
(邦訳:映像とテキストを対応づける特徴量およびその応用)
| 大谷 まゆ (株)サイバーエージェント リサーチャー |
[背景]オブジェクトやアクションなど多様な要素からなる映像の内容を推定したい
[問題]映像とテキストの意味的類似度の推定
[貢献]映像とテキストの意味を捉える共通の特徴量の開発
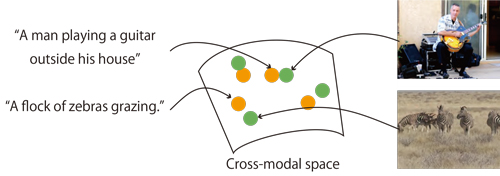
人間のように画像や映像の内容を理解することはコンピュータビジョンの大きな目標の1つである.近年,画像や映像のような視覚情報と,オブジェクトラベルや説明文などの言語情報を対応づけることで視覚情報の理解を目指す研究が広く取り組まれている.このような試みは視覚情報からの意味理解技術にとって重要であることはもちろん,映像検索や映像の説明文自動生成など,広範な応用が期待される研究である.
本研究では映像と自然言語を対応づけるため,両者の意味内容を統一的に表現することができる特徴量を開発する.この研究では特徴量開発のため,2つの方向性を検討する.具体的には,ヒューリスティックな特徴量設計と大規模データを用いた特徴量学習である.それぞれの性能を評価するため,本研究では提案特徴量を用いた映像要約や映像検索の性能を調査した.
本研究は以下の3つのサブトピックで構成される.
(1)映像と文章を対応づけるためのオブジェクトに基づく特徴量
映像と文章の意味的類似度を算出するための特徴量と類似度指標を設計した.さらにこの特徴量の有用性を確認するため,ユーザが記述したテキストの内容に沿って,映像中の場面を抜き出す映像要約手法を開発,評価した.
(2)深層学習を用いた映像と文の特徴量学習
短い映像と文を共通の特徴空間にマッピングすることで,意味的類似度を推定する手法を開発した.具体的には,映像とテキストそれぞれを共通の特徴空間にマッピングするニューラルネットワークモデルを構築し,映像のキャプションデータセットを用いて学習した.またこのモデルを拡張し,文のマッピング算出のための補助的な入力としてウェブ画像検索結果を用いるモデルを提案した.ここで得られた特徴量は自然言語をクエリとした映像検索,および映像要約で評価した.
(3)動的な意味的類似度推定のための特徴量学習
2で開発したモデルを拡張し,映像を特徴ベクトルの系列に変換するモデルを提案した.映像を特徴量の系列にすることで,動的に変化する映像と文の意味的類似度を扱うことが目的である.提案モデルを学習するためには膨大な映像と文に加え,動的に変化する意味的類似度のアノテーションを持つデータセットが必要となる.しかし,そのようなデータセットは限られているため,本研究では既存の映像キャプションデータセットから擬似データを生成し,その生成されたデータを使ってモデルを学習する手法を提案した.実験により,擬似データで学習されたモデルであっても,実際の映像において動的に変化する類似度を推定可能であることが確認された.
本研究では映像と自然言語を対応づけるため,両者の意味内容を統一的に表現することができる特徴量を開発する.この研究では特徴量開発のため,2つの方向性を検討する.具体的には,ヒューリスティックな特徴量設計と大規模データを用いた特徴量学習である.それぞれの性能を評価するため,本研究では提案特徴量を用いた映像要約や映像検索の性能を調査した.
本研究は以下の3つのサブトピックで構成される.
(1)映像と文章を対応づけるためのオブジェクトに基づく特徴量
映像と文章の意味的類似度を算出するための特徴量と類似度指標を設計した.さらにこの特徴量の有用性を確認するため,ユーザが記述したテキストの内容に沿って,映像中の場面を抜き出す映像要約手法を開発,評価した.
(2)深層学習を用いた映像と文の特徴量学習
短い映像と文を共通の特徴空間にマッピングすることで,意味的類似度を推定する手法を開発した.具体的には,映像とテキストそれぞれを共通の特徴空間にマッピングするニューラルネットワークモデルを構築し,映像のキャプションデータセットを用いて学習した.またこのモデルを拡張し,文のマッピング算出のための補助的な入力としてウェブ画像検索結果を用いるモデルを提案した.ここで得られた特徴量は自然言語をクエリとした映像検索,および映像要約で評価した.
(3)動的な意味的類似度推定のための特徴量学習
2で開発したモデルを拡張し,映像を特徴ベクトルの系列に変換するモデルを提案した.映像を特徴量の系列にすることで,動的に変化する映像と文の意味的類似度を扱うことが目的である.提案モデルを学習するためには膨大な映像と文に加え,動的に変化する意味的類似度のアノテーションを持つデータセットが必要となる.しかし,そのようなデータセットは限られているため,本研究では既存の映像キャプションデータセットから擬似データを生成し,その生成されたデータを使ってモデルを学習する手法を提案した.実験により,擬似データで学習されたモデルであっても,実際の映像において動的に変化する類似度を推定可能であることが確認された.
(2018年5月31日受付)