
(邦訳:平易なコーパスを用いないテキスト平易化)
| 梶原 智之 大阪大学データビリティフロンティア機構(特任助教) |
[背景]子どもや言語学習者など人々の文章読解を支援するテキスト平易化
[問題]英語以外の言語ではテキスト平易化モデルの訓練用データを利用できない
[貢献]訓練用データの自動構築手法を提案し,テキスト平易化の多言語展開に貢献
テキスト平易化は,入力されたテキストの意味を保持しつつ平易に書き換えるという自然言語処理タスクである.システムは,子どもや言語学習者をはじめとする人々の文章読解を支援し,他の自然言語処理タスクの性能改善にも寄与する.テキスト平易化は,難解な文から平易な文への「単言語翻訳」と考えることができ,機械翻訳に似た要領で実現される.つまり,意味的に等価な難解な文と平易な文のペアを大量に用意し,モデルに変換規則を学習させていく.
これまでテキスト平易化は,データが豊富な英語を中心に研究されてきた.たとえばWikipediaには,500万記事を超える英語で書かれたテキストと,10万記事を超える平易な英語で書かれたテキストが存在する.これらのうち,同じ見出しを持つ記事のペアから,テキスト平易化モデルの訓練のために必要な「意味的に等価な難解な文と平易な文のペア」を大量に収集することができる.しかし,英語以外の言語では,語彙や文法を制限して平易に書かれた大規模テキストは利用できない.そのため,多くの言語ではテキスト平易化モデルの訓練のために必要なデータセットを用意できず,人々はテキスト平易化の恩恵を受けることができない.
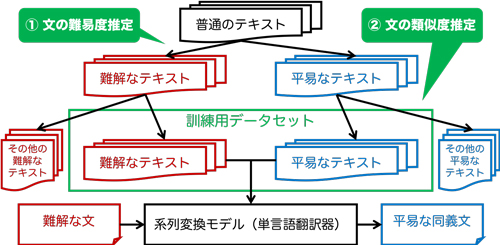
本研究では,大規模な訓練用データセットを擬似的に自動構築することでこの問題に対処し,テキスト平易化の多言語展開に貢献した.平易に書かれた大規模テキストを入手することが難しい一方で,普通のテキストデータは多くの言語で大規模に利用可能である.そこで本研究では,「①文の難易度推定」と「②文の類似度推定」を組み合わせて,図に示すように普通のテキストデータから難易度の異なる文のペアを収集する手法を提案した.大規模な普通のテキストデータの中には,たまたま難しく書かれた文も大量に存在するが,たまたま易しく書かれた文も大量に含まれる.そこで①の難易度推定では,大規模なテキストデータを,難解な文集合と平易な文集合の2つのサブセットに分割した.このような大規模な2つの文集合の中には,たまたま同じようなことを記述している文のペアが含まれることがある.たとえば,共通の事物や関連する事物についての複数の言及の中に,同じ内容を表現する難解な文と平易な文が存在する場合がある.②の類似度推定では,難解な文集合と平易な文集合の間で,このように同義な関係にある文のペアを見つけた.
上記のように,本研究では,テキスト平易化モデルの訓練用データを大規模に自動構築した.英語における実験では,提案手法によって自動的に構築された訓練用データから学習したモデルが,既存のモデルと同等の性能でテキストを平易化できることが明らかになった.そして日本語においても同様に訓練用データを自動構築し,テキスト平易化が実現できることを確認した.本研究の成果をもとに,テキスト平易化の多言語展開が期待できる.また,本研究の応用として,他の自然言語処理タスクにおいても訓練用データを自動構築できる可能性がある.特に機械翻訳では,すでに本研究を応用して訓練用データを拡張し,翻訳品質が改善されたという報告がある.
これまでテキスト平易化は,データが豊富な英語を中心に研究されてきた.たとえばWikipediaには,500万記事を超える英語で書かれたテキストと,10万記事を超える平易な英語で書かれたテキストが存在する.これらのうち,同じ見出しを持つ記事のペアから,テキスト平易化モデルの訓練のために必要な「意味的に等価な難解な文と平易な文のペア」を大量に収集することができる.しかし,英語以外の言語では,語彙や文法を制限して平易に書かれた大規模テキストは利用できない.そのため,多くの言語ではテキスト平易化モデルの訓練のために必要なデータセットを用意できず,人々はテキスト平易化の恩恵を受けることができない.
本研究では,大規模な訓練用データセットを擬似的に自動構築することでこの問題に対処し,テキスト平易化の多言語展開に貢献した.平易に書かれた大規模テキストを入手することが難しい一方で,普通のテキストデータは多くの言語で大規模に利用可能である.そこで本研究では,「①文の難易度推定」と「②文の類似度推定」を組み合わせて,図に示すように普通のテキストデータから難易度の異なる文のペアを収集する手法を提案した.大規模な普通のテキストデータの中には,たまたま難しく書かれた文も大量に存在するが,たまたま易しく書かれた文も大量に含まれる.そこで①の難易度推定では,大規模なテキストデータを,難解な文集合と平易な文集合の2つのサブセットに分割した.このような大規模な2つの文集合の中には,たまたま同じようなことを記述している文のペアが含まれることがある.たとえば,共通の事物や関連する事物についての複数の言及の中に,同じ内容を表現する難解な文と平易な文が存在する場合がある.②の類似度推定では,難解な文集合と平易な文集合の間で,このように同義な関係にある文のペアを見つけた.
上記のように,本研究では,テキスト平易化モデルの訓練用データを大規模に自動構築した.英語における実験では,提案手法によって自動的に構築された訓練用データから学習したモデルが,既存のモデルと同等の性能でテキストを平易化できることが明らかになった.そして日本語においても同様に訓練用データを自動構築し,テキスト平易化が実現できることを確認した.本研究の成果をもとに,テキスト平易化の多言語展開が期待できる.また,本研究の応用として,他の自然言語処理タスクにおいても訓練用データを自動構築できる可能性がある.特に機械翻訳では,すでに本研究を応用して訓練用データを拡張し,翻訳品質が改善されたという報告がある.
(2018年5月29日受付)