データアクセス制御を持つ自動テスト環境の構築
Building Automated Testing Environment with Data Access Control Function
1. はじめに
近年,デジタル技術を活用して従来の活動を変革するデジタルトランフォーメーション(DX)がスポーツを含むあらゆる分野で進んでいる[1], [2].また,共創活動において顧客に価値を迅速に提供するために,顧客から得られるデータを分析および活用し,課題抽出および対策検討を行い,実装の優先順位を決定するアジャイル開発が注目されている[3]-[5].そのひとつとして,我々は,国際体操連盟と共同で,体操競技のおける正確かつ公平な採点の実現を目指して,体操採点支援システム[6]を開発している.
本体操採点支援システムは,複数のモジュール(モジュールセット)から構成されており,各モジュール開発を担当するチームが,上記の膨大なデータを使用して,課題抽出および対策検討を行い,設計および実装の優先度を決定し,実行に移すサイクルを繰り返している.このようなアジャイル開発では,各モジュールは頻繁にアップデートされ,システム全体の速度評価および精度評価が毎回実施される.
本システムのシステム構成は,対応種目の増加[7]-[9]に伴い,大規模化および複雑化が進み,開発スケジュールに遅れが発生する原因として,システム全体のテストを扱える人員が限られてしまう属人化が問題となった.さらに,データ取得は国内外複数の大会で行われ,複数の連続した技から構成される演技データの数は膨大なものになるため,速度測定および精度評価を実施する人員の作業負担が増加し,ヒューマンエラーによる失敗および再実行のための原因調査といった時間的な無駄が顕在化した.
そのうえ,ファイルサーバ上に格納される演技データは個人を特定できる情報に該当し,テストで演技データから生成される評価用データも含めて,高い機密レベルのデータ管理が求められる[10], [11].情報漏洩防止の観点より,分析および評価といった特定の業務に関わる人員にのみアクセスを限定しなければならない.
表1に高い機密レベルで扱われる情報を示す.氏名やパスワードだけでなく,画像や動画なども個人を特定できる情報として高い機密レベルが求められる.
Table 1 Information treated with high level of confidentiality.
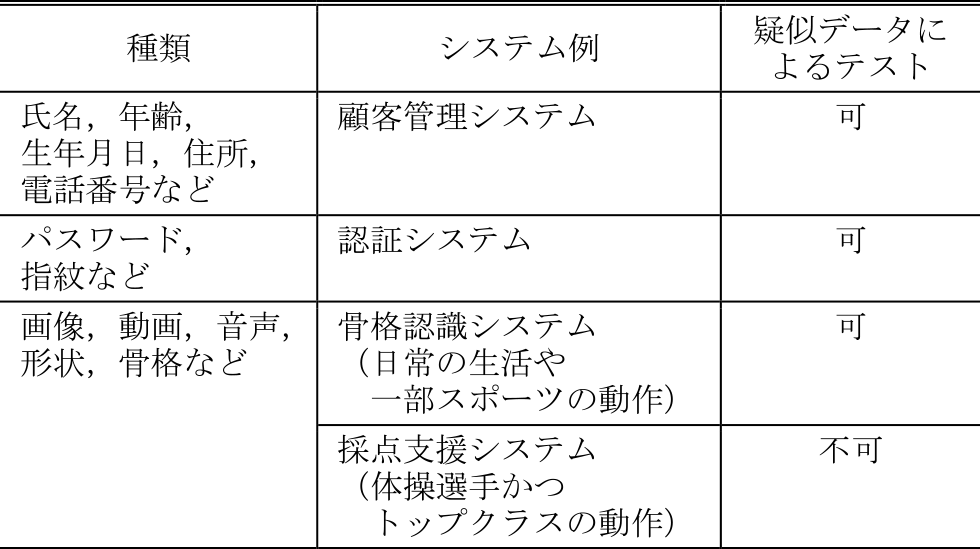
表1に示す顧客管理システムや認証システムでは,本番データを疑似データに差し替え,テストを行ったあと,本番環境にデプロイする際に本番データに置き換えることができる.また,表1の個人を特定できる情報を扱う場合に注目すると,従来骨格認識システムとしてKinect [12]を用いた骨格認識システムが挙げられる.Kinectは近距離(0.5 mから5 m程度)測定に対応しており,主に日常生活の動作や一部のスポーツを対象としていると考えられ,Web公開データや,モーションキャプチャとCG技術により作成したデータを利用することで,疑似データを用意できる.以上のようなシステムでは,疑似データによるテストと本番データのアクセス制御を分離して考えることができる.
一方,本体操採点支援システムは,個人を特定できる情報を入力および出力として扱う点は同じである.しかしながら,体操選手かつトップクラスの動作を対象としているため,一般人が同じ動作を再現できず,入力として擬似データを用意できない.そのため,実際の演技データを本システムの入力として用いることになる.また,本システムの出力は骨格情報であるため,新しい入力データに対して精度評価および分析を行い,出力データに対して高い認識精度を継続的に達成しなければならない.よって,本システムでは,個人を特定できる情報を含むデータを直接入出力として扱い,アクセス制御できるテスト環境が必要となる.
さらに,急速に拡大するDXや共創活動において,開発チームと運用チームが互いに協調[13], [14]し,顧客に高い価値を提供していくにあたり,顧客の個人情報といった機密レベルの高いデータを運用段階だけでなく開発段階でも利用することが一般的になると考えられる.そのため,データの機密レベルに応じて厳密な管理が必要となり,データアクセス制御できるテスト環境を求める声が社内外で高まる[15], [16]と予想される.そこで,本稿では,本体操採点支援システムの開発において得られた知見を整理し,他システムでも適用できるプラクティスとして報告する.
以降,2章で関連技術,3章で課題と解決方針,4章で提案する自動テスト環境,5章で自動テスト環境の構築方法,6章で実践結果と考察を述べ,7章でまとめる.
2. 関連技術
本章では,1章で述べた背景を踏まえ,本自動テスト環境の関連技術について述べる.
2.1 継続的インテグレーション
属人化や実行失敗のリスクを解決するために,テスト自動化として,継続的インテグレーション(CI:Continuous Integration)[17], [18]が普及しており,一般的にはモジュールのビルドテスト,機能テスト,単体テストなど比較的小規模なテストを,バージョン管理システムのリポジトリが更新されるたびに,実行することで,モジュールの不具合を早期に発見し,開発にかかる時間とコストを削減しつつ,品質の高いシステムを開発できる.
最近では,システム全体のテストをCIで行う事例[19], [20]が報告されているものの,テスト対象システムの構成に特化したものとなっている.とくに,入出力データの機密レベルに応じたアクセス制御については触れられていない.1章で述べた機密レベルの高いデータを入出力として扱うシステムを対象とした場合,自動テストにおいてCIツールにアクセス制御の機能を組み合わせる必要がある.
また,CIツールは数多く公開されており,CIツールによって同じ機能でも用語が異なることがある.本稿で対象とするCIツールの定義は以下のとおりである.
- (1) CI環境はジョブを管理するCIサーバとジョブを実行するCIランナーの2つから構成される.
- (2) CIランナーはあらかじめ実行マシンに導入され,役割を示すタグが設定される.
- (3) ユーザはジョブをビルドステージやテストステージなどで構成されるCIパイプラインとして定義する.
- (4) ユーザはジョブにタグを指定してCIサーバに発行する.
- (5) CIサーバはタグに従って,空きCIランナーにジョブを割り当てる.
- (6) CIランナーは自身のマシン上でジョブを実行する.
2.2 データアクセス制御
システム全体のテストでは,各モジュールのデバッグ情報やログを含む結果データが大量に出力される.データにアクセスするプロジェクト人員が多い場合,結果データをファイルサーバに格納し,ファイルサーバ上に格納されたデータ,つまり,ファイルおよびフォルダに対してアクセス制御リスト(ACL:Access Control List)[21]を用いてアクセス制御することが適している.ファイルサーバを構築するために,公式ドキュメント[22]-[24]や文献[25]-[27]が存在する.これらの情報に記載されている単純な例として,secureフォルダとpublicフォルダを用意し,高い機密レベルのデータをsecureフォルダ,それ以外のデータをpublicフォルダに格納し,それぞれのフォルダにアクセスできるユーザおよびグループを設定し,読み書き実行の権限を設定することが挙げられる.
しかしながら,プロジェクトごとに開発や人員の規模が異なるため,プロジェクトに合わせたアクセス権の設定が必要となる.たとえば,同じプロジェクト内でも,契約上の都合により,高い機密レベルにアクセスできる人員とできない人員が混在するプロジェクトでは,アクセスできない人員の作業において,自動テストになにかしらの問題が発生し,機密レベルの高いデータの配置が原因である場合,原因調査のために,アクセスできる人員とアクセスできない人員のやりとりが頻繁に発生し,各人員の本来の業務が遅れ,全体のスケジュールに影響するといったことが挙げられる.
3. 課題と解決方針
本稿の目的は,CIツールとファイルサーバを組み合わせ,自動テスト環境を構築し,開発効率の改善とデータ管理の両立を実現することである.1章および2章で述べた背景および関連技術を踏まえ,本稿の課題は以下の2点である.
課題1
システム全体のテストにかかる属人化および実行失敗のリスクを解消する自動テスト環境をどう実現するか?
課題2
提案する自動テスト環境において高い機密レベルを維持するためにデータアクセス制御をどう実現するか?
解決方針
我々のプロジェクトでは,体操採点支援システム向けに自動テスト環境を構築するにあたり,一旦,本システムに関わる部分を取り除き,一般的なシステムとして1つの要素とみなし,設定,実行,入力および出力について検討し,課題1および課題2に対して,以下の機能を有する自動テスト環境を構築することにした.
- (1) 設定および実行について,CIに加えて,1設定ファイル化し,1コマンド化することで,設定の再利用が可能とし,システムの設定および実行に精通していない人員でも,許可されていれば,容易にテストを実行できる.また,各人員が必要とするデータ出力を切り替えるために,容易にシステムの実行モードを操作できる.
- (2) 入力および出力について,データのファイルおよびフォルダに対して,ACLを利用して,機密レベルに応じて各人員の読み書きアクセスを適切に設定および制御でき,各人員は特別なルールを意識することなく,データにアクセスできる.とくに,各人員のアクセス権にかかわらず,最低限,データの配置を確認できる.
- (3) システムの実行にかかる機器の間で入出力データをシームレスに移動およびコピーできる.また,出力データに対して,異常検出,結果比較,および,結果集計など後処理機能を実装できる.さらに,データ管理者は入出力データに対して,従来と同様の操作で,容易かつ適切に管理および削除ができる.
4. 自動テスト環境の提案
本章では,3章で述べた解決方針を踏まえ,体操採点支援システムに適用した自動テスト環境について述べる.
4.1 システム全体の自動テスト
本自動テスト環境の概要を図1に示す.システムの前後に入力と出力のデータを格納するための共有フォルダを配置した単純な形となっている.以降,詳細を述べる.
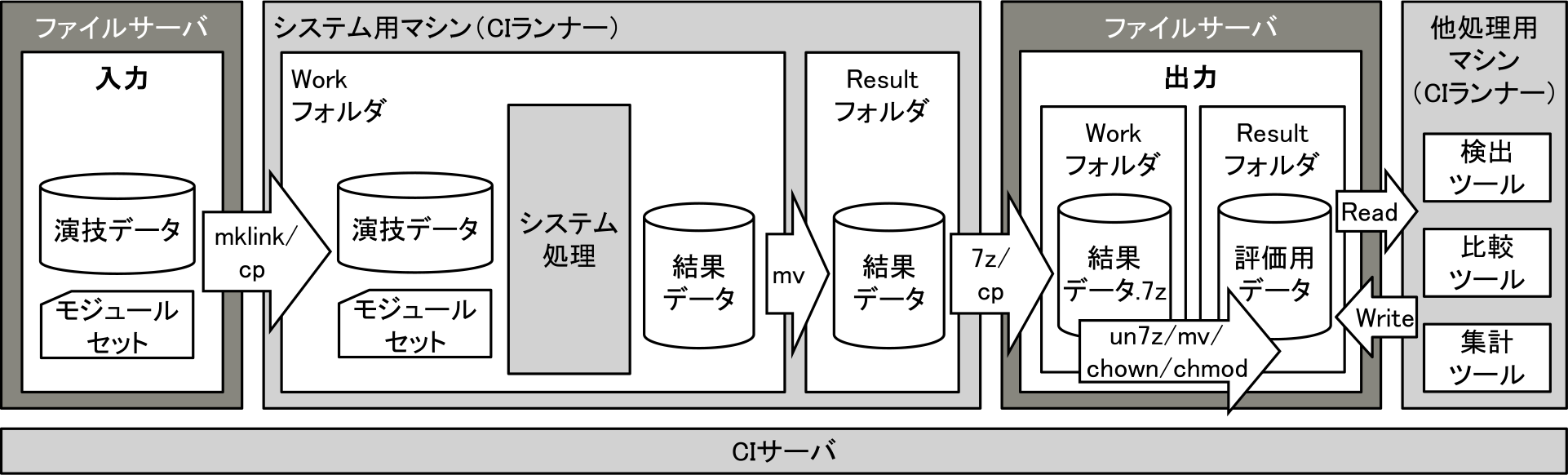
Fig. 1 The overview of our automated testing environment.
自動テストの設定
システムの速度評価や精度評価において,モジュールセットの差し替えが発生するため,それらの情報(ファイルパスやモジュールセット版数など)を1テスト設定ファイルに指定し,それに従って実行させる.これにより,テストを実行する人員同士の情報共有を円滑化し,過去のテストとの設定差分を把握しやすくなることが期待できる.
ファイルサーバから実行マシンへのデータ入力
ファイルサーバから演技データおよびモジュールセットを,選択されたマシンにコピーする必要がある.そこで,ファイルサイズが大きいものは,一時的にマシンのローカルディスクにコピー(cp)し,ファイルサイズが小さいものはローカルディスク上にファイルサーバ上のファイルへのシンボリックリンクを作成(mklink)することで,運用時と同等のフォルダ構成を再現する.
実行モード
自動テストの主な目的は,速度測定と精度評価の2つである.そこで,それぞれに対応する実行モードを用意する.前者では,大会現地と同等の設定を行い,演技本番と同等の処理速度で採点支援アプリに出力するデータのみを生成する.一方,後者では,各モジュールのデバッグ出力機能を有効化し,評価用データを生成する.
実行マシンからファイルサーバへのデータ出力
実行する演技データは各大会(大会名,個人総合,団体,種目別,予選,決勝など)により分類され,データセットとしてフォルダにまとめられているものの,1データセット内の演技データは数十個となるため,速度測定では1演技あたり5分,精度評価では1演技あたり20分の実行時間であると仮定すると,実行が完了してユーザが評価用データにアクセスできるようになるまでに1時間から数時間かかることになり,開発効率が損なわれることになる.そこで,ユーザに実行済み評価用データを逐次提供するために,図1のように,マシンとファイルサーバにWork(作業用)フォルダとResult(格納用)フォルダを設ける.各マシンはWorkフォルダでシステム処理を実行し,並行して,実行結果をResultフォルダに移動し,圧縮(7z)したファイルをファイルサーバ上のWorkフォルダにコピー(cp)する.ファイルサーバは定期的(たとえば10分ごと)にWorkフォルダを監視し,各マシンから格納された圧縮ファイルをResultフォルダに展開(un7z)および統合(mv)し,機密レベルの高いファイルと低いファイルを検索し,それぞれに対して適切なアクセス権を設定(chown/chmod)する.
各種ツールの実行
上記の実行により,ファイルサーバ上のResultフォルダに実行結果となる評価用データが格納され,ユーザが評価で使用するとともに,評価用データに対して,検出,比較,集計といった後処理(データの読み書き)を実行することで,定量的に分析し,評価の補助を行う.
4.2 入出力データに対するアクセス制御
本アクセス制御の概要を図2に示す.各処理マシンの入力側にはpublicフォルダとsecure/restrictedフォルダの2つのデータ領域,出力側にはci_secure/ci_restrictedフォルダの1つのデータ領域を用意する.以降,詳細を述べる.
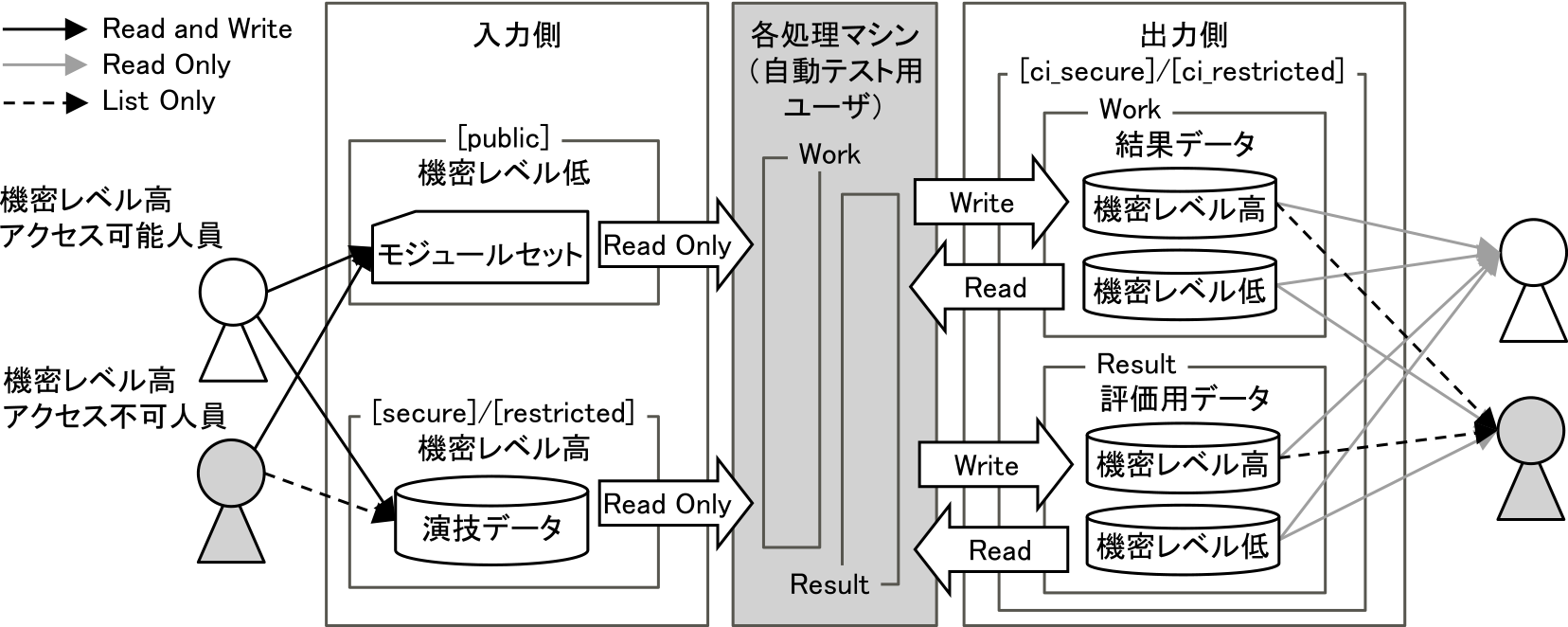
Fig. 2 The overview of our access control function.
データのアクセス権
入力側のpublicフォルダには全ユーザが読み書きでき,secureフォルダには,アクセス権のあるユーザのみが読み書き(Read/Write)できる.演技データなど機密レベルの高いデータはsecureフォルダに格納され,モジュールセットなど機密レベルの低いデータはpublicフォルダに格納されることを想定している.ここで,アクセス権を持たないユーザが,secureフォルダ内のフォルダやファイルの配置を把握できなければ,テスト設定ファイルにパスを指定できず,自動テストを利用することができない.そこで,secureフォルダにアクセスできないユーザでも,secureフォルダ内のフォルダとファイルの配置を確認(List)できるようsecureフォルダの実体をrestrictedフォルダとして見せることで解決する.
また,各処理マシンの自動テスト用ユーザは自動テスト用スクリプトを実行するうえで,スクリプト自体の不具合によるデータの誤操作(削除や上書き)を防止しなければならない.そこで,自動テスト用ユーザには,入力は読み出しのみ(Read Only)とし,出力は読み書きできるようにする.
出力側の評価用データには機密レベルの低いファイル(速度測定結果や各種評価ツールの結果など)が含まれており,単純に評価用データすべてをsecureフォルダに格納してしまうと,secureフォルダにアクセスできないユーザがそれらのファイルを参照できず,作業効率が低下してしまう.また,入力側のように,機密レベルに応じてファイルをsecureフォルダとpublicフォルダに分けて格納してしまうと,管理が煩雑化する問題がある.そこで,出力側は自動テスト結果が格納されるci_secureフォルダのみを設け,評価用データのうち,機密レベルに応じてファイル単位でアクセス権を設定する.ここで,ci_secureフォルダにアクセスできないユーザでも,機密レベルの低いファイルのみ読み出しできるようci_secureフォルダの実体をci_restrictedフォルダとして見せることで解決する.
データの管理および削除
選手や演技データにはIDを付与し,また,いつのテストのどのジョブで実行した結果か判別するためのIDを付与することで,ファイルおよびフォルダの名前から個人を特定できる情報を取り除いたうえで,実行結果データおよび評価用データをフォルダにまとめて管理し,個人からの問い合わせ時の追跡,選手単位でのデータ削除,および,使用期限によるデータ検索およびデータ削除に対応する.
なお,各マシン上に作成されるWorkフォルダやResultフォルダは実行直後のクリーンアップ処理により削除される.一方,ファイルサーバ上の評価用データには,選手個人を特定できる骨格データなどがファイルとして生成される.そこで,Workフォルダは実行失敗時の調査のために利用される可能性があることを考慮して,作成日時から数日程度で自動的に削除させる.一方,Resultフォルダはユーザが評価のために参照するため,評価作業が終了するタイミングで,管理責任者が保存や削除を行う.
5. 自動テスト環境の構築
本章では,4章で提案した環境を実現するための具体的な構築方法について述べる.
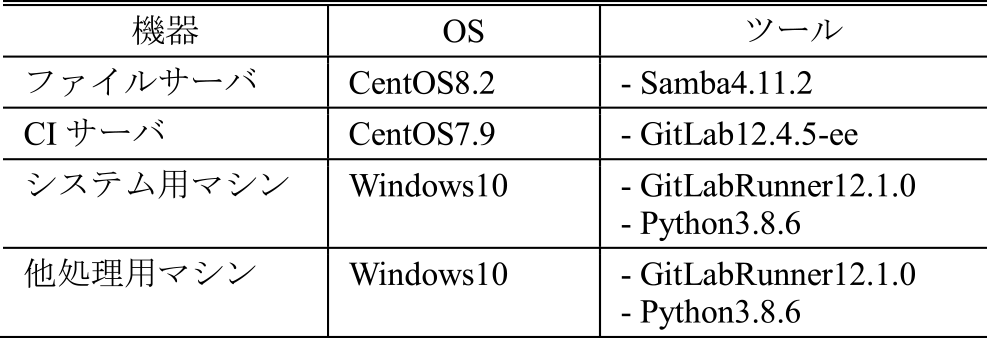
5.1 機材,OSおよびツール
本自動テスト環境の機材,OSおよびツールを表2に示す.CIツールには,Gitによるバージョン管理機能とCI機能がセットになっているGitLab [28]-[30]を採用した.CIジョブの実装方法としては,Pythonスクリプトを採用し,Windowsの機能を利用する場合はバッチファイル,Linuxの機能を利用する場合はBashスクリプトとする.ファイルサーバおよびアクセス制御にはSamba [31]を採用した.
Table 2 Configuration of machines and server systems.
5.2 CIパイプラインの設計
本節では,4.1節で述べたシステム全体の自動テストをCIで実現するための設計について述べる.本自動テスト環境のCIパイプラインを図3に示す.ユーザPC上で,テスト設定ファイル(run_list.json)に,演技データとモジュールセットのファイルパス,および,実行マシンセット数を設定し,手元のPC上にて,LoadJsonInfo.pyを実行すると,run_list.jsonの内容を読み出し,整合性チェック,複数実行時のリスト分割を行ったのち,実行モードの選択をユーザに要求する.ユーザが速度測定もしくは精度評価を選択するキー入力を行うと,テスト設定ファイル含め,CIサーバ上の自動テスト用Gitリポジトリに対してGit PUSH操作が実行される.
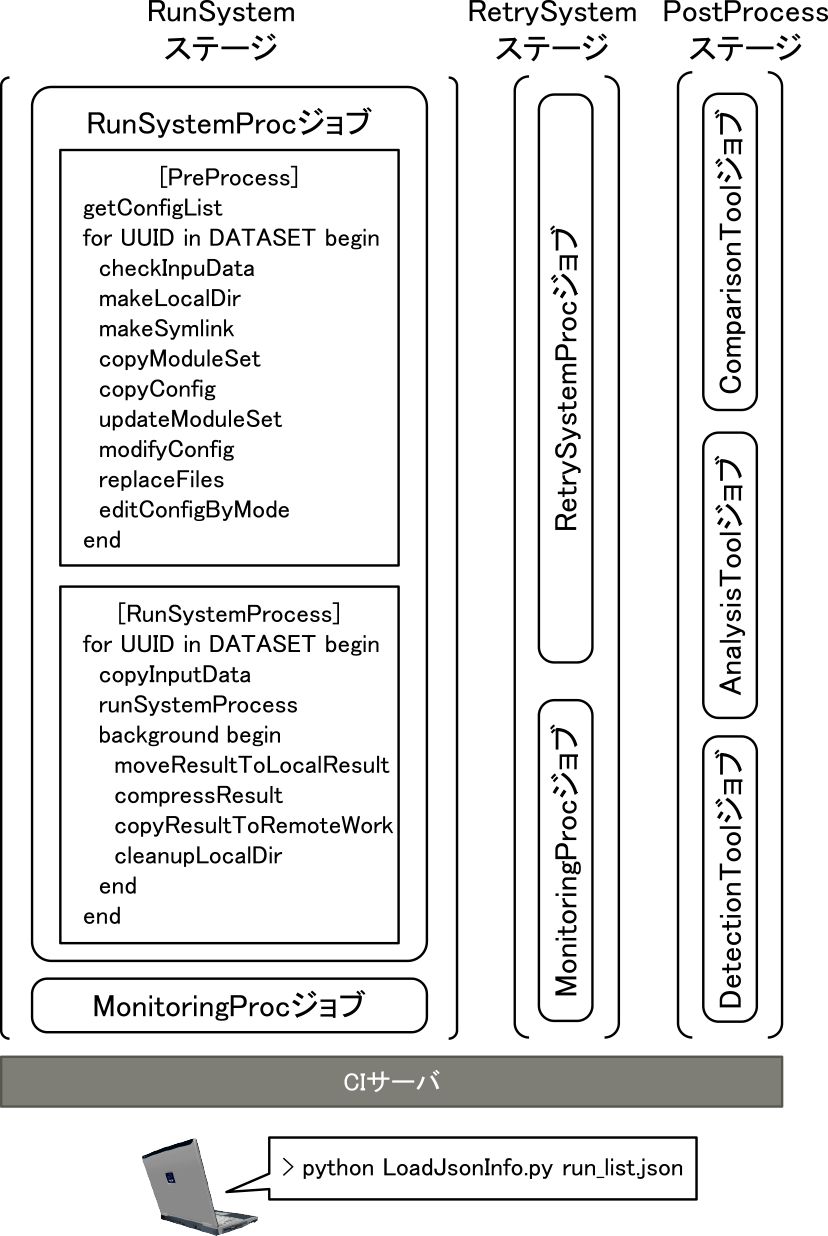
Fig. 3 The overview of CI Pipeline on GitLabCI.
その後,CIサーバはRun Systemステージ,Retry Systemステージ,Post Processステージを順番に実行する.各ステージには複数のジョブがあり,CIサーバは各ジョブにて指定さているタグに従って,マシンを選択する.たとえば,Run System Procジョブはシステム用マシン,Monitoring Procジョブは他処理用マシンのタグが指定されている.
各マシンの実行結果は,ファイルサーバ(URL)上の下記のフォルダに格納される.ここで,PIPELINE_IDとJOB_IDは,テスト実行時にCIサーバによって割り当てられる一意の整数であり,GitLabに限らず,一般的なCIツールでも同機能を有する.なお,データセット名は「日付_大会名_イベント名_種目名」,演技データ名はUUIDで表現される.
<URL>/<Sambaセクション>/{Work, Result}/<PIPELINE_ID>/<JOB_NAME>/<JOB_ID>/<データセット名>/<演技データ名>/
Run Systemステージにて,各マシンは,上記のフォルダ内に,自身のIPアドレスや実行状況などの情報を「ジョブ名.json」ファイルに書き出し,互いの情報を読み出す.さらに,各関数の標準出力は「関数名.log」ファイルに書き出され,各関数の完了は「関数名.done」ファイルに書き出されることで,各マシンはポーリングやハンドシェイクにより同期しながら,処理を実行する.ここで,Run Systemステージにて,実行が失敗した場合は,例外処理後,上記のフォルダ内にリトライリストファイルが作成され,次のRetry Systemステージにて,リストに記載された演技データがRun Systemステージと同じ仕組みで再実行される.最後に,Post Processステージのジョブが他処理用マシンで実行される.
5.3 ファイルサーバの設定
本節では,4.2節で述べたアクセス権をファイルサーバで実現するための設定について述べる.Sambaにおける設定を表3に示す.各列は図2で示した共有フォルダ(セクション)名を表し,各行は設定項目を表す.なお,フォルダおよびファイルに対して「1所有者/1グループ/その他」の設定(POSIX標準ACL)を想定している.
Table 3 Configuration of Samba.
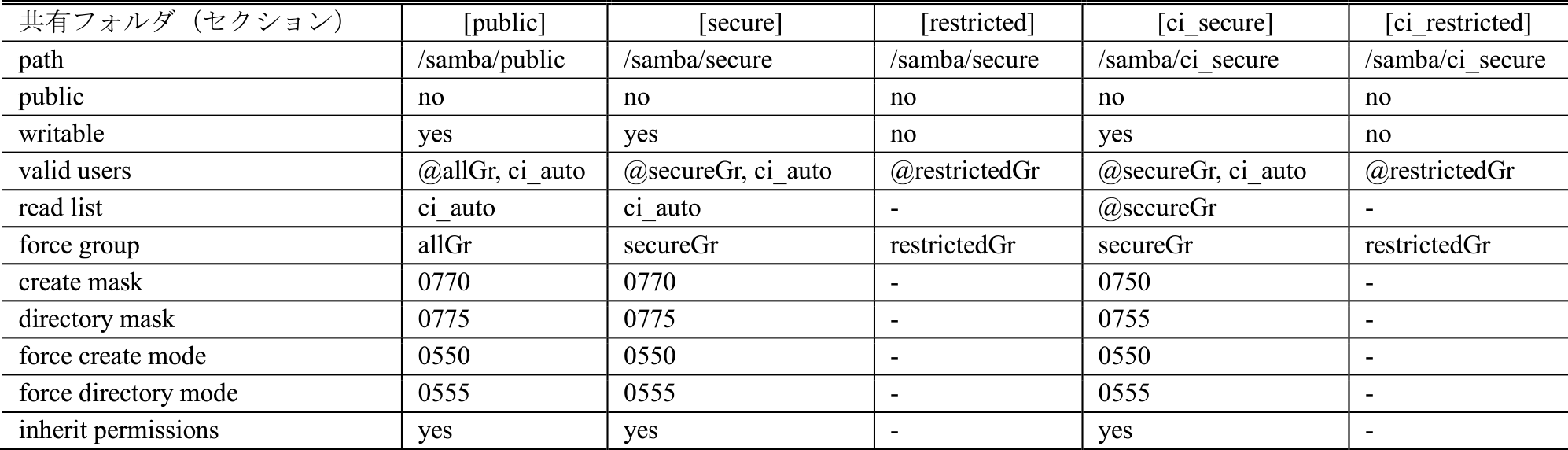
グループには,secureGr,restrictedGr,allGrの3つを用意する.secureGrには機密レベルの高いファイルにアクセスできるユーザが登録されており,restrictedGrにはアクセスできないユーザが登録されている.また,自動テスト環境においてCIランナーを実行する自動テスト用ユーザとしてci_autoを用意し,secureGrに登録する.allGrはsecureGrとrestrictedGrに登録されているユーザ全員が登録されている.また,各処理マシンおよび各ユーザのPC(Windows OS)において表4のようにネットワークドライブを設定することで,機密レベルの高いファイルにアクセスできる人員とアクセスできない人員で同じ領域のフォルダおよびファイルを同じパスで表現できるため,格納先の確認などの情報伝達が改善できると考えられる.
Table 4 Configuration of network drive.
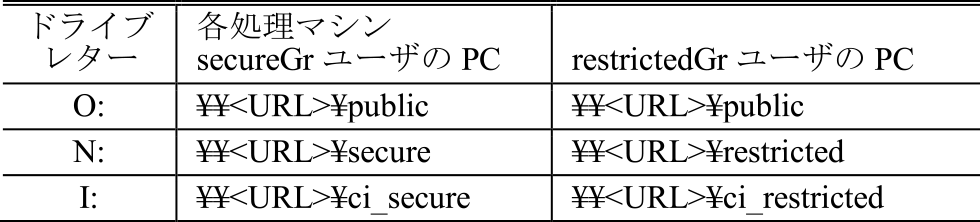
表3のSamba設定における各セクションの説明は以下のとおりである.
publicセクション
所有者とallGrユーザに対して読み書きアクセスを許可し,その他のユーザにはアクセスを禁止する.ここで,ci_autoユーザは読み出し専用となる.
secureセクション
secureGrユーザに対して読み書きアクセスを許可し,restrictedGrユーザにはアクセスを禁止する.ここで,ci_autoユーザは読み出し専用となる.
restrictedセクション
restrictedGrユーザに対してsecureセクションと同じ領域にアクセスを許可する.ここで,secureセクションにてファイルに0770権限,フォルダに0775権限を設定しているため,restrictedGrユーザはフォルダとファイルの配置を確認できるが,フォルダの変更およびファイルの読み書きはできない形となる.
ci_secureセクション
ci_autoユーザに対して読み書きアクセスを許可し,自動テストにて評価用データを格納させる.ここで,secureGrユーザは読み出し専用として評価用データにアクセスを許可し,restrictedGrユーザにはアクセスを禁止する.
ci_restrictedセクション
restrictedGrユーザに対してci_secureセクションと同じ領域にアクセスを許可する.ここで,ci_secureセクションにてファイルに0750権限,フォルダに0755権限を設定しているため,基本的に,restrictedGrユーザはフォルダとファイルの配置を確認できるが,フォルダの変更およびファイルの読み書きはできない.そこで,restrictedGrユーザが機密レベルの低いファイルにアクセスするために,評価用データ格納時にBashスクリプトにより,評価用データを展開するとともに,機密レベルの低いファイルに0755権限を設定する.
6. 自動テスト環境の実践結果と考察
本自動テスト環境の実践結果を表5に示す.導入前は(1)から(13)まですべて手作業であり,とくに,(2)から(5)について1セットあたり2時間を要していた.また,(6),(7)および(8)ではヒューマンエラーが多発し,原因調査に時間を要した.さらに,(10)と(11)についてデータ提供および利用に2時間かかるといった問題があった.一方,導入後は,(3)から(9)がCIツールにより自動化され,(1),(2)および(6)で所要時間は10分に改善した.また,(8)にて,Gitによる版数管理機能により,過去の版との差分や変更箇所を容易に確認できるため,原因調査にかかる時間を改善するとともに,ファイルサーバとの連携により,(10)と(11)の圧縮,転送および展開の手間が解消した.よって,システム開発効率を大幅に改善できたといえる.さらに,データの管理および削除について(12)と(13)のとおり負担を軽減できた.
Table 5 Results of automated testing environment.

課題1に対して,4.1節および5.2節で述べたCIにより,(1)から(9)のとおりシステム全体のテストをすべて自動化することができた.また,課題2に対して,4.2節および5.3節で述べたアクセス制御により,(10)から(13)のとおりユーザがデータの機密レベルを意識することなく開発を行えること,および,管理者責任者が容易にデータの管理および削除できることを確認できた.
本自動テスト環境のプラクティスは,従来のCIとファイルサーバをアクセス制御の観点で組み合わせたものであるため,体操採点支援システムに限らず,機密レベルの高いデータを扱う他のシステムでも有用である.
たとえば,不特定多数の人物が映っている画像から特定の人物を検出するシステム(人物検出システム)が挙げられる.このようなシステムでは,入出力データは老若男女にわたり膨大なデータとなり,機密レベルの高いデータとなるため,評価や分析においてプロジェクト人員に適切なアクセス権を付与する必要があると考えられる.
上記人物検出システムに適用する場合,3章で述べた解決方針を踏まえ,まずは,システムの入出力データの機密レベルを高低で分類し,データにアクセス可能または不可の人員を分類し,グループを作成する.次に,システムを構成する単一もしくは複数の機器の入力側と出力側に共有フォルダを設け,作成したグループのアクセス制御を設定する.最後に,各機器にCIツールを導入し,システムを自動実行するフローを実装することで,本体操採点支援システムに適用した場合と同等の効果が得られると考えられる.
拡張例として,たとえば,入力側の機密レベルが高低(secureおよびpublic)の2種から,高中低(secureH,secureM,および,public)の3種に分類する場合,まずは,グループとしてsecureHGr/restrctedHGrとsecureMGr/restrictedMGrの2組を用意し,各グループに該当する人員を登録する.次に,共有フォルダとしてpublicに加えてsecureH/restrictedHとsecureM/restrictedMの2組を用意する.最後に,共有フォルダとグループの紐付けを行う.ここで,共有フォルダに複数のグループを設定する場合はPOSIX拡張ACL [32]やWindows ACL [33]を用いる点に注意することが挙げられる.
7. おわりに
本稿では,CIとファイルサーバを利用して,機密レベルの高い入力データを読み出して,システム全体のテストを実行し,適切なアクセス権が設定された出力データを生成する自動テスト環境を提案し,構築,管理および運用まで行った.その結果,プロジェクト人員が容易にテストを実行でき,テスト作業の属人化を解消できた.また,プロジェクト人員が適切にデータアクセスでき,データ管理の負担も軽減できた.よって,本自動テスト環境は効率的なシステム開発と入出力データの管理を実現できたといえる.
現在,本自動テスト環境は安定稼働しているものの,システム改版に伴う,自動テスト環境の保守および管理における作業効率改善が課題である.また,本体操採点支援システムではAI技術を用いていることから,本自動テストの出力データをAIの学習データとしてフィードバックする仕組みについて取り組みたい.
参考文献
- [1] 柴田翔平,加瀬悠人,稲毛正也:日本野球市場に練習革命を起こす―センサ内蔵野球ボールを活用した野球指導効率化に向けた取り組みから―,情報処理,Vol.61, No.11 (2020).
- [2] 廣瀬雅治,荒川 陸,稲見昌彦:アジャイル開発を取り入れた協調的分析プロセスの提案と生産工場での実践,情報処理学会論文誌デジタルプラクティス(DP), Vol.2, No.4, pp.23–39 (2021).
- [3] 田中優之,青山幹雄:複数プロダクトのエンタープライズアジャイル開発方法の提案と実践,デジタルプラクティス,Vol.11, No.3, pp.569–588 (2020).
- [4] 松浦豪一:アジャイル開発プロジェクトマネジメントに対応する人材育成―改善によって成長を期待するマネジメント―,デジタルプラクティス,Vol.7, No.3, pp.260–267 (2016).
- [5] 誉田直美:アジャイルと品質会計―プロジェクトの高成功率を確保するハイブリッドアジャイルへの取り組み―,デジタルプラクティス,Vol.7, No.3, pp.218–225 (2016).
- [6] 桝井昇一,手塚耕一,矢吹彰彦,佐々木和雄:3Dセンシング・技認識技術による体操採点支援システムの実用化,情報処理,Vol.61, No.11 (2020).
- [7] 日本体操協会と富士通および富士通研究所,体操競技における採点支援技術の共同研究について合意,〈https://pr.fujitsu.com/jp/news/2016/05/17-1.html〉, (参照2022-01-18).
- [8] 国際体操連盟と富士通,体操競技の採点支援システムの実用化に向けて提携,〈https://pr.fujitsu.com/jp/news/2017/10/8.html〉, (参照2022-01-18).
- [9] 国際体操連盟,富士通の採点支援システムの採用を決定,〈https://pr.fujitsu.com/jp/news/2018/11/20.html〉, (参照2022-01-18).
- [10] 米国等における個人情報保護と利活用に関する近況,独立行政法人日本貿易振興機構(2018).
- [11] 情報セキュリティ白書2021,独立行政法人情報処理推進機構(2021).
- [12] Azure Kinect DK: 〈https://azure.microsoft.com/ja-jp/services/kinect-dk/〉(参照2022-01-18).
- [13] 川口恭伸,荻野恒太郎,古川貴朗:楽天でのエンタープライズアジャイルとDevOps―Dev/Test/Ops三位一体の自動化―,デジタルプラクティス,Vol.7, No.3, pp.243–251 (2016).
- [14] Jennifer Davis, Ryn Daniels,吉羽龍太郎,長尾高弘:Effective DevOps 4本柱による持続可能な組織文化の育て方,オライリー・ジャパン(2018).
- [15] Werner, C., Li, Z. S., Ernst, N. and Damian, D.: The Lack of Shared Understanding of Non-Functional Requirements in Continuous Software Engineering: Accidental or Essential?, 2020 IEEE 28th International Requirements Engineering Conference (RE), pp.90–101 (2020).
- [16] Li, Z. S., Werner, C. and Ernst, N.: Continuous Requirements: An Example Using GDPR, 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), pp.144–149 (2019).
- [17] Shahin, M., Ali Babar, M. and Zhu, L.: Continuous Integration, Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices, IEEE Access, Vol.5, pp.3909–3943 (2017).
- [18] Ebert, C., Gallardo, G., Hernantes, J. and Serrano, N.: DevOps, IEEE Software, Vol.33, No.3, pp.94–100 (2016).
- [19] Du, B., Azimi, S., Moramarco, A., Sabena, D., Parisi, F. and Sterpone, L.: An Automated Continuous Integration Multitest Platform for Automotive Systems, IEEE Systems Journal, early access, pp.1–12 (2021).
- [20] Yu, B., Liu, J., Zhou, X. and An, B.: Simulation Verification Platform for Complex Facility Control System, 2020 Chinese Automation Congress (CAC), pp.359–363 (2020).
- [21] Grünbacher, A.: POSIX Access Control Lists on Linux, USENIX 2003 Annual Technical Conference, FREENIX Track, pp.259–272, 2003. 〈https://www.usenix.org/legacy/events/usenix03/tech/freenix03/gruenbacher.html〉, (参照2022-01-18).
- [22] “Windows Server documentation”, 〈https://docs.microsoft.com/en-us/windows-server/〉, (参照2022-01-18).
- [23] “System Administrator's Guide”, 〈https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/system_administrators_guide/〉, (参照2022-01-18).
- [24] “Official Ubuntu Documentation”, 〈https://help.ubuntu.com/〉, (参照2022-01-18).
- [25] 大竹龍史,市来秀男,山本道子,山崎佳子:標準テキストCentOS 7構築・運用・管理パーフェクトガイド,SBクリエイティブ(2017).
- [26] 古賀政純:CentOS8実践ガイド[システム管理編],インプレス(2020).
- [27] 髙橋基信:【改訂新版】サーバ構築の実例が分かるSamba[実践]入門,技術評論社(2016).
- [28] GitLab Documentation, 〈https://docs.gitlab.com/〉, (参照2022-01-18).
- [29] 北山晋吾:GitLab実践ガイド,インプレス(2018).
- [30] 古賀政純:Docker実践ガイド,インプレス(2019).
- [31] “Samba Documentation”, 〈https://www.samba.org/samba/docs/〉, (参照2022-01-18).
- [32] Setting up a Share Using POSIX ACLs: 〈https://wiki.samba.org/index.php/Setting_up_a_Share_Using_POSIX_ACLs〉(参照2022-01-18).
- [33] “Setting up a Share Using Windows ACLs”, 〈https://wiki.samba.org/index.php/Setting_up_a_Share_Using_Windows_ACLs〉(参照2022-01-18).

吉村 和浩(非会員)
2007龍谷大学理工学部電子情報学科卒業.2009奈良先端科学技術大学院大学情報科学研究科情報システム学専攻博士前期課程修了.2012同大学同研究科同専攻博士後期課程修了.博士(工学).同年 株式会社富士通研究所入社.入社後,デジタル信号処理プロセッサ,ウェアラブルデバイスの研究開発に従事.現在,体操採点支援システムの研究開発に従事.

本田 崇(非会員)
1996早稲田大学理工学部機械工学部卒業.1998早稲田大学大学院理工学研究科機械工学専攻修士課程修了.同年 富士通株式会社入社.入社後,FLASHWAVE,1FINITYなど北米グローバル市場向けの光通信システム開発に従事.現在,体操採点支援システムの開発にプロジェクトマネージャーとして従事.
再受付日 2021年11月15日/2022年1月28日
採録日 2022年3月11日
会員登録・お問い合わせはこちら
会員種別ごとに入会方法やサービスが異なりますので、該当する会員項目を参照してください。