
(邦訳:知的環境におけるインタラクション支援のための実世界コンテキスト認識および応用)
| 孔 全 (株)日立製作所 研究開発グループ |
[背景]居住者生活改善を目指す知的環境の実現
[問題]居住者と住む環境とのインタラクションの容易化
[貢献]コンテキスト認識・応用によりインタラクション支援手法の提案
[問題]居住者と住む環境とのインタラクションの容易化
[貢献]コンテキスト認識・応用によりインタラクション支援手法の提案
近年の無線通信やセンシング技術の進展により知的環境の実現が可能となりつつある.居住者の生活サポートや生活の質の改善を目指す知的環境の実現には,居住者と居住環境とのインタラクションを支援することが重要である.本研究では,ユーザが物理的な操作により意識的に居住環境内のサービスを要求すること(例:テレビを見たいときにリモコンを用いてテレビを起動する)を,コンシャス・インタラクションと定義する.一方,ユビキタスコンピューティングの分野ではユーザの物理的な操作を必要とせず,環境が認識したユーザのコンテキスト情報に応じてサービスを自動的に提供することが重要な目標のひとつとされている.このようなサービスへの要求・提供は無意識で行われるインタラクションとして,本研究ではアンコンシャス・インタラクションと定義する.このような,コンシャスおよびアンコンシャス・インタラクションの支援は知的環境を実現するための重要なタスクであり,本研究ではこれらの2つのタスクを実現するセンサデータ処理技術の開発を行った.
コンシャス・インタラクションにおける家電選択の過程において,居住環境内に遍在する多数の家電から操作したい家電を選択することはユーザに大きな負担を強いる.人の音声やジェスチャなどを用いて効率的に操作したい家電を選択する方法がこれまでに提案されているが,音声の場合,家電を特定するために長い命令を必要とすることがある.ジェスチャの場合,ユーザは家電とジェスチャとの関連付けを覚えることが必要である.一方,認識されたコンテキスト情報に基づいてユーザに適したサービスを提供するアンコンシャス・インタラクションを実現するためには,正確かつユーザに負担がかからない手段でコンテキスト情報を認識することが重要である.コンテキスト情報は行動と位置情報に主に分けられる.既存の行動認識研究の多くは教師あり学習を用いるため,大量のトレーニングデータを用意するコストをユーザに強いる.一方,位置情報の既存研究は,人の位置と物の位置を推定するものに主に分けられる.物の位置,すなわちどこで何を使ったという情報はユーザの位置・行動を反映する1つ重要なコンテキストである.しかし, 一般的な物の位置推定手法ではRFIDタグなどのデバイスを物に添付する必要があり,導入コストとメンテナンスコストの問題が存在する.
本研究では,上述したコンシャスおよびアンコンシャス・インタラクションを実現する際の問題点に対する解決方法を提案した.(1)まずコンシャス・インタラクションを支援するため, Google Glassなどのスマートグラスを装着するユーザが操作したい家電を注目するだけで,Glassから撮影した画像とGlassに搭載されたさまざまなセンサから推定された人のコンテキスト情報を組み合わせることにより,その家電を高精度に選択することを可能とする手法を提案した.(2)アンコンシャス・インタラクションを支援するため,行動認識におけるトレーニングデータを準備するコストにかかわる問題に対して,異なる行動における同じ部位の類似センサデータを再利用することで,少量のトレーニングデータでも高精度の行動認識手法を提案した.(3)最後に,物の屋内位置を推定するための導入・メンテナンスコストの問題に対して,電気系統を流れる電流を安価な電流センサにより観測し,電圧降下現象に基づき,屋内の電化製品の利用位置を推定する手法を提案した.
本研究で提案した手法は日常生活におけるコンシャスおよびアンコンシャス・インタラクションの支援をより現実的にするものであり,人の生活のサポートおよび改善を可能とする知的環境の構築が容易になると期待される.また,環境は認識されたコンテキスト情報を基に最適なサービスを提供することが可能となる.たとえば,行動や家電利用位置情報に応じた温度や照明,空調の自動調整などの提供が期待される.
コンシャス・インタラクションにおける家電選択の過程において,居住環境内に遍在する多数の家電から操作したい家電を選択することはユーザに大きな負担を強いる.人の音声やジェスチャなどを用いて効率的に操作したい家電を選択する方法がこれまでに提案されているが,音声の場合,家電を特定するために長い命令を必要とすることがある.ジェスチャの場合,ユーザは家電とジェスチャとの関連付けを覚えることが必要である.一方,認識されたコンテキスト情報に基づいてユーザに適したサービスを提供するアンコンシャス・インタラクションを実現するためには,正確かつユーザに負担がかからない手段でコンテキスト情報を認識することが重要である.コンテキスト情報は行動と位置情報に主に分けられる.既存の行動認識研究の多くは教師あり学習を用いるため,大量のトレーニングデータを用意するコストをユーザに強いる.一方,位置情報の既存研究は,人の位置と物の位置を推定するものに主に分けられる.物の位置,すなわちどこで何を使ったという情報はユーザの位置・行動を反映する1つ重要なコンテキストである.しかし, 一般的な物の位置推定手法ではRFIDタグなどのデバイスを物に添付する必要があり,導入コストとメンテナンスコストの問題が存在する.
本研究では,上述したコンシャスおよびアンコンシャス・インタラクションを実現する際の問題点に対する解決方法を提案した.(1)まずコンシャス・インタラクションを支援するため, Google Glassなどのスマートグラスを装着するユーザが操作したい家電を注目するだけで,Glassから撮影した画像とGlassに搭載されたさまざまなセンサから推定された人のコンテキスト情報を組み合わせることにより,その家電を高精度に選択することを可能とする手法を提案した.(2)アンコンシャス・インタラクションを支援するため,行動認識におけるトレーニングデータを準備するコストにかかわる問題に対して,異なる行動における同じ部位の類似センサデータを再利用することで,少量のトレーニングデータでも高精度の行動認識手法を提案した.(3)最後に,物の屋内位置を推定するための導入・メンテナンスコストの問題に対して,電気系統を流れる電流を安価な電流センサにより観測し,電圧降下現象に基づき,屋内の電化製品の利用位置を推定する手法を提案した.
本研究で提案した手法は日常生活におけるコンシャスおよびアンコンシャス・インタラクションの支援をより現実的にするものであり,人の生活のサポートおよび改善を可能とする知的環境の構築が容易になると期待される.また,環境は認識されたコンテキスト情報を基に最適なサービスを提供することが可能となる.たとえば,行動や家電利用位置情報に応じた温度や照明,空調の自動調整などの提供が期待される.
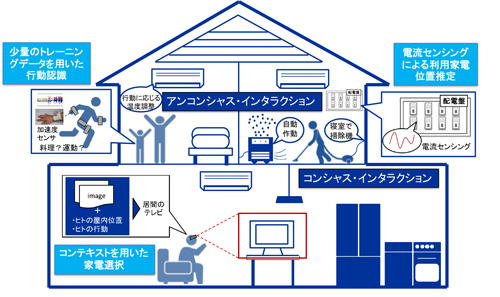
コンテキスト情報の認識および応用における知的環境の構築
(2016年6月11日受付)