LSTMモデルによる金融経済レポートの指数化
Extracting Sentiment Indicators from Financial Reports by Using LSTM Model
1. はじめに
政府や中央銀行のマクロ経済レポートや日々の新聞,証券会社のアナリストレポートなど,投資に関する膨大なテキストが日々発行されており,投資家はこれらのテキストから情報を得て,自らの投資判断を下す必要がある.実際,ある投資家向けのアンケート調査によると[1],投資家の約60%が新聞記事を,約19%がアナリストレポートを投資情報として活用しており,テキスト情報は最も重要な投資情報の1つである.しかし,テキストを読むのには時間が掛かり,1人の投資家が読めるレポートやニュースは全体の極一部である.
株価や財務データ等の数値データであれば,時系列の変化や他社との比較,マクロでの集計が容易に行え,投資家はそれらから有益な情報を得ることができる.一方,テキストデータの場合には比較や集計は数値データのように容易ではない.もし金融テキストを機械的に数値で評価することが可能となれば,投資家は時系列や他社との比較,あるいは平均値や合計値への集計を通して自分で読める以上の膨大なテキストから瞬時に投資情報を得ることが可能になると期待される.
金融テキストに含まれる株価や景気にポジティブ/ネガティブなセンチメントを評価する(センチメント分析と呼ばれる)ことで,有益な投資情報が得られるとする先行研究が多くあり[2],本研究でも金融テキストのセンチメント分析に着目する.その手法は大別して極性辞書を用いた手法[3]-[7]と,特徴となるキーワードの数え上げにより数値化を行うBag-of-Words(BoW)で抽出した特徴量を入力とする機械学習手法[8]-[12]がある[2].極性辞書を用いる手法では精度を上げるために,極性辞書と係り受けや否定語処理,文脈の重み付け等のルール(テキスト処理ルールと呼ぶ)の作りこみが必要となるため,コストが掛かるうえに分析者の裁量が入り込む余地が大きいという課題がある.また,BoWと機械学習を用いた手法では言語の語順や文脈が考慮されていないという課題がある.
本稿では金融テキストのセンチメントを推定するモデルとして,近年急速に発展している深層ニューラルネットワークを用いることを提案する.これによって,キーワードの絞り込み,極性辞書の作成,テキスト処理ルール作りを必要とせず,データドリブンな手法で語順や文脈を考慮した景気センチメントを推定することが可能となる.深層ニューラルネットワークモデルとしては,Long Short-Term Memory(LSTM) [13]ユニットを持つRecurrent Neural Network(RNN)モデルを用いる.LSTMを用いることで,語順を考慮したセンチメント評価が可能となるため,“悪くなる要素は感じられないので、このまま良くなる方向に進む。”といった否定表現を含む文でも正確な推定が可能と期待される.なお,LSTMは深層ニューラルネットとしては比較的古くからある手法で,学習に必要なデータやコストも最新手法に比べると少ないという利点があるが,近年では注意機構(アテンション)をベースにしたTransformerモデル[14]がLSTMのようなRNNモデルよりも高精度であることが報告されている.また,Transformerを使ってBidirectional Encoder Representations from Transformers(BERT)のようにより大規模なデータで事前学習することで精度を高める手法も報告されている[15]-[18].本研究のセンチメント推定にこれらの手法を用いることも可能と考えられる.
このようなニューラルネットワークモデルの学習には大規模教師データの準備が課題となるが,日本政府(内閣府)が調査・公表している景気ウォッチャー調査[19]を教師データに用いることで,これを解決する.景気ウォッチャー調査は景気に関するセンチメント(景気センチメントと呼ぶ)のラベルとその判断理由テキストが紐付いた約20万サンプルの大規模データである.センチメントラベルの集計値である景気ウォッチャー調査のDiffusion Index(DI)は代表的な景気マインド指標として活用[7]されてきたが,個々の判断理由テキストは研究事例がほとんど無く,センチメントモデルの学習データとして用いるのは本研究が初と考えられる.景気ウォッチャー調査データに含まれるセンチメントラベルは景気に関するものであり,株価や為替等へのセンチメントは含まれていない.このため,本稿の以下の分析は景気センチメントに限定して記述するが,学習データを変更・追加することで景気センチメント以外にも適用可能と期待される.
提案手法の有効性を評価するために,景気ウォッチャー調査のテストデータで景気センチメント推定精度を評価する.ベースラインとして代表的なBoW手法であるTF-IDFによるモデルと比較し,提案手法により精度が向上することを確認する.また,LSTMで正答/誤答した例を考察し,語順や文脈を考慮した学習ができていることを確認する.
得られた景気センチメント推定モデルが実際に金融・経済レポートの評価に有効であることを確かめるために,日本政府や日本銀行(日銀)が発行する月次レポートの文書全体の景気センチメントをモデルで評価して指数化する.なお,本研究ではこの指数をレポート景況感指数と呼ぶ.指数化手順の概要を図1に示した.得られた政府,日銀レポートのレポート景況感指数を既存の経済指標や株価指数と比較し,指数の有効性を確認する.
Fig. 1 Procedure for calculating the report sentiment indicator.
なお,本稿は[20]で発表した内容をもとに加筆修正したものである.
本研究の主な貢献は以下のとおりである.
- ・深層ニューラルネットを用いることで,景気センチメントを約95%の精度で分類可能とした(2値分類の場合).これは,TF-IDFと比較して約7ポイント高い精度である.
- ・上記のモデルを学習するために,景気ウォッチャー調査データを用いた.景気センチメントの機械学習に本データを用いたのは筆者の知る限る本研究が初めてである.
- ・政府や日銀の発行するレポートのテキストを指数化することで,他の経済指標や過去のレポートと比較し,日経平均株価との相関が既存の経済指標と比較しても高いことを確認した.
- ・本研究の手法が発表[20]されて以降,本研究で用いた景気センチメント推定手法を応用した様々な指数が公表され,社会で実用された.例として,筆者らのチームは提案手法をベースとして“SNS×AI景況感指数”(経済産業省,野村證券株式会社から公表)として実用化した.この研究では提案手法と同様に学習した景気センチメント推定モデルをTwitterに応用することで,リアルタイムに日本全体の景気センチメントを算出している[21].でき上がった指数は既存の統計指標である景気ウォッチャー調査 現状判断DIと高い相関を示しており,特に新型コロナパンデミックによって,景気センチメントが大きく下落,回復した時期が良く捉えられていることが報告されている[22].また,他社も類似した手法を開発しており,業界のベースとなる手法を作った.
本章の最後に本研究の応用範囲について述べる.本稿では政府と日銀の2つのレポート景況感指数を試しているが,本研究の手法はより一般のレポートやニュース記事,SNSの書き込み等に応用可能である.その際,学習に用いるテキストと指数化するテキストの話題や文体が類似している必要があるが,金融分野では景気に関する様々なレポートが発行されており,景気ウォッチャー調査データで学習したモデルとの親和性が高い.また,StockTwits [23]やYahoo!ファイナンス掲示板[24]といった株式に関するラベル付きのテキストを用いることで,景気だけでなく株価に関する金融テキストも評価可能と期待される.さらに,金融分野以外にもE-Commerceサイトやグルメサイトのレビューを用いることで,商品やレストランに関するテキストを指数化することも可能と考えられる.
以降の章では2章で関連研究について述べたのち,3章で図1のStep1,4章でStep2-4について述べる.5章はまとめと結論である.
2. 関連研究
金融・経済分野におけるセンチメント分析を用いた研究と,本研究で用いた深層ニューラルネットによるセンチメント分析および景気ウォッチャー調査データを使った研究について以下でまとめる.
2.1 金融テキストのセンチメント分析
ニュースやレポート等のテキストデータを投資に活用する試みは多くある.特に近年では本研究と同様に文章のセンチメントを解析し,株価等のマーケットデータとの連動性を示すことを報告するものが多数ある.
2.1.1 極性辞書を用いたセンチメント分析
Tetlock et al. [3],Heston and Sinha [4]や石島ら[5]ではニュース記事のセンチメントを単語の出現頻度と極性辞書から評価し,得られた指標が企業の利益や株価と相関を持つことを示した.また,近年ではより膨大で即時性の高いテキストデータであるSNSを利用する研究もある.Bollen et al. [25],迫村・和泉[6]ではTwitterのテキストに対して同様のセンチメント分析を行い,金融市場との相関があることを確認している.Antenucci et al. [26]は失業に関連する単語の辞書を作り,Twitterでの出現頻度から指数化した.得られた指数は米国政府の公表する失業保険申請者数の予測に有用であることを示した.諏訪部[27]では,四季報や決算議事録やアナリストレポートのセンチメントをあらかじめ用意した辞書で評価し,それを元に株式を売買することで統計的に有意な正のリターンを得られるとしている.
2.1.2 BoWと機械学習を用いたセンチメント分析
極性辞書を用いず本研究のように機械学習を用いてセンチメントを推定した研究としてはAntweiler and Frank [8],Huang et al. [9],Das and Chen [10],Li [11],前川ら[12]などが挙げられる.Huang et al. [9]ではアナリストレポートを教師データとして,レポートのレーティング(買い推奨/売り推奨)をテキストから推定するセンチメントモデルを学習している.モデルはBoWの一種であるNaive Bayesモデルを用いており,辞書を用いた手法に比較して精度が高かったことを報告している.Das and Chen [10]はいずれもBoWを用いた5つの異なる手法を用いてインターネット掲示板のメッセージをセンチメント分析している.Antweiler and Frank [8]も同様にインターネット掲示板のメッセージをNaive Bayesモデルで分析している.Li [11]は企業の有価証券報告書に含まれる経営者による経営成績の分析であるManagement Discussion & Analysis(MD&A)と呼ばれるテキストをNaive Bayesモデルで分析し,MD&Aのセンチメントが将来の企業業績と正に相関があると報告している.前川ら[12]は半教師有り学習で構築した極性辞書とNaive Bayesモデルを用いて,ニュース記事から株価の予測を行っている.
これらはいずれも機械学習モデルとしてNaive BayesモデルのようなBoWを用いたモデルを採用されている.
ここまで,深層ニューラルネット登場以前の金融・経済分野でのテキストのセンチメント分析について紹介した.いずれもテキストのセンチメントと株価や企業業績,経済指標との相関が報告されている.一方,センチメント分析モデルについては極性辞書またはBoWを使った機械学習が採用されており,前者では極性辞書やテキスト処理ルールの作成に手間が掛かる点が課題であり,後者では語順や文脈が無視されることにより精度が低下する可能性がある点が課題である.
2.1.3 深層ニューラルネットを用いたセンチメント分析
次に,本研究で用いたLSTMの様な深層ニューラルネットを用いたセンチメント分析を紹介する.深層ニューラルネットによる一般のセンチメント分析はLSTMを用いた手法[28], [29]やConvolutional Neural Network(CNN)を用いた手法[30]を中心に発展し,近年ではBERT [15]を用いた手法が注目されている.金融関連テキストにRNNを用いた分析としては,ニュース記事の要約を試みたChen et al. [31]がある.青嶋・中川[17]は景気ウォッチャー調査データにBERTを適用し,LSTMより分類精度が高いことを確認した.BERTの学習には景気ウォッチャー調査データより大規模なテキストデータが必要なため,彼らは日本語Wikipediaを用いて事前学習を行っている.本研究でも景気センチメント推定にBERTを用いることで精度が向上し,より良いレポート景況感指数につながる可能性がある.西ら[16]は同じくBERTとLSTMをニューステキストで比較して,やはりBERTのほうが精度が高くなることを報告している.Xing et al. [18]は投資情報SNSであるStockTwitsデータでLSTMやBERTを含む様々なモデルを学習し,精度の比較を報告している.本研究と同様の分析をCNNを用いて行った五島ら[32]の研究については次節で述べる.
なお,本研究の元となった研究[20]以前には,深層ニューラルネットを用いた金融テキストのセンチメント分析を行った研究は見つけられなかった.
2.2 景気ウォッチャー調査データを用いた研究
景気ウォッチャー調査データのテキストを用いた研究は多く無いが,岡崎・敦賀[7]は語彙の出現頻度や共起ネットワークと各月のDIとの関係を調べ,DIが変化した理由を語彙レベルに分解して要因を明らかにする試みが成されている.景気ウォッチャー調査データをセンチメント推定モデルの教師データとして用いた研究は本研究が初と考えられる.
五島ら[32]は本研究を参照して,景気ウォッチャー調査データでCNNを学習しニュース記事から景況感ニュース指数を計測している.得られた指数は本稿のレポート景況感指数と同様に景気動向を表す経済指標と相関しており,さらに,指数が株価や国債価格のボラティリティ(変動率の標準偏差)の予測に有効であることが報告されている.
3. 景気センチメント推定機の学習
金融文書を指数化するために,比較的短いテキスト(たとえば1つのセンテンス)の景気センチメントを推定するセンチメント推定機を学習した.機械学習の中でも近年急速に発展している深層ニューラルネットワークの一手法であるLSTMモデルを用いることで,先行研究のように極性辞書やテキスト処理ルールを作りこむこと無く,語順や文脈を考慮したセンチメントモデルが学習できることを示す.以下では学習に用いたデータとモデルについて説明する.
3.1 学習データ:景気ウォッチャー調査
学習データには内閣府が調査・公表している景気ウォッチャー調査[19]を用いた.景気ウォッチャー調査とは内閣府が行う景気動向に関するアンケート調査で,タクシー運転手や小売店の店主等,景気に敏感な人達(景気ウォッチャー)に景気に対する判断(5段階,現状・先行き別)とその理由(テキストデータ,現状・先行き別)をアンケートしている.結果は毎月公表され,景気判断の集計値がPDF等で公表されるのに加えて,全件のテキストデータと景気判断がCSVで利用可能となっている.利用したデータの期間は2010年1月から2015年12月である.
本研究では,この景気判断理由のテキストから,景気判断を予測する教師有り学習によって,景気に関する文章からそのポジティブ/ネガティブ度合を自動で推定(分類または回帰)する機械を学習する.判断理由のテキストの多くは1センテンス程度の短いもので,たとえば“最近は客の反応も非常に良いため、先行きはやや良くなる。(先行き判断,やや良い)”,“東日本大震災の影響は避けられず、厳しい状況となる。(先行き判断,悪い)”といったものである.このため,学習されるモデルも比較的短いテキストを推定するモデルとなる.
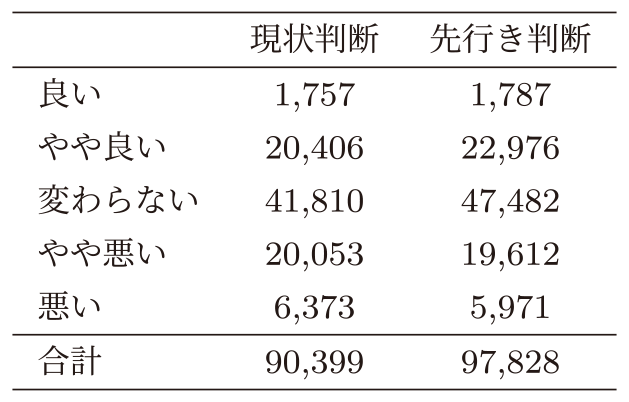
景気ウォッチャー調査データの回答別件数を表1にまとめた.解答は景気の現状判断と先行き判断に分かれており,いずれも中央の“変わらない”を中心に概ね対称に分布している.実際の回答サンプルや質問項目の詳細については[19]を参照されたい.
Table 1 Number of responses to the economic watcher survey.
3.2 景気センチメント推定機の構築
用いた機械学習モデルの概要と推定精度について述べる.
3.2.1 LSTMモデル
以下ではLSTMユニットを用いたRNNモデルについて説明する.RNNは時系列データのような連続した系列をニューラルネットワークで解析する手法であり,長さが異なる系列への適用も可能であるため,本研究のような自然言語の解析に向いている.RNNでは,前の層の中間層を次の層の入力ベクトルの一部として用いるため,過去の系列を“記憶”することができる.言語の解析ではこれによって語順や文脈の解析が可能となる.RNNで活性化関数にtanh関数を用いる場合,時刻tでxtとht−1からhtを求める式は以下となる.\[h_t = \tanh (Wx_t + Uh_{t-1} + b)\](1)
ここで,xtはt時点の入力,ht−1はt−1時点の隠れ層,W,U,bはそれぞれの重み行列,切片である.しかし,RNNの活性化関数に1式のような単純なtanh関数を用いた場合,誤差の勾配が消失または発散してしまう問題があり,長期の系列の学習が難しいことが知られている.LSTMモデル[13], [33]はこのRNNの勾配消失・発散問題を解決するために用いられ,近年,言語のセンチメント推定タスクにおいても高い性能を発揮することが報告されている[28], [29].LSTMではxtとht−1からhtを求める際に,1(式)の代わりに下式で表される入力ゲート(it),忘却ゲート(ft),出力ゲート(ot)を用いることで,それぞれ入力の重み,前の隠れ層の重み,出力の重みを調節して記憶することが出来,これによって長期の記憶を可能としている.\[i_t = \sigma (W^{(i)} x_t + U^{(i)} h_{t-1} + b^{(i)})\](2)
\[f_t = \sigma (W^{(f)} x_t + U^{(f)} h_{t-1} + b^{(f)})\](3)
\[o_t = \sigma (W^{(o)} x_t + U^{(o)} h_{t-1} + b^{(o)})\](4)
\[u_t = \tanh (W^{(u)} x_t + U^{(u)} h_{t-1} + b^{(u)})\](5)
\[c_t = i_t \circ u_t + f_t \circ c_{t-1}\](6)
\[h_t = o_t \circ \tanh (c_t)\](7)
ここでσはSigmoid関数,$\circ$は要素間の積を表す.
3.2.2 テキストのLSTMへの入力と出力層
景気ウォッチャー調査データのテキストをLSTMモデルで解析するため,本研究ではまず形態素解析エンジンMeCab [34]を用いてテキストを単語に分解した.分解した各単語を200次元のベクトルに埋め込んだ後,テキストの最初の単語ベクトルをx0,次の単語をx1,・・・,として順にLSTMに入力した.計算コストを考慮して1つのテキストにおける単語数の上限は150とし,それ以降の単語は切り捨てたが,全テキストの99.9%が150単語以下であったため,学習への影響は軽微と考えられる.なお,MeCabにはテキストを各単語に分解するだけでなく,各単語の原形を返す“原形”という出力がある.活用形による単語種類の増大を防ぐため,入力する単語はすべてMeCab出力の“原形”を用いた.なお,学習データにおいて2回以上出現しない単語はすべて未知語として“[UNK]”で置換した.これによって単語は全部で12,849種類となった.さらに,文頭のみからテキストを入力するとLSTMの場合にも最初のほうの入力が重視され難くなる懸念があるため,文の最後から入力するプロセスも加えたBidirectional LSTM(BLSTM) [35]も実装して比較した.LSTMプロセスで得られた最終時点のhtに全結合層と出力層をつなげることでセンチメント予測を行った.出力層の活性化関数は次節で説明するタスク種別によって異なり,2値分類の場合にはSigmoid関数,回帰の場合には恒等関数を用いた.損失関数は2値分類ではクロスエントロピー,回帰ではMean Squared Error(MSE)とした.なお,htと全結合層をつなぐ際には各時点のhtを平均して用いる方法も考えられるが,[29]を参考に最終時点のhtのみを全結合層の入力に用いた.
3.2.3 作成したモデルの種類
ここでは作成したモデルの種類について記述する.モデルは“タスク種別”,“学習データ”,“機械学習モデル”の3つの軸で分けて複数個を作成している.
- ・タスク種別:2値分類,または回帰の2パターン.2値分類は単純で評価が簡単である.一方,回帰の場合には“変わらない”も含めてすべてのサンプルを利用できる点と,分類問題と違って“悪い”~“良い”まで5段階の順序情報を考慮できる点が優れている.
- −2値分類:学習データのラベルのうち,“良い”/“やや良い”を1,“悪い”/“やや悪い”を0として2値分類.
- −回帰:“悪い”~“良い”までの5段階をそれぞれ−2~+2として回帰.
- ・学習データ:現状について記述したテキストでは“良くなった”/“良くなっている”といった事実を記述する表現が多く,先行きについて記述したテキストでは“良くなる(だろう)”/“期待される”と言った未来の推量や期待を記述する表現が多くなるなど,使われる単語や表現に違いがあるため,以下の3パターンで学習した.
- −現状:景気の現状判断について記述した現状判断データのみを使って学習
- −先行き:同様に先行きデータのみを使って学習したモデル
- −現状・先行き:両者を併せて使って学習したモデル
- ・機械学習モデル:以下の3パターン.
- −LSTM:LSTMモデル.長期記憶によって語順を考慮した学習が可能.
- −BLSTM:Bidirectional LSTMモデル.文頭に重要な主張がある場合にLSTMより高精度と期待される.
- −TF-IDF:テキストに出現する単語のTF-IDF値を特徴量としたロジスティック回帰(2値)または線形回帰(回帰)モデル.学習にはl2正則化を使用.語順を考慮しないベースラインモデルとして構築.
3.2.4 モデルの学習方法
いずれのモデルも全データの90%を学習データ,10%をテストデータとしてランダムに分割し,テストデータの精度を計測している.また,モデルのハイパーパラメーターのチューニングは学習データの中からさらにランダムに10%を検証データとして分割して行った.パラメーターごとに数パターンを試して検証データの損失関数が最小となる以下の値を用いた.中間層の次元は250,バッチサイズは50,エポック数は3,ドロップアウトは0.3,最適化手法はAdam(学習率0.001) [36]である.なおデータサイズは最大で約20万件(表1)あるため,イテレーション数は最大1万回程度となる.
3.2.5 モデル精度の検証
表2に示したモデル精度について説明する.表の列方向はそれぞれ“LSTM”,“BLSTM”,“TF-IDF”の結果を示している.表の行方向のラベルは“2値”は2値分類モデル,“回帰”は回帰モデルをそれぞれ表す.“現状”は現状判断のデータで学習したモデル,“先行き”は先行き判断のデータで学習したモデル,“現状・先行き”は両者を併せて学習したモデルを表す.また,表中の数値は“2値”では正答率を,“回帰”では平均二乗誤差の平方根(Root Mean Squared Error, RMSE)を示している.なお,学習データと同じく,“現状”モデルのテストデータは“現状”テキストのみ,“先行き”モデルのテストデータは“先行き”テキストのみ,“現状・先行き”モデルのテストデータは“現状”テキストと“先行き”テキストを併せたデータである.
Table 2 Accuracy/RMSE of sentiment model.
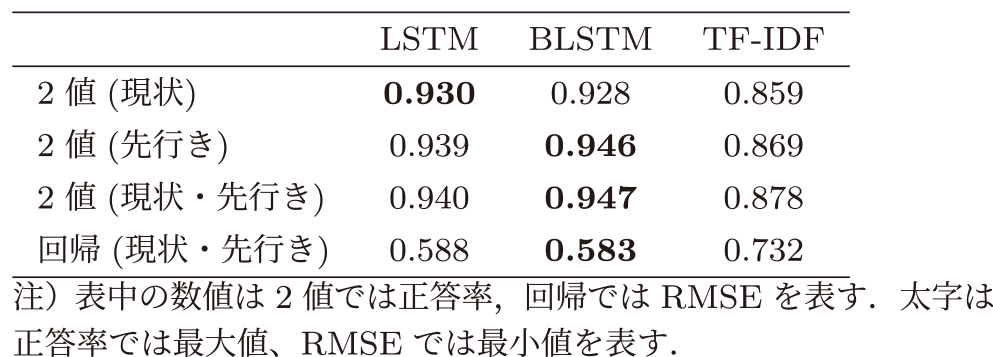
まず列方向に比較すると,いずれのタスク種別(2値/回帰),学習データ(現状/先行き/現状・先行き)においてもLSTMまたはBLSTMの精度がTF-IDFに比べて高くなった.2値分類ではBLSTMが95%近い正答率のところ,TF-IDFは88%であり,誤答率はTF-IDFで二倍以上となっている.これはTF-IDFでは語順情報が失われるため,たとえば“悪くはならない”,“良くなるとは思えない”といった否定表現による係り受けのある文章を正確に評価できないためと考えられる.この結果から,景気ウォッチャー調査データを用いた景気センチメントの推定では,LSTMのような語順を考慮したモデル化を用いることが重要であると考えられる.LSTMとBLSTMを比較すると,“2値(現状)”以外ではBLSTMの精度が高くなっており,双方向からテキストを入力するBidirectional LSTMには一定の効果がみられる.“現状”と“先行き”に関しては両者の正答率に大きな差はみられず,最も精度が高いのは両者を併せて用いた“現状・先行き”であった.これは両者を併せることで学習データが増加したためと思われる.この結果から,本データに関しては日本語の現状表現・先行き表現の差異によるセンチメント評価モデルのチューニングの必要性は無いと考えられる.
3.2.6 モデル分類結果の考察
ここでは解釈が容易な2値分類モデルの推定値から,開発した(B)LSTMモデルの特徴を考察する.なお,いずれもテストデータに含まれるサンプルである.
表3はTF-IDFモデルで誤答したサンプルをBLSTMモデル推定誤差が低い順に並べて表示したものである.No.1~3は正解ラベルが1(良い/やや良い)のサンプル,No.4~6は正解ラベルが0(悪い/やや悪い)のサンプルである.
Table 3 Text answered correctly by the BLSTM and incorrectly by the TF-IDF.

No.1~3は景気をポジティブに捉えているテキストであるが,いずれも“悪くなる”,“混乱”,“景気が悪い”等のネガティブな表現が含まれている.いずれも語順や文脈に注目するとポジティブな文章であることは明らかであるが,BoWによって文の構造が失われるTF-IDF法ではこのような語順の考慮が必要な文章の評価は難しいと考えられる.一方で,語順保持するBLSTMモデルでは正しい判定結果が得られている.
No.4~6は景気をネガティブに捉えているテキストであるが,同様に“新商品”,“少し景気が良く”,“今月が良すぎる”等のポジティブな意味で使われることが多い表現が含まれている.このため語順や文脈の考慮が重要であり,No.1~3と同様に,TF-IDFでの評価が難しくBLSTMでは正答に至ったと推察される.また,No.3とNo.6はいずれも現在の景気は悪い(良い)とする一方で,後半に結論として今後の景気が良くなる(悪くなる)と述べている.(B)LSTMでは,このようなセンテンスの後半で結論が来ることが多い日本語の特徴を学習した結果,後半部分を重視して正答に至ったと考えられる.上記から,LSTMモデルでデータから自動的に語順や文脈を考慮した景気センチメント推定が学習できたと言える.
次に,表4は表3と反対にTF-IDFで正答し,BLSTMで誤答したサンプルである.No.1~3は正解ラベルが1(良い/やや良い)のサンプル,No.4~6は正解ラベルが0(悪い/やや悪い)のサンプルである.
Table 4 Text answered correctly by the TF-IDF and incorrectly by the BLSTM.

表4のNo.1~3はいずれも筆者が読んでも景気にポジティブな内容と判別するのは難しい文章であり,回答者による正解ラベルの付け間違いの可能性も考えられる.
表4のNo.4と6については結論がどちらとも取れる文章で,やはり筆者が読んでも判定が難しい文章と感じられる.一方,No.5は明確にネガティブな文章と読み取れるがBLSTMでは非常にポジティブな評価となっている.これは“集客に苦労”という表現が学習できておらず,“繁忙期”というポジティブな単語に引っ張られたためと推察される.“集客に苦労”という表現は学習データには5回しか現れず,慣用的な表現の学習にはより多くの学習データが必要である可能性がある.このような誤りはさらに学習データを増やすことで改善すると期待される.
本節の考察から,定性的ではあるが以下の3点を見ることができた.
- ・LSTMモデルが狙いどおり語順や文脈を学習できている
- ・LSTMで2値分類を誤った約5%のデータの中には人間でも判別が難しいサンプルが一定程度含まれる
- ・学習データの増加がモデルの改善に繋がると期待される
4. 金融・経済レポートの指数化
ここでは得られた景気センチメント推定モデルを用いて,内閣府の月例経済報告と日銀の金融経済月報を指数化する.
4.1 指数化の方法
以下では内閣府の月例経済報告を例に,指数化の方法を説明する.なお,指数化の方法は日銀の金融経済月報でもほぼ同様であるが,金融経済月報の“参考計表”以降のページは図表と注釈のみなので評価からは除いた.
月例経済報告は日本政府が毎月発行する経済レポートである.景気動向に関する日本政府の公式見解を示しており,閣議資料等で用いられる重要な文書である.図表はほぼ無く,1998年1月から2015年12月までの平均で各月17,036文字,219センテンスから成るレポートである.
3章で学習した景気センチメント推定モデルは1センテンス程度の短いテキストで学習しているため,評価対象のレポートを句点(“。”)までを1つのセンテンスとして分割し,各センテンスごとにモデルで評価した.学習データに出現しない単語は埋め込み表現が学習できていないため,入力テキストから削除した.景気センチメント推定モデルは“変わらない”を含むすべてのサンプルで学習できる点と“悪い”~“良い”までの順序情報を利用できる点を考慮して,回帰モデルを用いた(2値分類モデルを用いた場合にも,以下の定性的および定量的な評価に大きな違いは無い).得られた各センテンスの景気センチメントを月次レポートごとに平均値で集計しその月の指数値とした.つまり,景気センチメント推定モデルでポジティブ/ネガティブに評価されているセンテンスの割合が多い月ほど高い/低い指数値が算出されることになる.集計方法に関しては合計値やセンテンスの文字数や文字サイズによる加重平均等も考えられるが,合計値はレポートのコンテンツの追加/削減によって変化する懸念があり,加重平均は文字数やサイズが必ずしも重要性を表していると言えないことから単純平均とした.また,ノイズと思われる注釈や定型文の除去も必要となる場合があるが,本レポートの“。”で終わるセンテンスに関してはそのようなノイズは少ないため特段の処理は行っていない.
得られたレポート景況感指数の時系列(1998年1月から2015年12月)を図2に示した.
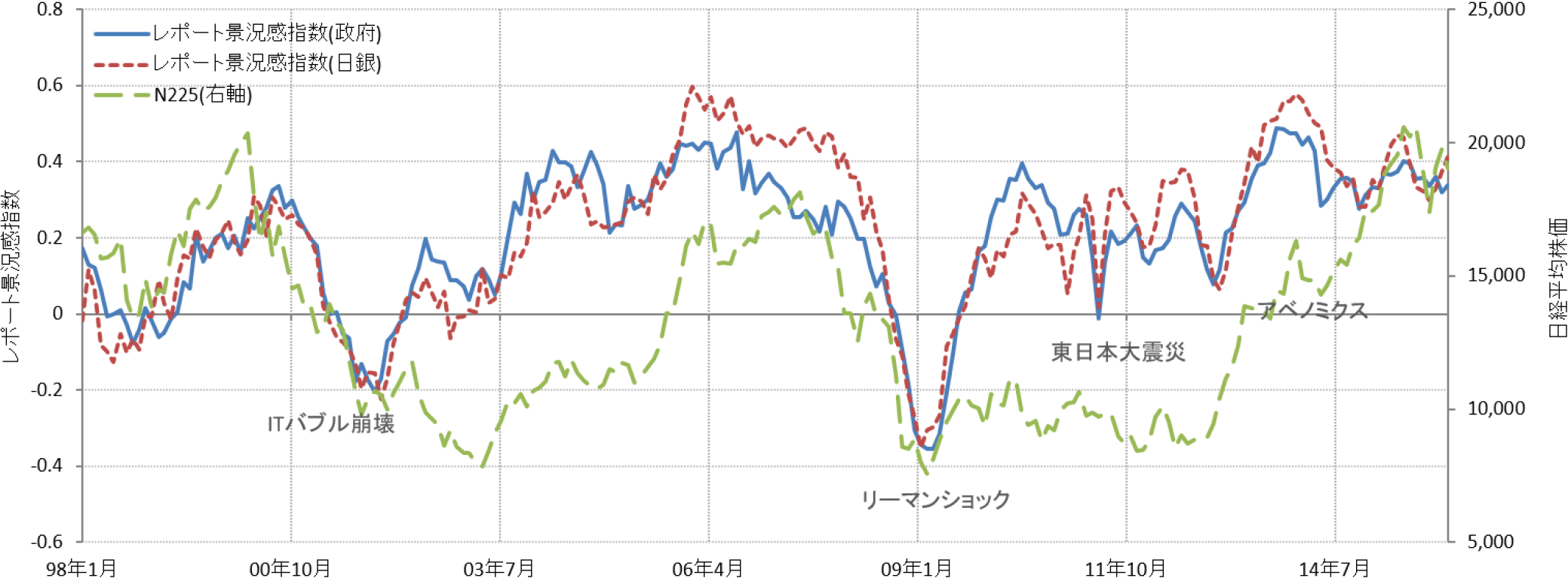
Fig. 2 Time series of the report sentiment indictors.
4.2 得られた指数の評価
この節では提案する指数を定性的,定量的に評価する.まず定性的な評価として,政府の月例経済報告から得られた指数と日銀の金融経済月報から得られた指数が非常によく似た動きを示していることは重要な点である.いずれの文書も各時点の景気動向について書かれたレポートであるので,本来,似たような景気センチメントを持つべきであるが,もしノイズが大きい手法で指数化を行った場合,異なる文書がこのような高い連動性を偶然持つとは考え難く,本手法の有効性を示す結果と考えられる.また,両指数ともにマクロ経済の動きを良く反映しており,“ITバブルの崩壊”,“リーマンショック”,“東日本大震災”,“アベノミクス”といった大きなイベントによって株価と連動して上下している.
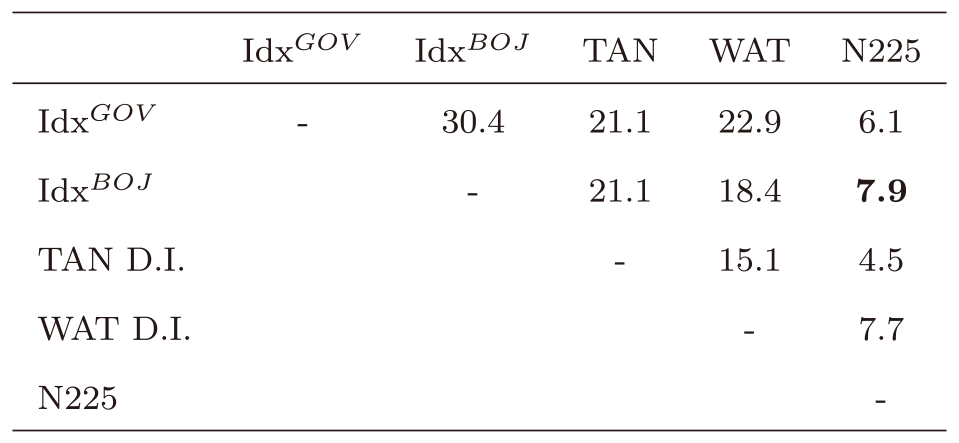
次に定量評価を行う.表5と表6は他の時系列との相関とt値をそれぞれ示している.表中の太字はN225との相関係数またはt値が最も高いことを示している.まず,政府の月例経済報告から得られた指数(IdxGOV)と日銀の金融経済月報から得られた指数(IdxBOJ)は,ともに投資指標として良く知られた日銀短観(TAN D.I.,四半期ごと)や景気ウォッチャー指数(WAT D.I.)と非常に強い相関を示した.日銀短観と景気ウォッチャー指数がともに大規模なアンケート調査から得られていることを考えると,非常に低コストで算出可能な本指数の意義はそれだけで大きいと考えられる.さらに,投資指標としての活用可能性を探る上では重要となる日経平均株価(N225)との相関係数は,本研究の手法で算出した指数(IdxBOJ)が最も高く,日銀短観や景気ウォッチャー指数を上回る株価との連動性を示した.この結果は本研究のようにテキストデータを指数化することで,実際に投資情報として活用できる可能性があることを示唆している.
Table 5 Correlation coefficients between indices.
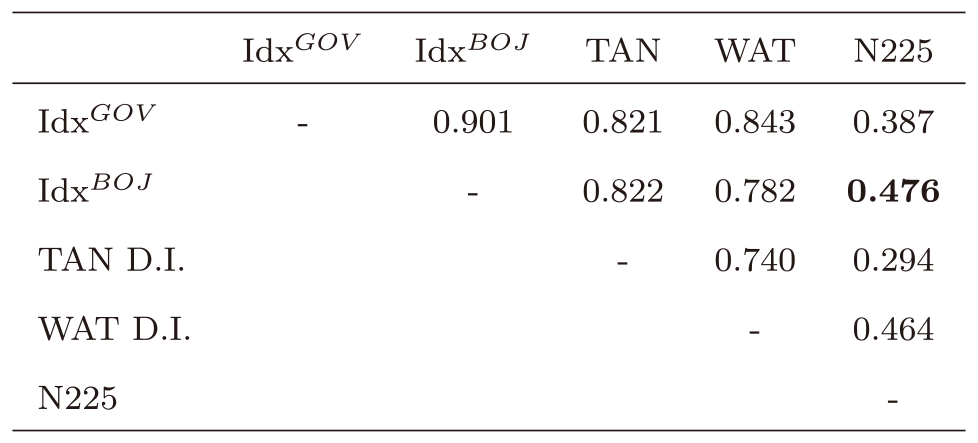
Table 6 T-values of correlation coefficients between indices.
4.3 実務への応用
本稿の元となった研究[20]が2016年に発表されて以降,本研究で開発された景気ウォッチャー調査を学習データとして学習したモデルでテキストの景気センチメントを定量化する手法は様々な社会実装が為されている.ここでは例として2つの応用を挙げる.
1つ目は“SNS×AI景況感指数”で,筆者らがプロジェクトリーダーとなって経済産業省と野村證券株式会社との共同で開発された.手法の詳細は[21]で公表されている.この指数は本研究と同様に景気ウォッチャー調査データから学習した景気センチメント推定モデルをTwitterに応用し,リアルタイムに日本全体の景気センチメントを指数化した.この研究では金融・経済テキストではなくTwitterという様々なトピックが含まれるテキストを指数化するために,まず大量のTweetの中から機械学習によって景気ウォッチャー調査データと類似したテキストのみを自動的に抽出した.これによって,本研究と同様の景気センチメント推定機の適用を可能にしている.この方法によって,金融・経済レポートだけでなく,一般のSNSや雑誌,新聞紙といった様々なテキストデータから景気センチメントを指数化できる可能性が示された.でき上がった指数は既存の統計指標である景気ウォッチャー調査 現状判断DIと高い相関を示しており,特に新型コロナパンデミックによって,景気センチメントが大きく下落,回復した時期が良く捉えられていることが報告されている[22].また本指数を経済産業省のwebサイトBigData-STATSで公表していた期間(2017-7-19~2018-3-16)では,サイト上で意見を募集しており,“(SNSの景況感は)チャレンジングで面白い”,“(景況感の)日次での把握はいろいろと用途がありそう”といった肯定的な意見が多い一方で,課題として“企業景況感や設備投資意欲、成長期待などにも応用できると、適切なマクロ政策運営にも役に立つ”,“SNSだとユーザ層が見えない部分もあってどういう方たちのどういう投稿で指標ができているのかという点が気になります”といったさらなる細分化を期待する声があった.
2つ目は,大和地域AI [37]で,本研究のモデルと類似の手法で学習したモデルで日銀のさくらレポートを評価し,四半期ごとの地域別景気センチメントを算出・公表している.たとえば,2021年4月21日発行の大和地域AI(地域愛)インデックスでは,“九州・沖縄”,“中国”,“四国”,“関東甲信越”,“東北”でインデックス改善がする一方で,新型コロナ感染拡大に伴う消費関連のインデックス悪化によって“近畿”,“東海”,“北陸”,“北海道”の4地域ではインデックスが悪化していることが報告されている.元となっている日銀の“さくらレポート”はテキストであるため,そのままでは地域間の横比較や長期の時系列比較が難しいが,指数化することによって地域ごとの特徴をより簡単に素早く比較することが可能となっている.
このように,本研究で開発された手法は様々な後続研究に活用されており,金融における景気センチメントの推定手法としてデファクトと言える発展を見せている.
5. 結論
本稿では景気ウォッチャー調査を学習データに用いたLSTMモデルから,景気センチメントを自動推定できる機械学習モデルを開発した.さらに,それを用いて政府や日銀の経済レポートを指数化し,その特徴を調べた.開発したLSTMモデルによって95%近い正答率で景気ウォッチャー調査の文章のセンチメントを推定することが可能であり,これはTF-IDFと比べて約7ポイント高い.得られたモデルを用いることで,景気ウォッチャー調査以外の景気に関する文章に対しても,景気センチメントの推定を行うことができる.1つの応用例として,日本政府が発行する“月例経済報告”と日銀が発行する“金融経済月報”の景気センチメントを算出した.得られた指数は景気の山,谷を反映した動きを示しており,日経平均株価との相関は日銀版で0.476(t値=7.9)であった.この日経平均との相関係数は,投資指標として一般によく用いられる日銀短観や景気ウォッチャー指数と比較しても高く,投資情報として活用できる可能性がある.また,日銀短観や景気ウォッチャー指数が大規模なアンケート調査によって得られていることを考えると,コストの観点からも有用である.
本稿の手法は様々なテキストデータに応用可能であり,これまで投資家の時間,知識,言語等の制約から十分な活用が難しかった,膨大なテキストデータを投資情報として活用できる可能性がある.実際,本稿の手法を初めて発表して以降,同様の手法を用いてTwitterや日銀さくらレポートへの応用が為されており,それぞれ即時性の向上や地域経済の把握といった面で発展がみられる.
今後の展望として,まずセンチメントモデルの改善が挙げられる.近年ではセンチメント判定のタスクにおいてBERTやTransformerベースのモデルが有効であることが報告されており,単語埋め込み表現にBERTを用いたり,LSTMではなくTransformerベースのモデルを用いることでセンチメント予測精度の向上とレポート景況感指数の改善が期待される.また,得られた指数による株価や経済指標の予測も今後の課題である.これによって投資や政策決定などへの活用がさらに進んでいくと期待される.さらに,Twitterへの応用事例から,SNS上の商品やレストランへの感想を指数化するといった応用も考えられる.その場合は本稿で用いた景気ウォッチャー調査データの代わりにE-Commerceサイトやグルメサイトのレビューの文章と評価点数を学習データに用いることが考えられる.
参考文献
- [1] 日本IR協議会:第6回個人投資家の投資意識とIRニーズに関するアンケート,〈https://www.meti.go.jp/committee/kenkyukai/sansei/kigyo_johokaiji/pdf/007_09_01.pdf〉 (2010).
- [2] Kearney, C. and Liu, S.: Textual sentiment in finance: A survey of methods and models, International Review of Financial Analysis, Vol.33, pp.171–185 (2014).
- [3] Tetlock, P. C., Saar-Tsechansky, M. and Macskassy, S.: More than words: Quantifying language to measure firms' fundamentals, The journal of finance, Vol.63, No.3, pp.1437–1467 (2008).
- [4] Heston, L., S. and Sinha, N. R.: News versus Sentiment: Comparing Textual Processing Approaches for Predicting Stock Returns, Robert H. Smith School Research Paper (2014).
- [5] 石島 博,數見拓朗,前田 章:日次データを用いた市場センチメント・インデックスの構築と株価説明力の分析,第11回人工知能学会金融情報研究会資料(2013).
- [6] 迫村光秋,和泉 潔:Twitterテキストマイニングによる経済動向分析,第9回人工知能学会ファイナンスにおける人工知能応用研究会(2013).
- [7] 岡崎陽介,敦賀智裕:ビッグデータを用いた経済・物価分析について,日本銀行レポート・調査論文(2015).
- [8] Antweiler, W. and Frank, M. Z.: Is all that talk just noise? The information content of internet stock message boards, The Journal of finance, Vol.59, No.3, pp.1259–1294 (2004).
- [9] Huang, A., Zang, A. and Zheng, R.: Large Sample Evidence on the Informativeness of Text in Analyst Reports, Unpublished working paper (2012).
- [10] Das, S. R. and Chen, M. Y.: Yahoo! for Amazon: Sentiment extraction from small talk on the web, Management science, Vol.53, No.9, pp.1375–1388 (2007).
- [11] Li, F.: The information content of forward-looking statements in corporate filings―A naïve Bayesian machine learning approach,Journal of Accounting Research, Vol.48, No.5, pp.1049–1102 (2010).
- [12] 前川浩基,中原孝信,岡田克彦,羽室行信:大規模ニュース記事からの極性付き評価表現の抽出と株価収益率の予測,オペレーションズ・リサーチ:経営の科学,Vol.58, No.5, pp.281–288 (2013).
- [13] Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural computation, Vol.9, No.8, pp.1735–1780 (1997).
- [14] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. and Polosukhin, I.: Attention is all you need, Advances in neural information processing systems, pp.5998–6008 (2017).
- [15] Devlin, J., Chang, M.-W., Lee, K. and Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, Association for Computational Linguistics, pp.4171–4186 (online), DOI: 10.18653/v1/N19-1423 (2019).
- [16] 西 良浩,菅 愛子,高橋大志:ニュースおよび高頻度データを用いたディープラーニングによる株式変動の分析―BERTによるニュース評価― (2019).
- [17] 青嶋智久,中川 慧:日本語BERTモデルを用いた経済テキストデータのセンチメント分析,人工知能学会全国大会論文集,Vol.JSAI2019, pp.4Rin127–4Rin127 (2019).
- [18] Xing, F., Malandri, L., Zhang, Y. and Cambria, E.: Financial Sentiment Analysis: An Investigation into Common Mistakes and Silver Bullets, Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), International Committee on Computational Linguistics, pp.978–987 (online), DOI: 10.18653/v1/2020.coling-main.85 (2020).
- [19] 内閣府:景気ウォッチャー調査,〈http://www5.cao.go.jp/keizai3/watcher/watcher_menu.html〉.
- [20] 山本裕樹,松尾 豊:景気ウォッチャー調査を学習データに用いた金融レポートの指数化,人工知能学会全国大会論文集,Vol.JSAI2016, pp.3L3OS16a2–3L3OS16a2 (2016).
- [21] 饗場行洋,山本裕樹:データサイエンスと新しい金融工学,財界観測,Vol.2018年春号(2018).
- [22] 小西葉子:POSでみるコロナ禍の購買動向:緊急事態宣言解除後編,〈https://www.rieti.go.jp/jp/columns/a01_0606.html〉 (2020).
- [23] StockTwits: 〈https://stocktwits.com/〉.
- [24] Yahoo!ファイナンス掲示板:〈https://finance.yahoo.co.jp/cm〉.
- [25] Bollen, J., Mao, H. and Zeng, X.: Twitter mood predicts the stock market, Journal of Computational Science, Vol.2, No.1, pp.1–8 (online), DOI: https://doi.org/10.1016/j.jocs.2010.12.007 (2011).
- [26] Antenucci, D., Cafarella, M., Levenstein, M., Ré, C. and Shapiro, M. D.: Using social media to measure labor market ows, Technical report, National Bureau of Economic Research (2014).
- [27] 諏訪部貴嗣:データ革命と株式運用戦略,証券アナリストジャーナル(2015).
- [28] Hong, J. and Fang, M.: Sentiment Analysis with Deeply Learned Distributed Representations of Variable Length Texts, stanford.edu (2015).
- [29] Tai, K. S., Socher, R. and Manning, C. D.: Improved semantic representations from tree-structured long short-term memory networks, arXiv preprint arXiv:1503.00075 (2015).
- [30] Kim, Y.: Convolutional Neural Networks for Sentence Classification, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, Association for Computational Linguistics, pp.1746–1751 (online), DOI: 10.3115/v1/D14-1181 (2014).
- [31] Chen, K. Y., Liu, S. H., Chen, B., Wang, H. M., Jan, E. E., Hsu, W. L. and Chen, H. H.: Extractive Broadcast News Summarization Leveraging Recurrent Neural Network Language Modeling Techniques, IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol.23, pp.1322–1334 (2015).
- [32] 五島圭一,高橋大志,山田哲也:自然言語処理による景況感ニュース指数の構築とボラティリティ予測への応用,金融研究,Vol.38, No.3, pp.1–41(オンライン),入手先〈https://ci.nii.ac.jp/naid/40021979430/en/〉 (2019).
- [33] Gers, F. A., Schmidhuber, J. and Cummins, F.: Learning to forget: Continual prediction with LSTM, Neural computation, Vol.12, No.10, pp.2451–2471 (2000).
- [34] KUDO, T.: MeCab: Yet Another Partof-Speech and Morphological Analyzer, http://mecab.sourceforge.net/, (online), available from 〈https://ci.nii.ac.jp/naid/10019716933/en/〉 (2005).
- [35] Schuster, M. and Paliwal, K.: Bidirectional recurrent neural networks, IEEE Transactions on Signal Processing, Vol.45, No.11, pp.2673–2681 (online), DOI: 10.1109/78.650093 (1997).
- [36] Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
- [37] 大和総研:大和地域AI(地域愛)インデックス,〈https://www.dir.co.jp/report/research/policy-analysis/regionalecnmy/regionalindex/index.html〉 (2017).

山本 裕樹yuhki.yamamoto@aiq-index.com
2004年京都大学理学部卒業.2006年同大学大学院修士課程修了.同年野村證券株式会社入社.金融・経済分野の研究開発に従事.証券アナリストジャーナル賞(2010年度).

落合 圭一
2008年千葉大学大学院博士前期課程修了.同年株式会社NTTドコモ入社.2017年東京大学大学院工学系研究科博士後期課程修了.2020年8月より東京大学特任助教.博士(工学).SNS,位置情報,ヘルスケアデータやスマートフォンログ解析,FinTech分野の研究開発に従事.ICWSM 2020 Best Paper Honorable Mentions受賞.ACM,日本データベース学会各会員.

鈴木 雅大
2013年北海道大学工学部卒業.2015年同大学大学院修士課程修了.2018年東京大学工学系研究科博士課程修了.博士(工学).2020年まで東京大学大学院工学系研究科技術経営戦略学専攻 特任研究員.同年より同大学特任助教.人工知能,深層学習の研究に従事.

松尾 豊
1997年東京大学工学部卒業.2002年同大学大学院博士課程修了.博士(工学).産業技術総合研究所,スタンフォード大学を経て,2007年より,東京大学大学院工学系研究科技術経営戦略学専攻 准教授.2019年より同大学大学院人工物工学研究センター/技術経営戦略学専攻 教授.2014年より2018年まで人工知能学会倫理委員長.2017年より日本ディープラーニング協会理事長.人工知能学会論文賞,情報処理学会長尾真記念特別賞,ドコモモバイルサイエンス賞など受賞.専門は,人工知能,深層学習,Web工学.
再受付日 2021年9月30日
採録日 2021年11月1日
会員登録・お問い合わせはこちら
会員種別ごとに入会方法やサービスが異なりますので、該当する会員項目を参照してください。