タスク指向対話システムにおけるユーザの特徴を考慮した話題導入
Topic Introduction Considering User Characteristics for Task-Oriented Dialogue System
1. はじめに
深層学習をはじめとする各種AI技術の発展により,タスク指向対話システムを業務に活用するシーンが増えている.たとえば,よくある質問と回答のデータを学習させたモデルを利用した問い合わせ自動応答対話システムや,タスクを遂行する際に必要な情報をユーザから対話形式で引き出し,予約等の業務を行うシステムが存在する.AI技術の進展により,今後さらにシステムとユーザが協調して業務を推進することが想定されるが,現在,業務で活用されている対話システムの多くは,ユーザからシステムに話しかけることによってタスクを実施するものが多い.システムとユーザがより協調して業務を行うためには,システムとユーザが過去に話した内容を踏まえて,ときにはシステム側からユーザに話しかけ,必要な情報を獲得して業務を推進する必要があると考えられる.
そこで,システムがユーザに聞きたい内容があるときに,対話のきっかけをユーザに提供するとともに,ユーザがシステムから問われた内容を思い出しやすいように聞くことができるタスク指向対話システムを提案する.ここで,システムから問われた内容をユーザが思い出しやすく,かつ対話のきっかけとして利用できる言葉を見出しと定義する.本研究では,図1のような報告支援対話システムを検討する.本システムのユーザは,同じお客様先を複数回訪問する,かつ,訪問するたびにお客様先で実施した業務を会社に報告する必要がある社員である.本システムの利用フローについて,図1を用いて説明する.まず,ユーザはお客様先で業務を行った後,本システムを用いて自身の業務を報告する(①②).報告内容は報告のたびにログデータとして蓄積される(③).ユーザの業務特性として,ユーザは同じお客様先を複数回訪問する.本システムは外部データを参照しながら,ユーザが報告し忘れている可能性がある報告を制御部で検出し,すでに報告済みの内容の見出しを生成するとともに(④),ユーザから情報を得たい報告について,ユーザの特徴を捉えた要約を用いて問いかける(⑤)流れで動作する.本システムは報告済みの内容の見出しを付記してユーザに話しかけるため,システムは対話のきっかけを提供するとともに,ユーザが問われた内容を思い出しやすい状態を作ることが可能となる.そのことから,ユーザの応答率の向上や応答に要する時間を短縮しながら,ユーザが報告し忘れた情報を獲得できることが期待される.

Fig. 1 Our dialogue system that provides conversation opportunities using a headline generation model.
本研究では,対話データが十分に蓄積されていない状況を想定し社内ですでに蓄積されているデータを用いて図1④の見出し生成モデルの実現を検討した結果を記述する.2章では,対話履歴の利用ならびにユーザの記憶を引き出しやすくするよう設計された対話システムの先行研究について述べる.3章は,業務特性ならびに問題と,その対応方法を述べる.4章では検証目的と検証手順を述べ,5章で検証結果とまとめ,考察を述べる.
2. 関連研究
ユーザの記憶を思い出しやすくするための対話システムとして,高齢者の認知症や孤独感を軽減するために開発された傾聴対話システムがある[1].そのシステムは,ユーザである高齢者の記憶を思い出しやすくするための機能が備わっている.具体的には,ユーザの発話を繰り返したり,問い返したりする機能を有している.しかし繰り返し,問い返しの機能は,ユーザが直前にシステムに伝えた内容に対してのみ行うことができる機能であり,過去の対話の内容を用いて,システム側からユーザに話題として提供することは記述されていない.
過去にユーザと話した内容を対話に用いる事例が記述された論文がある[2].このシステムは,ユーザが過去に話した対話内容と関係がある発言を再び行った際,対話履歴からユーザ発話の要約を用いて応答するシステムである.しかしながら,過去に話した内容を用いて応答することは可能であるものの,システム側から話題は提示していないので,話題を提供する機能を実現できるものではない.
また,Twitterに投稿されたニュース記事を利用し,対話のきっかけとなる発話を生成する研究が存在する[3].きっかけとなる発話は記事の要約部分と雑談部分から構成され,対話のきっかけに要約を用いる点で本研究と類似している.しかし,過去のやりとりをユーザに思い出してもらうことが目的ではなく,本研究が着目するユーザの特徴をとらえた要約については検討されていない.他にも,ユーザの興味を引くような要約を生成する研究[4]-[6]や,システムからユーザに話しかける対話の研究として[7], [8]はすでにあるが,システムに問われた内容をユーザが思い出しやすくするために,ユーザに合わせた要約を対話のきっかけとして用いているものではない.
3. 提案内容
3.1 対話システムのタスクおよび想定ユーザ
本システムの想定ユーザは,お客様先を訪問し,営業などの業務を行う社員である.対話システムは,お客様先で業務を行うユーザから業務の報告を受けるタスクを負っている.システムがユーザから報告を受ける事案は1日では完了せず,長期間にわたってユーザが複数回お客様先を訪問し,進捗を確認する必要があるものである.なお,ユーザは1日に複数の事案の報告を行っているため,ときに報告を行うことを忘れてしまう可能性があるため,システム側からユーザに事案の報告を確認する機能が必要と考えられる.
3.2 システム構築に向けての課題
第1の課題として,システムがユーザに事案の進捗を聞く際,多くの事案の対応を同時並行で行うユーザは,いつ実施した何の事案についてシステムから問われているのかを思い出すことが困難になると想定される.そのため,システムがユーザに聞きたい事案を端的に表現したうえで,対話のきっかけをシステム側から提供する必要がある.事案を端的に表現する方法の1つとして,前述で定義した見出しを生成する方法が考えられる.
課題1で述べたような事案の見出しを作成する手段として,ユーザが報告した活動内容を入力とし,見出しが出力されるモデルを構築できれば実現可能となる.そのようなモデルの構築のために,社内にすでに蓄積されていたデータを活用する方法を検討した.具体的には,ユーザが作成した活動予定と活動結果の文書データである.この文書データは,業務特性上,活動予定を最初に入力し,その後に活動結果が作成される順序で構成されている.今回作成したいモデルは活動結果からそれを一言で表現する言葉を作る必要があるため,データが作成される順序と逆の使い方をする必要がある.社内に蓄積されているデータをそのまま使用すると,ユーザが予定を立てた段階では実行するつもりであったことが,結果として行わないケースも存在するため,見出しを生成することが不可能なデータも混在する状況となる(第2の課題).目的とするモデルの構築には,活動結果に記載されている内容から生成が可能な活動予定のデータを抽出する手段が必要となる.なお,活動予定のデータを見出しに利用することも可能であるが,現実には予定のデータがない活動も存在するため,見出しを生成する手段を検討した.
また,第3の課題として,事案を端的に表現する方法は,ユーザごとに異なる可能性がある.システムがユーザに聞きたい事案を聞くときに,たとえば,業務を行ったときに,会った人の名前を用いた表現のほうが伝わりやすいユーザもいる一方,そのとき自分が実施した内容を含む表現のほうが伝わりやすいユーザも存在すると考えられる.そのため,事案を端的に表現する方法がユーザごとに異なる場合は,ユーザの特徴を捉えた見出しを生成する手段が必要となる.また,第4の課題として,システムからユーザに提示される,事案を端的に表現したものを含む問いかけは,事案の進捗を聞く問いかけとしてユーザに受け入れられるかという課題もある.
3.3 提案するシステム
本研究は,対話データが十分に用意できない状況において,ユーザへの問いかけに利用する見出しを生成する方法について提案する.具体的には,社内に蓄積されている活動予定と活動結果のデータを活用し,見出し生成の問題を活動結果から活動予定を翻訳する問題と捉え,機械翻訳の分野で一般的に用いられているSequence-to-Sequence [9](以下Seq2Seq)のモデルを用いて実現する方法を提案する.Seq2Seqは機械翻訳や要約の分野で用いられる深層学習モデルの1つで,単語や画像の特徴量などの系列を別の系列に変換するモデルである.今回のケースでは,図2のように,活動結果について記述された自然文を,活動予定について記述された自然文に変換する形で用いる.今回は,Seq2Seqの中でも高い精度が導出可能とされているTransformer [10]を用いてモデルを構築した.活動結果の文字数は,活動予定の文字数よりも多い業務特性がある.そのため,活動結果から活動予定を出力する生成モデルの構築は課題1で述べた事案を端的に表現する手段として有効と考えられる.
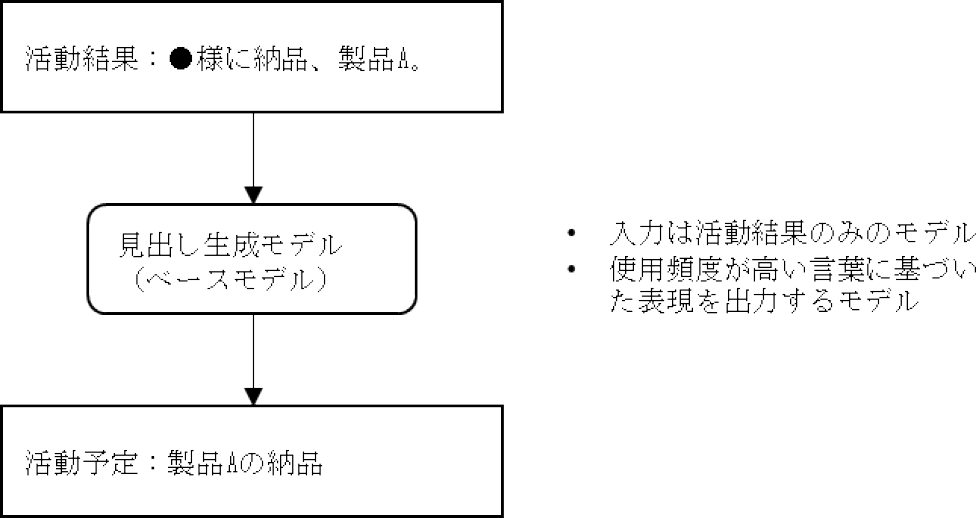
Fig. 2 A simple headline generation model.
課題2に記載の活動予定と活動結果のデータは,活動予定が先に記述され活動結果がその後に記述される業務特性を考慮する必要がある.これに対して,含意関係に基づく見出し生成タスクの見直し[11]に記載されている方法を参考に,活動予定に含まれる名詞がすべて活動結果に含まれているデータのみ抽出したうえでモデルを構築することとした.たとえば,活動予定と活動結果のデータについて,表1の#1は活動予定に含まれる名詞は「製品A」と「納品」であり,活動結果に含まれる名詞は「●」「納品」「製品A」である.活動予定に含まれる「製品A」「納品」ともに活動結果に含まれているため本データはモデルの構築に利用するデータとした.一方#2は活動予定に含まれる名詞は「B」と「C」と「運搬」であり,活動結果に含まれる名詞は「B」「運搬」である.活動予定に含まれる名詞「C」が活動結果には含まれないため,活動結果のデータから活動予定のデータを生成することは不可能である.すなわち,活動予定に含まれる名詞がすべて活動結果に含まれている状態ではないため,モデルを作成するデータからは除外した.
Table 1 Selection of the training data.

今回構築するモデルは単語の特徴量の系列を別の系列に変換するモデルを用いている.課題3に記載のユーザの特徴を考慮した見出しを生成するため,図3のように,入力データである活動結果のテキストに加えて,ユーザ個人を識別する情報(以下タグと表現する)をモデルの入力に加えた見出し生成モデルも作成した.ユーザ個人を識別するタグをモデルの入力に用いることで,ユーザの特徴(見出しの書き方など)をモデルが学習することが期待できる.ユーザの言い方に合わせた表現ができればユーザの記憶を想起することができることを期待し,対話システムからユーザに話題を提供する際,スムーズな話題の導入を実現する1つの方法であると考えた.
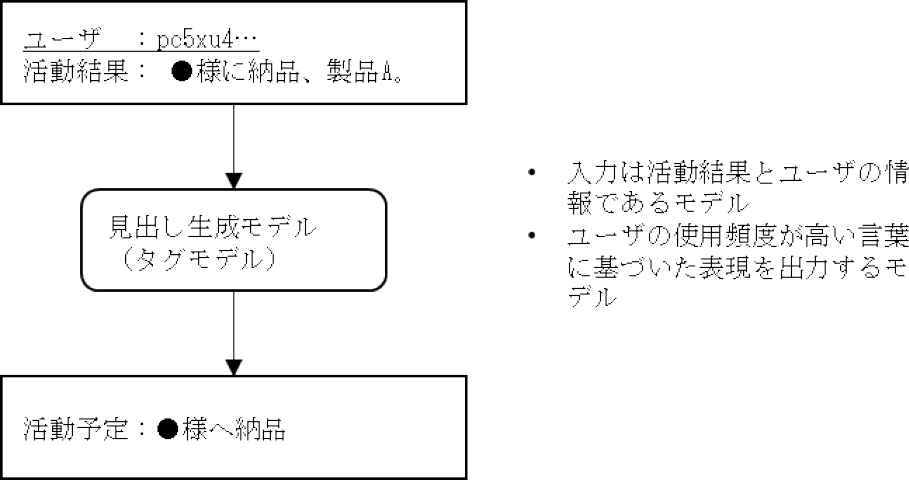
Fig. 3 Our headline generation model that takes users' taste of word choice into account.
課題4への対応として,近年の大規模言語モデルの進展により,実際に対話システムがユーザに話しかけるメッセージをすべて自動生成する方法も可能ではあるが,今回は,会社での業務で活用する対話システムであることを考慮し,安定したメッセージの提供が重要であるため,図4のようなルールベースを採用した.
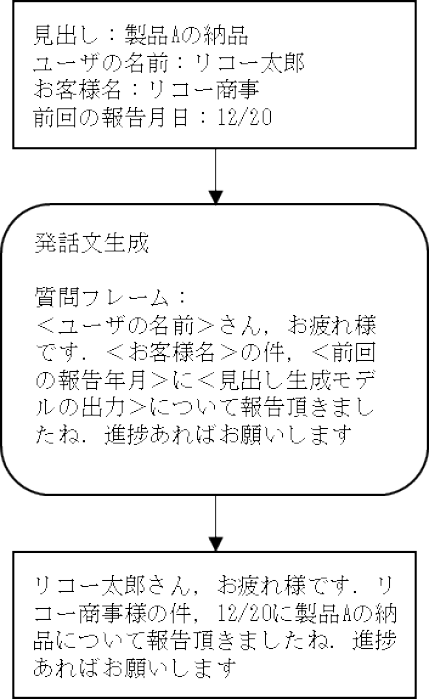
Fig. 4 An example to generate a friendly reminder by using our message template.
具体的には,対話システムの問いかけは,あらかじめ用意された質問フレームに,見出し生成モデルの出力結果を代入することで生成した.
なお,質問フレームは,「<ユーザの名前>さん,お疲れ様です.<お客様名>の件,<前回の報告年月>に<見出し生成モデルの出力>について報告いただきましたね.進捗あればお願いします.」とした.
4. 実験
4.1 見出し生成モデルの検証目的
社内にすでに存在する活動予定と活動結果のデータを用い,ユーザの報告内容を端的に一言で表現する見出し生成モデルを構築が可能かを検証することが目的である.検証の観点としては,社内ですでに存在するデータを用いて,ユーザが報告した内容を一言で表せるモデルが構築可能かを検証すること(目的①),ユーザの特徴を踏まえた見出しを生成できるかを検証すること(目的②)である.また,ベースモデルまたはタグモデルで生成した見出しを用いた対話システムの問いかけが,ユーザに受け入れられるかを判断することである(目的③).今回,ユーザへの問いかけを作成する方法として,ベースモデルとタグモデルを比較する形で検証するが,このベースモデル以外のものをタグモデルと比較することも考えられる.たとえば過去の活動結果をそのまま使う,活動結果から抽出した名詞をそのまま出力する,テンプレートに当てはめて出力するなどの方法がある.過去の活動結果をそのまま使う方法について,今回は,本システムの想定シーンに沿わなかったため比較検証しなかった.本システムは,外出先にいるユーザがスマートフォンを通してシステムと対話することを想定したものであるため,スマートフォン画面をスクロール操作することなく読める長さのメッセージが望ましい状況があった.仮に,PC等のデバイスで操作することを想定した場合はこの方法を検討してもよいと考えられる.次に,活動結果から抽出した名詞をそのまま出力する方法について,本システムは将来的に音声対応等の拡張を予定しているため,入出力がテキストから音声に変わった場合でも利用しやすいメッセージを生成したかった状況がある.仮に,名詞が列挙されている箇所を含む問いかけを音声出力する場合,対話としては不自然となる可能性が極めて高いため比較検証しなかった.また,テンプレートに当てはめて出力する方法については,テンプレートやルールの作成および管理運用のコストがかかる懸念があったため実施しなかった.
4.2 方法
実験は,データ準備,データ前処理,モデル構築,評価の順で実施した.
テータ準備について,社内に蓄積されている営業日報データの活動予定と活動結果のテキストと,報告を作成した個人を識別することができるIDのデータを用意した.
データ前処理では,スクリーニングと,IDの処理と,データを分ける処理を実施した.はじめに,データスクリーニングについて,この処理は主に次に述べる2つの観点で実施した.ひとつはシステムの対象とした業務の報告に絞るために文字数をつかってスクリーニングした.もう1つは,業務特性を考慮するため,3.3節の課題2への対応に記載した方法でスクリーニングした.具体的には,活動結果と活動予定をともに分かち書きし,活動予定のテキストに含まれる名詞のうち,活動結果テキストに含まれない名詞があるデータを除外した.テキストに記載された名詞の特定は,自然言語処理で一般に利用されているMeCab(辞書はIPADIC)を利用した.次に,IDの処理は,同一個人のデータが100件以上存在するユーザには個人を識別することができるタグを,それ以外のユーザにはOtherタグを付与し,約400種類強のタグを用意した.最後に,データを分ける処理については,学習,パラメータチューニング,評価の用途として6:2:2になるよう3つにデータを分割した.最終的に学習に利用したデータは約17万件で,活動結果は平均45文字,活動予定は平均11文字のデータで,表2のようなイメージのデータである.たとえば表2の3行目は,活動結果が「●様に納品した。製品Dについては完了。」,活動予定が「製品Dの納品」のデータである.本システムは活動結果から,活動予定に相当する見出しを生成することを検討しているが,この例の場合,活動結果に含まれる名詞「製品D」と「納品」を選び,さらに対話のきっかけとして利用するため,日本語として適切となるよう,助詞を補いながら名詞の語順を入れ替えて見出しを作る必要がある.見出しを作る方法として,単に名詞を抽出するという方法もあるが,これでは対話のきっかけとして利用するには不自然な問いかけとなってしまうため,今回見出しを生成する方法を検討した.さらに,この例以外にも,単なる名詞の抽出では,異なる意味として認識されてしまう懸念があるものも存在したため,見出しを生成する方法について検討した.
Table 2 An imaginary example of the training data.

ここから,モデル構築について述べる.活動結果の単語列から活動予定の単語列を出力するために,今回は深層学習モデルの1つであるTransformerを用いてモデルを構築した.Transformerは系列を別の系列に変換することが可能なモデルで,入力された系列の中から,生成の際,どの単語に注目するのかを考慮することが可能な注意機構を備えた要約の分野でよく用いられているモデルである.Transformerは注意機構を複数個並列で処理することが可能なため処理速度早く精度も高いと言われているため採用した.実行環境は,Ubuntu16.04.6LTS(Xenial Xerus)を利用した.GPUはGeForce RTX2080 Tiで,Python3.8,フレームワークはfairseqを用いた.Transformerの各種パラメータは,Optimizerはadamを,学習率は0.0005,ドロップアウトは0.1,バッチサイズは3584,エポック数は200とした.なお,Transformerの注意機構のヘッドの数は,エンコーダ,デコーダともに8層のモデルを利用した.モデルの学習やパラメータチューニングおよび評価は,前記分割した3種類の各々のデータを用いた.
最後に評価について述べる.まず,目的①に対する評価は,ベースモデルを用いて出力された結果と正解データとのROUGE-1,ROUGE-2,ROUGE-Lの値を算出する形で評価した.ROUGE値は,要約などの分野で評価指標として一般的に用いられている値であり,1に近いほどゴールドデータに似ている系列が出力される値である.なお,ROUGE値の算出はSumEvalを利用した.また,各モデルで生成した見出し適切か判断するため,(a)日本語として不適切な生成となっていないか,(b)誤解を生む表現なく生成されているかを目視評価した.次に,目的②に対する評価は,前述の目的①のベースモデルに対する評価と同じことを,タグモデルに対して評価する形で実施した.さらに,目的②の評価では,事案を端的に表現する方法がユーザごとに異なるかをデータ解析により確認したうえで,タグモデルの出力がユーザの特徴を満たす形で生成されたか,目視評価も実施した.最後に,目的③に対する評価は,モデルで生成した見出しを用いた対話システムの問いかけが,ユーザに受け入れられるか主観評価した.具体的には,対話システムの問いかけが,システムから送付されるメッセージとして違和感がないか,過去事案を思い出すのに役立つと感じるか否かを評価者に判定してもらった.
5. 結果と考察
5.1 学習結果
学習の結果,図5のように,Validデータセットにてベースモデルは141エポックで,タグモデルは187でROUGEが最大となった.図6のように,Lossの値も確認した所,前述のエポック数で劇的に値が上昇している様子がなかったため今回はこれらをベストモデルと判断した.
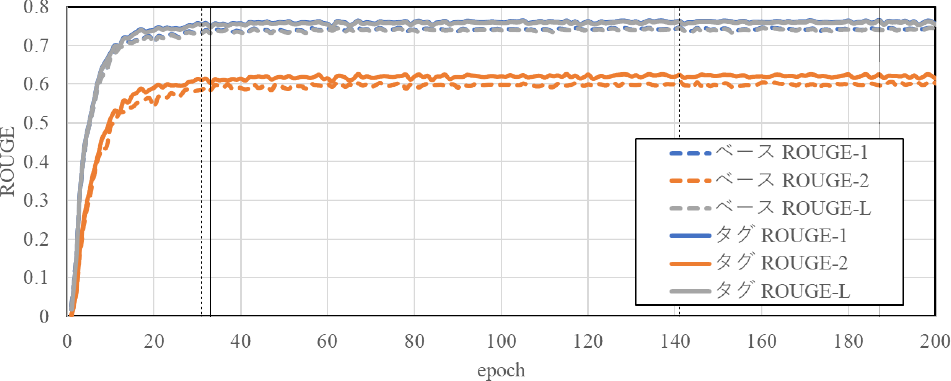
Fig. 5 The learning curve in terms of ROUGE score.
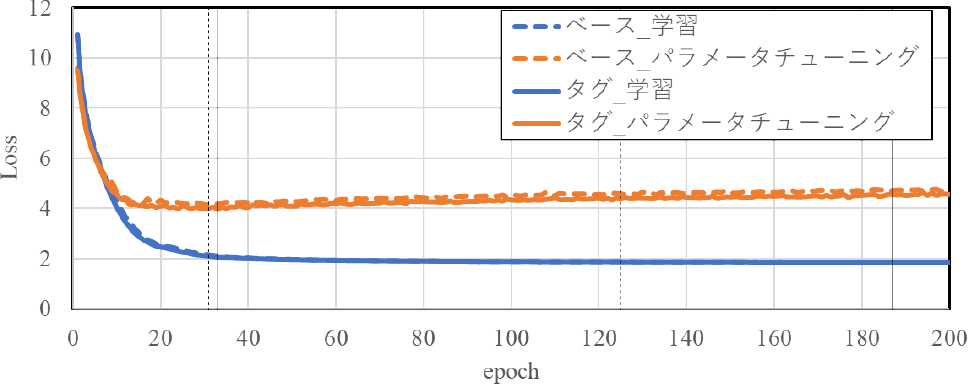
Fig. 6 The learning curve in terms of the training loss.
5.2 評価結果
5.2.1 ROUGE値
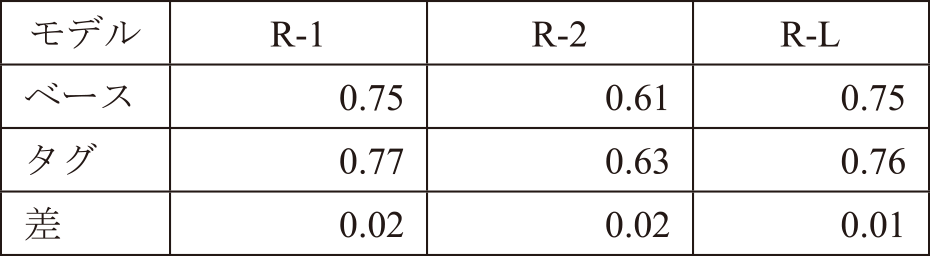
評価データに対するROUGE値を表3にまとめた.表ではROUGE-1をR-1,ROUGE-2をR-2,ROUGE-LをR-Lと標記した.表3のROUGE値を確認すると,ベースモデルとタグモデルともに高い値であった.そのためどちらのモデルもユーザが報告した内容を一言で表せていると判断できる.また,ベースモデルとタグモデルを比較すると,タグモデルのほうが約2ポイント高い値となった.また,ベースモデルとタグモデルのROUGE-1の値を有意水準0.05で検定した結果,有意差が確認された.そのため,ユーザの言い方に合わせた生成ができていると見なせた.なお,今回ROUGE値が0.7以上と比較的高い数値が出ているが,これは,今回用いたデータが活動結果の平均文字数は45字程度,活動予定は平均11文字程度のものであったことから,比較的短い文字数のものから短い見出しを生成する簡単なタスクであったことが理由として考えられる.また業務特性を考慮する際に実施したスクリーニングにおいて,活動予定のテキストに含まれる名詞のうち,活動結果テキストに含まれない名詞があるデータを除外したことも,よりタスクを簡単にした要因であると考えられる.
Table 3 ROUGE scores.
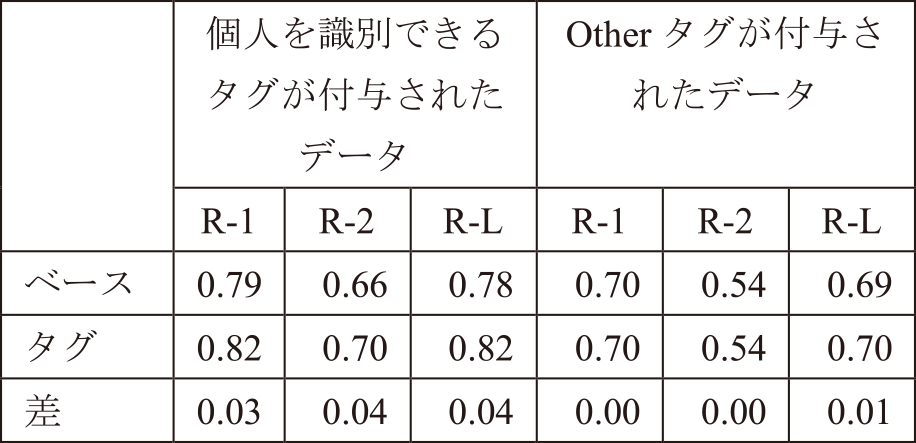
タグモデルは,ユーザの言い方に合わせた生成を実現することを期待して作成したモデルである.そのため,Otherタグが付与されたデータはベースモデルとタグモデルとの出力結果に差はなく,個人を識別するタグが付与されたデータに対してはベースモデルよりもタグモデルのほうがROUGE値は高くなると予想される.そこで,個人を識別するタグが付与されたデータと,Otherタグが付与されたデータ各々に対するROUGE値を確認した.その結果,表4のように,Otherタグが付与されたデータでは,2つのモデルで差がないが,個人を識別することができるタグが付与されたデータに対するROUGE値はベースモデルよりもタグモデルのほうが約3~4ポイント高くなる結果であった.よって,タグモデルは,ユーザの言い方に合わせた生成ができていると考えられる.
Table 4 Differences between the baseline model and our tag model.
5.2.2 目視評価
各モデルで生成した見出し適切か判断するため,(a)日本語として不適切な生成となっていないか,(b)誤解を生む表現なく生成されているかを目視評価した.具体的には,(a)については,同じ意味の言葉が2回出てきている場合や,人名や商品名などの文字が一部欠落している場合に,日本語として不適切な生成であると判断した.(a)は,日本語として適切かを判断するのではなく,不適切ではないことを確認する形としたのは,今回利用したデータが,ユーザのメモとして業務で使われる場合があることから,必ずしも日本語として適切な状態であることが理想とは言い切れないことが理由である.(b)については,活動結果に記載していない内容が生成された場合は,誤解を生む表現が含まれると判断した.上記判断基準は,主観が介在する領域が少なく客観的に判断できるものであったため,目視評価は筆者自身で実施した.目視評価に用いたデータは,個人を識別するタグが付与できた340名の中からランダムに抽出された35名の評価データ1531件に対する評価を実施した.
その結果,表5のように,ベースモデル,タグモデルともに(a),(b)いずれの観点でも多くの生成が適切に行われたと判断した.目視評価が高い傾向にあるのは,モデル作成時のスクリーニングを行ったため,比較簡単なタスクにしぼりこまれたためと考えられる.
Table 5 Inconsistency evaluation result 1.

次に,タグモデルは,システムが獲得したい事案を端的に表現する方法はユーザごとに異なるとの考えのもとに構築したモデルであるが,この考えを確かめるために,前述の検証で用いた35名の評価データ1531件の中から,20名の活動予定と活動結果のデータを20件ずつ計400件抽出し,解析した.その結果,活動結果から特定の内容(たとえば活動の進捗を表す内容など)を活動予定に記載しているユーザが5名存在し,その内容は人によって違いがあることが確認された.また残りの15名も,特定の内容を書く場合と書かない場合があるなど揺らぎはあるが記載内容に傾向はあることが分かった.このことからシステムが獲得したい事案を端的に表現する方法にユーザの特徴があることが確認された.
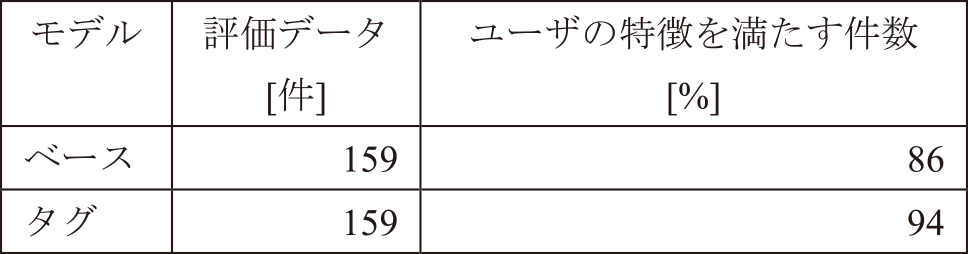
さらに,この20名の活動結果に対する2つのモデルの出力結果はユーザの特徴を満たす形で生成されているか目視評価した.その結果,表6のように,ベースモデルよりもタグモデルのほうがユーザの特徴を満たす形で生成できている件数が多いことが確認できた.
Table 6 Inconsistency evaluation result 2.
5.3 ユーザ評価
モデルで生成した見出しを用いた対話システムの問いかけが,システムから送付されるメッセージとして違和感がないか,過去事案を思い出すのに役立つと感じるか否かを主観評価した.
評価者には,過去に活動結果に記載の内容を自分が報告したと仮定してもらい,後日,システムから,報告済みの活動結果に関する問いかけを受け取った場合に,その問いかけは,違和感がなく,かつ過去の事案を思い出すことに役立つと感じた場合に1を,そうではない場合に0の評価をつけてもらった.評価者は,客観的な評価ができるよう,本研究に携わっていない社員4名で実施した.評価者は,100件の活動結果に関する問いかけを評価した.問いかけは,ベースモデルを使ったものと,タグモデルを使ったものと2種類存在するため,1名あたり200件,評価をした.評価者がどちらのモデルを使った問いかけか分からないようにするため,評価データの順番をシャッフルした.また,評価の際,判断に迷ってしまうものがあった場合や活動結果に誤植などを含むものが存在した場合には,評価結果として,0,1以外の値として,対象外の評価も認める形で実施した.
その結果,表7のように,被験者4名全員が,違和感なく過去の報告したシステムに問われた内容を思い出すきっかけになると感じたものはベースモデルで23件,タグモデルで27件存在した.1名以上が肯定した件数も確認したところ,ベースモデルで92件,タグモデルで96件であった.これは,人によって感じ方に違いがあるからであると考えられる.なお,表7の結果は,肯定の割合が極端に高い評価者が存在する場合に大きく影響を受けるため,各評価者の肯定の割合とその標準偏差を確認した.確認の結果,各評価者の肯定の割合は0.58,0.66,0.56,0.77で,その標準偏差0.09であった.このことから,今回の評価者には極端に肯定の割合が高い評価者は含まれていなかったことが確認できた.
Table 7 Functionality evaluation for the output messages from user feedback.

評価者には,肯定しなかった問いかけについては,肯定しなかった理由など,コメントを記載してもらった.コメントを解析した結果,日本語として不適切といったコメントが存在した.これは,モデルの出力を質問フレームにそのまま入力したため,たとえば,文の途中に読点が付与されてしまったものや,質問フレームに入力する際,一部同じ言葉が重複して出てきてしまうケースが存在したためである.テンプレートは,「<見出し生成モデルの出力>について報告いただきましたね.進捗あればお願いします.」という部分があるが,モデルの出力の中に「について」という言葉が含まれてしまう場合には,問いかけとしては不適切なメッセージになってしまうことがあった.この点は,テンプレート入力前にフィルタ等で処理することで解決可能である.ほかには,活動結果に記載の内容の一部を記載している場合に,より内容を包含し,漏れがない形のほうがよいとのコメントもあった.その他,汎用的すぎる表現で分かりにくい,意味の伝わりやすさや読みにくさを感じたため,といった内容もあった.
5.4 まとめと考察
システムが過去にユーザから報告をうけた事案に対する進捗の情報を獲得するタスクを実行する対話システムを題材に,ユーザの報告内容をユーザが普段よく使用する言葉を用いて表現する見出し生成モデルを用いて,システムが獲得したい事案を端的にかつユーザが思い出しやすい形で提供するシステムを検討した.本研究ではまずはユーザが普段よく使用する言葉を用いて報告内容を端的に表現する機能として,保有済みのデータをもとに作成された見出し生成モデルが利用できそうかどうかを検証した.検証の結果ROUGE0.7以上の高い精度を満たす見出し生成モデル(ベースモデル)を作成することができた.また,個人を識別できるタグを用いたタグモデルでは,ベースモデルよりも高いROUGE値となったことから,ユーザの特徴を加味した見出しを生成できることが分かった.目視評価では,日本語として不適切ではないか,誤解を生む表現がないかを確認し,9割強のデータが正しく生成できていることを確認した.なお,今回の検証の値が高い傾向になるのは,研究に用いたデータが,活動結果は平均45文字,活動予定は平均11文字のデータであったことと,業務特性を考慮したスクリーニングを実施したことで,比較的簡単なタスクとなり,活動結果の単語を抽出する形で見出しを生成することが可能となるものが含まれていたことが要因として考えられる.また,質問フレームと見出し生成モデルの出力結果を用いてシステムからユーザに提示する問いかけを作成したが,ユーザ評価では評価者全員が肯定と判断したものは少なかったが,1名以上が肯定したものは多く存在することが分かった.ただ,不適切なものと判断されたものは存在し,また,活動結果に記載されている内容を包含する形での生成,汎用的すぎる表現,意味の伝わりやすさや読みにくさに対する改善が必要であることが分かった.
また,本稿では,システムから問われた内容をユーザが思い出しやすくする方法の1つとして,あたかも自分が書いたかのような見出しを生成することを試した.システムから問われた内容を想起させやすくする方法は他にも存在する.たとえば,見出しを書くのが上手い人の情報をタグとして付けて見出しを生成するなどの方法も考えられる.この方法を用いると,ユーザ自身が書いたかのような見出しではなくなるが,より端的に,業務内容を想起させやすい見出しが生成できる可能性がある.本稿では,対話の問いかけ部分を生成することについて述べた論文であったが,この問いかけ以降もユーザとシステムの対話は続く.問いかけ以降の対話については,たとえば定型文で対話を続ける,大規模言語モデル等を用いた対話を行うなど様々な方法がある.今後は,対象となるデータの拡大や,問いかけの質を高めるとともに見出しの内容,質の改善などの課題対応が必要である.
参考文献
- [1] 音声対話ロボットのための傾聴システムの開発:〈https://www.jstage.jst.go.jp/article/jnlp/24/1/24_3/_article/-char/ja/〉
- [2] 対話システムにおける対話履歴要約の有効性について:〈https://cir.nii.ac.jp/crid/1050001339021732480〉
- [3] Conversation Initiation by Diverse News Contents Introduction: 〈https://aclanthology.org/N19-1400/〉
- [4] ContextEnhanced Personalized Social Summarization: 〈https://aclanthology.org/C12-1075.pdf〉
- [5] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization?: 〈https://aclanthology.org/Y09-2005.pdf〉
- [6] Enriching Cold Start Personalized Language Model Using Social Network Information: 〈https://aclanthology.org/O16-2003.pdf〉
- [7] ProDial – An Annotated Proactive Dialogue Act Corpus for Conversational Assistants using Crowdsourcing: 〈https://aclanthology.org/2022.lrec-1.339/〉
- [8] Proactive Human-Machine Conversation with Explicit Conversation Goals: 〈https://aclanthology.org/P19-1369.pdf〉
- [9] Sequence to Sequence Learning with Neural Networks: 〈https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf〉
- [10] Attention Is All You Need: 〈https://arxiv.org/abs/1706.03762〉
- [11] 含意関係に基づく見出し生成タスクの見直し:〈https://ipsj.ixsq.nii.ac.jp/ej/?action=repository_uri&item_id=197564&file_id=1&file_no=1〉

松原 真弓(非会員)mayumi.nakamura@jp.ricoh.com
株式会社リコー 2009年電気通信大学大学院修士課程修了,同年(株)リコーに入社.2019年より対話システムの研究開発と業務活用の検討に従事.

麻場 直喜(非会員)
株式会社リコー 2010年東京農工大学大学院修士課程修了,同年(株)リコーに入社.2019年より自然言語処理に関する研究開発に従事.

内藤 昭一(非会員)
株式会社リコー 2010年千葉大学大学院修士課程修了,同年(株)リコー入社.ソフトウェア開発および自然言語処理の研究開発に従事.現在,東北大学大学院博士課程に在籍中.

川村 晋太郎(正会員)
株式会社リコー 2006年早稲田大学大学院修士課程修了,同年(株)リコーに入社.LSI回路設計,無線通信サービス開発を経て,現在NLPに関する技術探索および研究開発に従事.

井口 慎也(非会員)
株式会社リコー 1998年神戸大学大学院修士課程修了,同年(株)日立製作所に入社,2017年(株)FRONTEO入社,2020年(株)リコー入社,AIロボット,スマートグラスの研究開発に従事.

能勢 将樹(非会員)
株式会社リコー 1999年,富士通(株)に入社し,主に(株)富士通研究所に在籍.2013年,(株)リコーに入社.音声認識やチャットボット,バーチャルエージェントの研究開発に従事しているほか,ディスプレイデバイスの駆動制御や画像処理,画質評価も専門.博士(工学).

岡崎 直観(正会員)
東京工業大学 2007年東京大学大学院情報理工学系研究科博士課程修了.東京大学大学院情報理工学系研究科・特任研究員,東北大学大学院情報科学研究科准教授を経て,2017年8月より東京工業大学情報理工学院教授.専門は,自然言語処理,テキストマイニング,機械学習.言語処理学会,人工知能学会,情報処理学会,ACL各会員.
採録日 2023年4月21日