
(邦訳:言語の普遍性を取り入れた統語モデリングのための左隅型解析法)
| 能地 宏 奈良先端科学技術大学院大学 情報科学研究科 助教 |
[背景]さまざまな言語の構文木の集合が利用可能に
[問題]あらゆる言語の構造に普遍的な偏りは何か
[貢献]左隅型解析のもつ言語普遍性抽出能力の検証
世界には何千という言語が存在するといわれ,また各言語はそれぞれ大きく異なっている.たとえば英語と日本語はSVOとSOVというように,語順も大きく異なる.しかしながら,言語はどれも,人間がコミュニケーションのために使う道具であるという点は共通している.この点に着目し,一見異なって見える言語にも何らかの共通の性質があるであろうという仮定のもと,その共通性(普遍性)を明らかにするということが本研究の目標である.このような言語の普遍性はそれ自体理学的にも興味深いものであるが,工学的にも,あらゆる言語の構造に対する事前知識,もしくは事前分布として利用できるという点で有用なものである.本研究では実際に,着目した普遍性を教師なし構文解析に活用し,多言語に渡って精度が向上することを示した.
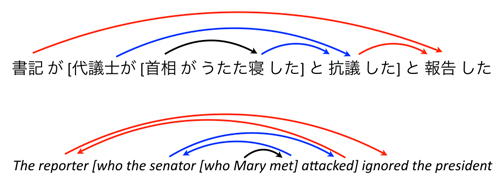
本研究では,言語の文法構造に見られる普遍性に着目する.特に「中央埋め込み文」と呼ばれる構造の文に着目し,この構造がどんな言語においても滅多に出現しない,ということを定量的に示した.図に示したのが,英語と日本語の中央埋め込み文の例である.中央埋め込み文はこのように,文の中に別の文(または節)が埋め込まれている構造を持っており,人間はこのような構造をうまく処理できないことが知られている.この現象は心理言語学では古くから注目されてきたものであるが,本研究はこの観察を推し進め,20以上に渡る言語のデータを統一的に解析することで,この観察が実際の言語データの上で普遍的に成り立つということを定量的に示した.具体的には,図のように2段の埋め込みを持つ構造がどんな言語でもほとんど出現しない,ということを発見した.
このような検証実験が可能になった背景として,近年のさまざまな言語に対する構文情報を付与したコーパスの蓄積があげられる.図の文には,構文情報として単語間の係り受けの情報が付与されている(代議士が -> 抗議,など).1つの言語に対し,このような構造を数千文〜数万文の規模で付与したデータはツリーバンクと呼ばれる.ツリーバンクは,自然言語処理における構文解析手法の主流である教師あり構文解析のために必要な資源であり,近年さまざまな言語で構築が進められている.本研究は,このように蓄積されたデータを言語理論の検証という立場から利用した先駆的な研究であるといえる.
さらに本研究では,この観察を教師なし構文解析と呼ばれる問題に適用し,その有効性を検証した.通常の構文解析は,図に示したような構造を予測する統計モデルを大量の教師データから学習するものであるが,教師なし構文解析ではこのような構造を構文構造の付与されていない文の集合のみから獲得することを目標とする.この目的のために,新たな学習のアルゴリズムとして,左隅型構文解析に基づく教師なし学習手法を構築した.左隅型構文解析は,文の構造の中央埋め込み度合いを解析中に捉えることのできる手法である.この観察のもと,左隅型構文解析の上で既存の確率モデルを定式化し,実際に提案手法が言語の構造の普遍的な性質及び偏りを抽出し,さまざまな言語の教師なし構文解析の精度を向上させられることを示した.
本研究では,言語の文法構造に見られる普遍性に着目する.特に「中央埋め込み文」と呼ばれる構造の文に着目し,この構造がどんな言語においても滅多に出現しない,ということを定量的に示した.図に示したのが,英語と日本語の中央埋め込み文の例である.中央埋め込み文はこのように,文の中に別の文(または節)が埋め込まれている構造を持っており,人間はこのような構造をうまく処理できないことが知られている.この現象は心理言語学では古くから注目されてきたものであるが,本研究はこの観察を推し進め,20以上に渡る言語のデータを統一的に解析することで,この観察が実際の言語データの上で普遍的に成り立つということを定量的に示した.具体的には,図のように2段の埋め込みを持つ構造がどんな言語でもほとんど出現しない,ということを発見した.
このような検証実験が可能になった背景として,近年のさまざまな言語に対する構文情報を付与したコーパスの蓄積があげられる.図の文には,構文情報として単語間の係り受けの情報が付与されている(代議士が -> 抗議,など).1つの言語に対し,このような構造を数千文〜数万文の規模で付与したデータはツリーバンクと呼ばれる.ツリーバンクは,自然言語処理における構文解析手法の主流である教師あり構文解析のために必要な資源であり,近年さまざまな言語で構築が進められている.本研究は,このように蓄積されたデータを言語理論の検証という立場から利用した先駆的な研究であるといえる.
さらに本研究では,この観察を教師なし構文解析と呼ばれる問題に適用し,その有効性を検証した.通常の構文解析は,図に示したような構造を予測する統計モデルを大量の教師データから学習するものであるが,教師なし構文解析ではこのような構造を構文構造の付与されていない文の集合のみから獲得することを目標とする.この目的のために,新たな学習のアルゴリズムとして,左隅型構文解析に基づく教師なし学習手法を構築した.左隅型構文解析は,文の構造の中央埋め込み度合いを解析中に捉えることのできる手法である.この観察のもと,左隅型構文解析の上で既存の確率モデルを定式化し,実際に提案手法が言語の構造の普遍的な性質及び偏りを抽出し,さまざまな言語の教師なし構文解析の精度を向上させられることを示した.
(2016年6月7日受付)