サッカースクールにおける楽しさに関するアンケート分析と因果探索
Questionnaire Analysis and Causal Search for Enjoyment in Soccer Schools
1. はじめに
スポーツにおいて,身体活動を楽しむことや他者との交流の重要性が示唆されている[1]が,どのような活動が楽しさにつながっているのかは明らかにされていなかった.そこで,谷岡ら[2]は,徳島ヴォルティスサッカースクール*1(以下,スクール)に通う小学生を対象にMicrosoft Forms*2を用いたオンラインアンケート調査を行い,スクールに参加して感じたこと,サッカースクールの活動を楽しんでいるか,どんな活動が楽しさにつながっているかについて分析を行った.アンケートの集計結果から,サッカースクールの練習で楽しかったのは,ゲーム形式の練習であると回答したスクール生が最も多かった.また,アンケート項目間の相関分析を行った結果,「たのしかったですか?」「たくさん走りましたか?」「シュートやパスがたくさんできましたか?」「ドリブルがたくさんできましたか?」「ゴール点数」や,「いたいところがありますか?」と「つかれましたか?」に相関関係が示された.
スクールは,人間形成の指導とサッカーの指導を指導方針として掲げ,徳島県内8ヶ所で開講しているサッカースクールである.表1のように年齢やスキルレベルに応じたクラスを開講している.アンケート対象となったキッズクラス,小学校低学年,小学校高学年は,セレクションなしで参加可能なクラスであり,コーチ陣はサッカーの人格形成や技術指導を念頭に置きながらも,地域のスポーツ振興のために,長期的に参加してもらえるような環境とカリキュラム作りにも力を入れている.このような理念の下で検討されたカリキュラムに含まれるゲーム形式の練習は,JFA技術委員会が策定したJFAスモールサイドゲーム ガイドライン[3]でも言及されているスモールサイドゲーム(Small-Sided Games,SSG) [4]であり,年代ごとのサッカーの楽しみ方について考えられた練習内容となっていることが推察される.
Table 1 Tokushima Vortis Soccer School classes and instructional outline.

一方,「たのしかったですか?」の項目を『楽しかった』,「たくさん走りましたか?」の項目を『たくさん走った』,「シュートやパスがたくさんできましたか?」と「ドリブルがたくさんできましたか?」を『ボールにたくさん関わった』と分類したとき,図1で示すように相関関係を双方向の点線矢印で表せるが,『楽しかった』が原因で『たくさん走った』『ボールにたくさん関わった』のか,『たくさん走った』が原因で『楽しかった』『ボールにたくさん関わった』のか,『ボールにたくさん関わった』が原因で『楽しかった』『たくさん走った』のかについては明らかにできない.そこで本稿では,以下の流れでアンケート項目間の因果関係を探索することを考える.まず,2章でスポーツ分野・教育分野の関連研究,因果推論についての関連研究について紹介し,3章では,因果推論と因果探索の関係性について説明する.さらに,4章では,DirectLiNGAMを用いた因果探索の手法について説明する.5章では,アンケートの実施方法について説明する.6章では,相関分析と因果探索をアンケート結果を用いて分析を行う.7章では,分析結果の妥当性を検証し,アンケート項目間の関係性を明らかにする.
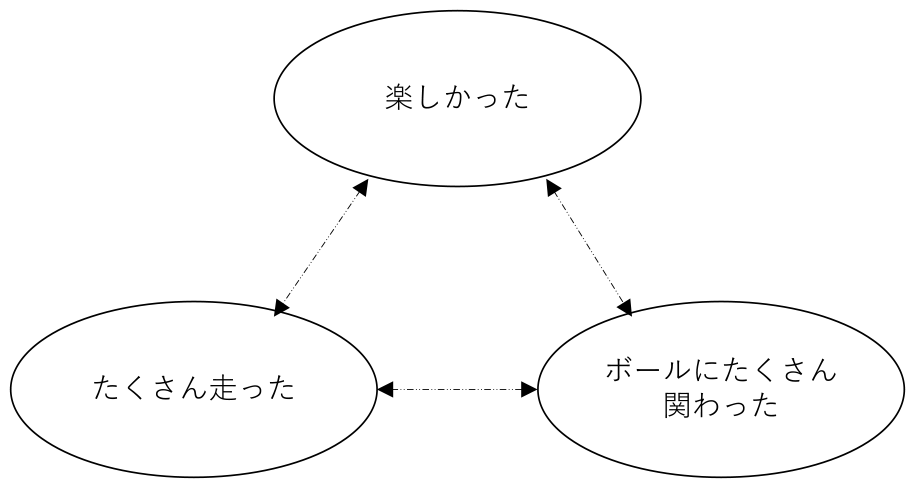
Fig. 1 Correlation estimation.
2. 関連研究
2.1 スポーツ分野
Elbeらの研究[1]では,8歳から10歳の幼児にとっては,チームスポーツによる運動が楽しさと結束力(社会性)の発達に有利である可能性が示され,スポーツ活動の継続と健康上の結果にプラスの影響を与える要因であると述べている.また,幼児教育の分野では,内田らの研究[5]で,内発的動機を意識した運動遊びの指導プログラムが運動能力の発達を促進することが示唆された.さらに,梅崎[6]は,ライフステージに応じたスポーツ活動における個人の動機付けの重要性を論じているが,スポーツ活動への参加継続については,動機の維持や目標志向性を適応的にすることなど,まだ多くの課題が残されていると述べている.一方で,Scharfenら[7]は,11歳から13歳のサッカー選手において,認知テストの累積得点が運動テストの累積得点と正の相関があると述べており,後藤らの研究[8]では,小学4年生から6年生では,戦術の意識とゲームの楽しさの間に高い相関があることが示されたことから,認知能力や戦術理解と運動能力や参加意識には何らかの関係性があることが分かる.また,Fumotoらの研究[9]では,U-12世代のボールリフティングスキルは優秀なアスリートの指標にはならないことが示されているが,後藤ら[10]の研究では,インステップでリフティングする技がゲームを楽しむ技であることが示唆された.このことから,参加意識に影響を与える技術や運動能力はあると考えられる.これらの研究結果から,プレイヤーの技術,運動能力,認知能力,参加意識には互いに何らかの関係性があるといえる.
2.2 因果推論の分野
統計的因果推論の分野において,Pearl [11]は構造フレームワークと潜在的結果フレームワークの間の形式的および概念的な関係を定義し,両方の強力な機能を使用する共生分析のツールを提示し,構造的因果モデル(Structural Causal Model,SCM)を利用することで,多変量解析から因果推論への移行を促している.一般に因果関係が事前に不明な場合,特定の変数のみを操作したランダム化比較試験(Randomized Controlled Trial,RCT)が採用されるが,教育効果の因果関係の分析においては,教育的公平性や技術的な問題から,一部のグループに介入する前向きコホート分析のようなランダム化比較試験[12]を行うことは難しい.
教育分野における教育効果の分析については,Yanoら[13]は,教育的公平性を保ったランダム化比較試験の手法を提案しているが,その効果の検証については相関関係を用いた多変量解析に留まっている.ランダム化比較試験が頻繁に実施されている医療分野においても,健診データなどから後ろ向きコホート分析を行う場合には,相関関係のみを示す形になる.そこで,大山ら[14]は健診データに対してDirectLiNGAM [15], [16]を用いて因果関係の構築を行い,医療分野での因果探索の利用可能性についての理論的な説明がなされた.また,Uchidaら[17]は健康診断データを用いて未知の疾患進行要因を特定する際に,LiNGAMを用いて検診項目間の因果関係を分析した結果,血中尿素窒素(Blood Urea Nitrogen,BUN)値が非アルコール性脂肪肝疾患(Nonalcoholic Fatty Liver Disease,NAFLD)の進行に負の影響を与えることが確認できたと報告している.
3. 因果推論と因果探索
因果推論の方法には,大きく分けると介入を伴う因果推論と介入を伴わない因果推論がある.介入を伴う因果推論の方法としては,ランダム化比較試験がある.介入を伴わない因果推論の方法としては,構造方程式モデル(Structural Squation Models,SEM) [18]やベイジアンネットワーク(Bayesian networks,BN) [18]などがある.構造方程式モデルは共分散構造分析とも呼ばれる.
ランダム化比較試験では,被検対象を2つ以上のグループにランダムに分け(ランダム化),一部のグループ(実験群・介入群)に介入し,その他のグループ(対照群・統制群)との比較を行うことで,その介入効果を検証する.構造方程式モデルでは,仮説として設定した多数の観測変数間の関係をパス図と呼ばれる因果グラフをモデリングし,その変数間の因果関係を推定する.直接観測できない潜在変数が存在する場合については対応できないが,変数間の因果関係を用いて反事実について検証し,交絡変数を発見することなどが可能となる.
ベイジアンネットワークでは,ある事象が起こった場合に他の事象が起こる条件付き確率の大きさから因果関係の強さを判断することで,複数の事象間の因果関係についてネットワーク図で表現することができるが,潜在的な交絡変数(共通因子)を持つ変数間の擬似相関を見分けることができないことや,3つ以上の変数で因果構造を学習する場合は計算コストが高いことなど,実用上の課題が多い.
因果推論では,変数間の仮説に基づいて因果関係を事前に決定しておくことや,潜在的な交絡変数を排除することが困難であったが,因果探索は,対象となる変数を特定の条件に基づく変数に限定することで,原因と結果の方向とその因果効果の強さといった因果関係そのものを見つけようとするものである.因果探索の方法は,パラメトリックなアプローチ,ノンパラメトリックなアプローチ,セミパラメトリックなアプローチに大別される.
パラメトリックなアプローチでは,構造方程式モデル(SEM)を用いて実現される.関数が線形であること,誤差変数が正規分布(ガウス分布)に従いかつ独立であるという仮定をおくため,観測変数とその誤差変数が正規分布に従わないデータに対しては適用が困難である.また,因果グラフを一意に識別できない場合があり,生成されたネットワークは,必ずしも因果関係を表しているとはいえないため,介入または事前知識を用いて因果グラフを構築する必要がある.
ノンパラメトリックなアプローチでは,任意のパラメータによって変数間の独立・従属関係が変化しない定常性と,因果的マルコフ条件によって変数間の独立性があると仮定[20], [21]した制約ベース法とベイズ法がある.制約ベース法には,PCアルゴリズム(Peter and Clark algorithm,PC algorithm) [22],FCIアルゴリズム(fast causal inference,FCI) [23],CCDアルゴリズム(cyclic causal discovery,CCD) [24]がある.ベイズ法には,ベイズ情報量基準(Bayesian information criterion,BIC)などのスコアに基づくアプローチであるGESアルゴリズム[25]などが提案されいる.分布や関数形を仮定せずに因果グラフを推測するが,データの分布や関数型を仮定すれば区別できるような因果グラフの集合を見つけることができない場合がある.
セミパラメトリックなアプローチでは,線形非正規非巡回モデル(Linear Non-Gaussian Acyclic Model,LiNGAM) [15]が提案されている.観測変数に非正規連続分布や線形性を仮定することで,因果グラフを一意に識別できる.2つの観測変数ついて,それ以外の観測変数間の因果構造を推定することで,未観測共通原因がある場合にも因果グラフを推測できるが,対象となる2つの観測変数が離散変数の場合や,正規分布に従う場合,関数型が非線形である場合は因果関係を識別できない.
実際に因果探索を行うことを考えたとき,まず観測変数(あるいは観測変数に含まれる誤差変数)について,以下の条件を確認する必要がある.
- (1) 観測変数は連続値か?あるいは離散値か?
- (2) 観測変数の分布は正規分布か?
- (3) 2つの観測変数の関係を表現する関数は線形か?
対象となる観測変数が連続値または離散値のいずれかで,分布が正規分布,2つの観測変数の関係を表現する関数が線形またはカーネル法等[26]を用いて非線形写像が可能である場合には,パラメトリックなアプローチを利用できる可能性がある.対象となる観測変数が連続値,分布が正規分布,2つの観測変数の関係を表現する関数が線形であり,十分な量のデータが入手できる場合には,ノンパラメトリックなアプローチを利用できる可能性がある.対象となる観測変数が連続値,1つの観測変数を除くすべての観測変数の分布が非正規分布(正規分布の観測変数が1つの場合は許容される)で,2つの観測変数の関係を表現する関数が線形または加法的な非線形であれば,セミパラメトリックなアプローチを利用できる可能性がある.ただし,いずれのアプローチを用いた場合にも,因果関係を推定できない例外や,実行速度の問題で結果を得ることが困難な場合があることに留意する必要がある.
4. DirectLiNGAM
線形非正規非巡回モデル(LiNGAM)は,構造方程式モデルとベイジアンネットワークの非正規型変形であり,観測されたデータは,有向非巡回グラフ(Directed Acyclic Graph;以下,DAG)で表現される過程から生成されたと仮定する.このDAGを$m \times m$の隣接行列$B = \{b_{i,j}\}$で表現したとき,$b_{i,j}$は変数$x_j$からDAG内の他の$x_i$への接続強度を表す.DAG内の変数$x_i$の因果関係順序は$k(i)$により決定する.$k(i)$はアンケート項目$i$についての変数$x_i$から変数$x_j$への接続強度順に,アンケート項目$j$を列挙したものである.このとき,因果関係順序の低い変数から高い変数に有向パスを持つことはない($b_{i,j} = 0$ $\mathrm{if}$ $k(i) \le k(j)$)という制約により非巡回であることが保証される.さらに,変数間の関係は線形であり,各観測変数$x_i$はゼロ平均であると仮定すると,次のようになる.\[{x_i} = \sum\limits_{k(j) < k(i)} {{b_{i,j}}} {x_j} + {e_i},\](1)
ここで,$e_i$は外部からの影響である.すべての外部影響$e_i$は,平均が0で分散が0でない非正規分布の連続的な確率変数であり,$e_i$は互いに独立である.また,$e_i$は互いに独立であり,潜在的な交絡変数が存在しないものとする[19].
式(1)を行列形式で書き直すと次のようになる.\[\mathbf{x} = \mathbf{Bx} + \mathbf{e},\](2)
ここで$\mathbf{x} = {[{{\mathbf{x}}_{\mathbf{1}}}, \ldots ,{{\mathbf{x}}_{\mathbf{p}}}]^{\mathbf{T}}}$は$p$-次元のベクトルであり,$\mathbf{B}$は非巡回の仮定により,厳密に下三角形になるように行と列の並べ換えを行うことができる[18].厳密な下三角とは,対角線上に0を持つ下三角構造として定義される.構造方程式を用いて,データ$\mathbf{x}$のみを観測して隣接行列$\mathbf{B}$を推定するためには,観測変数は1つを除いて非正規分布の連続的な確率変数であることが必要とされる.これらの仮定の下,変数間の因果関係順序が判明するまで変数間の単回帰,独立性評価を繰り返し,隣接行列(接続強度)を推測することでDAGを一意に推測するアプローチがLiNGAMである.なお,LiNGAMのモデルの推定には,独立主成分分析(independent component analysis,ICA) [27], [28]を用いる方法の他に,回帰分析の残差を利用するDirectLiNGAM [16]があるが,本研究ではDirectLiNGAMを用いる.
LiNGAMでは,アルゴリズムの制約から観測変数に連続変数(比例尺度または間隔尺度)を用いる必要がある.順序尺度や名義尺度の場合においても,観測変数を累積して集計することで間隔尺度と解釈し,集計結果が非正規性を持つ連続値とみなせる場合に,LiNGAMを用いて観測変数間の接続強度と方向,接続強度に基づく順序(以下,因果関係順序)の推定が可能となる.リッカート尺度(Likert scale)を用いる場合は,アンケート項目に対応する変数を累積して集計することで間隔尺度と解釈し,集計結果が非正規性を持つ連続値とみなせる場合に,LiNGAMを用いてアンケート項目間の接続強度と方向,因果関係順序の推定が可能となる.
5. アンケートの収集方法
本アンケート調査は,2021年12月から2022年4月までの約5ヶ月間,アンケートの対象は徳島校で開催されたセレクションのないキッズクラス,小学校低学年,小学校高学年のクラスの未就学児から小学6年生(4歳から12歳)のスクールの生徒とした.なお,本調査期間は新型コロナウィルス感染症が蔓延する期間であったが,感染症対策についての通知*3を都度行い,スクールの開催には細心の注意を払って開催したことが功を奏し,調査対象の徳島校においては,新型コロナウィルス感染症の影響によるスクールの開講中止には至らなかった.
調査の実施にあたっては,図2に示すMicrosoft Formsで作成したオンラインアンケートを用いた.また,オンラインアンケートでの平均回答時間は305秒,標準偏差は328秒であった.つまり,ほとんどの回答者が10分以内に回答できたため,ユーザビリティ的に大きな問題はなかったといえる.スクール実施後,定期的にオンライン調査への協力を依頼し,QRコードで読み取るアンケートサイトを利用して,スクール生は保護者の協力の下,スマートフォンやパソコンを使ってアンケートに回答してもらった結果,スクール生48名からのべ97件の回答を得た.徳島校は,1クラスあたりの定員20名,開講クラス数9クラス,総定員180名であり,定員充足率80%,参加率90%としたときサンプル数は約130名なので,回収率は37%(48 / 180)であり,定点観測に用いるには一定の信頼性があるといえる.さらに,アンケート期間20週を対象と考えた場合のサンプル数はのべ2,600名なので,回収率は3.73%(97 / 2,600)である.このため,時系列分析に用いるには信頼性が不足しているといえる.徳島校では,半数以上の生徒が入校後1年以上継続してスクールに通っており,時系列変化についても観測可能であると考えられるため,今後も継続的にアンケートを実施したい.
![スマートフォンを利用したオンラインアンケート画面(出典:文献[2],p.2) Online questionnaire on smartphone (Note: adapted from Reference [2], p.2).](TR0403-11/image/4-3-9-3.png)
オンラインアンケートの主な設問は以下のとおり.個人の属性として「1年齢」を設問とし,スクール全体については,「2たのしかったですか?」「3つかれましたか?」「4いたいところはありますか?」といった設問,練習内容の達成度については,「5シュートやパスがたくさんできましたか?」「6ドリブルがたくさんできましたか?」「7たくさん走りましたか?」「8リフティング回数」「9ゴール点数」といった設問を加えた.(ここで,5-pointは5段階リッカート尺度(5-point Likert scale)を表す.)
- (1) 年齢(numerics)
- (2) たのしかったですか?(5-point)
- (3) つかれましたか?(5-point)
- (4) いたいところはありますか?(5-point)
- (5) シュートやパスがたくさんできましたか?(5-point)
- (6) ドリブルがたくさんできましたか?(5-point)
- (7) たくさん走りましたか?(5-point)
- (8) リフティング回数(numerics)
- (9) ゴール点数(numerics)
6. アンケート結果の分析
アンケート項目は,「1年齢」「8リフティング回数」「9ゴール点数」については連続値の比例尺度として取り扱う.「2たのしかったですか?」「3つかれましたか?」「4いたいところはありますか?」「5シュートやパスがたくさんできましたか?」「6ドリブルをたくさんできましたか?」「7たくさん走りましたか?」については5段階リッカート尺度(とてもそう思う・そう思う・わからない・あまりそう思わない・まったくそう思わない)の5段階評価とし,連続値の間隔尺度として取り扱う.なお,年齢については2名が無回答であったため平均値代入により欠損値を補完した.
6.1 相関関係の分析
5段階リッカート尺度で収集した各アンケート項目が99%信頼区間($p \ge 0.01$)でデータが正規分布に従うと仮定してシャピロ=ウィルク検定を行った結果を表2に示す.また,各調査項目の正規QQプロット(Normal Quantile-Quantile plot)を図3に示す.この結果,すべてのアンケート項目が正規分布に従うとはいえないことが示された.
Table 2 Normality evaluation using Shapiro-Wilk test.

Fig. 3 Normality test using Quantile-Quantile plot for each data.
次に,アンケート項目間の相関をスピアマンの順位相関係数(Spearman Rank Order Correlation) [29]を用いて分析した結果を表3に示す.スピアマンの順位相関係数ρの検定統計量は自由度$n - 2$の$t$分布に従うため,$p$値は$t$分布において横軸の値が検定統計量の上側確率である.
Table 3 Correlation coefficients between survey items ρ.
アンケート項目間に相関がないと仮定した場合の95%信頼区間($p \ge 0.05$)としたとき,$p < 0.05$となった項目間には有意に相関があるといえる.「1年齢」は「8リフティング数」と正の相関があり,「6ドリブルをした」「7よく走った」「9ゴール数」と負の相関がある.「2楽しかった」は「5シュートやパスをした」「6ドリブルをした」「7よく走った」と正の相関がある.「3疲れた」は「4痛みがある」と正の相関がある.「5シュートやパスをした」は「2楽しかった」「6ドリブルをした」「7よく走った」「9ゴール数」と正の相関がある.「6ドリブルをした」は「1年齢」と負の相関があり,「2楽しかった」「5シュートやパスをした」「9ゴール数」と正の相関がある.「7よく走った」は「1年齢」と負の相関があり,「2楽しかった」「5シュートやパスをした」「6ドリブルをした」「9ゴール数」と正の相関がある.
6.2 クラスター分析
相関係数に基づく散布図行列(クラスターマップ)[30]を図4に示す.アンケート項目はすべて正規分布に従わないため,相関係数にはスピアマンの順位係数を用いる.散布図行列は,アンケート項目間の相関関係に基づいて図示され,相関係数に基づく距離基準に従った階層型クラスタリングで分類されている.階層型クラスタリングから,大きく2つのクラスターに分類できることが分かる.
Fig. 4 Cluster map for correlations regarding survey responses.
クラスター1は,「2たのしかったですか?」「5シュートやパスがたくさんできましたか?」「6ドリブルがたくさんできましたか?」「7たくさん走りましたか?」「9ゴール点数」で構成される.
クラスター2は,「1年齢」「3つかれましたか?」「4いたいところはありますか?」「8リフティング回数」で構成される.
図5は,クラスター1の散布図行列,図6は,クラスター2の散布図行列である.クラスター1は『楽しさ』に関する意見,クラスター2は『疲れ』『痛み』に関する意見がグループ化されているといえる.クラスタ2には「1年齢」と「8リフティング数」も含まれている.
Fig. 5 Pair plots of cluster 1.
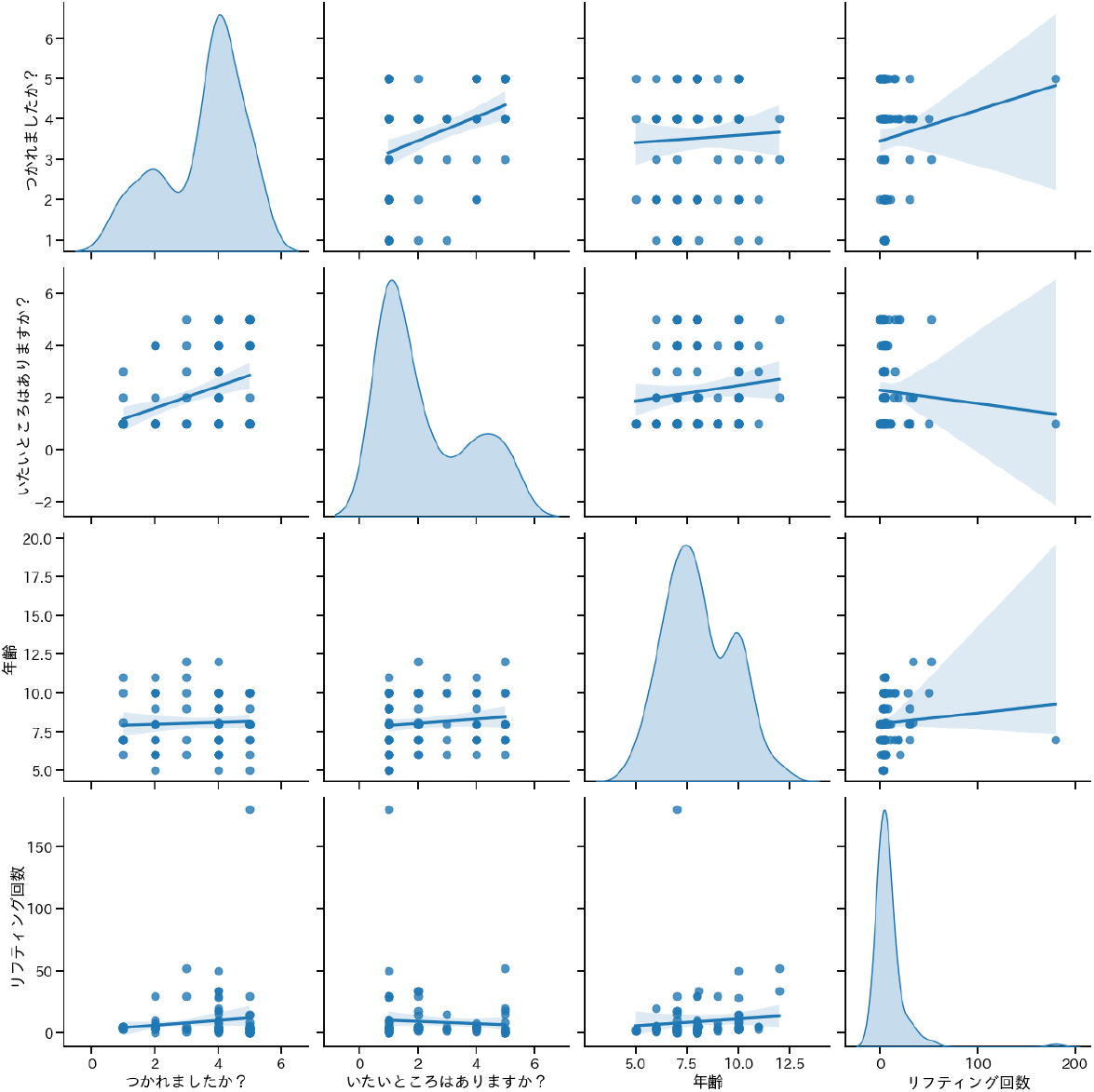
Fig. 6 Pair plots of cluster 2.
詳しく見ていくと,次のような推測ができる.
クラスター1 ドリブルをして,シュートやパスをすることは,よくゴールを決めることと相関がある.よく走ること,よくゴールを決めること,スクールを楽しむことには相関がある.
クラスター2 痛いところのあることと疲れていることに相関がある.年齢とリフティング回数に相関がある.年齢と痛いところのあることには弱い相関がある.
6.3 因果関係の分析
アンケート項目間の因果関係についてはDirectLiNGAM [15], [31]を用いた.実行環境にはGoogle Colaboratory*4を採用し,アンケート項目間の因果関係については事前知識がないため,prior_knowledgeは設定せず,その他のパラメータについてもすべてデフォルト値を用いた.DirectLiNGAMによる分析結果の係数行列adjacency_matrix_から得られた隣接行列$\mathbf{B}$を表4に示す.$\mathbf{B}$の要素$b_{i,j}$は,変数$x_j$から変数$x_i$への直接効果を表現する係数であり,変数${x_j}$から変数$x_i$へ因果効果を$[- 1,1]$の範囲で表している.また,アンケート項目$i = 1 \ldots 9$について,因果関係順序$k(i)$は式(3)となる.\[\{ k(i)\} = \{ 4,8,2,3,7,1,6,5,9\} \],(3)
Table 4 Adjacency matrix obtained from DirectLiNGAM.
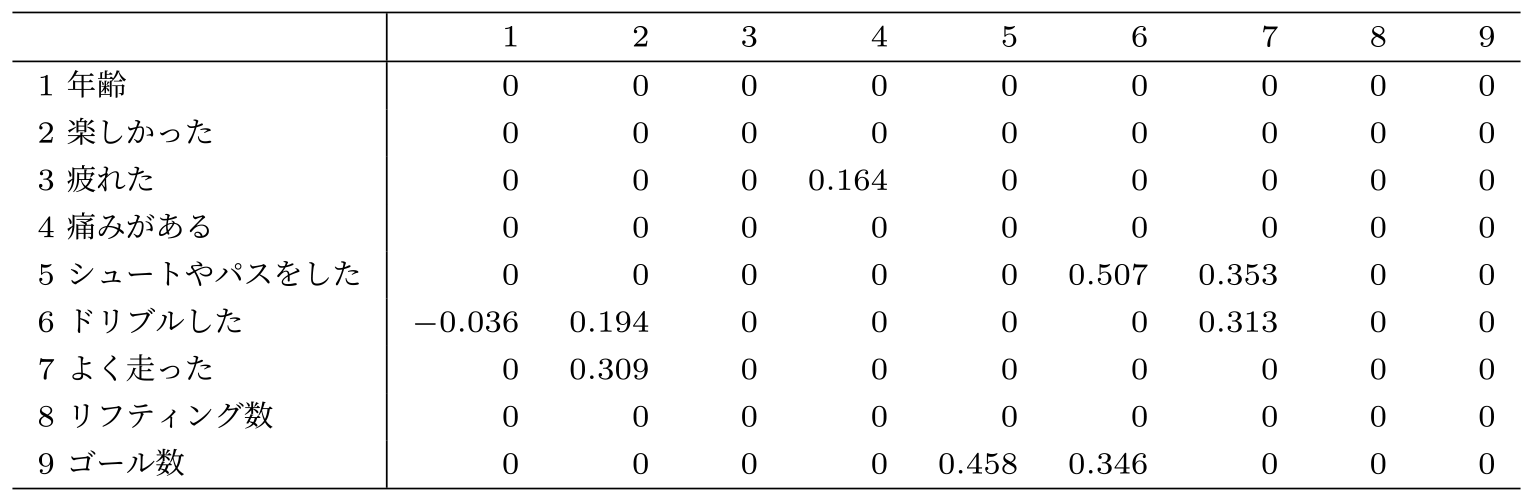
さらに,$k(i)$に基づいて行列$\mathbf{B}$の行と列を入れ替えた行列$\mathbf{B}\mathrm{^{(tri)}}$は式(4)となる.\[\begin{split} & \mathbf{B} \mathrm{^{(tri)}} = \\ & \left( {\begin{array}{*{10}{c}}0 & {} & {} & {} & {} & {} & {} & {} & {} \\ 0 & 0 & {} & {} & {} & {} & {} & {} & {} \\ 0 & 0 & 0 & {} & {} & {} & {} & {} & {} \\ {0.164} & 0 & 0 & 0 & {} & {} & {} & {} & {} \\ 0 & 0 & {0.309} & 0 & 0 & {} & {} & {} & {} \\ 0 & 0 & 0 & 0 & 0 & 0 & {} & {} & {} \\ 0 & 0 & {0.194} & 0 & {0.313} & { - 0.036} & 0 & {} & {} \\ 0 & 0 & 0 & 0 & {0.353} & 0 & {0.507} & 0 & {} \\ 0 & 0 & 0 & 0 & 0 & 0 & {0.346} & {0.458} & 0 \end{array}} \right) \end{split} \](4)
係数行列$\mathbf{B}$を因果関係順序$k(i)$に基づいて行と列を入れ替えた下三角行列$\mathbf{B}\mathrm{^{(tri)}}$は,非巡回の遷移行列を表しており,因果効果が非0の係数を用いてDAGで表現可能である.なお,各観測変数間の因果関係をDAGで表現したグラフは因果グラフであり,$\mathbf{B}\mathrm{^{(tri)}}$に基づいて,因果グラフはDAG1とDAG2の2つのDAGで表現できる.図7は「1楽しかった」から「9ゴール数」につながる観測変数の因果関係を表すDAG1,図8は「4痛みがある」から「3疲れた」への因果関係についての関係を表すDAG2である.「8リフティング回数」はいずれのアンケート項目とも因果関係が示されなかった.
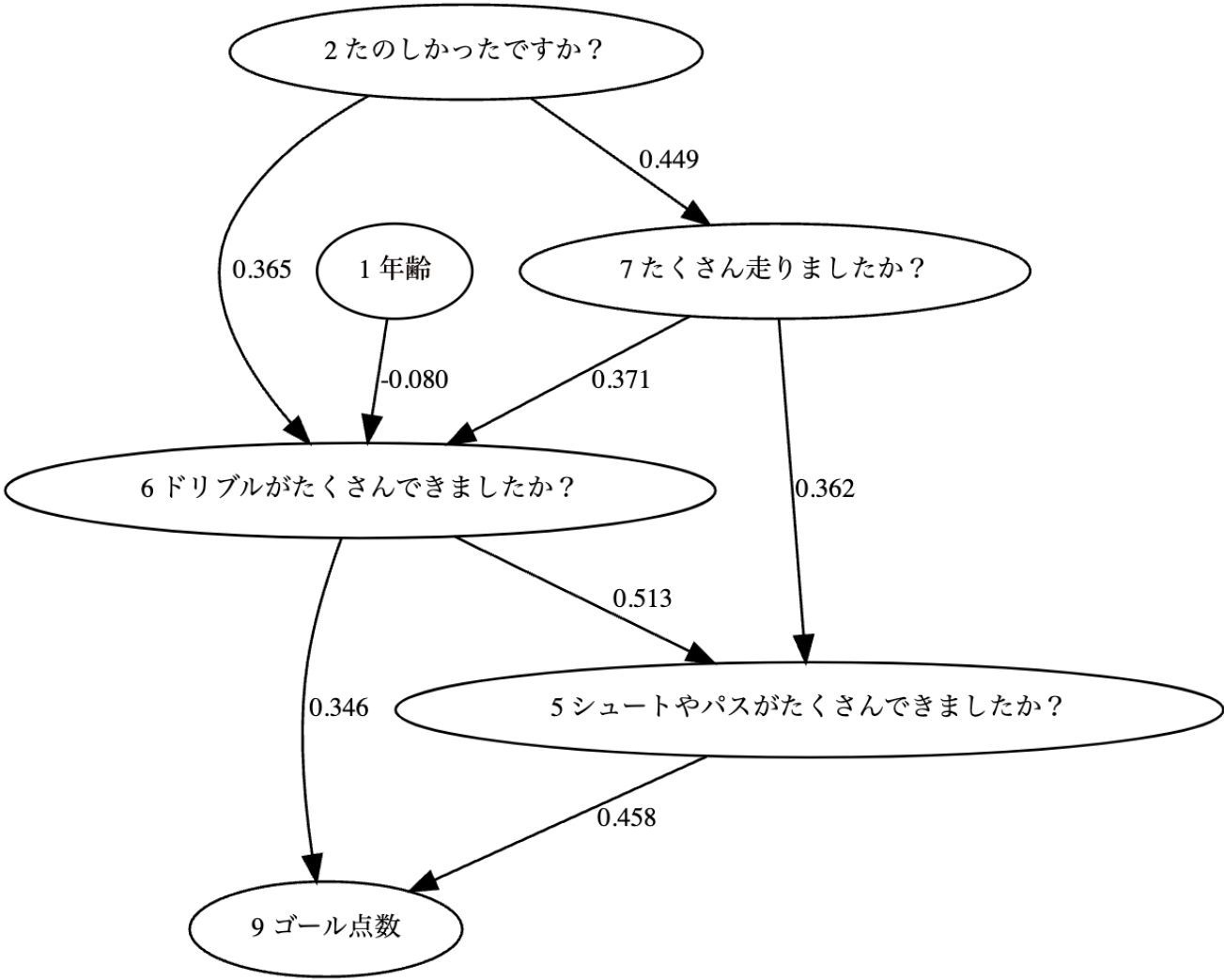
Fig. 7 DAG1 for adjacency matrix obtained from DirectLiNGAM.
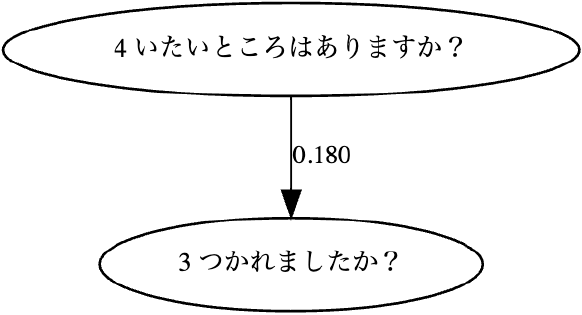
Fig. 8 DAG2 for adjacency matrix obtained from DirectLiNGAM.
DAG1は,「1年齢」「2たのしかったですか?」「5シュートやパスがたくさんできましたか?」「6ドリブルがたくさんできましたか?」「7たくさん走りましたか?」「9ゴール点数」で構成される.
DAG2は,「3つかれましたか?」「4いたいところはありますか?」で構成される.
図7は因果グラフDAG1を表し,丸いブロックで表されたノードは観測変数$x$,ノードとノードを結ぶ実線矢印は因果関係(原因$\to$結果,$x_i$ $\to$ $x_j$),実線矢印に付された数値は因果効果(係数$b_{i,j}$)を表す.「2楽しかった」が「6ドリブルをした」と「7よく走った」の原因になりうる.「1年齢」と「2楽しかった」と「7よく走った」が「6ドリブルをした」の原因になりうる.「6ドリブルをした」と「7よく走った」が「5シュートやパスをした」の原因になりうる.「6ドリブルをした」と「5シュートやパスをした」が「9ゴール数」の原因になりうる.
図8も同様に因果グラフDAG2を表し,丸いブロックで表されたノードは観測変数$x$,ノードとノードを結ぶ実線矢印は因果関係,実線矢印に付された数値は因果効果を表す.「4痛みがある」は「3疲れた」の原因になりうる.詳しく見ていくと,次のような推測ができる.
DAG1スクールを楽しめると,よく走り,よくドリブルをして,シュートやパスすることにつながる.よくドリブルをして,よくシュートやパスをすると,ゴールを決めることにつながる.年齢が低いほどよくドリブルをしている.
DAG2 DAG2から,痛いところのあるスクール生は疲れを感じている.
7. 分析結果の妥当性
図7は因果関係を図示したものである.実線矢印で因果の方向,実線矢印に付された数値が因果効果を表しており,正の数値は正の因果効果,負の数値は負の因果効果を表す.観測変数$x_i$から観測変数$x_j$を考えたときの因果効果を$b_{i,j}$としたとき,正の因果効果は観測変数$x_i$の増加に対して観測変数$x_j$が増加する関係を意味する.一方,負の因果効果は観測変数$x_i$の増加に対して観測変数$x_j$が減少する関係を意味する.
このことを踏まえると次のようにいえる.スクールを楽しんだと回答したスクール生が,よく走って($b_{2,7} = 0.309$),よくドリブルできた($b_{2,6} = 0.194$)と回答した.よく走ったと回答したスクール生が,よくドリブルができて($b_{7,6} = 0.313$),よくシュートやパスができた($b_{7,5} = 0.353$)と回答した.よくドリブルができたと回答したスクール生は,よくシュートやパスができたり($b_{6,5} = 0.507$),ゴールの得点数が多かった($b_{6,9} = 0.346$)と回答した.よくシュートやパスができたと回答しているスクール生は,ゴールの得点数が多かった($b_{5,9} = 0.458$)と回答した.また,年齢が低いほどよくドリブルができた($b_{1,6} = - 0.036$)と回答する傾向にあった.この結果は,年齢とドリブルに関する因果関係が示されていないことを除いて,クラスター1(図5)により得られた結果と矛盾はない.
図8で表された因果関係からは,痛いところがあると回答しているスクール生は,疲れたと回答している($b_{4,3} = 0.164$)ことも分かった.この結果は,クラスター2(図6)により得られた結果と矛盾はない.以上のことから,アンケート結果から,スクールに参加したスクール生から得られた情報を観測変数$\mathbf{x}$としたとき,観測変数$\mathbf{x}$に介入することなく因果関係を明確にすることができたといえる.
ただし,LiNGAMにより明らかになった因果関係については,因果グラフが非巡回であるため,よく走ったから楽しかった可能性(反事実)について検討できない.この点においては,追加実験で介入を行うか,因果探索の結果得られた因果グラフをパス図として,構造方程式モデルやベイジアンネットワークを用いて因果関係を検証してみる余地がある.
一方,年齢については相関関係の分析と因果関係の分析で異なる結果となった.相関関係では年齢はクラスター2に分類され,リフティング回数と正の相関$\rho _{1,8} = 0.261$が示されたが.因果関係ではDAG1に分類され,よくドリブルができたことに対してわずかに負の因果$b_{1,6} = - 0.036$であることが示された.つまり,相関関係からは,年齢とリフティング回数に正の相関があり,因果関係からは,年齢が低いほどドリブルができたと回答している傾向がうかがえる.相関関係においても,年齢とよくドリブルができたことには負の相関$\rho_{1,6} = -0.284$があり,相関の強さを絶対値でみると$|\rho_{1,6}|>|\rho_{1,8}|$となるため,クラスター1に含むべきであるが,相関関係の階層型クラスタリングでは距離基準に相関係数をそのまま用いたため,相関係数が負の値の場合は過小評価$\rho_{1,6}<\rho_{1,8}$されたことに起因して,クラスター2に分類されてしまったため,年齢とよくドリブルができたことの相関関係を見逃す結果となってしまった.
リフティング回数は,相関関係ではクラスター2に分類され,年齢との相関の強さが認められたが,因果関係は示されなかった.これは,相関関係を否定する結果ではなく,リフティングの回数が多いから年齢が高いわけでも,年齢が高いからリフティングの回数が多くなるわけでもない.図9のように,年齢とリフティング回数に双方向の点線矢印で表したような相関はあるが,因果関係は不明であり,実線矢印で表したような因果関係を持つ未観測共通原因があるような擬似相関であると解釈できる.
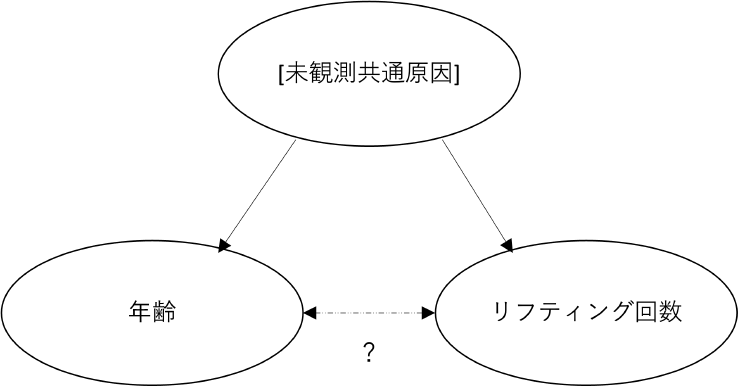
Fig. 9 Hidden common cause of age and juggling.
8. おわりに
本稿では,サッカースクールでのアンケート調査に基づいて,アンケート項目間の相関分析を行った結果から,「たのしかったですか?」「たくさん走りましたか?」「シュートやパスがたくさんできましたか?」「ドリブルがたくさんできましたか?」「ゴール点数」の回答に相関関係があること,「いたいところがありますか?」と「つかれましたか?」の回答に相関関係があることを示した.次にDirectLiNGAMを用いて因果関係を探索し,アンケート項目間の因果関係を因果グラフを用いて示した.相関係数に基づくクラスター分析の結果と,因果探索による因果グラフに矛盾はなく,相関関係のみでは示されなかったアンケート項目間の関係性を明らかにできた.
ここで,「たのしかったですか?」の項目を『楽しかった』,「たくさん走りましたか?」の項目を『たくさん走った』,「シュートやパスがたくさんできましたか?」と「ドリブルがたくさんできましたか?」を『ボールにたくさん関わった』と分類したとき,図10で表すような因果関係が示せる.ここで実線矢印は,因果関係の方向を表しており,『楽しかった』が原因で『たくさん走った』『ボールにたくさん関わった』こと,『たくさん走った』が原因で『ボールにたくさん関わった』ことが明らかになった.このほか,たくさん走ればドリブルがたくさんできて,シュートやパスがたくさんできること.ドリブルをたくさんし,シュートやパスがたくさんできればたくさんゴールを決めることができること.痛いところがあると疲れることなどの因果関係が示された.一方で,年齢とリフティング回数の因果関係は示されず,年齢が上がれば自然にリフティング回数が増えるものではないことが確認できた.このように,DirectLiNGAMを用いたアンケート結果に対する因果探索のプラクティスから,これまで,相関関係を用いた分析手法のみでは明らかにできなかったアンケート項目間の因果関係を明らかにできるという知見が得られた.
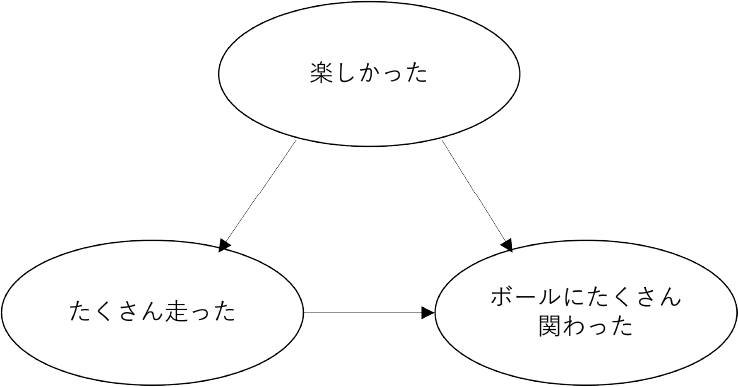
Fig. 10 Estimation of causality.
本研究は,徳島大学と徳島ヴォルティスサッカースクールの共同研究プロジェクトとして,2021年11月から2022年12月の間で実施された.共同研究プロジェクト調査終了後の2022年12月には報告会を開催した.本報告会には,大学関係者2名・スクール関係者5名が参加し,研究成果の共有と意見交換を行った.この報告会の中でコーチから出た意見の一部を以下に紹介する.
コーチA スクール生が楽しくスクール活動を行えるような指導内容,指導方法とするために,たとえば,ゲームの様子を観察していて,足の止まっている子どもがいたり,積極的にボールに関わっていない子どもがいたりした場合,ボールの数やゴールの数を調整したり,コートの広さや人数を調整することの重要性を再認識した.
コーチB これまで肌感覚では感じていた事実も含めて,数値化して報告された分析結果から,楽しく感じているスクール生ほど,より多く走り,より多くボールに関わったと感じられていることから,楽しく活動できるカリキュラム作りが技術レベルの向上や体力向上に役立つ可能性があることが理解できた.
この他,いずれのコーチからも,データを収集し,可視化することによって,客観的に現状を把握し,改善につなげていけることが分かったとの意見が得られた.このプラクティスから,本スクールでは,実際のデータに基づいた指導が実施される可能性が高まったといえる.
本研究のアンケート調査で回収したアンケート項目には,本稿で取り扱った項目のほかに,楽しかった練習,うまくできた練習,うまくできなかった練習などを選択式および自由記述で回収したものがある.今後は,これらのカテゴリカルデータを,説明変数に連続値と離散値が混在する場合にもLiNGAMモデルを拡張する手法[19]を適用するなどして,因果関係の分析を行いたい.また,相関分析の結果から,年齢が上がると痛みを感じているスクール生が増加する傾向にあることが分かったが,スクールの練習で痛めたのか,どのような練習で痛めたのか,長期的にスクールへの参加したことが要因となっているのか,セレクションのありなし,年齢やクラスによる違いなどについては明らかになっていないので,体調管理に注目した調査も検討したい.
謝辞 本研究はJSPS科研費JP22K12293,JP18K11572の助成を受けたものです.本研究を進めるにあたり,徳島ヴォルティスサッカースクールの参加者,保護者,関係者の皆さんにはご協力いただき,大変ありがとうございました.論文を執筆するにあたり,職場の同僚や関係者の皆さんのご助力,アドバイスがあったこともここに記します.大変感謝しております.本研究成果を活かして子ども達に,サッカーの楽しさを伝えられるよう尽力いたします.最後に,休日や夏休みに論文執筆のために時間を割いて迷惑をかけた家族には,お詫びをしたいと思います.
参考文献
- [1] Elbe, A.-M., Wikman, J. M., Zheng, M., Larsen, M. N., Nielsen, G. and Krustrup, P.: The importance of cohesion and enjoyment for the fitness improvement of 8–10-year-old children participating in a team and individual sport school-based physical activity intervention, European Journal of Sport Science, Vol.17, No.3, pp.343–350 (online), DOI: 10.1080/17461391.2016.1260641 (2017).
- [2] Tanioka, H., Sato, M. and Tsuge, R.: Analyze the enjoyment of soccer school in the elementary school age, IIAI Open Conference Publication Series, IIAI Letters on Informatics and Interdisciplinary Research (LIIR), Vol.1, pp.1–11 (online), DOI: 10.52731/liir.v001.011 (2022).
- [3] JFA技術委員会:JFAスモールサイドゲームガイドライン,〈https://www.jfa.jp/attachment/61f23dc0-05c0-42a5-abca-7f9ad3093d95/JFA_small_sided_gamessg_guideline20220127.pdf〉 (2022(accessed Aug 1, 2022)).
- [4] Clemente, F. M.: Small-Sided and Conditioned Games in Soccer Training: The Science and Practical Applications, Springer Singapore (2016).
- [5] 内田智子,筒井清次郎:幼児期の運動指導が体力・運動能力向上につながる運動プログラムに関する研究:内発的動機づけを重視した指導に注目して,教科開発学論集= Studies in subject development, No.7, pp.81–91(オンライン),入手先〈https://cir.nii.ac.jp/crid/1571698602746904576〉 (2019).
- [6] 梅崎高行:スポーツ活動と動機づけ,教育心理学年報,Vol.59, pp.170–190(オンライン), DOI: 10.5926/arepj.59.170 (2020).
- [7] Scharfen, H.-E. and Memmert, D.: The Relationship Between Cognitive Functions and Sport-Specific Motor Skills in Elite Youth Soccer Players, Frontiers in Psychology, Vol.10 (online), DOI: 0.3389/fpsyg.2019.00817(2019).
- [8] 後藤幸弘,松本 靖:サッカーにおける楽しさと戦術行動に関わる能力との関係:児童の意識調査とゲーム様相の実態から,兵庫教育大学研究紀要.第3分冊,自然系教育・生活・健康系教育・総合学習系教育,Vol.21, pp.41–52(オンライン),入手先〈https://cir.nii.ac.jp/crid/1050282810839955840〉 (2001).
- [9] Fumoto, N. and Kumagai, K.: Does a Player whose Ball Juggling Skill is the Best shows the Best Ability in a Soccer Game?: A Consideration of the Validity of Skill Tests from a New Viewpoint keeping Utility in Mind, Football Science, Vol.11, pp.18–28 (2014).
- [10] 後藤幸弘,高橋 潤,長井 功:サッカーのリフティング能力と個人技能,ゲームパフォーマンスならびに楽しさの関係:中学生男子を対象として,兵庫教育大学研究紀要:学校教育・幼年教育・教育臨床・障害児教育・言語系教育・社会系教育・自然系教育・芸術系教育・生活・健康系教育・総合学習系教育,Vol.26, pp.125–137(オンライン),入手先〈https://cir.nii.ac.jp/crid/1050845760793254912〉 (2005).
- [11] Pearl, J.: Causal inference in statistics: An overview, Statistics Surveys, Vol.3, No.none, pp.96–146 (online), DOI: 10.1214/09-SS057 (2009).
- [12] Medical Research Council: Streptomycin Treatment of Pulmonary Tuberculosis: A Medical Research Council Investigation, BMJ, Vol.2, No.4582, pp.769–782 (online), DOI: 10.1136/bmj.2.4582.769 (1948).
- [13] Yano, R., Tanioka, H., Matsuura, K., Sano, M. and Ueta, T.: Quantitative Measurement and Analysis to Computational Thinking for Elementary Schools in Japan, Information Engineering Express, IIAI International Journal Series, Vol.8, No.1, pp.1–17 (online), DOI: 10.52731/iee.v8.i1.658 (2022).
- [14] 大山飛鳥,古徳純一,土岐 博:ビッグデータのデータサイエンス~ニューノーマル時代のビッグデータ~:招待論文:2.大阪府の特定健康診査データの因果探索,情報処理,Vol.63, No.2, pp.d19–d47(オンライン), DOI: 10.20729/00215856 (2022).
- [15] Shimizu, S., Hoyer, P. O., Hyvarinen, A. and Kerminen, A.: A Linear Non-Gaussian Acyclic Model for Causal Discovery, Journal of Machine Learning Research, Vol.7, No.72, pp.2003–2030 (online), available from 〈http://jmlr.org/papers/v7/shimizu06a.html〉 (2006).
- [16] Shimizu, S., Inazumi, T., Sogawa, Y., Hyvärinen, A., Kawahara, Y., Washio, T., Hoyer, P. O. and Bollen, K.: DirectLiNGAM: A Direct Method for Learning a Linear Non-Gaussian Structural Equation Model, J. Mach. Learn. Res., Vol.12, No.null, pp.1225–1248 (2011).
- [17] Uchida, T., Fujiwara, K., Nishioji, K., Kobayashi, M., Kano, M., Seko, Y., Yamaguchi, K., Itoh, Y. and Kadotani, H.: Medical checkup data analysis method based on LiNGAM and its application to nonalcoholic fatty liver disease, Artificial Intelligence in Medicine, Vol.128, p.102310 (online), DOI: 10.1016/j.artmed.2022.102310 (2022).
- [18] Bollen, K. A.: Structural equations with latent variables, John Wiley & Sons (1989).
- [19] Zeng, Y., Shimizu, S., Matsui, H. and Sun, F.: Causal Discovery for Linear Mixed Data, Proceedings of the First Conference on Causal Learning and Reasoning (Schölkopf, B., Uhler, C. and Zhang, K., eds.), Proceedings of Machine Learning Research, Vol.177, PMLR, pp.994–1009 (online), available from 〈https://proceedings.mlr.press/v177/zeng22a.html〉 (2022).
- [20] Spirtes, P., Glymour, C. and Scheines, R.: Causation, Prediction, and Search, MIT press, 2nd edition (2000).
- [21] Pearl, J.: Causality: Models, Reasoning and Inference, Cambridge University Press, USA, 2nd edition (2009).
- [22] Le, T. D., Hoang, T., Li, J., Liu, L., Liu, H. and Hu, S.: A Fast PC Algorithm for High Dimensional Causal Discovery with Multi-Core PCs, IEEE/ACM Transactions on Computational Biology and Bioinformatics, Vol.16, No.5, pp.1483–1495 (online), DOI: 10.1109/TCBB.2016.2591526 (2019).
- [23] Spirtes, P.: An Anytime Algorithm for Causal Inference, Proceedings of the Eighth International Workshop on Artificial Intelligence and Statistics (Richardson, T. S. and Jaakkola, T. S., eds.), Proceedings of Machine Learning Research, Vol.R3, PMLR, pp.278–285, Reissued by PMLR on 31 March 2021. (online), available from 〈https://proceedings.mlr.press/r3/spirtes01a.html〉 (2001).
- [24] Lacerda, G., Spirtes, P., Ramsey, J. and Hoyer, P. O.: Discovering Cyclic Causal Models by Independent Components Analysis, Proceedings of the Twenty-Fourth Conference on Uncertainty in Artificial Intelligence, UAI'08, Arlington, Virginia, USA, AUAI Press, pp.366–374 (2008).
- [25] Chickering, M.: Statistically Efficient Greedy Equivalence Search, Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI) (Peters, J. and Sontag, D., eds.), Proceedings of Machine Learning Research, Vol.124, PMLR, pp.241–249 (online), available from 〈https://proceedings.mlr.press/v124/chickering20a.html〉 (2020).
- [26] Schölkopf, B. and Smola, A. J.: Learning with kernels: support vector machines, regularization, optimization, and beyond, Adaptive computation and machine learning, MIT Press (2002).
- [27] Hyvärinen, A., Karhunen, J. and Oja, E.: Independent Component Analysis, John Wiley & Sons (2001).
- [28] Jutten, C. and Herault, J.: Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture, Signal Processing, Vol.24, No.1, pp.1–10 (online), DOI: 10.1016/0165-1684(91)90079-X (1991).
- [29] Spearman, C.: The Proof and Measurement of Association between Two Things, The American Journal of Psychology, Vol.15, No.1, pp.72–101 (online), available from 〈http://www.jstor.org/stable/1412159〉 (1904).
- [30] Waskom, M.: seaborn.clustermap, 〈https://seaborn.pydata.org/generated/seaborn.clustermap.html1〉 (2012 (accessed Jun 8, 2020)).
- [31] Hyvärinen, A. and Smith, S. M.: Pairwise Likelihood Ratios for Estimation of Non-Gaussian Structural Equation Models, J. Mach. Learn. Res., Vol.14, No.1, pp.111–152 (2013).
脚注
- *1 https://www.vortis.jp/school/spread.html
- *2 https://www.microsoft.com/en-us/microsoft-365/online-surveys-polls-quizzes
- *3 https://www.vortis.jp/information/news/detail.php?id=3252
- *4 Python 3.7.13, NumPy 1.21.6, pandas 1.3.5, LiNGAM 1.6.0.

谷岡 広樹(正会員)tanioka.hiroki@tokushima-u.ac.jp
1973年生.1997年千葉大学工学部電気電子工学科卒業.2004年信州大学大学院工学系研究科情報工学専攻修了.2008年同大学大学院総合工学系研究科システム開発工学専攻修了.博士(工学).1997年株式会社ジャストシステム入社.2011年古河インフォメーション・テクノロジー株式会社入社.2014年株式会社ワークスアプリケーションズ入社.2016年徳島大学情報センター助教.2021年同大学情報センター講師.情報セキュリティ・スポーツデータサイエンス等の研究に従事.情報処理学会,人工知能学会,IEEE,ACM各会員.JFA公認C級ライセンス.

佐藤 充宏satom@tokushima-u.ac.jp
1962年生.1985岡山大学教育学部中学校教員養成課程卒業.1987年同大学大学院教育学研究科修士課程修了.1990年同大学大学院教育学研究科研究生修了.2009年徳島大学大学院先端技術科学教育部博士後期課程修了.教育学修士.博士(工学).1987年学校法人金光学園中学高等学校教諭.1990年中国短期大学非常勤講師.1991年徳島大学総合科学部講師.1996年同大学総合科学部助教授.2007年同大学総合科学部教授.2009年同大学大学院ソシオ・アーツ・アンド・サイエンス研究部教授.2017年同大学大学院社会産業理工学研究部教授.スポーツ社会学の研究に従事.日本スポーツ社会学会会員,日本体育学会,(一社)日本体育・スポーツ・健康学会 各代議員,四国体育・スポーツ学会理事.

柘植 竜治tsuge@vortis.jp
1976年生.1999年鹿屋体育大学卒業.1999年大塚製薬サッカー部入部.2001年大塚製薬(育成普及部).2005年徳島ヴォルティスU-13監督.2007年徳島ヴォルティスU-15吉野川監督.2010年徳島ヴォルティスU-18コーチ.2011年徳島ヴォルティス普及チーフコーチ.2015年徳島ヴォルティス ホームタウン推進部 リーダー.JFA公認A級ライセンス,JFA公認キッズインストラクター,R-Conditioning Coach.
採録日 2023年3月16日