ソーシャル創薬プロジェクト
─人智(創薬知)と計算(IT創薬)の融合,創薬エコシステムの社会実装を目指して─
1.はじめに
物理化学シミュレーションや機械学習等,計算機による予測手法を活用して創薬の効率化を目指すIT創薬が脚光を浴びているが,薬を上市するに至るまでの現実的なボトルネックが実験による生データの取得とそれに必要な莫大な資金であることには今も変わりがない.創薬標的分子の同定,薬剤候補化合物の発見,化合物最適化,そして上市に至るまでの臨床試験プロセス,いずれをとっても過去よりハードルは上がってきている.従来の意味でドラッガブル(druggable ; 低分子化合物で介入可能)とされる創薬標的は枯渇傾向にあって新規標的に対する創薬の難易度は上昇している. また,人間に投与する薬としての確実な安全性を確認する試験の要求も厳格化が進んで,今や1剤を上市するために必要な資金は千億円単位にも上る.一方,開発化合物は臨床試験でドロップアウトする可能性と常に隣り合わせであり,新規合成化合物が上市にまで至る率は2~3万分の1[1]と,創薬は製薬企業にとって多大な負荷を伴う賭けである.
すなわち,予測技術による創薬の効率化が必須であることはさることながら,いずれにしろ莫大な開発資金は必要なので経済的に持続可能な形で創薬研究開発サイクルを回し続けることが肝要である.そこで著者らは,創薬を営む母地を万人に開放し,IT創薬のクラウドソーシングと研究開発資金のクラウドファンディングによって創薬エコシステムを社会実装するプロジェクト,ソーシャル創薬の実現を目指している.本稿では,IT創薬および人智に基づく創薬知も交えた創薬の実務的背景の概説とともに,クラウド(群衆)を創薬に巻き込むための我々の端緒的な試みについて紹介する.
2.IT創薬と創薬知
創薬プロセスの加速・効率化を目指して計算による薬の候補化合物選別技術(バーチャルスクリーニング ; VS)の研究が進んでいる.VSの手法は標的タンパク質の立体構造情報を活用する Structure-Based VS (SBVS) と既知化合物の活性情報を活用する Ligand-Based VS(LBVS)とに大別されるが,両者のハイブリッドや種々の機械学習手法の適用などさまざまな方法論が提案されており,今なお研究者がしのぎを削ってスクリーニング性能の改善を目指している(第3章).一方でメディシナルケミスト(新薬創製のための化合物設計・合成を担う医薬品化学者; 通称メドケム)等の創薬科学者の目利きのような,人手による要素も創薬プロセスにおいてはなくてはならないものであるが,情報科学との融合,VSの方法論への反映のための手段は,必ずしも整備されているとは言いがたい.
筆者らは,創薬において用いられる形式知に加え人間の認知能力に基づく暗黙知も含めた「創薬知」を定義し,人間がどのような視点を創薬に駆使するのかということの明文化を目指しつつ,人間と計算の融合(ヒューマンコンピュテーション),ひいては創薬とシチズン・サイエンス(科学者と一般市民が協同した研究活動)との連携の実現可能性について検討している(第4章).
3.バーチャルスクリーニング実践の概況
3.1 IT創薬コンテストにおける手法の内訳
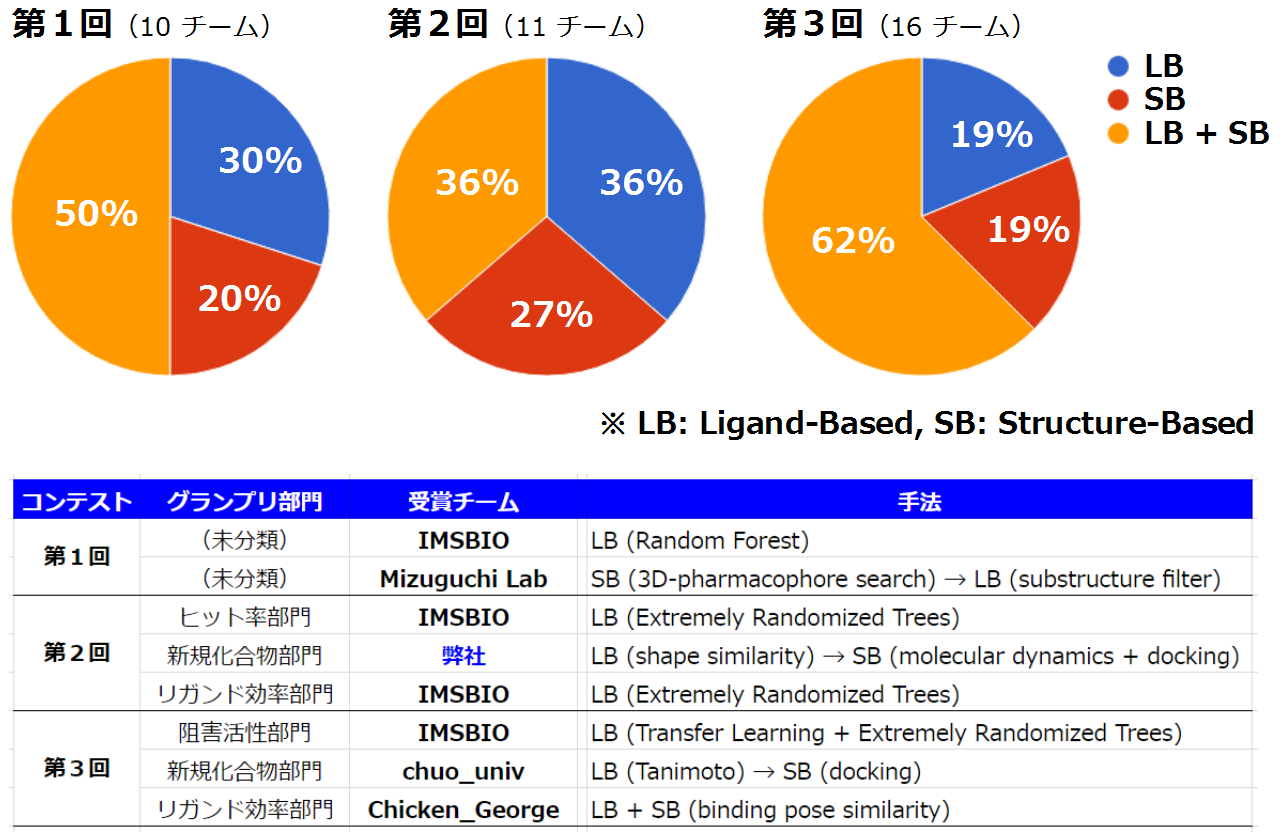
まず,筆者ら自身も実際に参戦したIT創薬コンテスト[2],[3],[4],[5](主催: 並列生物情報処理イニシアティブ ; IPAB)を例に,どのようなVS手法が実践されているか概観してみよう.手法の内訳を図1に示す.参加者の構成も初学者から玄人まで幅広く[6],チームによって用いている手法の系統は多岐に渡る(個々のチームは同一系統の手法をコンテストの回をまたいで用いている傾向がある).加えて,各チームが使用した計算資源の規模もさまざまである.スパコンを駆使したチームもあり,たとえば総あたりドッキング計算に基づくSBVSや大規模データのディープラーニングに基づくLBVSなどは計算量が大きい手法の代表である.一方,3回のコンテスト[2],[3],[4]を通してグランプリを堅持したチーム(IMSBIO望月正弘氏)は一般的な個人PCレベルの計算資源でも効率的にLBVSを実施している.第2回コンテスト[3],[5]において弊社チームがLBVSとSBVSの複合手法を用いてヒット化合物を取得し新規化合物部門グランプリを受賞した際も,計算機としてはノートPC(ゲーミング仕様)程度の代物を用いた.今の時代のコンピュータ普及状況を鑑みれば,計算リソース的にはもはや誰でもバーチャルスクリーニングを実践できることの証左である.より多様性のあるヒット化合物を創出するためにも,VSに取り組む者の裾野が広がってゆくことが望まれる[7].
3.2 各種VS手法の特性
計算量と予測精度は一般的にトレードオフの関係にあり,たとえば大規模並列計算によって結合自由エネルギーを求めるMP-CAFEE法は高精度な予測性能を誇る[8]が,その分スループットに難がある.スクリーニング時に数百~数千個以上の化合物をアッセイ(試料を用いて実施する活性評価実験)にかけることを前提とすれば,一定以上のヒット化合物数の濃縮(エンリッチメント)さえ達成されれば複数のヒット化合物を得ることが可能であり,バーチャルスクリーニングにおいてスループットをある程度優先して計算量を節約することは実務上は現実的な方策である.総じてLBVSは比較的少ない計算量でヒット率も高いが,得られるヒット化合物の新規性は乏しくなりがちである.一方,SBVSは計算コストが高くヒット率もLBVSほど高くないが新規性の高いヒット化合物を得られる可能性があり,図1に示すグランプリ部門ごとの手法の違いにもそれらが表れていることが見てとれよう.各種手法はそれぞれの特性が活きるよう目的に応じて相補的に使い分ければよく,また,個々の標的タンパク質に関する情報および既知のアッセイデータ等のアベイラビリティによっても バーチャルスクリーニングの工程は調整することになるだろう.
3.3 計算コストを抑えつつSBVSを行う実践例
現代の一般的な家庭にある計算資源でも処理可能と考えられる範囲内の計算コストのバーチャルスクリーニングの実践例として,筆者らが実際にIT創薬コンテストで実施し活性化合物の取得に成功した[3],[5]SBVSの概略を図2に示す.

数百万種類の購入可能な在庫のある化合物ライブラリがスクリーニング対象である.10コア以内程度のPCで数百万化合物をドッキング(標的タンパク質の標的部位の空間に化合物がフィットするかどうかを探索するシミュレーション)しようとすると,ソフトウェアの種類と設定にもよるが,おおむね数日以内では計算が終わらない程度の計算量になってしまう.そこで,まずはドッキングによるSBVSの前に既知活性化合物情報を用いたLBVSで効率良く化合物の母数を削減し,SBVSで容易に取り扱える化合物数とした.LBVSには類似構造検索や形状比較によるもの,記述子の主成分分析や機械学習によるもの等があるが,いずれも多数の化合物を高速に処理できるものが利用可能である.
粗めのLBVSによってライブラリ化合物数を数万個以内程度にしてしまえば,一般家庭の限られた計算資源でもドッキング遂行が可能である.LBVSによって一定のヒット率を担保しつつ,SBVSによって新規性の高い化合物の発見も狙うことができよう.
なお実行時の並列数にライセンス制限のないソフトウェア(AutoDockやmyPrestoなど)を使用するのであれば,自前の計算資源にこだわらずともクラウドIaaS(Infrastructure as a Service)を利用してしまって数千円の課金で数百コア・数時間の計算で数百万化合物のドッキングを総あたりに行うことは可能である.
4.人智に基づく選別の実際
4.1 アッセイ対象とする化合物のさらなる選抜
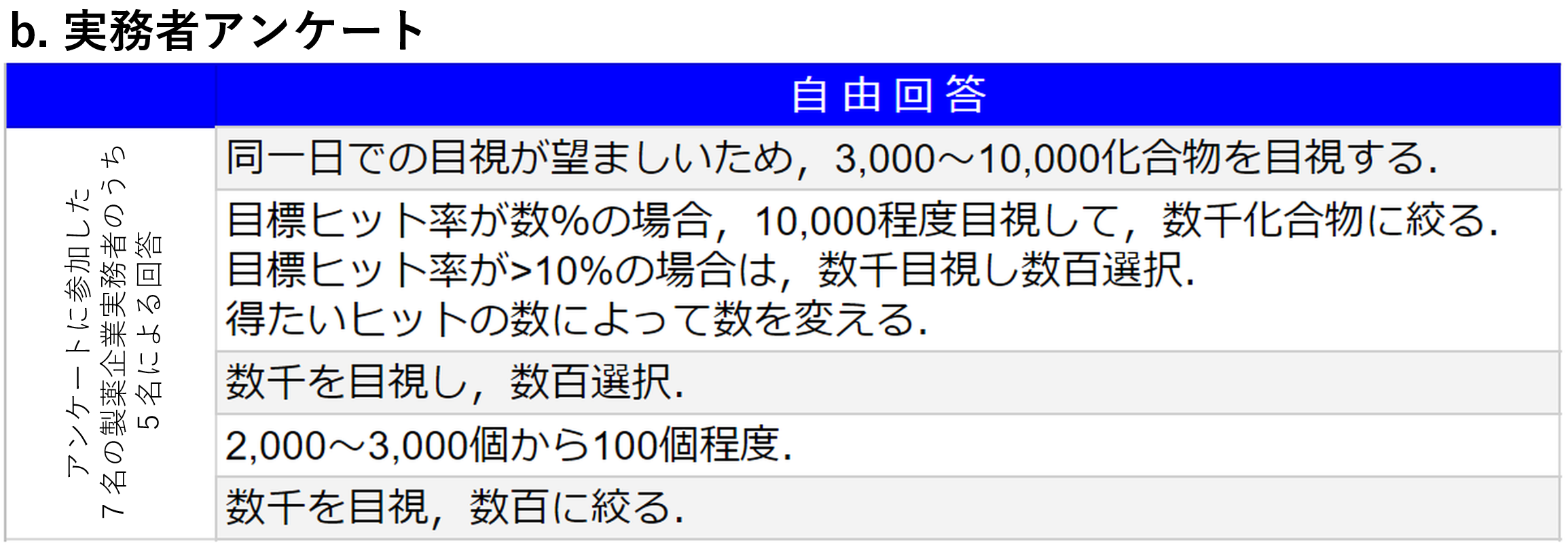
薬剤活性を有する可能性が高い化合物を計算で選別するバーチャルスクリーニングによって,スコアでランク付けされた候補化合物リストが得られるが,その中から実際にアッセイにかけられる化合物は,(研究体制・規模にもよるが)人手によってさらに選抜されるケースが多い.文献上の傾向および筆者がIT創薬実務者に対して実施したアンケートの結果を図3に示す.数百万化合物のライブラリから計算によって数百~数千程度に絞るわけだが,そこからさらに人智に基づいて厳しくアッセイ対象が選抜されていることが分かる.スクリーニングの実務としては,バーチャルスクリーニングによるランキング結果を必ずしもそのままでは使っていないのである.
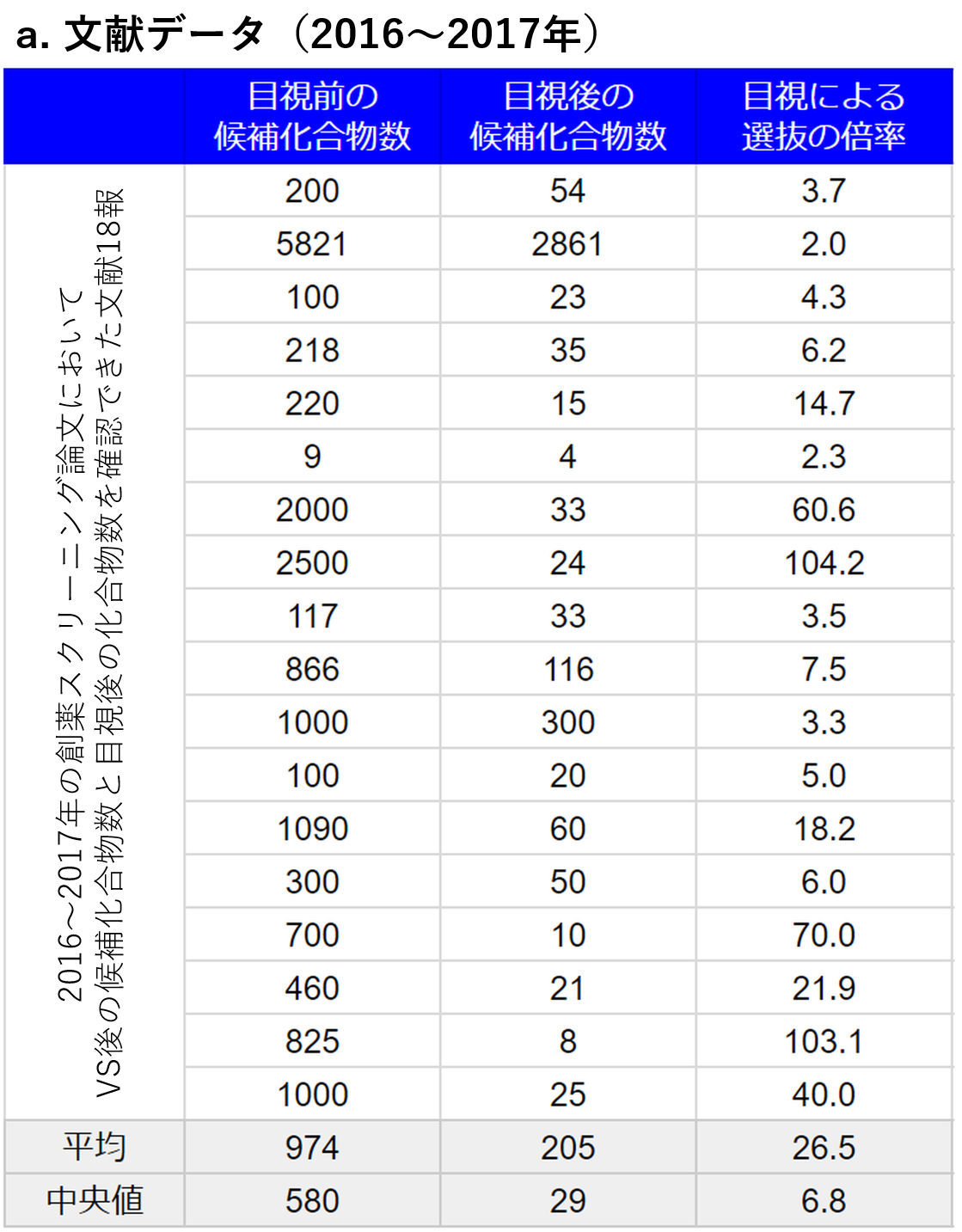
a.2016~2017年の文献において,目視前後の化合物数が確認できたもののデータ.
b.製薬企業の実務者に対するアンケートの結果.
4.2 「創薬知」のカテゴリ
人手による選抜は,具体的にはどのような属性に着目して行われているのであろうか? 結合の可能性(ヒット化合物となる可能性)がより高い化合物を選ぶためにはドッキングにおける結合様式が目視(visual inspection)され,一方,開発薬としての適性の判断には構造式そのものが目視される.それぞれの判断基準としては,表1に挙げたような個別の属性がある.ただし何を重視するかについては各担当者(スクリーニングおよびメドケム)間で捉え方が異なり,属人的な面も大きいのが現実である.また,そもそも言語化が難しいような属性についても情報を収集することが可能かどうか,パイロット実験を試みている(次節4.3).

4.3 Visual inspection の有効性
エキスパートのvisual inspectionによって化合物選別が改善され得るということは,実務者の間ではコンセンサスとなっているが,それを直接的に証明した報告は乏しい.構造式に関するメディシナルケミストの人智の活用の有効性を議論した報告[9]等はある一方,ドッキングにおける結合様式の目視の有効性に関しては具体的報告がない.そこで我々は,ドッキングの目視の有効性を直接証明することを試みている.まずパイロット実験として,図4に示すようなWebアプリケーションを作成し,SBVS(特にドッキングスタディ)において化合物の結合様式に関して目視によって判断される属性は何か,そして目視による選抜が実際にヒット率を向上させ得るかを検証している.被験者には専門家に加えて非専門家も交え,万人にタスクをこなしてもらうシチズン・サイエンスとしての実現可能性,クラウドソーシングの可能性も含めて検討中である.
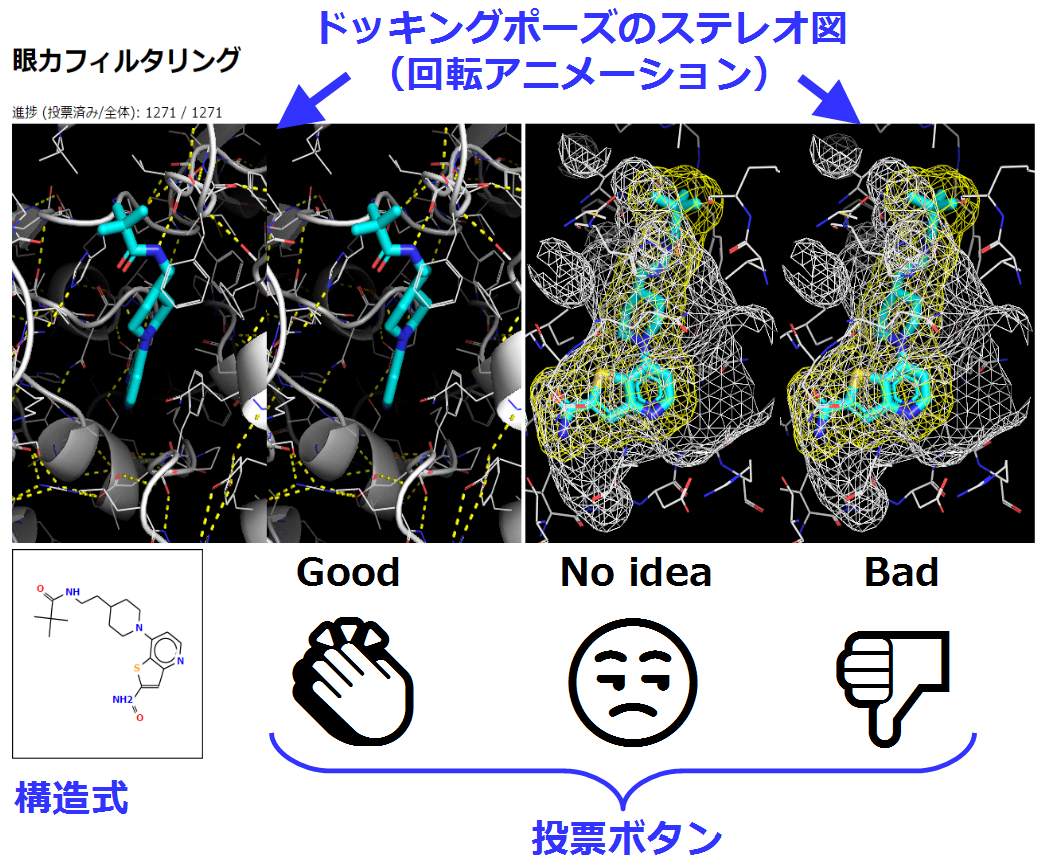
また,Twitterを活用したクイズ方式でも随時visual inspection実験を実施している(https://twitter.com/souyakuchan)[10].図5に示す形で選択式の結合様式正誤クイズ等を出題している(図5の正解は本稿付録に記載).当該アカウント(創薬ちゃん ; @souyakuchan)は創薬に関する情報を日々発信するキャラクターとして2016年8月から運用しており,創薬に関心のある多くのフォロワーを抱えている.結果これまでに出題した目視クイズ3題においては,投票を多数決と見なして一番回答が多かった選択肢を群衆が選んだ回答とすれば正解率100%を達成しており,群衆による目利きの有効性を示唆している.

5.今後のIT創薬の方向性
5.1 創薬標的と化合物空間の拡充の必要性
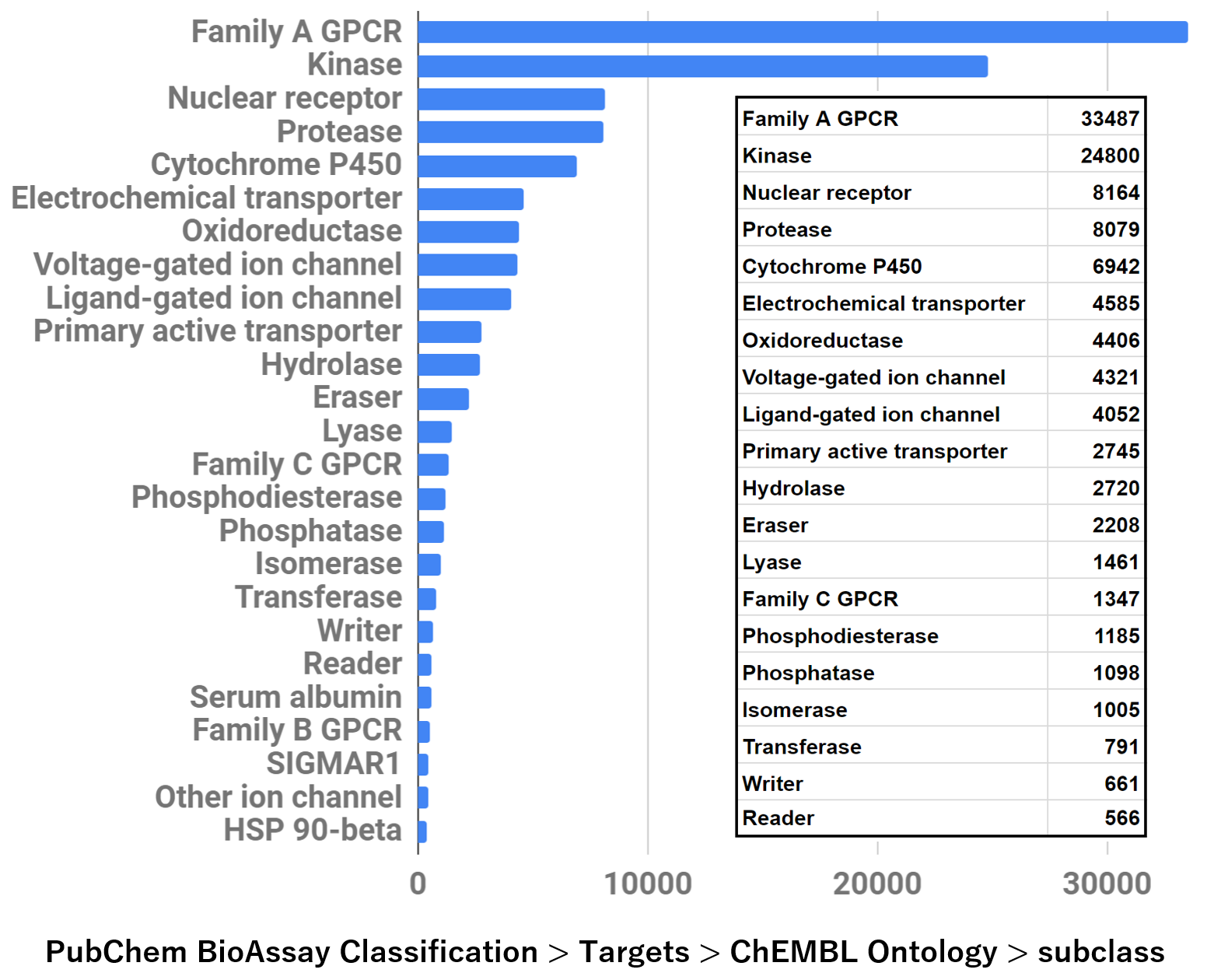
昨今,多くの分野で機械学習が威力を発揮しており,創薬においてもさまざまな手法が試されている状況である.しかしながら,囲碁・将棋や画像認識・生成等の分野でディープラーニングに代表される機械学習手法が大活躍しているのと比べて,創薬分野ではいまだ目覚ましい成果に欠けるのはなぜであろうか? 複雑なグラフ構造から成る構造式は学習の入力データにしづらいといった点や,標的タンパク質と化合物が持つ3次元構造情報を上手く取り込めていないといった点などが挙げられるが,現状最大の難点は,学習に用いるデータセットが絶対的に不足していることである.現在 公的に利用可能なアッセイデータにおける標的の内訳を図6に示す.GPCR(G protein-coupled receptor)とキナーゼ(kinase)が圧倒的に多く,タンパク質の種類が大きく偏っていることが分かる.機械学習が幅広い標的を対象とするためには,利用可能なアッセイデータにおける標的の多様性の拡充が必須であろう.
またたとえば,今後有望な新たな創薬標的群として,タンパク質ータンパク質間相互作用(PPI)が注目を集めているが,PPIの構造的な相互作用面は酵素の活性部位などと比べて平たく浅いことが多く,低分子では結合しづらいため,中分子(分子量500〜1,000以上の化合物)領域の開拓が重要と目されている.そのような領域では,アッセイデータが不足していることはもちろんであるが,アッセイ可能な中分子化合物の多様性自体が足りていない.探索可能な化合物空間(存在し得るあらゆる化合物の集合 ; chemical space)を大きく拡大するような合成化学的なブレークスルーも望まれるところである.
5.2 新しい創薬エコシステムを目指して
すなわち,将来的な機械学習等の活躍を見据える上でも,現時点では現実の実験データの増産が必要不可欠であり,アッセイ系の開発による標的の多様性拡大,新規化合物合成による化合物空間の拡大,そしてそれらを実験に供したアッセイデータの整備が喫緊の課題である.いずれも大きな資金が必要な活動であるが,これらを公的研究費や製薬企業資本に求めるばかりでは経済的な持続可能性に難がある.昨今ただでさえ新薬の研究開発費用は増大し,それが薬価に跳ね返された高価な新薬が国の医療財政を揺るがしかねないような事例も散見されている.企業体力を削る形での研究開発資金の捻出には限界がある.そこで弊社は,元来,製薬企業や高度な研究開発組織だけに許された活動であった「創薬」への門戸を広く一般に開放し,創薬研究開発のクラウドソーシングおよび創薬資金のクラウドファンディングを可能とする「ソーシャル創薬」の社会実装を目指している.企業等の個々の組織体に莫大な開発費を負わせるのではなく,クラウド(「叢」)としての一般国民に負担を分散する形で,「叢薬(そうやく)」エコシステムを実現するのが目標である.それにより,薬剤としての市場性に縛られた従来の創薬標的の選び方からも脱却し,標的・化合物空間ともに万遍なく探索・アッセイを実施することで創薬ビッグデータを持続的に生産し,創薬科学の進歩を加速したい.
5.3 創薬の社会実装へのハードルを越えるために
とはいえ,創薬は個々の国民にとって身近に感じられる活動とは言い難く,それに労力や金銭を投じようと考える人間はごく一部であろう.しかしながら,上述の「叢薬」の実現のためには万人を巻き込む必要がある.そのための弊社のソリューションが,ソーシャルゲーム化を介した創薬のゲーミフィケーション(課題解決の方策をゲームの形に置き換えること)である.近年,実用レベルの手法が出揃ってきているIT創薬ソフトウェア群を,敷居の低いユーザインタフェースを介して広く一般に開放し,誰でも新薬候補の品定めをできる環境を整える(IT創薬のクラウドソーシング).加えて,すでに国内だけでも年間1兆円を超えているゲーム市場の資本を活用したい.すなわち,化合物の活性確認実験(アッセイ)を実施する費用を,候補化合物を品定めした者自身が負担できるシステムを構築し,有望な新薬候補に関しては治験も見据えた費用捻出の場を設ける (創薬資金のクラウドファンディング).以上のプロセスを万人にとって親しみやすいものとするため,新薬発見への報酬システムを組み入れたソーシャルゲームを開発する.
先述(4.3節)のvisual inspectionのクラウドソーシング可能性の検討も,筆者らが目指す創薬シチズン・サイエンスのエビデンス確保の一環である.
6.おわりに─コンテンツIPの重要性
以上,バーチャルスクリーニングの実務を主体にIT創薬について概説し,人智との連携の可能性,そして「叢薬」と銘打った創薬エコシステムの社会実装について展望した.一方,ゲーミフィケーションを介した社会実装を目指すにしても,まずはゲームを流行させるためにはそもそもコンテンツがブレイクしないと始まらない.そのため,まずはIP(著作権コンテンツ)をしっかり育てるところから取り組んでいる.タンパク質科学者としてのこだわりを最大限に反映した生命科学・創薬科学モチーフの世界観を作り込んでいるので成果に期待されたい(図7 ; その物語の主人公となる創薬科学者キャラクター).並行して,創薬知および人間の柔軟な認知能力を活用したヒューマンコンピュテーションをIT創薬と融合させる研究を進めつつ,ゲームを介して誰でも自分の力で現実の創薬に参加でき,疾患と戦う創薬RPGの制作が当面の目標である.

謝辞 本稿作成にご協力いただいた皆様に深謝いたします.
参考文献
- 1)日本製薬工業協会: 製薬産業2016-2017 てきすとぶっく(2017),
http://www.jpma.or.jp/about/issue/gratis/tekisutobook/ - 2)IPAB:第1回 IT創薬コンテスト(2014),
http://www.ipab.org/eventschedule/contest/contest1 - 3) IPAB:第2回 IT創薬コンテスト(2015),
http://www.ipab.org/eventschedule/contest/conetst2results - 4)IPAB:第3回 IT創薬コンテスト(2016),
http://www.ipab.org/eventschedule/contest/contest3results - 5)東京工業大学プレスリリース:第2回オープン創薬コンテストで13個のヒット化合物を発見(2015), http://www.titech.ac.jp/news/2015/031914.html
- 6)関嶋政和:オープンイノベーションによるIT創薬:コンテスト形式による薬剤候補化合物の探索,情報管理,58(12), pp.900-907 (2016).
- 7)Chiba, S., Ikeda, K., Ishida, T., Gromiha, M. M., Taguchi, Y., Iwadate, M., Sugaya, N. et al. : Identification of Potential Inhibitors based on Compound Proposal Contest : Tyrosine-protein Kinase Yes as a Target, Scientific reports, 5 (2015).
- 8)Fujitani, H., Tanida, Y., and Matsuura, A. : Massively Parallel Computation of Absolute Binding Free Energy with Well-equilibrated States, Physical Review E, 79(2), 021914 (2009).
- 9)Kutchukian, P. S., Vasilyeva, N. Y., Xu, J., Lindvall, M. K., Dillon, M. P., Glick, M., Brooijmans, N. et al. : Inside the Mind of a Medicinal Chemist : The Role of Human Bias in Compound Prioritization During Drug Discovery, PLOS ONE, 7(11), e48476 (2012).
- 10) @souyakuchan:創薬Visual inspectionクイズまとめ.Twitter,
https://twitter.com/i/moments/1022088984703295489(随時更新)
付録:創薬SNSアカウント@souyakuchanの遊び方
A.構造式描画機能
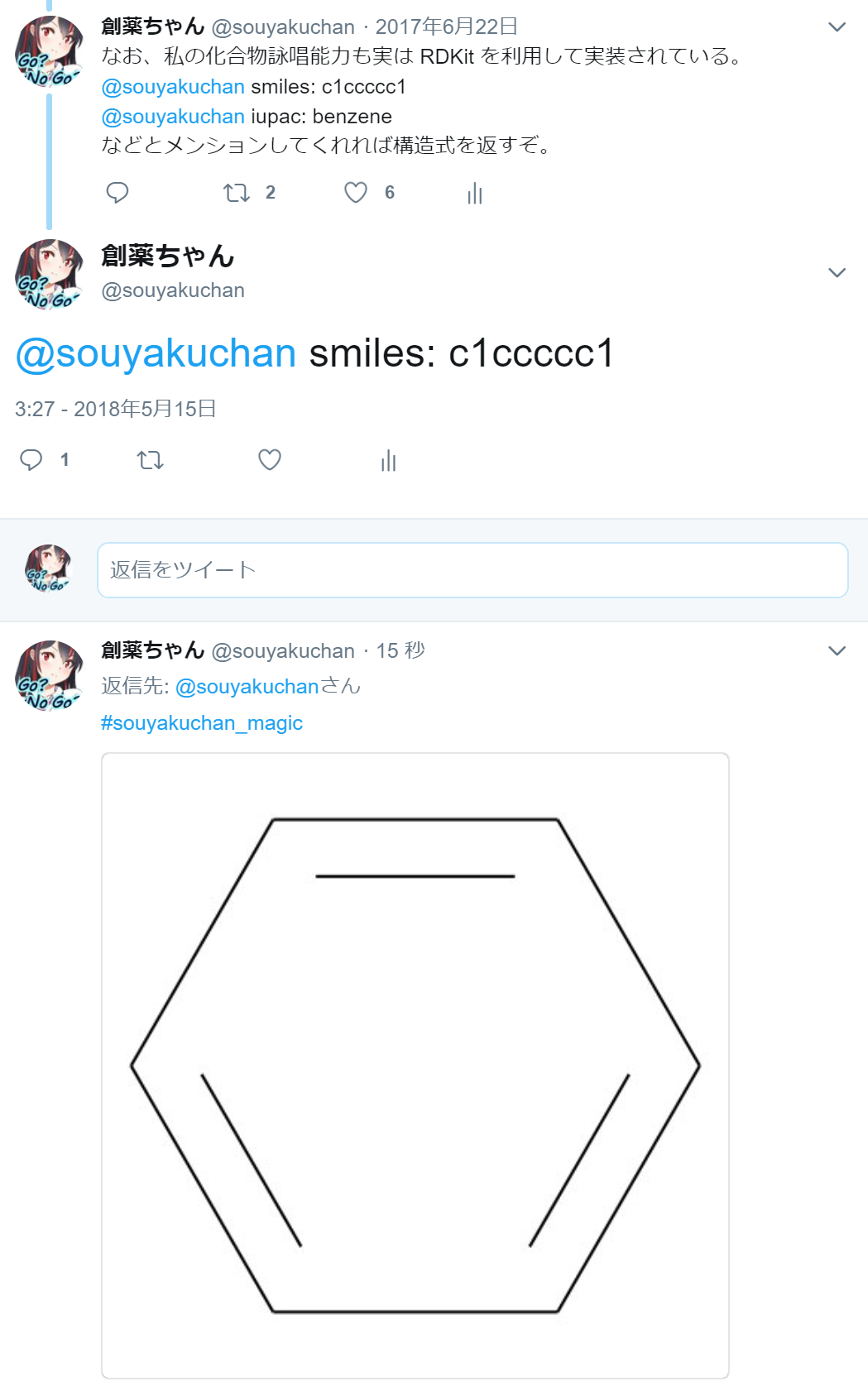
Twitterアカウント(@souyakuchan)に図8に示す書式でメンションを飛ばすと任意の化合物の構造式を描画し,Twitter上で共有できる.人智による新規構造式創出・収集の試みである.
B.創薬クイズ(随時出題)
投票形式の創薬クイズ出題(図9).四択以下の選択となるが,誰もが容易に結合様式の良否判定問題やその他創薬にまつわるクイズにトライできる.図9は図5(4.3節)のTwitterでの出題時の様子であるが,本問の正解は③である.

C.アドベントカレンダー
エンジニアたちがためになる記事を年末にこぞって執筆する風習である,アドベントカレンダー(元々は欧米のクリスマスの風習で,日めくりでお菓子などが出てくるクリスマスカウントダウンカレンダー)の創薬版を実施している(図10).記述ベースの創薬知収集といえる.
創薬 Advent Calendar 2017:https://adventar.org/calendars/2412
2009年東京大学医学部医学科卒業.2011年同大医学部附属病院にて初期臨床研修修了.2015年同大大学院医学系研究科分子細胞生物学専攻修了,博士(医学).エピジェネティクス・プロテオミクス研究に携わる傍ら,創薬スクリーニングを手掛ける.2015年〜東京大学アイソトープ総合センター特任研究員,2018年〜特任助教(非常勤).2017年(株)シャルクス設立.万人の知識・アイディアと資本を創薬に活かすソーシャル創薬の社会実装を目指す.
編集担当:上條 浩一(日本アイ・ビー・エム(株))