メールを発見することを目的としており,これには機械学習が有効であると考えた.
なお,受信者の合意なく一方的に送り付けられるスパムメールに対する機械学習を用いた分類は,すでに多くのセキュリティサービスで利用されており,当社の使用するEメールセキュリティサービスにも実装されている.しかし,一般的なEメールセキュリティサービスが行う機械学習は,世界中で広く観測されている不審メールを学習対象としており,必ずしも当社に送付された不審メールの特徴を捉えているわけではない.
当社では,過去数年間にわたり受信者から提供されたすり抜けメールの情報を蓄積していたため,このデータを基に機械学習を行うことで,より精度の高い分類を行えるのではないかと考えた.
加えて,Eメールセキュリティサービスのログには業務情報が含まれているため,既存のクラウドサービスではなく,ローカル環境で動作する独自のシステムを構築することとした.
2.4 ログの検討
次に,機械学習で扱うデータの選定を行う.Eメールセキュリティサービスのログの内,送信者アドレスや送信元メールサーバは頻繁に変更されるため,学習対象には適していない.一方,現在確認されているすり抜けメールの多くはフィッシングメールであり,件名には通販サイトやクレジットカードの名称が記載されている.また,受信者にメールを開封させるため,「至急」や「重要」など興味を引くような文言となっていることも多いため,不審メールの特徴が表れていると考え,メールの件名を使用することとした.
なお本文にも同様の特徴が表れていると思われるが,Eメールセキュリティサービスのログには本文が記録されないため使用することはできなかった.
3.不審メール分類システムの構築
本章では,機械学習と自然言語処理による不審メールの分類について記載する.なお,本稿に記載する業務メールの件名はすべて架空のものである.
3.1 機械学習と自然言語処理の概要
先に述べたとおり,現在Eメールセキュリティサービスをすり抜ける不審メールの多くは,アカウント情報の窃取を目的としたフィッシングメールであり,その件名には標的となるクレジットカード会員サイトや通販サイトに関連する単語が使用される傾向にある.本システムでは,機械学習によって過去に当社に送信された不審メールの件名を学習し,同様の特徴を持つ未知のすり抜けメールを発見することを目的とする.
機械学習アルゴリズムは,事前に正しいデータ(学習データ)を学習し,その結果に基づいて予測を行う「教師あり機械学習」と,学習データを用いない「教師なし機械学習」に分けられるが,今回の目的である不審メールの発見には,あらかじめすり抜けメールの件名を学習させる「教師あり機械学習」が適している.
3.2 学習データの準備
教師あり機械学習では,学習データの量と多様性によって分類精度が左右されるため,いかに豊富な学習データを用意するかが重要となる.今回,学習データの作成には,(1)利用者から提供されたすり抜けメールの件名,(2)外部の専門機関から情報提供された不審メールの件名,(3)Eメールセキュリティサービスが遮断した不審メールの件名の,計13,500件を用意した.
3.3 前処理
機械学習では計算によって予測を行うため,日本語の文章(自然言語)であるメールの件名を単語に分解して解析する「形態素解析」と,個々の単語を数値データに変換する「ベクトル化」を行う必要がある.本節では,形態素解析とベクトル化について述べる.
3.3.1 形態素解析
日本語の文章は,英語のように単語と単語の間に区切り文字(スペース)が含まれておらず,そのままでは文章全体が一塊とみなされてしまうため,自然言語処理において,文章を単語ごとに分割する「形態素解析」を行う必要がある.オープンソースの形態素解析エンジン「MeCab」を用いた単語分割の例を表1に示す.
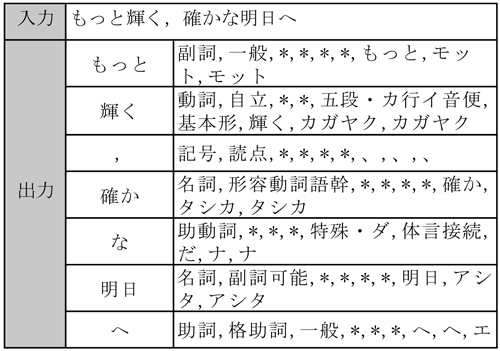
入力された文章が単語ごとに分割して出力されていることが確認できる.続いて,使用する単語の選別を行う.
教師あり機械学習では,学習データが増えるほど計算に必要なCPUリソースが必要になるため,重要度の低いデータはあらかじめ取り除いておくことが望ましい.本システムでは,不審メールの件名から不要な単語を除去するため,件名に使用されている各品詞のバリエーションを確認することとした.
日本語は品詞によって単語の種類に大きな偏りがあり,名詞のように種類が非常に豊富な品詞と,助詞や接続詞など種類の少ない品詞がある.多くのメールで共通的に使用される単語は,不審メールの分類においては重要ではないと考え,学習データとして用意した不審メールの件名13,500件に対し,各品詞の出現回数と単語数を確認した.その結果を表2に示す.
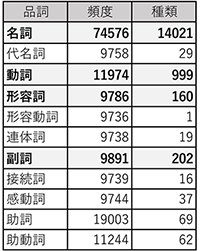
確認の結果,「名詞」「動詞」「形容詞」「副詞」の4種類以外の品詞は,出現回数に比べて単語数が少なく,同じ単語が繰り返し使用されていることが分かった.この結果に基づき,実際に不審メールの件名から4種類の品詞を抽出した結果を表3に示す.
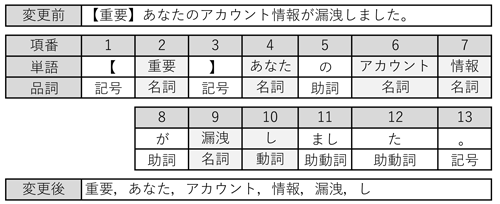
元の文章と比較して単語数は13個から6個に削減されているが,「重要」「アカウント」「漏洩」などメールの内容にかかわる単語は残されていることが確認できる.なお,形態素解析ツールが行う品詞の分類には一部誤りもあるが,今回はそのまま使用している.
続いて,抽出した単語同士の組合せについて検討する.形態素解析と品詞の選択により,必要な単語のみを洗い出したが,個々の単語をバラバラに学習しても,元の文章にあった文脈が無視されてしまい,精度の高い予測を行うことができない.そのため,自然言語処理では,隣り合う単語同士の組合せを切り出す「Nグラム」[3]という手法が用いられる.Nグラムでは,隣り合ったN個の単語(文字)を一まとまりの言葉として捉え,その言葉が文章中に何度出現するかを求める.不審メールの件名を用いて隣り合う単語を組み合わせた例を表4に示す.
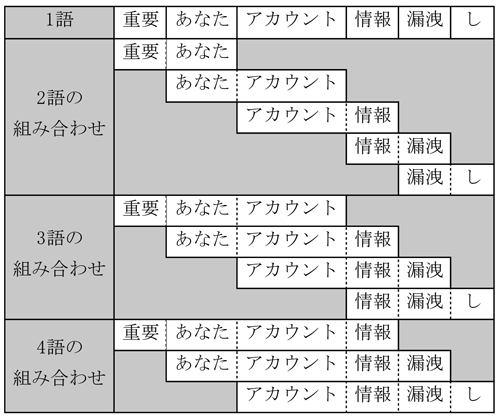
複数の単語を組み合わせることで「アカウント情報」や「情報漏洩」「アカウント情報漏洩」等,単語のみの場合よりも,フィッシングメールの特徴が表れている.ただし,4語の組合せの場合は,3語までの組合せと比べて特別な優位性は見られなかったため,本システムでは3語までの組合せを用いることとした.
形態素解析の最後に,品詞の選択による学習データの削減効果を確認する.学習データとして用意した不審メールの件名13,500件を形態素解析によって分割し,隣り合う3語までの組合せを考慮する場合,学習データは117,606個となるが,品詞を「名詞」「動詞」「形容詞」「副詞」の4種類のみに限定することで学習データは101,576個となり,16,030個(11.5%)の削減となった.
3.3.2 ベクトル化
2つ目の前処理として,単語(文字)を,機械学習で処理可能な数値(ベクトル)に変換する「ベクトル化」を行う.単語のベクトル化には複数の手法があるが,今回は最も基本的な「One hot表現(Bag Of Words)」[4],[5]を選択した.One hot表現は,文章中に使用されている単語の出現頻度を数値(ベクトル)に変換する方式であり,自然言語を扱う機械学習ではメジャーな手法のため,情報の入手が容易で機械学習の入門に適している.
オープンソースの機械学習エンジン「scikit-learn」には, One hot表現によるベクトル化を行うための関数が用意されており,単語の出現頻度をカウントする「Countvectrizer」[6]と,単語のレア度を評価する「Tfidfvectrizer」[7]を使用することができる.Countvectrizerはシンプルに単語の出現回数のみをカウントし,Tfidfvectrizerによる単語のレア度評価では,「ある文章中に何度も出てくる単語は,その文章の特徴を表している」が「多くの文章で共通して使用されている単語は重要ではない」という考え方に基づいて数値化する.Countvectrizer(出現頻度)とTfidfvectrizer(レア度)による数値化の例を表5に示す.
- ■変換前の文章
- ・文章A:広島は牡蠣と穴子と鯛が美味しい
- ・文章B:広島はレモンとブドウとミカンが美味しい
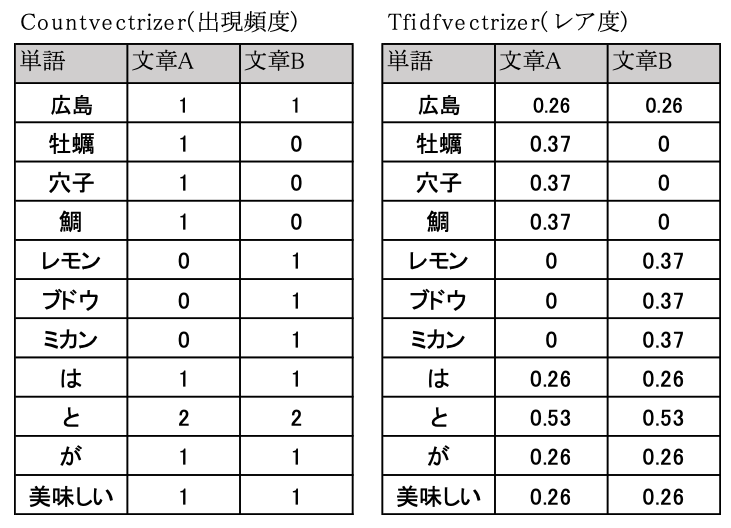
Countvectrizerでは,単純に1文中に唯一2回出現している「と」が最も高い「2」となっており,その他の単語はすべて「1」ないし「0」となっている.一方,Tfidfvectrizerでは,片方にしか出現しない「牡蠣」や「レモン」のスコア(0.37)が,2つの文章で共通して出現する「広島」や「美味しい」のスコア(0.26)よりも高くなっており,文章固有の単語が重視されていることが分かる.なお,この例ではTfidfvectrizerにおいても「と」が最も高いスコアとなっているが,これは文章数と単語数が少ないためであり,文章の数や一文の長さが増えるほど,共通的に出現する単語のスコアは低く判定される.
これら2種類のベクトル化方式のうち,どちらが不審メールの分類に適しているかを確認する.ニュース記事や小説など,ある程度の長さを持った文章を機械学習で分類する場合,文章中で繰り返し使用される,助詞や接続詞を除外できるTfidfvectrizerを用いた方が,Countvectrizerよりも分類精度が高くなる傾向にある.ただし,不審メールの件名には通販サイトの名称など特定の単語が多く使われているため,Tfidfvectrizerではこれらの単語も不要とみなされてしまう可能性がある.加えて,本システムでは,あらかじめ不要な品詞を排除しており,最も重複していると思われる「助詞」や「接続詞」はデータに含まれていない.そのため,Countvectrizerによる変換でも有効な結果を得られる可能性があると考え,2種類の変換方法を比較することとした.不審メールの件名を2種類の方式で数値化し,重要度が高いと判定された単語10個を降順に並べた結果を表6に示す.
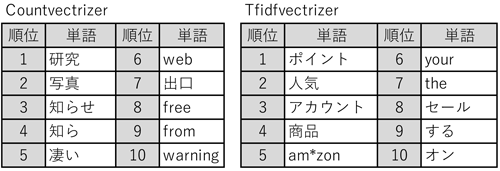
処理結果を見ると,いずれの方式でもフィッシングメールの件名に用いられる,「am*zon」や「アカウント」「warning」といった単語が抽出されており,2種類とも有効に機能していることが確認できる.この結果に基づき,本システムではCountvectrizerとTfidfvectrizerを併用することとした.
3.4 機械学習によるメール分類
ここからは,機械学習による予測について述べる.機械学習が行う予測には「分類」と「回帰」の2種類がある.「分類」はあらかじめ人の手で正しく分類されたデータに基づいて,新しく与えられたデータのラベルを予測する.「回帰」は連続する数値データから,将来の数値を予測するために用いられる.今回の目的であるすり抜けメールの特定では,メール件名に対して「不審メール」か「正規メール」いずれかのラベルを付与するため,「分類」処理となる.
「scikit-learn」には分類に使用できる分類器(関数)が複数用意されており,数値データを渡すだけで簡単に予測を行うことができる.処理対象となるデータの件数と種類に応じて,どのアルゴリズムを使用すればよいかは,scikit-learnのドキュメント[8]で公開されており,ドキュメントに基づくと「学習データが100,000件未満」の場合は,まず「線形SVC」[9]を用いて効果を確認し,期待する結果が得られない場合は,対象がテキストデータであれば「ナイーブベイズ」[10]を,それ以外の場合は「K近傍法」[11]「カーネルSVC」[12]「アンサンブル法(ランダムフォレスト)」[13]のいずれかを使用すればよいとある.今回用いる学習データは約100,000個のテキストデータであり,「線形SVC」か「ナイーブベイズ」が適しているということになるが,本当にその分類器が適しているかを確認するため,各分類器の分類精度を比較することとした.
評価するアルゴリズムは,上記5種類に,ディープラーニングで用いられる「ニューラルネットワーク(多層パーセプトロン)」[14]を加えた6種類とし,公式ドキュメントで推奨されている「ナイーブベイズ」には2種類の分類器を用いて検証を行った.検証に用いた分類器を表7に示す.

なお,各分類器の動作原理を説明するには,筆者の知識が不足しているため,本稿では結果の比較のみを行っている.
分類器の評価においては,既知の不審メールの内,学習データとして使用していない件名を用いて,分類器による予測結果の正答率を確認するとともに,混同行列を用いて内訳を確認した.混同行列は,予測結果を「真陽性」「真陰性」「偽陽性」「偽陰性」の4項目で表現することができる.本稿では以下のように混同行列を定義し,各分類器の比較を行った.
- 真陽性:「不審メール」を「不審メール」と正しく判定
- 真陰性:「正規メール」を「正規メール」と正しく判定
- 偽陽性:「正規メール」を「不審メール」と誤って判定
- 偽陰性:「不審メール」を「正規メール」と誤って判定
本システムでは大量のメールログの中から,不審メールを抽出することを目的としており,不審メールを正規メールと誤って判定する「偽陰性」は可能な限り低く抑えることが望ましい.そのため,分類器の選定においては,精度に加えて,偽陰性件数の低さも重要であると考えた.各分類器の精度を表8に示す.
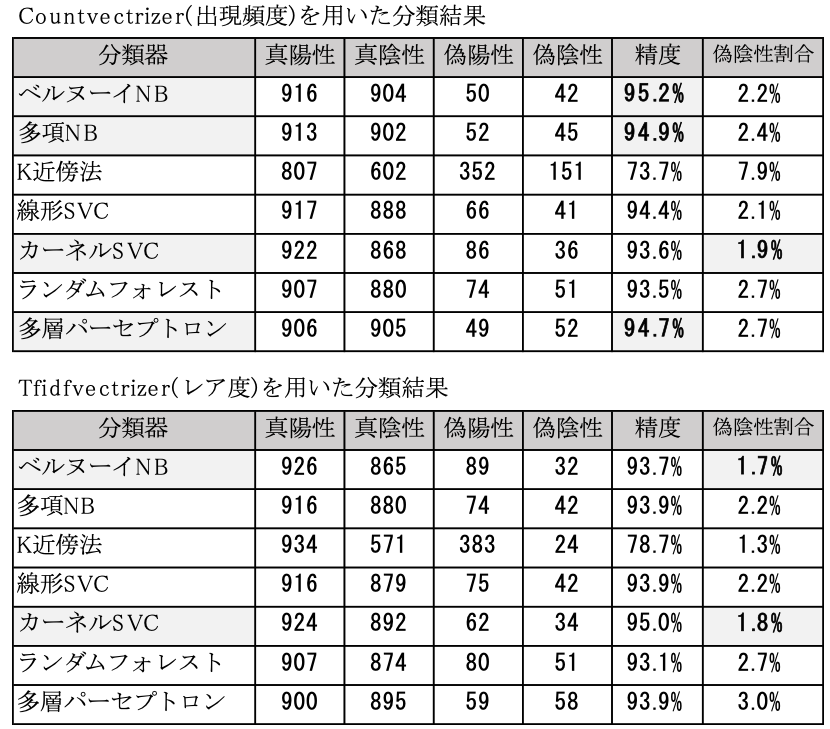
評価の結果,ほとんどの分類器で精度90%以上となっている中,K近傍法のみ70%台となっており,不審メールの抽出には適していないことが分かった.また,その他の分類器は精度には大きな差が出ていないが,偽陰性の割合を見ると,若干の差が出ていることが確認できた.この結果に基づき,本システムでは以下6種類のによる分類を行うこととした.
- (1)Countvectrizer+ベルヌーイナイーブベイズ
- (2)Countvectrizer+多項ナイーブベイズ
- (3)Countvectrizer+カーネルSVC
- (4)Countvectrizer+多層パーセプトロン
- (5)Tfidfvectrizer +ベルヌーイナイーブベイズ
- (6)Tfidfvectrizer +カーネルSVC
3.5 スコアリング
最後に,各分類器から得られた判定結果をもとに,抽出されたメールがどの程度「不審」と判定されたかを表すスコアリングを行う.各分類器の判定結果は「不審メール」か「正規メール」の2択で出力されているが,分類器によって評価が分かれたメールについては,どの程度差が出ているかを確認するため,6種類の分類方法の分類精度を用いて重みづけを行った.
正規メールと判定された場合はスコア「0」,不審メールと判定された場合は,判定した分類器の分類精度(0.94~0.95)をスコア値に加算し,複数の分類器から得られたスコアの合計値を,そのメールの最終的なスコアとする.本システムにより実際のメールログを分類した結果を表9に示す.
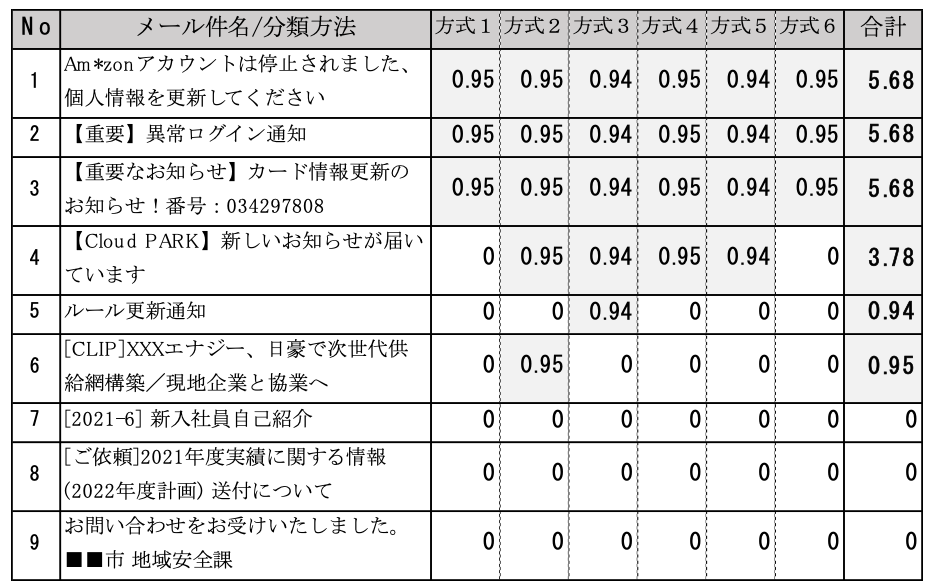
不審メール(No.1~3)には高いスコアがつけられ,正規メール(No.7~9)には低いスコアがつけられていることが分かる.また,No.4~6のように,不審メールか正規メールかが曖昧な件名については,分類器による評価が分かれ,どの程度怪しいと判定されたかを数値として表現することができた.
4.システムの有効性確認
本章では,システムの有効性を確認した結果について述べる.
4.1 性能評価
本システムが,未知の不審メールに対してどの程度有効なのかを評価する.既知の不審メール件名を用いた検証では93%以上の精度となっていたが,未知の不審メールをどの程度発見できるのかを確認するため,無作為に抽出したEメールセキュリティサービスのログを用いて不審メールの分類を行い,人による判定結果と,本システムのスコア値を比較することとした.
人が行う判定では,件名の特徴だけでなくメールサーバの所在地や管理組織名等を,外部のセキュリティ機関が公開する脅威情報に照らして確認することで,より詳細に判定することができる.実際にEメールセキュリティサービスのログから無作為に抽出したメール件名100件を,システムと人がそれぞれ判定する検証を行った結果,正答数91件,偽陽性件数9件,偽陰性件数0件となった.本システムにおいては判定精度に加え,偽陰性を低く抑えることが重要になるが,いずれも実用的な数値を出すことができたと考える.
4.2. 分類精度の向上
最後に,本システムの分類精度について考える.既知の不審メールを用いた検証では,93%~95%の精度を出せていたが,未知の不審メールに対する判定では91%(91件)と,わずかに低くなった.これは実際のメール件名には,学習データに含まれていない単語が多数含まれており,分類器が評価できない未知の単語に影響を受けたものと考えられる.教師あり機械学習においては,予測対象となるデータに対して,じゅうぶんな量と多様性を備えた学習データを用意することが重要であり,これが不足していた場合に分類精度が低下してしまう.今回,学習データとして不審メールの件名約13,500件を用意したが,当社で実際に送受信されるメールを分析するには,学習データが不足していたと考えられる.分類精度の向上には,学習データの拡充が有効な対策となるため,今後の運用において,受信者から提供されたすり抜けメールの件名を学習データに追加していく必要があることが分かった.
今後は機械学習アルゴリズムに対する理解を深め,さらなる精度の向上に取り組んでいきたい.
参考文献
- 1)Scikit-Learn Consortium : https://scikit-learn.org/stable/(2022年9月15日アクセス)
- 2)工藤 拓:MeCab : Yet Another Part-of-Speech and Morphological Analyzer, https://taku910.github.io/mecab/(2022年9月15日アクセス)
- 3)(株)zero to one:<体験型>学習ブログ N-gram,https://zero2one.jp/learningblog/(2023年4月18日アクセス)
- 4)Scikit-Learn Consortium : Scikit-Learn sklearn.preprocessing.OneHotEncoder, https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html(2023年4月6日アクセス)
- 5)Scikit-Learn Consortium : Scikit-Learn 6.2.3.1. The Bag of Words representation, https://scikit-learn.org/stable/modules/feature_extraction.html(2023年4月6日アクセス)
- 6)Scikit-Learn Consortium : Scikit-Learn sklearn.feature_extraction.text.CountVectorizer, https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html(2023年4月6日アクセス)
- 7)Scikit-Learn Consortium, : Scikit-Learn sklearn.feature_extraction.text.TfidfVectorizer, https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html(2023年4月6日アクセス)
- 8)Scikit-Learn Consortium : Scikit-Learn scikit-learn Choosing the right estimator, https://scikit-learn.org/stable/tutorial/machine_learning_map/(2023年4月6日アクセス)
- 9)Scikit-Learn Consortium : Scikit-Learn sklearn.svm.LinearSVC, https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html(2023年4月6日アクセス)
- 10) Scikit-Learn Consortium : Scikit-Learn 1.9. Naive Bayes, https://scikit-learn.org/stable/modules/naive_bayes.html(2023年4月6日アクセス)
- 11) Scikit-Learn Consortium : Scikit-Learn K-means Clustering, https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_iris.html(2023年4月6日アクセス)
- 12) Scikit-Learn Consortium : Scikit-Learn SVM-Kernels, https://scikit-learn.org/stable/auto_examples/svm/plot_svm_kernels.html(2023年4月6日アクセス)
- 13) Scikit-Learn Consortium : Scikit-Learn 1.11.2.1. Random Forests, https://scikit-learn.org/stable/modules/ensemble.html(2023年4月6日アクセス)
- 14) Scikit-Learn Consortium : Scikit-Learn Varying regularization in Multi-layer Perceptron, https://scikit-learn.org/stable/auto_examples/neural_networks/plot_mlp_alpha.html(2023年4月6日アクセス)
脚注
- ☆1 さまざまな機械学習アルゴリズムを利用することができるPython用機械学習ライブラリ.
- ☆2 日本語の文章を「それ以上分割できない最小単位(形態素)」に分割し,品詞や語尾の変化を識別するツール.
- ☆3 SCIKIT-LEARNは,Institut National de Recherche en Informatique et en Automatique および Institute Mines Telecomの登録商標です.

伊藤峰行(非会員)
mi-ito@enecom.co.jp
2011年広島工業大学情報学部卒,2017年(株)エネルギア・コミュニケーションズ入社.入社後はCSIRT(Computer Security Incident Response Team)に所属し,情報セキュリティインシデントの初動対応やセキュリティサービスの導入等を担当.現在は社外向けセキュリティサービスの企画立案に従事.
編集担当:斎藤彰宏(日本IBM)