レガシーシステム移行時の性能劣化を改善するリファクタリング支援手法の提案
Proposal of a Refactoring Support Method to Improve Performance Degradation after Legacy System Migration
1. はじめに
業務上は重要だが保守の継続が困難なメインフレーム上の基幹システム(以降はレガシーシステムと呼ぶ)がいまだに多数存在している[1], [2].レガシーシステムもビジネス変化に対応するためには保守し続けることが必要であり,そのために新しいプログラミング言語や実行環境への移行といったシステム再構築のための活動が行われる[3].
レガシーシステムを新しいプログラミング言語に移行する際に,メインフレームとサーバのハードウェアアーキテクチャの違いなどから,実行時性能の劣化がしばしば起こる[4], [5].
実行時性能を改善する方法として,移行後のハードウェアスペックの増強(スケールアップ)やハードウェア台数の増強(スケールアウト)がある.スケールアップはハードウェアの調達コストやランニングコストの増大につながることと,増強できるスペックにも限界があるため,スケールアウトを選択することが多い.しかしスケールアウトはプログラム自体が並列実行に適している必要がある.
レガシーシステムの移行において単純なスケールアウトで解決できない性能劣化が起こることがある.レガシーシステムでは複数のプログラムを並列に実行することができるため,それをそのまま移行することで移行後システムでも複数プログラムの並列実行ができ,このような部分に関してはスケールアウトで性能改善を行うことができる.一方で,単一のプログラム内の処理の中身までを単純に並列実行することはできない.たとえば,データベースやファイルから取得したひとまとまりのデータを一括して処理するバッチ処理と呼ばれる処理方式では,1つのプログラム内で大量のデータを処理するが,各データについての処理を単純に並列実行することができない.単一のプログラムにおいて実行時間が非常に長くかかる場合,そのプログラムがボトルネックとなり,複数プログラムの並列実行では全体の実行時間を短くできなくなる.
単一のプログラムの性能劣化を改善するためには,そのプログラム内の処理の中身を並列実行できるようにプログラム自体を書き換える必要があるが,この書き換えは単純ではなく工数がかかる.
本稿では,レガシーシステムを新しいプログラミング言語に移行した際の性能劣化(特に単一プログラムによる性能劣化)を解決するため,プログラム内の処理を並列実行可能な形に書き換える作業を支援する手法について提案する.本手法では,レガシーシステムのプログラムの中からパターンマッチによって並列実行可能な処理を抜粋し,書き換え方法を示す.書き換え作業者はその内容を基に抜粋された処理を並列実行可能なプログラムに書き換える.
レガシーシステムのプログラムの中から並列実行可能な処理を抜粋する基本的なアイディアについては,先行研究[6]において発表しており,本稿ではその手法の詳細と評価実験を主に述べる.
評価実験として,2つの実際のレガシーシステムのプログラム集合に対して提案手法を適用した.書き換え前後のプログラムに同一の入力データを与えることで振る舞いを保った書き換えができていることを確認するとともに,書き換え前後のプログラムの実行時間の評価を行うことで,提案手法の有効性を確認した.
以降,2章では移行に伴う性能劣化問題の詳細とその解決のために行われる一般的な手法について紹介し,3章で提案手法について述べる.4章で評価実験の方法と結果を説明し,5章で実験結果について考察する.6章では関連研究につて紹介し,7章でまとめと今後の課題を述べる.
2. 背景
2.1 レガシーシステムにおけるバッチ処理プログラム
基幹システムでは,データベースやファイルから取得したひとまとまりのデータを一括して処理するバッチ処理と呼ばれる処理方式が数多く存在する.レガシーシステムにおけるバッチ処理の入出力結果の例を図1に,そのバッチ処理プログラムの例を図2に示す.この処理は「入力の売上データの中から数量が100以上のレコードだけを抽出し,数量が400以上のレコードの場合は「大量flg」にTrueを,そうでない場合はFalseを設定した結果を出力する」処理であり,このプログラムでは「売上データから1レコードずつ読み込み,読み込んだレコードの『数量』の値が100以上なら,その内容を抽出結果として出力する」ことによって実現している.
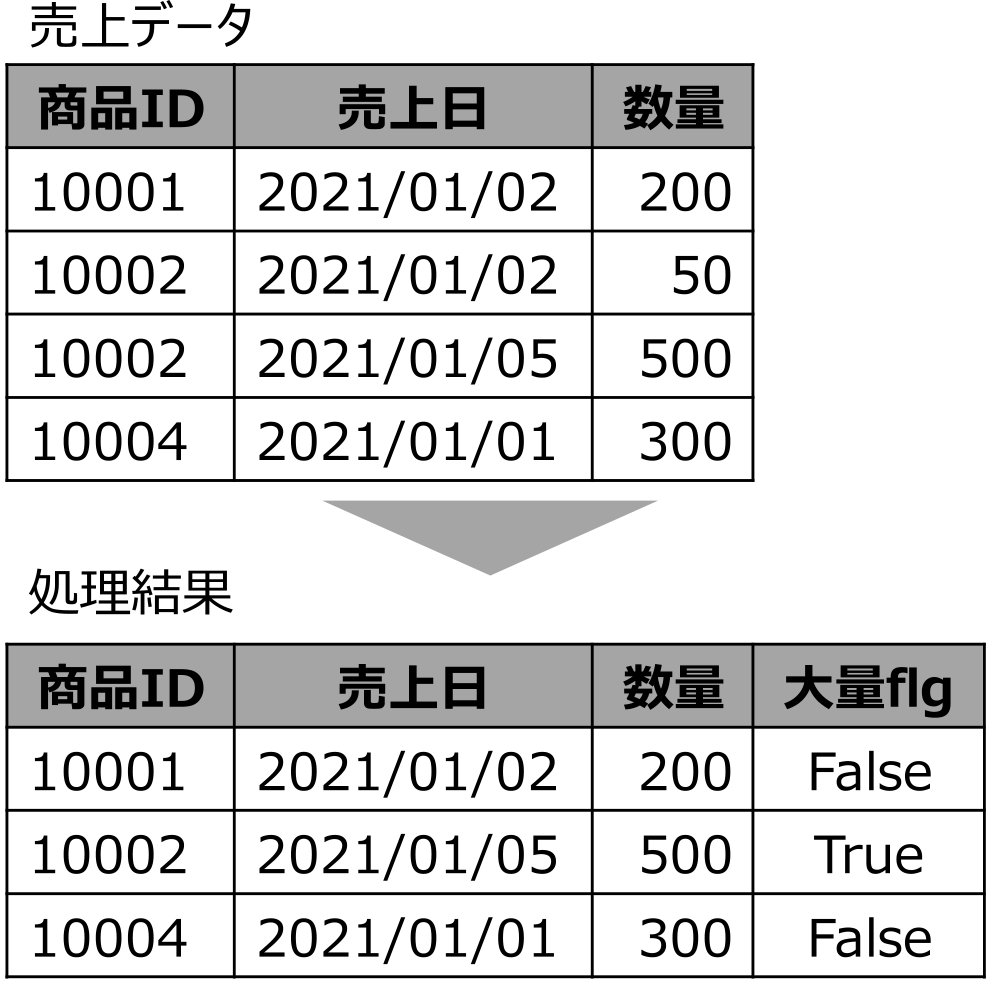
Fig. 1 Example of input/output for batch processing (Filter).

Fig. 2 Example of a batch processing program (Filter).
レガシーシステムのバッチ処理プログラムにおいて「ループ内でファイルを1レコード分読み込み,そのレコードに対する処理を行い,結果を出力する」といった実装は一般的である.このようなループを使った手続き的な実装では,レコード数だけ繰り返される各レコードに対する処理は直列に処理されることとなる.またすべてのレコードの処理を完了させるためには,各レコードの処理にかかった時間の総和分だけの時間が必要となる.
このような各レコードを直列に処理するプログラムには潜在的な性能問題がある.メインフレームはオープン系サーバに比べて処理性能が高く,各レコードの処理が非常に高速に行われるため,各レコードの処理を直列処理してもその総和の時間も小さく,性能問題として顕在化しない.一方でこういったプログラムをメインフレームに比べて相対的に処理性能が劣るオープン系サーバで実行すると,各レコードの処理で時間がかかり,その総和の時間も大きくなるため性能問題として顕在化する.このような性能問題は,メインフレーム上で動くレガシーシステムのプログラムをそのままオープン系サーバで実行できるようにするリホストと呼ばれる再構築や,レガシーシステムのプログラムを機械的に別の言語に書き換えてオープン系サーバで実行するリライトと呼ばれる再構築を行った際に起こる[4], [5], [7].
性能問題が起こったときに一般的に行われる性能改善方法として,処理の並列化がある.各レコードの処理を別個に並列実行することで,並列数に応じて処理にかかる時間を短くすることができる.
2.2 バッチフレームワーク
バッチ処理プログラムの並列化を簡易に行える方法として,バッチフレームワークを利用することが挙げられる.バッチフレームワークが備えるべき仕様はJSR-352 [8]で提案されており,その実装としてSpringBatch*1やJBeret*2などがある.バッチフレームワークはバッチ処理に必要な基本的な機能や並列実行のための仕組みを有しており,バッチフレームワークの利用者は実現したいバッチ処理プログラム固有の処理ロジックだけを実装することで並列実行可能なバッチ処理プログラムを実現することができる.
代表的なバッチフレームワークであるSpringBatchでは,以下の3つの処理について利用者が個別に実装することでバッチ処理プログラムを実現することができる.
- ・Reader:加工対象のデータを読み込む処理
- ・Processor:読み込まれたデータ1レコード分を加工する処理
- ・Writer:加工後のデータを書き出す処理
多くの場合,ReaderやWriterはSQLで記述し,ProcessorはJavaなどの手続き型プログラミング言語で記述する.
リライトにおいて性能問題が顕在化した場合,このようなバッチフレームワークを利用し,既存の直列に処理するバッチ処理プログラムをReader/Processor/Writerの各要素に分割して実装しなおすことで,並列化実装を実現し,性能問題を解決する.図3にレガシーシステムプログラムの移行からバッチフレームワークの利用までの一連の流れを示す.

Fig. 3 Flow from migration of legacy system programs to use of a batch framework.
図1を実現するバッチフレームワークでの並列実装の例を図4に示す.Readerでは加工対象のデータを読み込む処理として「売上データから数量が100以上のデータだけを抽出する」ことを意味するSQLのSELECT文を記述している.Processorでは読み込まれたデータ1レコード分を加工する処理を記述する.今回の例では入力の「数量」が400以上のレコードの場合は「大量flg」に「True」を,そうでない場合は「False」を設定する処理を記述している.Writerでは加工後のデータを書き出す処理として「Processorで加工後の売上データを抽出結果テーブルに書き込む」ことを意味するSQLのINSERT文を記述している.バッチフレームワークを用いてこのように実装すると,Readerでデータが読み込まれ,Processor部分が並列実行され,Writerでその結果が出力されるバッチ処理プログラムを実現することができる.
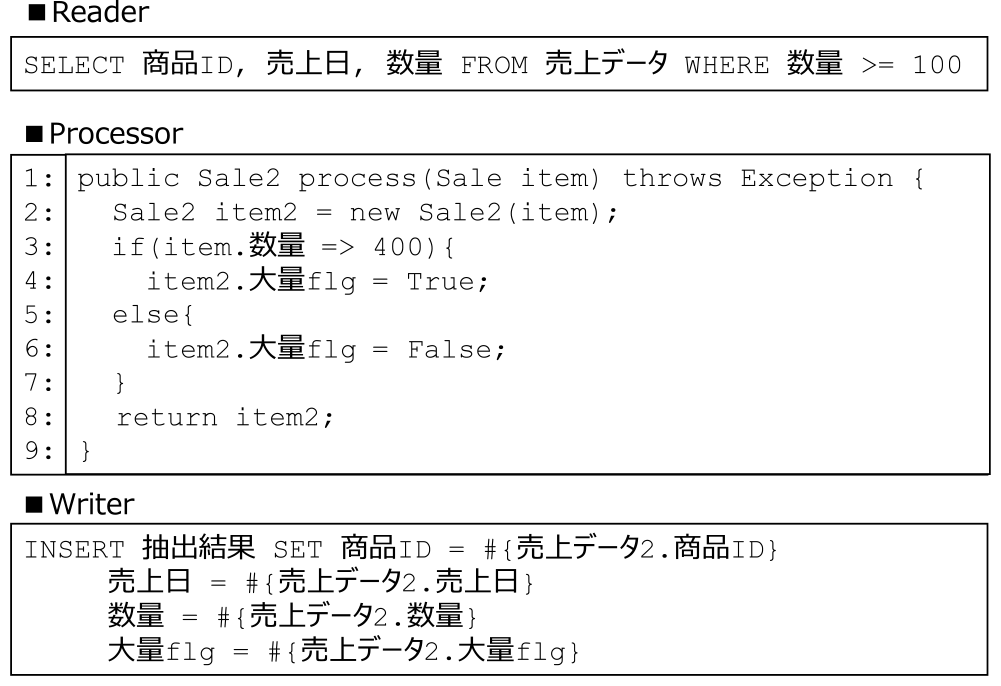
Fig. 4 Example of implementation using a batch framework (Filter).
2.3 バッチフレームワークへの変換
このように既存の直列処理のプログラムをバッチフレームワークを使った並列化実装に書き換えること(以降はバッチ処理プログラムのリファクタリングと呼ぶ)はバッチ処理プログラムの性能問題解決に有用なものの,実際にリファクタリングを行うことは容易ではない.容易ではない理由として処理の混在の問題が挙げられる.既存の直列処理のプログラムではバッチフレームワークのReader/Processor/Writerに相当する処理が混在して書かれており,既存のプログラムのどこがそれぞれと対応する部分なのか,対応する部分をバッチフレームワークでどのように記述すべきかを判断することが難しいためである.
図2のようなCOBOLのバッチ処理プログラムでは,バッチフレームワークのReaderに記述する「数量が100以上」というロジックも,Processorに記述する「数量が400以上」というロジックも1つのプログラム内に混在して記述されており,それぞれがバッチフレームのどの要素と対応しているのかはプログラムの詳細を理解しないと判断することができない.実際のレガシーシステムのバッチ処理プログラムにおいては1つのCOBOLプログラムが数千行から数万行に及ぶこともあり,その内容を理解しながらバッチ処理プログラムのリファクタリングを行うことは非常に困難である.
3. 提案手法
本研究では,性能改善を目的としたレガシーシステムのバッチ処理プログラムからバッチフレームワークの実装へのリファクタリングを支援する手法を提案する.提案手法ではレガシーシステムのバッチ処理プログラムのリファクタリングを以下のステップで実施する.
- (1)Reader部分の抽出
- (2)Reader部分のSQLへの変換
- (3)Processorの書き換え
- (4)Writer部分のSQLへの変換
以降の節ではまずシンプルなバッチ処理プログラムに対する各ステップの詳細を紹介し,3.5節では発展的な内容として実際のレガシーシステムに存在する複雑なバッチ処理プログラムに対する考え方を述べる.
3.1 Reader部分の抽出
まず機械変換されたレガシーシステムのバッチ処理プログラムのソースコードからReaderに該当する部分を抽出する.
Readerは読み込むテーブルの全レコードの中からProcessorやWriterが処理する対象レコードのみを抽出する処理である.レガシーシステムのバッチ処理プログラムの実装では,ループを使って1行ずつ読み込み,そのレコードを出力するかどうかを分岐文を使って手続き的に記述する.このため,各レコードを処理するループ中のREAD/WRITEに相当する文と,そのREAD/WRITEに相当する文の実行有無を決定する制御構造に着目することでReaderに該当する部分を抽出できる.
たとえば図2の例では,10行目のWRITE文によって処理されたレコードが出力されるが,このWRITE文は3行目のIF文によって実行されるかどうかが決まる.このため,3行目のIF文はバッチフレームワークの実装のReaderに関係するロジックであることが分かる.一方で,5行目のIF文はWRITE文の実行有無には関係しておらず,Readerに関係するロジックではない.
提案手法では以下の手順でReader部分に該当するロジックを抽出する.
- ・プログラム呼び出し文を呼び出し先の内容でインライン展開する
- ・各レコードを処理するループに含まれない文を削除する
- ・READ/WRITE文および,そのREAD/WRITE文の実行有無を決定する制御構造以外の文を削除する
- ・分岐文のネストは条件式をANDで繋げて1つの分岐文にまとめる
図5に図2のReader部分に該当するロジックを示す.

Fig. 5 Logic corresponding to the Reader portion of Fig. 2.
3.2 Reader部分のSQLへの変換
次に抽出したReader部分に該当するロジックをSQLに変換する.
一般的にはReader部分に該当するロジックは無数にあり,それに対応するSQLも無数にある.しかし我々の予備調査の結果,実システムに存在する多くのバッチ処理プログラムのReader部分に該当するロジックは少数のパターンでカバーできることが分かったため,Reader部分に該当するロジックのパターンごとに対応するSQLをあらかじめ用意しておき,そのSQLに変換する.
表1に我々が見つけたReader部分に該当するロジックのパターン(以降,Loop Idiomと呼ぶ)の一覧を示す.
Table 1 List of Loop Idioms.
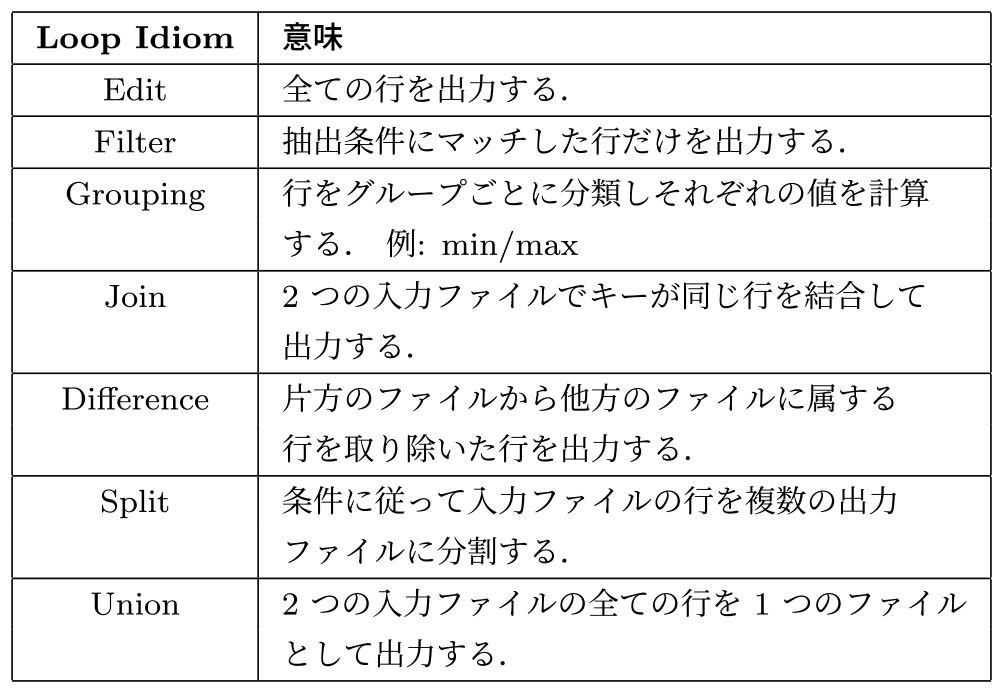
図5はFilterのLoop Idiomの例だが,別の例として図6にJoinのLoop Idiomの例を示す.この例では売上データに対して,売上データの商品IDと同じIDの商品データの情報を結合して出力する.

Fig. 6 Loop Idiom (Join).
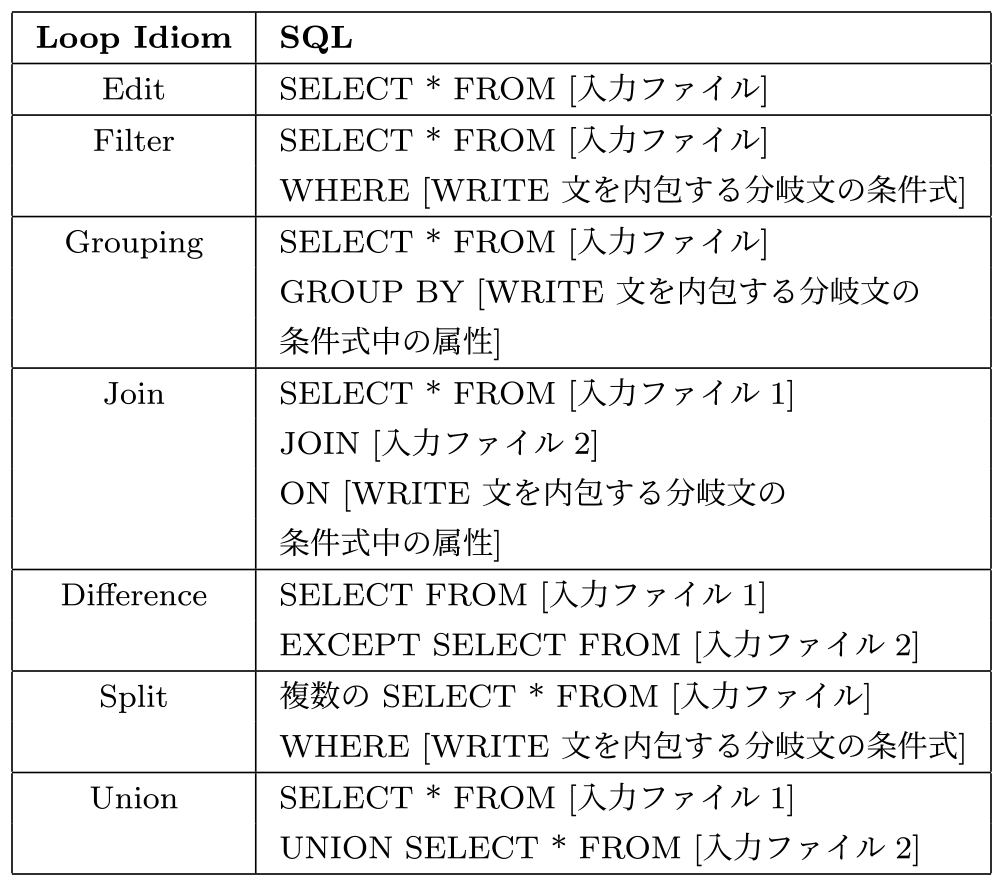
また各Loop Idiomと対応するSQLへの変換方法は表2のとおりである.
Table 2 Loop Idioms and corresponding SQL.
また実際のソースコードでは,条件式に中間変数が使われている場合があるが,その場合は中間変数についてデータフロー解析を行い,関連する文を抽出し,その内容を基にSQLに変換する.
3.3 Processorの書き換え
次にProcessor部分の書き換えを行う.本提案手法のステップ(1)「Reader部分の抽出」ではREAD/WRITE文の実行有無を決定する制御構造に着目したが,このステップでは逆にその際に無視した分岐文や代入文に着目する.たとえば図2の例では,4行目のMOVE文(代入文)や5行目から9行目までのIFブロックは処理対象となった行の編集処理であり,Processorに記述する内容である.
基本的には,ステップ(1)で無視した分岐文や代入文をそのままProcessorに記述するだけだが,ステップ(2)「Reader部分のSQLへの変換」で抽出したLoop IdiomがGroupingだった場合は以下のようなReader部への記述を追加する.
- (I)単純な代入文の場合,Readerでその変数の最終レコードの値を取得するSQLを書く
- (II)変数に1を加算している場合(例:num = num + 1),ReaderのSQLで属性名にCOUNTを用いる
- (III)変数に別の変数の値を加算している場合(例:total = total + num),ReaderのSQLで属性名にSUMを用いる
- (IV)前回の値よりも大きい(もしくは小さい)場合のみ値を更新している場合(例:if(prev > now) prev = now),ReaderのSQLで属性名にMAX(もしくはMIN)を用いる
3.4 Writer部分のSQLへの変換
最後にWriter部分をSQLに変換する.WRITE文で出力されるファイルに相当するテーブルへのINSERT文を記述する.
3.5 Loop Idiomの組み合わせ
本章では1つのバッチ処理プログラムにLoop Idiomが1つだけ含まれる場合について説明したが,実際のレガシーシステムでは1つのバッチ処理プログラムに複数のLoop Idiomが含まれることも多い.このような場合,表1で示したLoop Idiomの組み合わせとしてみなすことで,Reader部分のSQLに変換することができる.
たとえば,1つのバッチ処理プログラム中にFilterとJoinの両方が含まれていた場合,Filterに由来するWHERE句と,Joinに由来するJOIN ON句の両方を持つSQLとする.ただし,本プロジェクトでは予算の関係で変換は行わなかった.
4. 評価実験
実際のレガシーシステムのシステム再構築プロジェクトの一環として,レガシーシステムのプログラムに対して,提案手法を用いてLoop Idiomの抽出と対応するリファクタリング方法の提示を行い,その結果に従って人手でリファクタリングを行った.また,それぞれの種類のLoop Idiomを含むプログラムを1つずつ選択し,手法の適用有無による工数および性能についての比較実験を行った.
4.1 実験方法
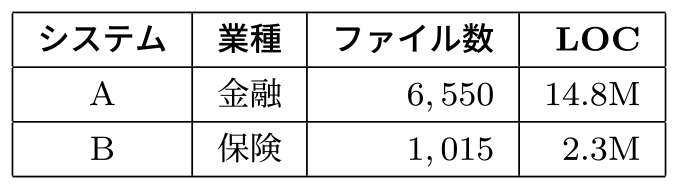
実験に用いたソースコードは,第一著者が所属する企業で実際に保守開発を行っているレガシーシステム2つのものである.各システムのプロフィールを表3に示す.
Table 3 Profile of the target legacy systems.
レガシーシステムのプログラムはすべてCOBOLで記述されていたが,実験を行う前に機械変換ツールを用いてJavaに変換しており,実験にはJavaに変換後のプログラムを利用している.
まずこれらのレガシーシステムのバッチ処理プログラムにどのようなLoop Idiomがどれだけあるのかを作成したツールを用いて調査する.
次にLoop Idiomを1つだけ含むプログラムについては,すべて人手でリファクタリングを行う.この際,リファクタリング実施者には,リファクタリング対象のプログラムにどのLoop Idiomが存在するのかという情報とともに,図7のようなSQLに書き直す際に必要な情報が,プログラムのどの文に対応するのかといった情報も与える.SQLに書き直す際に必要な情報としては,Editであれば編集内容,FilterであればWhere句となるWRITE文を内包する分岐文の条件式などである.実プロジェクトの予算および期間的な制約のため,Loop Idiomの組み合わせとなるプログラムに関しては,Loop Idiomの調査までは行うもののリファクタリングを行わない.
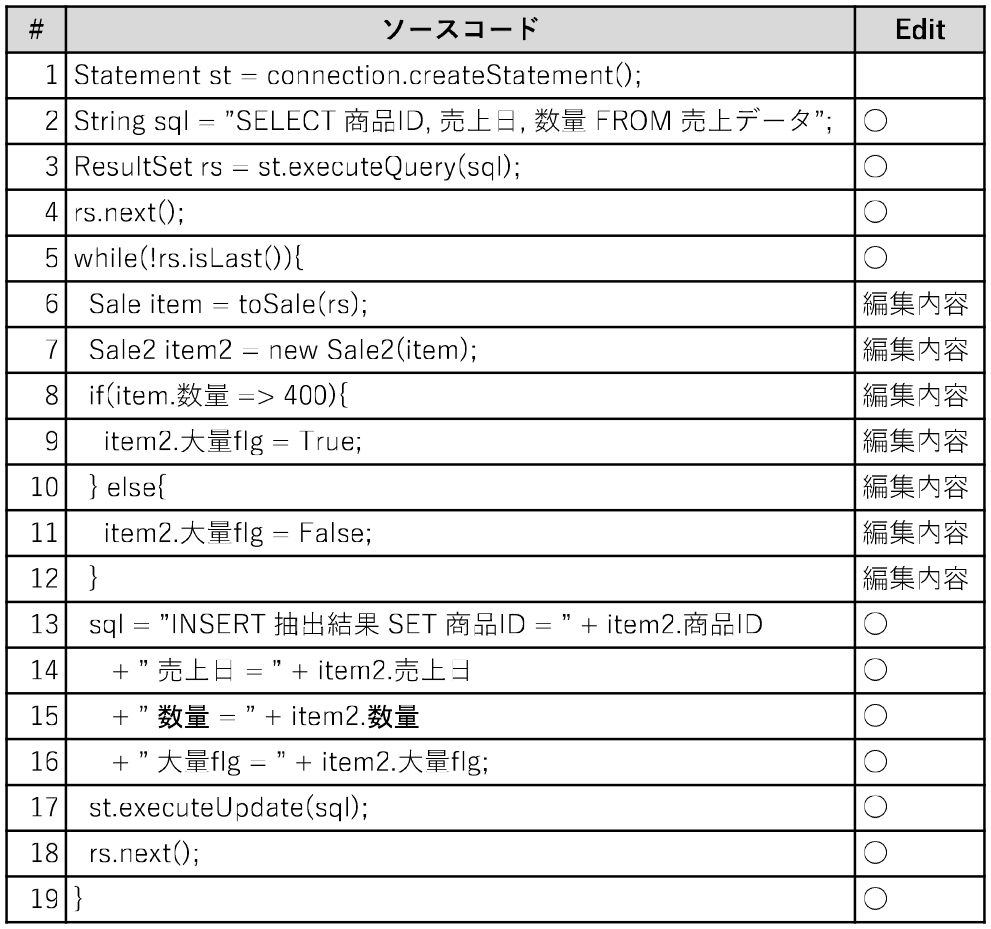
Fig. 7 Example of information to be presented to the refactoring implementers.
リファクタリング後には,リファクタリング前の振る舞いを保持できているかを確認するため,書き換え前後のプログラムに同一の入力データを与えて同じ出力がされるかを確認するテストを行う.実際のレガシーシステムの再構築プロジェクトでは,ここまで実施したものを運用する.
その後,実プロジェクトとは別に,手法の適用有無による工数および性能についての比較実験を行う.これらの比較実験では,各Loop Idiomを含むプログラムを1つずつランダムに選択し,そのプログラムだけを対象とする.
工数についての比較実験では,提案手法を用いてリファクタリング方法を示した場合と提案手法無しでリファクタリングを行う場合の工数を比較し,提案手法の工数削減効果について確認する.工数についてはリファクタリングによる書き換えの時間だけでなく,上述の振る舞いを保持できているかを確認するテストの時間も含む.実施者による影響を小さくするため,Loop Idiomごとに実施者への提案手法の有無の割り当てを入れ換えて実施した.たとえば,Loop IdiomがEditの際にリファクタリング実施者Aが提案手法有りで実施し,Bが提案手法無しで実施した場合,Loop IdiomがFilterの際にはAが提案手法無しで実施し,Bが提案手法有りで実施するといった割り当てを行った.
性能についての比較実験では,同一のデータを用いてリファクタリング前後のプログラムを実行し,リファクタリング前後で実行時性能が変化するか確認する.リファクタリング後の実行時性能については,並列度を1と8に変えて実行時間を計測することで並列度の違いによる実行時性能についても比較する.
使用したマシンのスペックとバッチフレームワークは以下のとおりである.
- ・CPU:Intel Core i5 1.4 GHz
- ・仮想CPUコア数:8
- ・Memory:16 GB
- ・OS:RedHat Enterprise Linux 7.5
- ・バッチフレームワーク:Spring Batch 4.3.3
- ・DBMS:MySQL 8.0.24
リファクタリング前後の両方で,DBに格納されている各テーブルの主キーとなるカラムにインデックスを付与した.それ以外のDBチューニングはリファクタリング前後ともに実施していない.
またプログラム実行時に必要な入力データは各プログラムが必要なデータ形式に合わせて作成したダミーデータを用いた.Edit/Filter/Grouping/Splitはそれぞれ124万レコードのデータ,Joinは124万レコードのデータと400レコードからなるデータ,Differenceは124万レコードのデータと123万レコードからなるデータ,Unionは124万レコードのデータと124万レコードからなるデータをそれぞれ用いた.
また今回はDBMSにMySQLを採用したため,EXCEPTを利用できなかった.このため,Differenceに対応するSQLではEXCEPTの代わりに「LEFT JOIN」と「IS NULL」を用いて書き換えを行った.
4.2 Loop Idiomの調査結果
レガシーシステム内に含まれるLoop Idiomの調査結果は表4のとおりである.「組み合わせ」は複数のLoop Idiomが1つのファイルに存在していたことを意味している.
Table 4 Loop Idiom survey results.
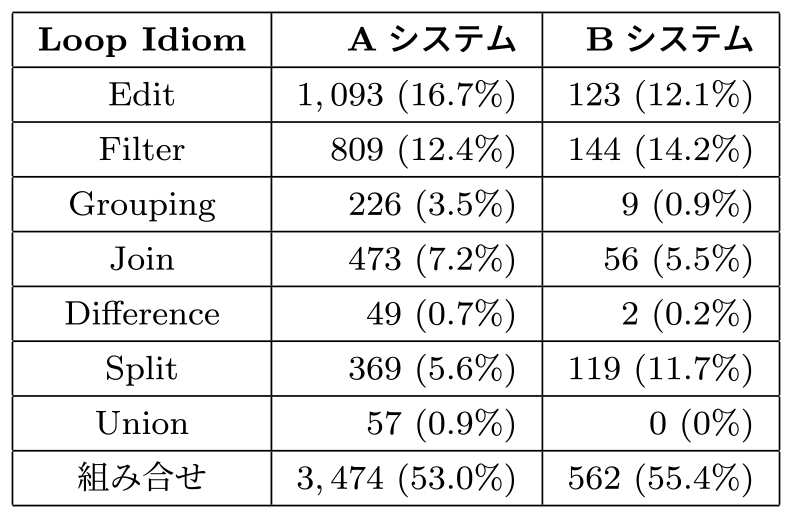
実験に用いた実システムにおいては,組み合わせでないLoop Idiomが半数近くを占めている.またLoop Idiomの種類によって出現数にばらつきがあることが分かり,どちらのシステムもEdit/Filter/Join/Splitの出現数が多く,Difference/Unionはほとんど出現しないことも分かった.また,すべてのプログラムは7種類のLoop Idiomまたはその組み合わせで表現できた.
実プロジェクトでは1つのLoop Idiomだけが含まれるプログラムのすべて3,529本について,リファクタリングおよびテストを行った.一方で,複数のLoop Idiomが含まれる4,036本のプログラムについてはリファクタリングを行っていない.
4.3 提案手法によるリファクタリング工数の差
提案手法の有無によるリファクタリング工数の違いは表5のとおりである.
Table 5 Difference in refactoring man-days with and without the proposed method.
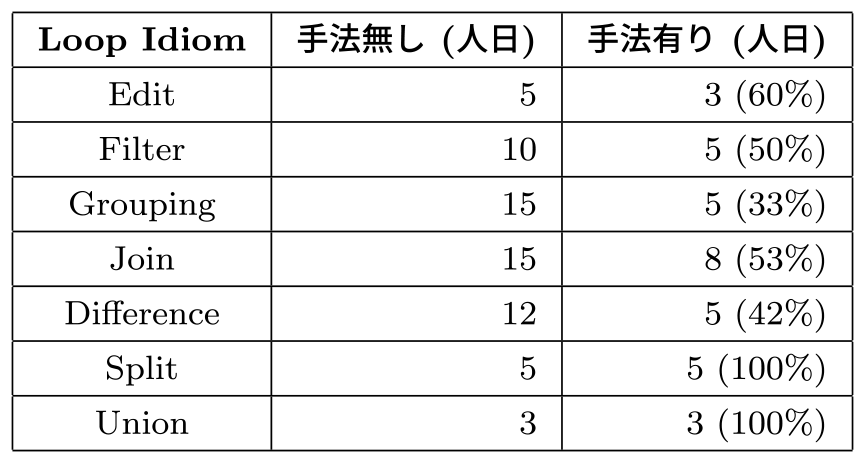
SplitやUnionでは提案手法の有無で工数の差は無いものの,それ以外のLoop Idiomにおいてはいずれも本提案手法による手法有りのほうが工数が小さくなっている.特にFilter/Grouping/Differenceについては工数が50%から66%程度まで削減されており,工数削減の効果が大きい.
4.4 リファクタリングによる性能改善結果
リファクタリングによる性能改善の結果は表6のとおりである.「実施前」はJavaへの機械変換がなされただけのプログラムの実行結果であり,「1並列」および「8並列」は提案手法を用いてリファクタリングを行ったプログラムの実行結果である.
Table 6 Performance improvement results.
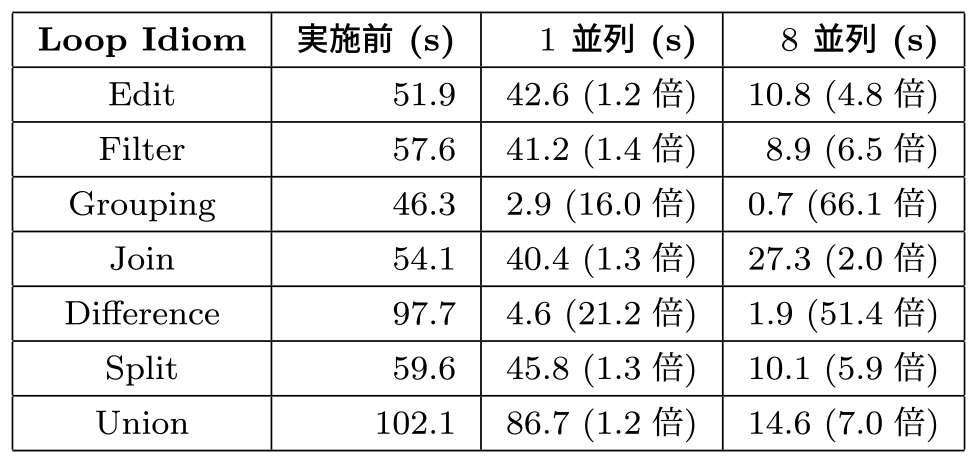
いずれのLoop Idiomにおいてもリファクタリング実施後のプログラムのほうがリファクタリング前よりも実行時性能が改善されることが確認された.またいずれも並列度を1から8に上げると実行時性能が改善されることから,並列実行が効果的に働いていることが分かる.
特にGroupingとDifferenceについては,他のLoop Idiomと比較して並列度1においても顕著に性能が改善されている.
5. 考察
Loop Idiomの出現数のばらつきや提案手法による工数,作業品質,性能への影響について,それぞれ考察を行った.
5.1 Loop Idiomの出現数
Loop Idiomの種類ごとに出現数にばらつきがあることについて,それぞれのシステムの保守を担当する有識者にヒアリングを行ったところ,「連続するバッチ処理では,その前半にJoinを行い,その後Edit/Filterといった処理を多数行い,最後に必要に応じてGroupingを行うといった業務が多いため,Join/Edit/Filter/Groupingが多いのは感覚と一致する」という回答を得た.いくつかのバッチ処理についてそのプログラム間の実行順を調査したところ,有識者の回答どおりの傾向があることを確認した.
5.2 提案手法による工数への影響
提案手法の有無による工数の差について,その理由をリファクタリング実施者にヒアリングを行ったところ,「本手法の適用の有無で工数が変わらなかったSplit/Unionは元々のプログラムの構造が単純で,プログラムの規模自体が大きくても構造把握自体は難しくなかった.一方で適用無しで工数が相対的に大きかったGrouping/Join/Differenceは,構造が難しく内容を把握するのに時間がかかった.またEdit/Filterは構造の把握自体は難しくないものの,条件分岐が多い場合に出力条件と編集条件を見分けることに工数がかかるため,機械的にその見分けをしてくれる本手法は工数削減に有効だった」という回答を得た.
5.3 提案手法による作業品質への影響
本手法の有無によるリファクタリングの作業品質についても確認したところ,提案手法の適用があった場合はリファクタリング時のバグの作り込みは1件だけであったが,提案手法の適用が無かった場合には8件のバグの作り込みがあったことが分かった.この差異についてリファクタリング実施者にヒアリングを行ったところ,「本手法の適用がある場合には抽出箇所などが明確になるため,作業内容が難しくなくバグを作り込みにくい.一方で適用無しの場合はどのようなReaderとしてどのようなSQLを選ぶべきかを考える必要があり,その選択ミスや,出力条件と編集条件の見極めの誤りなどバグを作りこむ要素が多い」という回答を得た.
5.4 提案手法による性能への影響
本手法の適用によりどのLoop Idiomにおいても性能が改善されたが,Loop Idiomの種類によって異なる3種類のボトルネックがそれぞれ改善されたためと考えられる.
1つ目はCPUがボトルネックとなるもので,複雑な編集や抽出条件を持つ場合のEditやFilterが該当する.図2の例は非常に簡単な抽出条件だが,実際のソースコードでは数千行に及ぶ条件式や計算ロジックを持っていることが多く,CPUがボトルネックになっている.このような場合は,バッチフレームワークによるProcessorの並列化が効果的となる.
2つ目のボトルネックとしてはI/Oネックが挙げられる.これはSplitやUnion,単純なEditやFilterが該当する.これらのLoop Idiomは処理が単純であり,CPU部分ではなくデータの入出力を行うI/Oがネックになる.このような場合は,バッチフレームワークによるチャンク化(複数件をまとめて入出力する方式)が性能改善に貢献する.
3つ目の改善ポイントしてはインデックスを用いた計算量の変更があり,GroupingやDifferenceが該当する.これらのLoop Idiomは,ReaderのSQLにおいてインデックスを張ったカラムについて集約計算や差集合を求める内容であり,MySQLの最適化により通常であればO(n)必要な計算も,インデックスを使用することでO(logn)となったためと考えられる.
6. 関連研究
Allamanisら[9]は,ソースコード内のループに着目してパターンマイニングを行う手法を提案している.この手法では変数の読み書きを対象にしているが提案手法はファイルの読み書きを対象にしている点で異なる.また,この手法では11プロジェクト,577 KLOCのソースコードに対して評価を行っているが,我々の提案手法は17.1 MLOCとより大規模なソースコードに適用しており,また実システムのプロジェクトとして実施した点も異なる.
提案手法と同様の問題を対象にしている研究として,Wiedermannら[10], [11]の研究がある.彼らによるとORM(Object-relational Mapping)を用いたシステムでも性能問題は起きており,その原因としてデータベースの内部で処理したほうが良いとも思われるFilterやJoinなどの操作をプログラマーが手続き型プログラミング言語で記述していることを指摘している.提案手法と同じく,こういったプログラムをSQLクエリに書き換えることで性能問題を解決しようとしている.Wiedermannらの手法では,提案手法におけるFilterやJoinに関しては書き換えることができるが,提案手法でカバーしているGroupingやSplit,Unionなど他のLoop Idiomに関しては書き換えることができない.また,手法の評価は900 LOCと小規模なソースコードに留まっている.
同様の問題を解決する別のアプローチとしてCheungら[12]は,基となるプログラムコードから後条件と不変条件を生成し,それらの条件を満たすSQLクエリを合成するという手法を提案している.これらの手法では,FilterやJoinだけでなく,Groupingについても書き換えることができるが,基となるプログラムはORMのようなテーブル構造を変換する操作だけである.一方で提案手法がターゲットにしているバッチ処理では,テーブル構造を変換する操作に加えて,データの値を編集する操作も1つのプログラムに混在して書かれている.データの値を編集する操作を後条件と不変条件だけで表現するのは不十分であり,Cheungらの手法でバッチ処理を合成することはできない.この手法は123 KLOCのソースコードに対して評価しているが,提案手法のほうがより大規模に適用している点も異なる.
7. おわりに
本稿では,レガシーシステムのプログラムが新しいプログラミング言語に移行されたときに起こる性能劣化を改善するリファクタリング手法について提案した.また,2つの企業のレガシーシステムのソースコードを人手で調査し,どのようなLoop Idiomがどれくらい存在するかを調査し,各Loop Idiomの種類について提案手法による支援を用いてリファクタリングを行った.
提案手法による支援を行うことでリファクタリングに必要な工数を最大66%削減でき,リファクタリング前後で実行時性能が最大62倍まで改善されることを示した.
本手法は実プロジェクトで採用されており,本手法による支援によってリファクタリングされたプログラムは実案件で運用されている.これらのことから本手法によるリファクタリング支援およびそのリファクタリングは有効であったと言える.
参考文献
- [1] Bennett, K.: Legacy systems: Coping with success, IEEE software, Vol.12, No.1, pp.19–23 (1995).
- [2] Khadka, R., Batlajery, B. V., Saeidi, A. M., Jansen, S. and Hage, J.: How do professionals perceive legacy systems and software modernization?, Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, pp.36–47 (2014).
- [3] Bisbal, J., Lawless, D., Wu, B. and Grimson, J.: Legacy information systems: Issues and directions, IEEE software, Vol.16, No.5, pp.103–111 (1999).
- [4] 独立行政法人情報処理推進機構:システム再構築を成功に導くユーザガイド第2版~ユーザとベンダで共有する再構築のリスクと対策~(2018).
- [5] 独立行政法人情報処理推進機構:デジタル変革に向けたITモダナイゼーション企画のポイント集~注意すべき7つの落とし穴とその対策~(2018).
- [6] Okada, J., Ishio, T., Sakata, Y. and Inoue, K.: Towards Classification of Loop Idioms Automatically Extracted from Legacy Systems, 2019 IEEE 13th International Workshop on Software Clones (IWSC), pp.34–35 (online), DOI: 0.1109/IWSC.2019.8665854 (2019).
- [7] Suganuma, T., Yasue, T., Onodera, T. and Nakatani, T.: Performance pitfalls in large-scale java applications translated from COBOL, Companion to the 23rd ACM SIGPLAN conference on Object-oriented programming systems languages and applications, Nashville, USA, pp.685–696 (2008).
- [8] Kurz, S.: Batch Applications for the Java Platform Version 1.0.
- [9] Allamanis, M., Barr, E. T., Bird, C., Devanbu, P., Marron, M. and Sutton, C.: Mining semantic loop idioms, IEEE Transactions on Software Engineering, Vol.44, No.7, pp.651–668 (2018).
- [10] Wiedermann, B. and Cook, W. R.: Extracting queries by static analysis of transparent persistence, Proceedings of the 34th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages, pp.199–210 (2007).
- [11] Wiedermann, B., Ibrahim, A. and Cook, W. R.: Interprocedural query extraction for transparent persistence, ACM Sigplan Notices, Vol.43, No.10, pp.19–36 (2008).
- [12] Cheung, A., Solar-Lezama, A. and Madden, S.: Optimizing database-backed applications with query synthesis, ACM SIGPLAN Notices, Vol.48, No.6, pp.3–14 (2013).
脚注
- *1 https://spring.io/projects/spring-batch
- *2 https://github.com/jberet/jsr352

岡田 譲二(正会員)joji.okada@nttdata.com
2008年名古屋大学大学院情報科学研究科博士前期課程修了.同年株式会社NTTデータ入社.プログラム解析技術の研究開発および現場適用に従事.

パルヴァテ アブヘイabhay.parvate@intellilink.co.jp
2012年インド・プネー大学物理学博士号を取得.2005年~2009年,プネー大学モデリングとシミュレーションセンター(CMS)で学科課程幹事.2009年~2011年インド・タタ基礎研究院(TIFR)と2011年~2013年インド・数学的科学院(IMSc)で博士研究員.2013年NTTデータ先端技術株式会社入社.入社後,主にレガシーシステム解析と改善の研究開発に従事.

石尾 隆(正会員)ishio@is.naist.jp
2003年大阪大学大学院基礎工学研究科博士前期課程修了.2006同大学大学院情報科学研究科博士後期課程修了.同年日本学術振興会特別研究員(PD).2007大阪大学大学院情報科学研究科助教授.2017奈良先端科学技術大学院大学情報科学研究科准教授.2018同大学先端科学研究科准教授.博士(情報科学).プログラム解析,プログラム理解に関する研究に従事.

坂田 祐司(正会員)yuji.sakata@nttdata.com
1996年東京大学大学院工学系研究科材料学科博士前期課程修了.同年NTTデータ通信株式会社(現,株式会社NTTデータ)入社.プログラム解析,システムモダナイゼーションに関する研究に従事.

井上 克郎(正会員)inoue@ist.osaka-u.ac.jp
1984年大阪大学大学院基礎工学研究科博士後期課程修了(工学博士).同年同大学基礎工学部情報工学科助手.1984年~1986年,ハワイ大学マノア校コンピュータサイエンス学科助教授.1991年大阪大学基礎工学部助教授.1995年同学部教授.2002年より大阪大学大学院情報科学研究科教授.ソフトウェア工学,特にコードクローンやコード検索などのプログラム分析や再利用技術の研究に従事.本会フェロー.
再受付日 2021年7月2日
採録日 2021年8月24日
会員登録・お問い合わせはこちら
会員種別ごとに入会方法やサービスが異なりますので、該当する会員項目を参照してください。