
(邦訳:階層的なタイリングデータレイアウトに基づくタイル・ライン両アクセス対応キャッシュメモリの研究)
| 王 宝康 マイクロンメモリジャパン(株)(プロセス インテグレーション) |
[背景]配列データのSIMDによる並列処理が一般化
[問題]SIMD処理が行・列のいずれかの優先方向にしか対応できないことの解消
[貢献]行・列両方向の並列アクセスを実現するキャッシュメモリの提案
[問題]SIMD処理が行・列のいずれかの優先方向にしか対応できないことの解消
[貢献]行・列両方向の並列アクセスを実現するキャッシュメモリの提案
科学技術計算,画像処理等で広く用いられている2次元以上の配列データ処理では,配列要素の自然な処理順がラスタ走査方向に限られることはない.しかし,従来のメモリシステムはラスタレイアウトに基づく格納形式を採っており,ラスタ走査方向以外のアクセスで,TLBミスが大幅に増加する上に,高速化の要であるSIMD処理に必須の並列アクセスに対応できない.そのため,ラスタ走査方向の処理順が強いられてコーディングが複雑化したり,配列の並びをラスタ走査方向に揃えるために不可避となる転置処理がSIMDによる高速化の障害となったりしている.そこで,本研究では,このラスタ走査方向優先の制約解消あるいは転置不要化を目指して,行・列両方向の並列アクセスを両立するタイル・ライン両アクセス対応のキャッシュメモリを提案している.
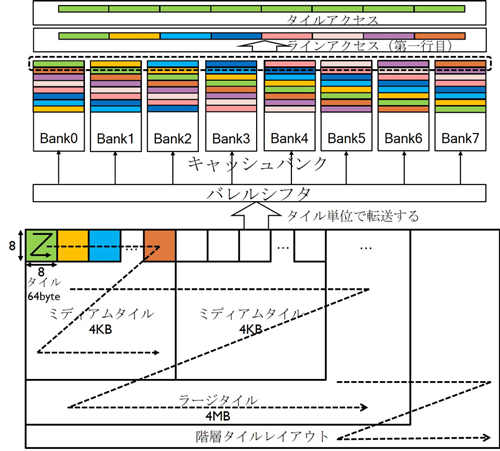
提案キャッシュは,スキューイング形式で格納する多バンク構成キャッシュと,ラスタレイアウトの論理アドレスから4MB,4KB(キャッシュサイズ),64Byte(キャッシュラインサイズ)の3階層の細分される階層タイルレイアウト(図参照)の仮想アドレスに変換するアドレスビット入替器とで構成している.スキューイング格納形式は,図に示されるようにタイルの構成データである同一色のサブラインをバンク間で1バンク分ずつ右方向にローテートさせる形で格納することで,タイル(列)とライン(行)の両方の並列アクセスを可能とする.しかし,タイル・ラインのそれぞれでヒット判定を行うのに,タグメモリも多バング化することが必要で,それがタグメモリ部の大幅な規模増をまねいてしまう.そこで,置換の単位をタイルセット(4ないし8タイル)とし,タグメモリの多バンク化を列方向の非整列タイルアクセスに必要な2バンクまでに抑える新規のRATS法(Replace multiple tiles with an Aligned Tile Set)を採用した.
提案キャッシュの実現性を検証するために,SIMD汎用データパースに提案キャッシュを組み込んで,VDECの0.18μmCMOSにより,2.5×5mm2のチップを試作した.その結果,RATS法により,従来のL1キャッシュと同じ動作速度・レイテンシの条件で,提案キャッシュ全体のハードウェア規模増を高々7%程度に抑えられることが明らかになった.
性能評価は,SimpleScalarシミュレータを改造し,行列計算の要となっている行列乗算とLU分解に対して行った.そして,1. ラスタ走査方向優先の従来のコードが従来のメモリシステムと同等の速度で実行できること,2. 行・列両方向のキャッシュライン単位の並列アクセス頻度を均等にする条件で,TLBミスが従来のメモリシステムの1/10〜1/100程度の頻度にまで抑えられ,非ラスタ走査方向の処理順が速度低下の要因とならないことなどを明らかにした.これらの結果は,提案キャッシュが2次元配列データの構成要素に対する処理順をラスタ走査方向に強いる制約を不要とし,コーディングの自由度を大幅に高められることを示している.
提案キャッシュは,スキューイング形式で格納する多バンク構成キャッシュと,ラスタレイアウトの論理アドレスから4MB,4KB(キャッシュサイズ),64Byte(キャッシュラインサイズ)の3階層の細分される階層タイルレイアウト(図参照)の仮想アドレスに変換するアドレスビット入替器とで構成している.スキューイング格納形式は,図に示されるようにタイルの構成データである同一色のサブラインをバンク間で1バンク分ずつ右方向にローテートさせる形で格納することで,タイル(列)とライン(行)の両方の並列アクセスを可能とする.しかし,タイル・ラインのそれぞれでヒット判定を行うのに,タグメモリも多バング化することが必要で,それがタグメモリ部の大幅な規模増をまねいてしまう.そこで,置換の単位をタイルセット(4ないし8タイル)とし,タグメモリの多バンク化を列方向の非整列タイルアクセスに必要な2バンクまでに抑える新規のRATS法(Replace multiple tiles with an Aligned Tile Set)を採用した.
提案キャッシュの実現性を検証するために,SIMD汎用データパースに提案キャッシュを組み込んで,VDECの0.18μmCMOSにより,2.5×5mm2のチップを試作した.その結果,RATS法により,従来のL1キャッシュと同じ動作速度・レイテンシの条件で,提案キャッシュ全体のハードウェア規模増を高々7%程度に抑えられることが明らかになった.
性能評価は,SimpleScalarシミュレータを改造し,行列計算の要となっている行列乗算とLU分解に対して行った.そして,1. ラスタ走査方向優先の従来のコードが従来のメモリシステムと同等の速度で実行できること,2. 行・列両方向のキャッシュライン単位の並列アクセス頻度を均等にする条件で,TLBミスが従来のメモリシステムの1/10〜1/100程度の頻度にまで抑えられ,非ラスタ走査方向の処理順が速度低下の要因とならないことなどを明らかにした.これらの結果は,提案キャッシュが2次元配列データの構成要素に対する処理順をラスタ走査方向に強いる制約を不要とし,コーディングの自由度を大幅に高められることを示している.
(2018年5月26日受付)