特許文献によるBERT事前学習モデルと特許調査業務への応用
BERT Pre-trained Model with Patent Documents and Application for Patent Survey
1. はじめに
毎年数多く公開される特許文献や研究論文から,自らの業務や研究テーマに即した文献を効率よく仕分けする作業は様々な場面で求められる.特に製品開発で他社特許を強く意識しなければいけない企業や,特許に関する調査を行う会社ではニーズが高い.人手による仕分け作業には多くの工数を要し,増大する文献に対応するのが難しくなっている.その解決策の1つとして,特許検索システムに自然言語処理技術を取り込み,検索された文献に調査対象技術の文書上の類似性によるランキングを行うシステムも実現されている[1], [2].
自然言語処理技術としては2018年に発表されたBERT(Bidirectional Encoder Representations from Transformers)モデルは,様々な評価タスクで従来の性能を凌駕する性能を達成し[3],Web検索システムや翻訳システムなどに応用が広がっている[4].さらにGoogleからは米国特許で訓練された特許専用モデルもリリースされた[5].一方でBERTは計算コストが大きいという課題があり,専用のグラフィックボードや多くのメモリを搭載した計算機が必要となる.そのためモデルの軽量化[6]の検討も行われている.
本稿ではBERTの特許調査業務への応用について論じるので,最初に図1の特許調査の作業フローを使って調査の特質を説明する.企業が行う特許調査には「技術動向調査」「出願前調査」「侵害回避調査」などがある.技術動向調査は調査対象の技術を元にクエリを作成し特許データベースから特許公報の集合を検索した後,人が調査対象の技術と判断できるものを数百件仕分けして,その統計的な分析を行う調査である.出願前調査は特許庁における先行技術調査とおなじで,新しく出願を考えている(出願された)文書から関連する特許文献を収集し,新規性/進歩性の判断基準となる数件を人手で仕分けする調査である.このときに特許検索された公報集合を更に調査対象の技術を表した文書との比較で機械学習がランキングすることで,人の仕分け作業をサポートすることも考えられている.
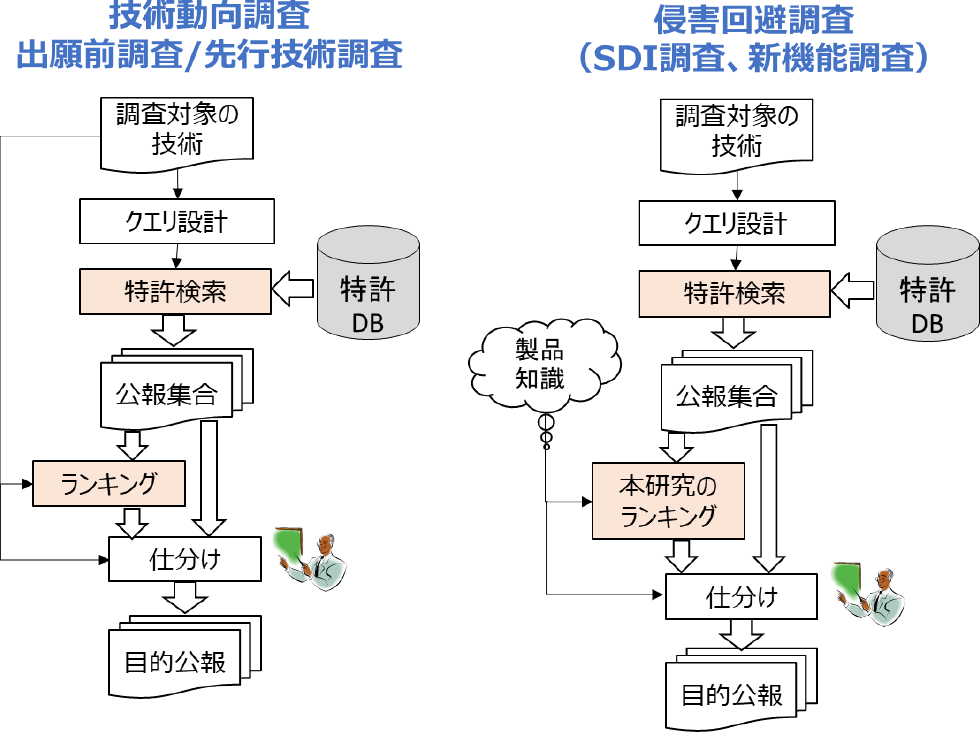
Fig. 1 Workflows of patent surveys.
一方,侵害回避調査では調査する製品が他社特許を侵害していないことを確認する調査である.特許検索して公報集合を作成するところまでは同じ手順であるが,その後の仕分けの方法が異なり,公報集合と製品搭載技術を比較して仕分けする必要がある.ここで課題となるのは,製品に関する知識は製品仕様書や取扱説明書に記載されているかもしれないが,特許文献と類似性を比較できるような文書として存在しないことである.また製品知識の多くは開発者の頭の中にだけ存在する情報で,特許文献を解釈しながら判断する必要がある.知財専門雑誌の中で迫川も「侵害回避調査は文書の中身を解釈しないと判断できないという難しさを持っている」と指摘している[7].
侵害回避調査には2とおりの実施方法がある.ひとつは新機能調査といって,新機能を導入するときに当該技術が他社の特許技術を侵害していないことを確認するためのものである.もうひとつはキーワードや技術分野などの条件をあらかじめ指定しておき,その条件に該当する特許情報を定期的に検索して自社と関係しそうな特許を仕分けし,必要なデータを収集・管理する調査である.この手法は一般的にSelective Dissemination of Information(SDI)と呼ばれて,特許文献以外の科学技術論文でも一般的に行われている.
侵害回避調査では人手による仕分け作業に工数がかかるという課題がある.製品開発には有限な費用と工数の範囲で行う必要があるので,漏れのない調査を目指しながら妥当な範囲に絞って調査実務を行っているのが現状である.この課題に対応すべく,本研究ではSDI調査を対象として,過去に仕分けした情報の蓄積を使って製品との関連性で特許公報集合をランキングする,という方法を提案する.この仕分け情報には製品との関係を人が判断した情報が含まれているためである.これにより侵害回避調査の効率化を図ることを目的とする.提案の有効性を示すために,SDI調査の仕分け情報を使ったランキングが正しく行えるかをBERTモデルで検証する.また何年データを蓄積していると有効なランキングができるかを検証する.
更に,Wikipedia等で事前学習した一般BERTモデルは計算コストが高いという課題があるので,特許文献で事前学習した特許専用の小型のモデルを作成し,一般BERTモデルとの代替可能性ついても確認を行う.
本稿では次の順序で説明する.2章では今回の提案と関連した研究と特許検索サービスについて概観する.3章では本研究で使用するBERTモデルの基本的な構成と特質を説明し,日本語特許専用モデルの作成方法について述べる.4章ではランキングを評価するためのタスクの説明を行うとともに,5章では評価指標としてより分かりやすいREIという指標を導入したので,その考え方とメリットを説明する.6章では実験結果を示し,7章でその結果の考察を行い,8章で提案手法の有効性と将来の応用についてまとめる.
2. 関連研究
文書のランキングに関しては,古川らは入力文書と検索対象特許公報の文書ベクトルのコサイン類似度によってランキングする方法を提案している[8].一方TianらはBERTのコンテキスト依存の類似性計算の利点を使った科学技術論文の検索について提案している[9].
またこのような機械学習を使った類似度計算を実際の特許検索システムに適用した事例もある.たとえば,amplified ai Inc.が提供するサービスでは,調べたい技術を説明した文章や指定した登録番号の特許との類似度の高さで特許公報をソートする機能を提供している[1].
パテント・インテグレーション株式会社では入力した文書から類似の特許公報を検索する概念検索を可能としており,クエリ設計も自動化する一方で,検索された特許公報に対してランキングを行うことで人手の仕分け作業が効率化できる機能を有している[2].以上のランキング機能はいずれも出願前調査などでクエリ作成の前提となる文書との類似度を計算するもので,製品知識を使ってランキングするものではない.
一方でPanasonicが提供するPatentSQUAREでは「AI検索機能」という機能を提供しており,社内分類情報を付与した情報から検索された特許と社内分類との関係の有無を判断するサービスを提供している[10].この機能に社内分類情報として過去の仕分け情報を入力すれば,本研究で行うランキングに近い機能が達成できる.AI検索機能の性能については特に情報が開示されていないが,本研究はこれと同等の機能をBERTモデルで確認することに相当する.さらに本研究ではWebサービスで使用している大規模な計算機を使用せず,一般的なPCでも実行できる特許専用モデルの検証も行う.
3. BERTと分野専用事前学習モデル
3.1 BERTのしくみ
BERTの詳細な動作に関してはAlammarの解説[13]に委ねるが,ランキングを行う上で必要な構成と性能に影響するパラメータについて図2を使って説明する.
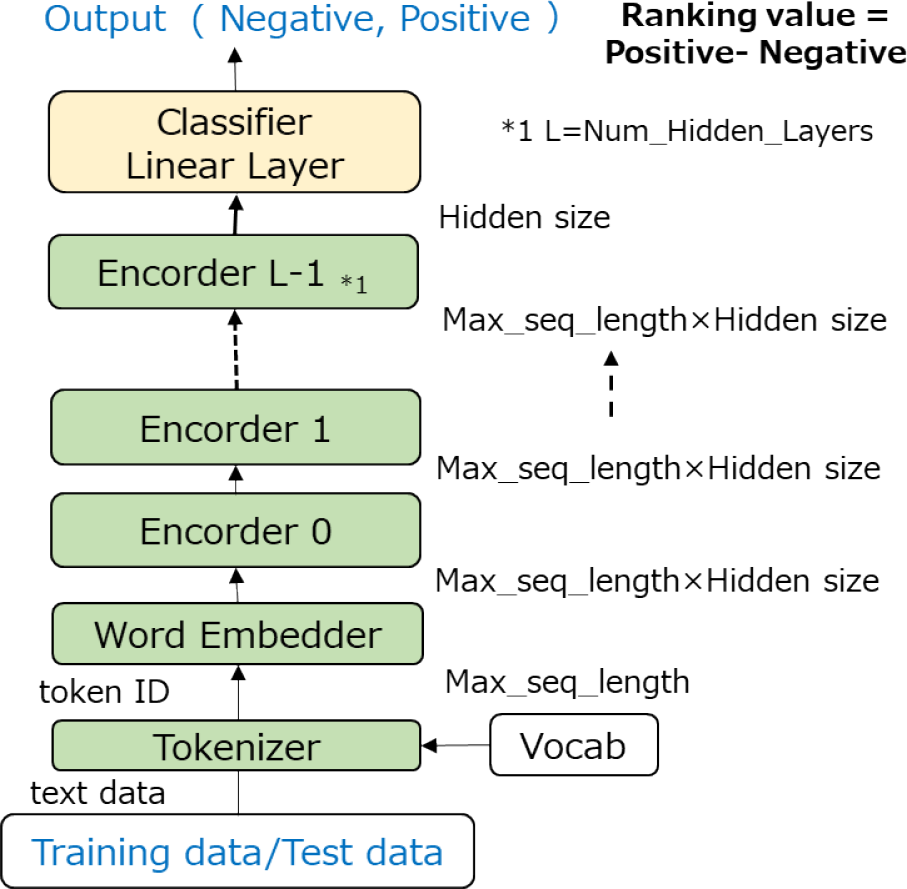
Fig. 2 Structure of BERT model.
BERTは従来の自然言語処理モデルである再帰型ニューラルネットワーク(Recurrent Neural Network:RNN)[11]のようなトークンのシーケンス入力を再帰的に計算して文書全体の情報をベクトルで表現する方法と異なり,アテンション(注意機構)により計算するTransformers [12]を使った複数のエンコーダ層で構成されることが特徴である.BERTのアテンションの計算は入力されるトークン間のすべての関係を計算するためパラメータ数がRNNに比べて格段に大きくなり複雑なモデル表現が可能な一方で,計算機資源を多く必要とする.
BERTのもう1つの特徴は,個別タスクの学習前に大規模なコーパスを使って事前学習モデルを作成することである.事前学習モデルには図2の緑色部分が含まれ,大規模コーパスを使ってエンコーダのパラメータを学習する.この学習はコーパス文書のトークンの一部をマスクして,それを予測する訓練と,一連の文が次に現れる文か否かを判定する訓練を行うことで,トークン間の関係を学習する.この訓練データはコーパス文書があれば自動で生成できるので大規模な学習が可能となる.従来の事前学習モデルは大規模な計算資源を持った組織が作成・公開して,個別タスクに使うユーザが利用できるようになっている.
事前学習モデルをベースに分類タスクのような個別学習を行うときには,黄色の分類器を付加して分類タスクの訓練データを入力して分類器のパラメータを調整するとともに,エンコーダのパラメータも微調整する.そのため個別学習はFinetuningと呼ばれている.あらかじめ事前学習することで少ない教師有りデータでも,個別の分類タスクにおいて高い性能を上げることが可能となる.
具体的な個別学習の手順を説明する.本研究で取り上げる「製品との関連性で特許公報集合をランキングする」というタスクでは,過去に選別を行って関係あり(正例)関係なし(負例)のラベルがついた文書を訓練データとして入力する.
形態素分解(Tokenizer)では「Vocab」という辞書ファイルにもとづきテキストがトークン単位に分解され,文書の先頭に[CLS],区切りに[SEP]という特殊トークンを付加した後にトークンIDに変換される.このとき辞書にない単語は[UNK]というトークンに置き換えられる.また辞書に登録されていない単語でも,Byte Pair Encoding(BPE)を使うことで,複数のサブワードに分解する手法を使う場合もある[14].たとえば“エアコンディショナ”という単語を,“エア”と“コンディショナ”という2つのサブワードに分割することで,辞書登録数を大幅に増やさずに[UNK]トークンを減らすことができる.
単語埋め込み層(Word Embedder)ではトークン単位で辞書に登録されたトークンIDがHidden sizeの埋め込みベクトルに変換されエンコーダ層(Encoder 0)に入力される.辞書にはVocab_sizeのトークンが登録されていて,1つのトークンがHidden_sizeの次元のベクトルに変換されるので,この次元が高いほど多様なトークンの表現が埋め込まれることになる.エンコーダに入力できるトークン数(文の長さに相当)は最大シーケンス長(Max_seq_length)であらかじめモデル設計時に決められているので,それを超える入力は切り捨てられる.
エンコーダ層は複数(Num_hidden_layers)のエンコーダによって構成される.このエンコーダ層の中でアテンション計算が行われ,入力されたトークン間の関連性が埋め込みベクトルによって計算される.さらに1つのエンコーダ層の中で並列して複数のアテンション計算が行われており,並列数をNum_attention_headsで表す.
エンコーダの最終層からは先頭の[CLS]に対応するHidden_sizeの埋め込みベクトルだけが取りだされ,個別タスクの分類器(Classifier Linear Layer)に入力される.今回検証するタスクは2値分類タスクになるので,分類器は正例および負例の予測確率に対応した値(Positive,Negative)を出力する.個別学習時にはこれらの出力と教師データとの差を損失関数として計算し,分類層のパラメータにフィードバックするとともに,エンコーダ層のパラメータも微調整する.
予測計算時にはラベルのないデータが個別学習後のモデルに入力され,分類層の出力(Positive,Negative)を比較して入力文書に対する分類を決める.またPositiveとNegativeの値の差を評価値として,入力された文書のランキングを行うことができる.
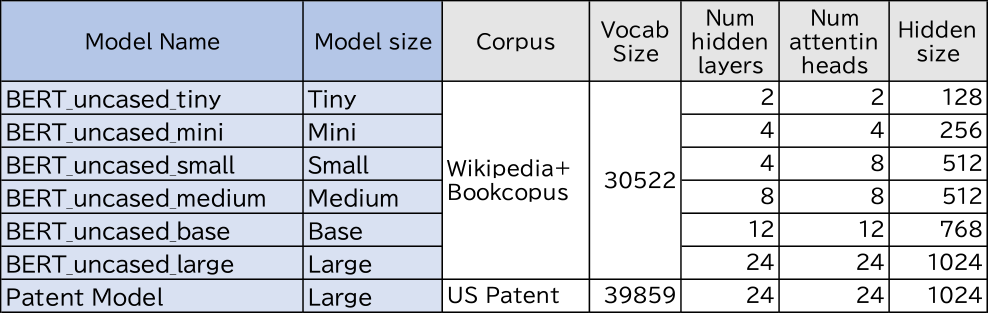
Googleから発表されたBERTのオリジナル事前学習モデルは英語のWikipedeaとBookCorpas [15]を使ってモデルが作成された.その中で代表的なBERT-uncasedというモデルのパラメータを表1に示す.ここでuncasedは入力される文字を大文字と小文字の区別をせず,すべて小文字に置き換えて処理するモデルである.モデルサイズによってTinyからLargeまでのモデルサイズが定義されている.また辞書は各モデル共通で,BPEを使った30522個のトークン辞書でモデルが作成されている.
Table 1 Parameters and performances of typical BERT models.
3.2 英語版特許専用モデル
特許文献を使った事前学習モデルはGoogleから2020年に公開された[5].このモデルは米国の特許公報のみを使って事前学習されており,BERT-uncasedで使われた辞書に対して,特許文献に特有な単語約1万件を追加している[16].このモデルをPatent Modelとよびパラメータを表1の下段に示す.本研究では日本語版の特許専用モデルの作成に先だって,特許専用モデルの性能をオリジナルモデルと比較する検証を行った.特許関連タスクとして特許分類コードを推定するタスクを定義する.
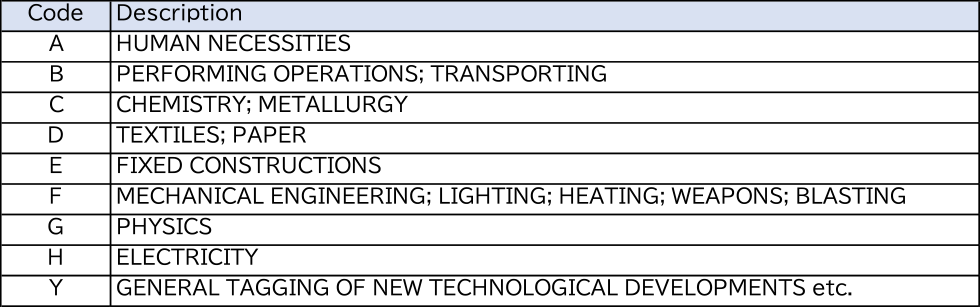
米国に特許出願された発明文書は,発明の要約を示すAbstractと詳細な発明内容を説明するDescriptionと,特許の権利範囲を確定させるClaimから構成されている.通常Claimは複数含まれているが第一請求項の権利範囲が広く,発明の特徴を最も良く表す内容が記載されている.また出願され公開される発明にはCorporative Patent Classification(CPC)というコードが,欧州特許庁と米国特許庁で付与される.表2にCPCコードの例を示す.
Table 2 CPC code Examples.

この分類コードは4桁のアルファベットおよび数字と「/」で区切られた2つの数字で構成され,25万の技術を表現している.この分類コードは階層的な構造を持っており,表2の例ではH01Bがケーブル等に関係する技術で,1/02はケーブルが金属または合金から構成されること,下の階層の1/023はアルミ合金であることを表している.前記4桁の文字の先頭文字はA~HおよびYの9種で,表3に示すような技術範囲を表していて,例のH01Bは電気の分野であることを示している.特許文献には複数のCPCが付与されているが,先頭のCPCはその特許の最も特徴的な技術範囲を表している.今回はモデル間の比較をすることが目的なので,最も簡単なCPC上位1桁を要約から推定するタスク(CPC1_abst)と,第一請求項から推定するタスク(CPC1_fclaim)を行った.
Table 3 Technical descriptions in section level CPC codes.
また,一般文書のタスクとしては良く知られているGeneral Language Understanding Evaluation(GLUE)の中から2つのタスクを実行した[17].MRPC(Microsoft Research Paraphrase Corpus)はオンラインニュースソースから集められた2つの文書が意味的に一致しているかを判定するタスクである.SST-2(The Stanford Sentiment Treebank)は映画レビューが肯定的か否定的かを判定するタスクである.事前の評価として,これら2つのタスクを使って評価する.
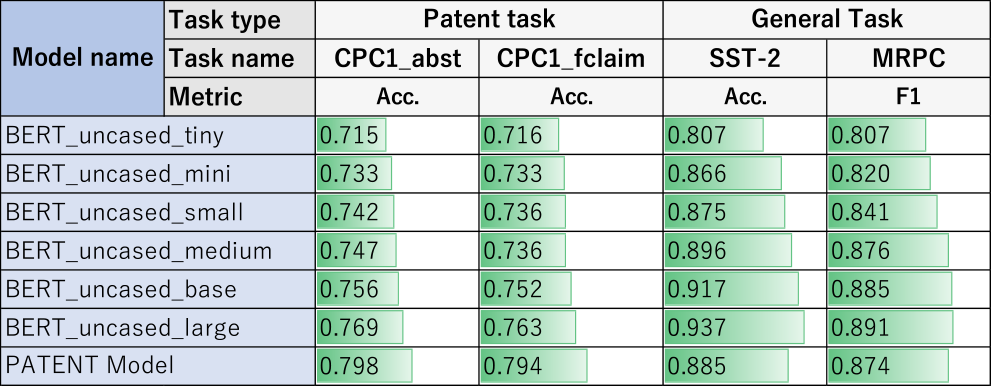
事前検証結果を表4に示す.CPC1_abstおよびCPC1_fclaimともにモデルサイズが大きくなるに従って精度が高くなることが確認された.Bert_uncased_largeと同じモデルサイズのPATENT ModelはCPC1_abstで最も高い0.798の精度を達成している.しかし,一般文書のタスクではモデルサイズが大きくなるに従って性能が向上していることは確認できるが,PATENT ModelはSST-2で0.885の精度,MRPCで0.874のF1値であり,Baseサイズにも満たない性能となることが確認された.以上のことから特許専用モデルは特許に関するタスクには良い性能を発揮するが,一般文書のタスクでは有効でないことが確認できた.特許専用の辞書を持っていることで未知語が減ることと,特許文書に固有の文書の特徴を事前学習モデルが学習していることが要因と推測している.
Table 4 Performance comparison for patent specific model.
なお,BERTは多くの計算機資源を必要とし,モデルサイズがLargeのモデルは付録A.2で示した実験環境では動作しない.そのためWeb上の計算機資源であるGoogle Colaboratory [25]を使い,ランタイムの仕様をハイメモリというメモリ容量を大きく確保する設定を行って実施した.Baseモデルでも一般PCでは一度に処理するデータ量(Batch size)を8に制限しないと動作しないので,すべての個別学習時のBatch sizeを8とした.
3.3 日本語版BERT
BERTの日本語版モデルとしては情報通信研究機構(以後NICT)から日本語Wikipediaをコーパスとした事前学習したモデルが公開されている[18].このモデルの諸元を表5の上部に示す.形態素分解の際にBPEを使用した約3万語の辞書によるモデル(NICT_Base_32KBPE)と,BPEを使用せずにおよそ10万語の辞書を使ったモデル(NICT_Base_100K)が提供されている.
Table 5 Japanese BERT pre-trained models for the experiments.
その他京都大学[19]や東北大学[20]からも,同様な日本語Wikipediaをコーパスとしたモデルが公開されている.いずれもオリジナルモデルのBaseおよびLargeのモデルサイズを基準にして作成されたモデルである.これらを利用して日本語タスクに適用することが可能な環境が整ってきている.しかしながら,日本語の特許文献を使った事前学習モデルは現状発表されていない.英語版で特許専用モデルの優位性は事前検証できたので,日本語版でも特許文献をコーパスとしたモデルが特許文献を対象とした個別タスクに対してより適していることが予想される.
3.4 日本語版特許専用モデルの作成
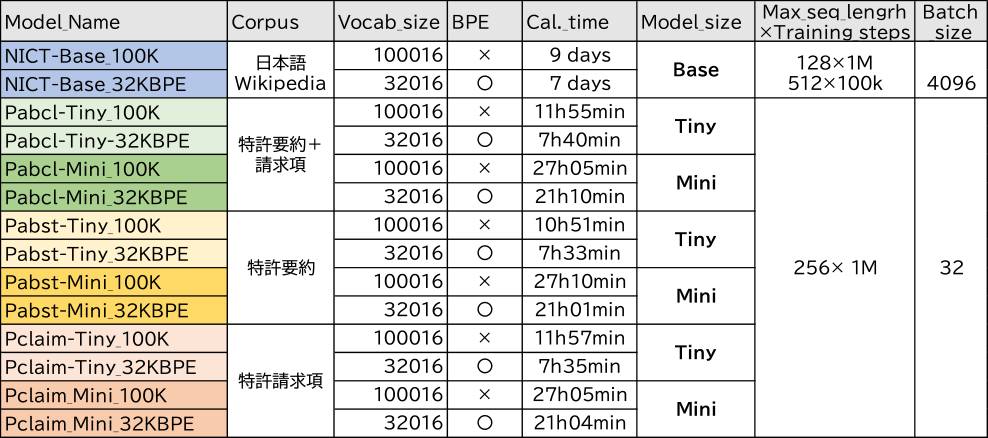
本研究では日本語特許文献をコーパスにしたBERT事前学習モデルを作成し,NICTが作成した一般モデルと比較する.NICTと同等なモデルサイズではモデルのパラメータが1億1千に達するため通常のPCでは資源不足から計算できない.NICTモデルの作成にはグラフィックボード(NVIDIA社製Tesra V100)を32枚搭載したコンピュータで7~9日を要した,とNICTのWebページの中[18]で報告されている.本研究では,通常のグラフィックボードを搭載した一般的なPCでも計算できるよう,TinyとMiniという小さなパラメータサイズのモデルを作成した.Max_seq_lengthは特許の要約がおおよそ収まるサイズとして256を選択し,Batch sizeも大幅に減らして32とした.使用した特許公報も2012年から2017年に公開された約180万件の公開公報を使ったもので,限られたデータで事前学習モデルを作成した.これらのモデルのパラメータ値を表5の下部に示す.
コーパスとしては要約,請求項,および両方を使ったモデルを作成した.また特許公報で使用頻度の高いトークンを登録した専用辞書を作成し,BPEを使うモデルと使わないモデルを作成した.ただし,登録単語数はNICTのモデルと同じで,BPE有りで100016トークン,BPE無しで32016トークンとした.モデルの具体的な事前学習方法を付録A.1に示す.また事前学習には付録A.2で示したPCを使いTinyで7~12時間,Miniで21~27時間を要した.
特許専用の事前学習モデルを作れば,同じモデルサイズならば性能が高くなることが3.2節の英語版モデルで確認されている.従って,企業が所有している一般的なPCを使って企業ごとに持っている過去データで個別学習を行いランキングが実行できるように,小さなモデルで検証を行った.
4. 特許ランキング手法
特許に関係するタスクとしては,国立情報学研究所(NII)が主催するNTCIR(NII Testbeds and Community for Information access Research)から特許分類タスク[21]が提供されているが,本研究では,特許調査の実務に即した独自の特許ランキングタスクを設定した.
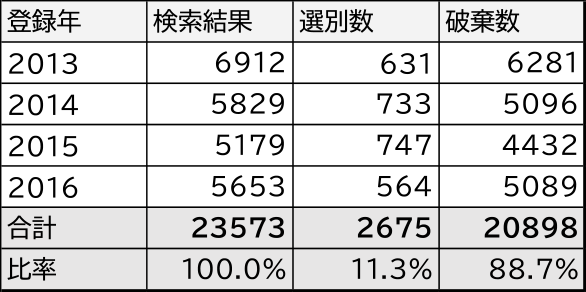
本研究に協力をいただいた企業では,SDI調査として毎月新たに登録される特許公報から検索式に基づいて特許を抽出し,それを専門の調査会社が振り分ける作業をしていた.この中で2013年から2016年までの4年間に行った調査データを使用させていただいた.表6にデータの概要を示す.年ごとに比率の変動はあるが,全体で23573件の検索結果から2675件,比率では11.3%の特許を人手で仕分けしている.この作業が機械学習で代替えできるか否かを確認する.
Table 6 Patent publication ranking task data.
4.1 事前学習モデルとランキング性能
事前学習モデルごとの性能を比較するため,特許ランキングタスクのデータをすべて使うランキング性能検証タスクを表7のように定義する.ランダムに並べた公報を9対1の割合で分割してそれぞれ訓練データと試験データとする.また個別学習および予測に特許公報の要約文を使うケースと,請求項を使うケースの2種のデータを作成する.ただしすべての請求項を使用するとトークン数が大きくなり過ぎるので,第一請求項のみを使用する.事前学習モデルとしては表5に示した14種の日本語事前学習モデルを使い,要約または請求項でランキングを行う.
Table 7 Ranking performance evaluation task data.

実験は,訓練データを使って事前訓練済みのBERTモデルの個別学習を行い,訓練後のモデルを使って試験データに対して予測を行う.このとき分類器から得られる評価値のPositiveとNegativeの差でランキングを行う.個別学習は1回から5回のエポック数で繰り返し訓練を行い,エポックごとに試験データの予測を行う.実験結果には5回のエポック数の中で試験データの予測性能が最もよいものを結果として示す.評価指標としてREI,AUC,NDCGの値を示すが,評価指標の詳細については5章で説明する.
4.2 訓練データ量の検証
4.1節のランキング評価は,4年間のデータを訓練データと試験データとに分割してランキングを行っているが,実務上は過去何年かの実績データをもとに新たに公開された特許公報をランキングすることが行われる.そこで前年までに得られた仕分け結果を訓練データとし,当年に公開された公報をランキングする年度評価タスクとして再定義する.この評価タスクのデータ構成を表8に示す.年度評価タスクの事前学習モデルにはNICT-BaseのBPE無し/有りの2種と,特許の要約と請求項を使って事前訓練を行ったPabcl-MiniのBPE無し/有りの2種を使う.そして要約を使って個別学習と予測を行う評価実験を実施する.
Table 8 Yearly evaluation task data.

5. ランキング性能の評価
文書集合に対して選択/破棄を予測する問題は2値分類問題として扱うことができる.しかし,今回定義したタスクデータで選択されたものを正例,破棄されたものを負例とすると,正例と負例の割合はおよそ1対9と不均衡なので,精度で評価しても分かりやすい指標が得られない.本研究では分類タスクで得られた評価値を元にランキングを行い,3つの指標で結果を示す.第1の指標はROC(Receiver Operation Characteristic)カーブの下の領域の大きさで評価するAUC(Area Under Curve)[22],第2の指標はランキング評価で良く使われるDiscounted Cumulative Gainを規格化したNDCG(Normalized Discounted Cumulative Gain))[23]を使用する.そして第3の指標として仕分け作業効率の改善度を表すためのランキング評価指標(Ranking Evaluation Index:REI)を独自に導入する.これはROCと同様な手法で計算される指標であるが,REIは無作為なランキングがされていれば0,完璧なランキングができれば1となる指標であり,平均的な改善率を示す指標として理解しやすい.従ってREIを使って説明し他2つの指標も結果に併記した.各ランキング指標の特質を以下に示す.
5.1 AUC
2値分類の識別能力を評価する判別の特性は受信者動作特性(ROC)で表すことができる[22].図3(a)は2値判定の閾値を変えたときの偽陽性数と真陽性数をグラフ化したものでROC曲線と呼ぶ.グラフがより上方向を通過すると陽性と陰性のデータをきれいに切り分けられたことになる.従ってグラフの下の領域の面積(AUC)を理想的な場合を基準に規格化することでランキング評価指標として使うことができる.
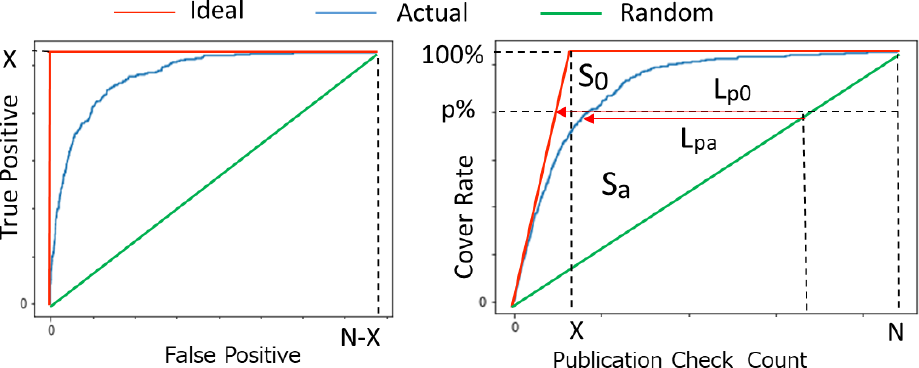
Fig. 3 ROC/REI curve.
5.2 NDCG
Webサイト検索のランキング評価指標として広く用いられるのはNDCGである.ランキングされた適合度を順位に応じた割引率で累積した値をDCG(Discounted Cumulative Gain)としてランキング評価に使う手法でK.Javelinらによって提案された[23].DCGは次の式で表される.\[DCG( \boldsymbol{G} ) = {G_1} + \;\sum\nolimits_{i = 2}^k {\frac{{{G_i}}}{{lo{g_2}i}}} \]
ここでGはゲインベクトルでGiはi番目のランキングに対する適合度を表している.DCGはk番目までの要素まで累積計算しており,適合度の高い要素が上位に出現するほど大きくなる指標である.理想的なランキングGidealに対して推定したランキングがGpredとなった場合,各ゲインベクトルのDCGの比率をランキング評価値NDCGとする.\[NDCG = \frac{{DCG( {{\boldsymbol{G}_{pred}}} )}}{{DCG( {{\boldsymbol{G}_{ideal}}})}}\]
この指標は1から0の値を取り,適合度の高いものを上位にランキングするほど1に近い値となる.
5.3 REI
ランキングによる作業効率の改善という観点でランキング性能指標(REI)という評価尺度を導入する.図3(b)は文献をランキングした順序でチェックした場合に,何件目のチェックで選択すべき文献を何パーセントカバーしたかを示すグラフで,REI曲線と呼ぶ.文献総数をN,選択すべき文献数をXとする.全く無作為に文献がランキングされたならば,緑色のグラフのようにチェックの進捗に従ってカバー率が比例して上がっていく.一方,理想的なランキングができた場合には,目的の文献は最上位にランクされるので,赤色のグラフのようにX件をチェックした時点ですべてカバー率は100%となる.実際ランキングの推定ではカバー率曲線は青い曲線のように2つの線の間を通過する.
たとえば,選択すべき文献のp%をカバーしたいと考えた場合,対応する横軸に引いたラインで緑色グラフとの交点が無作為に文献を当たったときの作業量,赤色グラフとの交点が理想的なランキングの場合の作業量,青色グラフとの交点が実際の作業量に対応する.図中のLpa/Lp0は理想的なランキングと比較して作業改善できた指標となる.この指標は選択すべき文献のカバー率によって変わるが,すべてのカバー率に渡ってこの比率を積算することで,平均的な作業改善を表現できる.そこで緑色グラフと赤色グラフで囲まれる面積S0,および緑色グラフと青色グラフで囲まれる面積Saから,次の式でREIを定義する.\[REI = \frac{{{S_a}}}{{{S_0}}}\]
この指標値は−1から1の値をとり,1に近いほど理想的なランキングであり,0に近いほど無作為なランキングになり,理想と真逆のランキングをすると−1となる.
5.4 ランキング指標の比較
ROC曲線はチェックした文献の中に含まれる選択すべき文献数を縦軸に,外れた文献数を横軸にプロットするので図3(a)で示す曲線となる.この曲線から下の面積を計算する指標AUCは理想的なランキングの場合1,無作為なランキングの場合0.5,真逆なランキングになるとに0となる.REIとAUCは考え方が異なるが次式で置き換えられる.\[AUC = 0.5 + REI/2\]
ランキング評価には,無作為なランキングの指標値が0となるREIのほうが,理想的なランキングとの近さを直感的に理解しやすいと考える.
前述のNDCGとREIを具体的な事例で比較したものを表9に示す.10個の文献の中に3つの適合度の高い文献があるとすると,理想的なランキングはGidealとなる.これに対して適合度の高いものを最下位に推定したGpred1と適合度の低いものを最上位に推定したGpred2を仮定する.これらランキングの指標値を表の右側に示す.
Table 9 Comparison of ranking indicators.

NDCGはランキング順位の対数を分母とする重みづけがされるので,適合度の高い文献を下位に推定したGpred1よりも,適合度の低い文献を上位に推定したGpred2のNDCGが悪化する傾向にある.一方,REIはGpred2よりもGpred1のほうが悪くなる.これは適合度の高い文献を下位にしたことが同じ比率で指標に影響を与えるためである.従って,NDCGは上位の精度を重視した指標で,REIは再現率を重視した指標と言える.また,NDCGは全く無作為のランキングに対して1より小さいどのような値を取るかは条件によって異なるので,ランキング良否判断のベースラインが分かりにくい.
以上のことから,Web検索のランキングなどでは上位に適合率の高いものを多く含むことを優先したNDCGが適しているが,特許侵害調査などで関連技術を含む文献を仕分けする場合は,下位のランキングも上位と同等に扱うREIが適していると考えられる.本研究ではREIを中心にして説明を行う.
6. 実験結果
6.1 事前学習モデルとランキング性能の結果
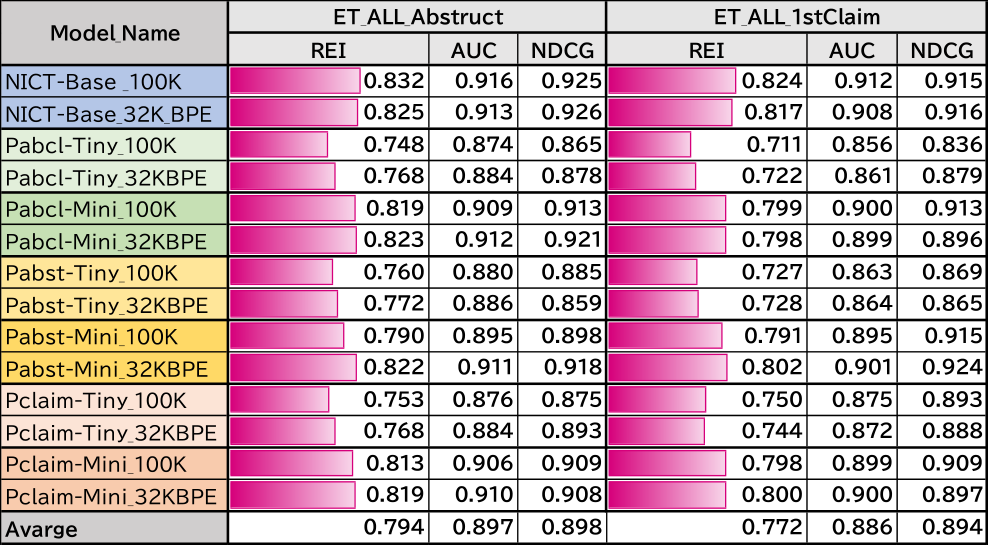
ランキング性能検証タスクの実験結果を表10に示す.NICT-BaseモデルではBPE無しおよびBPE有りの事前モデルで要約を使って個別学習した場合に,REIでそれぞれ0.832と0.825の値が得られた.一方で,特許で事前学習したモデルでは,パラメータ数の大きいMiniのほうがTinyに比べて高い性能が得られることが確認できた.ランキングに特許公報の要約を使った場合の平均が0.794に対して,第一請求項の平均は0.772なので,要約は0.022程度高めに出る傾向となった.特許請求項は,使用する文言が上位概念化された特別な単語を使われる傾向にある.また過去に出現した文言を参照するときには「前記○」,「該○」のような表記をすることや,すべてを一文で表すなど一般文書と比べ特有の表現をしていることから,要約に比べて悪い結果になった可能性がある.
Table 10 Results of ranking performance evaluation tasks.
また特許公報のトークン数の影響も考えられる.図4に公報データに含まれるトークン数のヒストグラムを示す.要約は文書全体を300文字以内で作成することを求められるので,ほとんど最大シーケンス長の256以内に収まっており,これを越えるものは全体の1.5%である.一方請求項にはこのような制限がなく,第一請求項に関しては36%が最大シーケンス長を越えていて,これが性能に影響した可能性がある.しかし,要約に比べて極端に悪い結果ではなく,クレームを使った分類も可能であることを確認することができた.
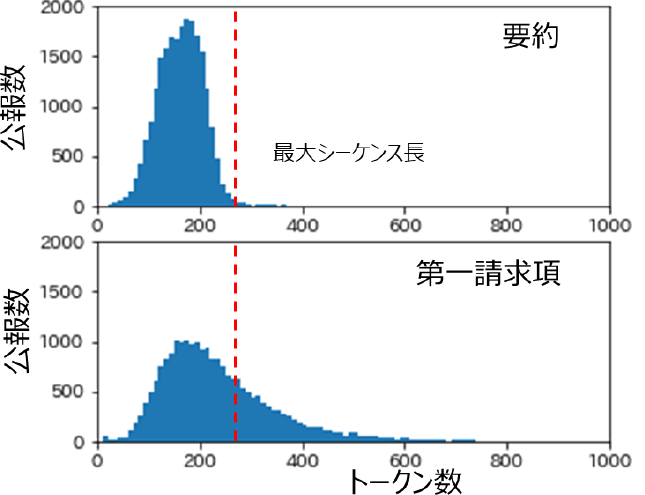
Fig. 4 Token number in patent publication data.
事前学習モデルに注目すると,請求項と要約を使ったモデル(Pabcl-**)が最も高い性能を示している.要約だけでは文書の量が少ないが,請求項は平均でも約13.9個の請求項をもっているので,これらを個別の文書として事前学習に使うことにより,要約だけの場合より多くの文書で訓練できていることが理由と考えられる.特許を使ったモデルの中では,Pabcl-Mini_32KBPEが最も高い0.823の値を出しており,NICT-Base_32KBPEに迫る値となっている.表1で示したように,モデルサイズを上げれば高い性能が得られることは分かっているので,特許で作ったbaseサイズのモデルが作成できれば,NICTで得られた成績よりも高い性能を達成することが期待できる.
6.2 訓練データ量の検証結果
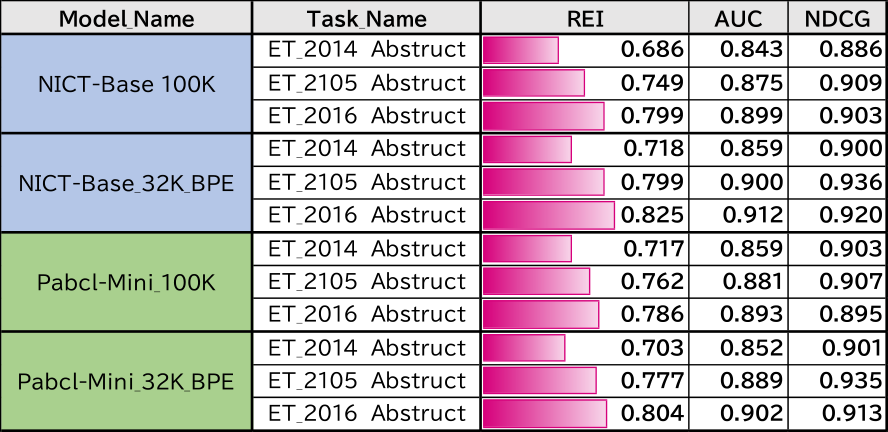
年度評価タスクの実験結果を表11に示す.各モデルとも過去1年のデータでは0.7程度の結果で,過去3年程度(約16千件)のデータがあれば6.1節で示した全データによる評価結果値近づくことが分かった.
Table 11 Results of yearly evaluation tasks.
7. 考察
7.1 ランキング性能と改善効果
特許文献から作成した事前モデルにおいてREIで最大0.823の成績が得られたが,どのくらい正解文献が上位にランクされたか直感的に理解しにくい.図5にランキング順序における正解の出現率をグラフとして表した.試験データ数2357件の中から263件の選択れたドキュメントを上位にランキングするタスクなので,理想的なランキングができれば赤線のようにランキング順位263位までは正解出現率は1.0でその後正解は0になる.無作為にランキングされた場合は緑のように一定して0.11程度の値を取る.実際のランキング結果を青線で,そのときのREI曲線を橙色で示す.正解数の2倍の526位までに82%,3倍の789位までに91%の正解が含まれており.関心のある文献をより先に確認できる効果が得られることが視覚的に理解できる.
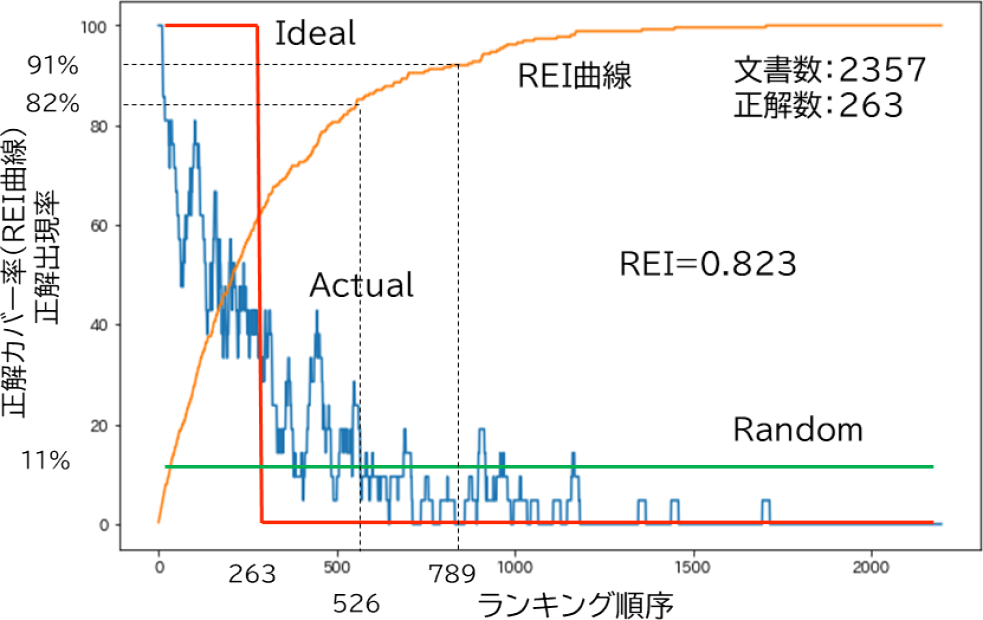
Fig. 5 Correct answer rate in ranking order.
ランキングによる作業効率改善効果について考察する.SDI調査では毎回同じ条件で検索するので,仕分けで関係あると判定される公報数はおよそ予想できる.この実験の例では11%を関係ありとしていたので,ランキング上位から3倍の33%を仕分けすれば関係ありと判定される91%はカバーできる.このカバー率を許容すれば残り67%は仕分け作業から外すことが可能となる.データ提供に協力いただいた会社では毎月500件程度の仕分け作業を行っていた.検索結果の特許公報から大まかな製品との関係性を見る作業でも1件1分程度はかかるので,500件の仕分け作業の67%が削減できれば,500分×67%≒5時間半程度の工数削減が可能となる.
侵害回避調査は漏れを無くした調査が求められるので,カバーできなかった9%が気になるかもしれない.しかし,実務的には限られた予算と時間で行う必要があり,仕分け作業が時間的に難しければ,クエリ設計に条件を加えて検索の段階で件数を絞らざるを得ない.本実験では約2万件から2千件余りを仕分けしたデータを使っているが,仕分けしたデータがすべて特許侵害しているわけではない.実際に侵害回避のために設計変更をしたり,見つかった特許の無効化調査を行ったりするケースは,2千件の中で数件である.従って仕分け段階であらかじめ製品との関係でランキングされていれば,上位の案件に調査時間を割き,時間の許す限り選別作業を行うという選択や,関係性の低い特許公報ばかりが出現すると感じた時点で仕分け作業を終了することも現実的な選択となり,図5において2千件余りの検索結果をすべて人手で仕分けする作業からは解放される.
7.2 未知語の削減による効果
小さなモデルでも,大規模モデルに近い性能を確認できた.表12に各モデルでタスクのデータを扱ったときの未知語の出現確率を示す.NICT-Baseのような一般文書から作成した辞書を使ったモデルでは未知語が0.25~1.78%発生してしまう.一方特許文献を元に単語辞書を作成することで未知語減らすことができている.BPEを使わない場合でも0.39%以下,BPEを使うことで0.04%以下に落とすことができている.この未知語の削減が小さなモデルでも大規模モデルに迫る性能を上げた理由のひとつと考えられる.
Table 12 Unknown word appearance probability.
7.3 クエリ検索しないデータに対する応用
6章の検証では,検索式を使って抽出された公報集合とその仕分け結果をもとにモデルの個別学習を行った.この個別学習されたモデルが,クエリによる検索を行わない特許公報集合の仕分けに役立つかを検証した.
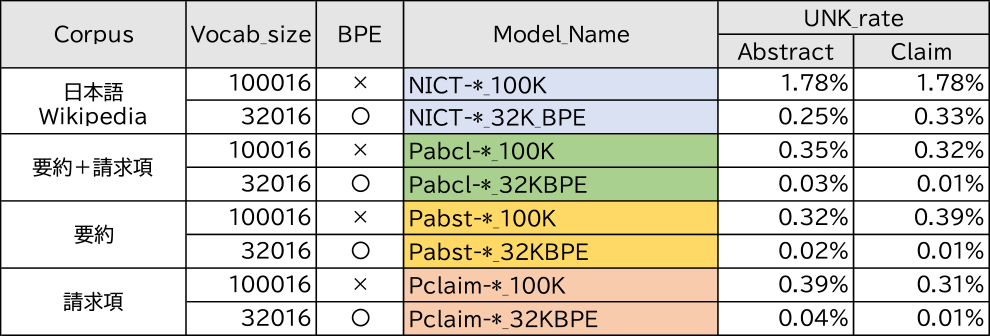
2021年11月の2週間で新たに特許登録され公開された5990件に対して,3.4節の特許文献から作成したPabcl-mini_32KBPEを要約で個別学習したモデルを使ってランキングを実行した.そのときの分類器の出力の差(Positive–Negative)をランキング順位で1位から1000位までプロットしたものを図6に示す.事前のキーワード検索を掛けていないのでほとんどが無関係の特許公報と想定されるが,Positive–Negativeの値も一部の公報についてのみ正の値を出力している.この上位100位までの公報について,自社製品との関連性で3段階評価(1:関連有り,0:中立,−1:関連なし)を人手で行った結果を図7に示す.上位100件の中でも上位側に関連性の高いものが集まっている様子が確認できる.このことから,事前に自社製品との関係性を学習したモデルを作成しておくと,検索式なしで関係性の高い文献を取り出すことができることも確認できた.最初に検索式で選別していない公報集合に対しても製品との関連性でランキングできるので,今まで検索式で切り捨てていた中から新たに注目すべき公報を見つけられる可能性も考えられる.
Fig. 6 Recent publication ranking and classifier output.
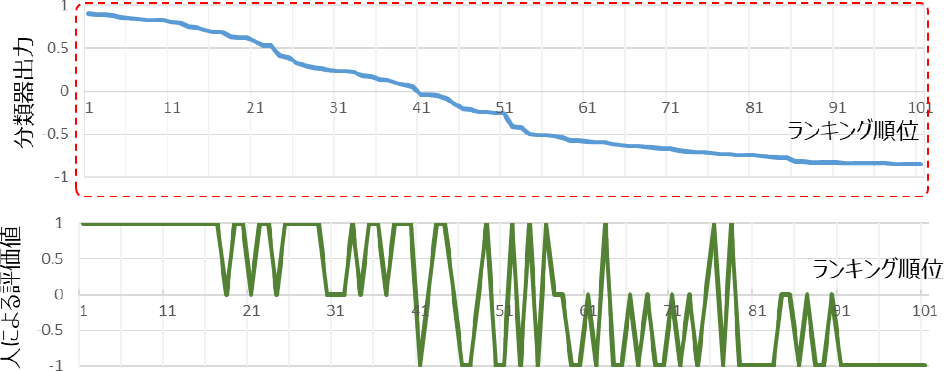
Fig. 7 Evaluation value by person for the top 100.
8. 結論と今後の課題
本研究により,SDI調査結果データを機械学習の訓練データとして使い,侵害回避調査のために検索した公報集合を調査対象の製品との関連性でランキングを行いうことで,人による仕分けのサポートができることを確認した.本稿の事例では67%の作業改善が可能となることが分かった.これは特許関連の業務に関わらず,科学技術論文の検索など別の分野でも応用できると考える.検索クエリで表現しきれない人の志向や関心事に関する仕分け実績を使って,より自分の望む情報に早くたどり着くことが期待できる.SDI調査の結果データを適切に残して,今後の業務改善に役立てたい.
また特許文献を扱うタスクでは,小さなサイズのモデルでも特許文献による事前学習モデルで作成することで,大規模な汎用モデルに迫る性能を示すことが確認できた.これにより,一般の企業の中で仕分け作業の機械化を行うことが可能となる.またパラメータサイズが大きいほど高い性能が得られることは知られている.今後大規模な特許事前学習モデルが作成されれば,ランキング性能の向上が見込まれる.また特許庁では,2016年から「人工知能技術を活用した特許行政事務の高度化・効率化実証的研究事業」として,特許出願から審査,登録に関わる業務を対象に,人工知能技術の活用について調査を実施しており[24],特許専用モデルはこのような業務改善にも資することが期待できる.
謝辞 本研究のために特許調査に関するデータを提供いただいたFCNT株式会社に感謝する.
参考文献
- [1] Amplified:自然で直感的な特許調査,〈https://www.amplified.ai/ja/how-it-works〉.
- [2] パテント・インテグレーション:機能説明,〈https://patent-i.com/ja/wiki/〉.
- [3] Devlin J., Chang M., Lee K. and Toutanova K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Proceedings of NAACL-HLT 2019, pp.4171–4186, ACL (2019).
- [4] Google: google-research/bert, 〈https://github.com/google-research/bert〉.
- [5] Google: patents-public-data, 〈https://github.com/google/patents-public-data/blob/master/models/BERT〉 for Patents.md.
- [6] Sanh V., Debut L., Chaumond J. and Wolf T.: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, ArXiv abs/1910.01108 (2019).
- [7] 追川康之:深層学習を利用した自然言語処理の発展と特許調査への応用の現状, Patent, Vol,75, No.2, pp.3–16 (2022).
- [8] 古川修平,関 洋平,青野雅樹:特許の無効資料調査のための類似特許検索とリランキング,FIT2008第7回情報科学技術フォーラム,D-027 (2008).
- [9] Tian X. and Wang J.: Retrieval of Scientific Documents Based on HFS and BERT, IEEE Access 9, pp.8708–8717 (2021).
- [10] Panasonic:特許調査支援サービスPatentSQUARE, 〈https://www.panasonic.com/jp/business/its/patentsquare.html#ai-search-function〉.
- [11] Ilya S., Vinyals O. and Le Q. V.: Sequence to Sequence Learning with Neural Networks, NIPS (2014).
- [12] Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N., Kaiser Ł. and Polosukhin I.: Attention Is All You Need, 31st Conference on Neural Information Processing Systems NIPS (2017).
- [13] Alammar J.: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) 〈https://jalammar.github.io/illustrated-bert/〉.
- [14] Sennrich R., Haddow B. and Birch A.: Neural Machine Translation of Rare Words with Subword Units, Proc. of the 54th Annual Meeting of the ACL (2016).
- [15] Zhu Y., Kiros R., Zemel R., Salakhutdinov R., Urtasun R., Torralba A. and Fidler S.: Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books, ICCV (2015).
- [16] Google: How AI, and specifically BERT, helps the patent industry, 〈https://cloud.google.com/blog/products/ai-machine-learning/how-ai-improves-patent-analysis〉.
- [17] Wang A., Singh A., Michael J., Hill F., Levy O. and Bowman S. R.: GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding, Conference paper at ICLR (2019).
- [18] 情報通信研究機構:NICT BERT日本語Pre-trainedモデル,〈https://alaginrc.nict.go.jp/nict-bert/index.html〉.
- [19] 京都大学:BERT日本語Pretrainedモデル,〈https://nlp.ist.i.kyoto-u.ac.jp/?ku_bert_japanese〉.
- [20] 東北大学:Pretrained Japanese BERT models released /Tohoku NLP Lab, 〈https://www.nlp.ecei.tohoku.ac.jp/news-release/3284/〉.
- [21] Fujii A., Iwayama M. and Kando N.: Overview of the Patent Retrieval Task at the NTCIR-6 Workshop, Proceedings of NTCIR-6 Workshop (2007).
- [22] Streiner D. L. and Cairney J.: What's under the ROC? An introduction to receiver operating characteristics curves, The Canadian Journal of Psychiatry, Vol.52, No.2 (2007).
- [23] Jarvelin K. and Kekalainen J.: Cumulated gain-based evaluation of IR techniques, ACM Transactions on Information Systems, Vol.20, No.4, (2002).
- [24] 富永泰規:特許庁業務における人工知能技術の活用, Patent, Vol.75, No.2, pp.43–49 (2022).
- [25] Google: Welcome To Colaboratory – Google Research, 〈https://colab.research.google.com/〉.
- [26] MeCab: Yet Another Part-of-Speech and Morphological Analyzer, 〈https://taku910.github.io/mecab/〉.
- [27] Rico Sennrich: rsennrich/subword, 〈https://github.com/rsennrich/subword-nmt〉.
付録
付録A.1 特許専用日本語BERTモデルの事前学習方法
特許専用日本語BERTモデルの事前学習時の設計条件を示す.githubのgoogle-research/bert [4]で公開されているプログラムのtokenization.pyにMecab [26]による日本語形態素解析ができるよう修正を加えた.コーパスは2012年から2017年に公開された約180万件の公開公報の要約と請求項を使い,前処理として「【要約】【課題】制御システムにおいて・・・」のような【 】書きの文字は削除し,半角文字は数字も含めて全角文字に変換した後に形態素分解を行った.辞書作成はgithubのrsennrich/subword-nmt [27]で公開されているsubword_nmt.pyを使った.形態素解析されたトークンで出現頻度の上位10万件(BPE無し)と3万2千件(BPEあり)を選別しNICTモデルの辞書と同じ[UNUSED*]を含む特殊トークン16個を加えて登録した.事前学習はpretrain.pyを次のパラメータで実行した.
--train_batch_size=32
--max_seq_length=256
--max_predictions_per_seq=20
--num_train_steps=1000000
--num_warmup_steps=10
--learning_rate=2e-5
付録A.2 PCの概略仕様
実験に使用したPCの概略仕様を下記に示す.
OS:Windows 10 Pro(64bit)
CPU:インテル® CoreTM i9-9900Kプロセッサー
GPU:NVIDIA® GeForce RTXTM 2080Ti 11GByte
Memory:32Gbyte
Storage:512GbyteSSD+2TbyteHDD

秋山 賢二(正会員)ken2akiyama@gmail.com
1984年 東北大学大学院工学研究科博士前期課程修了.同年東芝入社.2011年富士通転籍.2018年FCNT株式会社(旧富士通コネクテッドテクノロジーズ)転籍.現在知財部門に所属.東京農工大学 生物システム応用科学府博士後期課程在籍.

斎藤 隆文(正会員)
1982年東京大学工学部計数工学科卒業.1990年東京大学大学院工学系研究科博士課程修了.工学博士.1987年NTT研究所勤務.1997年東京農工大学工学部助教授.現在,東京農工大学大学院工学研究院教授.コンピュータグラフィックス,可視化,形状処理などの研究に従事.本学会フェロー,画像電子学会フェロー.
採録日 2022年11月10日